Hadoop HDFS 3.3.4 讲解~


✨博客主页: https://blog.csdn.net/m0_63815035?type=blog
💗《博客内容》:.NET、Java.测试开发、Python、Android、Go、Node、Android前端小程序等相关领域知识
📢博客专栏: https://blog.csdn.net/m0_63815035/category_11954877.html
📢欢迎点赞 👍 收藏 ⭐留言 📝
📢本文为学习笔记资料,如有侵权,请联系我删除,疏漏之处还请指正🙉
📢大厦之成,非一木之材也;大海之阔,非一流之归也✨


前言
Hadoop是一个开源的分布式计算框架,主要用于处理和存储大规模数据集。它的设计初衷是解决海量数据的存储和计算问题,具有高容错性、高扩展性和低成本等特点。下面详细讲解Hadoop的核心知识点:
分而治之
所谓“分而治之”,就是把一个复杂的算法问题按一定的“分解”方法分为等价的规模较小的若干部分,然后逐个分别找出各部分的解,再把各部分的解组成整个问题的解。这种朴素的思想来源于人们生活与工作的实践经验,如下图。

以下图做讲解:
1. Hadoop的核心组件
-
HDFS(Hadoop Distributed File System):分布式文件系统,用于存储海量数据
- 采用主从架构(NameNode和DataNode)
- 将文件分割成固定大小的块(默认128MB)进行存储
- 每个块会在多个DataNode上备份(默认3份),保证数据可靠性
- NameNode管理文件系统的元数据,DataNode负责实际数据存储
-
MapReduce:分布式计算框架,用于处理大规模数据
- 基于"分而治之"思想,将计算任务分为Map和Reduce两个阶段
- Map阶段:将输入数据分割成多个片段,并行处理
- Reduce阶段:汇总Map阶段的结果,得到最终输出
- 自动处理任务分发、容错、数据本地化等问题
-
YARN(Yet Another Resource Negotiator):资源管理和任务调度框架
- 负责集群资源(CPU、内存等)的管理和分配
- 主从架构:ResourceManager(主节点)和NodeManager(从节点)
- 支持多种计算框架(MapReduce、Spark等)共享集群资源
2. Hadoop的架构特点
- 主从架构:大部分组件采用主从架构设计,便于集中管理和分布式执行
- 高容错性:通过数据备份和节点故障自动转移实现
- 高扩展性:可以通过增加节点轻松扩展集群规模
- 数据本地化:计算任务尽可能在数据所在节点执行,减少网络传输
- 开源免费:基于Apache协议开源,降低企业使用成本
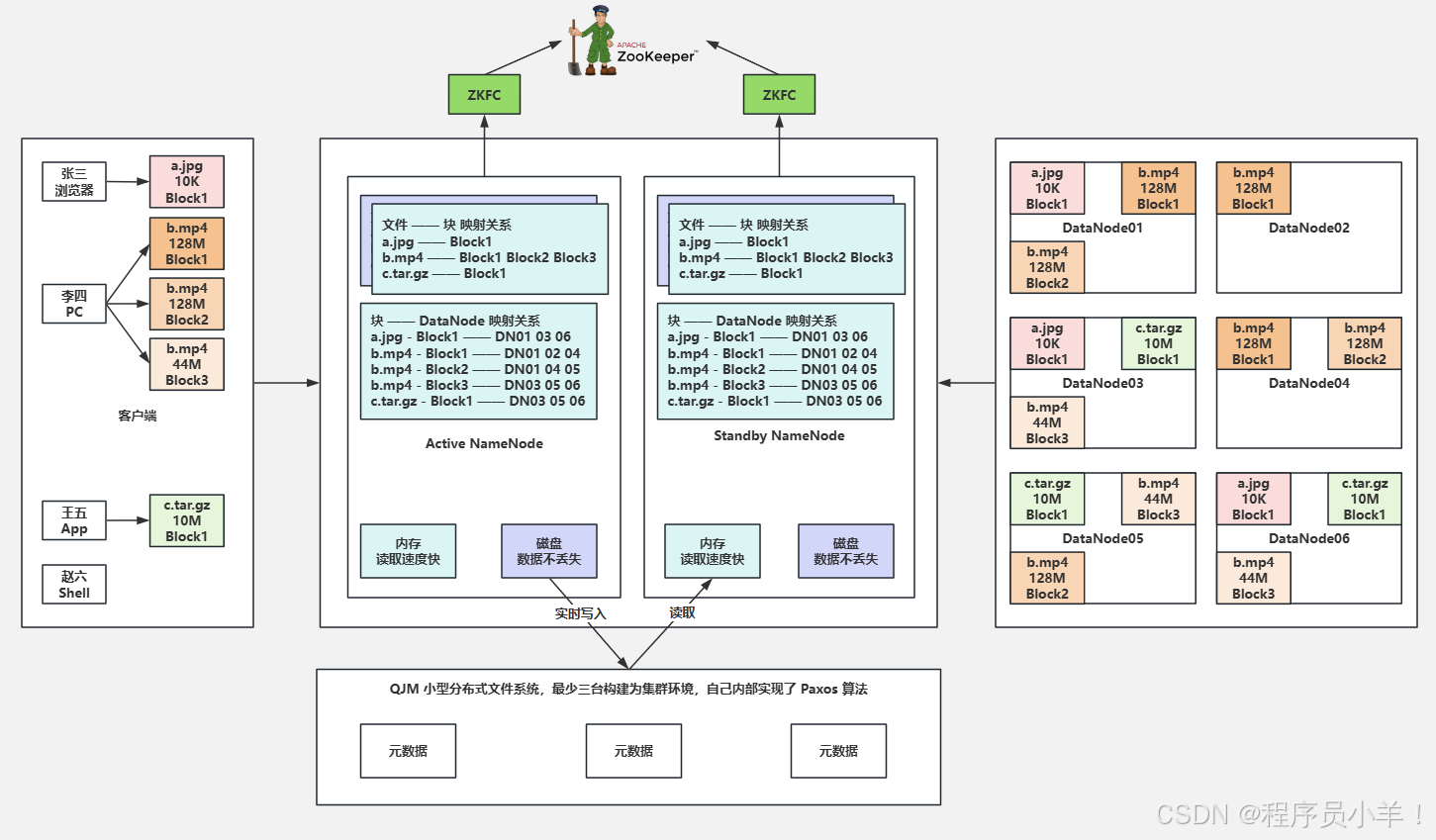
3. HDFS的工作原理
-
读写流程:
- 写文件:客户端将文件分块,与NameNode交互获取存储位置,然后直接向DataNode写入数据
- 读文件:客户端从NameNode获取文件块的存储位置,然后直接从DataNode读取数据
-
NameNode与DataNode的协作:
- NameNode维护文件系统的目录结构、文件与块的映射关系
- DataNode定期向NameNode发送心跳信息和块报告
- 当DataNode故障时,NameNode会安排其他节点复制数据块
-
安全模式:HDFS启动时的一种特殊状态,此时只允许读操作,不允许写操作,用于检查数据块的完整性
4. MapReduce的工作原理
-
执行流程:
- InputFormat:将输入数据分割成InputSplit
- Map阶段:对每个InputSplit执行map函数,产生中间键值对
- Shuffle阶段:对map输出进行排序、分组等处理
- Reduce阶段:对shuffle后的结果执行reduce函数,产生最终输出
- OutputFormat:将reduce输出写入到指定位置
-
Shuffle机制:MapReduce的核心,负责在Map和Reduce之间传输和处理数据,包括分区、排序、合并等操作
5. YARN的工作原理
-
核心组件:
- ResourceManager:全局资源管理器,负责资源分配和调度
- NodeManager:每个节点上的资源管理器,负责本节点的资源管理
- ApplicationMaster:每个应用程序的管理者,负责与ResourceManager协商资源并管理任务执行
- Container:资源分配的基本单位,包含CPU、内存等资源
-
作业提交与执行流程:
- 客户端提交应用程序到ResourceManager
- ResourceManager分配第一个Container启动ApplicationMaster
- ApplicationMaster向ResourceManager申请资源
- ApplicationMaster在分配的Container上启动任务
- 任务执行并向ApplicationMaster汇报进度
- 所有任务完成后,ApplicationMaster向ResourceManager注销并关闭
6. Hadoop的生态系统
Hadoop生态系统包含多个相关项目,共同构成了大数据处理的完整解决方案:
- Hive:数据仓库工具,提供类SQL查询语言(HQL)
- Pig:数据流处理工具,提供类SQL的脚本语言(Pig Latin)
- HBase:分布式NoSQL数据库,适合存储非结构化和半结构化数据
- ZooKeeper:分布式协调服务,用于管理集群配置、命名服务等
- Flume:日志收集工具,用于高效收集、聚合和传输大量日志数据
- Sqoop:数据传输工具,用于在Hadoop与关系型数据库之间传输数据
- Spark:快速通用的计算引擎,可替代MapReduce进行数据处理
7. Hadoop的应用场景
- 日志分析:处理海量日志数据,提取有价值信息
- 数据仓库:构建大规模数据仓库,支持数据分析和决策
- 搜索引擎:存储和处理网页数据,支持全文检索
- 机器学习:处理大规模训练数据,训练机器学习模型
- 科学计算:处理科学研究中的海量数据
今天这篇文章就到这里了,大厦之成,非一木之材也;大海之阔,非一流之归也。感谢大家观看本文
