外设数据到昇腾310推理卡 之五 3403ATU
目录
存储器事务地址空间
ATU 两个方向
outbond
inbond
3403 outbond示例
ATU_REGION_CTRL2
寄存器相关位说明
inbound方向的默认配置
310i pro inbound方向的默认配置
外设到推理卡
总结
存储器事务地址空间
| 地址空间类型 | 大小 | 起始地址 | 结束地址 | 说明 |
| 存储器事务地址空间 | 256M | 0x030000000 | 0x03FFFFFFF | 在此空间内的读写操作将在 PCIe 链路上转换为PCIe 协议所定义的存储器读写事务(需地址转换功能配合,地址转换功能请参考地地址转换单元ATU(Address Translation Unit ))。 |
| 扩展存储器事务地址空间 | 4G | 0x3 0000 0000 | 0x3 FFFF FFFF | 支持大地址空间扩展为PCIe 存储器事务地址空间。 在此空间内的读写操作将在 PCIe 链路上转换为PCIe 协议所定义的存储器读写事务(需地址转换功能配合,地址转换功能请参考地址转换单元ATU(Address Translation Unit ))。 |
ATU 两个方向
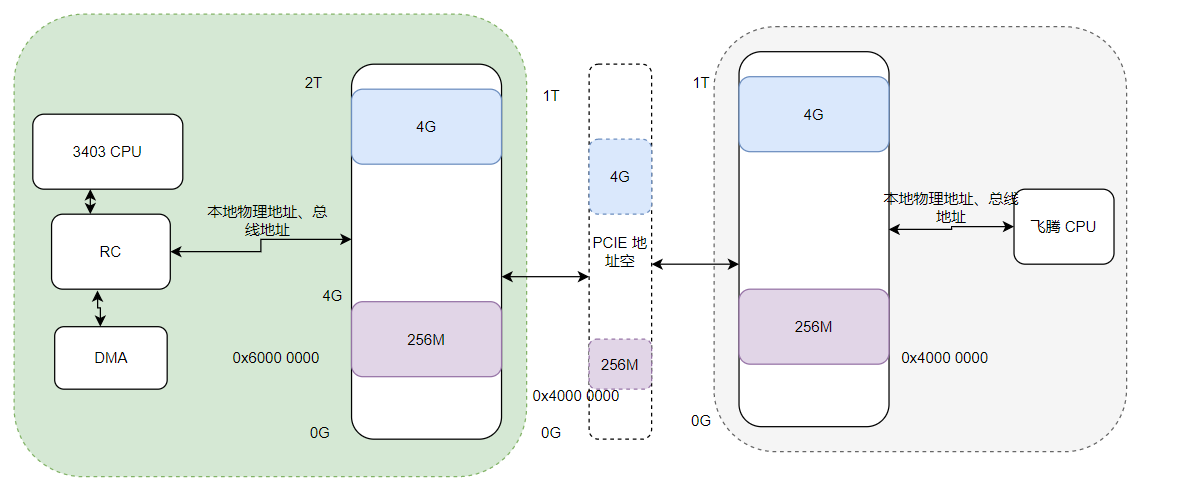
outbond
即3403 作为事务的发起方。从CPU 地址空间 流转到PCIE地址空间的过程。
inbond
即3403 作为事务的接收方。从PCIE地址空间流转到CPU 地址空间 的过程。
3403 outbond示例
3403 DMA作为主,发起请求事务,从飞腾CPU内存读取数据。
* 1) 采用映射表项2
* 2) 3403侧的地址为0x30000000,即3403对此地址段访问就可以访问到对端内存
* 3) RC侧的基地址为 0x22_0000_0000
* 4)3403侧限制了共享内存的大小,即为256Mstruct dev_addr atu_addr;atu_addr.phy_addr = 0x103D0000;atu_addr.virt_addr = 0;atu_addr.reg_len = 0x1000;if (NULL == ioremap_system_mem(&atu_addr))return -1;write_reg(atu_addr.virt_addr, 0x900, 2); //采用映射表2,支持8个映射表write_reg(atu_addr.virt_addr, 0x90c, 0x30000000); //映射的源地址,即3403侧的地址write_reg(atu_addr.virt_addr, 0x914, 0x3fffffff); //映射地址的空间大小,总共256M#if 0 //固定内存地址write_reg(atu_addr.virt_addr, 0x918, 0);write_reg(atu_addr.virt_addr, 0x91c, 0x22);
#elsewrite_reg(atu_addr.virt_addr, 0x918, g_buffer_base); //映射到的目的地址,write_reg(atu_addr.virt_addr, 0x91c, g_buffer_base >> 32); //映射到的目的地址的高位
#endifprintf("buffer base addr:0x%llx\n", g_buffer_base);write_reg(atu_addr.virt_addr, 0x904, 0);write_reg(atu_addr.virt_addr, 0x908, 0x80000000); //使能此区域1) 采用映射表2
2) 设置3403侧的源地址
3) 设置PCIE侧的目的地地址。
4) 使能此region。当3403访问0x3000 0000~0x3fff ffff之间的区域时,通过ATU 翻译到中间地址空间的目的地址,而飞腾端不需要配置ATU或者说pcie地址空间与飞腾CPU地址空间是一一对应的,即可以访问到飞腾CPU设备。
ATU_REGION_CTRL2
通过这一组寄存器,可以实现对发送方向和接收方向的各 8 个地址转换区的配置

寄存器相关位说明
1) 匹配模式。地址匹配 or bar 匹配模式。
在上述的outbond例程中,我们采用了地址匹配模式。
在后续的inbound使用中,我们采用BAR 匹配模式。
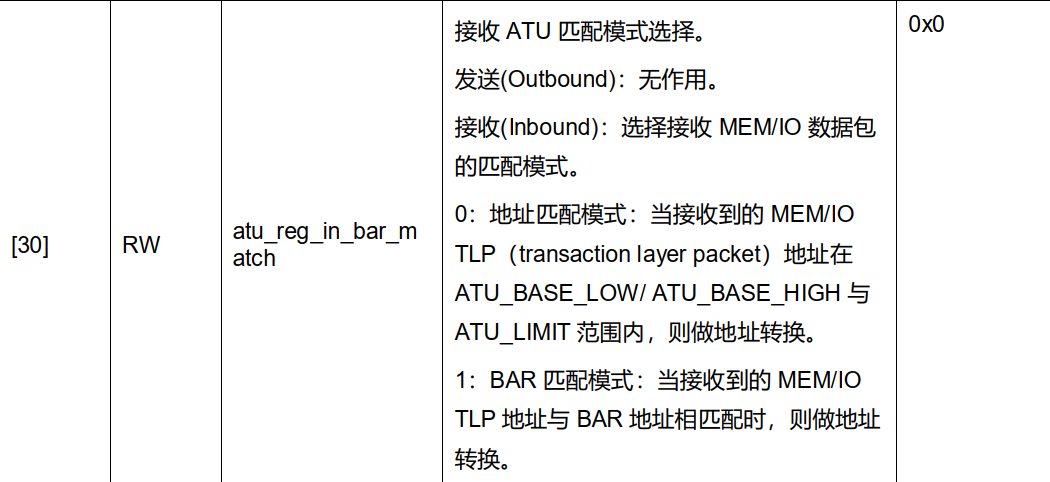
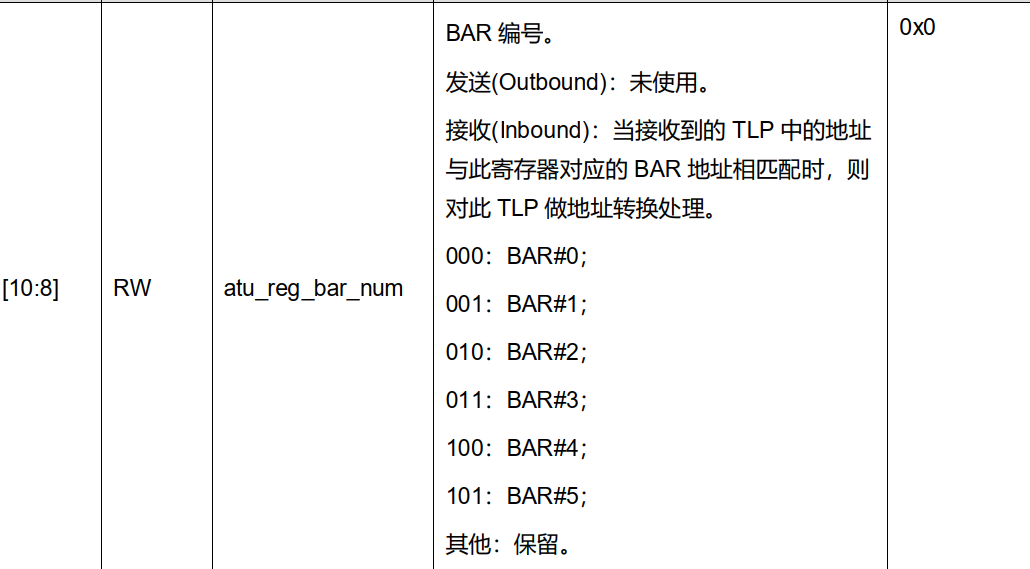
2) bar的编号
inbound方向的默认配置
[root@localhost ~]# lspci -vv -s b:0.0
0b:00.0 Multimedia controller: Hunan Goke Microelectronics Co., Ltd Device 0928 (rev 02)Control: I/O- Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr- Stepping- SERR- FastB2B- DisINTx-Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx-Latency: 0Interrupt: pin A routed to IRQ 255NUMA node: 0Region 0: Memory at 800 65800000 (32-bit, non-prefetchable) [size=8M]Region 1: Memory at 800 66200000 (32-bit, non-prefetchable) [size=64K]Region 2: Memory at 800 66000000 (32-bit, non-prefetchable) [size=1M]Region 3: Memory at 800 66100000 (32-bit, non-prefetchable) [size=1M]Region 4: Memory at 800 66210000 (32-bit, non-prefetchable) [size=64K]Region 5: Memory at 800 66220000 (32-bit, non-prefetchable) [size=4K]310i pro inbound方向的默认配置
Region 0: Memory at 58000000 (64-bit, non-prefetchable) [size=8M]
Region 2: Memory at 1020000000 (64-bit, prefetchable) [size=128M]
Region 4: Memory at 1000000000 (64-bit, prefetchable) [size=512M]是否和3403非常像。
外设到推理卡
此时我们需要3403侧配置为inbound,采用bar4 映射到3403 或者310i pro 的某段内存。
通过类似outbond的简单配置,就可以实现如下红色线部分RC都512M内存的读写。
而FPGA通过绿色线访问512M内存,则需要走P2P流程。
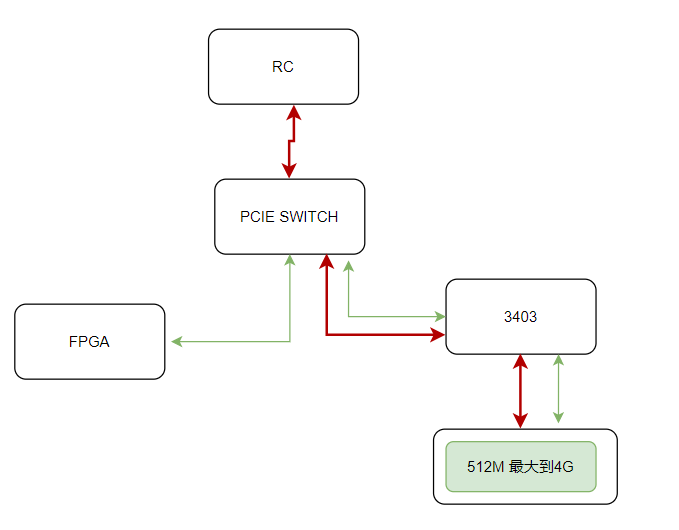
总结
虽然我们无从知晓AI卡的详细设计,但通过分析3403的实现及AI卡的外部信息,可以窥测内部实现是一脉相承的。
通过对外的编程接口文档《CANN社区版 8.1.RC1.alpha001 AscendCL应用软件开发指南(C&C++) 01.pdf》说明:

也可以知晓上述的实现是完全可行。
310i pro此region 4的实现大概率是滑动的,毕竟region大小只有4G,而模块内存为24G或者48G
英伟达在这方面已经做的比较完善,详细可以参考: (81 封私信) 【研究综述】浅谈GPU通信和PCIe P2P DMA - 知乎