GPU 优化-用 tensor core实现5G Massive MIMO 64x64
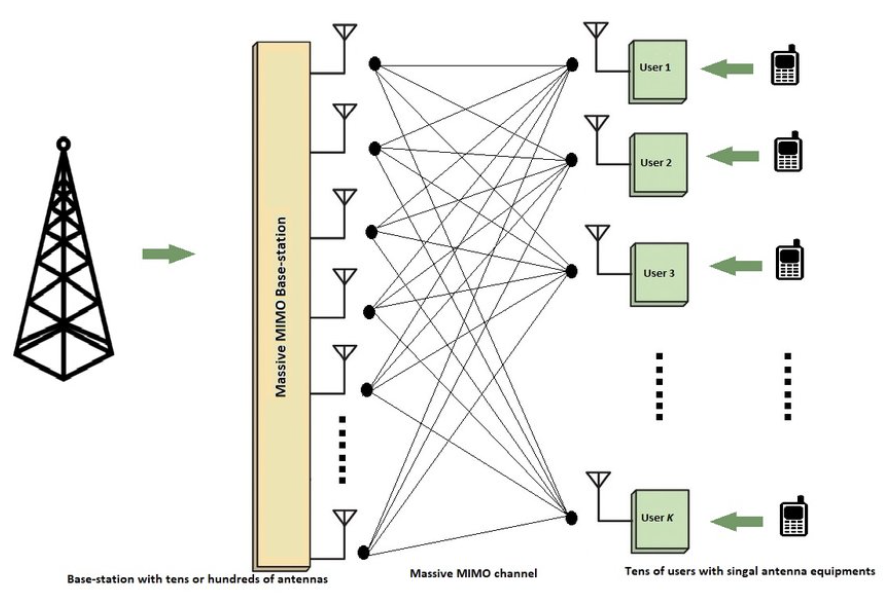
这篇文章会介绍如何在ARM和GPU做一个典型的64(接收天线)x 64 (发射天线)的均衡器(equalization). GPU方面,会比较不用tensor core和用tensor core的优化效果。
接收端 Y (64维向量), 信道估计系数H(64 x 64), 发送端X(64 维向量),无线噪音N(64维向量)。所以Y = H * X + N。现在,我们在接收端接收到了Y, 同时H和N通过参考信号算出来了, 那么我们要恢复发送端的信息。对H矩阵求逆得到G之后,最终我们会有如下的公式: X = G * Y + N0. 我们把这个乘加叫做均衡。Y的dimension是64 x NumOfElements (通常大小位: 273 x 12 x 14)。G的dimension 是64 x 64, 但是每过1/4/8/12/24元素,矩阵会变化一次。我们考虑每连续4个元素共用一个64 x 64的G矩阵吧。接下来,我们慢慢的去优化这个计算。