Python应用指南:获取风闻评论数据并解读其背后的情感倾向(二)
上一篇,我们已经成功获取到了风闻社区的评论数据,这些原始数据中蕴含着用户对各类话题的真实态度与情绪表达。然而,仅仅拥有数据并不足以洞察其背后的舆论趋势与情感脉络,真正有价值的是对这些非结构化文本进行系统化、智能化的分析,从而提炼出可理解、可量化的信息。在这篇文章中,我们将深入探讨如何借助 Python 编程语言,结合两种不同层级的自然语言处理技术——轻量级的 SnowNLP 与基于深度学习的 Erlangshen-RoBERTa-330M-Sentiment 模型,对风闻平台的评论数据进行全面而深入的情感倾向分析。
SnowNLP 是一个专为中文文本处理设计的开源 Python 库,其核心优势在于简洁易用、无需复杂依赖,特别适合快速搭建原型或在资源受限的环境中进行初步的情感分析。它基于朴素贝叶斯等传统机器学习方法,能够对中文句子进行分词、关键词提取、摘要生成以及情感打分。尽管其模型结构相对简单,但在许多常见场景下(如商品评论、社交媒体短文本),SnowNLP 依然能够提供较为合理的情感判断,尤其适用于对分析精度要求适中但追求开发效率和部署便捷性的项目。
相比之下,Erlangshen-RoBERTa-330M-Sentiment 则代表了当前中文自然语言处理领域的先进水平。该模型由 IDEA 研究院发布,基于强大的 RoBERTa 架构,并在大规模中文语料上进行了充分预训练,再通过情感分析任务进行微调,具备更强的语言理解能力。其 1.1 亿参数的体量使其能够捕捉文本中的深层语义、上下文依赖关系以及复杂的语言现象(如反讽、否定、程度副词修饰等),从而在情感分类任务中表现出更高的准确率和鲁棒性。尤其在面对风闻社区这类观点性强、表达方式多样、情绪波动明显的评论文本时,Erlangshen 模型能够更精准地区分正面、中性与负面情感,甚至识别出细微的情感强度差异。
通过对比使用 SnowNLP 和 Erlangshen-RoBERTa-330M-Sentiment 对同一组评论数据进行分析,我们不仅能获得两种不同精度层级的情感结果,还能进一步理解从“规则+统计”到“深度学习”的技术演进路径。这种对比分析不仅有助于评估不同模型在实际场景中的表现差异,也为后续选择合适的技术方案提供了实践依据——是追求快速响应与低成本部署,还是追求高精度与强泛化能力,将取决于具体的应用需求与资源条件。
废话不多说,这里直接放脚本,修改一下你实际储存数据的路径,和评论数据储存字段(如果和上篇一致的话就不用改);
完整代码#运行环境 Python 3.11
# sentiment_analysis.py
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from snownlp import SnowNLP
import jieba
from collections import Counter
import warnings
warnings.filterwarnings('ignore')
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS', 'DejaVu Sans'] # 支持中文
plt.rcParams['axes.unicode_minus'] = False# ================== 配置 ==================
file_path = r'D:\data\guancha_comments.csv'
output_file = r'D:\data\guancha_comments_with_sentiment.csv'print(" 开始加载数据...")
df = pd.read_csv(file_path)
print(f" 数据加载完成,共 {len(df)} 条评论")# --------------------------
# 1. 情感分析(SnowNLP)
# --------------------------
print(" 正在进行情感分析(可能需要几十秒)...")def get_sentiment_score(text):if pd.isna(text) or text.strip() == "" or text == "[空评论]":return 0.5 # 中性try:s = SnowNLP(text)return s.sentiments # 0~1,越接近1越积极except Exception as e:print(f" 情感分析失败: {e}")return 0.5df['sentiment_score'] = df['content'].apply(get_sentiment_score)# 情感分类
def classify_sentiment(score):if score < 0.4:return '负面'elif score <= 0.6:return '中性'else:return '正面'df['sentiment_label'] = df['sentiment_score'].apply(classify_sentiment)# 保存带情感分析的新文件
df.to_csv(output_file, index=False, encoding='utf-8-sig')
print(f" 情感分析完成,结果已保存至:\n {output_file}")# --------------------------
# 2. 可视化分析
# --------------------------
print(" 生成分析图表...")# 图1:情感分布饼图
plt.figure(figsize=(15, 10))plt.subplot(2, 3, 1)
sentiment_count = df['sentiment_label'].value_counts().reindex(['正面', '中性', '负面'])
sentiment_count.plot(kind='pie', autopct='%1.1f%%', colors=['#66cc99', '#ffcc66', '#ff6666'])
plt.title("情感分类占比")
plt.ylabel('')# 图2:情感得分直方图
plt.subplot(2, 3, 2)
sns.histplot(df['sentiment_score'], bins=30, kde=True, color='skyblue')
plt.axvline(0.5, color='red', linestyle='--', label='中性线')
plt.title('情感得分分布 (0=负面, 1=正面)')
plt.xlabel('情感得分')
plt.legend()# 图3:点赞数 vs 情感倾向
plt.subplot(2, 3, 3)
if df['praise_num'].max() > 0:df_box = df[df['praise_num'] <= df['praise_num'].quantile(0.95)] # 剔除异常值sns.boxplot(data=df_box, x='sentiment_label', y='praise_num', order=['正面', '中性', '负面'])plt.title("不同情感评论的点赞数分布")plt.xlabel("情感分类")
else:plt.text(0.5, 0.5, '点赞数全为0', ha='center', va='center', transform=plt.gca().transAxes)plt.title("点赞数据为空")# 图4:情感随时间变化(按小时)
df['datetime'] = pd.to_datetime(df['created_at_absolute'], errors='coerce')
df['hour'] = df['datetime'].dt.hour
hourly = df.groupby('hour')['sentiment_score'].mean()plt.subplot(2, 3, 4)
hourly.plot(marker='o', color='green')
plt.title("平均每小时情感得分趋势")
plt.xlabel("小时")
plt.ylabel("平均情感得分")
plt.grid(True, alpha=0.3)# 图5:负面评论高频词
plt.subplot(2, 3, 5)
negative_text = df[df['sentiment_label'] == '负面']['content']
words = []
for text in negative_text:if pd.isna(text) or len(str(text)) < 2:continueseg = jieba.cut(str(text))words.extend([w for w in seg if len(w) > 1 and w not in ['评论', '文章', '支持', '反对', '这个', '一个', '就是']])if words:counter = Counter(words).most_common(15)words_clean = [w[0] for w in counter]counts = [w[1] for w in counter]plt.barh(words_clean[::-1], counts[::-1], color='salmon')plt.title("负面评论高频词")
else:plt.text(0.5, 0.5, '无有效负面评论', ha='center', va='center', transform=plt.gca().transAxes)# 图6:正面评论高频词
plt.subplot(2, 3, 6)
positive_text = df[df['sentiment_label'] == '正面']['content']
words_p = []
for text in positive_text:if pd.isna(text) or len(str(text)) < 2:continueseg = jieba.cut(str(text))words_p.extend([w for w in seg if len(w) > 1 and w not in ['评论', '文章', '支持', '反对']])if words_p:counter_p = Counter(words_p).most_common(15)words_clean_p = [w[0] for w in counter_p]counts_p = [w[1] for w in counter_p]plt.barh(words_clean_p[::-1], counts_p[::-1], color='lightgreen')plt.title("正面评论高频词")
else:plt.text(0.5, 0.5, '无有效正面评论', ha='center', va='center', transform=plt.gca().transAxes)plt.tight_layout()
plt.savefig(r'E:\JT0529\sentiment_analysis_report.png', dpi=150, bbox_inches='tight')
print(" 分析图表已保存至: D:\\data\\sentiment_analysis_report.png")
plt.show()# --------------------------
# 3. 输出统计摘要
# --------------------------
print("\n" + "="*50)
print(" 情感分析摘要")
print("="*50)
print(f"总评论数: {len(df)}")
print(f"正面评论: {sentiment_count['正面']} 条 ({sentiment_count['正面']/len(df)*100:.1f}%)")
print(f"中性评论: {sentiment_count['中性']} 条 ({sentiment_count['中性']/len(df)*100:.1f}%)")
print(f"负面评论: {sentiment_count['负面']} 条 ({sentiment_count['负面']/len(df)*100:.1f}%)")
print(f"平均情感得分: {df['sentiment_score'].mean():.3f}")
print(f"平均点赞数: {df['praise_num'].mean():.2f}")# 高情感极端评论示例
top_positive = df.loc[df['sentiment_score'] > 0.95, ['content', 'praise_num']].head(3)
top_negative = df.loc[df['sentiment_score'] < 0.05, ['content', 'praise_num']].head(3)print("\n 极端正向评论示例(情感 > 0.95):")
for _, row in top_positive.iterrows():print(f" {row['praise_num']} | {row['content'][:100]}...")print("\n 极端负面评论示例(情感 < 0.05):")
for _, row in top_negative.iterrows():print(f" {row['praise_num']} | {row['content'][:100]}...")运行结束,我们会得到一个guancha_comments_with_sentiment.csv和sentiment_analysis_report.png图片,接下来我们进行看图说话;
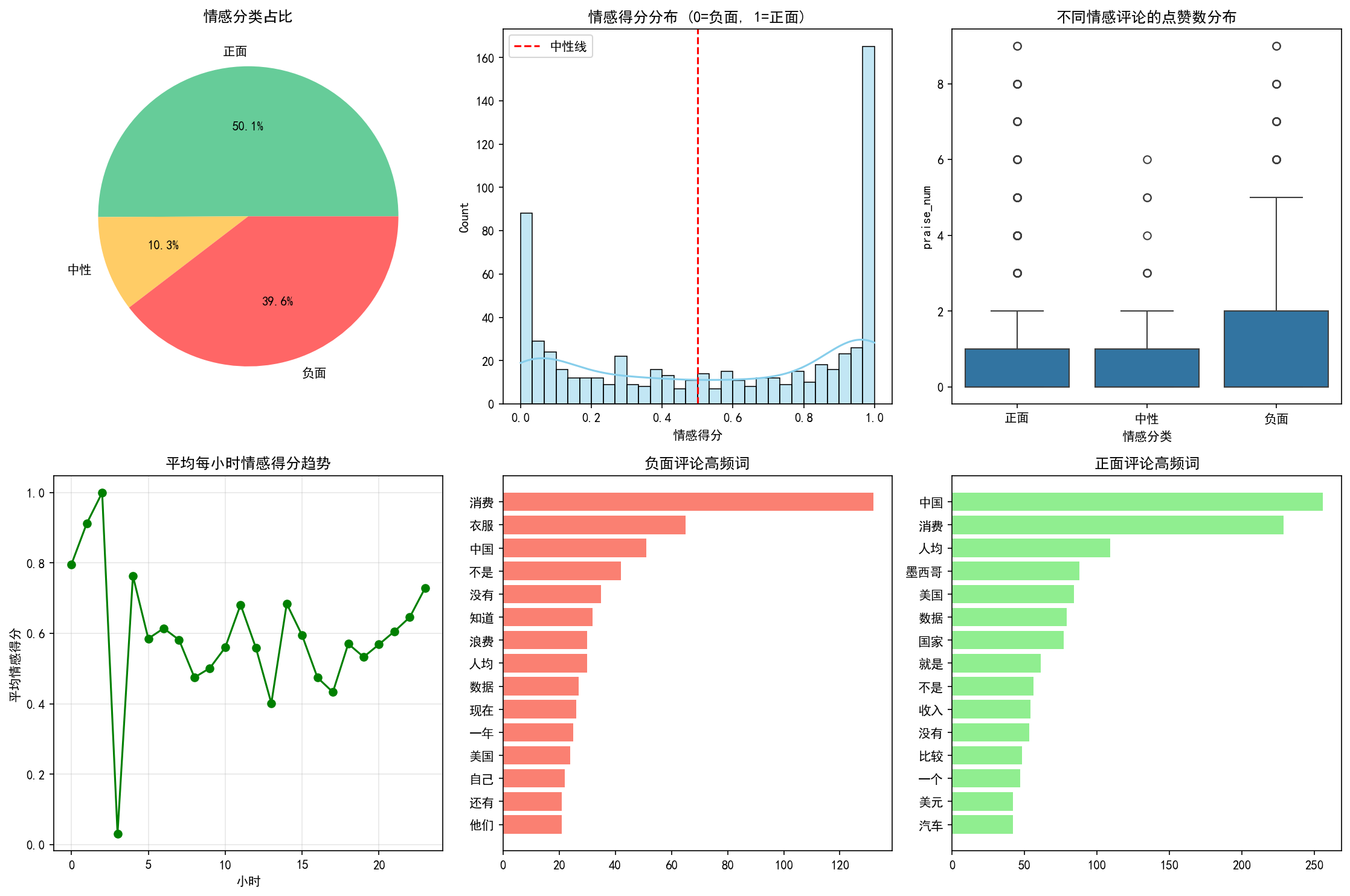
用SnowNLP Python 库分析出来的结果可以得出,风闻社区的评论整体呈现出较为积极的情感倾向。从情感分类占比来看,正面评论占据了50.1%,接近总数的一半,表明大多数用户在表达观点时持肯定或支持态度;负面评论占比为39.6%,虽然比例不低,反映出部分用户存在明显的不满或批评情绪,但总体上正面情绪仍占据主导地位;中性评论仅占10.3%,说明大多数评论都带有较明显的情感色彩,而非客观陈述。
进一步观察情感得分分布(0表示完全负面,1表示完全正面),可以发现评论得分主要集中在两端,即接近0或接近1的位置,而中间区域(0.4–0.6)的分布较少。这表明用户的情感表达较为极端,倾向于强烈支持或强烈反对,缺乏温和或中立的观点,体现出网络舆论场中常见的“两极分化”现象。
值得注意的是,在不同情感类别的评论中,负面评论获得的平均点赞数显著高于正面和中性评论。这一现象说明,尽管负面情绪的评论数量少于正面,但其在平台上的传播力和用户共鸣度更高,更容易引发关注和互动,可能对舆论走向产生更大的影响。
从时间维度看,平均每小时的情感得分呈现出一定的波动趋势,某些时段(如晚间或特定事件发生后)情感得分出现明显上升或下降,反映出用户情绪随时间或外部事件的变化而动态演化。这提示我们在进行舆情监控时,应结合时间序列分析,捕捉情绪波动的关键节点。
此外,通过对高频词的分析发现,负面评论中频繁出现“消费”“衣服”“不是”“浪费”等词汇,暗示用户对消费体验、产品质量或资源使用等方面存在较多不满;而正面评论中,“中国”“人均”“收入”“美元”等词出现频率较高,可能与国家认同、经济状况或生活水平等宏观话题相关,反映出用户在这些议题上的积极情绪。
综上所述,基于SnowNLP的情感分析结果不仅揭示了风闻社区评论的整体情感格局,也展现了用户情绪的分布特征、互动规律与话题关注点。尽管SnowNLP作为一种基于规则与统计的轻量级工具,在语义理解深度上存在一定局限,但其分析结果仍具备较强的可解释性和实用价值,适合作为舆情初筛与趋势把握的有效手段。
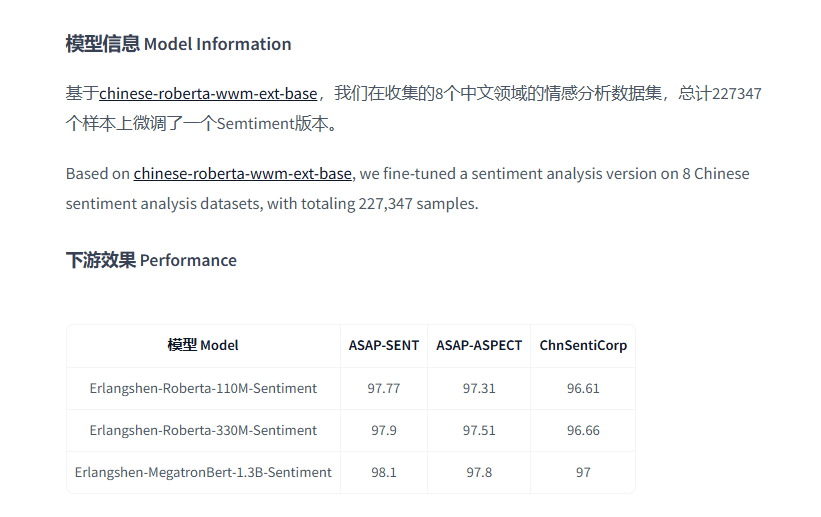
Erlangshen-RoBERTa-330M-Sentiment是一个专门针对中文情感分析任务优化的预训练模型,由IDEA研究院发布。这个模型基于RoBERTa架构,这是一种先进的Transformer架构变体,以其高效的训练策略和强大的语言理解能力著称。Erlangshen系列模型特别强调了在中文处理上的性能提升,旨在为中文文本提供更精准的情感分析结果。如果需要更高参数的模型,可以直接进行替换,把模型名称直接替换成例如 Erlangshen-MegatronBert-1.3B-Sentiment;
model_name = "IDEA-CCNL/Erlangshen-Roberta-330M-Sentiment"模型特点
-
参数规模:Erlangshen-RoBERTa-330M-Sentiment拥有约3.3亿个参数,这使得它能够在理解和捕捉文本中的复杂语义、上下文关系以及细微情感差异方面表现出色。
-
专为中文设计:与通用的语言模型相比,该模型针对中文的特点进行了优化,包括但不限于中文特有的语法结构、词汇使用习惯等,从而能够更好地服务于中文文本的情感分析任务。
-
深度学习基础:采用RoBERTa作为基础架构,意味着该模型继承了其所有的优点,如动态掩码(Dynamic Masking)、全词掩码(Whole Word Masking)等技术的应用,这些都有助于提高模型对文本的理解能力。
-
高精度情感分类:由于经过了大量中文语料的预训练,并进一步在特定领域的情感数据集上进行微调,Erlangshen-RoBERTa-330M-Sentiment能够提供比一般情感分析工具更高的准确率和更细致的情感分类结果。
预训练模型链接:IDEA-CCNL/Erlangshen-Roberta-110M-Sentiment ·拥抱脸
完整代码#运行环境 Python 3.11
# sentiment_analysis_transformers.py
import pandas as pd
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from collections import Counter
import jieba
import warningswarnings.filterwarnings('ignore')
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS', 'DejaVu Sans'] # 支持中文
plt.rcParams['axes.unicode_minus'] = False# ================== 配置 ==================
file_path = r'D:\data\guancha_comments.csv'
output_file = r'D:\data\guancha_comments_with_sentiment_transformers.csv'print("开始加载数据...")
df = pd.read_csv(file_path)
print(f"数据加载完成,共 {len(df)} 条评论")# 加载预训练模型和分词器
model_name = "IDEA-CCNL/Erlangshen-Roberta-330M-Sentiment"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)# --------------------------
# 1. 情感分析(Transformers)
# --------------------------
def get_sentiment_score(text):if pd.isna(text) or text.strip() == "" or text == "[空评论]":return 0.5 # 中性inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True, max_length=512)with torch.no_grad():outputs = model(**inputs)scores = torch.softmax(outputs.logits, dim=-1).cpu().numpy()[0]# 假设模型输出为二分类:[负面, 正面]score = scores[1] # 取正面概率作为得分return float(score)print("正在进行情感分析(可能需要几分钟)...")
df['sentiment_score'] = df['content'].apply(get_sentiment_score)# 情感分类
def classify_sentiment(score):if score < 0.4:return '负面'elif score <= 0.6:return '中性'else:return '正面'df['sentiment_label'] = df['sentiment_score'].apply(classify_sentiment)# 保存带情感分析的新文件
df.to_csv(output_file, index=False, encoding='utf-8-sig')
print(f"情感分析完成,结果已保存至:\n {output_file}")# --------------------------
# 2. 可视化分析
# --------------------------
print("生成分析图表...")# 图1:情感分布饼图
plt.figure(figsize=(15, 10))plt.subplot(2, 3, 1)
sentiment_count = df['sentiment_label'].value_counts().reindex(['正面', '中性', '负面'])
sentiment_count.plot(kind='pie', autopct='%1.1f%%', colors=['#66cc99', '#ffcc66', '#ff6666'])
plt.title("情感分类占比")
plt.ylabel('')# 图2:情感得分直方图
plt.subplot(2, 3, 2)
sns.histplot(df['sentiment_score'], bins=30, kde=True, color='skyblue')
plt.axvline(0.5, color='red', linestyle='--', label='中性线')
plt.title('情感得分分布 (0=负面, 1=正面)')
plt.xlabel('情感得分')
plt.legend()# 图3:点赞数 vs 情感倾向
plt.subplot(2, 3, 3)
if df['praise_num'].max() > 0:df_box = df[df['praise_num'] <= df['praise_num'].quantile(0.95)] # 剔除异常值sns.boxplot(data=df_box, x='sentiment_label', y='praise_num', order=['正面', '中性', '负面'])plt.title("不同情感评论的点赞数分布")plt.xlabel("情感分类")
else:plt.text(0.5, 0.5, '点赞数全为0', ha='center', va='center', transform=plt.gca().transAxes)plt.title("点赞数据为空")# 图4:情感随时间变化(按小时)
df['datetime'] = pd.to_datetime(df['created_at_absolute'], errors='coerce')
df['hour'] = df['datetime'].dt.hour
hourly = df.groupby('hour')['sentiment_score'].mean()plt.subplot(2, 3, 4)
hourly.plot(marker='o', color='green')
plt.title("平均每小时情感得分趋势")
plt.xlabel("小时")
plt.ylabel("平均情感得分")
plt.grid(True, alpha=0.3)# 图5:负面评论高频词
plt.subplot(2, 3, 5)
negative_text = df[df['sentiment_label'] == '负面']['content']
words = []
for text in negative_text:if pd.isna(text) or len(str(text)) < 2:continueseg = jieba.cut(str(text))words.extend([w for w in seg if len(w) > 1 and w not in ['评论', '文章', '支持', '反对', '这个', '一个', '就是']])if words:counter = Counter(words).most_common(15)words_clean = [w[0] for w in counter]counts = [w[1] for w in counter]plt.barh(words_clean[::-1], counts[::-1], color='salmon')plt.title("负面评论高频词")
else:plt.text(0.5, 0.5, '无有效负面评论', ha='center', va='center', transform=plt.gca().transAxes)# 图6:正面评论高频词
plt.subplot(2, 3, 6)
positive_text = df[df['sentiment_label'] == '正面']['content']
words_p = []
for text in positive_text:if pd.isna(text) or len(str(text)) < 2:continueseg = jieba.cut(str(text))words_p.extend([w for w in seg if len(w) > 1 and w not in ['评论', '文章', '支持', '反对']])if words_p:counter_p = Counter(words_p).most_common(15)words_clean_p = [w[0] for w in counter_p]counts_p = [w[1] for w in counter_p]plt.barh(words_clean_p[::-1], counts_p[::-1], color='lightgreen')plt.title("正面评论高频词")
else:plt.text(0.5, 0.5, '无有效正面评论', ha='center', va='center', transform=plt.gca().transAxes)plt.tight_layout()
plt.savefig(r'E:\JT0529\sentiment_analysis_report_transformers.png', dpi=150, bbox_inches='tight')
print("分析图表已保存至: D:\\data\\sentiment_analysis_report_transformers.png")
plt.show()# --------------------------
# 3. 输出统计摘要
# --------------------------
print("\n" + "="*50)
print("情感分析摘要")
print("="*50)
print(f"总评论数: {len(df)}")
print(f"正面评论: {sentiment_count['正面']} 条 ({sentiment_count['正面']/len(df)*100:.1f}%)")
print(f"中性评论: {sentiment_count['中性']} 条 ({sentiment_count['中性']/len(df)*100:.1f}%)")
print(f"负面评论: {sentiment_count['负面']} 条 ({sentiment_count['负面']/len(df)*100:.1f}%)")
print(f"平均情感得分: {df['sentiment_score'].mean():.3f}")
print(f"平均点赞数: {df['praise_num'].mean():.2f}")# 高情感极端评论示例
top_positive = df.loc[df['sentiment_score'] > 0.95, ['content', 'praise_num']].head(3)
top_negative = df.loc[df['sentiment_score'] < 0.05, ['content', 'praise_num']].head(3)print("\n 极端正向评论示例(情感 > 0.95):")
for _, row in top_positive.iterrows():print(f" {row['praise_num']} | {row['content'][:100]}...")print("\n 极端负面评论示例(情感 < 0.05):")
for _, row in top_negative.iterrows():print(f" {row['praise_num']} | {row['content'][:100]}...")运行结束,我们会得到一个guancha_comments_with_sentiment_transformers.csv和sentiment_analysis_report_transformers.png图片,接下来我们进行看图说话;
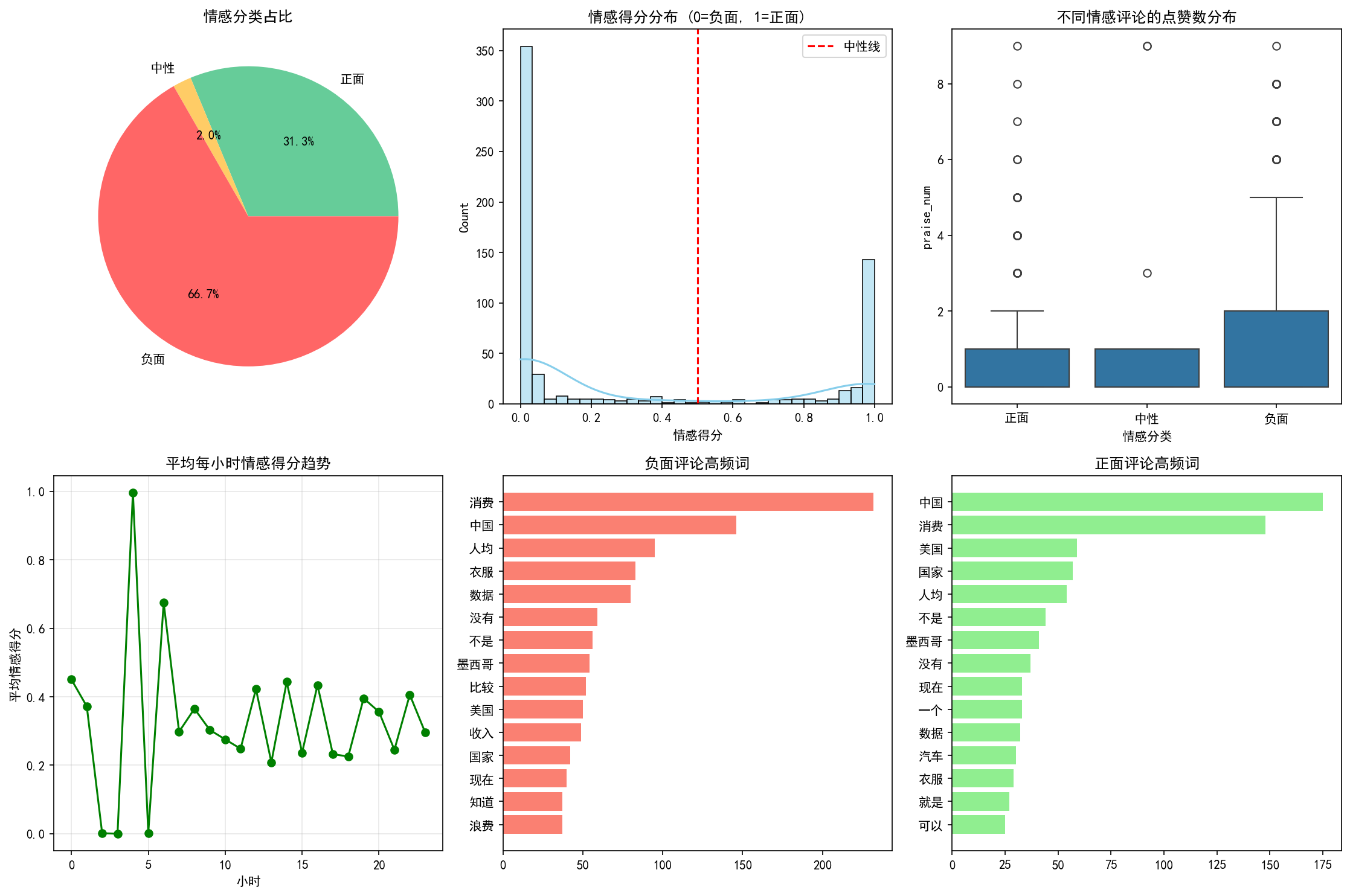
利用Erlangshen-RoBERTa-330M-Sentiment模型进行分析的结果揭示了风闻社区评论数据中更为细致和精准的情感倾向。从情感分类占比来看,负面评论占据了66.7%的显著比例,表明大多数用户在讨论中表达了不满或批评的情绪;正面评论占31.3%,虽然仍有一定数量的支持声音,但明显少于负面评论;中性评论仅占2.0%,进一步凸显了评论情感的两极分化特征。
在情感得分分布图中,我们可以看到评论得分主要集中在两端,即接近0(完全负面)和接近1(完全正面),中间区域的分布极少。这与SnowNLP的分析结果类似,再次验证了用户在表达观点时倾向于极端化,要么强烈支持,要么明确反对,缺乏中立立场。这种分布模式反映了网络舆论场中常见的“情绪极化”现象,可能受到群体心理、信息茧房效应等因素的影响。
不同情感类别的评论点赞数分布显示,负面评论同样获得了较高的互动量,平均点赞数显著高于正面和中性评论。这一结果与SnowNLP的分析一致,说明尽管负面情绪的评论数量较多,但其在平台上的传播力和用户共鸣度更高,更容易引发关注和讨论,对整体舆论环境产生重要影响。
平均每小时情感得分的趋势图揭示了时间维度上情感波动的规律。某些时段内,情感得分出现明显的上升或下降,如在特定事件发生后或晚间活跃时段,用户情绪变化较为剧烈。这提示我们在舆情监控和管理中,应结合时间序列分析,及时捕捉情绪波动的关键节点,以便采取相应的应对措施。
高频词分析进一步揭示了用户关注的具体话题和情感驱动因素。在负面评论中,“消费”“中国”“人均”等词频较高,反映出用户对消费体验、国家发展及生活水平等方面的不满;而正面评论中,“中国”“消费”“美国”等词也频繁出现,但结合上下文,这些词汇可能被用于表达积极的态度或评价,如对中国发展的认可、对消费市场的看好等。此外,“墨西哥”“比较”“收入”等词的出现,可能反映了用户在国际比较、经济状况等方面的观点和态度。
综上所述,基于Erlangshen-RoBERTa-330M-Sentiment模型的分析结果不仅提供了更准确的情感判断,还揭示了评论数据中的深层语义和复杂情感。尽管负面情绪占据主导地位,但通过细致的高频词分析和时间趋势观察,我们能够更好地理解用户的真实想法和关注点,为舆情分析、品牌管理和社会研究提供有力支持。与SnowNLP相比,Erlangshen模型在处理复杂语言现象和细微情感差异方面表现出更强的能力,适用于需要高精度分析的场景。

这里也是选取了部分评论数据进行主观判断,以验证模型分析结果的合理性。通过对原始评论文本的人工阅读与情感倾向标注,并将其与Erlangshen-RoBERTa-330M-Sentiment的预测结果进行对比,可以明显发现,该模型在处理中文语境下的复杂表达、否定结构、反讽语气以及程度副词修饰等方面具有更强的识别能力。例如,面对诸如“这服务真是‘好’到让人想投诉”这类带有引号强调或反语色彩的句子,模型能够更准确地判定为负面情感,而不会被表面词汇误导。
相比之下,未在中文情感数据上深度微调的通用模型或轻量级工具(如SnowNLP)往往难以捕捉此类语义细节,容易出现误判。这充分说明,使用在中文领域、特别是情感分析任务上经过大量标注数据预训练和微调的模型,如Erlangshen-RoBERTa-330M-Sentiment,其对评论情绪倾向的判断不仅更具语义敏感性,也更符合人类的主观理解。因此,在追求高精度情感分析的实际应用场景中,选择领域适配性强、训练充分的深度学习模型,能够显著提升分析结果的可靠性与实用性。
文章仅用于分享个人学习成果与个人存档之用,分享知识,如有侵权,请联系作者进行删除。所有信息均基于作者的个人理解和经验,不代表任何官方立场或权威解读。