Calcite自定义扩展SQL案例详细流程篇
文章目录
- 前言
- 本章节源码
- 一、基于 Calcite 实现一个自定义 SQL 解析器
- 1.1、认识Calcite解析器
- 二、实战案例
- 2.1、快速构建一个可扩展sql语法的模板工程(当前暂无自定义扩展sql示例)
- 步骤1:拉取calcite源码,复制codegen代码
- 步骤2:配置pom插件实现JavaCC 编译( FreeMarker 模版插件、javacc插件)
- 步骤3:执行命令生成SqlParserImpl自定义解析器类
- 步骤过程
- 插件生成源码原理
- 实际使用生成出来的工厂类
- 额外说明maven-dependency-plugin插件
- 2.2、基于2.1工程扩展自定义SQL
- 参考学习案例(强推)
- 详细步骤如下
- 步骤1:自定义SQL语法
- 步骤2:定义解析结果类SqlCreateFunction及SqlProperty
- 步骤3:语法模板 parserImpls.ftl
- 步骤4:配置配置模板 config.fmpp
- 步骤5:javacc编译生成代码
- 实际测试自定义语法
- 未完待续
- 扩展
- 参考文章
- 资料获取

前言
博主介绍:✌目前全网粉丝4W+,csdn博客专家、Java领域优质创作者,博客之星、阿里云平台优质作者、专注于Java后端技术领域。
涵盖技术内容:Java后端、大数据、算法、分布式微服务、中间件、前端、运维等。
博主所有博客文件目录索引:博客目录索引(持续更新)
CSDN搜索:长路
视频平台:b站-Coder长路
本章节源码
当前文档配套相关源码地址:
- gitee:https://gitee.com/changluJava/demo-exer/tree/master/java-sqlparser/demo-calcite
- github:https://github.com/changluya/Java-Demos/tree/master/java-sqlparser/demo-calcite
一、基于 Calcite 实现一个自定义 SQL 解析器
可搭配学习:https://zhuanlan.zhihu.com/p/509681717
1.1、认识Calcite解析器
Calcite 默认使用 JavaCC 生成 SQL 解析器,可以很方便的将其替换为 Antlr 作为代码生成器 。JavaCC 全称 Java Compiler Compiler,是一个开源的 Java 程序解析器生成器,生成的语法分析器采用递归下降语法解析,简称 LL(K)。主要通过一些模版文件生成语法解析程序(例如根据 .jj 文件或者 .jjt 等文件生产代码)。
Calcite 的解析体系是将 SQL 解析成抽象语法树, Calcite 中使用 SqlNode 这种数据结构表示语法树上的每个节点,例如 “select 1 + 1 = 2” 会将其拆分为多个 SqlNode。
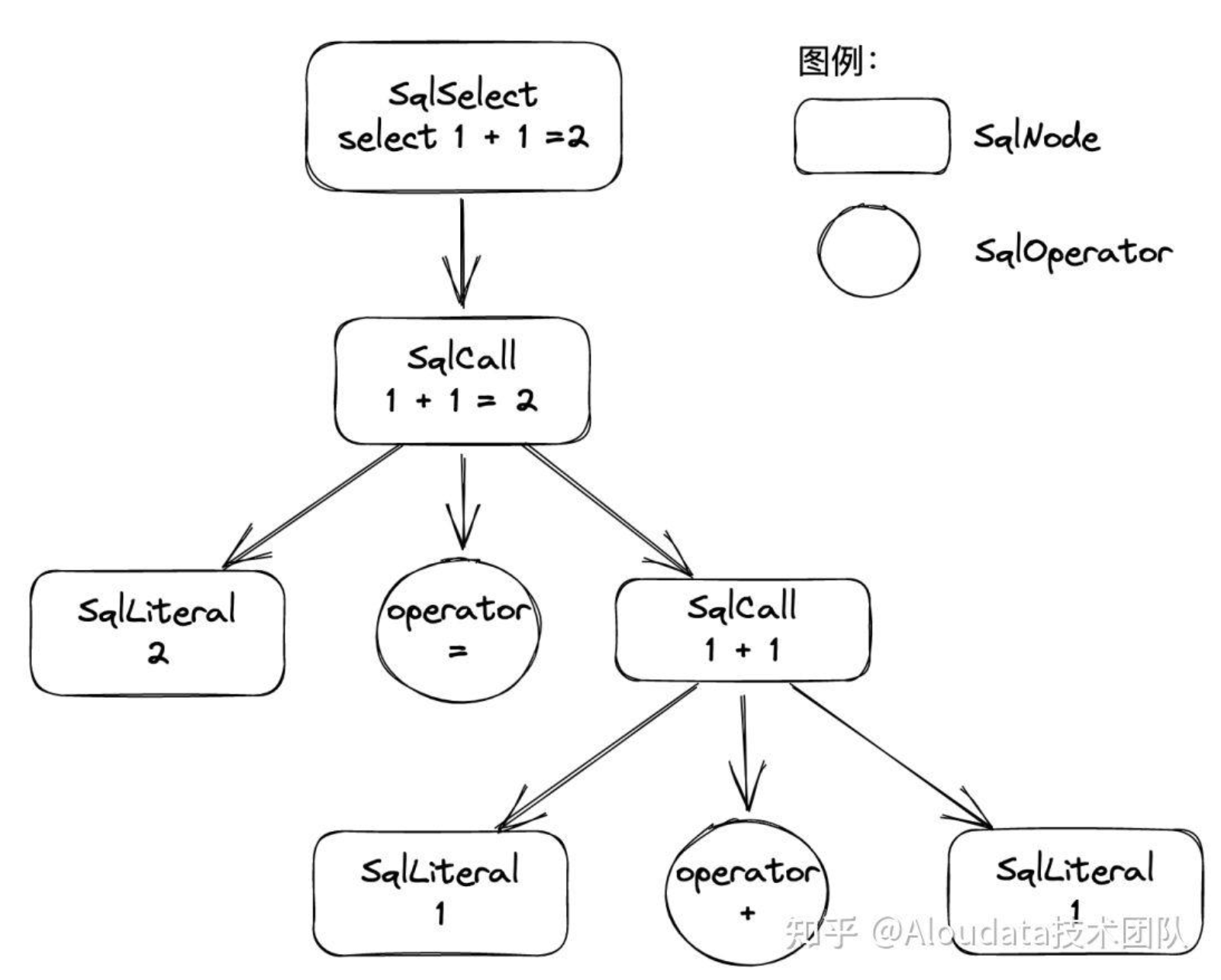
SqlNode 有几个重要的封装子类,SqlLiteral、SqlIdentifier 和 SqlCall。 SqlLiteral:封装常量,也叫字面量。SqlIdentifier:SQL 标识符,例如表名、字段名等。SqlCall:表示一种操作,SqlSelect、SqlAlter、SqlDDL 等都继承 SqlCall。
二、实战案例
2.1、快速构建一个可扩展sql语法的模板工程(当前暂无自定义扩展sql示例)
案例工程:demo1
📎demo1.zip
步骤1:拉取calcite源码,复制codegen代码
**拉取calcite源码1.21.0源码:**https://github.com/apache/calcite
📎calcite.zip(这里给出core、server模块源码,需要其他可去官网获取)
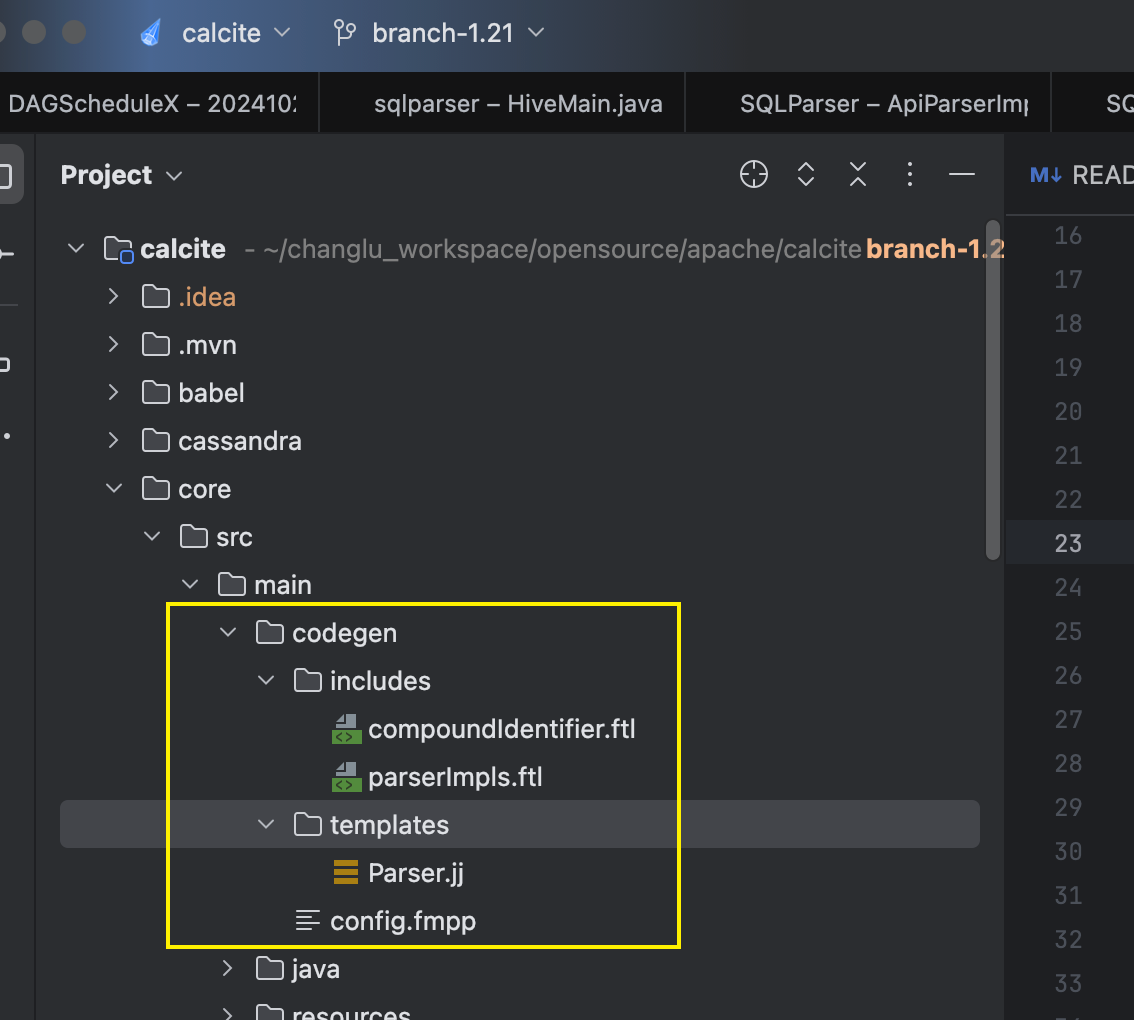
将这 部分代码拷贝到我们自己新建的工程:
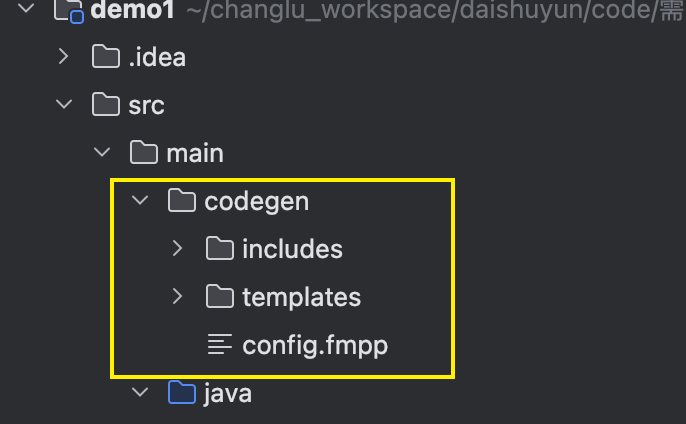
步骤2:配置pom插件实现JavaCC 编译( FreeMarker 模版插件、javacc插件)
以下配置均在pom.xml完成
定义caliate版本:
<properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><calcite.version>1.21.0</calcite.version>
</properties><build><plugins></plugins>
</build>
插件1:maven-resources-plugin 插件
说明:这个插件用于将指定的资源文件复制到构建目录中。在这个例子中,它将src/main/codegen目录下的文件复制到${project.build.directory}/codegen目录。
<plugin><!-- 指定插件的artifactId,这里是maven-resources-plugin --><artifactId>maven-resources-plugin</artifactId><executions><!-- 定义插件的执行阶段 --><execution><!-- 为这个执行阶段设置一个唯一的id --><id>copy-fmpp-resources</id><!-- 指定这个执行应该在哪个Maven生命周期阶段执行,这里是initialize阶段 --><phase>initialize</phase><goals><!-- 指定要执行的目标 --><goal>copy-resources</goal></goals><configuration><!-- 配置插件的参数 --><outputDirectory>${project.build.directory}/codegen</outputDirectory><!-- 定义要复制的资源 --><resources><resource><!-- 指定资源的目录 --><directory>src/main/codegen</directory><!-- 设置是否对资源文件进行过滤,这里设置为false --><filtering>false</filtering></resource></resources></configuration></execution></executions>
</plugin>
插件2:fmpp-maven-plugin 插件
说明:用于使用FreeMarker模板引擎生成源代码。它依赖于FreeMarker库,并且配置了模板和配置文件的位置,以及生成源代码的输出目录。
<plugin><!-- 指定插件的groupId和artifactId,这里是fmpp-maven-plugin --><groupId>com.googlecode.fmpp-maven-plugin</groupId><artifactId>fmpp-maven-plugin</artifactId><version>1.0</version><dependencies><!-- 定义插件依赖 --><dependency><groupId>org.freemarker</groupId><artifactId>freemarker</artifactId><version>2.3.28</version></dependency></dependencies><executions><execution><id>generate-fmpp-sources</id><phase>generate-sources</phase><goals><goal>generate</goal></goals><configuration><!-- 配置FreeMarker的配置文件位置 --><cfgFile>${project.build.directory}/codegen/config.fmpp</cfgFile><!-- 指定生成的源代码输出目录 --><outputDirectory>target/generated-sources</outputDirectory><!-- 指定模板文件的位置 --><templateDirectory>${project.build.directory}/codegen/templates</templateDirectory></configuration></execution></executions>
</plugin>
插件3:javacc-maven-plugin 插件
说明:用于使用JavaCC(Java Compiler Compiler)工具生成Java解析器。它配置了JavaCC源文件的位置、包含的文件模式、lookAhead参数、是否生成静态代码以及输出目录。
<plugin><!-- 注释说明这个插件必须在fmpp-maven-plugin之后执行 --><!-- 指定插件的groupId和artifactId,这里是javacc-maven-plugin --><groupId>org.codehaus.mojo</groupId><artifactId>javacc-maven-plugin</artifactId><version>2.4</version><executions><execution><phase>generate-sources</phase><id>javacc</id><goals><goal>javacc</goal></goals><configuration><!-- 指定JavaCC源文件的目录 --><sourceDirectory>${project.build.directory}/generated-sources/</sourceDirectory><!-- 指定包含的文件模式 --><includes><include>**/Parser.jj</include></includes><!-- 配置JavaCC的lookAhead参数,必须与Apache Calcite保持同步 --><lookAhead>1</lookAhead><!-- 设置是否生成静态代码,这里设置为false --><isStatic>false</isStatic><!-- 指定生成的JavaCC代码的输出目录 --><outputDirectory>${project.build.directory}/generated-sources/</outputDirectory></configuration></execution></executions>
</plugin>
步骤3:执行命令生成SqlParserImpl自定义解析器类
步骤过程
在当前工程目录下命令行执行命令:
mvn generate-sources
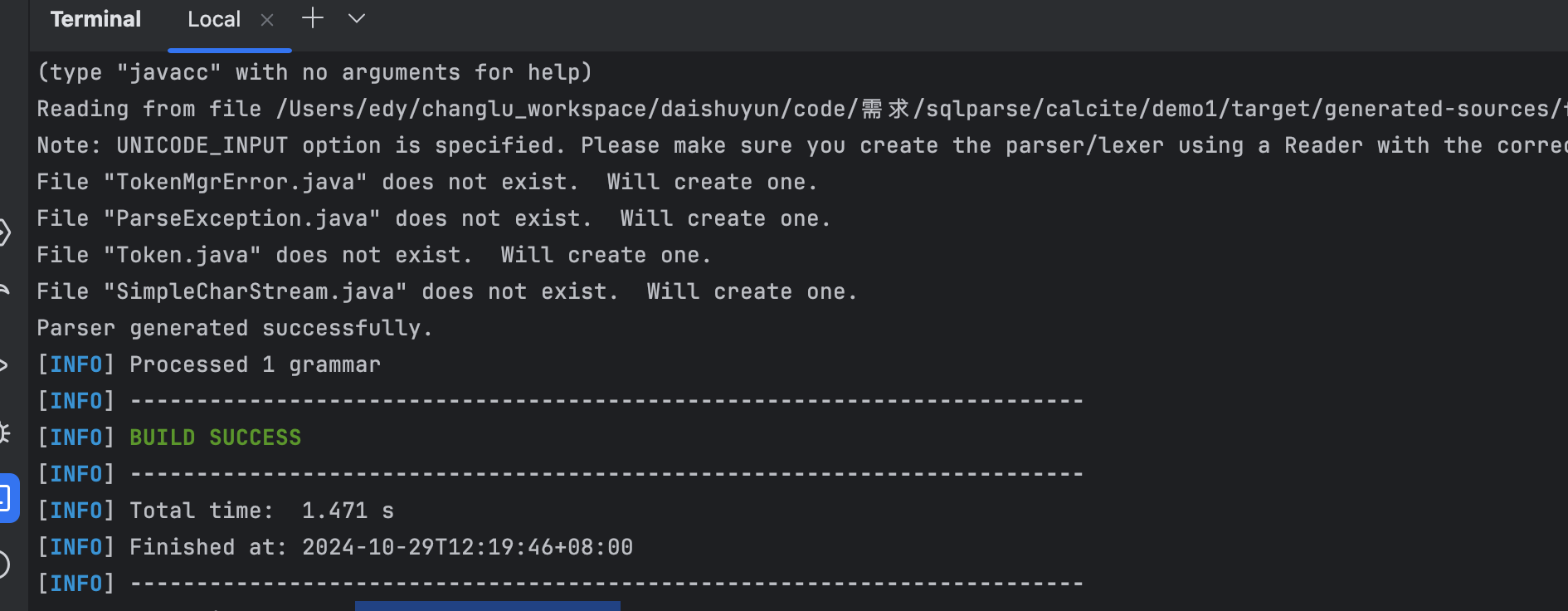
生成的内容如下:我们最终使用的就是其中的SqlParserImpl
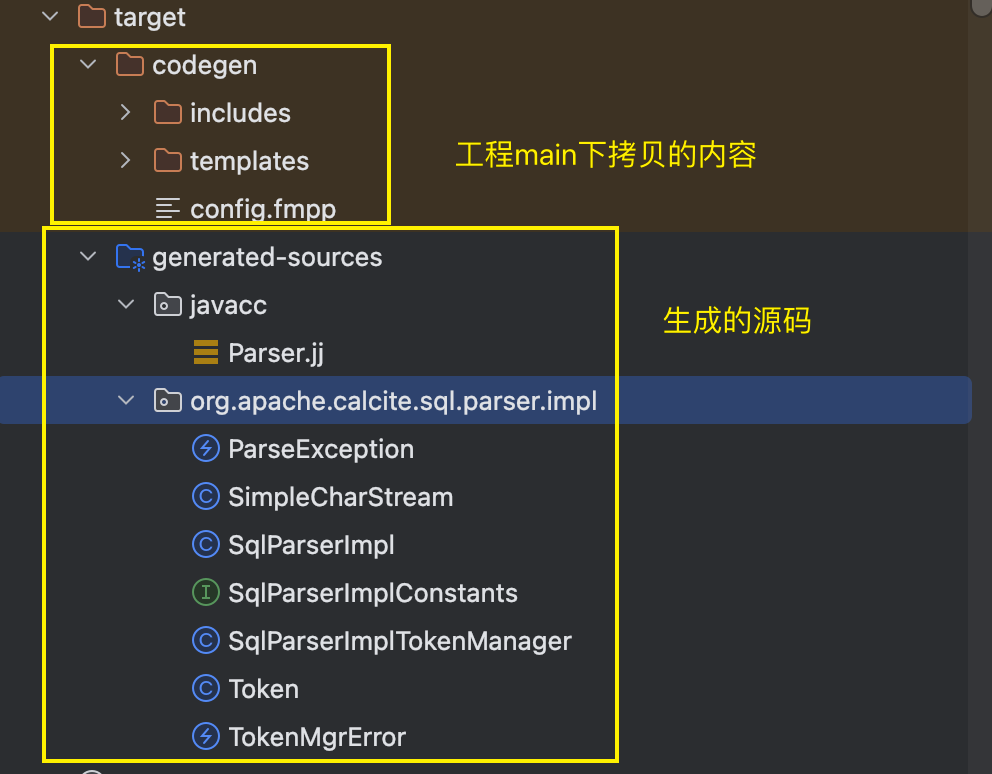
插件生成源码原理
我们主要使用的插件是两个,一个是freemarker,另一个是javacc。
- freemarker:可以将我们指定提供的模板 + 自己传入的动态值,生成我们想要的源码或者模板文件。(当前场景是生成最终的parser.jj模板)
- javacc:根据freemarker替换得到最终的parser.jj文件后,对该xx.jj文件进行。
执行命令mvn generate-sources的中间过程:
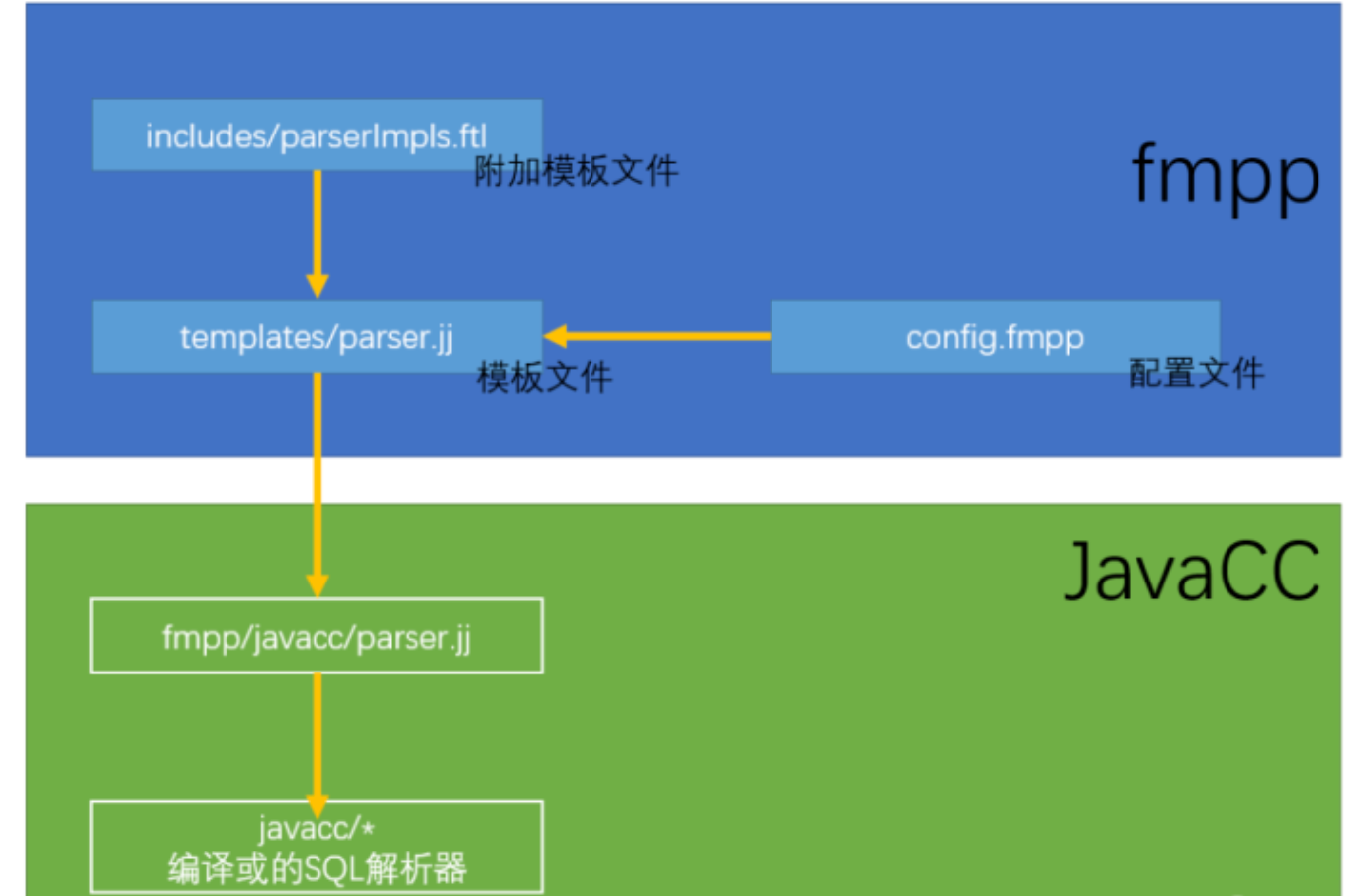
可以这么理解,就是calcite官方给我们提供了一个模板文件以及附加配置文件及附加模板文件,我们通过使用这三个部分通过freemarker来将我们生成目标文件,这里也就是parser.jj,这个parser.jj文件
- 详细细节可见这篇文章:Apache Calcite SQL解析及语法扩展 https://zhuanlan.zhihu.com/p/509681717
实际使用生成出来的工厂类
pom.xml中添加calcite核心包:
<dependency><groupId>org.apache.calcite</groupId><artifactId>calcite-core</artifactId><version>${calcite.version}</version>
</dependency>
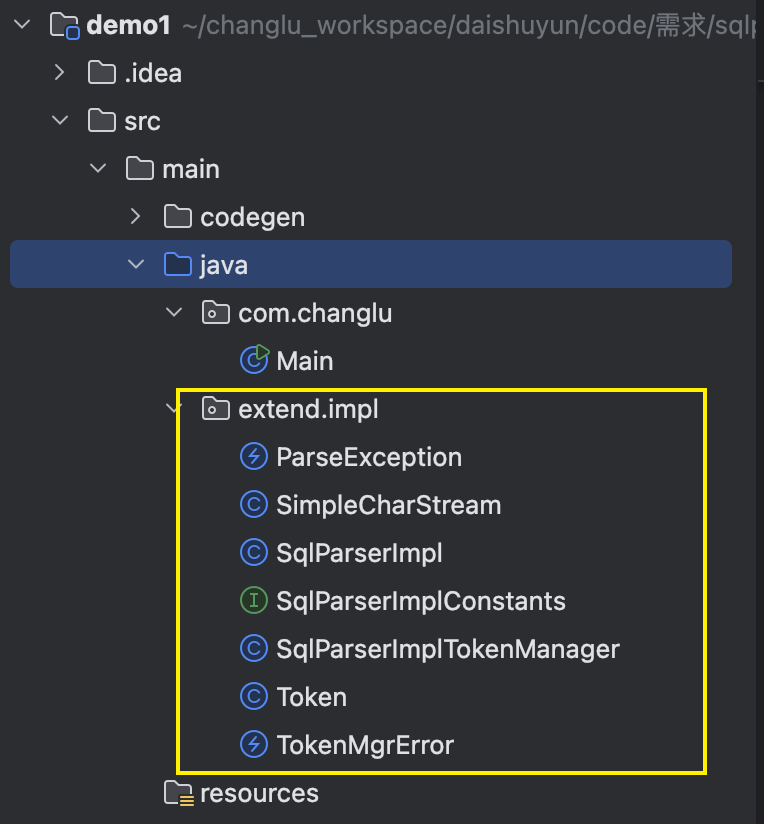
接着此时我们在Main.java中写一个main方法来看下:
package com.changlu;
import extend.impl.SqlParserImpl;
import org.apache.calcite.avatica.util.Casing;
import org.apache.calcite.sql.SqlNode;
import org.apache.calcite.sql.dialect.HiveSqlDialect;
import org.apache.calcite.sql.parser.SqlParseException;
import org.apache.calcite.sql.parser.SqlParser;
import org.apache.calcite.sql.validate.SqlConformanceEnum;public class Main {public static void main(String[] args) throws SqlParseException {// 提供sql语句String sql = "select * from emps where id = 1";// 生成sql解析配置SqlParser.Config config = SqlParser.configBuilder()// 这里引用的类名为当前自定义扩展的.setParserFactory(SqlParserImpl.FACTORY).setUnquotedCasing(Casing.UNCHANGED).setQuotedCasing(Casing.UNCHANGED).setCaseSensitive(false).setConformance(SqlConformanceEnum.MYSQL_5).build();SqlParser sqlParser = SqlParser.create(sql, config);SqlNode sqlNode = sqlParser.parseQuery(sql);System.out.println("sqlNode:\n" + sqlNode);System.out.println();String transferSql = sqlNode.toSqlString(HiveSqlDialect.DEFAULT).getSql();System.out.println("转换hivesql:\n" + transferSql);}
}
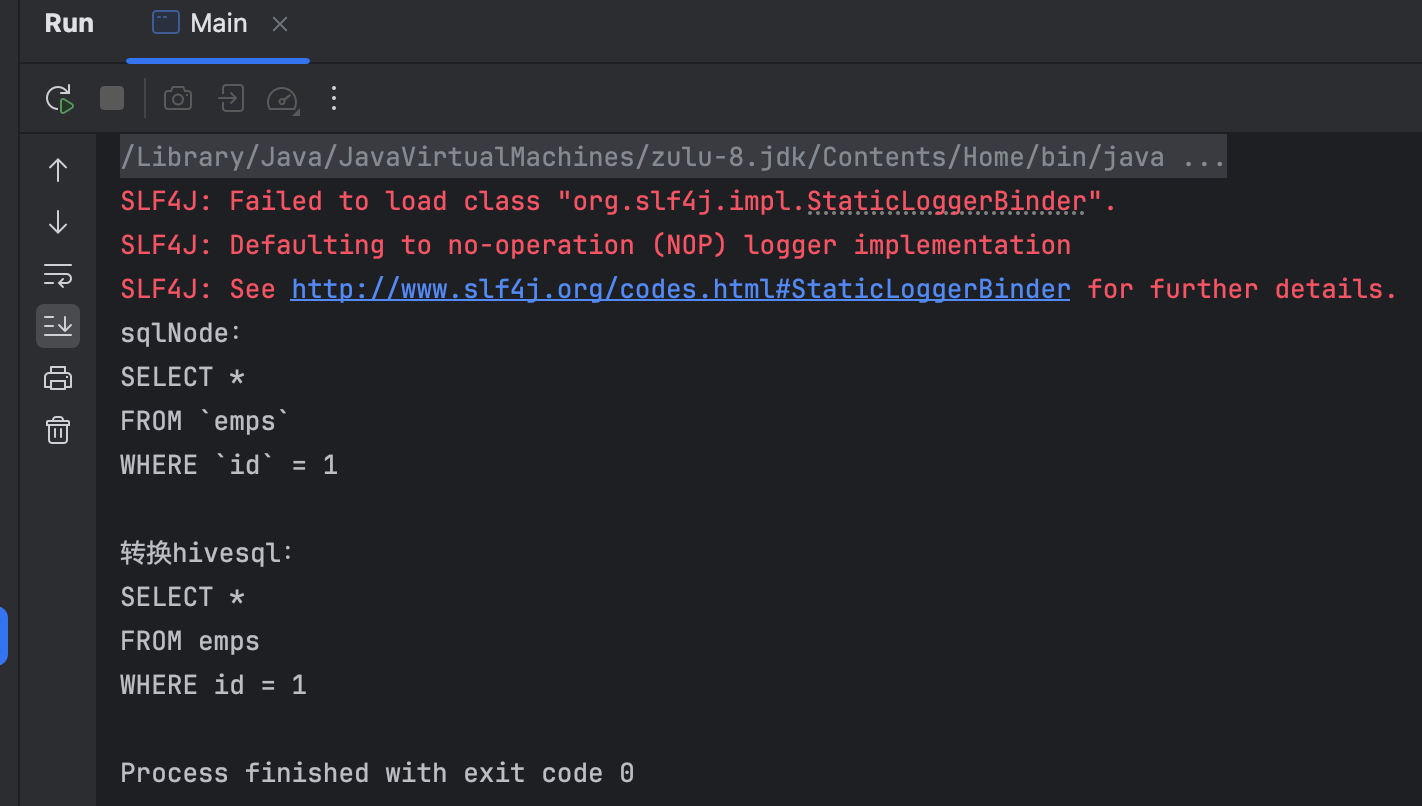
依旧正常能够运行:
额外说明maven-dependency-plugin插件
关于部分工程中引入的maven-dependency-plugin插件:
<plugin><!-- Extract parser grammar template from calcite-core.jar and putit under ${project.build.directory} where all freemarker templates are. --><groupId>org.apache.maven.plugins</groupId><artifactId>maven-dependency-plugin</artifactId><executions><execution><id>unpack-parser-template</id><phase>initialize</phase><goals><goal>unpack</goal></goals><configuration><artifactItems><artifactItem><groupId>org.apache.calcite</groupId><artifactId>calcite-core</artifactId><version>1.21.0</version><type>jar</type><overWrite>true</overWrite><outputDirectory>${project.build.directory}/</outputDirectory><includes>**/Parser.jj</includes></artifactItem></artifactItems></configuration></execution></executions>
</plugin>
该插件主要是将源码calcite-core指定版本的Parser.jj复制到target目录当中去,实际上如果我们做了步骤1的话,无需将该插件引入,如果说我们的工程里不想放入Parser.jj文件,只想要放置如下目录:
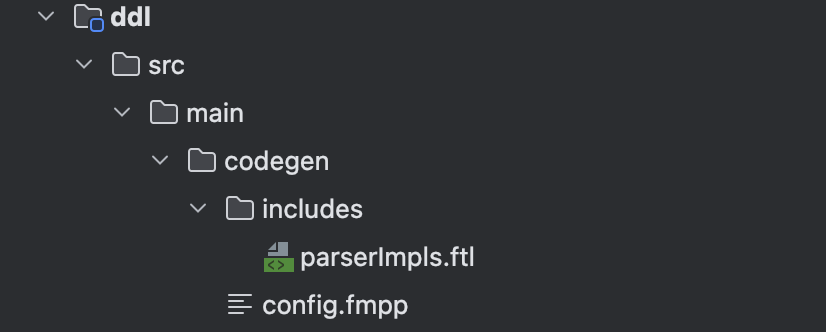
那么就可以将该插件添加进去,执行mave命令的时候自然会将Parser.jj拷贝进来,相当于我们自己预先在工程里拷贝Parser.jj而已。
2.2、基于2.1工程扩展自定义SQL
案例工程:demo2
📎demo2.zip
参考学习案例(强推)
大量互联网上参考的都是这个:
-
Apache Calcite教程 -目录(博客):https://blog.csdn.net/QXC1281/article/details/89070285
-
github地址:https://github.com/quxiucheng/apache-calcite-tutorial/tree/a7d63273d0c7585fc65ad250c99a67a201bcb8b5
-
- Apache Calcite系列专栏(先锋,字节跳动 大数据后台开发):https://zhuanlan.zhihu.com/p/614668529 【这篇博文是跟着这个github仓库学习的,可以搭配看】
代码拉下来后看这个工程,里面带上了README.md:
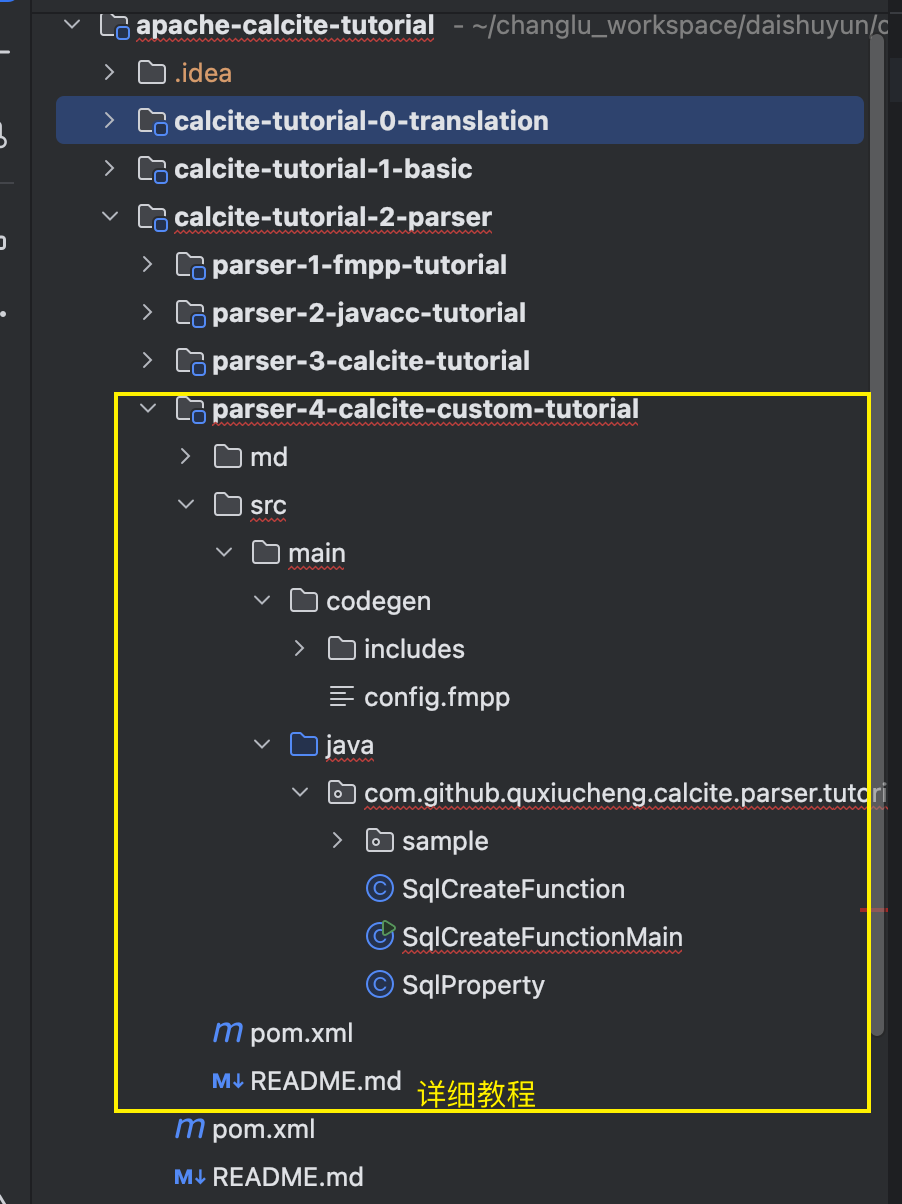
接下来学习该案例,下面的步骤会以该案例进行同步操作实践。
详细步骤如下
步骤1:自定义SQL语法
create function function_name as class_name
[method]
[with] [(key=value)]
实际举例:
# 创建函数关键字
create function
# 函数名hr.custom_function
# as关键字
as
# 类名称'com.github.quxiucheng.calcite.func.CustomFunction'
# 可选 方法名称
method 'eval'
# 可选 备注信息
comment 'comment'
# 可选 附件变量
property ('a'='b','c'='1')
步骤2:定义解析结果类SqlCreateFunction及SqlProperty
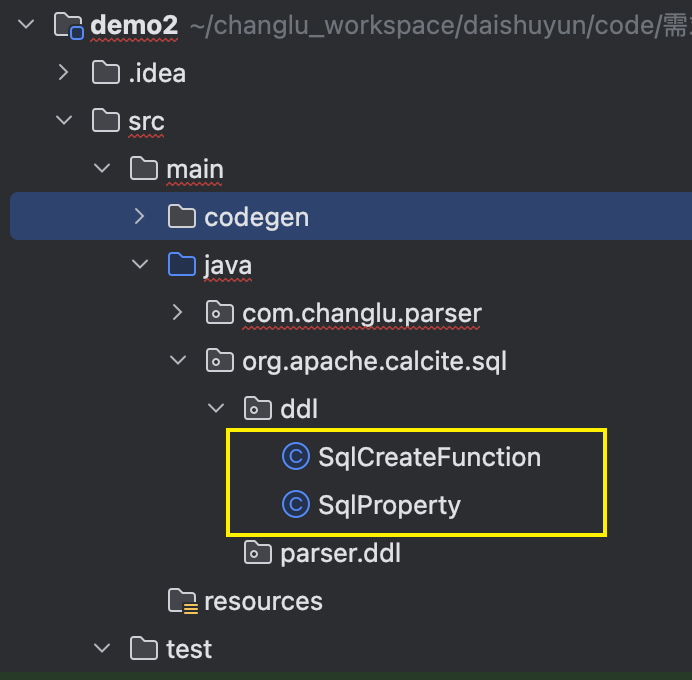
- 对于org.apache.calcite.sql.parser.ddl包是之后给生成代码放的。
SqlCreateFunction.java:解析结果类
package org.apache.calcite.sql.ddl;import org.apache.calcite.sql.SqlCall;
import org.apache.calcite.sql.SqlKind;
import org.apache.calcite.sql.SqlNode;
import org.apache.calcite.sql.SqlNodeList;
import org.apache.calcite.sql.SqlOperator;
import org.apache.calcite.sql.SqlWriter;
import org.apache.calcite.sql.parser.SqlParserPos;import java.util.List;public class SqlCreateFunction extends SqlCall {private SqlNode functionName;private String className;private SqlNodeList properties;private String methodName;private String comment;public SqlCreateFunction(SqlParserPos pos,SqlNode functionName, String className, String methodName, String comment,SqlNodeList properties) {super(pos);this.functionName = functionName;this.className = className;this.properties = properties;this.methodName = methodName;}public SqlNode getFunctionName() {return functionName;}public String getClassName() {return className;}public String getMethodName() {return methodName;}public SqlNodeList getProperties() {return properties;}public String getComment() {return comment;}@Overridepublic SqlOperator getOperator() {return null;}@Overridepublic List<SqlNode> getOperandList() {return null;}@Overridepublic SqlKind getKind() {return SqlKind.OTHER_DDL;}@Overridepublic void unparse(SqlWriter writer, int leftPrec, int rightPrec) {writer.keyword("CREATE");writer.keyword("FUNCTION");functionName.unparse(writer, leftPrec, rightPrec);writer.keyword("AS");writer.print("'" + className + "'");if (methodName != null) {writer.newlineAndIndent();writer.keyword("METHOD");writer.print("'" + methodName + "'");}if (properties != null) {writer.newlineAndIndent();writer.keyword("PROPERTY");SqlWriter.Frame propertyFrame = writer.startList("(", ")");for (SqlNode property : properties) {writer.sep(",", false);writer.newlineAndIndent();writer.print(" ");property.unparse(writer, leftPrec, rightPrec);}writer.newlineAndIndent();writer.endList(propertyFrame);}if (comment != null) {writer.newlineAndIndent();writer.keyword("COMMENT");writer.print("'" + comment + "'");}}
}
SqlProperty.java:解析key=value语句
package org.apache.calcite.sql.ddl;import com.google.common.collect.ImmutableList;
import org.apache.calcite.sql.SqlCall;
import org.apache.calcite.sql.SqlKind;
import org.apache.calcite.sql.SqlLiteral;
import org.apache.calcite.sql.SqlNode;
import org.apache.calcite.sql.SqlOperator;
import org.apache.calcite.sql.SqlSpecialOperator;
import org.apache.calcite.sql.SqlWriter;
import org.apache.calcite.sql.parser.SqlParserPos;
import org.apache.calcite.util.NlsString;import java.util.List;import static java.util.Objects.requireNonNull;public class SqlProperty extends SqlCall {/*** 定义特殊操作符*/protected static final SqlOperator OPERATOR =new SqlSpecialOperator("Property", SqlKind.OTHER);private SqlNode key;private SqlNode value;public SqlProperty(SqlParserPos pos, SqlNode key, SqlNode value) {super(pos);this.key = requireNonNull(key, "Property key is missing");this.value = requireNonNull(value, "Property value is missing");}@Overridepublic SqlOperator getOperator() {return OPERATOR;}@Overridepublic List<SqlNode> getOperandList() {return ImmutableList.of(key, value);}@Overridepublic SqlKind getKind() {return SqlKind.OTHER;}@Overridepublic void unparse(SqlWriter writer, int leftPrec, int rightPrec) {key.unparse(writer, leftPrec, rightPrec);writer.keyword("=");value.unparse(writer, leftPrec, rightPrec);}public SqlNode getKey() {return key;}public SqlNode getValue() {return value;}public String getKeyString() {return key.toString();}public String getValueString() {return ((NlsString) SqlLiteral.value(value)).getValue();}}
步骤3:语法模板 parserImpls.ftl
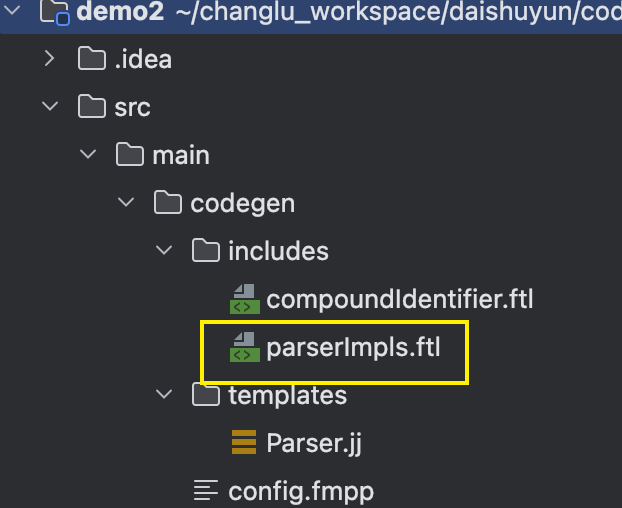
在codegen/includes/parserImpls.ftl中添加如下配置:
- 这里会使用到SqlCreateFunction、SqlProperty类。
- 这里大量使用到了javacc的语法,例如其中的关键字、if判断、java代码等。
// 创建函数SqlNode SqlCreateFunction() :{// 声明变量SqlParserPos createPos;SqlParserPos propertyPos;SqlNode functionName = null;String className = null;String methodName = null;String comment = null;SqlNodeList properties = null;}{// create 关键字<CREATE>{// 获取当前token的行列位置createPos = getPos();}// function 关键字<FUNCTION>// 函数名functionName = CompoundIdentifier()// as关键字<AS>// 类名{ className = StringLiteralValue(); }// if语句[// method关键字<METHOD>{// 方法名称methodName = StringLiteralValue();}]// if[// property 关键字,设置初始化变量<PROPERTY>{// 获取关键字位置propertyPos = getPos();SqlNode property;properties = new SqlNodeList(propertyPos);}<LPAREN>[property = PropertyValue(){properties.add(property);}(<COMMA>{property = PropertyValue();properties.add(property);})*]<RPAREN>]// if[<COMMENT> {// 备注comment = StringLiteralValue();}]{return new SqlCreateFunction(createPos, functionName, className, methodName, comment, properties);}}JAVACODE String StringLiteralValue() {SqlNode sqlNode = StringLiteral();return ((NlsString) SqlLiteral.value(sqlNode)).getValue();}/*** 解析SQL中的key=value形式的属性值*/SqlNode PropertyValue() :{SqlNode key;SqlNode value;SqlParserPos pos;}{key = StringLiteral(){ pos = getPos(); }<EQ> value = StringLiteral(){return new SqlProperty(getPos(), key, value);}}
步骤4:配置配置模板 config.fmpp
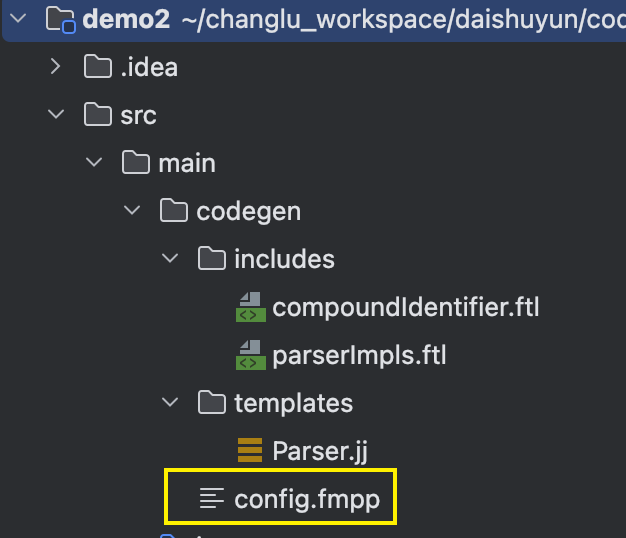 。
。
定义package、class 和 imports:
- 这里package就是最终生成的输出目录,class为最终生成的实现类名称,imports表示的是后续自定义class类中文件顶部会import引入的代码位置
package: "org.apache.calcite.sql.parser.ddl"class: "CustomSqlParserImpl",imports: ["org.apache.calcite.sql.ddl.SqlCreateFunction","org.apache.calcite.sql.ddl.SqlProperty"]
定义关键字keywords:
keywords: ["PARAMS""COMMENT""PROPERTY" ]
定义自定义解析 statementParserMethods:
statementParserMethods: ["SqlCreateFunction()"]
步骤5:javacc编译生成代码

在当前工程目录下执行命令进行编译生成:
mvn generate-sources
将生成的代码添加到之前的parser.ddl目录:
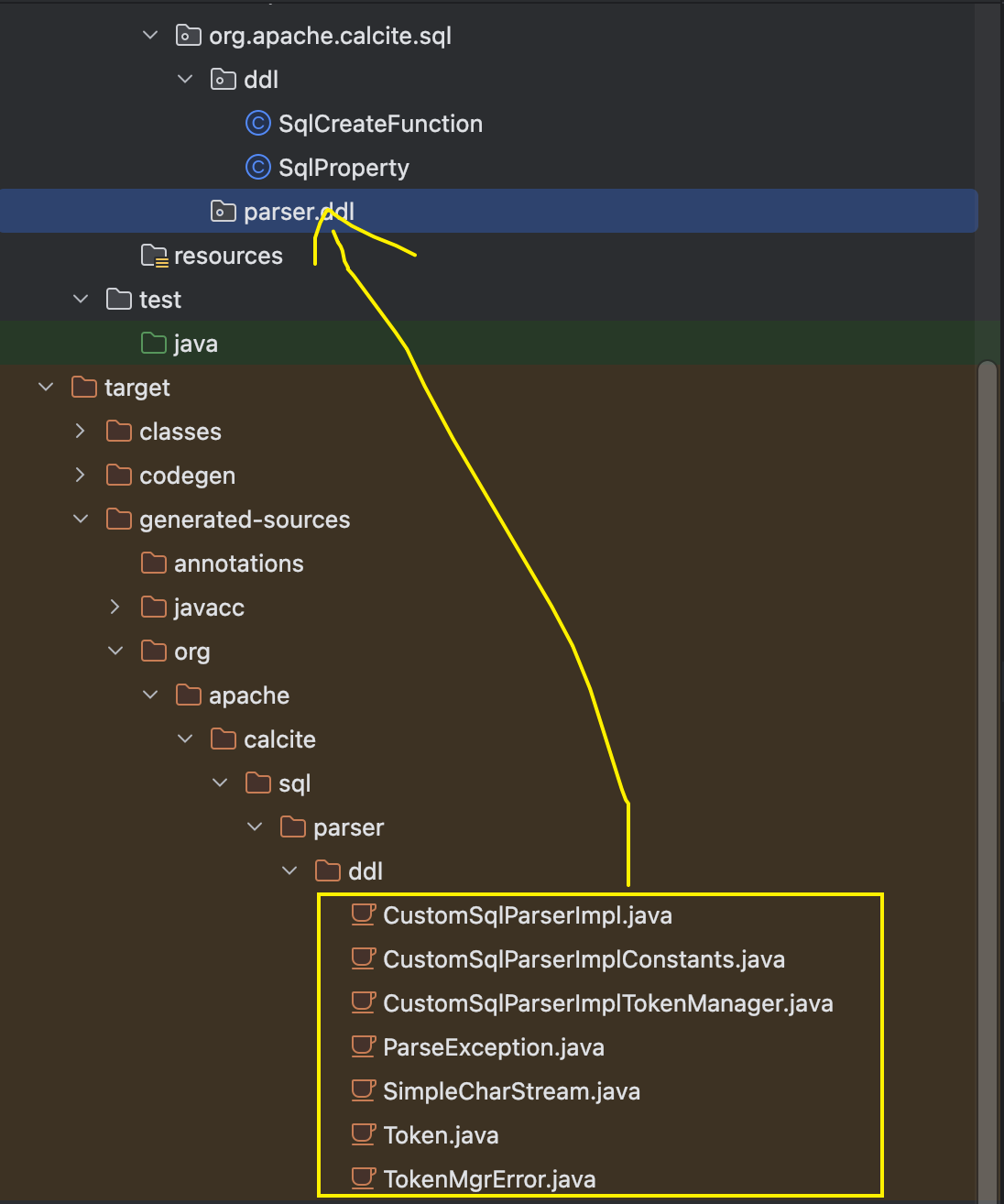
此时大功告成,准备测试:
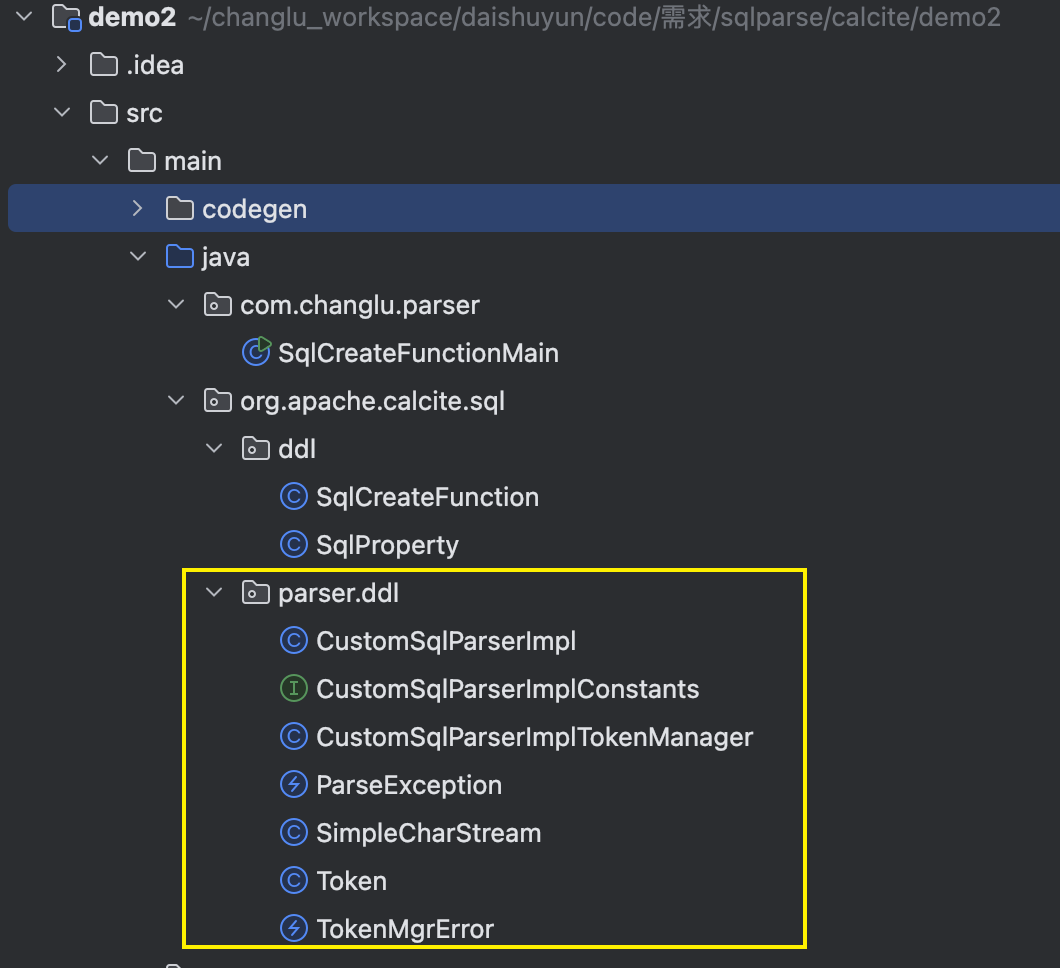
实际测试自定义语法
使用calicte原生的sql解析器工厂SqlParserImpl.FACTORY
package com.changlu.parser;
import org.apache.calcite.config.Lex;
import org.apache.calcite.sql.SqlNode;
import org.apache.calcite.sql.dialect.OracleSqlDialect;
import org.apache.calcite.sql.parser.SqlParseException;
import org.apache.calcite.sql.parser.SqlParser;
import org.apache.calcite.sql.parser.impl.SqlParserImpl;public class SqlCreateFunctionMain {public static void main(String[] args) throws SqlParseException {// 解析配置 - mysql设置SqlParser.Config mysqlConfig = SqlParser.configBuilder()// 定义解析工厂.setParserFactory(SqlParserImpl.FACTORY).setLex(Lex.MYSQL).build();// 创建解析器SqlParser parser = SqlParser.create("", mysqlConfig);// Sql语句String sql = "create function " +"hr.custom_function as 'com.github.quxiucheng.calcite.func.CustomFunction' " +"method 'eval' " +"property ('a'='b','c'='1') ";// 解析sqlSqlNode sqlNode = parser.parseQuery(sql);// 还原某个方言的SQLSystem.out.println(sqlNode.toSqlString(OracleSqlDialect.DEFAULT));}
}
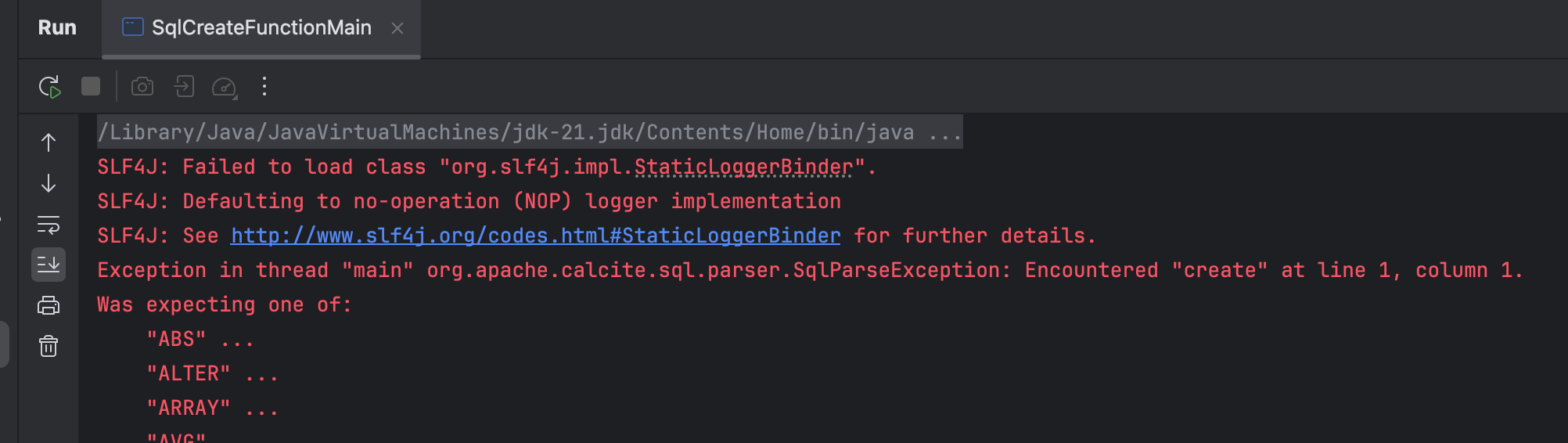
使用自定义解析工厂类测试
package com.changlu.parser;import org.apache.calcite.config.Lex;
import org.apache.calcite.sql.SqlNode;
import org.apache.calcite.sql.dialect.OracleSqlDialect;
import org.apache.calcite.sql.parser.SqlParseException;
import org.apache.calcite.sql.parser.SqlParser;
import org.apache.calcite.sql.parser.ddl.CustomSqlParserImpl;public class SqlCreateFunctionMain {public static void main(String[] args) throws SqlParseException {// 解析配置 - mysql设置SqlParser.Config mysqlConfig = SqlParser.configBuilder()// 定义解析工厂.setParserFactory(CustomSqlParserImpl.FACTORY).setLex(Lex.MYSQL).build();// 创建解析器SqlParser parser = SqlParser.create("", mysqlConfig);// Sql语句String sql = "create function " +"hr.custom_function as 'com.github.quxiucheng.calcite.func.CustomFunction' " +"method 'eval' " +"property ('a'='b','c'='1') ";// 解析sqlSqlNode sqlNode = parser.parseQuery(sql);// 还原某个方言的SQLSystem.out.println(sqlNode.toSqlString(OracleSqlDialect.DEFAULT));}
}
成功解析:
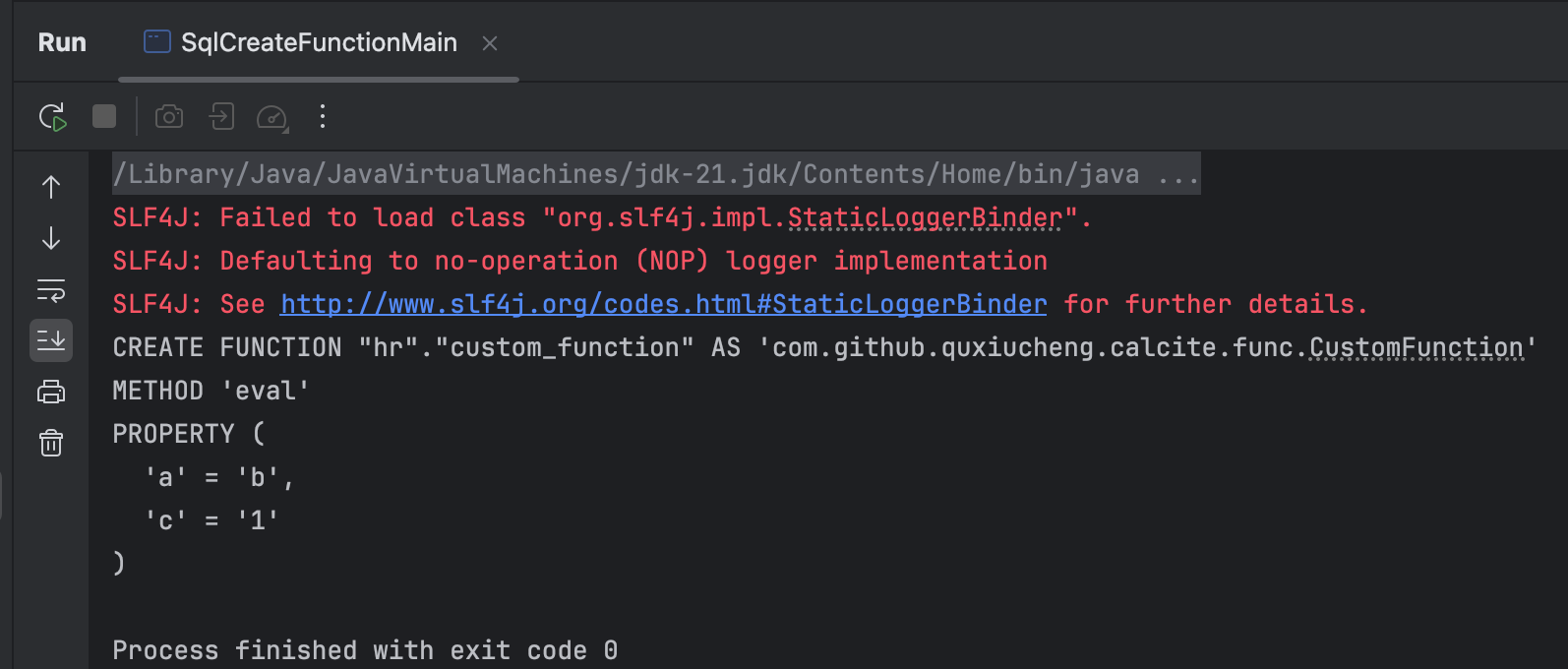
未完待续
到了这里,我感觉想要后续实现一些自定义扩展语法有两个难点:一个就是能够熟悉javacc语法,另一个就是熟悉Calcite去进行解析构建AstNode树的过程,因为支持部分自定义语法则需要去继承实现诸如下面一些Sqlxxx(这个是calcite提供的实现):
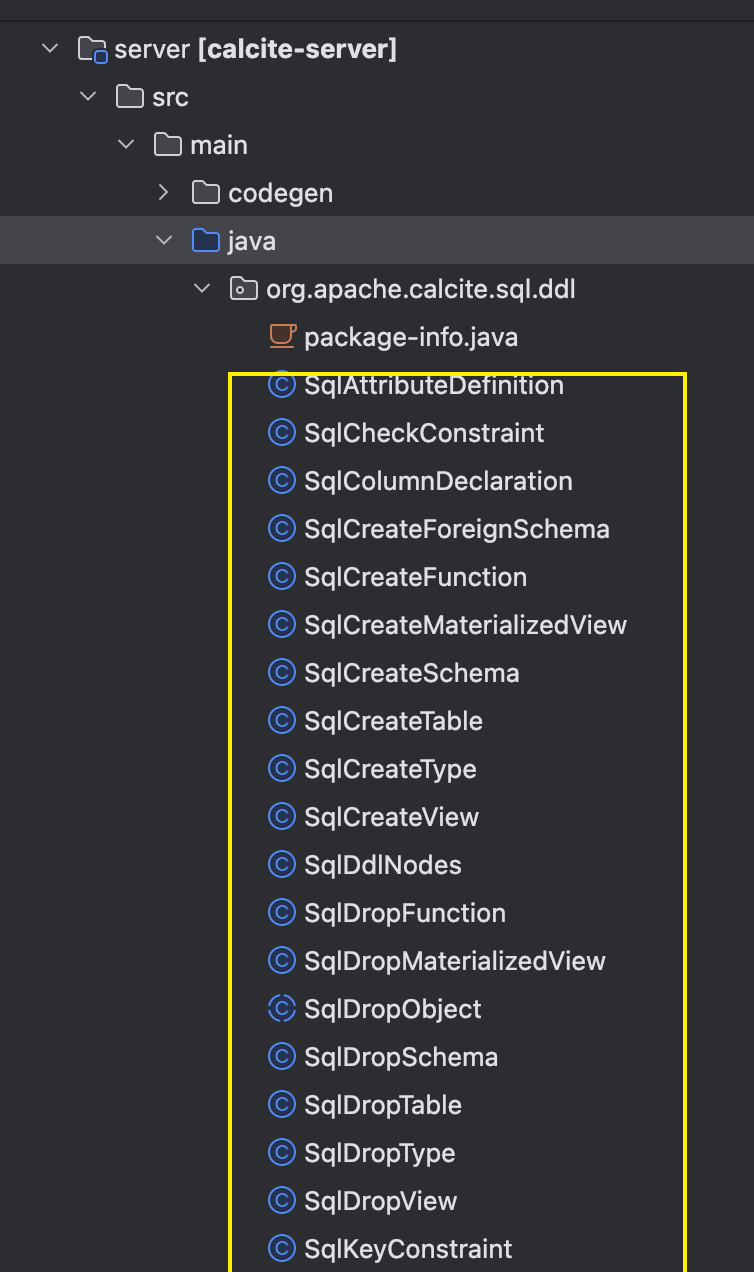
扩展
其他sqlparser解析器有:Antlr 4
SQL Parser的方式有很多种,JAVA语言中,主要有两个框架,一个是JavaCC,一个是Antlr4。比如像Apache Calcite就是用的JavaCC解析的SQL。而用Apache Calcite框架的,那是相当之多,如下:

参考文章
[1]. Calcite SQL 解析、语法扩展、元数据验证原理与实战(上):https://www.modb.pro/db/607373
[2]. Apache Calcite SQL解析及语法扩展:https://zhuanlan.zhihu.com/p/509681717
资料获取
大家点赞、收藏、关注、评论啦~
精彩专栏推荐订阅:在下方专栏👇🏻
- 长路-文章目录汇总(算法、后端Java、前端、运维技术导航):博主所有博客导航索引汇总
- 开源项目Studio-Vue—校园工作室管理系统(含前后台,SpringBoot+Vue):博主个人独立项目,包含详细部署上线视频,已开源
- 学习与生活-专栏:可以了解博主的学习历程
- 算法专栏:算法收录
更多博客与资料可查看👇🏻获取联系方式👇🏻,🍅文末获取开发资源及更多资源博客获取🍅