【Redis】hash哈希,List列表
目录
一. hash哈希
1.1.常用命令
1.1.1.HSET
1.1.2.HGET
1.1.3.HEXISTS
1.1.4.HDEL
1.1.5.HKEYS
1.1.6.HVALS
1.1.7.HGETALL
1.1.8.HMGET
1.1.9.HLEN
1.1.10.HSETNX
1.1.11.HINCRBY
1.1.12.HINCRBYFLOAT
1.2. 内部编码
1.3. 使用场景
1.4. 缓存方式对比
二 . List列表
2.1.常用命令
2.1.1.LPUSH(头插)
2.1.2.LPUSHX(存在时头插)
2.1.3.RPUSH(尾插)
2.1.4.RPUSHX(存在时尾插)
2.1.5.LRANGE(获取元素)
2.1.6.LPOP(头删)
2.1.7.RPOP(尾删)
2.1.8.LINDEX
2.1.9.LINSERT
2.1.10.LLEN
2.2 阻塞版本命令
2.2.1.BLPOP(阻塞版头删)
2.2.2.BRPOP(阻塞版尾删)
2.3. 内部编码
2.4. 使用场景
2.4.1.消息队列
2.4.2.分频道的消息队列
2.4.3.微博 Timeline
一. hash哈希
⼏乎所有的主流编程语⾔都提供了哈希(hash)类型,它们的叫法可能是哈希、字典、关联数 组、映射。在Redis中,哈希类型是指值本⾝⼜是⼀个键值对结构,形如key="key",value={{ field1, value1 }, ..., {fieldN, valueN } },Redis 键值对和哈希类型⼆者的关系可以⽤下面这个图来表⽰。
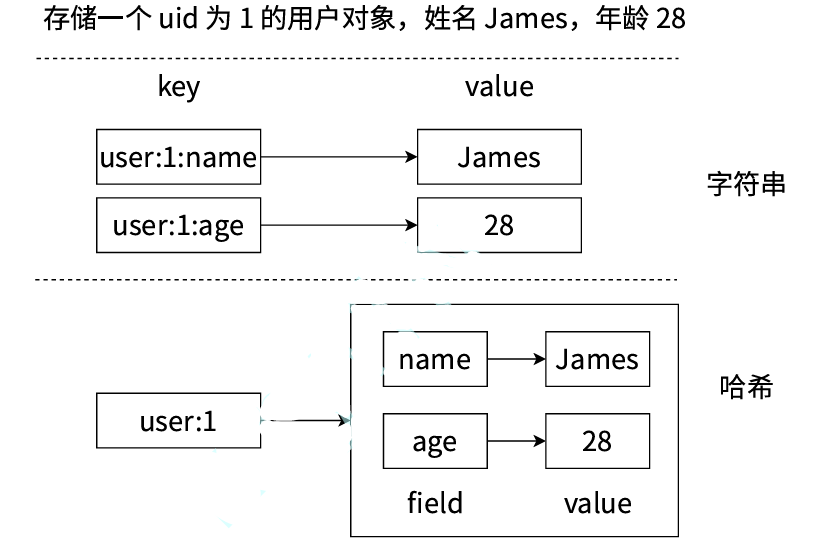
1.1.常用命令
1.1.1.HSET
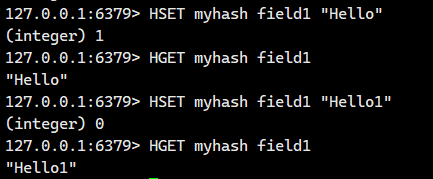
设置哈希表中指定字段的值。若字段已存在则更新其值;若字段不存在则创建新字段。
value得是字符串啊!!
语法:
HSET key field value [field value ...] - 命令有效版本:2.0.0 之后
- 时间复杂度:插入一组 field 为 O(1),插入 N 组 field 为 O(N)
- 返回值:添加的字段的个数。
示例 1:设置单个字段
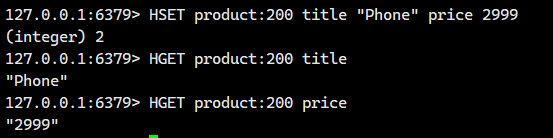
示例 2:设置多个字段,同时设置两个字段(注意空格分隔)
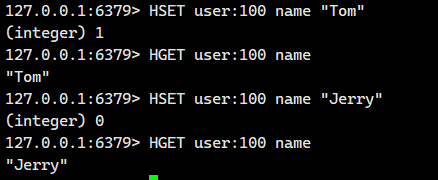
示例 3:更新已有字段
示例 4:混合操作(新增 + 更新)
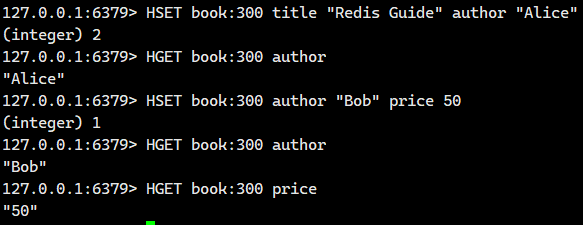
示例 5:键不存在时自动创建,对不存在的键操作会自动创建哈希表
1.1.2.HGET
获取 hash 中指定字段的值。
语法:
HGET key field- 命令有效版本:2.0.0 之后
- 时间复杂度:O(1)
- 返回值:字段对应的值或者 nil。
键不存在时
![]()
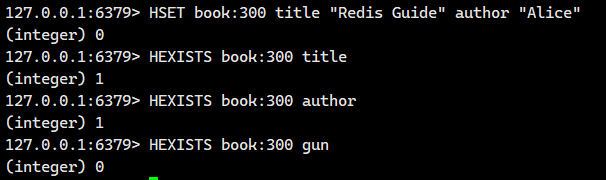
1.1.3.HEXISTS
判断 hash 中是否有指定的字段。
语法:
HEXISTS key field - 命令有效版本:2.0.0 之后
- 时间复杂度:O(1)
- 返回值:1 表示存在,0 表示不存在。
1.1.4.HDEL
删除 hash 中指定的字段。
语法:
HDEL key field [field ...] DEL删除的是key,field删除的是field
- 命令有效版本:2.0.0 之后
- 时间复杂度:删除一个元素为 O(1),删除 N 个元素为 O(N)。
- 返回值:本次操作删除的字段个数。
话不多说,直接看例子
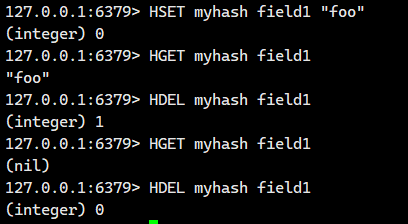
有的人想说,我想直接将整个键给删除掉,那怎么办?其实很简单,别忘记了我们最开始讲的全局命令,我们使用DEL命令即可。
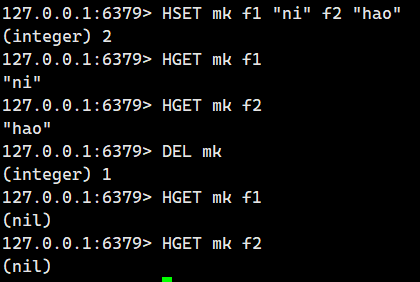
Redis 的 DEL 和 HDEL 命令操作的对象确实不同:
DEL (删除键):
-
作用对象: 整个 Redis 键 (key)。
-
功能: 删除一个或多个指定的键及其关联的所有数据(无论这个键存储的是字符串、哈希、列表、集合、有序集合还是其他类型)。
-
语法:
DEL key [key ...] -
返回值: 被成功删除的键的数量。
-
示例:
-
DEL user:1000删除键user:1000(如果它存储的是一个哈希,整个哈希结构及其所有字段/值都会被删除)。 -
DEL cache:itemA cache:itemB删除键cache:itemA和cache:itemB。
-
HDEL (删除哈希字段):
-
作用对象: 哈希 (Hash) 类型键内部的 字段 (field)。
-
功能: 删除存储在指定哈希键中的一个或多个字段及其关联的值。它只删除哈希内部的特定字段,不会删除整个哈希键本身(除非你删除了该哈希的所有字段)。
-
语法:
HDEL key field [field ...] -
返回值: 被成功删除的字段数量(如果尝试删除的字段不存在,则不计入)。
-
示例:
-
HDEL user:1000 email删除键user:1000这个哈希中的email字段。 -
HDEL user:1000 phone address删除键user:1000这个哈希中的phone和address两个字段。
-
1.1.5.HKEYS
获取 hash 中的所有字段。
语法:
HKEYS key- 命令有效版本:2.0.0 之后
- 时间复杂度:O(N),N 为 field 的个数。
- 返回值:字段列表。
这个操作会先找到key,根据key找到哈希,然后再遍历哈希
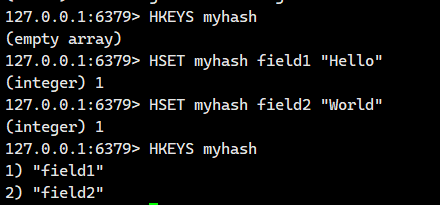
注意:这个命令也是存在一定风险的,因为我们不知道有没有这么一个hash里面会存储大量的field。
1.1.6.HVALS
获取 hash 中的所有的值。
语法:
HVALS key - 命令有效版本:2.0.0 之后
- 时间复杂度:O(N), N 为 field 的个数。
- 返回值:所有的值。
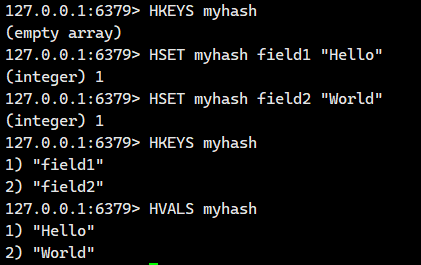
注意:这个操作的时间复杂度是O(N),N是哈希的元素个数,如果哈希非常大,这个操作就可能导致redis被阻塞住。
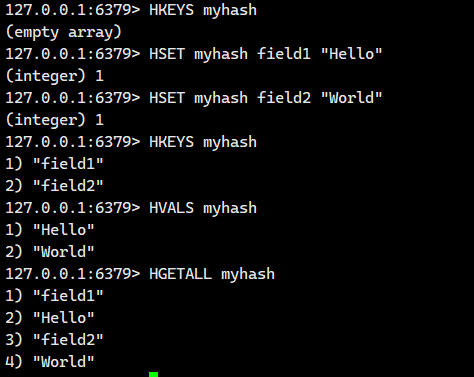
1.1.7.HGETALL
获取 hash 中的所有字段以及对应的值。
语法:
HGETALL key - 命令有效版本:2.0.0 之后
- 时间复杂度:O(N), N 为 field 的个数。
- 返回值:字段和对应的值。
有HMGET,为啥没有HMSET?
其实是有的,事实上我们的HSET就已经支持了一次设置多个字段的功能,完全没有必要再去用HMSET
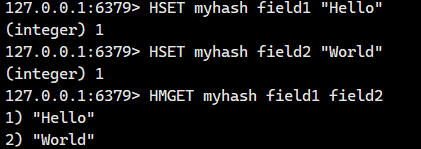
1.1.8.HMGET
一次获取 hash 中多个字段的值。
语法:
HMGET key field [field ...] - 命令有效版本:2.0.0 之后
- 时间复杂度:只查询一个元素为 O(1),查询多个元素为 O(N),N 为查询元素个数。
- 返回值:字段对应的值或者 nil。
![]()
HKEYS、HVALS和HGETALL命令存在潜在风险:当 Hash 的元素数量过多时,执行耗时显著增加,可能导致 Redis 实例阻塞(因其单线程模型)。如果开发人员只需要获取部分 field,可以使用 HMGET,如果一定要获取全部 field,可以尝试使用 HSCAN 命令,该命令采用渐进式遍历哈希类型,HSCAN 会在后续文章介绍。
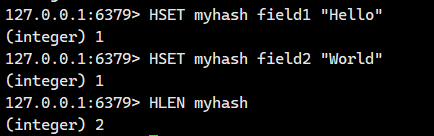
1.1.9.HLEN
获取 hash 中的所有字段的个数。
语法:
HLEN key- 命令有效版本:2.0.0 之后
- 时间复杂度:O(1)
- 返回值:字段个数。
1.1.10.HSETNX
在字段不存在的情况下,设置 hash 中的字段和值。
语法:
HSETNX key field value - 命令有效版本:2.0.0 之后
- 时间复杂度:O(1) ,这个是因为获取哈希的元素个数,是不需要进行遍历的
- 返回值:1 表示设置成功,0 表示失败。
我们看看字段不存在的情况
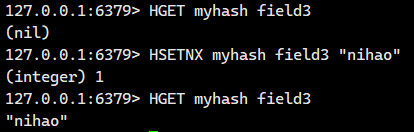
我们看看字段存在的情况
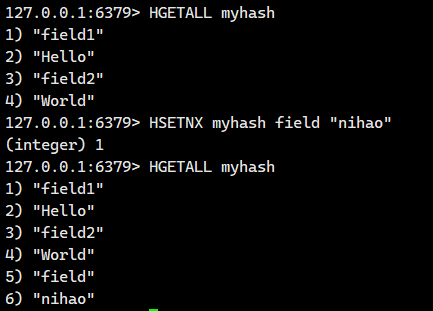
没有更新成功。
1.1.11.HINCRBY
将 hash 中字段对应的数值添加指定的值。
语法:
HINCRBY key field increment - 命令有效版本:2.0.0 之后
- 时间复杂度:O(1)
- 返回值:该字段变化之后的值。
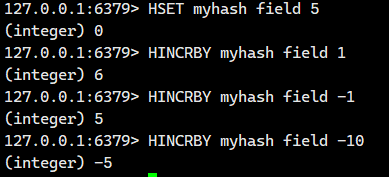
1.1.12.HINCRBYFLOAT
HINCRBY 的浮点数版本。
语法:
HINCRBYFLOAT key field increment- 命令有效版本:2.6.0 之后
- 时间复杂度:O(1)
- 返回值:该字段变化之后的值。
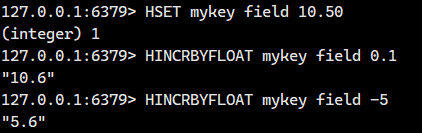
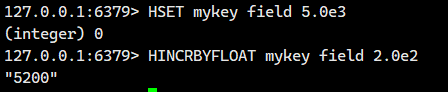
1.2. 内部编码
Redis 哈希结构的内部编码有两种实现方式:
1.ziplist(压缩列表)
-
适用条件:同时满足
-
哈希字段数量 ≤
hash-max-ziplist-entries(默认值:512) -
所有字段值的字节长度 ≤
hash-max-ziplist-value(默认值:64 字节)
-
-
优势:
采用连续内存存储,通过紧凑排列消除元数据开销,内存利用率显著高于 hashtable。 -
典型场景:
存储小型配置信息、轻量级对象属性(如短字符串、数值等)。
2.hashtable(哈希表)
-
触发条件:
任意字段数量或值大小突破 ziplist 的阈值上限。 -
特性:
-
标准字典结构(数组 + 链表/红黑树)
-
读写操作平均时间复杂度 O(1),性能稳定
-
-
优势:
数据规模较大时,避免 ziplist 的线性操作开销(如插入时连锁更新)。
说的直白一点就是
- 哈希的元素个数比较少,使用ziplist表示,元素个数比较多,则使用hashtable
- 每个value的值长度比较短,使用ziplist表示,如果某个value的值长度比较长,也会使用hashtable表示。
下面的示例演示了哈希类型的内部编码,以及响应的变化。
1) 当 field 个数比较少且没有大的 value 时,内部编码为 ziplist:
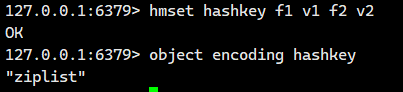
2) 当有 value 大于 64 字节时,内部编码会转换为 hashtable:

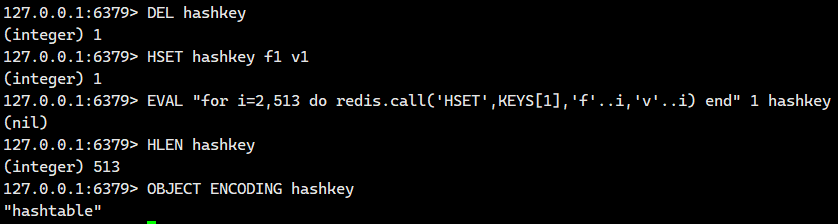
3) 当 field 个数超过 512 时,内部编码也会转换为 hashtable:
1.3. 使用场景
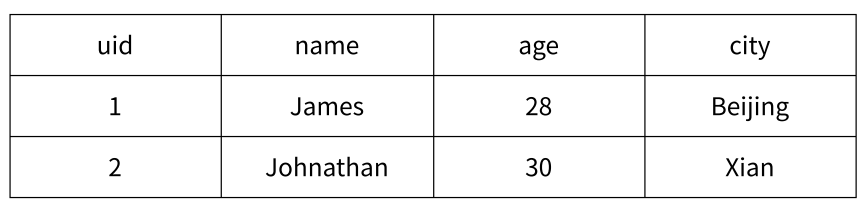
下图 为关系型数据表记录的两条用户信息,用户的属性表现为表的列,每条用户信息表现为行。
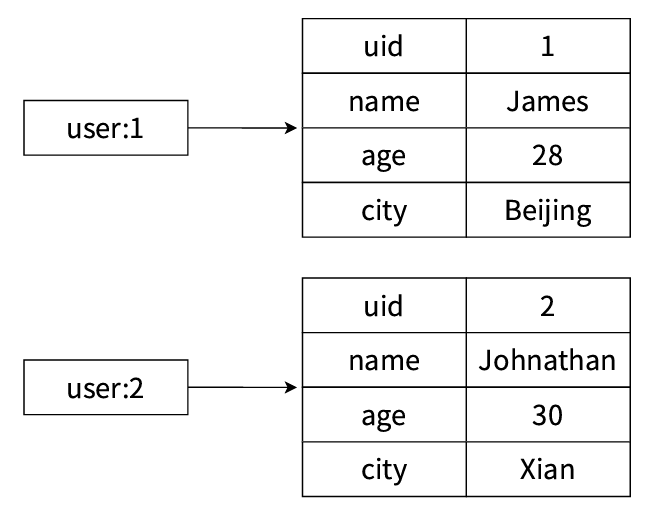
如果映射关系表示这两个用户信息,则如下图所示。
上面这个场景用string其实也可以做到:
如果使用 string (json) 的格式来表示 UserInfo
- 万一只想获取其中的某个 field, 或者修改某个 field ~~
- 就需要把整个 json 都读出来, 解析成 对象, 操作 field, 再重写转成 json 字符串, 再写回去~~
如果使用 hash 的方式来表示 UserInfo
- 就可以使用 field 表示对象的每个属性 (数据表的每个列)
- 此时就可以非常方便的修改/获取任何一个属性的值了~~
使用 hash 的方式, 确实读写 field 更直观高效, 但是付出的是空间的代价~~
- 需要控制哈希在 ziplist 和 /hashtable 两种内部编码的转换,可能会造成内存的较大消耗。
相比于使用 JSON 格式的字符串缓存用户信息,哈希类型变得更加直观,并且在更新操作上变得更灵活。可以将每个用户的 id 定义为键后缀,多对 field-value 对应用户的各个属性,类似如下伪代码:
UserInfo getUserInfo(long uid) {// 根据 uid 得到 Redis 的键String key = "user:" + uid;// 尝试从 Redis 中获取对应的值userInfoMap = Redis 执行命令: hgetall key;// 如果缓存命中 (hit)if (value != null) {// 将映射关系还原为对象形式UserInfo userInfo = 利用映射关系构建对象(userInfoMap);return userInfo;}// 如果缓存未命中 (miss)// 从数据库中,根据 uid 获取用户信息UserInfo userInfo = MySQL 执行 SQL: select * from user_info where uid = <uid>// 如果表中没有 uid 对应的用户信息if (userInfo == null) {响应 404return null;}// 将缓存以哈希类型保存Redis 执行命令: hmset key name userInfo.name age userInfo.age city userInfo.city// 写入缓存,为了防止数据腐烂 (rot),设置过期时间为 1 小时 (3600 秒)Redis 执行命令: expire key 3600// 返回用户信息return userInfo;
}但是需要注意的是哈希类型和关系型数据库有两点不同之处:
- 哈希类型是稀疏的,而关系型数据库是完全结构化的,例如哈希类型每个键可以有不同的 field,而关系型数据库一旦添加新的列,所有行都要为其设置值,即使为 null,如图 2-18 所示。
- 关系数据库可以做复杂的关系查询,而 Redis 去模拟关系型复杂查询,例如联表查询、聚合查询等基本不可能,维护成本高。
1.4. 缓存方式对比
截至目前为止,我们已经能够用三种方法缓存用户信息,下面给出三种方案的实现方法和优缺点分析。
1. 原生字符串类型——使用字符串类型,每个属性一个键。
set user:1:name James
set user:1:age 23
set user:1:city Beijing - 优点:实现简单,针对个别属性变更也很灵活。
- 缺点:占用过多的键,内存占用量较大,同时用户信息在 Redis 中比较分散,缺少内聚性,所以这种方案基本没有实用性。
2. 序列化字符串类型,例如 JSON 格式
set user:1 经过序列化后的用户对象字符串- 优点:针对总是以整体作为操作的信息比较合适,编程也简单。同时,如果序列化方案选择合适,内存的使用效率很高。
- 缺点:本身序列化和反序列需要一定开销,同时如果总是操作个别属性则非常不灵活。
3. 哈希类型
hmset user:1 name James age 23 city Beijing- 优点:简单、直观、灵活。尤其是针对信息的局部变更或者获取操作。
- 缺点:需要控制哈希在 ziplist 和 hashtable 两种内部编码的转换,可能会造成内存的较大消耗。
二 . List列表
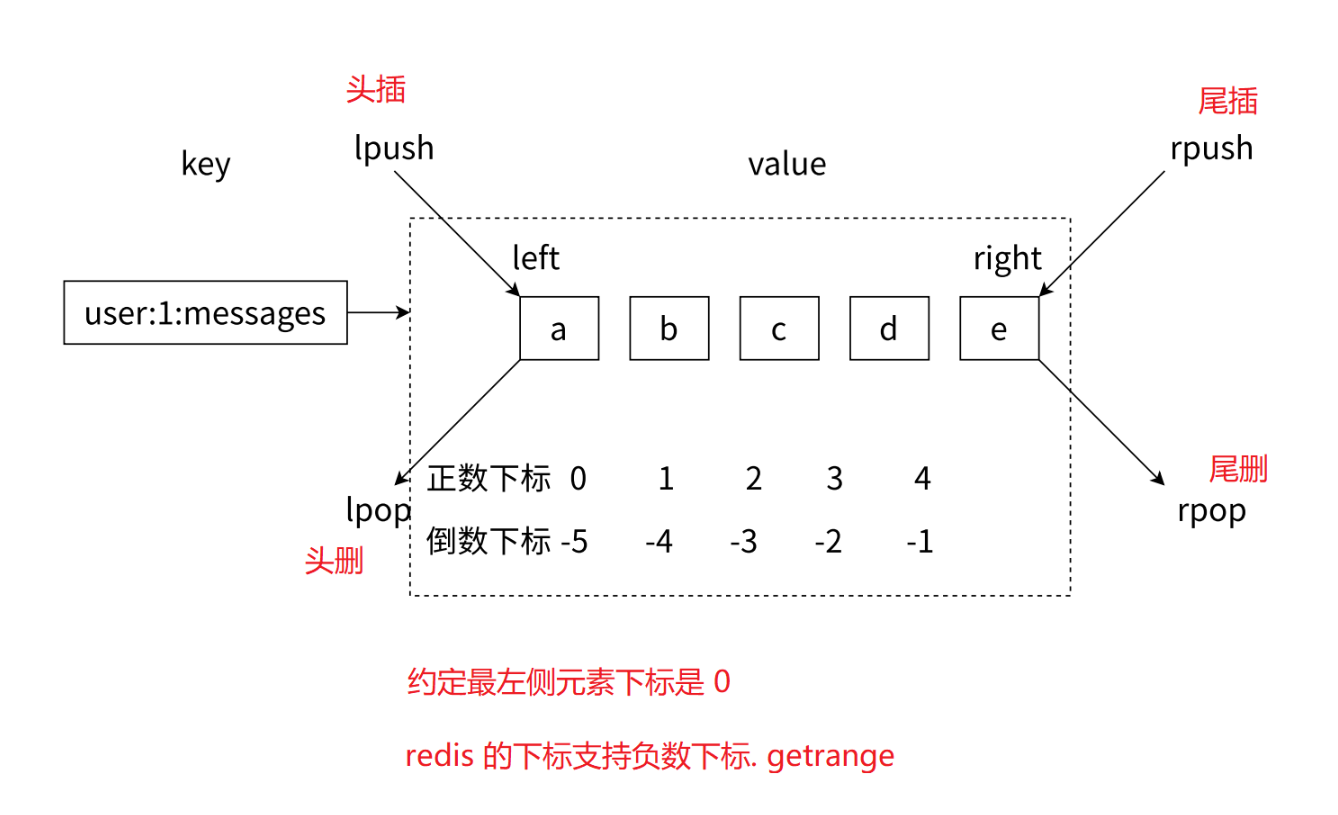
列表类型是⽤来存储多个有序的字符串,如图所⽰,a、b、c、d、e五个元素从左到右组成 了⼀个有序的列表,列表中的每个字符串称为元素(element),⼀个列表最多可以存储个元 素。
在Redis中,可以对列表两端插⼊(push)和弹出(pop),还可以获取指定范围的元素列表、 获取指定索引下标的元素等。列表是⼀种⽐较灵活的数据结构,它可以 充当栈和队列的⻆⾊,在实际开发上有很多应⽤场景。
列表类型的特点:
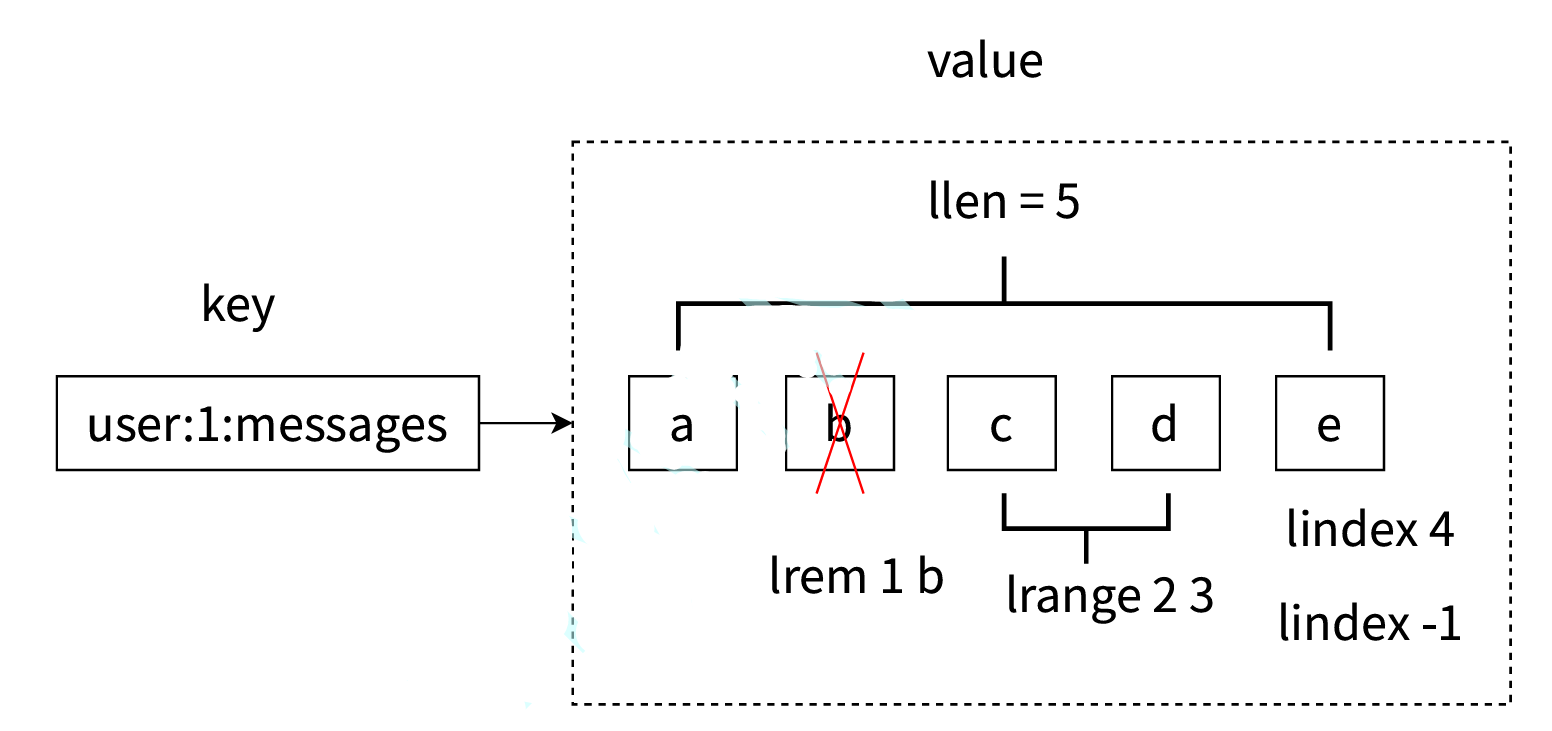
- 第⼀、列表中的元素是有序的,这意味着可以通过索引下标获取某个元素或者某个范围的元素列表, 例如要获取图2-20的第5个元素,可以执⾏lindexuser:1:messages4或者倒数第1个元素,lindex user:1:messages-1 就可以得到元素e。
- 第⼆、区分获取和删除的区别,例如图2-20中的lrem1b是从列表中把从左数遇到的前1个b元素删 除,这个操作会导致列表的⻓度从5变成4;但是执⾏lindex4只会获取元素,但列表⻓度是不会变化 的。
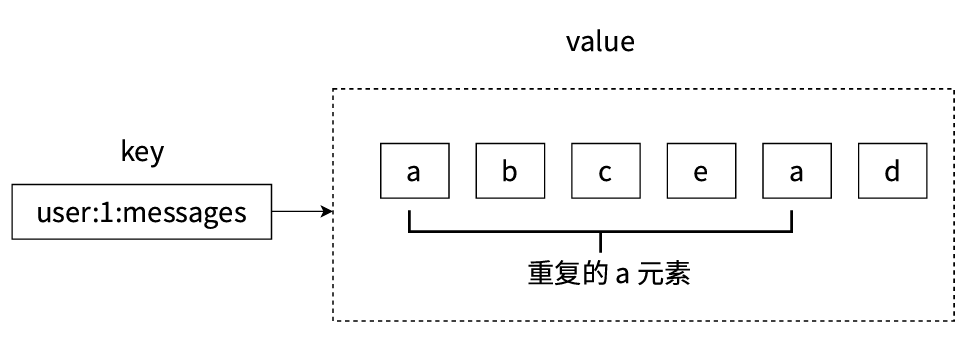
- 第三、列表中的元素是允许重复的,例如下图中的列表中是包含了两个a元素的。像hash里面的field是不能重复的
因为当前的List头和尾都能高效的插入删除元素,所以我们完全可以将List当成一个队列/栈来使用。
2.1.常用命令
2.1.1.LPUSH(头插)
LPUSH我们可以理解为left push,我们一般将左边视为头!所以为头插
将一个或者多个元素从左侧放入(头插)到 list 中。
一次可以插入一个或者多个元素
语法:
LPUSH key element [element ...]- 命令有效版本:1.0.0 之后
- 时间复杂度:只插入一个元素为 O(1), 插入多个元素为 O(N), N 为插入元素个数.
- 返回值:插入后 list 的长度。
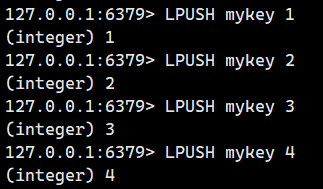
注意这个是头插,我们按顺序插入1234,事实上得到的是4321.
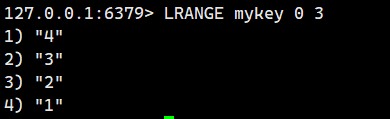
如果key已经存在,而且key对应的类型不是List,那么对这个key执行LPUSH则会报错

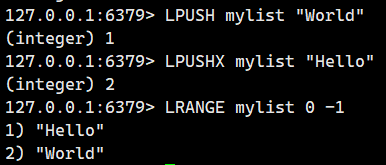
2.1.2.LPUSHX(存在时头插)
在 key 存在时,将一个或者多个元素从左侧放入(头插)到 list 中。
不存在,直接返回。
语法:
LPUSHX key element [element ...]- 命令有效版本:2.0.0 之后
- 时间复杂度:只插入一个元素为 O(1),插入多个元素为 O(N),N 为插入元素个数。
- 返回值:插入后 list 的长度。
我们看看键存在的情况
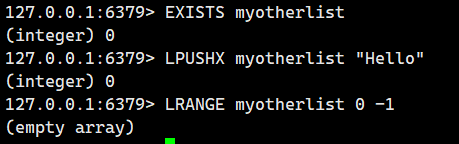
我们再看看键不存在的时候
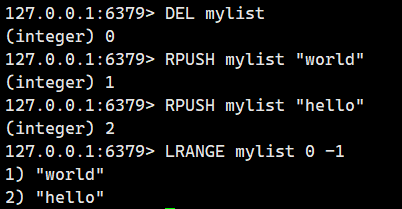
2.1.3.RPUSH(尾插)
RPUSH我们可以理解为right push,我们一般将右边视为尾!
将一个或者多个元素从右侧放入(尾插)到 list 中。
语法:
RPUSH key element [element ...]- 命令有效版本:1.0.0 之后
- 时间复杂度:只插入一个元素为 O(1), 插入多个元素为 O(N), N 为插入元素个数.
- 返回值:插入后 list 的长度。
注意这个是尾插啊!!!
2.1.4.RPUSHX(存在时尾插)
在 key 存在时,将一个或者多个元素从右侧放入(尾插)到 list 中。
语法:
RPUSHX key element [element ...]- 命令有效版本:2.0.0 之后
- 时间复杂度:只插入一个元素为 O(1),插入多个元素为 O(N),N 为插入元素个数。
- 返回值:插入后 list 的长度。
我们看看键存在时的情况
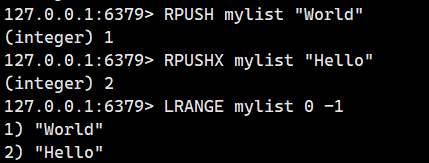
我们看看键不存在的情况
2.1.5.LRANGE(获取元素)
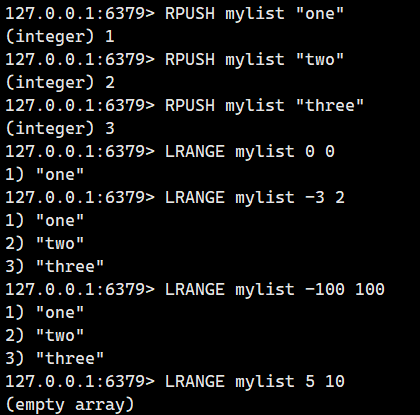
获取列表(list)中指定区间 [start, stop] 的所有元素,区间为左闭右闭(包含 start 和 stop 位置的元素)。
语法:
LRANGE key start stop - 命令有效版本:1.0.0 之后
- 时间复杂度:O(N)
- 返回值:指定区间的元素。
注意:START和STOP可以是数字,数字的含义如下:
- 支持索引:0表示第一个元素,1表示第2个元素,以此类推
- 支持负数索引:
-1表示最后一个元素,-2表示倒数第二个,依此类推
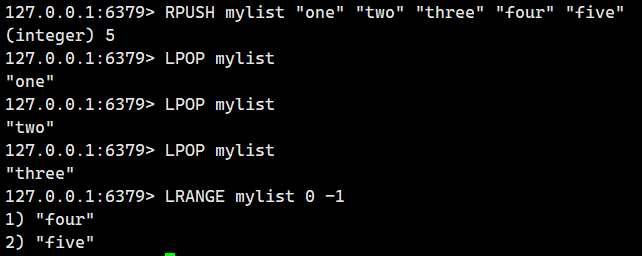
2.1.6.LPOP(头删)
从 list 左侧取出元素(即头删)。
语法:
LPOP key - 命令有效版本:1.0.0 之后
- 时间复杂度:O(1)
- 返回值:取出的元素或者 nil。
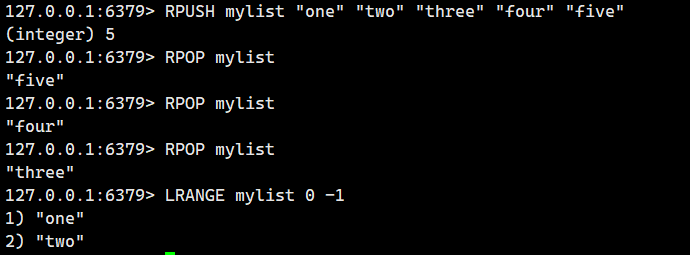
2.1.7.RPOP(尾删)
从 list 右侧取出元素(即尾删)。
语法:
RPOP key- 命令有效版本:1.0.0 之后
- 时间复杂度:O(1)
- 返回值:取出的元素或者 nil。
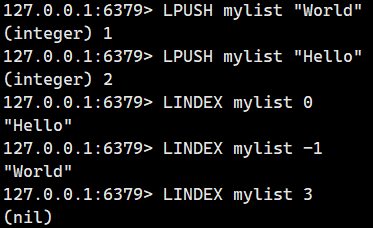
2.1.8.LINDEX
获取从左数第 index 位置的元素。
语法:
LINDEX key index - 命令有效版本:1.0.0 之后
- 时间复杂度:O(N)
- 返回值:取出的元素或者 nil。
注意:index可以取下面这些值
正数索引(从左向右)
-
0→ 第一个元素 -
1→ 第二个元素 -
n→ 第 n+1 个元素
负数索引(从右向左)
-
-1→ 最后一个元素 -
-2→ 倒数第二个元素 -
-n→ 倒数第 n 个元素
话不多说我们直接看例子
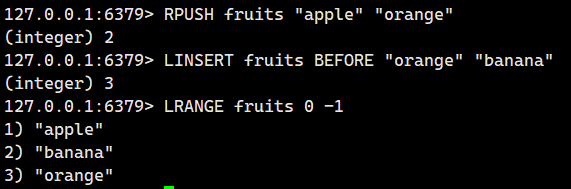
2.1.9.LINSERT
在特定位置插入元素。
语法:
LINSERT key <BEFORE | AFTER> pivot element 版本支持
2.2.0 及以上版本
时间复杂度
O(N),其中 N 为查找基准元素需遍历的长度
-
最佳情况(基准在头部):O(1)
-
最坏情况(基准在尾部):O(N)
返回值
-
成功插入:返回更新后的列表长度
-
基准不存在:返回
-1 -
key 不存在:返回
0
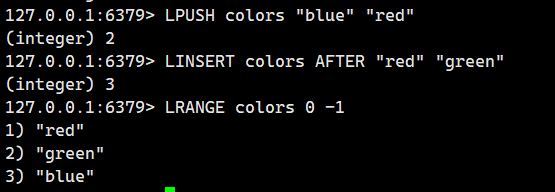
大家注意下面这2点:
-
位置标识符
-
BEFORE→ 插入到基准元素之前 -
AFTER→ 插入到基准元素之后
-
-
基准元素(pivot)
-
必须精确匹配列表中的现有元素值(区分大小写)
-
若列表存在多个相同值,以最先遍历到的为准
-
话不多说,直接看例子
示例 1:基础插入
示例 2:在元素后插入
示例 3:处理重复值
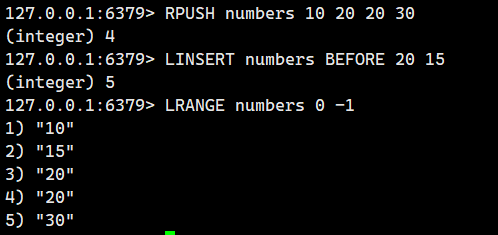
在第一个 "20" 前插入 "15"
示例 4:基准元素不存在
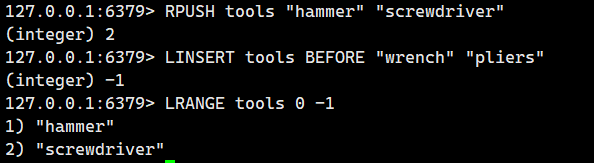
2.1.10.LLEN
获取 list 长度。
语法:
LLEN key - 命令有效版本:1.0.0 之后
- 时间复杂度:O(1)
- 返回值:list 的长度。
2.2 阻塞版本命令
blpop 和 bropp 是 lpop 和 rpop 的阻塞版本,和对应非阻塞版本的作用基本一致,
但是阻塞版本还是有一些特点的:
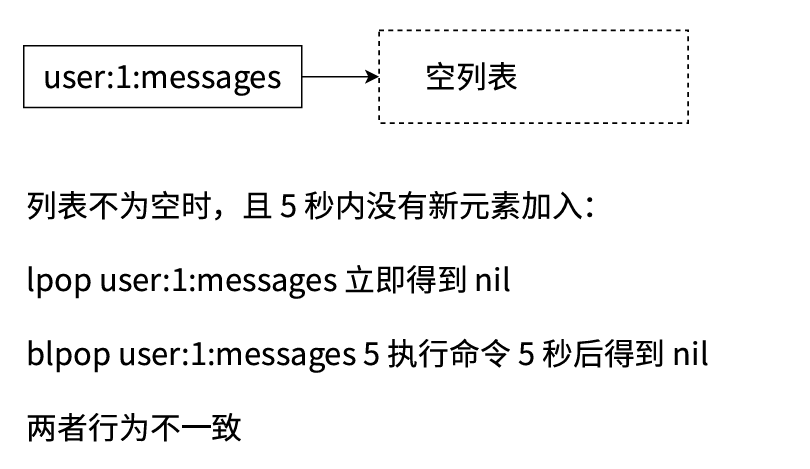
1. 空列表处理机制对比
-
非阻塞版本(LPOP/RPOP):当列表为空时立即返回
nil -
阻塞版本(BLPOP/BRPOP):
-
列表为空时阻塞客户端连接
-
阻塞时长由
timeout参数控制(单位:秒) -
阻塞期间 Redis 服务端可处理其他命令,但该客户端连接无法执行其他操作
-
超时后返回
nil,或在新元素到达时立即返回该元素
-
2. 多键监听机制
-
支持同时监听多个列表键:
BLPOP list1 list2 list3 10 # 按序检查 list1→list2→list3 -
执行流程:
-
从左向右扫描键列表
-
遇到第一个非空列表时,弹出其首元素并返回
-
若所有列表均为空,进入阻塞状态
-
3. 客户端竞争规则
-
当多个客户端同时阻塞监听同一个键时:
-
新元素到达后,最早发起监听的客户端优先获取
-
其他客户端继续阻塞等待
-
4. 阻塞原理深度解析
-
服务端行为:
-
将阻塞客户端加入监控队列
-
收到
LPUSH/RPUSH等写入命令时唤醒对应客户端
-
-
客户端表现:
-
TCP 连接保持但无数据流动
-
命令超时前无法执行其他操作
-
-
典型超时设置:
-
0= 无限等待(慎用) -
5-30= 常规业务超时 -
>60= 长轮询场景
-

2.2.1.BLPOP(阻塞版头删)
BLPOP 是 LPOP 的阻塞版本,用于从列表左侧(头部)删除元素。
- 当列表不为空时行为与
LPOP一致; - 当列表为空时,客户端连接将进入阻塞状态直到新元素到达或超时。
注意:在阻塞期间Redis其实是可以执行其他命令的,这里的BLPOP和BRPOP看起来耗时很久,但是实际上并不会对redis服务器产生负面影响。
语法:
BLPOP key [key ...] timeout 版本支持
1.0.0 及以上版本
时间复杂度
O(1) - 无论列表长度如何,弹出操作均为常数时间复杂度
核心特性深度解析
1. 阻塞机制
-
列表有元素:立即弹出最左侧元素
-
列表为空:
-
阻塞客户端连接,暂停后续命令执行
-
阻塞时长由
timeout参数指定(单位:秒) -
期间若其他客户端向列表写入数据,立即唤醒并返回元素
-
超时后返回
nil
-
2. 多键监听模式
-
可同时监控多个列表:
BLPOP orders alerts notifications 10 -
执行优先级:
-
从左向右检查列表
-
遇到第一个非空列表时弹出元素
-
返回格式:
[列表名, 元素值]
["alerts", "urgent:server_down"] # 示例返回值 -
3. timeout参数特殊值
-
0:无限阻塞(生产环境慎用) -
>0:阻塞指定秒数 -
支持小数精度(如
0.5表示 500 毫秒)
示例
话不多说,直接看例子
示例 1:从一个有元素的列表中阻塞式弹出元素。
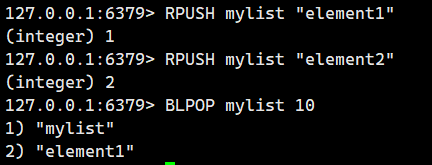
大家注意到我这个mylist里是有元素的,所以我一执行BLPOP,就立即返回结果了。
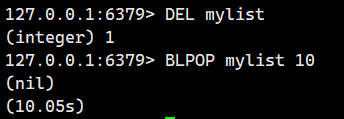
示例 2:从一个空的列表中阻塞式弹出元素。
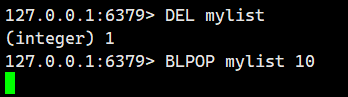
大家可以看到我这mylist里面可是没有任何元素的,当我一执行BLPOP,就立即阻塞住了。
这个时候会一直阻塞到timeout设置的10秒之后。
我们在这个期间对mylist不做任何操作,10S之后发现停止阻塞,直接返回了nil,代表没有删除任何元素。
示例 3:从一个空的列表中阻塞式弹出元素。
这个时候,我们打开另外一个客户端,往mylist里面插入一个元素

这个时候我们回到原来那个客户端
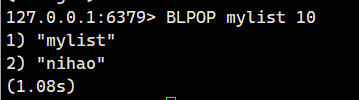
就会发现阻塞停止了。直接返回了。
我们这个时候看看
![]()
里面什么元素都没有,这很符合我们的预期!!!
2.2.2.BRPOP(阻塞版尾删)
BRPOP 是 RPOP 的阻塞版本,用于从列表右侧(尾部)删除元素。
- 当列表不为空时行为与 RPOP 一致;
- 当列表为空时,客户端连接将进入阻塞状态直到新元素到达或超时。
语法:
BRPOP key [key ...] timeout- 命令有效版本:1.0.0 之后
- 时间复杂度:O(1)
- 返回值:取出的元素或者 nil。
关键特性讲解
1. 阻塞机制
-
当指定的所有列表都为空时,客户端将被阻塞
-
一旦有指定列表被推入新元素(例如使用LPUSH/RPUSH),客户端立即从该列表的尾部弹出一个元素
-
如果超时时间(timeout)到达,则返回nil
2. 多键监听模式
可以同时监听多个键,按照从左到右的顺序检查列表,一旦有列表非空,则从该列表的尾部弹出元素。
示例命令:
BRPOP orders alerts notifications 10-
此命令会依次检查
orders、alerts、notifications三个列表 -
如果在10秒内,
alerts列表被添加了元素,则立即从alerts的尾部弹出元素:1) "alerts" # 键名 2) "urgent:server_down" # 弹出的值
3. timeout参数特殊值
-
timeout为0:表示无限期阻塞,直到有元素可弹出 -
timeout为正整数:表示阻塞的最长等待时间(单位为秒),支持小数(如0.1表示100毫秒)
话不多说,直接看例子
示例 1:从一个有元素的列表中阻塞式弹出尾部元素
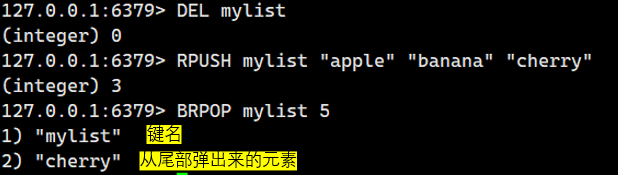
大家注意到我这个mylist里是有元素的,所以一执行BRPOP就立即返回了尾部元素"cherry"。
示例 2:从一个空的列表中阻塞式弹出尾部元素
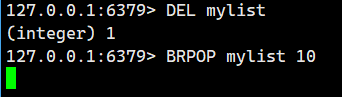
大家可以看到mylist是空的,执行BRPOP后立即阻塞。
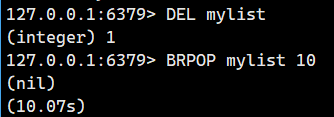
10秒内没有任何操作,超时后返回nil。
示例 3:阻塞过程中另一个客户端向列表添加元素
客户端A(阻塞状态):
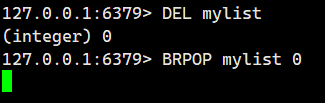
在阻塞期间,客户端B执行:
![]()
客户端A立即返回:
检查列表状态:

列表已为空,这完全符合预期!
2.3. 内部编码
Redis 列表(List)的内部编码机制经历了重要的优化。早期版本主要依赖两种结构,根据元素数量和大小自动切换:
-
ziplist (压缩列表)
-
触发条件: 需同时满足:
-
列表元素个数 ≤
list-max-ziplist-entries(默认值:512) -
每个元素值的长度(字节数) ≤
list-max-ziplist-value(默认值:64 字节)
-
-
优势: 将元素和长度信息紧凑、连续地存储在一块内存中,显著减少内存碎片,对于小型列表特别高效。
-
配置调整 (
redis.conf):list-max-ziplist-entries 512 # 可调整元素数量阈值 list-max-ziplist-value 64 # 可调整元素长度阈值(单位:字节)
-
-
linkedlist (双向链表)
-
触发条件: 当列表不满足 ziplist 的任意一个条件(元素数量过多或单个元素过大)时自动切换。
-
优势: 支持在列表任意位置进行高效的 O(1) 时间复杂度元素插入和删除,尤其适合大型列表。
-
特点: 每个元素作为独立的节点存储(包含指向前后节点的指针和实际值),可以存储任意长度的数据。缺点是每个节点有额外的内存开销(指针),且内存不连续。
-
重要更新:新版本中的 Quicklist
在较新的 Redis 版本(大约从 3.2 开始)中,ziplist 和 linkedlist 已不再是列表类型的默认或主要内部编码实现。它们被一个更优的结构所取代:quicklist。
-
设计理念:
quicklist本质上是一个ziplist的linkedlist。它巧妙地结合了两种旧结构的优点。 -
结构描述:
-
quicklist的整体结构是一个双向链表。 -
这个链表中的每个节点 (entry) 不再是一个单独的元素,而是一个
ziplist。 -
每个节点内的
ziplist被限制在一定的大小范围内(通常受list-max-ziplist-size配置控制,可正可负,例如-2表示 8KB),确保单个 ziplist 不会过大而失去其紧凑的优势。 -
多个这样的
ziplist节点通过链表指针连接起来,形成一个逻辑上的大列表。
-
-
核心优势:
-
内存效率: 在节点内部使用
ziplist存储多个元素,保持了紧凑存储,减少了小元素带来的内存碎片和指针开销。 -
访问性能: 对于按索引访问,可以通过链表快速定位到目标节点(ziplist),再在 ziplist 内部进行(相对)快速的偏移访问。
-
插入/删除性能: 在列表两端(头/尾)的插入/删除通常非常高效(可能发生在头/尾节点的 ziplist 内或创建新节点)。在列表中间插入/删除时,如果发生在某个 ziplist 节点内部且该节点未满,也能利用 ziplist 的紧凑性获得较好性能;如果导致节点分裂或合并,则成本稍高,但整体上通过限制单个 ziplist 的大小,将大列表操作的性能波动控制在可接受范围内。
-
灵活性: 能够高效地存储从小型到超大型的列表,并适应不同大小的元素。
-
-
配置 (
redis.conf):-
list-max-ziplist-size:这是控制quicklist行为的关键参数。它决定了每个 quicklist 节点(即一个 ziplist)所能包含的字节数或元素个数的上限(取决于配置值的正负)。-
正值:表示每个 ziplist 节点最多包含的元素个数。例如
5表示每个节点最多 5 个元素。 -
负值:表示每个 ziplist 节点占用的最大内存字节数(近似值):
-
-1: 4KB -
-2: 8KB (默认值) -
-3: 16KB -
-4: 32KB -
-5: 64KB
-
-
-
list-compress-depth:控制列表两端节点的 LZF 压缩深度,以进一步节省内存(0 表示不压缩,默认值)。
-
编码切换示例演示
✅ 案例 1:小元素+少量数据,这个情况本来是ziplist的,但是现在在新版本里面就只能是quicklist的
⚠️ 案例 2:批量插入513个元素(使用Lua脚本避免手动输入),这个本来是会切换 linkedlist(元素数量超标)的,但是现在只有quicklist!!

⚠️ 案例 3:插入70字节的长字符串(超过默认64字节)这个本来是应该是会切换 linkedlist(元素尺寸超标)的,但是现在还是quicklist
2.4. 使用场景
2.4.1.消息队列
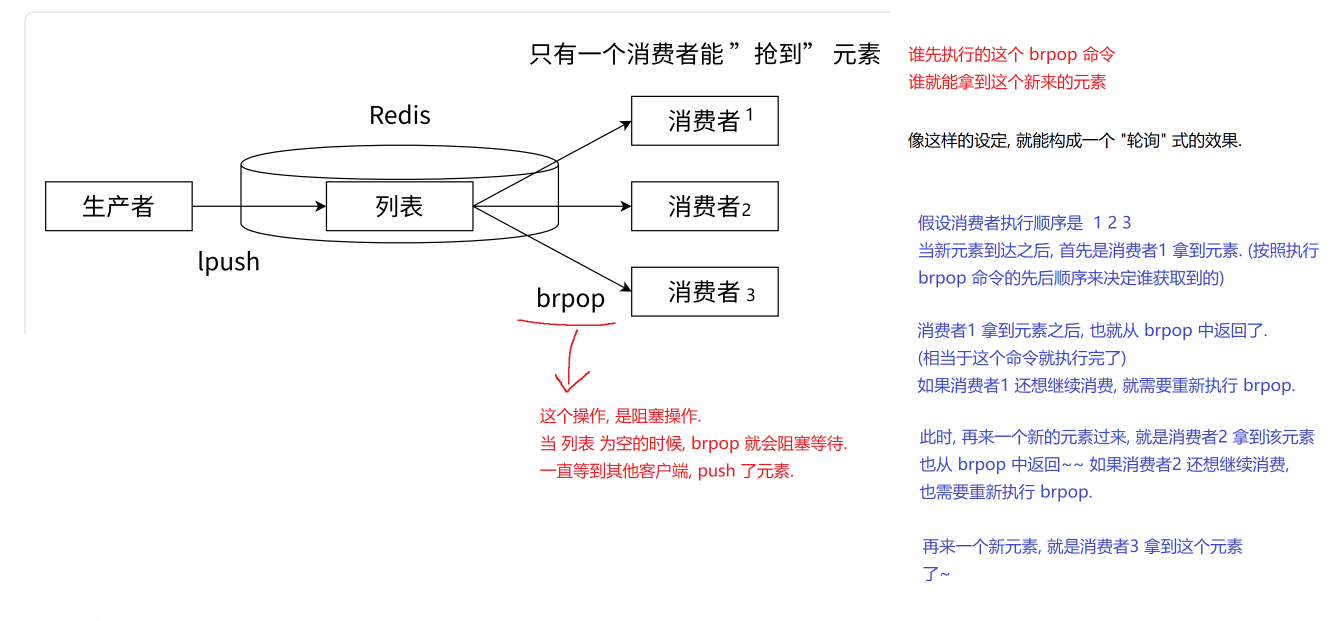
Redis 的列表(List)数据结构,结合 LPUSH 和 BRPOP 命令,是实现经典阻塞式生产者-消费者队列模型的有效方案。
-
生产者:使用
LPUSH命令将新元素插入到列表的左侧(队尾)。 -
消费者:多个消费者客户端使用
BRPOP命令,以阻塞方式尝试从列表的右侧(队首)移除并获取元素。
这种设计的关键优势在于实现了负载均衡和高可用性:
-
负载均衡:多个消费者客户端可以同时监听同一个队列。
-
阻塞与竞争:
BRPOP命令是阻塞的。如果队列为空,消费者会一直等待,直到有元素可用或超时。当新元素被生产者 (LPUSH) 推入队列时,所有正在阻塞等待 (BRPOP) 的消费者会同时被唤醒。 -
“争抢”与轮询:被唤醒的消费者会竞争获取这个新元素。Redis 内部处理这些并发请求时,大致遵循消费者发起
BRPOP命令的先后顺序来决定谁获得元素(尽管实际顺序会受到网络延迟、Redis 事件循环等细微影响,但整体呈现轮询效果)。
轮询过程示例:
假设有三个消费者客户端:C1, C2, C3。它们按顺序执行了 BRPOP myqueue 0 (0 表示无限期阻塞) 命令并处于等待状态。
-
新元素 A 到达 (生产者
LPUSH myqueue A):-
所有阻塞的消费者 (C1, C2, C3) 被唤醒竞争元素 A。
-
按照大致顺序,消费者 C1 成功获取到元素 A 并从
BRPOP命令返回。 -
C1 处理元素 A。如果 C1 想继续消费,它必须重新执行
BRPOP myqueue 0命令以再次进入阻塞等待状态。
-
-
新元素 B 到达 (生产者
LPUSH myqueue B):-
此时阻塞的消费者是 C2, C3 以及刚刚重新执行了
BRPOP的 C1(如果它动作够快)。 -
再次竞争后,消费者 C2 成功获取到元素 B 并从
BRPOP返回。 -
C2 处理元素 B,之后同样需要重新执行
BRPOP才能继续消费。
-
-
新元素 C 到达 (生产者
LPUSH myqueue C):-
阻塞的消费者现在是 C3, C1 (已重新阻塞), C2 (可能刚处理完 B 正在重新阻塞)。
-
按照轮询逻辑,消费者 C3 成功获取到元素 C。
-
C3 处理元素 C,然后重新执行
BRPOP。
-
关键总结:
-
轮询机制:通过消费者在获取元素后必须显式地重新发起
BRPOP命令这一行为,自然地实现了在活跃消费者之间的轮询式负载分发。哪个消费者刚消费完并最快重新进入等待状态,它在下一次元素到达时被选中的概率就更高(结合初始发起顺序)。 -
高并发处理:多个消费者并行阻塞等待和处理,显著提高了系统的吞吐量和响应能力。
-
资源高效:消费者的阻塞等待不消耗 CPU 资源,只在有消息到达时才被唤醒工作。
-
简单可靠:利用 Redis 单命令的原子性和列表的 FIFO(先进先出,LPUSH/BRPOP 组合下是左进右出)特性,构建了一个简单而可靠的消息队列。
2.4.2.分频道的消息队列
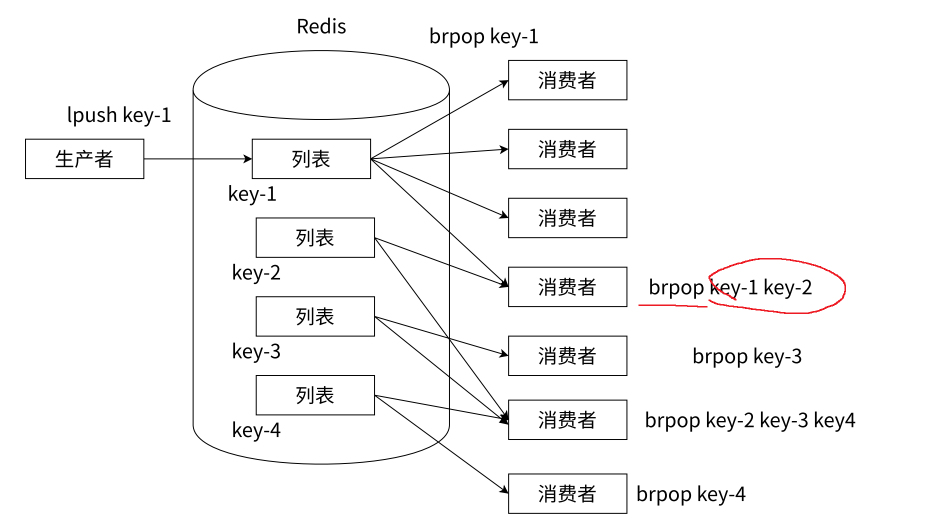
Redis 利用其 列表(List) 数据结构,结合 LPUSH 和 BRPOP 命令,可以构建一个强大的多频道(Channel)或多主题(Topic)消息系统。其核心机制如下:
-
频道即键(Key as Channel):
-
核心思想是将不同的逻辑频道或主题直接映射到不同的 Redis 列表键(Key)上。
-
每个独立的键代表一个独立的通信管道。
-
-
生产者定向推送(Directed Production):
-
生产者根据消息所属的业务类型、主题或频道,使用
LPUSH命令,将消息精确地推送到对应的频道键的头部。
-
-
消费者订阅消费(Subscription Consumption):
-
消费者通过执行
BRPOP命令来监听一个或多个频道键,实现“订阅”。 -
BRPOP key [key ...] timeout:消费者阻塞等待指定的一个或多个键(频道),直到其中任何一个键有新的元素(消息)到达。timeout为 0 表示无限期阻塞等待。 -
当指定的某个键有消息到达时,
BRPOP会返回该键名以及弹出的消息内容。 -
单个消费者可以同时监听多个频道键(
BRPOP chan1 chan2 chan3 0),哪个键先有消息就消费哪个,实现混合订阅。
-
我们举个例子好了
举例
1. 频道定义举例(频道即键)
-
videos:feed:传输短视频推荐流数据。 -
live:danmu:12345:传输特定直播间(房间 ID 为 12345)的弹幕消息。 -
interactions:likes:传输用户点赞事件数据。 -
interactions:comments:传输用户评论数据(或新评论通知)。 -
interactions:shares:传输用户转发/分享事件数据。 -
notifications:system:传输系统广播或全局通知。 -
tasks:image_processing:传输需要后台处理的图片任务。
2. 生产者行为举例(定向推送)
-
一个用户发送了一条弹幕到房间
12345:LPUSH live:danmu:12345 "{"user": "张三", "text": "主播666!", "color": "#FF0000"}" -
用户
李四点赞了视频video_67890:LPUSH interactions:likes "{"user_id": "li_si_uid", "video_id": "video_67890", "timestamp": 1722934567}" -
用户
王五发表了一条评论:LPUSH interactions:comments "{"user_id": "wang_wu_uid", "content": "这个视频太棒了!", "video_id": "video_abc123"}" -
后端系统生成了一个需要处理的图片任务:
LPUSH tasks:image_processing "{"task_id": "img_task_987", "image_url": "https://...", "operation": "thumbnail"}"
3. 消费者行为举例(订阅消费)
-
弹幕处理服务(只关心特定房间的弹幕):
BRPOP live:danmu:12345 0 # 阻塞等待并只消费房间 12345 的弹幕 -
点赞事件处理服务:
BRPOP interactions:likes 0 # 阻塞等待并只消费点赞事件 -
互动事件聚合服务(同时处理点赞、评论、分享):
BRPOP interactions:likes interactions:comments interactions:shares 0 # 阻塞等待,哪个互动频道有事件就先处理哪个(点赞、评论或分享) -
图片处理后台Worker:
BRPOP tasks:image_processing 0 # 阻塞等待并消费图片处理任务 -
通知推送服务(只关心系统通知):
BRPOP notifications:system 0
4. 故障隔离举例
-
场景:
interactions:comments频道的消费者服务因为一个评论内容的解析 Bug 而崩溃重启。 -
隔离效果:
-
interactions:comments队列中的消息会暂时堆积(因为消费者挂了)。 -
但是:
-
弹幕服务(消费
live:danmu:12345)完全不受影响,继续正常收发弹幕。 -
点赞服务(消费
interactions:likes)完全不受影响,继续正常处理点赞。 -
视频流服务(消费
videos:feed)完全不受影响,继续推送视频。 -
图片处理服务(消费
tasks:image_processing)完全不受影响,继续处理任务。 -
系统通知服务(消费
notifications:system)完全不受影响。
-
-
-
恢复: 当评论服务的 Bug 被修复并重新启动后,它会继续从
interactions:comments队列中消费堆积的消息,其他服务在整个过程中毫不知情且未受影响。
这种基于不同 Redis 键实现多频道的模式,其核心优势在于提供了强大的解耦与隔离能力:
-
逻辑解耦 (Decoupling):
-
不同的业务数据类型(如视频流、弹幕、点赞、评论、分享)被清晰地划分到独立的处理管道(频道键)中。
-
生产者和消费者只需关注自身负责的频道键,无需了解其他频道的数据格式、处理逻辑或存在状态。降低了系统复杂度。
-
-
故障隔离 (Fault Isolation) - 关键优势:
-
这是多频道设计最重要的价值之一。某个频道的故障(如数据处理异常、消息积压、消费者服务崩溃)会被严格限制在该频道自身及其相关的消费者上。
-
其他频道(键)的生产、消费、以及关联的服务完全不受影响,能继续正常运作。例如,弹幕处理服务宕机不会阻塞视频流推送或点赞通知的处理。
-
极大地提升了整个系统的鲁棒性(Robustness)和可用性。
-
-
资源隔离与扩展性 (Resource Isolation & Scalability):
-
不同频道的消息通常具有不同的特性(吞吐量、处理时延要求、重要性)。
-
独立的频道键使得可以:
-
按需扩展: 为高吞吐量频道(如弹幕)部署更多的消费者实例。
-
优先级管理: 为低延迟要求高的频道(如实时点赞通知)分配更高优先级的计算资源(更快的消费者、更好的服务器)。
-
独立监控: 单独监控每个频道队列的长度(LLEN)、生产速率(监控 LPUSH)、消费速率(监控 BRPOP)等关键指标,便于发现瓶颈和优化。
-
-
-
关注点分离 (Separation of Concerns):
-
开发、测试、运维和调试变得更加清晰。不同的团队或模块可以专注于特定频道的数据流和处理逻辑。
-
系统架构更易于理解和维护。
-
2.4.3.微博 Timeline
每个用户都有属于自己的 Timeline(微博列表),现需要分页展示文章列表。
此时可以考虑使用列表,因为列表不但是有序的,同时支持按照索引范围获取元素。
为了给用户提供分页展示的微博列表(Timeline),我们采用 Redis 的 列表(List) 数据结构作为核心存储方案。列表的有序特性(按插入时间逆序)天然支持按时间线展示微博,并且其 LRANGE 命令能高效地按索引范围获取元素,非常适合分页需求。
具体实现方案如下:
1.单条微博存储:
-
每条微博使用一个 Redis 哈希(Hash) 存储其核心属性(如
title,timestamp,content)。 -
示例命令:
HMSET mblog:1 title "xx" timestamp 1476536196 content "xxxxx" HMSET mblog:n title "xx" timestamp 1476536196 content "xxxxx"
2.用户 Timeline 构建:
-
为每个用户创建一个专属列表,键名格式为
user:<uid>:mblogs。 -
当用户发布新微博或微博被加入其 Timeline(例如,关注的人发微博)时,使用
LPUSH命令将对应的微博哈希键(如mblog:1) 插入到列表的头部。这保证了最新的微博总是位于列表最前面。 -
示例命令:
LPUSH user:1:mblogs mblog:1 mblog:3 LPUSH user:k:mblogs mblog:9
3.分页获取 Timeline:
获取用户(例如用户ID 1)第 1 页(前 10 条)微博的基本流程:
-
使用
LRANGE获取列表指定索引范围内的微博键名:LRANGE user:1:mblogs 0 9 # 获取索引 0 到 9 的元素 (共10条) -
遍历返回的键名列表 (
keylist),对每个键执行HGETALL来获取该微博的完整详细信息:for key in keylist {HGETALL key }
该方案潜在的问题与优化考虑:
1 + N 查询问题 (性能瓶颈):
-
问题描述: 当前的分页获取流程存在显著性能问题。第一步
LRANGE获取N个微博键名只需要1次 Redis 请求。然而,第二步需要为这N个键中的每一个单独发起一次HGETALL请求,总共产生N次请求。当N(即每页显示的微博数量)较大时,会产生大量的网络往返(Round-Trip Time, RTT)和 Redis 服务器处理开销,严重影响响应速度和系统吞吐量。 -
优化方案:
-
使用 Pipeline(流水线): 将第二步中对
N个键的HGETALL命令放入一个 Pipeline 中一次性发送给 Redis 服务器。Redis 会按顺序执行所有命令,但只将最终结果一次性返回给客户端。这将N次网络往返和请求/响应开销减少到接近1次,是解决此问题的首选高效方法。 -
使用序列化字符串 + MGET: 另一种思路是改变单条微博的存储方式。不再使用 Hash,而是将整个微博对象序列化(如 JSON, MessagePack)后作为一个字符串值存储(例如
SET mblog:1 "{serialized_data}")。在分页获取时,第一步LRANGE拿到N个键名后,第二步改用MGET命令一次性获取这N个键对应的序列化字符串值。客户端收到后再反序列化。这同样只需要2次请求(LRANGE+MGET)。优点: 请求次数少。缺点: 失去了 Hash 结构的部分优势(如单独更新某个字段不方便,需反序列化整个对象),序列化/反序列化增加客户端 CPU 开销。选择哪种方式需权衡业务需求(更新频率、读取模式)和性能要求。
-
长列表中间元素访问效率问题:
-
问题描述: Redis 的 List 底层实现是链表(LinkedList)。
LRANGE命令在访问列表两端(头部或尾部附近) 的元素时效率很高(时间复杂度 O(n),n 是获取的元素个数)。然而,当需要获取列表中间位置的元素时(例如,用户跳转到第 1000 页),LRANGE需要从链表头部开始遍历,直到找到目标索引的起点,时间复杂度为 O(n),n 是起始索引的位置。对于一个非常大的列表(例如,存储了数万条微博),获取中间页的数据会变得很慢。 -
优化方案:
-
列表分片(Sharding): 将单个超长的用户 Timeline 列表拆分成多个较小的子列表(Shards)。例如,可以为每个用户维护多个列表键:
user:1:mblogs:0,user:1:mblogs:1, ...,user:1:mblogs:k。每个子列表存储一定数量(如 1000 条)的微博键。优点: 将一个大列表的 O(n) 访问复杂度分散到多个小列表上,每个小列表的LRANGE操作都很快(因为 n 变小了)。关键点: 需要额外维护元信息(如一个小的 Hash 或 ZSET)来记录当前有哪些分片以及每个分片的大致时间范围或索引范围,以便在分页时快速定位目标数据在哪一个或哪几个分片中。这增加了实现的复杂度,但能有效解决超长列表的中间访问瓶颈。
-
补充说明:
-
Pipeline 的必要性: 在未使用 Pipeline 或
MGET的原始方案中,“for key in keylist { hgetall key }” 循环确实会为每一页数据(假设每页 N 条)触发 N 次单独的 Redis 请求。对于高并发场景或大分页(N 较大),这会造成严重的性能问题和 Redis 连接压力。强烈建议在生产环境中使用 Pipeline 或MGET(如果采用序列化存储)来优化。 -
分片策略: 列表分片主要针对的是历史数据访问(用户浏览很靠后的页)的性能优化。对于最新的几页数据(通常是最常访问的),即使列表很长,访问头部(
LRANGE 0 9)依然是高效的。因此,分片策略需要根据实际的用户访问模式(通常是长尾分布,最新数据访问频繁)来设计分片大小和粒度。
选择列表类型时,请参考:
- 同侧存取(lpush + lpop 或者 rpush + rpop)为栈
- 异侧存取(lpush + rpop 或者 rpush + lpop)为队列