Hadoop MapReduce 3.3.4 讲解~


✨博客主页: https://blog.csdn.net/m0_63815035?type=blog
💗《博客内容》:.NET、Java.测试开发、Python、Android、Go、Node、Android前端小程序等相关领域知识
📢博客专栏: https://blog.csdn.net/m0_63815035/category_11954877.html
📢欢迎点赞 👍 收藏 ⭐留言 📝
📢本文为学习笔记资料,如有侵权,请联系我删除,疏漏之处还请指正🙉
📢大厦之成,非一木之材也;大海之阔,非一流之归也✨


目录
- 前言
- 设计思想
- 1. MapReduce的基本概念
- 2. MapReduce的核心组件
- 3. MapReduce的工作流程
- 4. MapReduce的数据处理模型
- 5. Shuffle机制详解
- 6. MapReduce的优化策略
- 7. MapReduce的应用场景
- 8. MapReduce与YARN的关系
前言
Hadoop是一个开源的分布式计算框架,主要用于处理和存储大规模数据集。它的设计初衷是解决海量数据的存储和计算问题,具有高容错性、高扩展性和低成本等特点。下面详细讲解Hadoop的核心知识点:
设计思想

1. MapReduce的基本概念
- 定义:一种分布式计算模型,用于处理海量数据的并行计算
- 核心思想:将复杂的计算任务分解为Map(映射)和Reduce(归约)两个阶段
- 优势:
- 自动实现并行处理
- 提供容错机制
- 处理PB级别的海量数据
- 适用于各种分布式计算场景
2. MapReduce的核心组件
- JobTracker:负责整个作业的调度和监控(Hadoop 1.x中,Hadoop 2.x中被YARN的ResourceManager替代)
- TaskTracker:运行在每个节点上,负责执行具体任务(Hadoop 1.x中,Hadoop 2.x中被YARN的NodeManager替代)
- Map Task:执行Map阶段的任务
- Reduce Task:执行Reduce阶段的任务
- InputSplit:输入数据的逻辑分片,每个分片由一个Map Task处理
- Combiner:可选的本地Reduce操作,用于减少Map输出的数据量
- Partitioner:决定Map输出的键值对分配到哪个Reduce Task
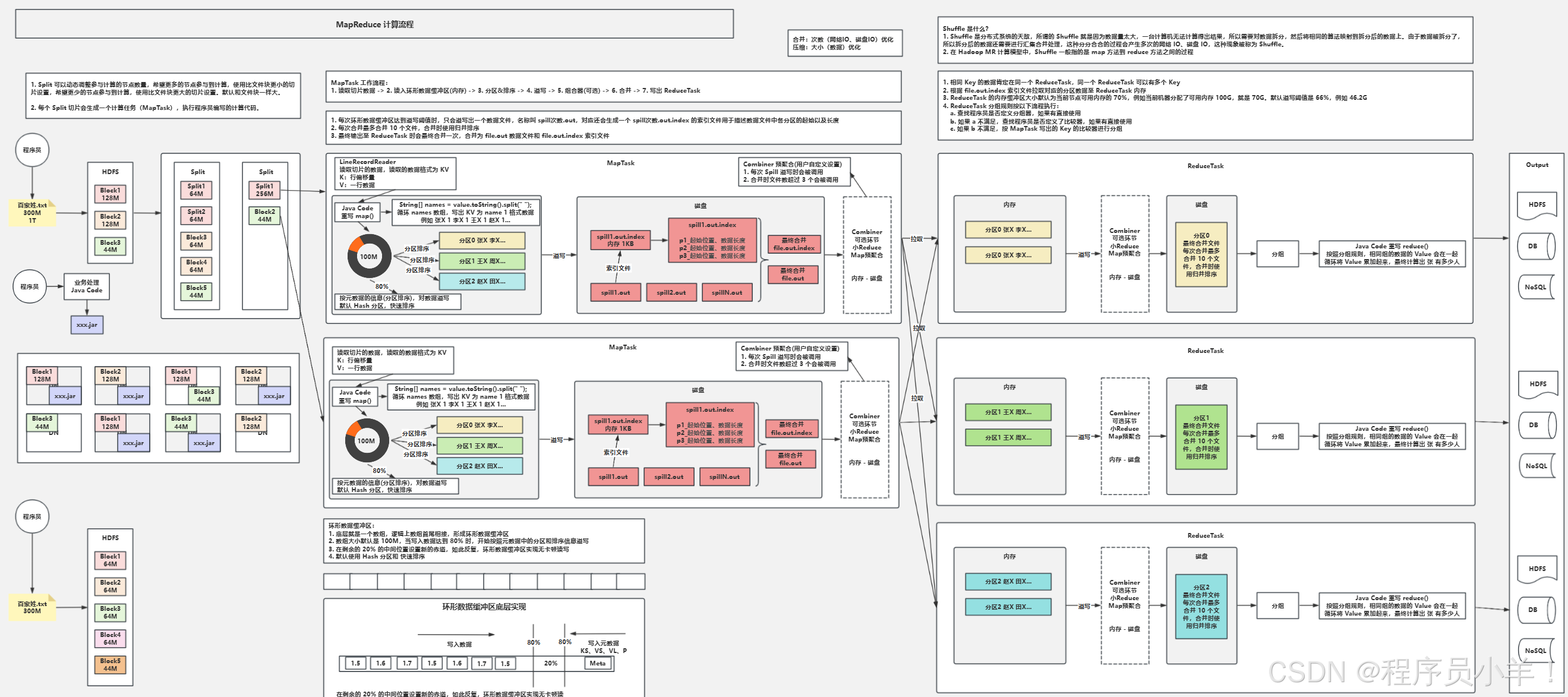
3. MapReduce的工作流程
-
输入分片(InputSplit)
- 将输入数据分割成多个InputSplit(通常与HDFS块大小一致)
- 每个InputSplit由一个Map Task处理
-
Map阶段
- 读取InputSplit中的数据,解析成键值对(K1, V1)
- 对每个键值对执行map函数,生成中间键值对(K2, V2)
- 示例:计算单词频率时,将(“文档1”, “hello world”)转换为(“hello”, 1)、(“world”, 1)
-
Shuffle阶段(核心)
- 分区(Partitioning):根据Partitioner将Map输出分到不同的分区
- 排序(Sorting):对每个分区内的键值对按键排序
- 合并(Combining):可选操作,对排序后的结果进行本地合并,减少数据传输
- 归并(Merging):将多个Map Task的输出合并成一个有序的数据集
-
Reduce阶段
- 读取Shuffle后的有序数据
- 对相同键的value集合执行reduce函数,生成最终键值对(K3, V3)
- 示例:将多个(“hello”, 1)合并为(“hello”, 5)
-
输出(Output)
- 将Reduce的输出写入到指定的存储系统(通常是HDFS)
4. MapReduce的数据处理模型
-
键值对:MapReduce的所有数据处理都基于键值对(Key-Value Pair)
-
数据类型:所有的Key和Value都必须实现Writable接口,常用类型包括:
- Text:用于字符串
- IntWritable:用于整数
- LongWritable:用于长整数
- DoubleWritable:用于浮点数
-
函数定义:
- Map函数:map(K1, V1) → list(K2, V2)
- Reduce函数:reduce(K2, list(V2)) → list(K3, V3)
5. Shuffle机制详解
Shuffle是MapReduce的核心,连接Map和Reduce阶段,负责数据的传输和处理:
-
Map端的Shuffle
- 环形缓冲区:Map输出先写入内存缓冲区(默认100MB)
- 溢出写(Spill):当缓冲区达到阈值(默认80%),将数据写入磁盘
- 合并溢出文件:将多个溢出文件合并成一个有序文件
-
Reduce端的Shuffle
- 拉取数据(Fetch):Reduce Task从各个Map Task拉取属于自己的分区数据
- 合并数据(Merge):将拉取的多个数据片段合并成一个大的有序数据集
- 分组(Grouping):将相同Key的Value合并成一个列表
6. MapReduce的优化策略
- 数据本地化:尽量将计算任务分配到数据所在的节点,减少网络传输
- Combiner使用:在Map端进行本地聚合,减少Shuffle阶段的数据量
- 合理设置Map和Reduce数量:根据数据大小和集群规模调整
- 压缩:对Map输出和中间数据进行压缩,减少IO操作
- JVM重用:在TaskTracker上重用JVM,减少启动开销
- 调整缓冲区大小:根据内存情况调整Map阶段的缓冲区大小
7. MapReduce的应用场景
- 日志分析:统计访问量、用户行为分析等
- 数据挖掘:关联规则挖掘、聚类分析等
- 机器学习:训练大规模数据集的模型
- 搜索引擎:网页排序、关键词统计等
- 数据转换:数据格式转换、数据清洗等
8. MapReduce与YARN的关系
在Hadoop 2.x中,MapReduce运行在YARN框架上:
- ResourceManager负责集群资源管理
- ApplicationMaster负责MapReduce作业的生命周期管理
- NodeManager负责单个节点的资源管理和任务执行
- Container为Map和Reduce任务提供计算资源
今天这篇文章就到这里了,大厦之成,非一木之材也;大海之阔,非一流之归也。感谢大家观看本文
