大模型×垂直领域:预算、时间、空间三重夹击下的生存法则
来gongzhonghao【图灵学术计算机论文辅导】,快速拿捏更多计算机SCI/CCF发文资讯~
众所周知,大模型虽展现出强大能力,但存在计算成本高、复杂场景处理能力不足、实际应用中易受冗余信息和模态歧义干扰等问题,因此对其高效优化与能力提升的需求愈发迫切。当下对这一方向的研究热情高涨,创新多围绕模型压缩加速、复杂任务评估基准构建、冗余与歧义问题解决等展开。
本文精选了3篇前沿论文,拆解其思路、创新点,帮你一键复现、快速延伸。满满干货,点赞收藏不迷路~
Short-LVLM: Compressing andAccelerating Large Vision-Language Models by Pruning Redundant Layers
方法:先用校准集计算每个token在视觉-语言双模态中的注意力得分,保留Top-k重要token并基于其余弦相似度定位冗余层;对被剪层与其最近保留层的特征差做SVD得到低秩子空间,将该子空间投影到保留层权重以重构被剪特征;整个过程仅需一次前向校准,无需梯度更新,即可在7B-13B的多种LVLM上实现1.2-1.4倍推理加速且性能几乎无损。
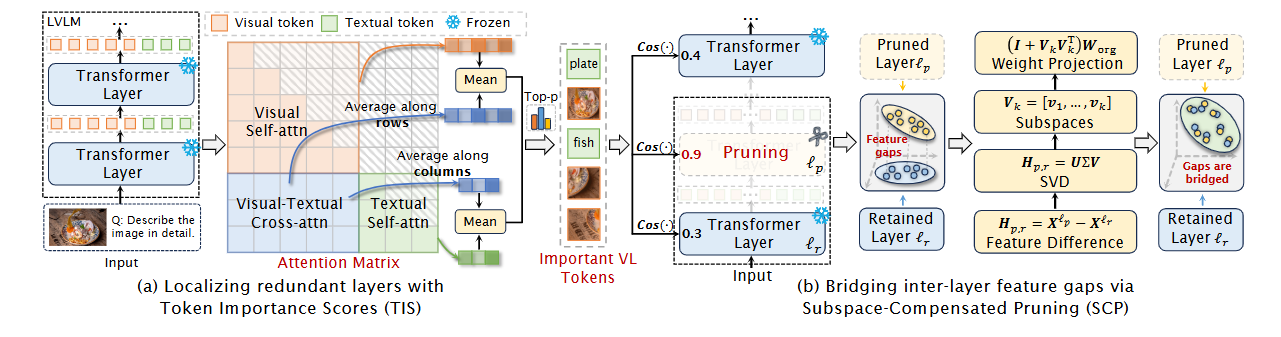
创新点:
提出Token Importance Score,通过自注意与跨注意联合打分过滤冗余视觉-语言token,实现精准冗余层定位;
设计Subspace-Compensated Pruning,用SVD提取被剪层与保留层特征差的低秩子空间并投影权重,弥合层间差距;
构建Short-LVLM框架,训练无关、模型无关、兼容量化和token裁剪,实现即插即用的LVLM压缩。
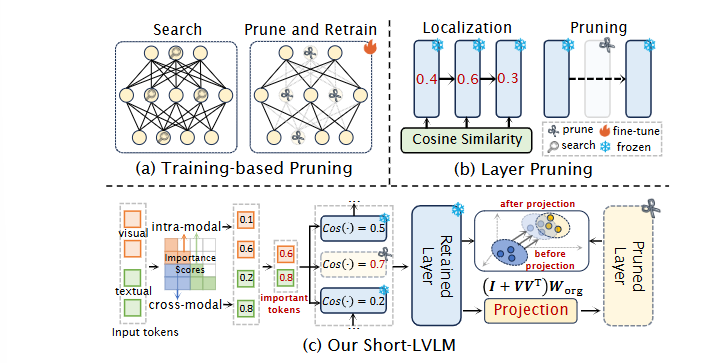
总结:这篇文章首次揭示大视觉-语言模型“层间冗余+跨模态噪声”双重陷阱,并给出无需训练即可砍掉40%层仍保持96%性能的方案,直接颠覆“剪层必重训”的定式。
MPCC: A Novel Benchmark for Multimodal Planning with Complex Constraints in Multimodal Large Language Models
方法:作者从航班、日程、会议三大真实场景出发,用代码生成初始实例后人工过滤并标注跨模态约束,确保视觉与文本均不可或缺;为每个任务设置预算、时序、空间三类约束并按参数调节难度,使搜索空间从27倍增至617,同时保证每例至少存在一个可行解;最终用可行率与最优率双指标对13个MLLM进行系统评估,并分析提示策略、模型规模及失败模式,为约束感知的多模态规划指出改进方向。
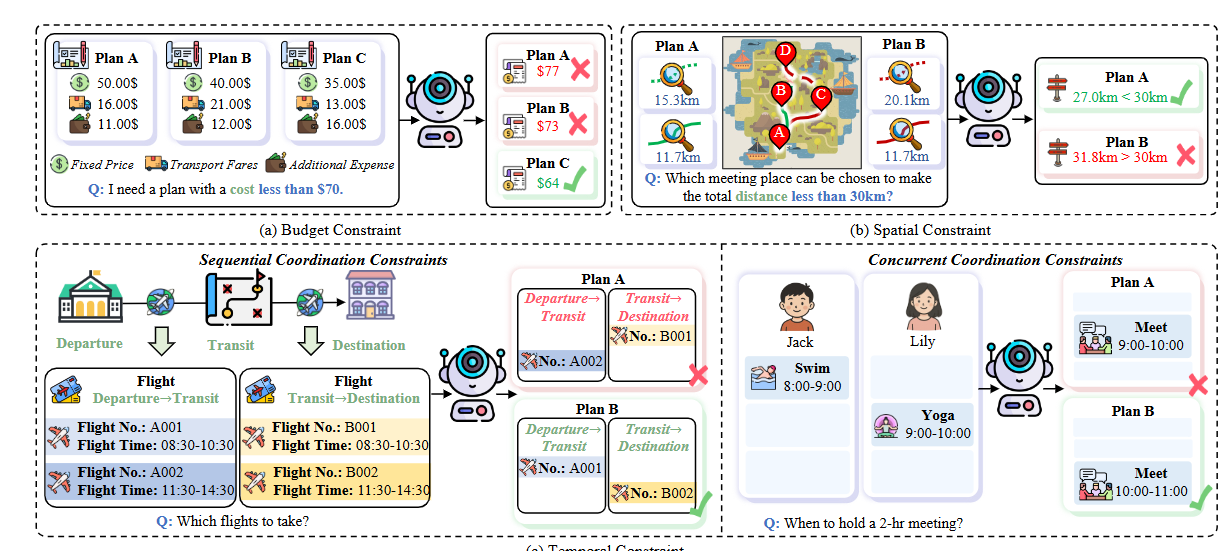
创新点:
提出“多模态约束”概念并构建MPCC基准,首次系统评估MLLM在真实规划任务中处理跨模态复杂约束的能力;
设计预算、时间、空间三类可分级复合约束,将难度与搜索空间解耦,实现从EASY到HARD的平滑挑战;
通过双重人工校验与暴力最优解标注,确保每例都有唯一最优方案,为后续研究提供可复现的严格评估框架。
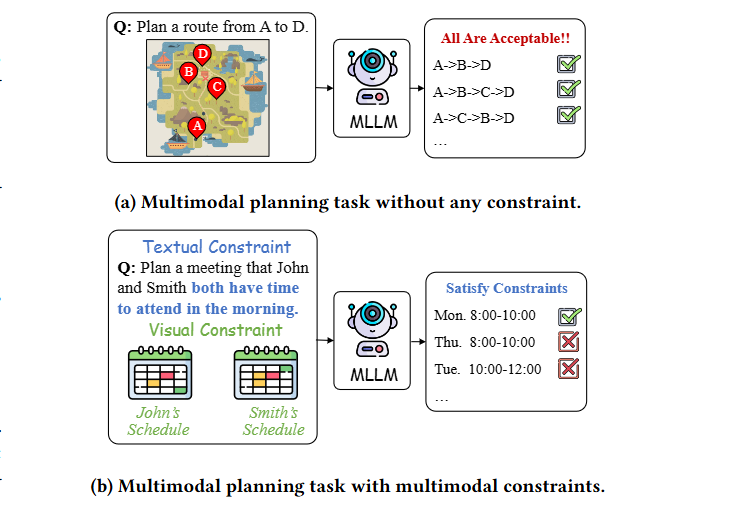
总结:这篇文章首次把“多模态+多约束”带进真实场景规划,用2700个任务揭示顶尖MLLM在预算、时间、空间三重夹击下平均可行率只有11%,直接暴露当前模型的规划盲区。
纠结选题?导师放养?投稿被拒?对论文有任何问题的同学,欢迎来gongzhonghao【图灵学术计算机论文辅导】,获取顶会顶刊前沿资讯~
Training-Free Class Purification for Open-Vocabulary Semantic Segmentation
方法:先用CLIP的图像-文本亲和生成初始类激活图,再用跨层自注意构建的自亲和矩阵精炼;随后计算精炼前后激活的IoU并设阈值剔除冗余类别,再对剩余类别按IoU聚类发现歧义组,在局部区域用LLM生成的细粒度描述重新投票定位;最终保留类别经argmax得到像素级分割,全过程无需训练,仅依赖一次前向推理。
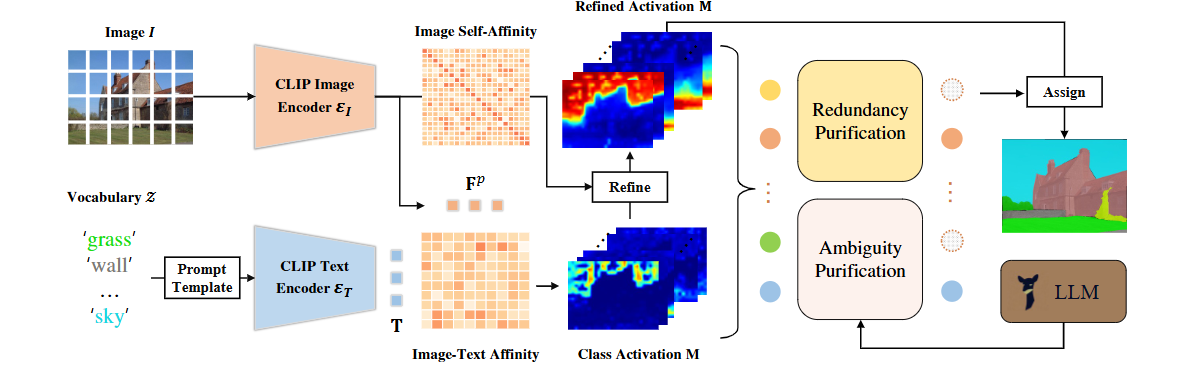
创新点:
首次将类别冗余与视觉-语言歧义形式化为OVSS核心瓶颈,并用激活图一致性给出可解释量化指标;
提出两阶段无训练框架FreeCP,仅用IoU阈值+LLM细粒度描述即可滤除冗余并消解歧义;
设计即插即用模块,可与任何CLIP系方法无缝组合,在零额外训练条件下刷新八项基准SOTA。
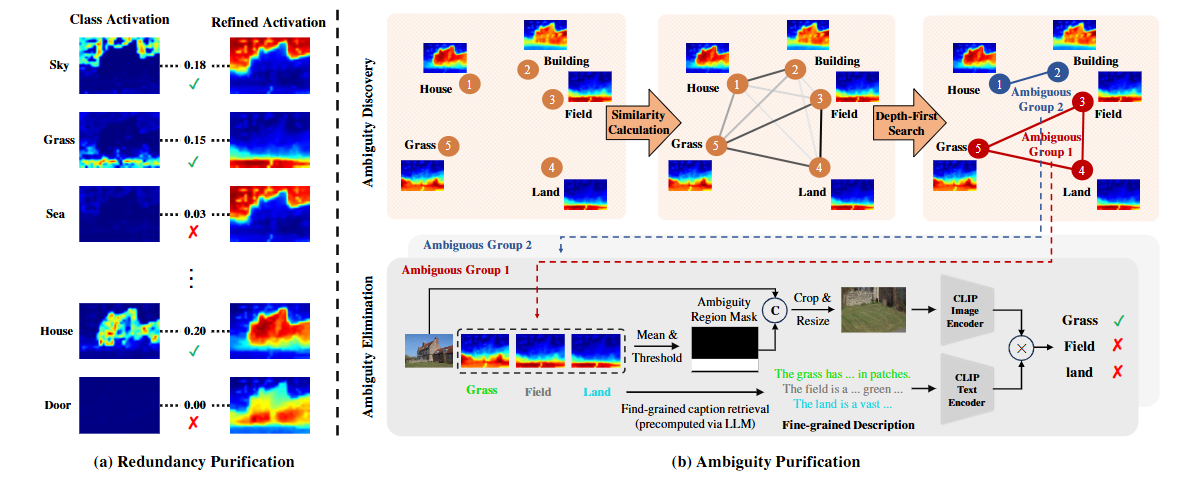
总结:这篇文章把“零训练开放词汇分割”从原型微调升级为类别净化,直击海量冗余类别与视觉-语言歧义两大顽疾,让MaskCLIP等基线方法在八个基准上的mIoU瞬间提升10%+。
来gongzhonghao【图灵学术计算机论文辅导】,快速拿捏更多计算机SCI/CCF发文资讯~