推动本地流智能:基于 Apache Kafka 与 Flink 的实时机器学习实践
推动本地流智能:基于 Apache Kafka 与 Flink 的实时机器学习实践

在数字化转型加速的今天,企业对实时数据洞察的需求愈发迫切。然而,许多中小企业在采用云服务时面临成本失控、数据主权模糊等挑战。本地部署的流处理架构成为破局关键——Apache Kafka 与 Apache Flink 的组合,凭借低延迟、高可靠的特性,为实时机器学习(ML)提供了理想的技术底座。本文将以制造业预测性维护为例,详解如何在本地环境构建端到端的实时 ML 管道,实现从数据摄取到智能决策的全流程自动化。
一、技术选型:为何选择 Kafka + Flink 组合?
在实时流处理领域,Kafka 与 Flink 的协同优势显著,成为本地部署的首选方案:
1. Apache Kafka:流数据的“高速公路”
Kafka 作为分布式消息队列,核心优势在于:
- 高吞吐量:支持每秒百万级消息传输,满足工业传感器等高并发场景;
- 容错设计:通过分区复制机制确保数据不丢失,最新的 KRaft 协议取代 ZooKeeper,简化架构并消除单点故障;
- 持久化存储:消息可持久化至磁盘,支持历史数据重放与回溯分析。
2. Apache Flink:实时计算的“发动机”
Flink 作为流处理引擎,完美适配 Kafka 的数据特性:
- 低延迟与高吞吐:基于内存计算模型,同时支持毫秒级响应与大规模数据处理;
- Exactly-Once 语义:通过 Checkpoint 机制确保数据精确处理,避免重复计算或丢失;
- 统一批流处理:同一引擎支持实时流处理与批处理,简化 ML 特征工程流程。
两者结合形成“数据摄取-处理-分析”的闭环,为本地实时 ML 提供稳定、高效的基础设施。
二、架构设计:制造业预测性维护的端到端流程
以制造工厂的设备预测性维护为例,完整架构涵盖数据从传感器采集到故障预警的全链路,架构流程图如下:
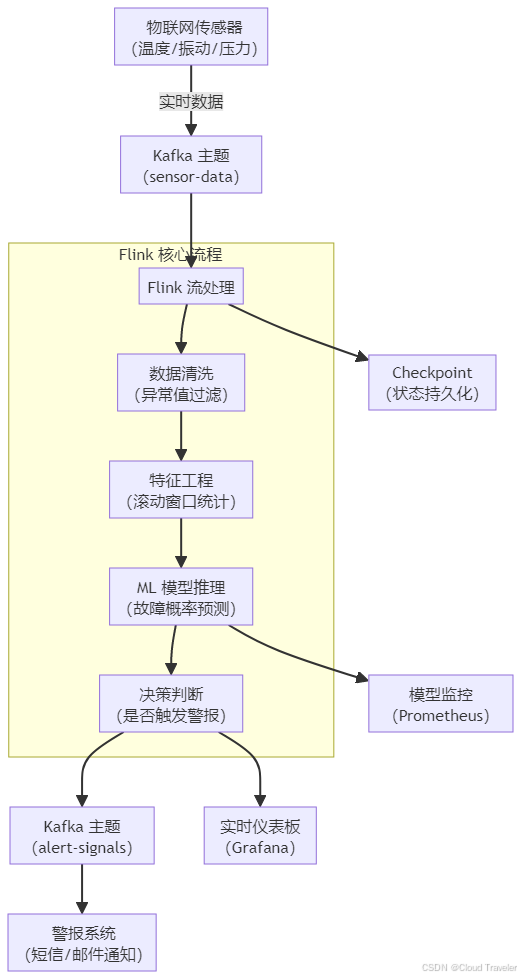
核心模块解析:
- 数据摄取层:工厂设备的物联网传感器实时采集温度、振动等数据,以 JSON 格式发送至 Kafka 主题
sensor-data; - 处理与推理层:Flink 消费 Kafka 数据,完成清洗、特征工程后,调用预训练的 ML 模型预测设备故障概率;
- 输出与监控层:推理结果一方面触发警报(如故障概率 > 阈值),另一方面通过仪表板可视化,同时监控模型性能指标。
三、实战部署:本地环境搭建与代码实现
1. 环境初始化:Kafka 与 Flink 本地集群搭建
(1)Kafka 集群配置(基于 KRaft 协议)
# 1. 下载并解压 Kafka 3.8
tar -xzf kafka_2.13-3.8.0.tgz && cd kafka_2.13-3.8.0# 2. 初始化 KRaft 元数据存储
./bin/kafka-storage.sh format -t $(./bin/kafka-storage.sh random-uuid) -c config/kraft/server.properties# 3. 启动 Kafka 服务(单节点演示,生产需多节点)
./bin/kafka-server-start.sh config/kraft/server.properties# 4. 创建传感器数据主题(3分区,2副本确保容错)
./bin/kafka-topics.sh --create --topic sensor-data --partitions 3 --replication-factor 2 --bootstrap-server localhost:9092
(2)Flink 集群配置
# 1. 下载并解压 Flink 1.18.1
tar -xzf flink-1.18.1-bin-scala_2.12.tgz && cd flink-1.18.1# 2. 配置主节点(修改 conf/flink-conf.yaml)
jobmanager.rpc.address: localhost# 3. 启动 Flink 集群(1主2从)
./bin/start-cluster.sh
2. 数据管道实现:从 Kafka 到 Flink 处理
使用 Flink DataStream API 消费 Kafka 数据,进行清洗与特征工程:
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import java.util.Properties;public class SensorDataPipeline {public static void main(String[] args) throws Exception {final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 启用 Checkpoint 确保 Exactly-Once 语义(每10秒一次)env.enableCheckpointing(10000);// 配置 Kafka 消费者Properties props = new Properties();props.setProperty("bootstrap.servers", "localhost:9092");props.setProperty("group.id", "sensor-consumer-group");// 从 Kafka 消费传感器数据DataStream<String> sensorData = env.addSource(new FlinkKafkaConsumer<>("sensor-data", new SimpleStringSchema(), props));// 1. 数据清洗:过滤异常值(温度>100℃或<0℃视为异常)DataStream<SensorReading> cleanedData = sensorData.map(json -> parseJsonToSensorReading(json)) // 自定义JSON解析方法.filter(reading -> reading.getTemperature() >= 0 && reading.getTemperature() <= 100);// 2. 特征工程:计算5分钟滚动窗口内的温度标准差(反映设备稳定性)DataStream<SensorFeatures> features = cleanedData.keyBy(SensorReading::getDeviceId).window(TumblingProcessingTimeWindows.of(Time.minutes(5))).aggregate(new TemperatureStatsAggregator()); // 自定义聚合器计算标准差// 后续:调用ML模型推理(见下一节)features.print();env.execute("Sensor Data Processing Pipeline");}
}
3. ML 模型集成:实时推理与决策
Flink 支持两种模型集成方式,此处以嵌入式推理为例(适合轻量级模型):
// 加载预训练的XGBoost模型(序列化文件)
private static XGBoostModel loadModel() {try (InputStream is = new FileInputStream("models/fault_prediction_model.bin")) {return XGBoostModel.load(is); // 自定义模型加载逻辑} catch (IOException e) {throw new RuntimeException("Model load failed", e);}
}// 在Flink流中进行实时推理
DataStream<Alert> predictionStream = features.map(features -> {// 特征转换为模型输入向量float[] input = new float[]{features.getTempStd(), features.getVibration(), features.getPressure()};// 模型预测故障概率float faultProbability = model.predict(input)[0];// 决策逻辑:概率>0.8则触发警报if (faultProbability > 0.8) {return new Alert(features.getDeviceId(), faultProbability, "High risk of failure");} else {return new Alert(features.getDeviceId(), faultProbability, "Normal");}});// 将警报写入Kafka主题,供下游系统消费
predictionStream.map(alert -> alert.toJson()) // 转换为JSON字符串.addSink(new FlinkKafkaProducer<>("localhost:9092", "alert-signals", new SimpleStringSchema()));
四、监控与优化:确保系统可靠运行
1. 模型与系统监控
采用 Prometheus + Grafana 构建监控体系:
- 系统指标:Flink 作业延迟、Kafka 分区积压量、节点资源使用率;
- 模型指标:预测准确率、假阳性率、特征分布漂移程度。
示例:在 Flink 中暴露模型指标:
// 注册Prometheus指标
private static final Counter falseAlerts = Metrics.counter("false_alerts_total");// 模型推理后更新指标
if (alert.isHighRisk() && laterVerifiedAsFalse(alert)) {falseAlerts.inc();
}
2. 性能优化建议
- Kafka 分区策略:分区数与 Flink 并行度保持一致(如 3 分区对应 3 个并行度),避免数据倾斜;
- Flink 状态管理:使用 RocksDB 作为状态后端,优化大状态场景的内存占用;
- 模型更新机制:通过 Flink 的广播流(BroadcastStream)实现模型热更新,无需重启作业。
五、挑战与未来展望
本地流智能部署仍面临挑战:模型在边缘设备的轻量化部署、大规模场景下的低延迟推理、跨节点状态一致性等。未来,随着 Flink ML 库的完善和 Kafka 流处理能力的增强,本地实时 ML 管道将更易用、更高效。
对于追求数据主权与成本可控的企业,Kafka + Flink 架构提供了一条切实可行的实时智能落地路径。通过本文的实践方案,企业可快速构建预测性维护、实时质检等场景的流智能应用,释放数据的即时价值。