秋招笔记-8.6
昨天开组会投文章以及玩苏丹的游戏去了,今天得知不久后有面试,所以我们需要快速地过一下基本的八股和项目。
C#
一个很容易被忽略的点:C#的类是单继承而C++是多继承(因而导致了菱形继承问题)。
C#中的const和C++中的完全不同,C#中的const必须在声明时初始化有值(和C++的constexpr相同),而C#中的readonly则运行在构造函数时初始化值(和C++的const类似)。
C#中的string为什么具有不可修改性?众所周知我们的string在修改时不会直接去修改原对象而是会拷贝一份新的对象之后返回修改后的新对象,然后把旧对象变为可以回收的资源,那么为什么要这样设计呢?
第一个重要的原因在之前的笔记中是有介绍过的,就是为了避免使用锁在多线程时避免竞态条件带来的开销;这里还要补充一个点就是我们的C#的内部是有一个字符串池的,针对字符串常量在C#中对于相同的字符串我们是复用一个对象的(动态生成的字符串会创建独立对象)。
我们都知道C#的数据类型大体上会分为两个类型:值类型和引用类型,但是具体区分的方式是什么呢?或者说从哪个角度导致了二者的不同呢?
一开始我以为是根据数据存储的位置来区分的,客观地说也没太大问题,值类型基本存储在栈上而引用类型基本存储在堆上(其实是把堆中的地址存储在栈上,地址指向的内存存储具体的值)。但其实最根本的核心差异是存储数据的方式,值类型就是直接存储数据的,而引用类型则是存储相应的地址,从这个角度来说,C#的引用颇有C++的指针的感觉。

foreach与for:不久前才介绍过,但是这里还是忍不住介绍一下因为确实比较底层;foreach不需要具体访问的数据容器的大小;foreach是只读循环,不可以对数据容器中的实际数据修改;foreach会产生比较大的GC开销。为什么会有GC开销?
关于反射,C#的反射机制是通过System.Reflection命名空间中的API(如Type、MethodInfo、PropertyInfo等)在运行时动态获取和操作元数据的核心能力,而元数据本质是“描述数据的数据”,具体包含代码中类型的结构(如类/接口定义)、成员细节(方法签名、字段类型、属性访问器)、程序集属性(版本号、强名称签名)以及附加的特性标记(如[Serializable]或自定义[Attribute])。这些元数据在C#源码编译时由编译器生成,并嵌入到程序集(Assembly)中,程序集作为.NET应用程序的物理部署单元(表现为.dll或.exe文件),其内容除元数据外还包括中间语言代码(IL)、清单(Manifest)以及可选的资源文件;其中IL是平台无关的指令集,清单则记录程序集自描述信息(如依赖项和公开类型),共同构成程序集的完整逻辑结构。在运行时,.NET平台通过两种路径执行程序集:其一由CLR(公共语言运行时)加载程序集,通过JIT(即时编译器)将IL动态编译为当前平台的机器码执行;其二在特定环境(如Unity的IL2CPP后端)中,IL会先被转换为C++代码,再经由传统C++工具链(预编译→编译→汇编→链接)生成原生机器码运行,此过程虽牺牲部分动态性但提升执行效率和跨平台兼容性。反射机制正是通过访问程序集内预置的元数据,在运行时实现类型发现(如Assembly.GetType("MyClass"))、动态实例化(如Activator.CreateInstance)及成员操作(如MethodInfo.Invoke),从而支撑插件化架构、序列化框架等动态场景,但其性能开销需通过缓存或预编译策略优化。综上,C#从源码到执行的完整流程可概括为:源码编译生成含IL与元数据的程序集 → 运行时由CLR/JIT转换为机器码执行,或经IL2CPP转为C++代码后由本地工具链编译为原生二进制执行。
反射的优缺点:
在 C# 中,匿名方法(Anonymous Methods)的核心本质是通过 delegate 关键字实现的匿名委托,它允许开发者在不定义独立命名方法的情况下,直接内联编写代码块并赋值给委托对象。
// 定义委托类型
delegate void PrintDelegate(string message);// 匿名方法赋值给委托
PrintDelegate print = delegate(string msg)
{ Console.WriteLine(msg);
};
print("Hello, Anonymous Delegate!"); // 输出:Hello, Anonymous Delegate!在这个基础上,匿名方法还有所谓的闭包功能,也就是变量捕获,它可以去获取定义匿名方法程序块的作用域之外的变量来使用,这样会延长二者的生命周期。
关于.NET:之前在介绍Unity的跨平台原理中也提到了,.NET主要就是一个提供了诸如运行时,一系列API的一个完整的开发平台,Mono则是在这个基础上将原来只能在Windows操作系统运作的.NET扩展到了其他的操作系统,Mono本质上是.NET的一部分。
关于using:我们知道using在C#中有第三种用法,也就是自动销毁实现了IDisposable接口的类的实例。
using (var resource = new ResourceType())
{// 使用 resource 操作资源
} // 此处自动调用 resource.Dispose()本质上编译器在执行时会把using执行为try-finally来保证销毁相应的资源。
关于GC:
C#的垃圾回收机制(GC)以托管堆为基础,通过分代回收(Generational Collection)和内存压缩(Compaction)两大核心策略实现高效内存管理。其设计基于“弱代假设”——绝大多数新对象生命周期极短,因此将堆划分为三个代龄:新对象首先进入第0代(Gen 0),此处回收频率最高(如内存满时自动触发),能在毫秒内清理90%以上的短期对象(如局部变量);存活对象晋升至第1代(Gen 1)作为缓冲区,回收频率较低;长期存活对象最终进入第2代(Gen 2),仅当内存严重不足时才触发回收,避免频繁处理长期对象的高昂开销。这种分层回收显著降低了GC的整体负担,优先快速清理短期对象,再逐级处理长期对象。
每次GC回收后(尤其是Gen 0和Gen 1),会执行内存压缩:暂停所有线程以保证引用关系稳定,将存活对象向堆的起始端移动,形成连续内存块,消除碎片空隙,最后更新所有对象引用指针。此过程解决了内存碎片化问题,使后续对象分配只需简单移动堆指针,无需搜索空闲链表,极大提升了分配效率和CPU缓存局部性。但压缩存在两项例外:大对象(≥85,000字节) 直接分配在大对象堆(LOH),默认不压缩以避免移动成本;钉住对象(Pinned Objects)(如通过fixed关键字或传递给非托管代码的对象)无法移动,以免破坏非托管代码中的地址引用。
相比之下,Unity传统GC(基于Boehm算法) 放弃压缩的核心原因是实时性约束。游戏帧率要求(如60FPS/16ms每帧)无法容忍压缩所需的全局线程暂停(Stop-the-World),尤其当堆中存活对象较多时,移动对象并修复指针的耗时可能达数百毫秒,远超单帧预算。此外,Unity的GC不分代,每次回收均需全堆扫描,若强行压缩会加剧卡顿;其保守式扫描还可能误判数值为指针,移动对象会导致数据损坏。因此Unity转而依赖增量式GC(分帧执行标记/清除)、对象池复用及预分配策略间接缓解碎片,代价是可能因碎片触发内存不足(OOM)。本质而言,C#的压缩与分代协同优化了内存利用率与分配速度,而Unity为保实时性牺牲压缩,凸显了通用运行时与实时引擎在设计目标上的根本差异——前者优先内存效率,后者容忍碎片以换取稳定帧率
C++
关于constexpr:我们知道这个关键字修饰的常量是编译时常量,而编译时常量是存储在内存分区中的常量区的。
关于dynamic_cast:只能转指针或者引用。核心原因是其依赖对象的虚指针和 RTTI 实现运行时类型安全,而值类型传递会触发对象切片,破坏 vptr 和 RTTI 的完整性,使类型信息丢失。指针/引用通过直接操作原始内存地址,确保 vptr 始终指向实际类的虚表,从而为 dynamic_cast 提供必要的类型检查基础。
关于对象切片:

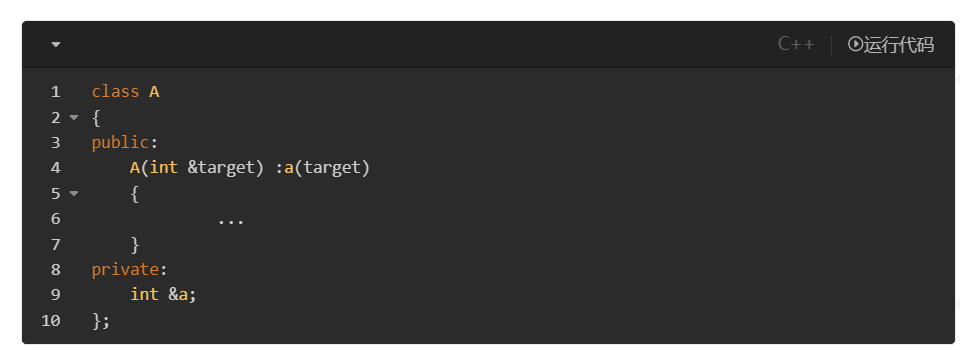
类中可以定义引用数据成员吗?答案是可以的,但是这个引用类型的变量必须用外部的引用变量初始化才可以。
new和delete的底层原理:
new 操作符的底层实现机制可以理解为两个关键步骤的协作:首先通过调用全局的 operator new 函数申请原始内存空间,该函数在默认情况下封装了 malloc 的逻辑,负责按指定大小分配内存,并在失败时抛出 std::bad_alloc 异常(而非返回空指针),确保了类型安全和异常处理机制。随后,在分配的内存地址上显式调用对象的构造函数(通过编译器隐式插入的定位 new(placement new)完成初始化,即 new (address) T(args) 的形式,从而将原始内存转化为一个构造完成的合法对象。对于数组分配(new T[n]),若元素类型包含析构函数,编译器会额外分配 4 或 8 字节存储元素数量 n,置于实际对象内存之前,以便后续析构时能正确遍历所有元素。
delete 操作符的执行过程与 new 严格对称但逆向操作:它首先利用对象的指针直接调用对象的析构函数释放对象内部的资源(内置类型可跳过),随后通过 operator delete 释放内存(默认封装 free)。对于数组(delete[]),其机制依赖 new[] 分配的隐藏计数头——它从内存块头部读取元素数量 n,并逆序调用所有元素的析构函数(从最后一个元素开始),最终释放整块含计数头的内存。若 new[] 与 delete 混用(或 new 与 delete[] 混用),会导致析构次数错误(仅析构首元素)或内存释放位置错位,引发未定义行为或崩溃。这一机制的核心在于将内存分配/释放(operator new/delete)与对象生命周期管理(构造/析构)解耦,既兼容 C 的底层内存操作,又通过自动化构造析构实现了 C++ 的对象语义。
C++中不同类型的new的用法:

关于STL的分配器Allocator:
STL的分配器负责给STL中的容器分配和管理空间,这里有两个二:一是STL的分配空间有两级,对于较小的内存需求,分配器直接分配内存池中的内存块,而对于较大的内存需求,分配器会重新去堆中申请内存;二是STL分配器在分配/释放内存时,会分为两阶段执行,分配时先调用allocate()方法执行申请内存,然后再执行对象的构造函数,释放时会先执行析构函数,再执行deallocate()释放内存。
STL迭代器如何删除元素?
对于顺序容器来说,当我们通过迭代器删除某个元素时,后序的迭代器会全部失效,所有后面的迭代器会往前移动一位,然后返回指向下一个元素的迭代器;对于无序容器来说,erase会返回指向下一个元素的迭代器;对于有序关联容器如map,底层是基于红黑树实现的自动维护有序的容器,所以只需要递增迭代器即可;对于list,直接返回下一个元素的迭代器即可。

关于迭代器:
我们都知道迭代器的本质是一个封装了指针的模板类,并提供了类似指针的++,--操作,但是迭代器实际返回的是对象的引用,所以对于迭代器我们要解引用才能使用。
map的insert()插入和直接重载[]实现插入的差异:如果插入前已经存在插入的key,那么[]会覆盖掉原来的键值对而insert不会。
sort的原理:一般情况下使用快速排序,针对较少的数据时使用插入排序,当快速排序递归深度过大时转换成堆排序。至于sort底层的这三种算法:
关于仿函数和匿名函数:可能乍一看这两个东西的关系似乎不大,但其实这两个东西设计的初衷都是帮助你避免重复或者冗余的函数定义,但是二者有什么区别呢?
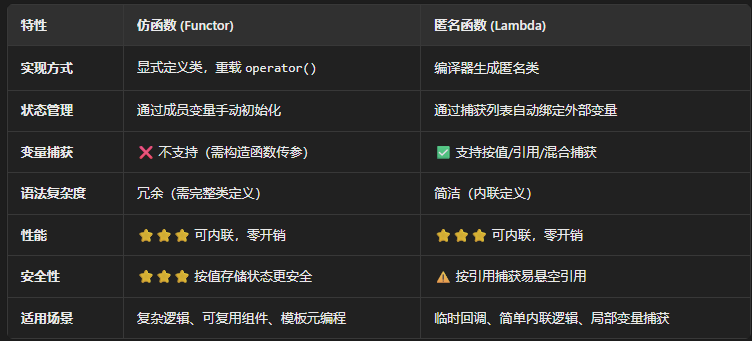
客观地二者除了在用途上类型其实也没有什么相似点了,我们使用仿函数之前要显示地定义重载了()的相关类或者结构体,且仿函数不支持闭包去捕获变量,当然,仿函数也不是一无是处,仿函数的参数是值传递的,更安全而匿名函数捕获的是变量的引用有出现悬空引用的可能。
auto和decltype:二者都和类型推导有关
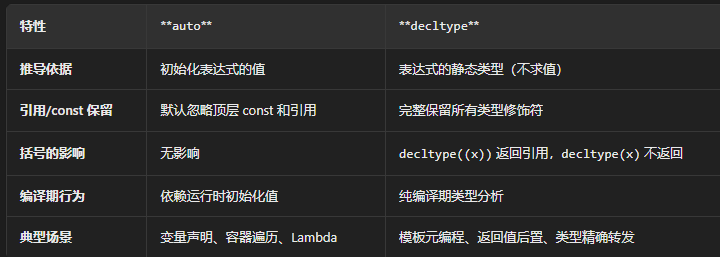
可以看到auto是依赖于表达式的值来推导类型而decltype则是在编译期就根据表达式判断类型,auto只保留数据类型而不保留其他类型的修饰符而decltype是完整保留的,decltype在编译期时执行而auto运行时推导。
malloc的底层原理:

int* a = (int*)malloc(10 * sizeof(int)); // 分配 40 字节未初始化内存
int* b = (int*)calloc(10, sizeof(int)); // 分配 40 字节并初始化为 0
int* c = (int*)realloc(a, 20 * sizeof(int)); // 将 a 的内存扩容至 80 字节 [3,4,9](@ref) 简单地说就是,malloc通过在堆中实现内存池技术来分配内存。malloc最开始会向操作系统申请一个大的内存块之后分成大小不一的小块,这些小块通过链表的形式连接,然后有一个显式的链表记录空闲的内存块。当调用malloc申请内存时先从已有的内存块中找寻匹配,如果没有的话会通过brk或者mmap重新从操作系统那里申请新的内存,brk申请小内存且brk申请的内存加入到我们的内存池,而mmap申请的就是大内存了,且新申请的内存独立于堆之外。
malloc,realloc和calloc:
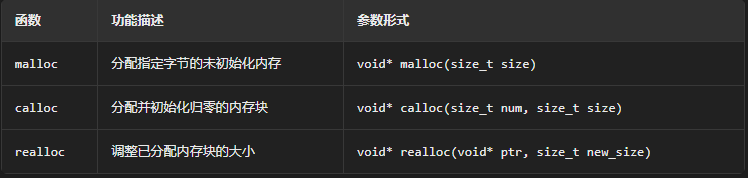
三个都是负责分配动态内存的,有一些小小的功能差异:
int* a = (int*)malloc(10 * sizeof(int)); // 分配 40 字节未初始化内存
int* b = (int*)calloc(10, sizeof(int)); // 分配 40 字节并初始化为 0
int* c = (int*)realloc(a, 20 * sizeof(int)); // 将 a 的内存扩容至 80 字节 [3,4,9](@ref) 有哪些new方法?

看起来似乎有些绕,plain new就是我们平时用的new,nothrow new就是new失败后不再抛异常而是返回nullptr,placement new也称为定位牛,是在给定的地址上执行构造函数,new[]则是在堆上分配数组对象。
操作系统虚拟内存的分区:
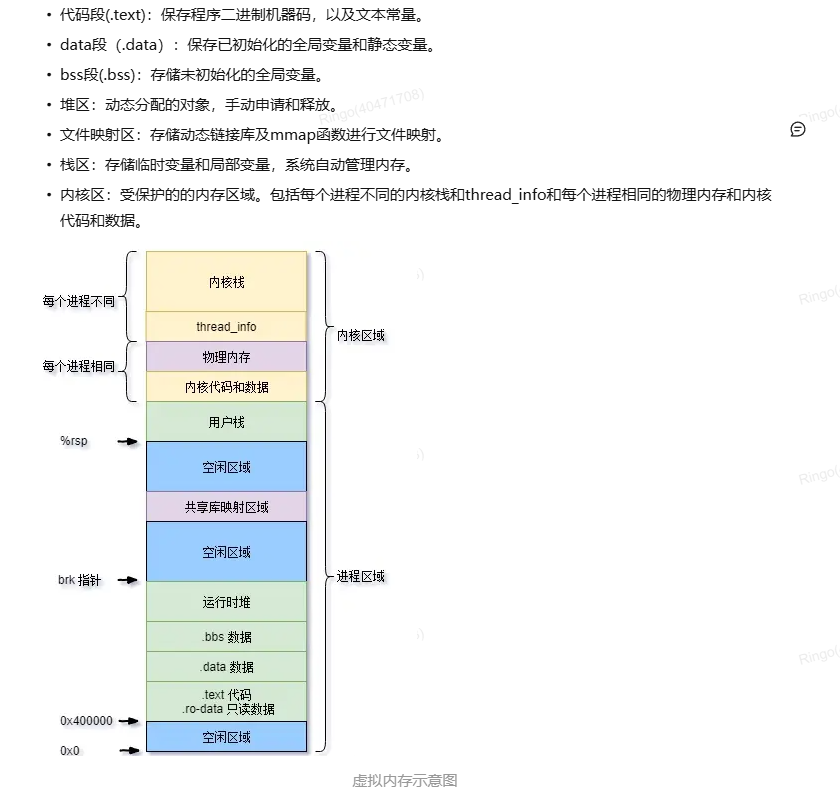
可以看到在虚拟内存中我们是通过栈基指针和brk指针来从共享库映射区域扩张栈和堆的大小。
如何理解段错误?
段错误的本质是内存访问越界,也就是访问了不允许访问的区域,又或者是栈溢出或者是new一次之后delete多次。栈溢出的常见诱因包括无限递归,局部变量过大或者是栈的缓冲区溢出。
动态库和静态库?
静态库的本质是一系列目标文件(.o 或 .obj)的归档集合(如 Linux 的 .a 或 Windows 的 .lib),它在编译链接阶段被链接器完整地提取并复制到最终的可执行文件中,成为其不可分割的一部分。这意味着程序运行时不再依赖外部文件,所有库代码已内嵌在可执行文件内,因此启动速度快、独立性高,但代价是可执行文件体积较大,且库的更新必须重新编译整个程序。
动态库(如 Linux 的 .so 或 Windows 的 .dll)则采用完全不同的机制:编译链接阶段仅记录库中的符号引用(如函数名)和库文件路径,不复制实际代码到可执行文件中。程序运行时,操作系统的动态加载器(如 ld-linux.so)根据记录的元数据查找并加载动态库到内存,再解析符号地址完成链接。这种设计允许多个程序共享内存中的同一份库代码,显著节省磁盘和内存空间,且库的更新只需替换文件(保持接口兼容),无需重新编译主程序;但代价是程序启动稍慢(需加载解析),且严重依赖运行时环境——若库文件缺失、路径错误或版本不兼容,程序将无法运行。
如何实现一个在main函数之前执行的函数?
通过 __attribute__((constructor))和 __attribute__((destructor))来显示利用编译器属性控制函数的执行顺序。
计算机网络
Socket中的客户端和服务器如何建立连接?
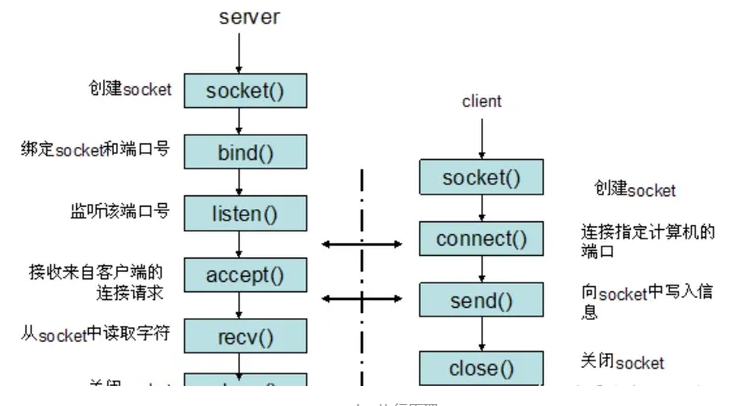
总结来说就是:服务器创建socket,绑定端口和IP让客户端可以去定位服务器,然后服务器进入监听状态。客户端创建socket后主动发起连接请求,经过TCP三次握手后服务器返回accept,然后客户端通过send往socket里面写信息后传输,服务器通过recv接收后处理之后重新发送send,而客户端recv,依次循环。然后断开时通过四次挥手断开即可
![]()
![]()
上述的内容是基于TCP来说的,对于UDP来说:
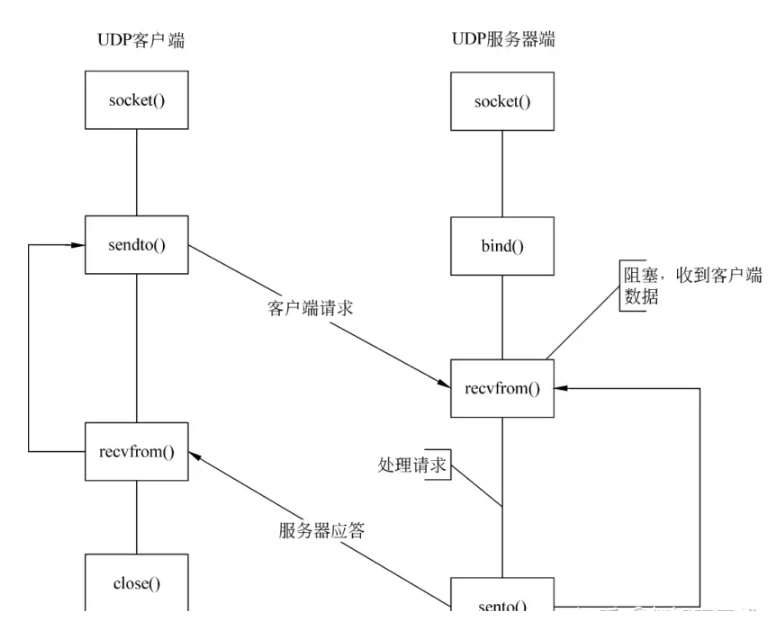
UDP的服务器在绑定对应的端口和IP之后没有监听阶段,客户端sendto之后服务器使用recvfrom之后处理并通过sendto返回,客户端也用recvfrom接收,完成所有的逻辑之后执行close。
TCP和UDP的区别?
虽然是老生常谈的问题,但是往往说不完全。
首先TCP是面向连接的而UDP不是,TCP具有可靠性而UDP没有,TCP是有序的(发送时可能乱序发送但是在接受方会重组)而UDP是无序的,然后TCP面向字节流传输而UDP面向报文传输(或者说TCP没有保留消息边界而UDP保留),TCP的报文体积更大而UDP报文体积更小。总的来说对延迟性要求高的场景如通话使用UDP,对可靠性要求高的使用TCP如邮件。
三次握手:
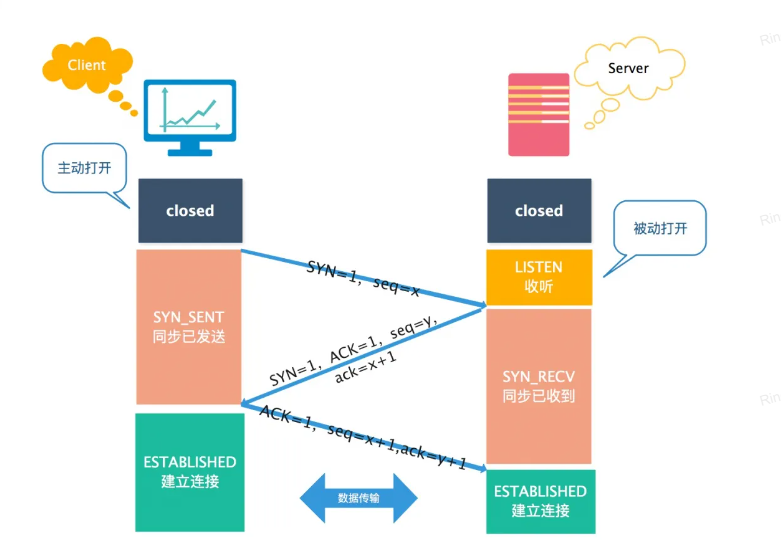
这个我就不多嘴了,太老生常谈了。
SYN洪泛攻击是啥?
简单地说就是,当我们的TCP三次握手中,我们的服务器接收到客户端的SYN报文并发送ACK报文后会进入一个半连接的等待客户端响应状态,会分配内存存储连接的控制块。如果短时间内大量的随机IP同时对服务器发起连接请求却不发送第三次ACK报文就会导致服务器的内存为了维护这些半连接影响正常的运作,解决方法是SYN Cookie:

SYN Cookie的意思就是我们第一次收到客户端的报文后不立即分配内存而是生成一个加密值嵌入返回的SYN+ACK包中,然后只有等客户端第三次返回的ACK包中有相应的加密值才直接建立连接。
为什么四次挥手的最后客户端要等待2MSL(报文存活最大时间)?
因为假如客户端的最后一个ACK报文没有正常传输到服务器,服务器在超时后会重新发送一个FIN报文给到客户端,此时如果客户端已经关闭那么服务器无法正常关闭连接。2MSL考虑的是客户端的ACK报文超时加上服务器重新发送的FIN报文的时长。
TIME_WAIT状态过多会怎样?
首先要明确的是TIME_WAIT状态是主动发起断开连接请求的一方等待回应的状态(通常是客户端),如果一个客户端同时与太多服务器同时断开连接就会出现大量的TIME_WAIT状态,那么首先第一个问题是端口不够用——一般客户端的端口数都是有限的,每一个与服务器的连接都占用一个端口;第二个问题是每一个连接都占用一定的内存(如存储连接信息的TCB),这样也会导致内存占用比较大。
TCP如何保证可靠性?
也是一个老生常谈但是经常回答不全的问题,大体上有校验和,序号,两种重传,拥塞避免,流量控制这些手段帮助我们实现可靠性。
HTTP常用的请求方法?
比较常见的有get,post,put,patch,head,delete等。
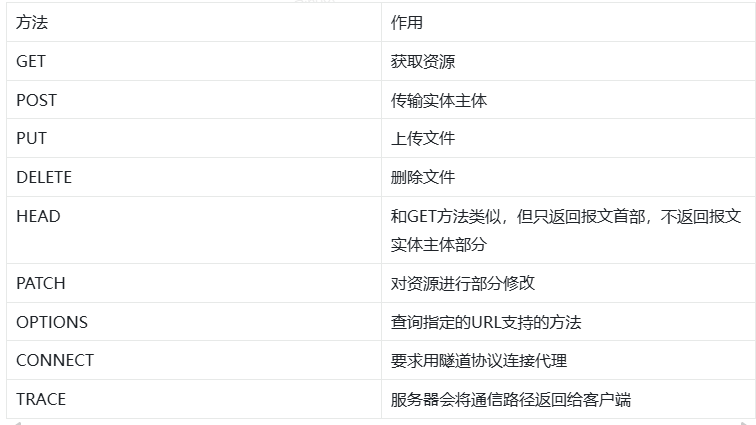
这里得提一嘴HTTP报文的格式:


比如我们的GET就是把请求的资源明文写在请求行里的,而POST则会把上传的内容放在请求主体里。
关于HTTP和HTTPS:
主要的差异就是在这个TLS协议上。(当然其实默认的端口也不相同)
要我说计算机网络最麻烦也是最复杂的两个问题,那莫过于这个TLS协议以及从输入网址到显示网页经历了哪些过程。
操作系统
进程和线程的切换的差异?
我们都知道进程的切换主要涉及到三个部分,分别是保存当前上下文,切换页表,以及更新上下文,而线程的切换只有两个部分,也就是保存当前线程上下文和更新线程上下文,也就是少了一个切换页表的过程。这底层的逻辑是切换进程时要切换不同的地址(每个进程都自己独立的内存空间)而不同线程共享一个进程的空间,切换现场不涉及到地址空间的变化。
进程和线程的同步方式?有何不同?
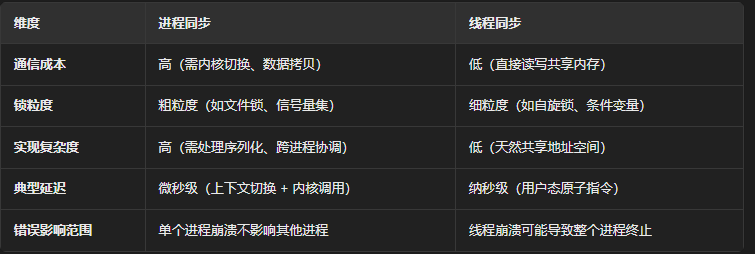
线程的分级?
可以分为用户级线程和内核级线程,内核级线程的一切操作包括创建,调度,切换,销毁都由内核执行,程序员无法插手,内核级线程的访问权限最高,可以访问和使用一切设备;用户级线程需要程序员在用户态下手动操作,操作系统的内核是无法感知用户级线程的(根本原因是内核能调度的最小单位是进程,进程中的用户级线程内核无法感知)。
分页的概念?
关于分页,我们首先是通过在物理内存中进行内存分块,然后在虚拟内存中也进行一个内存分块,我们把虚拟内存的内存块和物理内存的内存块进行一个映射关系的连接,记录在页表上。

什么是IO多路复用?
I/O 多路复用是一种高效的 I/O 处理机制,允许单个线程/进程同时监听多个文件描述符(如 Socket、管道等),并在其中任意一个可读/可写时通知程序进行处理,从而避免阻塞等待单个 I/O 操作。
常见的IO多路复用:
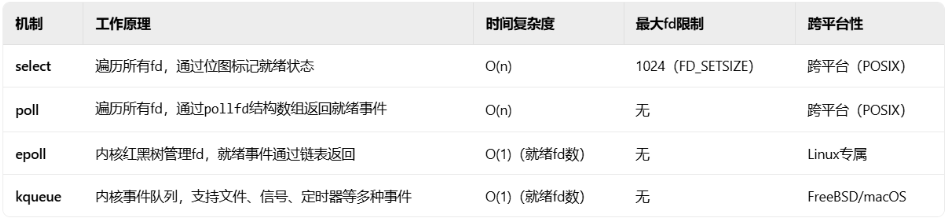
select,poll,epoll都是实现轮询的手段,但是区别在于select是一个有最大fd(File Descriptor,操作系统对打开的资源(如文件、套接字、管道等)的抽象引用,表现为一个非负整数)限制的无差别轮询而poll是一个无最大fd限制的轮询,二者的时间复杂度都为ON,epoll通过维护红黑树管理fd,这样查询的复杂度为O1。
什么是软链接/硬链接?软链接(符号链接)和硬链接是Linux/Unix系统中两种文件链接机制。
- 硬链接:直接指向文件的inode(索引节点),本质是同一文件的多个别名。它与原文件共享存储空间,不能跨文件系统,删除原文件后仍可通过硬链接访问数据(仅当所有硬链接被删除时文件才真正释放)。
- 软链接:独立文件,存储目标文件的路径而非inode,类似快捷方式。它可跨文件系统、链接目录,但若目标文件被移动或删除,链接会失效(成为“死链”),且占用少量空间存储路径信息
哎哟我,过八股确实太累了,一天过这么多吧先,明天再补充下Unity和UE,然后直接进入项目吧。