Redis数据组织方式
前言
Redis之所以高效,源自其优秀的架构设计。作为KV键值对存储数据库,数据的存储放在了内存中,KV键值对的组织方式更是其高效的原因之一。本文介绍其数据组织方式。
一、总体架构
在使用Redis时,服务端接收多个客户端的命令进行处理,Redis的命令处理采用单线程模型。Redis在处理KV键值对时,在其内部维护了一个dictht。所有的键值对,无论value值的数据类型是String、List、Hash、Set、ZSet等,其都会使用一个抽象的通用结构dictEntry放在这张dictht中。通过对Key值hash操作,然后取余,就可以得到一个值该值对应dictht中的一个位置。通过此方式将其记录到dictht中。这样后续查询通过dictht组织的所有的键值对,当一个Key值收到后,通过对Key值进行hash,然后取余,该值就对应了dictht中的某个位置。这个位置具体记录了value值的相关信息,就可以获取到该信息。其中对于dictht的大小也需要一种机制来控制。假如dictht的长度为4,此时需要存储5个Key,那么必定会出现hash碰撞,即两个Key值的hash值取余后是一样的。dictht解决哈希碰撞的方式是拉链法,每一个hash槽位记录的并非一个dictEntry地址,而是一个dictEntry链表的地址。找到对应dictht中的槽位后可以通过遍历链表获取到具体的key值信息。如下图所示:
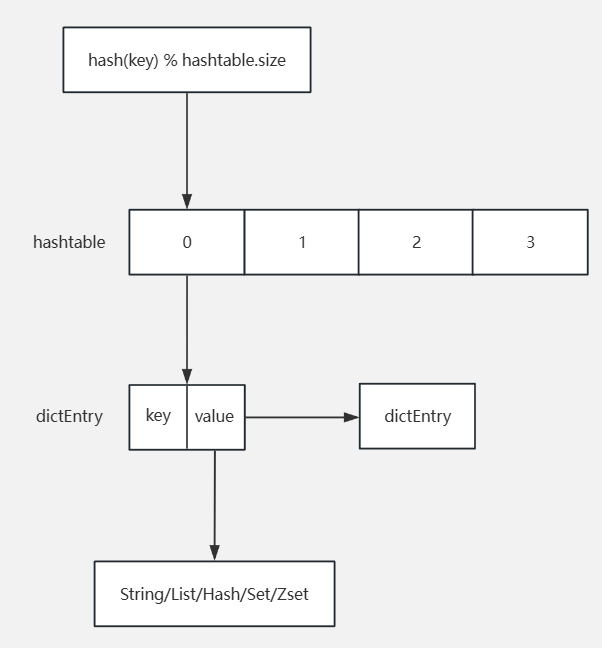
相关数据结构如下所示:
typedef struct dictEntry {void *key;union {void *val;uint64_t u64;int64_t s64;double d;} v;struct dictEntry *next;
} dictEntry;
typedef struct dictht {dictEntry **table;unsigned long size;// 数组长度unsigned long sizemask; //size-1unsigned long used;//当前数组当中包含的元素
} dictht;
typedef struct dict {dictType *type;void *privdata;dictht ht[2];long rehashidx; /* rehash 标志位*/int16_t pauserehash; /* If >0 rehashing is paused (<0 indicates coding error) 用于安全遍历*/
} dict;二、dictht的扩容与缩容
上述介绍了Redis的数据组织总体架构,即维护了dictht来维护所有的键值对,具体解决hash碰撞的方式为拉链法。这样就带来一个问题,当hash碰撞达到一定规模后,dictht中的链表就变得很长,此时dictht的查询效率就从O(1)退化到了O(n)。Redis对于该问题进一步通过对dictht扩容来解决。
此处介绍一个hash冲突的概念:负载因子。负载因子 = used / size。 used为数组存储元素的个数,size为数组长度。
负载因子可以反应hash冲突的程度,两者呈正比关系。Redis的负载因子上限为1。当Redis的负载因子 > 1时,会发生扩容。此时将dictht的长度扩容至原来的二倍。同时考虑数据的持久化操作,如果此时正在进行rdb、aof复写等持久化操作时,会阻止扩容。但是此时如果负载因子 > 5,则马上开始扩容。
既然扩容是为了解决hash冲突的问题,及利用扩大空间来提升dictht的查询效率从而提高Redis的查询效率。那么当dictht达到一定长度时,如果利用率较低,此时就会造成资源的浪费。Redis对于此问题采用dictht缩容来解决。
dictht的缩容也是根据负载因子,当负载因子 < 0.1 时,则会发生缩容。缩容的规则为缩减至恰好包含used的2的n次方。
三、渐进式rehash——合理解决扩容与缩容
上述提到了dictht的扩容与缩容,这两个操作是在不同情况下调整dictht到一个合适状态。但是这个调整操作相对于Redis的命令处理而言是一个耗时操作。同时Redis的命令处理必须依赖dictht提供查询Key值的功能。如果直接地进行扩容或者缩容此时会阻塞一定时间命令处理。导致客户端短时间内无法响应。针对此问题Redis采取渐进式rehash操作,既保证了Redis客户端命令的及时处理,也保证了dictht的扩容与缩容能够及时进行。
根据上述数据结构中dict的结构,可以看到其中ht变量,维护了两个dictht。这就是渐进式rehash的实现思路,Redis维护两个dictht,当需要进行rehash时,即需要进行扩容或者缩容时,Redis会将ht[0]中的元素重新经过hash函数生成64位整数,再对ht[1]的长度进行取余,从而映射到ht[1]中。
而渐进式rehash中的渐进体现在:上述对Key值的重新映射不是一次性完成的,因为上文也阐述过一次性完成该工作会长期占用Redis,导致阻塞命令处理流程。Redis采用分治的思想,把整体的rehash工作分摊到客户端发来的每一条命令(Key的增删改查)中。即在rehash阶段,执行的每条命令都会对其中的Key值进行rehash操作,从而完成整个rehash工作。如果此时Redis处于空闲状态,那么Redis内部维护一个定时器,在定时器规定事件中最大执行1ms的rehash操作,每次rehash100个数组槽位。这样在Redis空闲状态也能一直推进rehash工作。
对应两个ht的工作流程为:ht[0]:未发生rehash时,直接使用。rehash期间,存储了扩容和缩容前的数据。ht[1]:未发生rehash时,不会使用。rehash期间,其存储新的数据以及从ht[0]中迁移过来的数据。rehash工作完成后再将ht[0]指针直接指向ht[1]指向的数组,保证ht[0]永远指向正在使用的dictht。
更多资料:0voice · GitHub