在NVIDIA Orin上用TensorRT对YOLO12进行多路加速并行推理时内存泄漏
1.前因
在英伟达的Jetson Orin NX使用TensorRT对YOLO12s的人体姿态检测进行多路并行推理时,发现模型总是无法进行长时间的推理。内存持续增长,可能最多十分钟就自己挂掉,kill。在数次控制变量后,发现YOLO12的人体姿态估计在后处理这一块是远远复杂于YOLO12的目标检测任务的。而且后者可以保持数周的长时间稳定运行。
2.排查问题
1)首先是,使用内存分析工具,确定情况是否如上所推测
使用 memory_profiler 工具来监控内存使用情况。首先安装 memory_profiler:
pip install memory-profiler
2)然后在代码中添加 @profile 装饰器来标记需要监控的函数(仅监控后处理相关函数):
from memory_profiler import profileclass yolo12_trt_pose:@profiledef xywh2xyxy_with_keypoints(self, origin_h, origin_w, boxes, keypoints):#######return box_array, keypoint_array@profiledef post_process(self, output, origin_h, origin_w):# Return the post-processed results including keypointsreturn result_boxes, result_scores, result_classid, result_keypoints@profiledef bbox_iou(self, box1, box2, x1y1x2y2=True):return iou@profiledef non_max_suppression(self, prediction, origin_h, origin_w, conf_thres=0.5, nms_thres=0.4):return res_array》
3)运行带有 @profile 装饰器的代码,并使用 mprof 命令来查看内存使用情况:(第一个命令运行会产生.dat文件,第二个命令用于.dat文件可视化)
mprof run your_script.py
mprof plot
保存mprof的输出到本地化log文件
mprof run your_script.py > mprof_output.log 2>&1
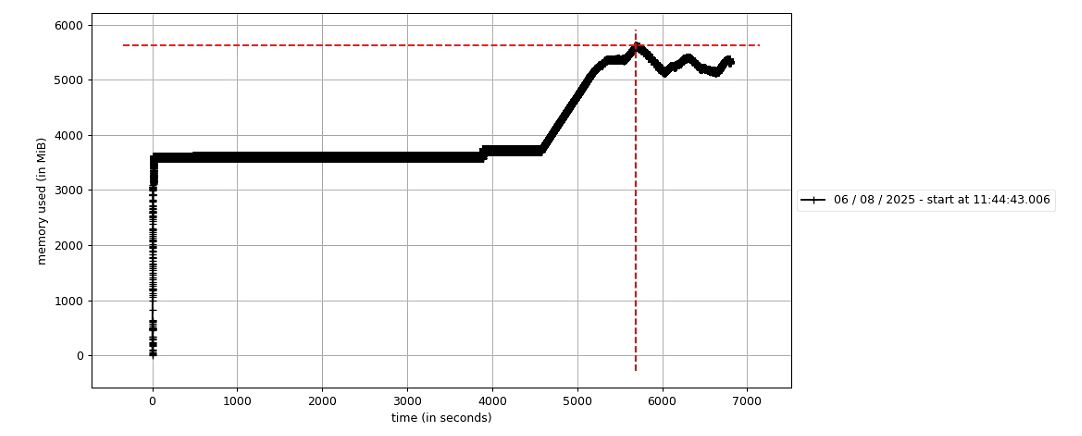
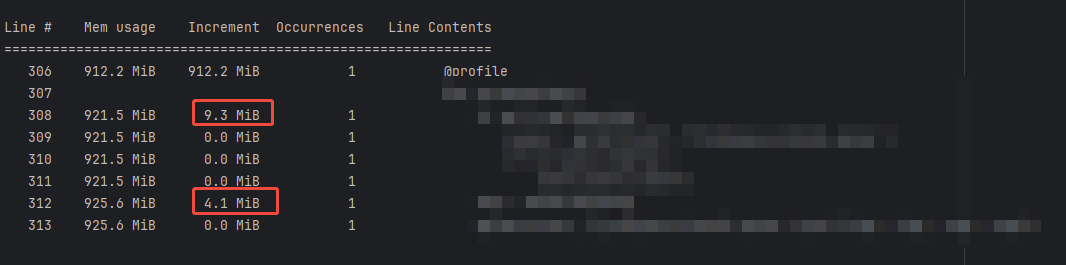
4)结果显示:和后处理的计算部分并无关系,那导致内存不断增长的原因就不是后处理部分了。同时,前处理部分也进行了相同方法的内存异常排查。
从下图可以直观看出,内存在持续增长,而不是平稳持平。
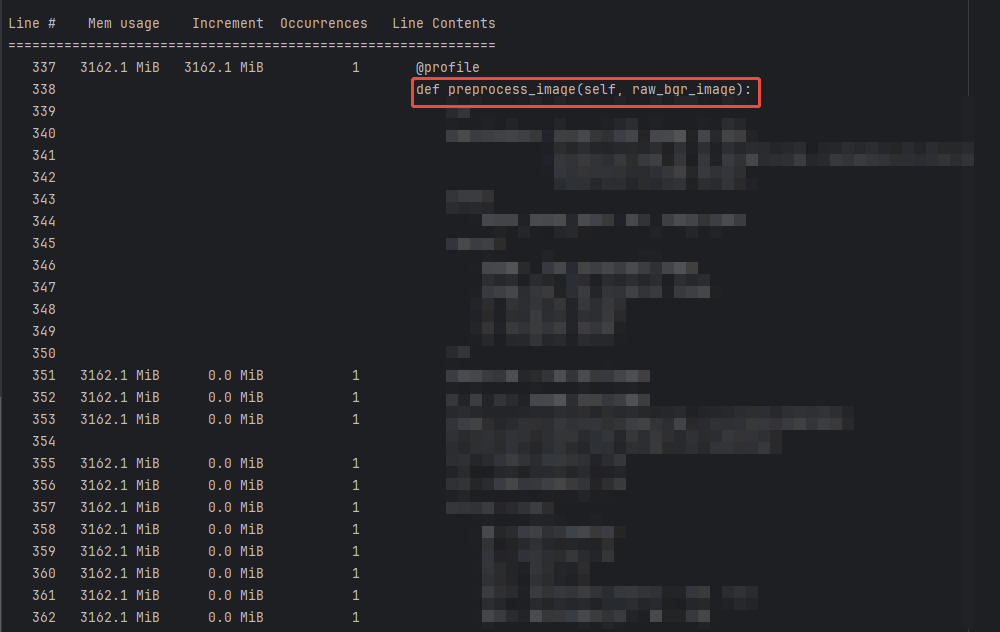
前处理:内存未增加
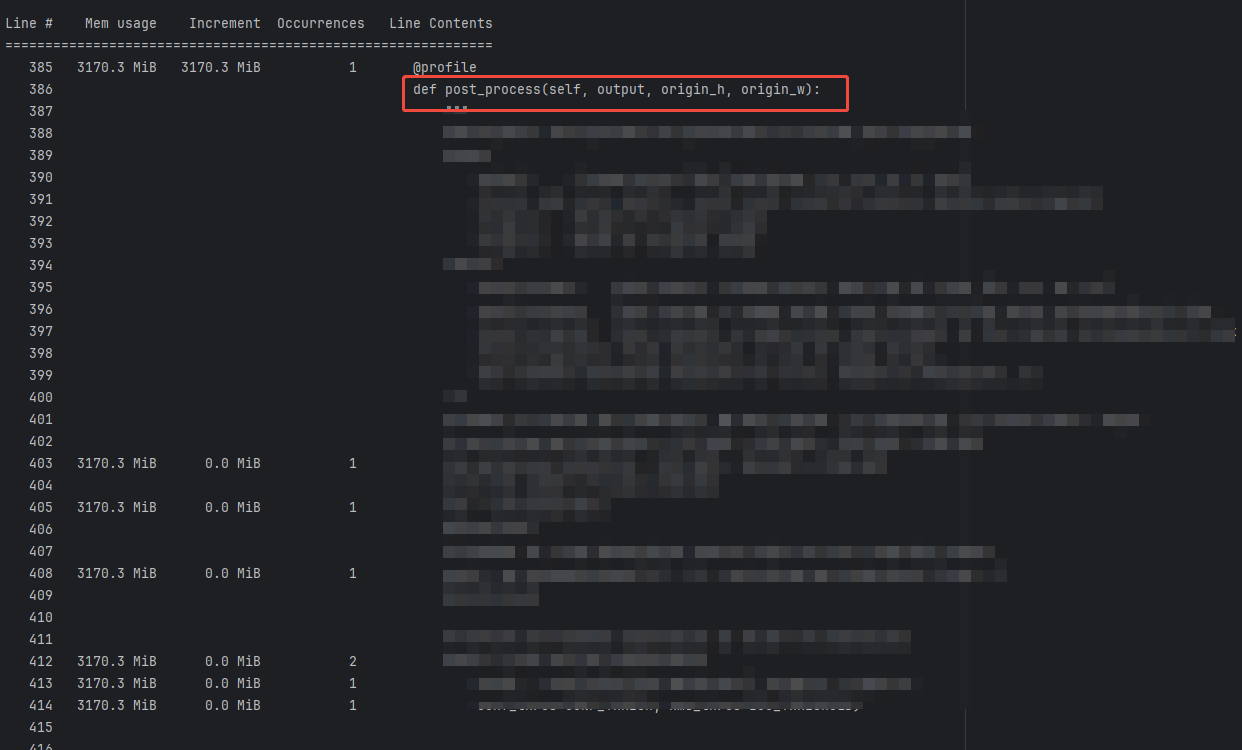
后处理:内存未增加
解码部分:内存在持续增长
3.解决方案
通过排查得出的结论,于是乎对解码后的存储多路视频帧数据的管理逻辑重新梳理。
在这个过程中发现,使用 queue.Queue 时,直接调用其内部属性 queue.queue.clear() 虽然能清空队列元素,但在多线程场景下可能存在线程安全问题(导致清空不彻底或异常)。
然后,改为在队列清空逻辑中,queue.get_nowait() 配合循环的清理方式,本质是通过逐个取出并丢弃队列中所有元素来实现清空,这是基于队列公开接口的线程安全操作。
while not queue.empty():try:queue.get_nowait() # 非阻塞取出一个元素except Empty:break