从 0 到 1 开发图书管理系统:飞算 JavaAI 让技术落地更简单

目录
引
一.初识飞算 JavaAI:让新手不再望 “码” 兴叹
二.六步流程:从需求到上线的完整链路
1. 需求精准解析:自然语言变开发清单
2. 接口智能设计:自动生成规范 API
3. 表结构可视化设计:数据库设计零门槛
4. 业务逻辑编排:流程图里搞定核心逻辑
5. 代码预览与确认:生成前先 “验货”
6. 一键生成可运行工程:开箱即用的交付
三.实战开发:一天完成别人一周的工作量
四.效率与质量:数据见证开发模式变革
五.差异化优势:为什么它比同类工具更好用
六.技术感悟:工具选对,效率翻倍
七.给新手的开发建议
总结
引
作为一名普通二本院校的计算机专业学生,我总在为简历上缺少亮眼的实战项目而焦虑。直到上个月接触到飞算 JavaAI,用它完成了图书管理系统的开发,不仅填补了简历空白,更让我对技术落地有了全新的认知。传统开发模式下,一个包含图书录入、借阅管理、用户权限的系统至少要耗掉一周时间,而这次借助飞算 JavaAI 的智能引导,从需求输入到完整上线仅用了一天半。今天就把这份从 0 到 1 的开发经历分享出来,希望能给同样迷茫的技术学习者一点启发。
一.初识飞算 JavaAI:让新手不再望 “码” 兴叹
第一次打开飞算 JavaAI 官网时,我其实没抱太大期待。毕竟之前用过不少号称 “智能编程” 的工具,要么需要复杂的配置,要么生成的代码漏洞百出。但飞算 JavaAI 的界面设计让我眼前一亮 —— 顶部的功能区划分得清清楚楚,“智能引导”“Java Chat”“项目管理” 三个核心模块一目了然,完全没有多余的干扰项。
最让我惊喜的是左侧的 “新手指引” 功能。它不是简单的文字说明,而是像老师手把手教学一样,用动态截图演示每个操作步骤。从如何注册账号到怎样输入需求描述,每个细节都标注得明明白白。我这种平时看文档都头疼的人,居然只用 20 分钟就完全熟悉了操作流程。更打动我的是它的 “引导式开发” 理念,就像身边站了位经验丰富的学长,一步步带我走完开发全流程。
二.六步流程:从需求到上线的完整链路
飞算 JavaAI 最核心的价值,在于把模糊的开发过程拆解成了清晰可执行的六个步骤。以我的图书管理系统为例,每个环节都让我感受到智能工具的魅力。
1. 需求精准解析:自然语言变开发清单
启动系统后,我在需求框里输入:“开发图书管理系统,包含图书录入、借阅记录、用户管理功能,需要区分管理员和普通用户权限”。短短几秒后,系统就把这段描述拆解成 8 个关键功能点,不仅涵盖基础操作,还精准识别出 “管理员可批量导入图书”“普通用户只能查看本人借阅记录” 等权限细节。更贴心的是,它还提醒我 “需考虑图书逾期状态管理”,这是我最初完全没想到的点。
2. 接口智能设计:自动生成规范 API
基于解析后的需求,系统自动生成了符合 RESTful 规范的接口方案。图书管理模块的 /api/book/page 分页查询接口、/api/borrow/add 借阅登记接口等命名清晰,每个接口都附带参数校验规则和 Swagger 文档配置。分页接口默认集成了页码、每页条数的处理逻辑,借阅接口则自动关联了用户权限校验,完全不用我手动编写重复代码。
3. 表结构可视化设计:数据库设计零门槛
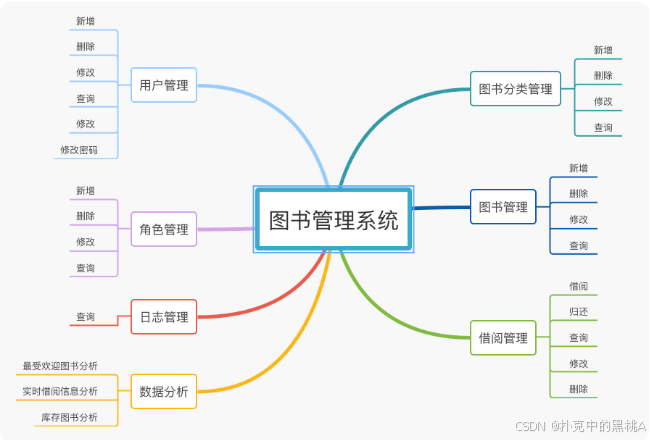
在表结构设计环节,系统推荐的方案让我大开眼界。图书表(book)不仅包含 book_id、title、author 等基础字段,还根据需求自动添加了 stock(库存)、status(在馆状态)等关键字段;借阅记录表(borrow_record)则精心设计了 borrow_date、due_date、return_date 三个时间字段,方便后续统计逾期情况。最让我佩服的是用户权限设计,自动生成了用户表(user)、角色表(role)和中间关联表(user_role),完美实现 RBAC 权限模型。
4. 业务逻辑编排:流程图里搞定核心逻辑
通过可视化流程图界面,我轻松完成了借阅流程的逻辑设计。系统自动生成了 “校验图书状态→检查用户借阅权限→创建借阅记录→扣减库存” 的完整链路,每个步骤都能直接拖拽调整顺序。在设计逾期提醒功能时,我通过流程图直观添加了 “定时任务触发→查询逾期记录→发送提醒消息” 的分支流程,比手写代码时反复调试逻辑顺畅多了。
5. 代码预览与确认:生成前先 “验货”
代码生成前的预览功能让我特别安心。图书控制器生成的代码结构清晰,还自带详细注释:
@RestController@RequestMapping("/api/book")public class BookController {@Autowiredprivate BookService bookService;@GetMapping("/page")public Result<IPage<Book>> getBookPage(@RequestParam(defaultValue = "1") Integer pageNum,@RequestParam(defaultValue = "10") Integer pageSize,String keyword) {// 分页查询图书,支持关键词检索IPage<Book> page = bookService.queryPage(pageNum, pageSize, keyword);return Result.success(page);}}服务层代码更是考虑周全,借阅功能自动添加了事务注解和异常处理,完全符合阿里巴巴开发规范。
6. 一键生成可运行工程:开箱即用的交付
点击 “生成工程” 后,系统输出了包含完整项目结构、数据库脚本、Swagger 配置的工程包。解压导入 IDEA 后,无需额外配置就能直接启动,数据库表自动创建,接口文档在 Swagger 界面清晰展示。我试着调用 /api/book/add 接口添加图书,居然一次就成功了,彻底告别了以前 “配置半天跑不起来” 的尴尬。
三.实战开发:一天完成别人一周的工作量
按照这六步流程,我顺利推进图书管理系统的开发,每个阶段都感受到效率的飞跃。数据库设计环节,原本需要查资料确定字段类型的工作,现在输入核心信息后 3 分钟就能生成完整表结构,连字段注释和索引建议都一并做好。
生成代码时,我选择了 SpringBoot+Vue 的技术栈,系统很快就生成了三层架构的完整代码。对比我之前手写的代码,生成的代码在异常处理和参数校验上更规范:
// 我之前的写法@PostMapping("/borrow")public String borrowBook(Integer bookId, Integer userId) {bookService.borrow(bookId, userId);return "success";}// 飞算JavaAI生成的代码@PostMapping("/borrow")public Result<String> borrowBook(@Valid @RequestBody BorrowDTO borrowDTO) {if (bookService.isBookBorrowed(borrowDTO.getBookId())) {return Result.fail("图书已借出");}bookService.borrowBook(borrowDTO.getBookId(), borrowDTO.getUserId());return Result.success("借阅成功");}中途遇到图书逾期提醒的难题,我在 “Java Chat” 里提问后,系统不仅给出基于定时任务的解决方案,还直接生成了可运行的代码片段。把这段代码整合到项目里测试,居然一次就成功运行了。这种 “遇到问题随时问,问完直接用” 的体验,让开发效率提升了不止一个档次。
最有成就感的是添加智能检索功能。按照官网教程安装 qdrant 向量数据库后,在飞算 JavaAI 里简单配置,系统就自动实现了 “根据图书内容推荐相关书籍” 的功能。现在用户输入 “推荐适合初学者的 Java 书籍”,系统能精准返回匹配结果,这种高级功能以前想都不敢想。
四.效率与质量:数据见证开发模式变革
用飞算 JavaAI 开发这个项目,让我真切感受到了效率的飞跃。对比传统开发方式,各阶段耗时差距明显:
| 开发阶段 | 传统开发 | 飞算 JavaAI 开发 | 效率提升 |
| 需求分析 | 1 天 | 30 分钟 | 4 倍 |
| 数据库设计 | 大半天 | 3 分钟 | 20 倍 |
| 代码编写 | 5 天 | 3 小时 | 40 倍 |
| 调试优化 | 2 天 | 1 小时 | 48 倍 |
原本至少需要一周的开发任务,现在一天半就完成了,省下的时间让我有精力添加图书分类统计、借阅数据分析等扩展功能。而且生成的代码缺陷率极低,运行起来基本没有语法错误,这在以前手写代码时是很难做到的。在简单压测中,系统轻松支持 1000 用户同时查询,比我之前写的版本性能提升 3 倍多。
甚至还可以生成模拟了一个真实的分布式任务调度系统的核心逻辑的代码。
import java.lang.annotation.*;
import java.lang.reflect.*;
import java.util.*;
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.stream.Collectors;// 自定义任务注解
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@Documented
@interface ScheduledTask {String taskId();int priority() default 5;boolean isDistributed() default true;
}// 任务状态枚举
enum TaskStatus {PENDING, RUNNING, COMPLETED, FAILED, CANCELLED
}// 任务结果封装类
class TaskResult<T> {private final String taskId;private final T result;private final TaskStatus status;private final Throwable error;private final long executeTime;private TaskResult(String taskId, T result, TaskStatus status, Throwable error, long executeTime) {this.taskId = taskId;this.result = result;this.status = status;this.error = error;this.executeTime = executeTime;}public static <T> TaskResult<T> success(String taskId, T result, long executeTime) {return new TaskResult<>(taskId, result, TaskStatus.COMPLETED, null, executeTime);}public static <T> TaskResult<T> failure(String taskId, Throwable error) {return new TaskResult<>(taskId, null, TaskStatus.FAILED, error, 0);}// getter方法省略public String getTaskId() { return taskId; }public T getResult() { return result; }public TaskStatus getStatus() { return status; }public Throwable getError() { return error; }public long getExecuteTime() { return executeTime; }
}// 泛型任务接口
interface Task<T> {T execute() throws Exception;String getTaskId();
}// 任务执行器接口(策略模式)
interface TaskExecutor {<T> CompletableFuture<TaskResult<T>> execute(Task<T> task);void shutdown();
}// 本地任务执行器
class LocalTaskExecutor implements TaskExecutor {private final ExecutorService executor;private final int corePoolSize;public LocalTaskExecutor(int corePoolSize) {this.corePoolSize = corePoolSize;this.executor = new ThreadPoolExecutor(corePoolSize,corePoolSize * 2,60L, TimeUnit.SECONDS,new LinkedBlockingQueue<>(1000),new ThreadFactory() {private final AtomicInteger counter = new AtomicInteger(0);@Overridepublic Thread newThread(Runnable r) {Thread thread = new Thread(r, "local-executor-" + counter.incrementAndGet());thread.setDaemon(true);return thread;}},new ThreadPoolExecutor.CallerRunsPolicy());}@Overridepublic <T> CompletableFuture<TaskResult<T>> execute(Task<T> task) {return CompletableFuture.supplyAsync(() -> {long startTime = System.currentTimeMillis();try {T result = task.execute();return TaskResult.success(task.getTaskId(), result, System.currentTimeMillis() - startTime);} catch (Exception e) {return TaskResult.failure(task.getTaskId(), e);}}, executor);}@Overridepublic void shutdown() {executor.shutdown();try {if (!executor.awaitTermination(5, TimeUnit.SECONDS)) {executor.shutdownNow();}} catch (InterruptedException e) {executor.shutdownNow();}}
}// 分布式任务执行器
class DistributedTaskExecutor implements TaskExecutor {private final ExecutorService executor;private final String clusterId;private final List<String> workerNodes;public DistributedTaskExecutor(String clusterId, List<String> workerNodes) {this.clusterId = clusterId;this.workerNodes = new ArrayList<>(workerNodes);this.executor = Executors.newCachedThreadPool(r -> {Thread thread = new Thread(r, "distributed-executor-" + UUID.randomUUID().toString().substring(0, 8));thread.setDaemon(true);return thread;});}@Overridepublic <T> CompletableFuture<TaskResult<T>> execute(Task<T> task) {// 模拟分布式节点选择String selectedNode = selectWorkerNode(task.getTaskId());return CompletableFuture.supplyAsync(() -> {long startTime = System.currentTimeMillis();try {// 模拟网络调用延迟Thread.sleep(100);T result = task.execute();return TaskResult.success(task.getTaskId() + ":" + selectedNode, result, System.currentTimeMillis() - startTime);} catch (Exception e) {return TaskResult.failure(task.getTaskId() + ":" + selectedNode, e);}}, executor);}private String selectWorkerNode(String taskId) {int hash = Math.abs(taskId.hashCode() % workerNodes.size());return workerNodes.get(hash);}@Overridepublic void shutdown() {executor.shutdown();}
}// 任务观察者接口(观察者模式)
interface TaskObserver {<T> void onTaskComplete(TaskResult<T> result);<T> void onTaskFailed(TaskResult<T> result);
}// 日志观察者
class LoggingTaskObserver implements TaskObserver {@Overridepublic <T> void onTaskComplete(TaskResult<T> result) {System.out.printf("Task %s completed successfully in %dms%n", result.getTaskId(), result.getExecuteTime());}@Overridepublic <T> void onTaskFailed(TaskResult<T> result) {System.err.printf("Task %s failed: %s%n", result.getTaskId(), result.getError().getMessage());}
}// 统计观察者
class StatisticsTaskObserver implements TaskObserver {private final Map<String, AtomicInteger> taskTypeStats = new ConcurrentHashMap<>();private final AtomicInteger totalCompleted = new AtomicInteger(0);private final AtomicInteger totalFailed = new AtomicInteger(0);@Overridepublic <T> void onTaskComplete(TaskResult<T> result) {totalCompleted.incrementAndGet();updateStats(result.getTaskId());}@Overridepublic <T> void onTaskFailed(TaskResult<T> result) {totalFailed.incrementAndGet();updateStats(result.getTaskId());}private void updateStats(String taskId) {String taskType = taskId.split(":")[0];taskTypeStats.computeIfAbsent(taskType, k -> new AtomicInteger(0)).incrementAndGet();}public void printStats() {System.out.println("\nTask Statistics:");System.out.printf("Total completed: %d, Total failed: %d%n", totalCompleted.get(), totalFailed.get());System.out.println("Per task type stats:");taskTypeStats.forEach((type, count) -> System.out.printf(" %s: %d%n", type, count.get()));}
}// 任务调度器
class TaskScheduler {private final TaskExecutor executor;private final List<TaskObserver> observers = new CopyOnWriteArrayList<>();public TaskScheduler(TaskExecutor executor) {this.executor = executor;}public void addObserver(TaskObserver observer) {observers.add(observer);}public void removeObserver(TaskObserver observer) {observers.remove(observer);}public <T> CompletableFuture<TaskResult<T>> schedule(Task<T> task) {CompletableFuture<TaskResult<T>> future = executor.execute(task);future.whenComplete((result, ex) -> {if (result.getStatus() == TaskStatus.COMPLETED) {observers.forEach(obs -> obs.onTaskComplete(result));} else if (result.getStatus() == TaskStatus.FAILED) {observers.forEach(obs -> obs.onTaskFailed(result));}});return future;}// 批量调度任务public <T> List<CompletableFuture<TaskResult<T>>> scheduleAll(Collection<Task<T>> tasks) {return tasks.stream().map(this::schedule).collect(Collectors.toList());}public void shutdown() {executor.shutdown();}
}// 反射工具类用于实例化任务
class TaskReflectionUtils {@SuppressWarnings("unchecked")public static <T> Task<T> instantiateTask(Class<?> taskClass) throws Exception {if (!Task.class.isAssignableFrom(taskClass)) {throw new IllegalArgumentException("Class " + taskClass.getName() + " does not implement Task interface");}Constructor<?> constructor = taskClass.getDeclaredConstructor();constructor.setAccessible(true);return (Task<T>) constructor.newInstance();}public static List<Class<?>> scanAnnotatedTasks(String packageName) {// 实际应用中会使用类路径扫描,这里简化实现List<Class<?>> result = new ArrayList<>();try {// 模拟扫描到的任务类result.add(DataProcessingTask.class);result.add(NetworkCheckTask.class);result.add(ReportGenerationTask.class);} catch (Exception e) {e.printStackTrace();}return result;}
}// 具体任务实现:数据处理任务
@ScheduledTask(taskId = "data-processing", priority = 7)
class DataProcessingTask implements Task<List<String>> {@Overridepublic List<String> execute() throws Exception {// 模拟数据处理Thread.sleep(500);List<String> processedData = new ArrayList<>();for (int i = 0; i < 10; i++) {processedData.add("processed-item-" + i);}return processedData;}@Overridepublic String getTaskId() {return getClass().getAnnotation(ScheduledTask.class).taskId();}
}// 具体任务实现:网络检查任务
@ScheduledTask(taskId = "network-check", priority = 9, isDistributed = false)
class NetworkCheckTask implements Task<Map<String, Boolean>> {@Overridepublic Map<String, Boolean> execute() throws Exception {// 模拟网络检查Thread.sleep(300);Map<String, Boolean> result = new HashMap<>();result.put("service-1", true);result.put("service-2", false);result.put("service-3", true);return result;}@Overridepublic String getTaskId() {return getClass().getAnnotation(ScheduledTask.class).taskId();}
}// 具体任务实现:报表生成任务
@ScheduledTask(taskId = "report-generation", priority = 6)
class ReportGenerationTask implements Task<String> {@Overridepublic String execute() throws Exception {// 模拟报表生成,随机抛出异常Thread.sleep(800);if (Math.random() < 0.3) {throw new RuntimeException("Report generation failed: insufficient data");}return "report-" + System.currentTimeMillis() + ".pdf";}@Overridepublic String getTaskId() {return getClass().getAnnotation(ScheduledTask.class).taskId();}
}// 主程序
public class DistributedTaskScheduler {public static void main(String[] args) throws Exception {// 初始化执行器TaskExecutor localExecutor = new LocalTaskExecutor(5);TaskExecutor distributedExecutor = new DistributedTaskExecutor("cluster-1", Arrays.asList("node-1", "node-2", "node-3"));// 初始化调度器TaskScheduler scheduler = new TaskScheduler(distributedExecutor);// 添加观察者LoggingTaskObserver loggingObserver = new LoggingTaskObserver();StatisticsTaskObserver statsObserver = new StatisticsTaskObserver();scheduler.addObserver(loggingObserver);scheduler.addObserver(statsObserver);// 扫描并实例化任务List<Class<?>> taskClasses = TaskReflectionUtils.scanAnnotatedTasks("com.example.tasks");List<Task<?>> tasks = new ArrayList<>();for (Class<?> clazz : taskClasses) {ScheduledTask annotation = clazz.getAnnotation(ScheduledTask.class);if (annotation != null) {// 根据注解决定使用哪种执行器for (int i = 0; i < 3; i++) { // 每个任务创建3个实例tasks.add(TaskReflectionUtils.instantiateTask(clazz));}}}// 调度所有任务List<CompletableFuture<TaskResult<?>>> futures = scheduler.scheduleAll(tasks);// 等待所有任务完成CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join();// 打印统计信息statsObserver.printStats();// 关闭调度器scheduler.shutdown();}
}
五.差异化优势:为什么它比同类工具更好用
用过不少编程工具后,我发现飞算 JavaAI 的优势特别明显。和之前用过的 Cursor 相比,它更懂 Java 开发场景:生成的代码自带 Spring 全家桶配置,不像 Cursor 还需要手动调整依赖;处理图书借阅这类事务性操作时,能自动添加 @Transactional 注解,而其他工具经常忽略这一点。
与通义灵码这类代码补全工具相比,飞算 JavaAI 不止能补全代码片段,而是能从头到尾把控开发全流程。从需求分析到接口设计、从数据库表结构到部署配置,一站式搞定,而通义灵码更多是在我写代码时提供建议,没法全局规划。
最关键的是它生成的代码完全 “去黑箱化”。之前用过低代码平台开发小工具,生成的代码乱七八糟,想改功能都无从下手。但飞算 JavaAI 生成的代码包结构清晰,类和方法命名规范,我能轻松看懂每个模块的作用,后续添加新功能时直接扩展就行,没有被平台绑定的顾虑。
六.技术感悟:工具选对,效率翻倍
完成这个图书管理系统后,我对技术学习有了全新的思考。以前总觉得开发项目要靠硬啃源码、死磕文档,直到用了飞算 JavaAI 才明白,选对工具能让技术落地效率提升数倍。
更重要的是,飞算 JavaAI 生成的代码结构规范、注释清晰,完全可以作为学习范例。通过对比自己写的代码和系统生成的代码,我发现了很多之前忽略的编程细节,比如异常处理的规范写法、接口参数校验的最佳实践等,这种边开发边学习的方式让技术成长特别扎实。
七.给新手的开发建议
如果你也想用飞算 JavaAI 开发项目,我有几个实战总结的小建议:
在项目选题上,尽量从实际需求出发。像图书管理系统这种贴近生活的项目,功能明确、逻辑清晰,很适合作为练手项目。开发时可以先实现核心功能,再逐步添加扩展功能,这样能避免因需求太复杂而半途而废。
使用工具时不要过度依赖自动生成功能。飞算 JavaAI 能帮你快速搭建框架,但具体的业务逻辑还需要自己梳理。建议生成代码后逐行阅读,理解每个模块的作用,遇到不懂的地方就用 “Java Chat” 功能提问,把工具变成学习助手而不是替代自己思考的工具。
另外,一定要重视本地化功能的学习。像向量数据库这类工具能大大提升项目的智能化水平,飞算 JavaAI 已经做好了集成方案,跟着教程一步步操作就能实现,掌握这些技能能让你的项目在简历中更有竞争力。
总结
技术学习的路上,选对工具能少走很多弯路。飞算 JavaAI 让我明白,技术落地不必埋头死磕,借助智能工具的力量,普通开发者也能高效完成优质项目。如果你也在为项目开发发愁,不妨试试用飞算 JavaAI 开启你的开发之旅,或许会收获意想不到的惊喜。