Flash Attention与SDPA
在Transformer中,同一个标记会因其角色(查询、键或值)的不同而有不同的表示形式。这些就是投影嵌入,或者简称为投影,如图所示。更有趣的是,模型完全可以自主学习所有这些内容:嵌入本身,以及这三种不同类型的投影。
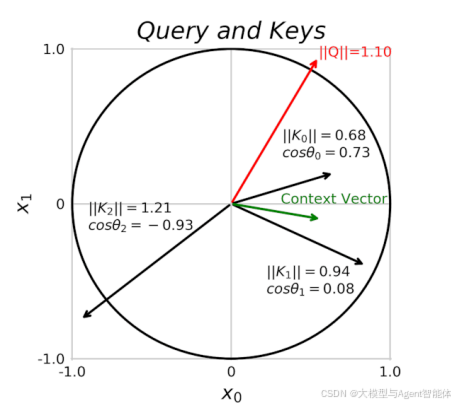
尽管这种方法简单且强大,但它存在一个主要瓶颈。你能猜到是什么吗?
内存再多也不为过
过去,我们在GPU内存方面没有遇到过重大问题。2017年,买一块配备6GB内存的GTX 1060显卡,当时它完全能满足训练任何模型的需求。但后来,Transformer模型和注意力机制出现了。如图所示,
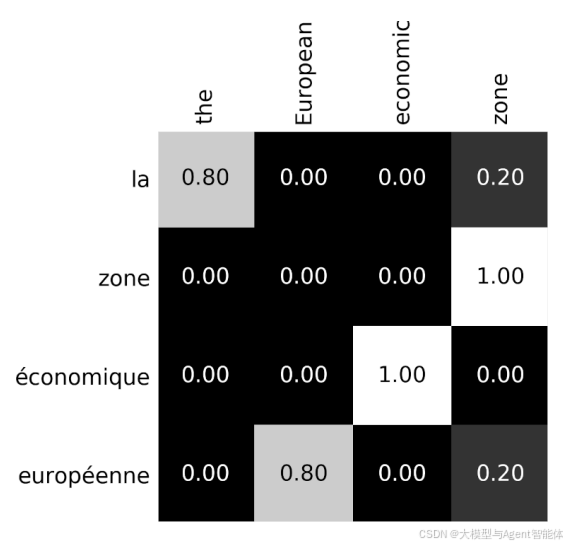
注意力机制需要计算成对的分数,因此分数的总数会随着序列长度的增加呈二次方增长。10个标记?需要计算100个分数。1000个标记?就需要100万个分数!而这还仅仅是针对一个注意力机制而言!
再想想,每个Transformer块(或称“层”)都有自己的注意力机制。这必然会带来一些问题,而首当其冲的就是单块GPU的内存。如今,从零开始训练Transformer模型已经不是普通人能在自家后院完成的事了,这成了大型科技公司的专属领域。这也是为什么我们现在主要从事微调工作的原因。
但即便是在微调时,这种耗费内存的注意力机制也会严重限制我们使用更长输