力扣top100--哈希
目录
1、两数之和【简单】
2、字母异位词分组【中等】
3、最长连续序列【中等】
1、两数之和【简单】
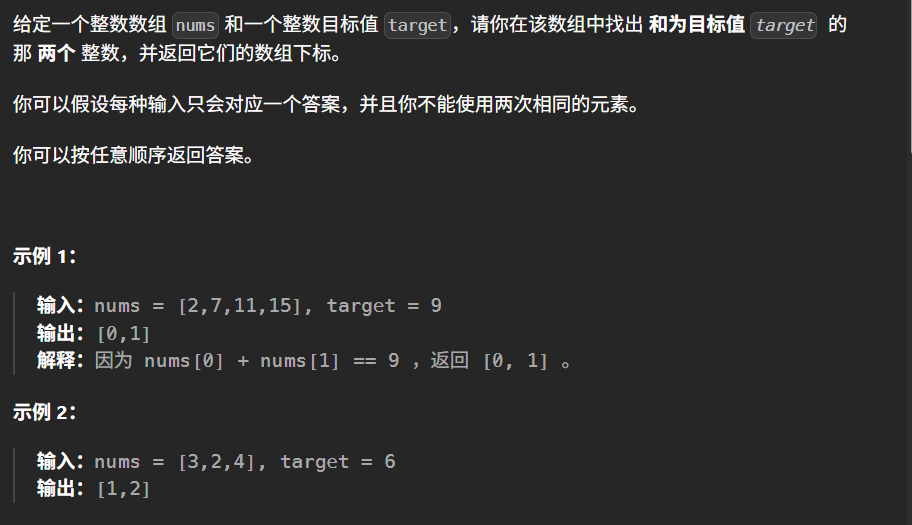
class Solution {
public:vector<int> twoSum(vector<int>& nums, int target) {// 使用unordered_map效率更高,不需要排序unordered_map<int, int> need;for(int i = 0; i < nums.size(); i++) {int complement = target - nums[i];// 查找是否存在需要的补数if(need.find(complement) != need.end()) {// 先返回已存储的索引,再返回当前索引return {need[complement], i};}// 存储当前值和它的索引,供后续查找need[nums[i]] = i;}return {};}
};
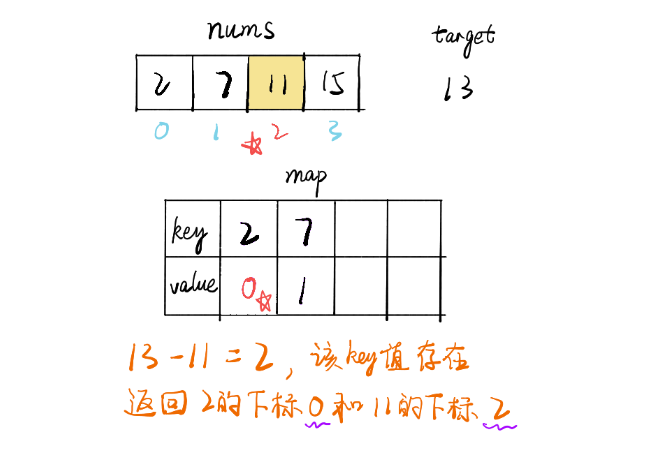
在map中查找target- 当前这个数,找到了就返回
2、字母异位词分组【中等】
字母异位词是通过重新排列不同单词或短语的字母而形成的单词或短语,并使用所有原字母一次

class Solution {
public:vector<vector<string>> groupAnagrams(vector<string>& strs) {unordered_map<string,vector<string>> mp;//存储哈希vector<vector<string>> res;//返回结果for(int i=0;i<strs.size();i++){//分离出 strs[i]string key=strs[i];sort(key.begin(),key.end());mp[key].emplace_back(strs[i]);}for(auto it=mp.begin();it!=mp.end();it++){res.emplace_back(it->second);}return res;}
};找到key,然后把排序后和key一样的string添加到key后面【排序很重要】
3、最长连续序列【中等】
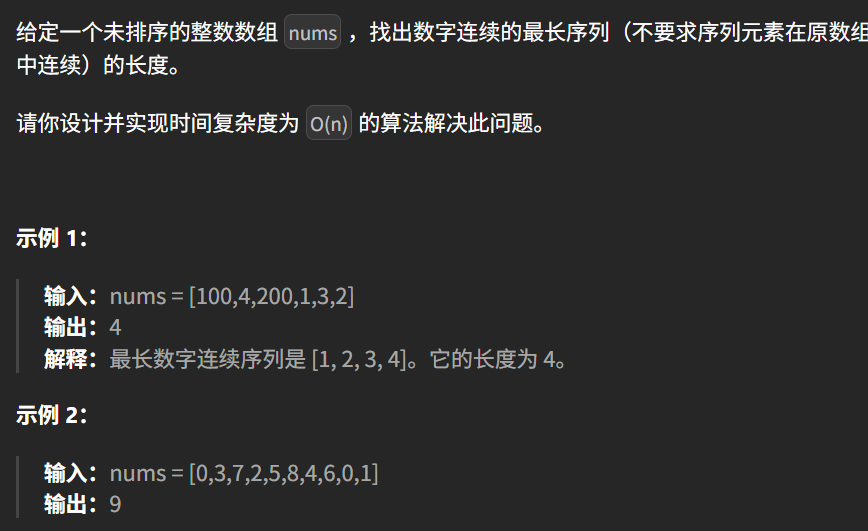
class Solution {
public:int longestConsecutive(vector<int>& nums) {//存储到哈希表[去重]unordered_set<int> st;int res=0;for(int i=0;i<nums.size();i++) st.insert(nums[i]);for(auto it :st){if(!st.count(it-1))//找到了前一个数{int cur=it;//当前的开头数字int cur_res=1;//当前的最长while(st.count(cur+1)) //只要有下一个比他大1的数字{cur++;cur_res++;}res=max(res,cur_res);}}return res;}
};简单来说就是每个数都判断一次这个数是不是连续序列的开头那个数。
- 怎么判断呢,就是用哈希表查找这个数前面一个数是否存在,即num-1在序列中是否存在。存在那这个数肯定不是开头,直接跳过。
- 因此只需要对每个开头的数进行循环,直到这个序列不再连续,因此复杂度是O(n)。
以题解中的序列举例:
[100,4,200,1,3,4,2]
去重后的哈希序列为:
[100,4,200,1,3,2]
按照上面逻辑进行判断:
- 元素100是开头,因为没有99,且以100开头的序列长度为1
- 元素4不是开头,因为有3存在,过,
- 元素200是开头,因为没有199,且以200开头的序列长度为1
- 元素1是开头,因为没有0,且以1开头的序列长度为4,因为依次累加,2,3,4都存在。
- 元素3不是开头,因为2存在,过,
- 元素2不是开头,因为1存在,过。
完