【arcmap中shp图层数据导入到postgresql数据库中,中文出现乱码,怎么办?】
项目场景:
arcmap中shp矢量图层数据导入到postgresql数据库或者是其他数据库中,中文字段出现乱码,怎么办?
当我从arcmap中导出shp矢量数据为csv属性表文件时,想要导入数据库,会出现乱码报错,无法导入。
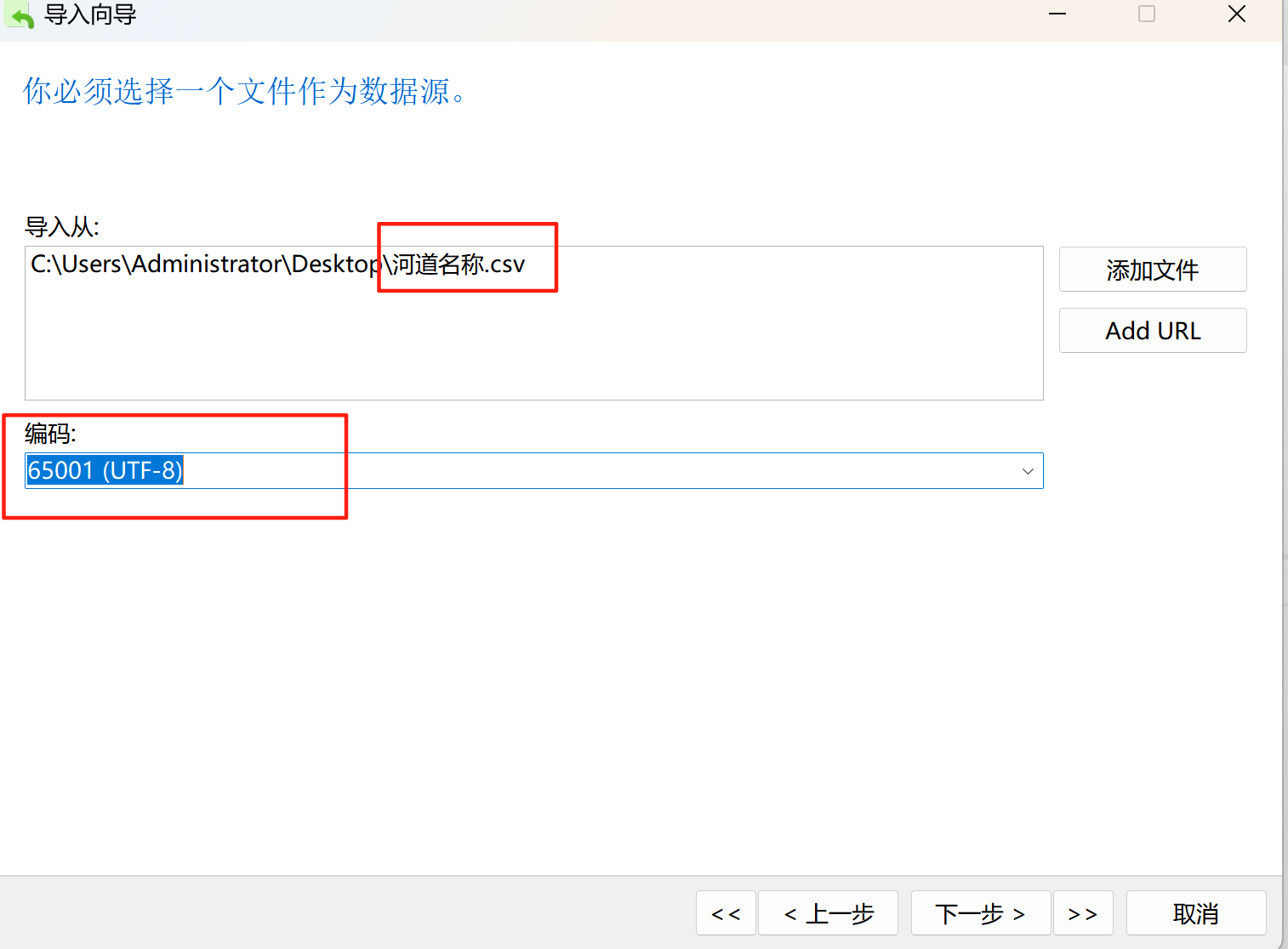
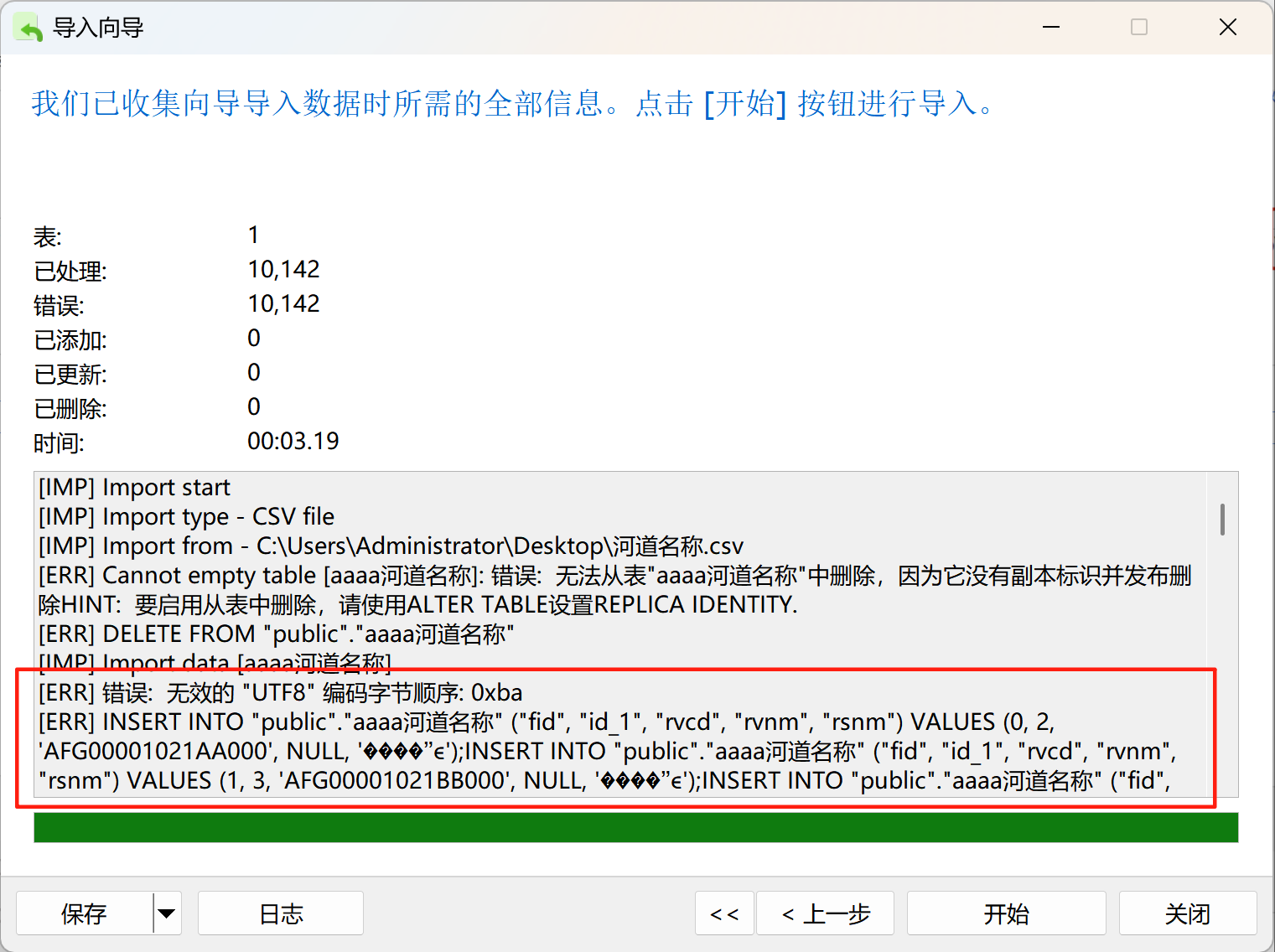
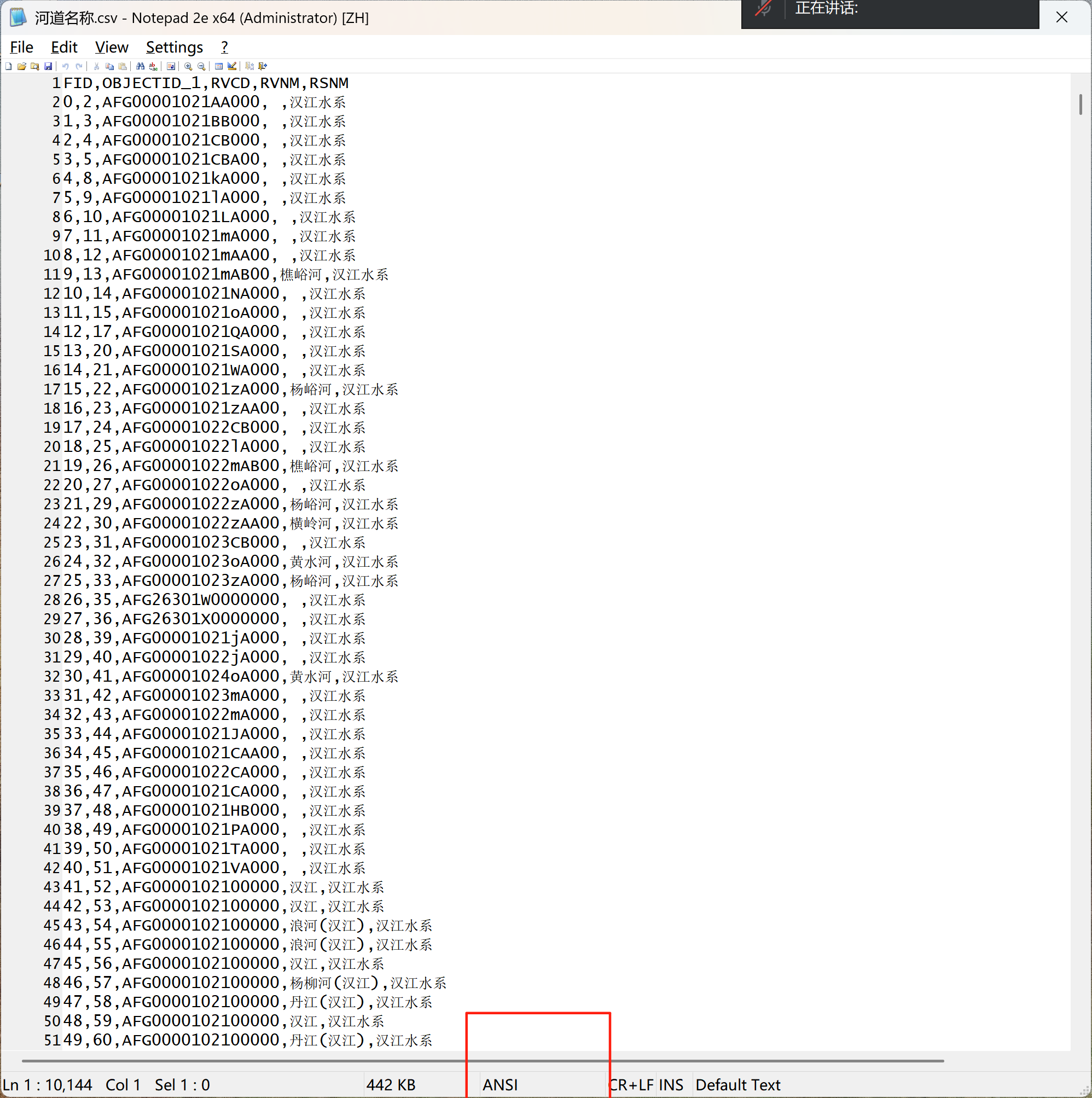
使用记事本打开,发现csv文件的编码格式并不是utf-8,而是ANSI。可以使用nodepad++等文本编辑工具将编码转化为utf-8,再进行导入,就可以导入成功了。

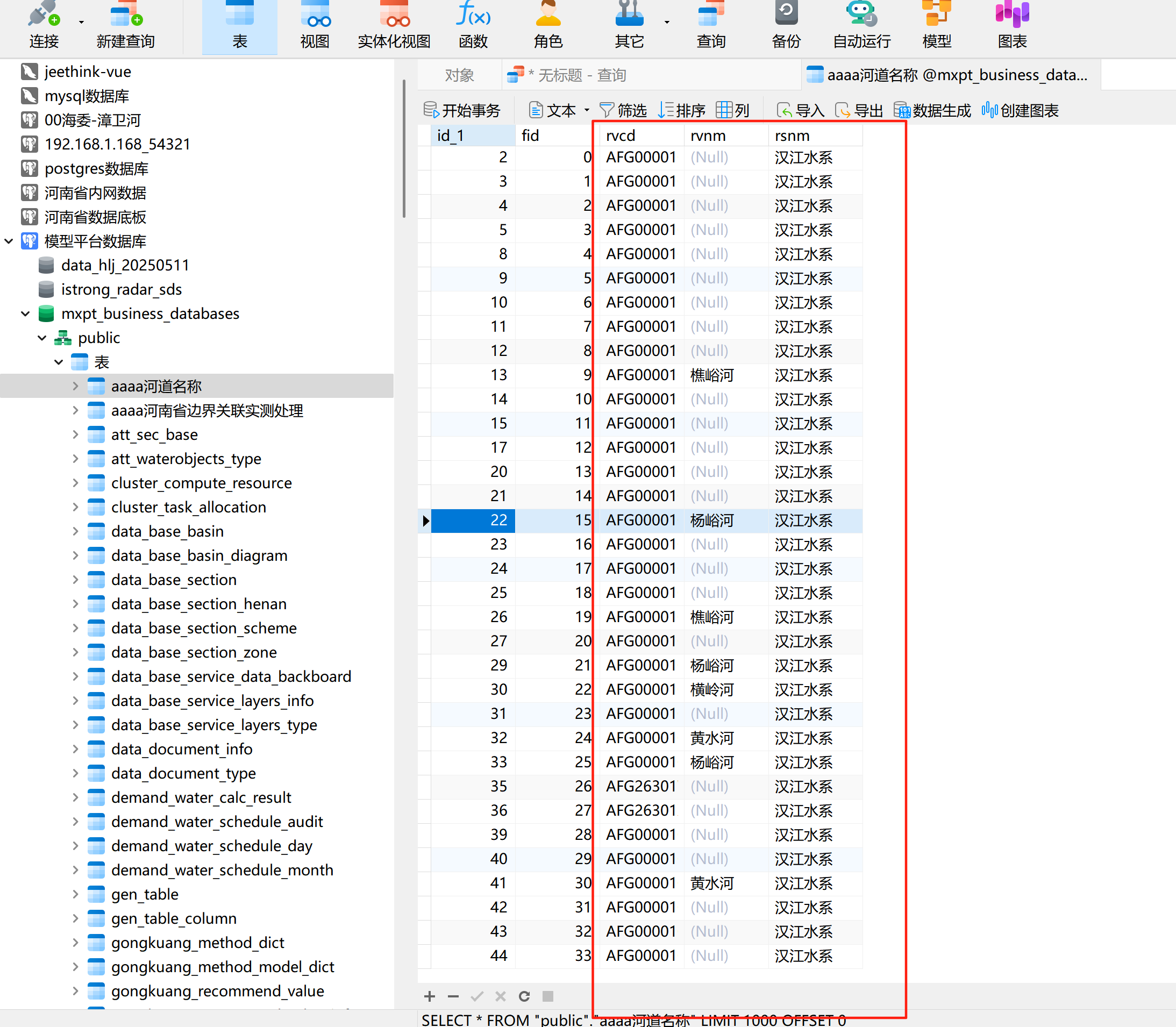
问题描述
如果已经在postgresql数据库中,乱码的信息已经导入到库表汇总了。类似于出现以下乱码的中文:
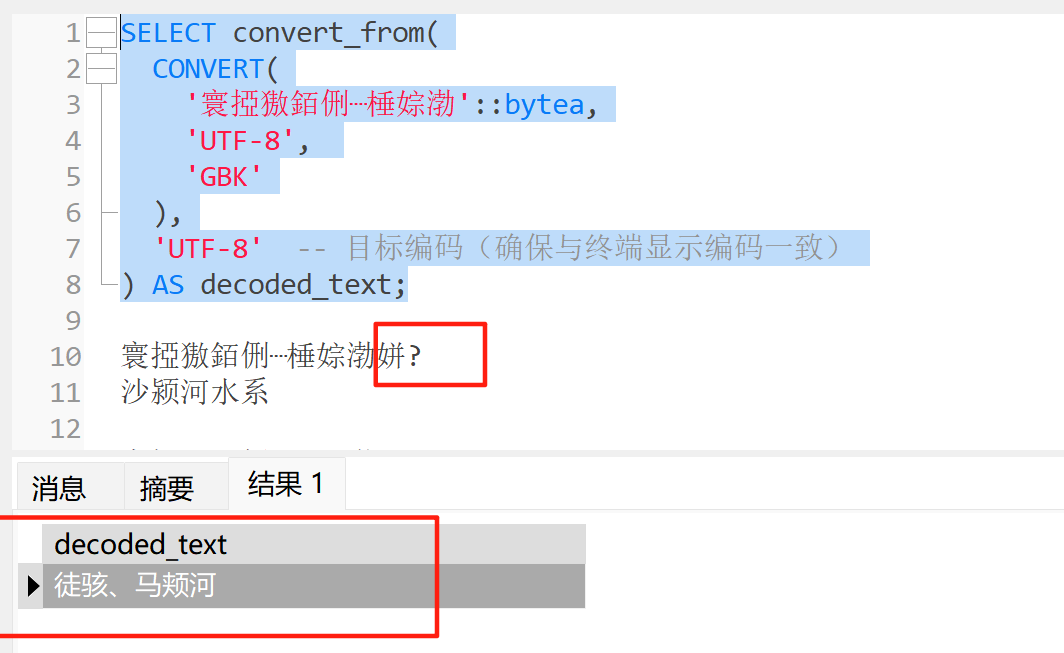
乱码中文:寰掗獓銆侀┈棰婃渤姘?
实际上是:徒骇、马颊河水系乱码中文:娣渤骞叉祦姘寸郴
实际上是:淮河干流水系乱码中文:婕冲崼鍗楄繍娌虫按绯?
乱码中文:濠曞啿宕奸崡妤勭箥濞岃櫕鎸夌化?
实际上是:漳卫南运河水系乱码中文:榛勬渤骞叉祦姘寸郴
实际上是:黄河干流水系
解决方案:
可以使用sql语句进行正确中文的验证:
SELECT convert_from(CONVERT('寰掗獓銆侀┈棰婃渤'::bytea,'UTF-8', 'GBK'),'UTF-8' -- 目标编码(确保与终端显示编码一致)
) AS decoded_text;
注意:navicat无法解析和展示特殊的字段。并且这种sql语句的方式只适合简单的查看和验证。
如果想要全部更新成正确的中文名称,那么可以使用转化为对的编码格式utf-8之后,再进行导入。然后结合sql语句进行数据更新。
UPDATE model_engineering_spatial_rivl AS target
SET rvnm = source.rvnm,rsnm = source.rsnm
FROM (SELECT distinct rvcd, rvnm, rsnmFROM "aaaa河道名称"
) AS source
WHERE target.engr_id = 137 AND target.rvcd = source.rvcd;