CNN卷积神经网络之MobileNet和ResNet(五)
CNN卷积神经网络之MobileNet和ResNet(五)
文章目录
- CNN卷积神经网络之MobileNet和ResNet(五)
- MobileNet V1/V2 & ResNet(附可直接运行的 PyTorch 代码)
- 1. 模型速查表
- 2. MobileNet V1 核心回顾
- 3. MobileNet V2 改进点
- 4. ResNet 核心回顾
- 5. PyTorch 最小复现代码
- 5.1 项目结构
- 5.2 `models.py`
- 5.3 `main.py`
- 6. 总结 & 何时选谁?
- 7. 参考资料
MobileNet V1/V2 & ResNet(附可直接运行的 PyTorch 代码)
本文主要讲的是移动端经典轻量网络 MobileNet V1 / V2 与深度残差网络 ResNet 的核心思想、结构差异、设计细节,并给出可直接
python main.py运行的最小复现代码。
1. 模型速查表
| 模型 | 发表 | 关键词 | 参数量* | Top-1* |
|---|---|---|---|---|
| ResNet-50 | 2015 | 残差、跳跃连接 | 25.6 M | 76.0 % |
| MobileNet V1 | 2017 | 深度可分离卷积、α/ρ 压缩 | 4.2 M | 70.6 % |
| MobileNet V2 | 2018 | Inverted Residual、Linear Bottleneck | 3.4 M | 72.0 % |
* 以 ImageNet 1k 官方数据为基准。
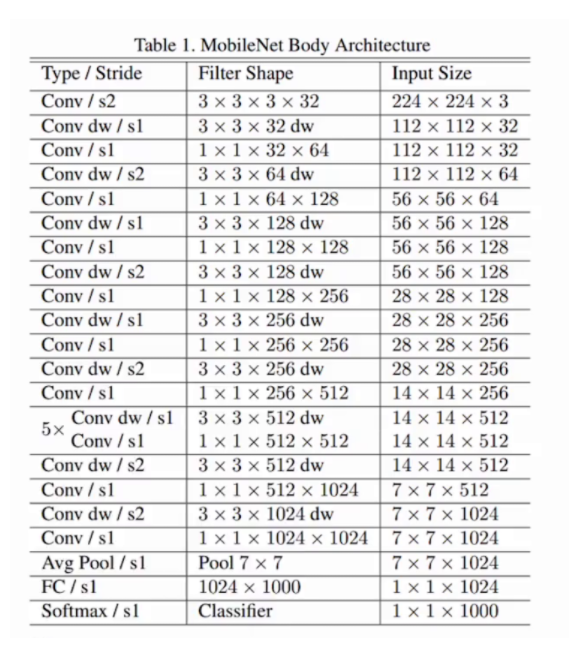
2. MobileNet V1 核心回顾
-
Depthwise Separable Convolution
- 先
3×3 DWConv(channel-wise) - 再
1×1 PWConv(point-wise) - 计算量降低约 8~9×。
- 先
-
两个超参数
- Width multiplier α 统一缩放通道数
- Resolution multiplier ρ 统一缩放输入分辨率
3. MobileNet V2 改进点
| 改进 | 动机 | 具体做法 |
|---|---|---|
| Inverted Residual | 解决 V1 信息坍塌 | 先 1×1 升维 → 3×3 DWConv → 1×1 降维 |
| Linear Bottleneck | 防止 ReLU 破坏 | 最后一个 1×1 后不加 ReLU |
| ReLU6 | 移动端量化友好 | min(max(x,0),6) |
| Shortcut | 复用特征 | 仅当 stride=1 且 in_channels==out_channels 时启用 |
结构示意:
4. ResNet 核心回顾
-
Residual Block
- 跳跃连接:
F(x) + x - 解决梯度消失,让 1000+ 层网络可训练。
- 跳跃连接:
-
两种 Block
- BasicBlock(小模型:18/34)
- Bottleneck(大模型:50/101/152)——使用
1×1降维/升维减少计算量。
-
下采样策略
- 当
stride=2或通道数改变时,shortcut 路径用1×1 Conv+stride=2对齐维度。
- 当
5. PyTorch 最小复现代码
环境:Python≥3.8,PyTorch≥1.10
运行:python main.py默认在 CIFAR-10 上训练 5 个 epoch 做演示。
5.1 项目结构
mbv2_resnet_demo/├─ main.py # 训练&验证├─ models.py # 三种网络定义└─ utils.py # 通用工具
5.2 models.py
import torch.nn as nn
import torch.nn.functional as F# ----------- MobileNet V1 -----------
class DepthwiseSeparable(nn.Module):def __init__(self, in_c, out_c, stride=1):super().__init__()self.depthwise = nn.Conv2d(in_c, in_c, 3, stride, 1, groups=in_c, bias=False)self.bn1 = nn.BatchNorm2d(in_c)self.pointwise = nn.Conv2d(in_c, out_c, 1, 1, 0, bias=False)self.bn2 = nn.BatchNorm2d(out_c)def forward(self, x):x = F.relu(self.bn1(self.depthwise(x)))x = F.relu(self.bn2(self.pointwise(x)))return xclass MobileNetV1(nn.Module):cfg = [64, (128, 2), 128, (256, 2), 256, (512, 2), 512, 512, 512, 512, 512, (1024, 2), 1024]def __init__(self, num_classes=10):super().__init__()self.conv1 = nn.Conv2d(3, 32, 3, 1, 1, bias=False)self.bn1 = nn.BatchNorm2d(32)self.layers = self._make_layers(in_planes=32)self.pool = nn.AdaptiveAvgPool2d(1)self.fc = nn.Linear(1024, num_classes)def _make_layers(self, in_planes):layers = []for c in self.cfg:out_planes = c if isinstance(c, int) else c[0]stride = 1 if isinstance(c, int) else c[1]layers.append(DepthwiseSeparable(in_planes, out_planes, stride))in_planes = out_planesreturn nn.Sequential(*layers)def forward(self, x):x = F.relu(self.bn1(self.conv1(x)))x = self.layers(x)x = self.pool(x).flatten(1)return self.fc(x)# ----------- MobileNet V2 -----------
class InvertedResidual(nn.Module):def __init__(self, in_c, out_c, stride, expand_ratio=6):super().__init__()hidden = int(round(in_c * expand_ratio))self.use_res_connect = stride == 1 and in_c == out_clayers = []if expand_ratio != 1:layers.append(nn.Conv2d(in_c, hidden, 1, 1, 0, bias=False))layers.append(nn.BatchNorm2d(hidden))layers.append(nn.ReLU6(inplace=True))layers.extend([nn.Conv2d(hidden, hidden, 3, stride, 1, groups=hidden, bias=False),nn.BatchNorm2d(hidden),nn.ReLU6(inplace=True),nn.Conv2d(hidden, out_c, 1, 1, 0, bias=False),nn.BatchNorm2d(out_c),])self.conv = nn.Sequential(*layers)def forward(self, x):if self.use_res_connect:return x + self.conv(x)return self.conv(x)class MobileNetV2(nn.Module):cfg = [(1, 16, 1, 1), (6, 24, 2, 1), (6, 32, 3, 2),(6, 64, 4, 2), (6, 96, 3, 1), (6, 160, 3, 2), (6, 320, 1, 1)]def __init__(self, num_classes=10):super().__init__()self.conv1 = nn.Conv2d(3, 32, 3, 1, 1, bias=False)self.bn1 = nn.BatchNorm2d(32)self.layers = self._make_layers()self.pool = nn.AdaptiveAvgPool2d(1)self.fc = nn.Linear(320, num_classes)def _make_layers(self):layers = []in_c = 32for t, c, n, s in self.cfg:for i in range(n):stride = s if i == 0 else 1layers.append(InvertedResidual(in_c, c, stride, t))in_c = creturn nn.Sequential(*layers)def forward(self, x):x = F.relu6(self.bn1(self.conv1(x)))x = self.layers(x)x = self.pool(x).flatten(1)return self.fc(x)# ----------- ResNet-18 -----------
class BasicBlock(nn.Module):expansion = 1def __init__(self, in_planes, planes, stride=1):super().__init__()self.conv1 = nn.Conv2d(in_planes, planes, 3, stride, 1, bias=False)self.bn1 = nn.BatchNorm2d(planes)self.conv2 = nn.Conv2d(planes, planes, 3, 1, 1, bias=False)self.bn2 = nn.BatchNorm2d(planes)self.shortcut = nn.Sequential()if stride != 1 or in_planes != self.expansion * planes:self.shortcut = nn.Sequential(nn.Conv2d(in_planes, self.expansion * planes, 1, stride, bias=False),nn.BatchNorm2d(self.expansion * planes))def forward(self, x):out = F.relu(self.bn1(self.conv1(x)))out = self.bn2(self.conv2(out))out += self.shortcut(x)return F.relu(out)class ResNet18(nn.Module):def __init__(self, num_classes=10):super().__init__()self.in_planes = 64self.conv1 = nn.Conv2d(3, 64, 3, 1, 1, bias=False)self.bn1 = nn.BatchNorm2d(64)self.layer1 = self._make_layer(64, 2, 1)self.layer2 = self._make_layer(128, 2, 2)self.layer3 = self._make_layer(256, 2, 2)self.layer4 = self._make_layer(512, 2, 2)self.pool = nn.AdaptiveAvgPool2d(1)self.fc = nn.Linear(512, num_classes)def _make_layer(self, planes, blocks, stride):layers = [BasicBlock(self.in_planes, planes, stride)]self.in_planes = planes * BasicBlock.expansionfor _ in range(1, blocks):layers.append(BasicBlock(self.in_planes, planes, 1))return nn.Sequential(*layers)def forward(self, x):x = F.relu(self.bn1(self.conv1(x)))x = self.layer4(self.layer3(self.layer2(self.layer1(x))))x = self.pool(x).flatten(1)return self.fc(x)
5.3 main.py
import torch, torchvision, time
from models import MobileNetV1, MobileNetV2, ResNet18device = 'cuda' if torch.cuda.is_available() else 'cpu'
batch_size = 128
epochs = 5
lr = 1e-3train_loader = torch.utils.data.DataLoader(torchvision.datasets.CIFAR10(root='./data', train=True, download=True,transform=torchvision.transforms.ToTensor()),batch_size=batch_size, shuffle=True, num_workers=4)test_loader = torch.utils.data.DataLoader(torchvision.datasets.CIFAR10(root='./data', train=False,transform=torchvision.transforms.ToTensor()),batch_size=batch_size, shuffle=False, num_workers=4)def train(model):model.to(device)opt = torch.optim.Adam(model.parameters(), lr=lr)loss_fn = torch.nn.CrossEntropyLoss()for epoch in range(epochs):model.train()tic = time.time()for x, y in train_loader:x, y = x.to(device), y.to(device)opt.zero_grad()loss_fn(model(x), y).backward()opt.step()print(f'Epoch {epoch+1} done in {time.time()-tic:.1f}s')if __name__ == '__main__':net = MobileNetV2() # 可换成 ResNet18() / MobileNetV1()print(net)train(net)
6. 总结 & 何时选谁?
| 场景 | 首选模型 | 理由 |
|---|---|---|
| 服务器高精度 | ResNet-50/101 | 精度高、训练稳定 |
| 手机端实时 | MobileNetV2 | 参数少 + 高帧率 |
| 超轻量级 MCU | MobileNetV1+α=0.25 | 极致压缩,量化后 < 1 M |
7. 参考资料
- MobileNetV1 paper: arXiv:1704.04861
- MobileNetV2 paper: arXiv:1801.04381
- ResNet paper: arXiv:1512.03385
码字不易,欢迎点赞收藏转发~