线程-线程池篇(二)
目录
一. 线程池
1.什么是线程池?
2.线程池常用类和接口
3.线程池常见方法
4.执行线程任务
5.关闭线程池
6.线程池的执行流程重要
7.线程池的配置参数重要
8.线程池的配置参数重要
9.线程池分类
9.1FixedThreadPool线程池
9.2CachedThreadPool线程池
9.3ScheduledThreadPool线程池
10.线程池的状态
11.线程池分类总结重要
11.1FixedThreadPool
11.2CachedThreadPool
11.3SingleThreadExecutor
11.4ScheduledThreadPool
线程池使用注意事项
二.线程池核心源码阅读
1.线程池相关的接口和实现类
2.工作线程Worker类
3.核心方法:execute()方法
4.核心方法:addWorker()方法
三.synchronized实现原理
1.synchronized底层实现
2.监视器(monitor)
3.锁升级
4.偏向锁
5.轻量级锁
6.轻量级锁的加锁过程
7.轻量级锁的解锁过程
一. 线程池
1.什么是线程池?
线程池内部维护了若干个线程,没有任务的时候,这些线程都处于等待空闲状态。如果有新的线程任务,就分配一个空闲线程执行。如果所有线程都处于忙碌状态,线程池会创建一个新线程进行处理或者放入队列(工作队列)中等待.
┌─────┐ execute ┌──────────────────┐
│Task1│─────────>│ThreadPool │
├─────┤ │┌───────┐┌───────┐│
│Task2│ ││Thread1││Thread2││
├─────┤ │└───────┘└───────┘│
│Task3│ │┌───────┐┌───────┐│
├─────┤ ││Thread3││Thread4││
│Task4│ │└───────┘└───────┘│
├─────┤ └──────────────────┘
│Task5│
├─────┤
│Task6│
└─────┘...2.线程池常用类和接口
在Java标准库提供了如下几个类或接口,来操作并使用线程池:
ExecutorService接口:进行线程池的操作访问;Executors类:创建线程池的工具类;ThreadPoolExecutor及其子类:封装线程池的核心参数和运行机制;
线程池的基本使用方式:
// 线程池基本使用方式
// 创建一个ThreadPoolExecutor类型的对象,代表固定大小的线程池
ExecutorService executor = Executors.newFixedThreadPool(3); // 该线程池拥有3个线程// 执行线程任务
executor.execute(task1);
executor.execute(task2);
executor.execute(task3);
executor.execute(task4);
executor.execute(task5);// 使用结束后,使用shutdown关闭线程池
executor.shutdown();3.线程池常见方法
- 执行无返回值的线程任务:
void execute(Runnable command); - 提交有返回值的线程任务:
Future<T> submit(Callable<T> task); - 关闭线程池:
void shutdown();或shutdownNow(); - 等待线程池关闭:
boolean awaitTermination(long timeout, TimeUnit unit);
4.执行线程任务
execute()只能提交Runnable类型的任务,没有返回值,而submit()既能提交Runnable类型任务也能提交Callable类型任务,可以返回Future类型结果,用于获取线程任务执行结果。
execute()方法提交的任务异常是直接抛出的,而submit()方法是捕获异常,当调用Future的get()方法获取返回值时,才会抛出异常。
// 计算1-100w的之间所有数字的累加和,每10w个数字交给1个线程处理
// 创建一个固定大小的线程池:
ExecutorService executorService = Executors.newFixedThreadPool(4);// 创建集合,用于保存Future执行结果
List<Future<Integer>> futureList = new ArrayList<Future<Integer>>();// 每10w个数字,封装成一个Callable线程任务,并提交给线程池
for (int i = 0; i <= 900000; i += 100000) {Future<Integer> result = executorService.submit(new CalcTask(i+1, i + 100000));futureList.add(result);
}// 处理线程任务执行结果
try {int result = 0;for (Future<Integer> f : futureList) {result += f.get();}System.out.println("最终计算结果" + result);
} catch (InterruptedException e) {e.printStackTrace();
} catch (ExecutionException e) {e.printStackTrace();
}// 关闭线程池
// 省略.....5.关闭线程池
线程池在程序结束的时候要关闭。使用shutdown()方法关闭线程池的时候,它会等待正在执行的任务先完成,然后再关闭。shutdownNow()会立刻停止正在执行的任务;
当使用awaitTermination()方法时,主线程会处于一种等待的状态,按照指定的timeout检查线程池。
第一个参数指定的是时间,第二个参数指定的是时间单位(当前是秒)。返回值类型为boolean型。
-
- 如果等待的时间超过指定的时间,但是线程池中的线程运行完毕,
awaitTermination()返回true。 - 如果等待的时间超过指定的时间,但是线程池中的线程未运行完毕,
awaitTermination()返回false。 - 如果等待时间没有超过指定时间,则继续等待。
- 如果等待的时间超过指定的时间,但是线程池中的线程运行完毕,
该方法经常与shutdown()方法配合使用,用于检测线程池中的任务是否已经执行完毕:
// 线程池已提交或执行若干个任务// 关闭线程池:必须等待任务执行结束后,线程池才会关闭
executorService.shutdown();// 每隔1秒钟,检查一次线程池的任务执行状态
while(!executorService.awaitTermination(1, TimeUnit.SECONDS)) {System.out.println("还没有关闭!");
}System.out.println("已关闭!");6.线程池的执行流程重要
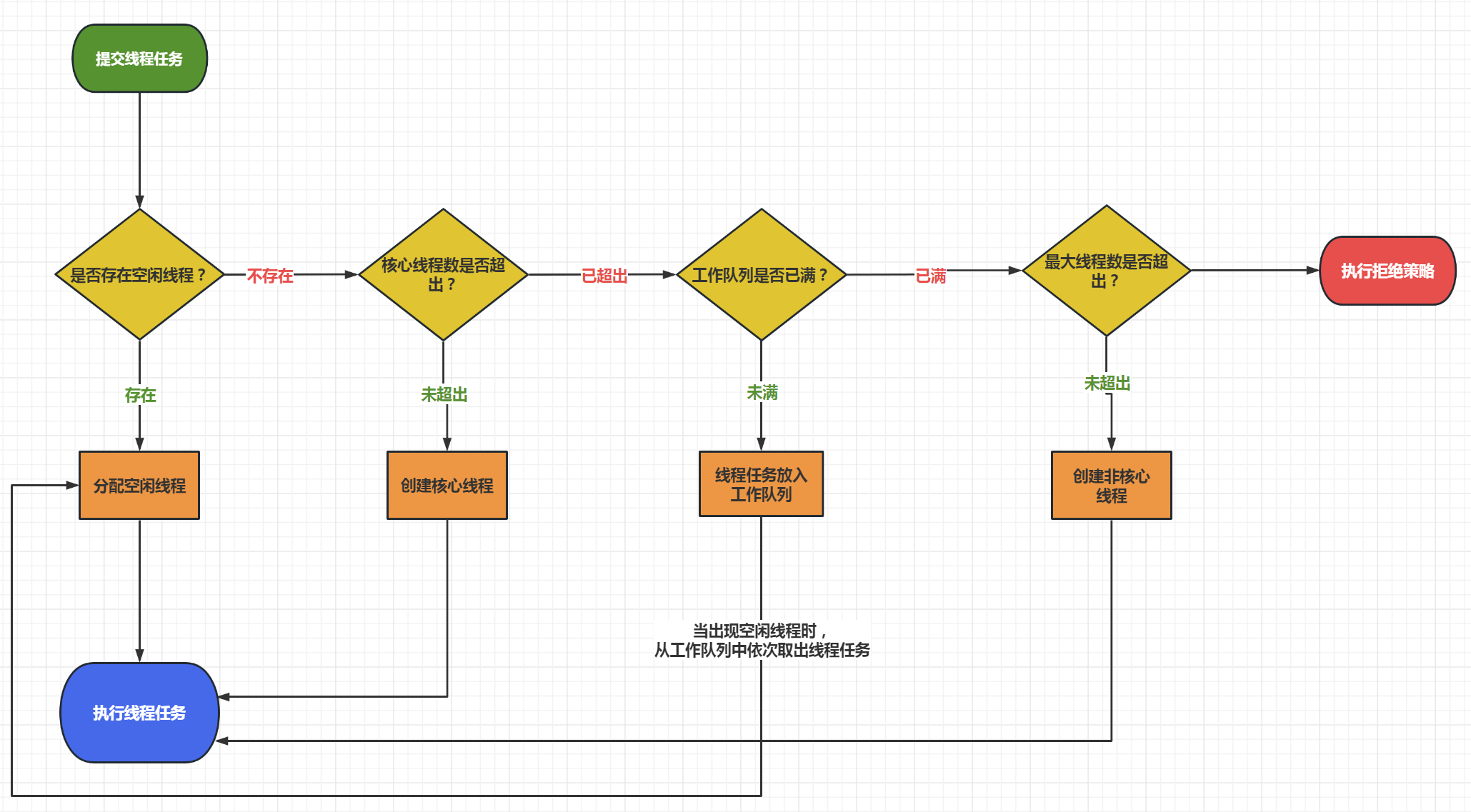
- 提交一个新线程任务,线程池会在线程池中分配一个空闲线程,用于执行线程任务;
- 2. 如果线程池中不存在空闲线程,则线程池会判断当前“存活的线程数”是否小于核心线程数
corePoolSize。
-
- 如果小于核心线程数
corePoolSize,线程池会创建一个新线程(核心线程)去处理新线程任务; - 如果大于核心线程数
corePoolSize,线程池会检查工作队列;
- 如果小于核心线程数
-
-
- 如果工作队列未满,则将该线程任务放入工作队列进行等待。线程池中如果出现空闲线程,将从工作队列中按照FIFO的规则取出1个线程任务并分配执行;
- 如果工作队列已满,则判断线程数是否达到最大线程数
maximumPoolSize;
-
-
-
-
- 如果当前“存活线程数”没有达到最大线程数
maximumPoolSize,则创建一个新线程(非核心线程)执行新线程任务; - 如果当前“存活线程数”已经达到最大线程数
maximumPoolSize,直接采用拒绝策略处理新线程任务;
- 如果当前“存活线程数”没有达到最大线程数
-
-
综上所述,执行顺序为:核心线程、工作队列、非核心线程、拒绝策略。
7.线程池的配置参数重要
- 提交一个新线程任务,线程池会在线程池中分配一个空闲线程,用于执行线程任务;
- 2. 如果线程池中不存在空闲线程,则线程池会判断当前“存活的线程数”是否小于核心线程数
corePoolSize。
-
- 如果小于核心线程数
corePoolSize,线程池会创建一个新线程(核心线程)去处理新线程任务; - 如果大于核心线程数
corePoolSize,线程池会检查工作队列;
- 如果小于核心线程数
-
-
- 如果工作队列未满,则将该线程任务放入工作队列进行等待。线程池中如果出现空闲线程,将从工作队列中按照FIFO的规则取出1个线程任务并分配执行;
- 如果工作队列已满,则判断线程数是否达到最大线程数
maximumPoolSize;
-
-
-
-
- 如果当前“存活线程数”没有达到最大线程数
maximumPoolSize,则创建一个新线程(非核心线程)执行新线程任务; - 如果当前“存活线程数”已经达到最大线程数
maximumPoolSize,直接采用拒绝策略处理新线程任务;
- 如果当前“存活线程数”没有达到最大线程数
-
-
综上所述,执行顺序为:核心线程、工作队列、非核心线程、拒绝策略。
8.线程池的配置参数重要
corePoolSize线程池核心线程数:也可以理解为线程池维护的最小线程数量,核心线程创建后不会被回收。大于核心线程数的线程,在空闲时间超过keepAliveTime后会被回收;
-
- 在创建了线程池后,默认情况下,线程池中并没有任何线程,当调用
execute()方法添加一个任务时,如果正在运行的线程数量小于corePoolSize,则马上创建新线程并运行这个任务。 - IO密集计算:由于
I/O设备的速度相对于CPU来说都很慢,所以大部分情况下,I/O操作执行的时间相对于CPU计算来说都非常长,这种场景我们一般都称为I/O密集型计算。最佳线程数 =CPU 核数 * [ 1 +(I/O 耗时 / CPU 耗时)]。 - CPU密集型:
CPU密集型计算大部分场景下都是纯CPU计算,多线程主要目的是提升CPU利用率,最佳线程数 =“CPU 核心数 +1”。这样的话,当线程因为偶尔的内存页失效或其他原因导致阻塞时,这个额外的线程可以临时替补,从而保证CPU的利用率。
- 在创建了线程池后,默认情况下,线程池中并没有任何线程,当调用
maximumPoolSize线程池最大线程数:线程池允许创建的最大线程数量;(包含核心线程池数量)keepAliveTime非核心线程线程存活时间:当一个可被回收的线程的空闲时间大于keepAliveTime,就会被回收。
-
- 当线程池中的线程数大于
corePoolSize时,如果一个线程空闲的时间达到keepAliveTime,则会被回收,直到线程池中的线程数不超过corePoolSize。 - 如果设置
allowCoreThreadTimeOut = true,在线程池中的线程数不大于corePoolSize时,keepAliveTime参数也会起作用,直到线程池中的线程数为0;
- 当线程池中的线程数大于
TimeUnit时间单位:参数keepAliveTime的时间单位;BlockingQueue阻塞工作队列:用来存储等待执行的任务;ThreadFactory线程工厂 : 用于创建线程,以及自定义线程名称,需要实现ThreadFactory接口;RejectedExecutionHandler拒绝策略:当线程池线程内的线程耗尽,并且工作队列达到已满时,新提交的任务,将使用拒绝策略进行处理;
-
ThreadPoolExecutor.AbortPolicy:默认策略,丢弃任务并抛出RejectedExecutionException异常;ThreadPoolExecutor.DiscardPolicy:丢弃任务,但是不抛出异常;ThreadPoolExecutor.DiscardOldestPolicy:丢弃工作队列中的队头任务(即最旧的任务,也就是最早进入队列的任务)后,继续将当前任务提交给线程池;ThreadPoolExecutor.CallerRunsPolicy:由原调用线程处理该任务 (谁调用,谁处理)
9.线程池分类
Java标准库提供的几种常用线程池,创建这些线程池的方法都被封装到Executors工具类中。
- FixedThreadPool:线程数固定的线程池,使用
Executors.newFixedThreadPool()创建; - CachedThreadPool:线程数根据任务动态调整的线程池,使用
Executors.newCachedThreadPool()创建; - SingleThreadExecutor:仅提供一个单线程的线程池,使用
Executors.newSingleThreadExecutor()创建; - ScheduledThreadPool:能实现定时、周期性任务的线程池,使用
Executors.newScheduledThreadPool()创建;
9.1FixedThreadPool线程池
线程数固定的线程池
public class Main {public static void main(String[] args) {// 创建一个固定大小的线程池:ExecutorService executorService = Executors.newFixedThreadPool(4);for (int i = 0; i < 6; i++) {executorService.execute(new Task("线程"+i));}// 关闭线程池:executorService.shutdown();}
}class Task implements Runnable {private String taskName;public Task(String taskName) {this.taskName = taskName;}@Overridepublic void run() {System.out.println("启动线程 ===> " + this.taskName);try {Thread.sleep(1000);} catch (InterruptedException e) {}System.out.println("结束线程 <= " + this.taskName);}
}观察执行结果,一次性放入6个任务,由于线程池只有固定的4个线程,因此,前4个任务会同时执行,等到有线程空闲后,才会执行后面的两个任务。
9.2CachedThreadPool线程池
线程数根据任务动态调整的线程池
ExecutorService executorService = Executors.newCachedThreadPool();
- 观察执行结果,由于这个线程池的实现会根据任务数量动态调整线程池的大小,所以
6个任务可一次性全部同时执行。
9.3ScheduledThreadPool线程池
能实现定时、周期性任务的线程池
- 例如:每秒刷新证券价格。这种任务本身固定,需要反复执行的,可以使用
ScheduledThreadPool; - 放入
ScheduledThreadPool的任务可以定期反复执行;
创建ScheduledThreadPool定时任务线程池
ScheduledExecutorService executorService = Executors.newScheduledThreadPool(3);延迟3秒钟后执行,任务只执行1次
executorService.schedule(new Task("线程A"), 3, TimeUnit.SECONDS);延迟2秒钟后,每隔3秒钟执行任务1次
// 方式1
executorService.scheduleAtFixedRate(new Task("线程A"), 2,3, TimeUnit.SECONDS);// 方式2
executorService.scheduleWithFixedDelay(new Task("线程A"), 2,3, TimeUnit.SECONDS);FixedRate和FixedDelay的区别:
FixedRate是指任务总是以固定时间间隔触发,不管任务执行多长时间;FixedDelay是指,上一次任务执行完毕后,等待固定的时间间隔,再执行下一次任务;
10.线程池的状态
线程池的状态分为:RUNNING , SHUTDOWN , STOP , TIDYING , TERMINATED
-
- RUNNING:运行状态,线程池被一旦被创建,就处于
RUNNING状态,并且线程池中的任务数为0。该状态的线程池会接收新任务,并处理工作队列中的任务。
- RUNNING:运行状态,线程池被一旦被创建,就处于
-
-
- 调用线程池的
shutdown()方法,可以切换到SHUTDOWN关闭状态; - 调用线程池的
shutdownNow()方法,可以切换到STOP停止状态;
- 调用线程池的
-
-
- SHUTDOWN :关闭状态,该状态的线程池不会接收新任务,但会处理工作队列中的任务;
-
-
- 当工作队列为空时,并且线程池中执行的任务也为空时,线程池进入TIDYING状态;
-
-
- STOP:停止状态,该状态的线程不会接收新任务,也不会处理阻塞队列中的任务,而且会中断正在运行 的任务;
-
-
- 线程池中执行的任务为空,进入TIDYING状态;
-
-
- TIDYING :整理状态,该状态表明所有的任务已经运行终止,记录的任务数量为
0;
- TIDYING :整理状态,该状态表明所有的任务已经运行终止,记录的任务数量为
-
-
terminated()执行完毕,进入TERMINATED状态;
-
-
- TERMINATED : 终止状态,该状态表示线程池彻底关闭。
11.线程池分类总结重要
11.1FixedThreadPool
线程数固定的线程池
- 线程池参数:
-
- 核心线程数和最大线程数一致
- 非核心线程线程空闲存活时间,即
keepAliveTime为0 - 阻塞队列为无界队列
LinkedBlockingQueue
- 工作机制:
-
- 提交线程任务
- 如果线程数少于核心线程,创建核心线程执行任务
- 如果线程数等于核心线程,把任务添加到
LinkedBlockingQueue阻塞队列 - 如果线程执行完任务,去阻塞队列取任务,继续执行
- 使用场景: 适用于处理
CPU密集型的任务,确保CPU在长期被工作线程使用的情况下,尽可能的少的分配线程,即适用执行长期的任务。
11.2CachedThreadPool
可缓存线程池,线程数根据任务动态调整的线程池
- 线程池参数:
-
- 核心线程数为
0 - 最大线程数为
Integer.MAX_VALUE - 工作队列是
SynchronousQueue同步队列 - 非核心线程空闲存活时间为
60秒
- 核心线程数为
- 工作机制:
-
- 提交线程任务
- 因为核心线程数为
0,所以任务直接加到SynchronousQueue工作队列 - 判断是否有空闲线程,如果有,就去取出任务执行
- 如果没有空闲线程,就新建一个线程执行
- 执行完任务的线程,还可以存活
60秒,如果在这期间,接到任务,可以继续存活下去;否则,被销毁。
- 使用场景: 用于并发执行大量短期的小任务。
11.3SingleThreadExecutor
单线程化的线程池
- 线程池参数:
-
- 核心线程数为
1 - 最大线程数也为
1 - 阻塞队列是
LinkedBlockingQueue - 非核心线程空闲存活时间为
0秒
- 核心线程数为
- 使用场景: 适用于串行执行任务的场景,将任务按顺序执行。
11.4ScheduledThreadPool
能实现定时、周期性任务的线程池
- 线程池参数:
-
- 最大线程数为
Integer.MAX_VALUE - 阻塞队列是
DelayedWorkQueue keepAliveTime为0
- 最大线程数为
- 使用场景: 周期性执行任务,并且需要限制线程数量的需求场景。
线程池使用注意事项
在《阿里巴巴java开发手册》中指出了线程资源必须通过线程池提供,不允许在应用中自行显示的创建线程,这样一方面是线程的创建更加规范,可以合理控制开辟线程的数量;另一方面线程的细节管理交给线程池处理,优化了资源的开销。而线程池不允许使用Executors去创建,而要通过ThreadPoolExecutor方式。jdk中Executor框架虽然提供了如newFixedThreadPool()、newSingleThreadExecutor()、newCachedThreadPool()等创建线程池的方法,但都有其局限性,不够灵活;另外由于前面几种方法内部也是通过new ThreadPoolExecutor方式实现,使用ThreadPoolExecutor有助于大家明确线程池的运行规则,创建符合自己的业务场景需要的线程池,避免资源耗尽的风险。
必须为线程池中的线程,按照业务规则,进行命名。可以在创建线程池时,使用自定义线程工厂规范线程命名方式,避免线程使用默认名称。
// 自定义线程工厂
public class MyThreadFactory implements ThreadFactory {// 线程名称前缀private String threadNamePrefix;// 具备原子性的Integer类型private AtomicInteger threadNumber = new AtomicInteger(1);// 构造方法:创建时需要传入线程名称前缀public MyThreadFactory(String threadNamePrefix) {this.threadNamePrefix = threadNamePrefix;}// 实现接口定义的抽象方法// 该方法作用:根据线程任务,创建线程对象(设置线程名称)@Overridepublic Thread newThread(Runnable r) {// 将线程任务封装成Thread线程对象Thread t = new Thread(r, threadNamePrefix+(threadNumber.getAndIncrement()));if (t.isDaemon())t.setDaemon(false);if (t.getPriority() != Thread.NORM_PRIORITY)t.setPriority(Thread.NORM_PRIORITY);return t;}
}二.线程池核心源码阅读
1.线程池相关的接口和实现类
Executor接口作为线程池技术中的顶层接口,它的作用是用来定义线程池中,用于提交并执行线程任务的核心方法:exuecte()方法。未来线程池中所有的线程任务,都将由exuecte()方法来执行。
ExecutorService接口继承了Executor接口,扩展了awaitTermination()、submit()、shutdown()等专门用于管理线程任务的方法。
ExecutorService接口的抽象实现类AbstractExecutorService,为不同的线程池实现类,提供submit()、invokeAll()等部分方法的公共实现。但是由于在不同线程池中的核心方法exuecte()执行策略不同,所以在AbstractExecutorService并未提供该方法的具体实现。
AbstractExecutorService有两个常见的子类ThreadPoolExecutor和ForkJoinPool,用于实现不同的线程池。
ThreadPoolExecutor线程池通过Woker工作线程、BlockingQueue阻塞工作队列 以及 拒绝策略实现了一个标准的线程池;
ForkJoinPool是一个基于分治思想的线程池实现类,通过分叉(fork)合并(join)的方式,将一个大任务拆分成多个小任务,并且为每个工作线程提供一个工作队列,减少竞争,实现并行的线程任务执行方式,所以ForkJoinPool适合计算密集型场景,是ThreadPoolExecutor线程池的一种补充。
ScheduledThreadPoolExecutor类是ThreadPoolExecutor类的子类,按照时间周期执行线程任务的线程池实现类,通常用于作业调度相关的业务场景。由于该线程池的工作队列使用DelayedWorkQueue,这是一个按照任务执行时间进行排序的优先级工作队列,所以这也是ScheduledThreadPoolExecutor线程池能按照时间周期来执行线程任务的主要原因。
2.工作线程Worker类
每个Woker类的对象,都代表线程池中的一个工作线程。
当ThreadPoolExecutor线程池,通过exeute()方法执行1个线程任务时,会调用addWorker()方法创建一个Woker工作线程对象。并且,创建好的Worker工作线程对象,会被添加到一个HashSet<Worker> workders工作线程集合,统一由线程池进行管理。
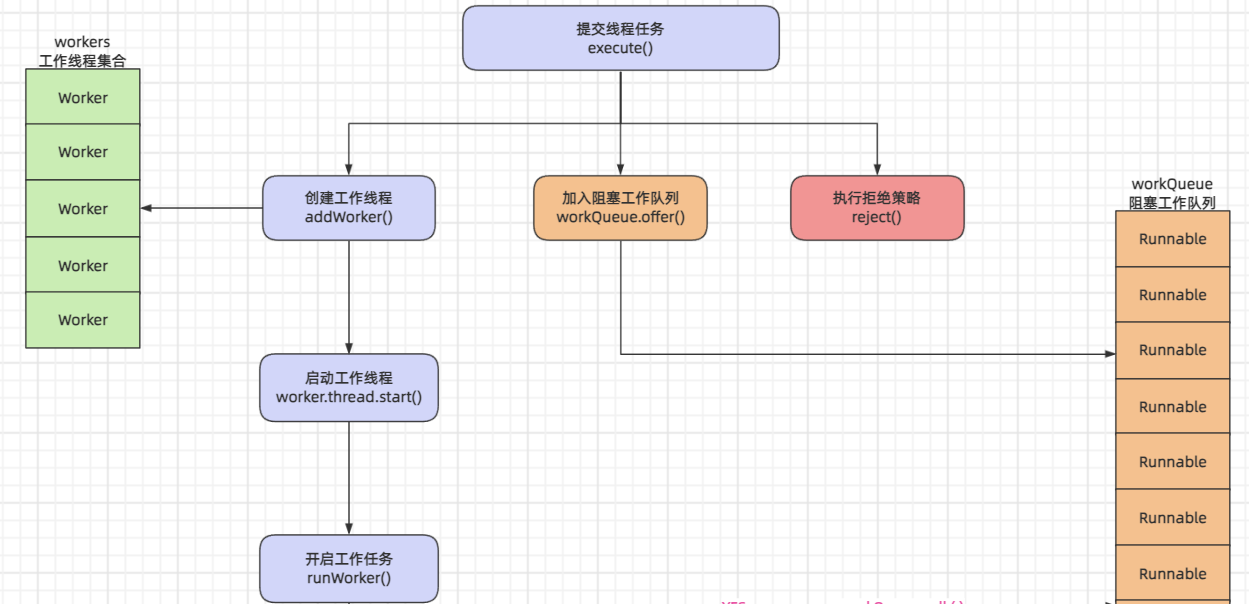
通过阅读源代码,可以看出Worker类是ThreadPoolExecutor类中定义的一个私有内部类,保存了每个Worker工作线程要执行的Runnable线程任务和Thread线程对象
值得重视的是:当Worker工作线程,在第一次执行完成线程任务后,这个Worker工作线程并不会销毁,而是会以循环的方式,通过线程池的getTask()方法,获取阻塞工作队列中新的Runnable线程任务,并通过当前Worker工作线程中所绑定Thread线程,完成新线程任务的执行,从而实现了线程池的中Thread线程的重复使用。
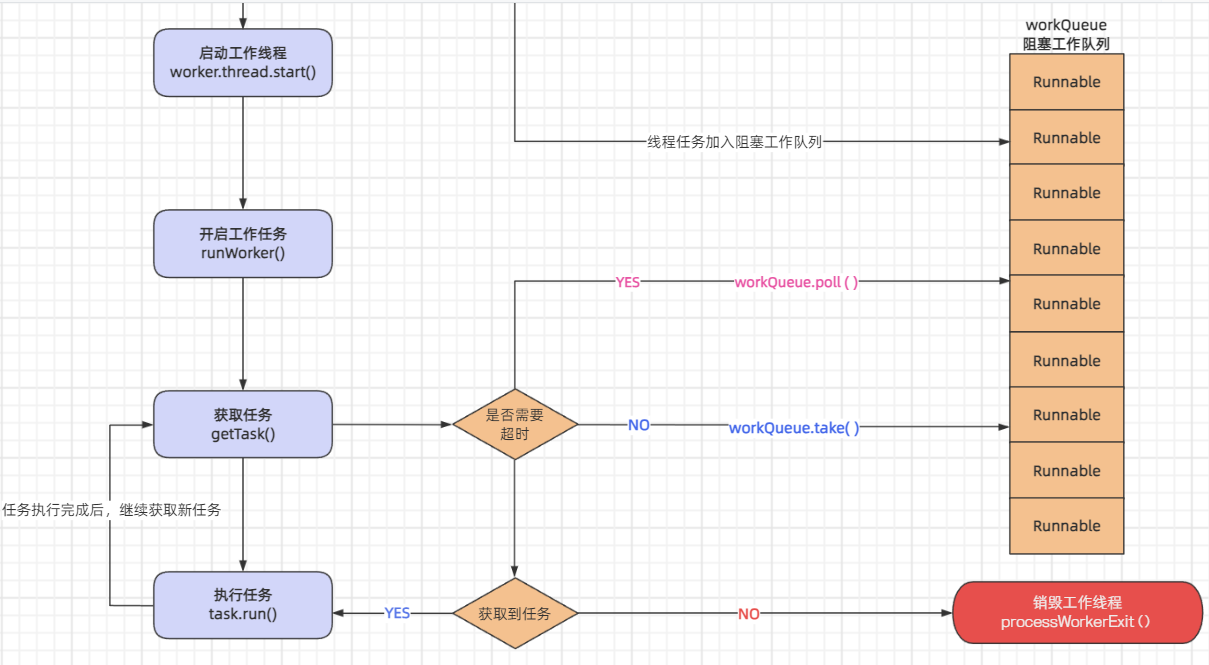
3.核心方法:execute()方法
ThreadPoolExecutor线程池中,会通过execute(Runnable command)方法执行Runnable类型的线程任务。
完整实现了Executor接口定义execute()方法,这个方法作用是执行一个Runnable类型的线程任务。整体的执行流程是:
- 首先,通过
AtomicInteger类型的ctl对象,获取线程池的状态和工作线程数; - 然后,判断当前线程池中的工作线程数;
- 如果,工作线程的数量小于核心线程数,则通过
addWorker()方法,创建新的Worker工作线程,并添加至workers工作线程集合; - 如果,工作线程的数量大于核心线程数,并且线程池处于
RUNNING状态,那么,线程池会将Runnable类型的线程任务,缓存至workQueue阻塞工作队列,等待某个空闲工作线程获取并执行该任务; - 如果,
workQueue工作队列缓存线程任务失败,代表工作队列已满。那么,线程池会重新通过addWorker()方法,尝试创建新的工作线程; - 这次创建时,会判断工作线程数是否超出最大线程数。如果没有超出,会创建新的工作线程;如果已经超出,则返回
false,代表创建失败; - 如果创建失败,线程池执行拒绝策略;
4.核心方法:addWorker()方法
在execute()方法的执行过程中,会通过addWorker()方法创建一个工作线程,用于执行当前线程任务。
阅读源代码,会发现,这个方法的整个执行过程可以分为两个部分:检查线程池的状态和工作线程数量、创建并执行工作线程。
private boolean addWorker(Runnable firstTask, boolean core) {// 第1部分:检查线程池的状态和工作线程数量// 循环检查线程池的状态,直到符合创建工作线程的条件,通过retry标签break退出retry:for (;;) {// 通过ctl对象,获取当前线程池的运行状态int c = ctl.get();int rs = runStateOf(c);// 如果线程池处于开始关闭的状态(获取线程任务为空,同时工作队列不等于空)// 则工作线程创建失败if (rs >= SHUTDOWN &&! (rs == SHUTDOWN &&firstTask == null &&! workQueue.isEmpty()))return false;// 检查工作线程数量for (;;) {// 通过ctl对象,获取当前线程池中工作线程数量int wc = workerCountOf(c);// 工作线程数量如果超出最大容量或者核心线程数(最大线程数)// 则工作线程创建失败if (wc >= CAPACITY ||wc >= (core ? corePoolSize : maximumPoolSize))return false;// 通过ctl对象,将当前工作线程数量+1,并通过retry标签break退出外层循环if (compareAndIncrementWorkerCount(c))break retry;// 再次获取线程池状态,检查是否发生变化c = ctl.get(); // Re-read ctlif (runStateOf(c) != rs)continue retry;// else CAS failed due to workerCount change; retry inner loop}}// 第2部分:创建并执行工作线程....
}- 创建并执行工作线程
-
private boolean addWorker(Runnable firstTask, boolean core) {// 第1部分:检查线程池的状态和工作线程数量....// 第2部分:创建并执行工作线程....boolean workerStarted = false; // 工作线程是否已经启动boolean workerAdded = false; // 工作线程是否已经保存Worker w = null;try {// 创建新工作线程,并通过线程工厂创建Thread线程w = new Worker(firstTask);// 获取新工作线程的Thread线程对象,用于启动真正的线程final Thread t = w.thread;if (t != null) {// 获取线程池的ReentrantLock主锁对象// 确保在添加和启动线程时的同步与安全final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {// 检查线程池状态int rs = runStateOf(ctl.get());if (rs < SHUTDOWN ||(rs == SHUTDOWN && firstTask == null)) {// 检查Thread线程对象的状态是否已经处于启动状态if (t.isAlive()) throw new IllegalThreadStateException();// 保存工作线程workers.add(w);// 记录线程池曾经达到过的最大工作线程数量int s = workers.size();if (s > largestPoolSize)largestPoolSize = s;workerAdded = true;}} finally {mainLock.unlock();}// 添加工作线程后,正式启动线程if (workerAdded) {t.start();workerStarted = true;}}} finally {if (! workerStarted)addWorkerFailed(w);}// 返回线程启动状态return workerStarted; }三.synchronized实现原理
1.synchronized底层实现
使用synchronized保证线程安全,就是保证原子性,简单说就是执行过程中不会被其他线程干扰。
通过下面的代码案例,观察一下synchronized的用法以及底层实现。
案例1:通过两个线程对变量sharedState进行10w次操作,观察每次操作后former与latter之间的关系。
public class ThreadSafeSample {public int sharedState;public void nonSafeAction() {while (sharedState < 100000) {int former = sharedState++;int latter = sharedState;if (former != latter - 1) {System.out.printf("数据观察结果: former is %d,latter is %d", former,latter);}}}public static void main(String[] args) throws InterruptedException {ThreadSafeSample sample = new ThreadSafeSample();Thread threadA = new Thread(){public void run(){sample.nonSafeAction();}};Thread threadB = new Thread(){public void run(){sample.nonSafeAction();}};threadA.start();threadB.start();threadA.join();threadB.join();System.out.println(sample.sharedState);}
}我们发现运行结果,并不是我们期望中的former等于latter,它们之间存在这误差。这部分误差是由于线程不安全导致的。
解决:将两次赋值过程用synchronized保护起来,使用this作为锁,就可以避免别的线程并发的去修改sharedState。
synchronized (this) {
while (sharedState < 100000) {
int former = sharedState++;
int latter = sharedState;
if (former != latter - 1) {
System.out.printf("数据观察结果: former is %d,latter is %d", former, latter);
}
}
}
synchronized代码块是由一对monitorenter/monitorexit指令实现,synchronized是通过对象内部的叫做监视器(monitor)来实现的,线程通过执行monitorenter指令尝试获取monitor的所有权,当monitor被占用时就会处于锁定状态。
2.监视器(monitor)
在JVM实现规范中关于monitor描述:每个对象有一个监视器(monitor),线程通过执行monitorenter指令尝试获取monitor的所有权,当monitor被占用时就会处于锁定状态。
获取monitor的所有权的过程如下:
- 如果
monitor的进入数为0,则该线程进入monitor,然后将进入数设置为1,该线程即为monitor的所有者,代表持有锁; - 如果线程已经占有该
monitor,只是重新进入,则进入monitor的进入数加+1; - 如果其他线程已经占用了
monitor,则该线程进入阻塞状态,直到monitor的进入数为0,再重新尝试获取monitor的所有权;
3.锁升级
在JVM底层实现锁的过程中,有三种类型的锁:偏斜锁 轻量级锁重量级锁
在Java 6之前,synchronized的实现完全是依靠操作系统内部的互斥锁,因为需要进行用户态到内核态的切换,所以同步操作是一个无差别的重量级操作,非常消耗系统资源。
在Java 6之后,在OracleJDK中,JVM对此synchronized进行了大刀阔斧地改进,提供了三种不同的Monitor实现,也就是常说的三种不同的锁:偏斜锁(Biased Locking)、轻量级锁和重量级锁,大大改进了其性能。
所谓锁的升级、降级,就是JVM优化synchronized运行的机制,当JVM检测到不同的竞争状况时,会自动切换到适合的锁实现,这种切换就是锁的升级、降级。
4.偏向锁
偏向锁的核心思想是“假设加锁的代码从始至终就只有一个线程在调用,如果发现有多于一个线程调用,再升级成轻量级锁”。
偏向锁是为了在单线程(没有出现多个线程并发)执行情况下,尽量减少不必要的轻量级锁执行路径,该线程在后续访问时便会自动获得锁,从而降低获取锁带来的消耗,即提高性能。因为轻量级锁的加锁与释放锁,也需要多次执行CAS原子指令。而偏向锁只需要在切换线程设置ThreadID的时候,执行一次CAS原子指令。所以,偏向锁的作用是在只有一个线程执行同步块时,进一步提高性能。
当没有线程并发出现时,默认会使用偏斜锁。JVM会利用CAS操作(compare and swap),在对象头上的Mark Word部分设置线程ID,以表示这个对象偏向于当前线程,所以并不涉及真正的互斥锁。这样做的假设是基于在很多应用场景中,大部分对象生命周期中最多会被一个线程锁定,使用偏斜锁可以降低无竞争开销。
如果有另外的线程试图锁定某个已经被偏斜过的对象,JVM就需要撤销(revoke)偏斜锁,并切换到轻量级锁实现。轻量级锁依赖CAS操作Mark Word来试图获取锁,如果重试成功,就使用普通的轻量级锁;否则,进一步升级为重量级锁。
5.轻量级锁
“轻量级”的概念,是相对于“使用操作系统互斥锁来实现的重量级锁”,但轻量级锁并不是用来代替重量级锁的,它的本意是在没有多线程竞争的前提下,减少传统的重量级锁使用产生的性能消耗。轻量级锁适应的场景是线程交替执行同步块的情况,如果存在同一时间访问同一把锁的情况,就会导致轻量级锁升级为重量级锁。
根据轻量级锁的实现,虽然轻量级锁不支持“并发”,遇到“并发”就要升级为重量级锁。但是轻量级锁可以支持多个线程以串行的方式访问同一个加锁对象。但是,每次执行,都消耗了重复的加锁与解锁的性能开销。
例如:A线程可以先获取对象obj的轻量锁,然后A线程释放了锁,这个时候B线程来获取obj的轻量锁,可以成功获取obj的轻量锁。其余线程对这个obj轻量锁的获取,也以这种方式可以一直串行下去。之所以能实现这种串行,是因为有一个释放锁的动作。
轻量级锁与偏向锁的区别:假设有一个加锁的方法,这个方法在运行的时候,并没有出现并发的情况,从始至终只有一个线程在调用,如果使用轻量级锁,每次调用完也要释放锁,下次调用还要重新获得锁。
锁的状态,保存在对象头中。在Hotspot虚拟机中,一个JAVA对象的存储结构,在内存中的存储布局分为 3 块区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。
6.轻量级锁的加锁过程
- 在代码进入同步块的时候,如果对象锁状态为无锁状态(lock标志位“
01”,biased_lock标志位“0”),虚拟机首先将在当前线程的栈帧中建立一个名为锁记录(Lock Record)的空间,用于存储锁对象目前的Mark Word的拷贝,官方命名为Displaced Mark Word。 - 拷贝对象头中的
Mark Word复制到锁记录(Lock Record)中。 - 拷贝成功后,虚拟机将尝试将对象的
Mark Word中的ptr_to_lock_record更新为指向Lock Record的指针,并将Lock record里的owner指针指向到对象的Mark Word。如果更新成功,则执行步骤4,否则执行步骤5。 - 如果这个更新动作成功了,那么这个线程就拥有了该对象的锁,并且对象
Mark Word的lock标志位设置为“00”,即表示此对象处于轻量级锁定状态。
- 如果这个更新操作失败了,虚拟机首先会检查对象的
Mark Word是否已经指向当前线程的栈帧。如果是,就说明当前线程已经拥有了这个对象的锁,那就可以直接进入同步块继续执行。否则说明多个线程竞争该对象的锁,轻量级锁就要升级为重量级锁,lock标志位的状态值变为“10”,Mark Word中存储的就是指向重量级锁(互斥量)的指针,后面等待锁的线程也要进入阻塞状态。 当前线程便尝试使用自旋来获取锁,自旋就是为了不让线程阻塞,而采用循环去获取锁的过程。
7.轻量级锁的解锁过程
- 通过
CAS指令,尝试把线程中复制的Displaced Mark Word对象替换当前的Mark Word。 - 如果替换成功,整个同步过程就完成了。
- 如果替换失败,说明有其他线程尝试过获取该锁,该锁已升级为重量级锁,那就要在释放锁的同时,通知其它线程重新参与锁的竞争。