Java——数组及Java某些方法、二维数组
文章目录
- 为什么要使用数组
- 什么是数组
- 数组的创建及初始化
- 数组的创建
- 数组的初始化
- 数组的使用
- 数组中元素访问
- 遍历数组
- 循环的方式遍历数组
- for-each的方式遍历数组
- 用工具类的方式遍历数组
- 数组是引用类型
- 初始JVM的内存分布
- 基本类型变量与引用类型变量的区别
- 数组练习
- 数组转字符串
- 求数组中元素的平均值
- 查找数组中指定元素(顺序查找)
- 二分查找
- 冒泡排序
- 数组拷贝
- 第一种拷贝方法
- 第二种拷贝方法
- 第三种拷贝方法
- equals方法
- fill方法
- 二维数组
- for循环遍历二维数组
- for-each来遍历二维数组
- 使用Java方法
为什么要使用数组
假设现在要存5个学生的成绩,并进行输出,按照之前我们掌握的知识点,我们会写出如下代码:
public static void main(String[] args) {int score1=70;int score2=80;int score3=85;int score4=60;int score5=90;System.out.println(score1);System.out.println(score2);System.out.println(score3);System.out.println(score4);System.out.println(score5);}
这段代码没有任何问题,但不好的是:万一有50个学生成绩呢?需要创建50个变量吗?这肯定是不现实的。
仔细观察可以发现:所以成绩的类型都是相同的,那Java中可以存储相同类型的多个数据吗?这就是数组。
什么是数组
数组:可以看成是相同类型的一个集合,在内存中是一段连续的空间。
比如现实中的车库:
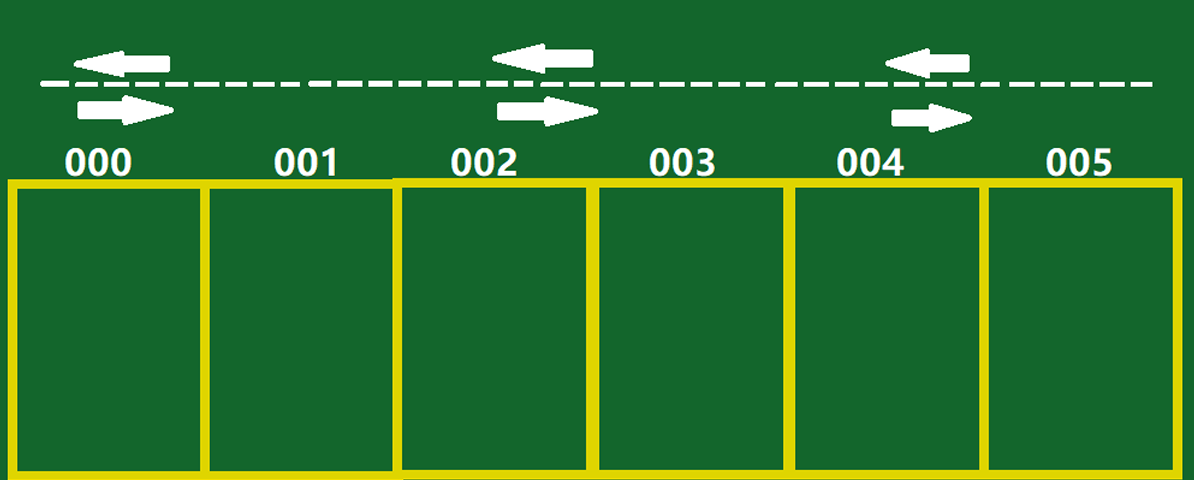
在Java中,包含6个整型类型元素的数组,就相当于上图中连在一起的6个车位,从上图中可以看到:
- 数组中存放的元素其类型相同
- 数组的空间是连在一起的
- 每个空间都有自己的编号
那在程序中如何创建数组呢?
数组的创建及初始化
创建了一个数组array
int[] array={1,2,3,4,5,6};
这个array是一个变量,存的是这个数组的地址0x99(可以理解为array存了这个数组的首元素地址,但在Java中一般说array存的是数组的地址)
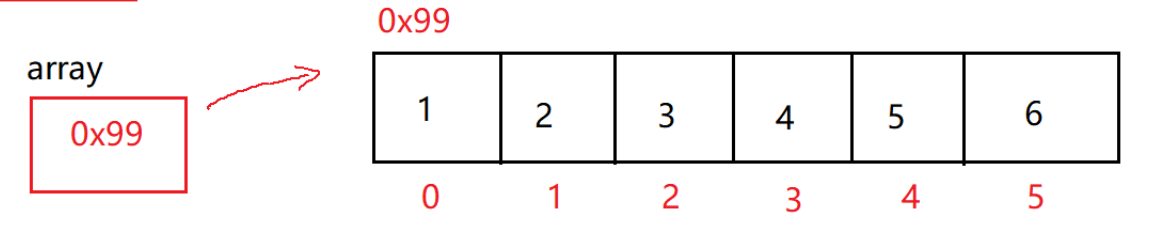
把array这种存了数组的地址的变量叫做“引用变量”,简称“引用”。
再创建一个数组array2
int[] array={1,2,3,4,5,6};
//第一种写法
int[] array2=new int[]{1,2,3,4,5,6};
//第二种写法
那么这两种写法有区别吗?
没有,第一种写法是语法上的简写,这两种写法没区别。第二种写法中的new这个关键字在Java中使用频率很高,一般是指创建新的对象。
既然new了一个新的对象,那么数组{1,2,3,4,5,6},就叫做数组对象
数组的创建
T[] 数组名=new T[N]
- T:表示数组中存放元素的类型
- T[ ]:表示数组的类型
- N:表示数组的长度
像
int[] array=new int[]{1,2,3,4,5};这种定义,左边的int[]是声明变量的类型,说明array这个变量是用来存放整数数组的;右边new后面的int[]是创建数组对象时指定的类型,说明要创建的是一个整数数组。
两者前后呼应,保证了变量类型和所赋值的对象类型一致
注:
int说明数组中存储的元素类型是整数[]是数组的标志
int[] array1=new int[10];
//创建一个可以容纳10个int类型元素的数组
double[] array2=new double[5];
//创建一个可以容纳5个double类型元素的数组
String[] array3=new String[3];
//创建一个可以容纳3个字符串元素的数组
所以,数组的创建可以有这三种方法:
int[] array1={1,2,3,4,5,6};
int[] array2=new int[6];
int[] array3=new int[]{1,2,3,4,5,6};
数组的初始化
数组的初始化主要分为动态初始化和静态初始化
- 动态初始化:在创建数组时,直接指定数组中元素的个数
int[] array=new int[10];
- 静态初始化:在创建数组时不直接指定数据元素个数,而直接将具体的数据内容进行指定
T[] 数组名称={data1,data2,data3,...,datan};
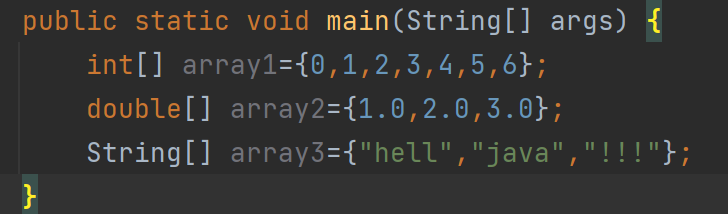
int[] array1=new int[]{0,1,2,3,4,5,6};
double[] array2=new double[]{1.0,2.0,3.0};
String[] array3=new String[]{"hell","java","!!!"};
注意:
- 静态初始化虽然没有指定数组的长度,编译器在编译时会根据
{}中元素个数来确定数组的长度 - 静态初始化时,
{}中数据类型必须与[]前数据类型一致 - 静态初始化可以简写,省去后面的
new T[]
注意:虽然省去了new T[],但编译器编译代码时还是会还原 - 数组也可以按照如下C语言个数创建,但不推荐
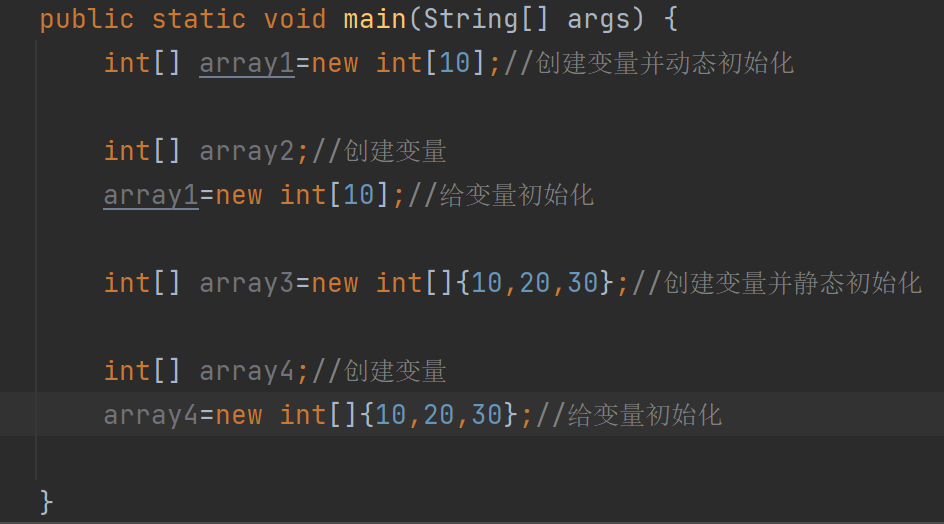
因为数组的类型是int[],用C语言方式创建容易造成数组的类型是int的误解 - 静态和动态初始化也可以分为两步
但是不可以省略格式
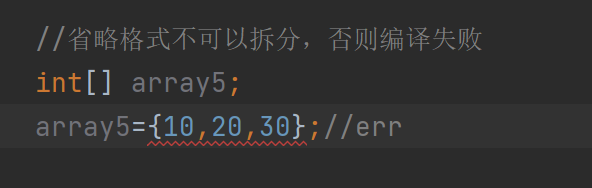
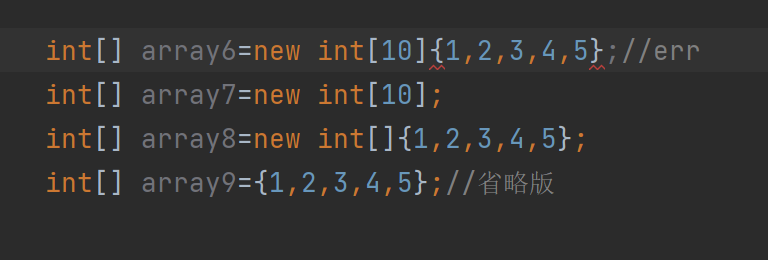
并且这种写法也是错误的:

要么只写[]里面的,要么只写{}里面的
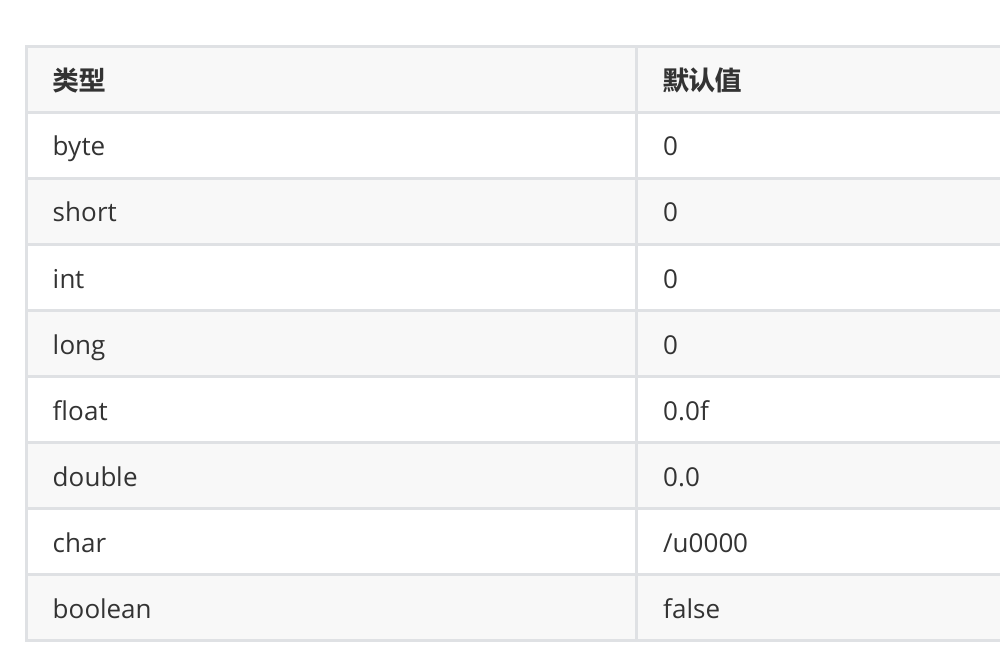
- 如果没有对数组进行给值,数组中元素是其默认值。
如果数组中存储元素类型为基类类型,默认值为基类类型对应的默认值,比如
如果数组中存储元素类型为引用类型,默认值为null
int[] array1=new int[10];
像这种定义是动态初始化了,但并没有给值,所以默认里面所有的值为0。
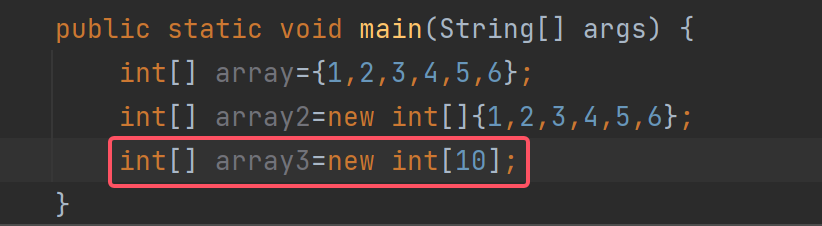
也就是array3这个引用指向长度为10个int,数据都是0的数组
我们调试观察一下:
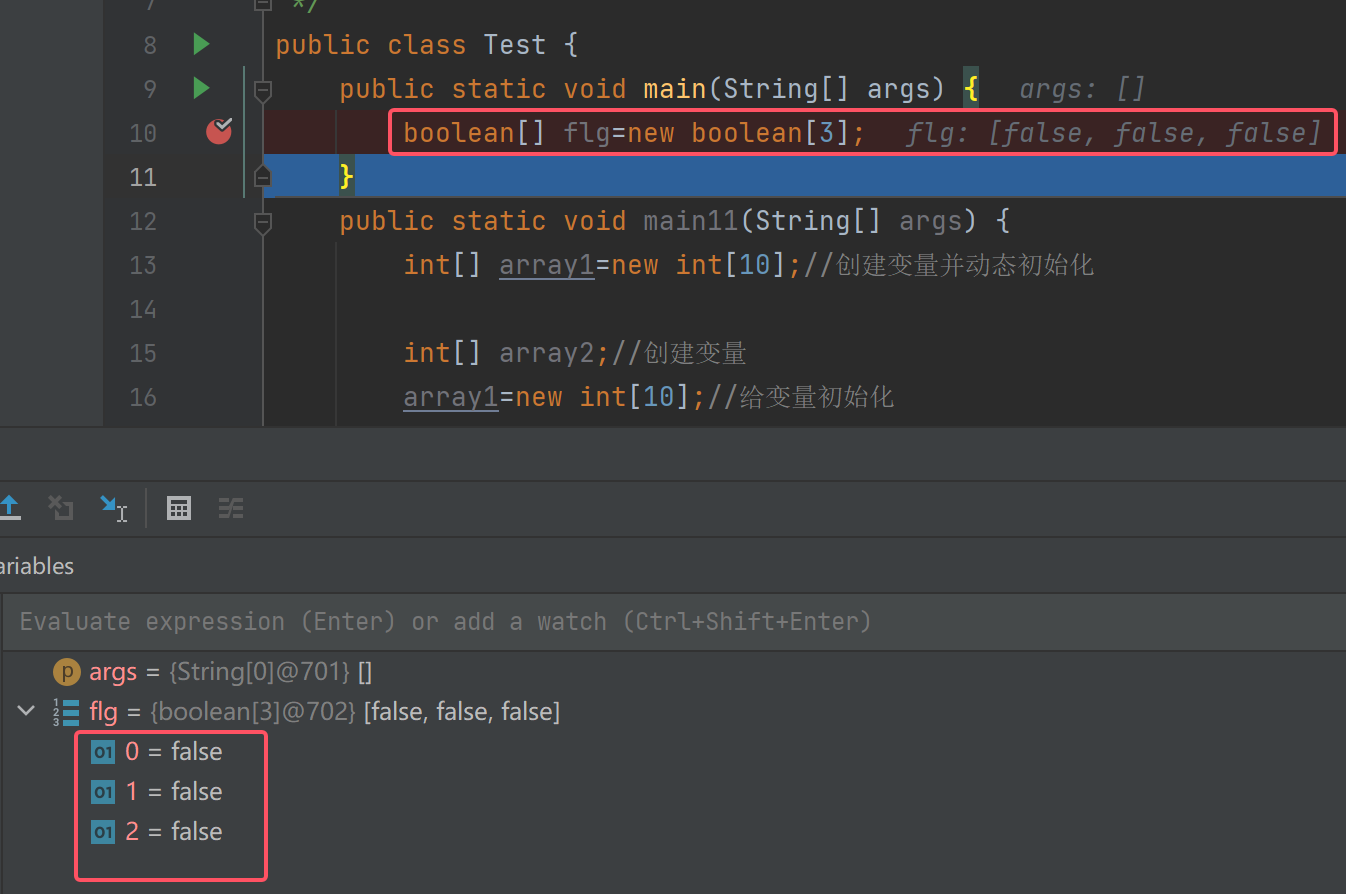
我们并没有给这个数组值,所以三个元素的值都是默认值false.
所以boolean[]类型的数组默认值是false
数组的使用
数组中元素访问
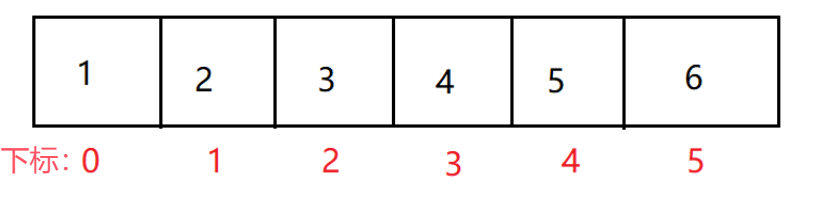
数组在内存中是一段连续的空间,空间编号都是从0开始的,依次递增,该编号称为数组的下标,数组可以通过下标访问其任意位置的元素。
比如:
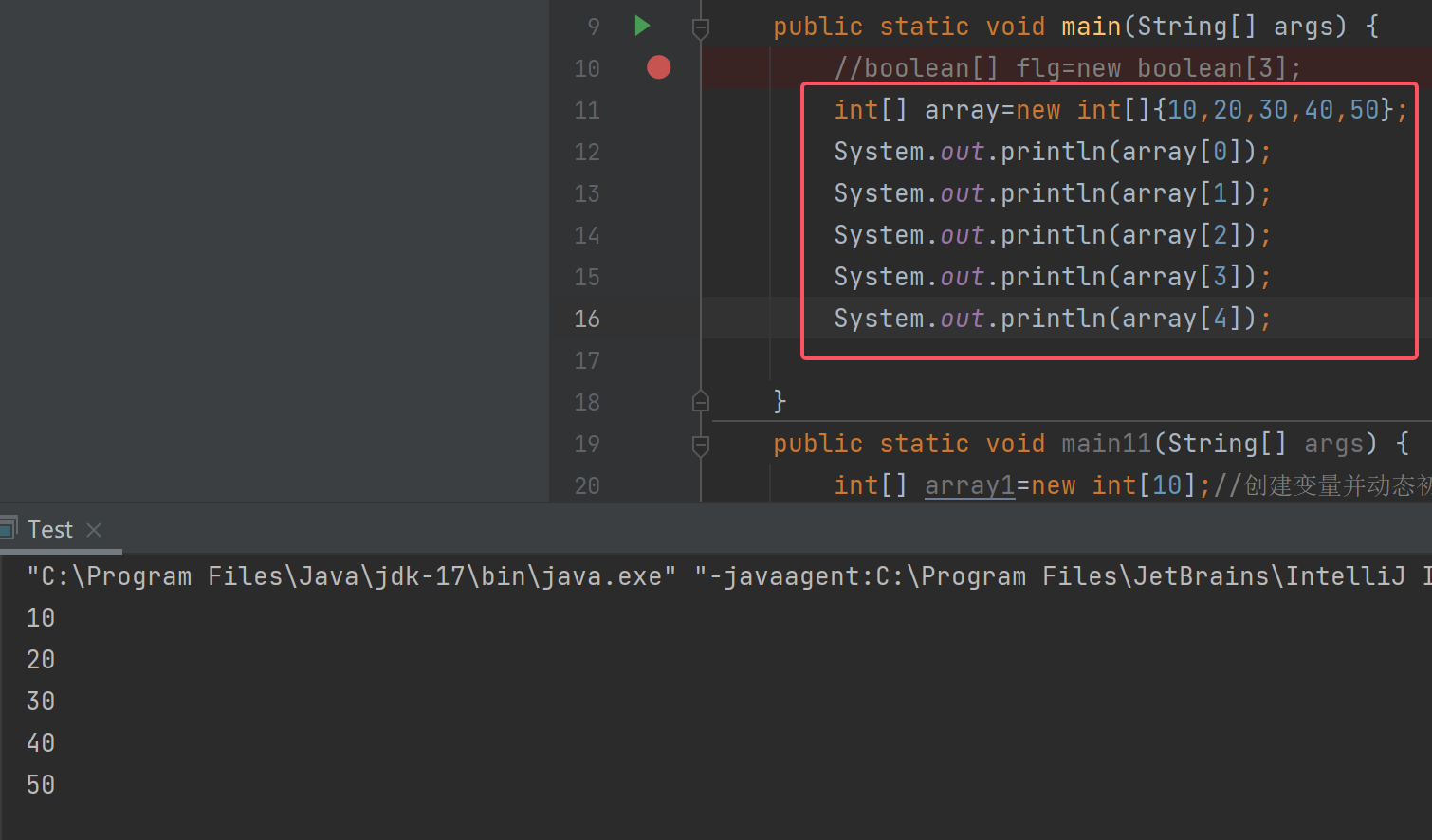
也可以通过[]对数组中的元素进行修改
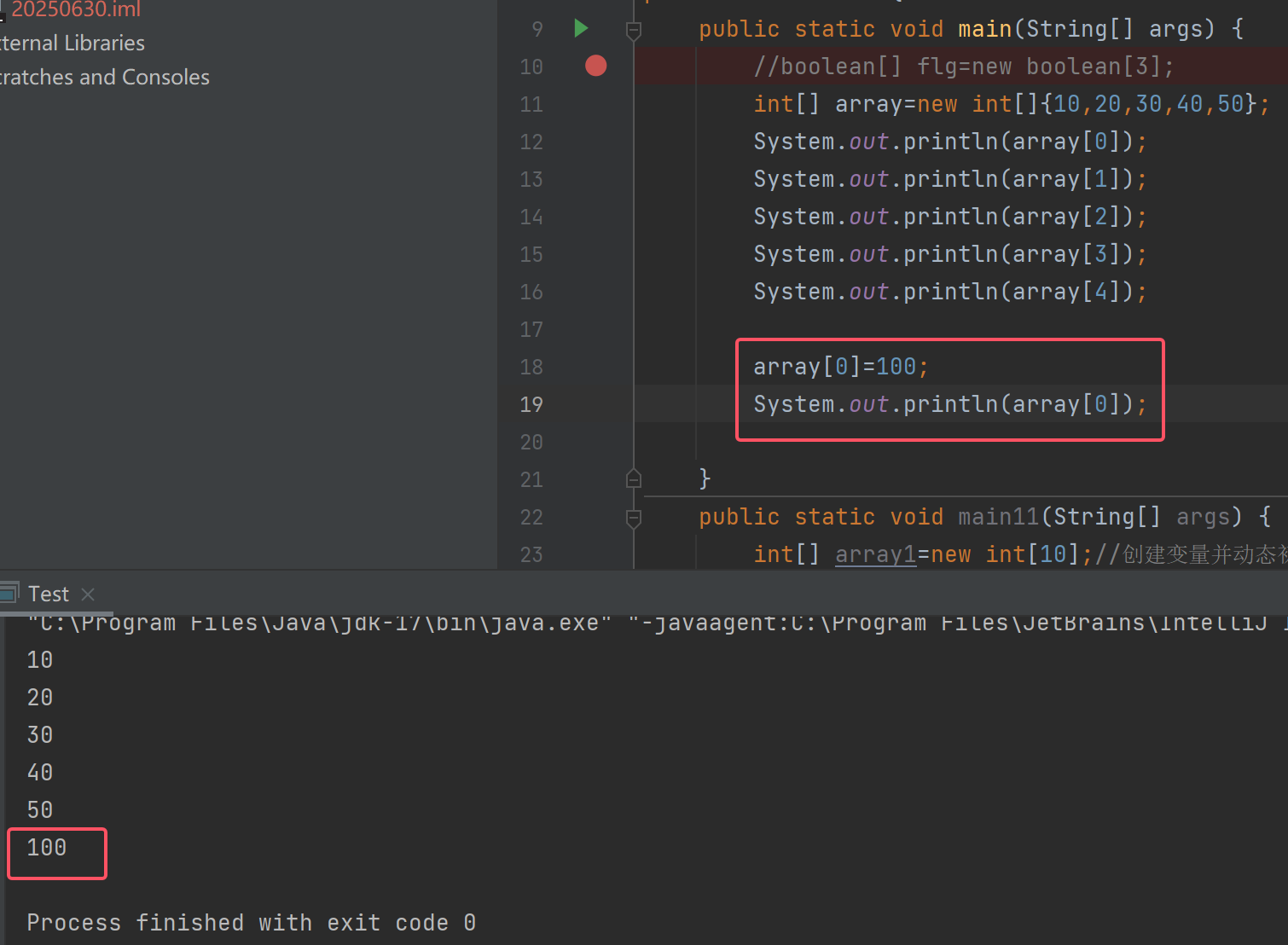
注意:
- 数组是一段连续的内存空间,因此支持随机访问,即通过下标访问快速访问数组中任意位置的元素
- 下标从
0开始,介于[0,N)之间不包含N,N为元素个数,不能越界,否则会报出下标越界异常
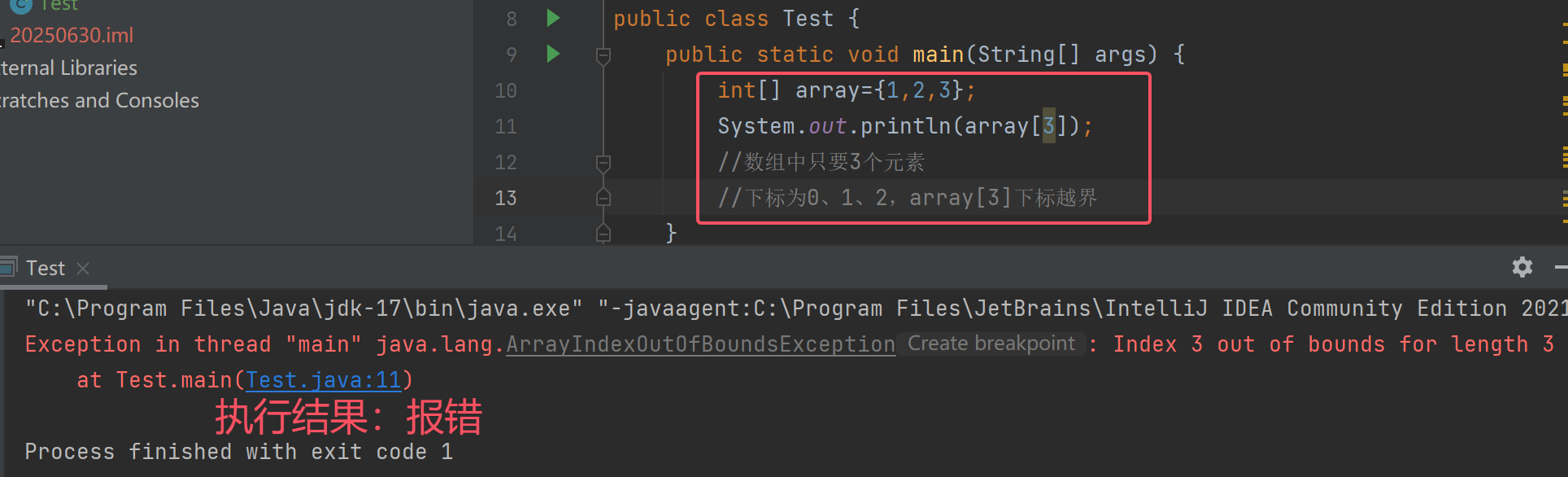
抛出了java.lang.ArrayIndexOutOfBoundsException异常,使用数组一定要谨防下标越界
遍历数组
所谓遍历是指将数组中的所以元素都访问一遍,访问是指对数组中的元素进行某种操作,比如:打印
int[] array=new int[]{10,20,30,40,50};System.out.println(array[0]);System.out.println(array[1]);System.out.println(array[2]);System.out.println(array[3]);System.out.println(array[4]);
上述代码可以起到对数组中元素遍历的目的,但问题是:
- 如果数组中增加了一个元素,就需要增加一条打印语句
- 如果输入中有100个元素,就需要写100个打印语句
- 如果要把打印修改为:给数组中每个元素+1,修改起来非常麻烦
循环的方式遍历数组
通过观察代码可以发现,对数组中每个元素的操作都是相同的,则可以使用循环来进行打印
int[] array=new int[]{10,20,30,40,50};
for(int i=0;i<5;i++){System.out.println(array[i]);
}
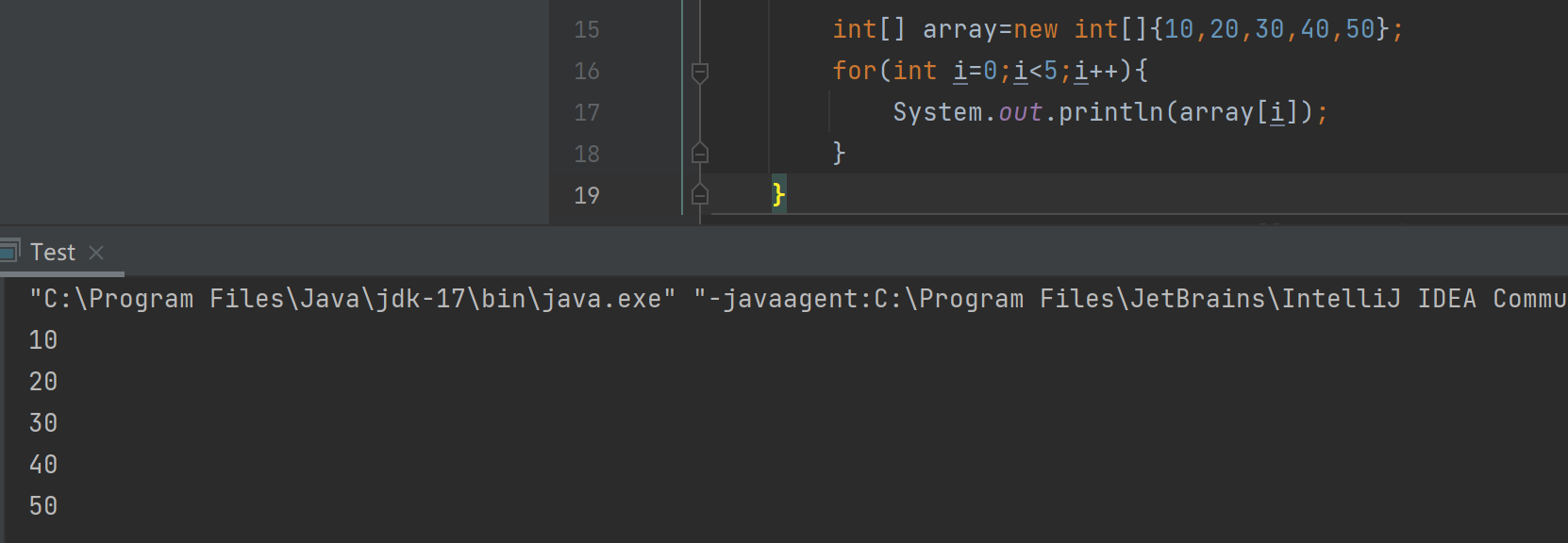
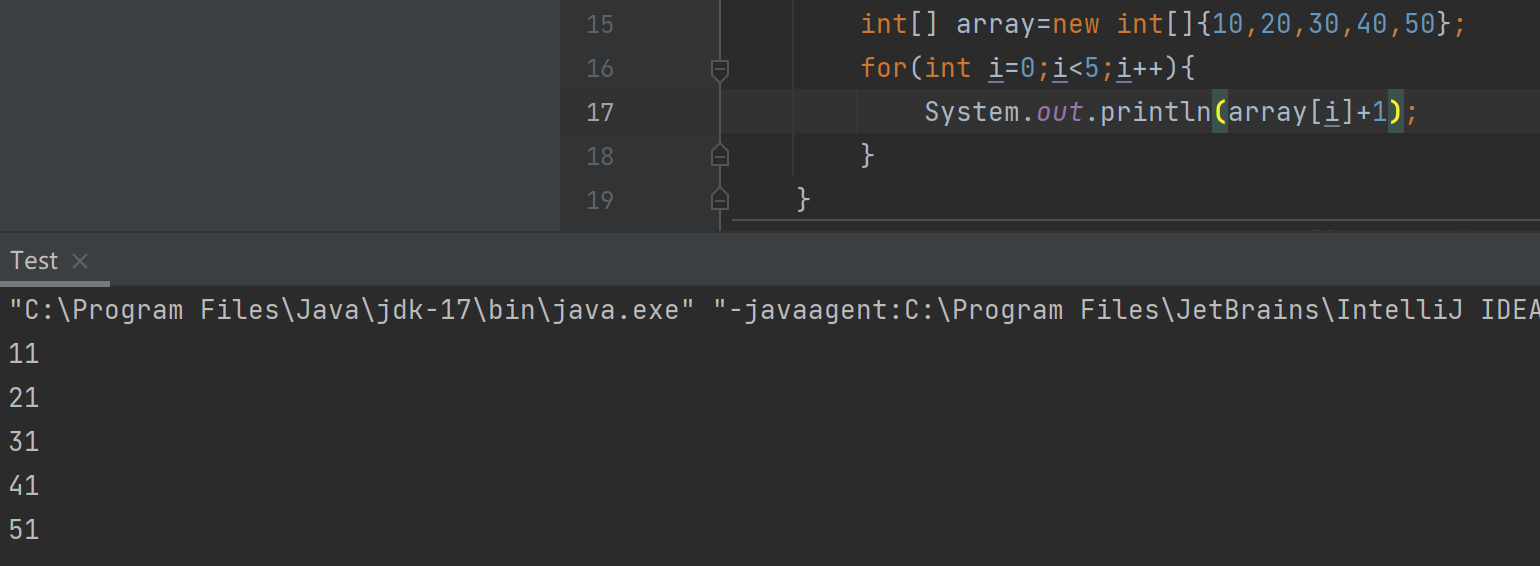
改成循环之后,上述问题2和3可以全部解决,但是无法解决问题1。
那能否获取数组的长度呢?
在数组中可以通过数组对象.length来获取数组的长度
int[] array=new int[]{10,20,30,40,50,60,70};
for(int i=0;i<array.length;i++){System.out.println(array[i]);
}
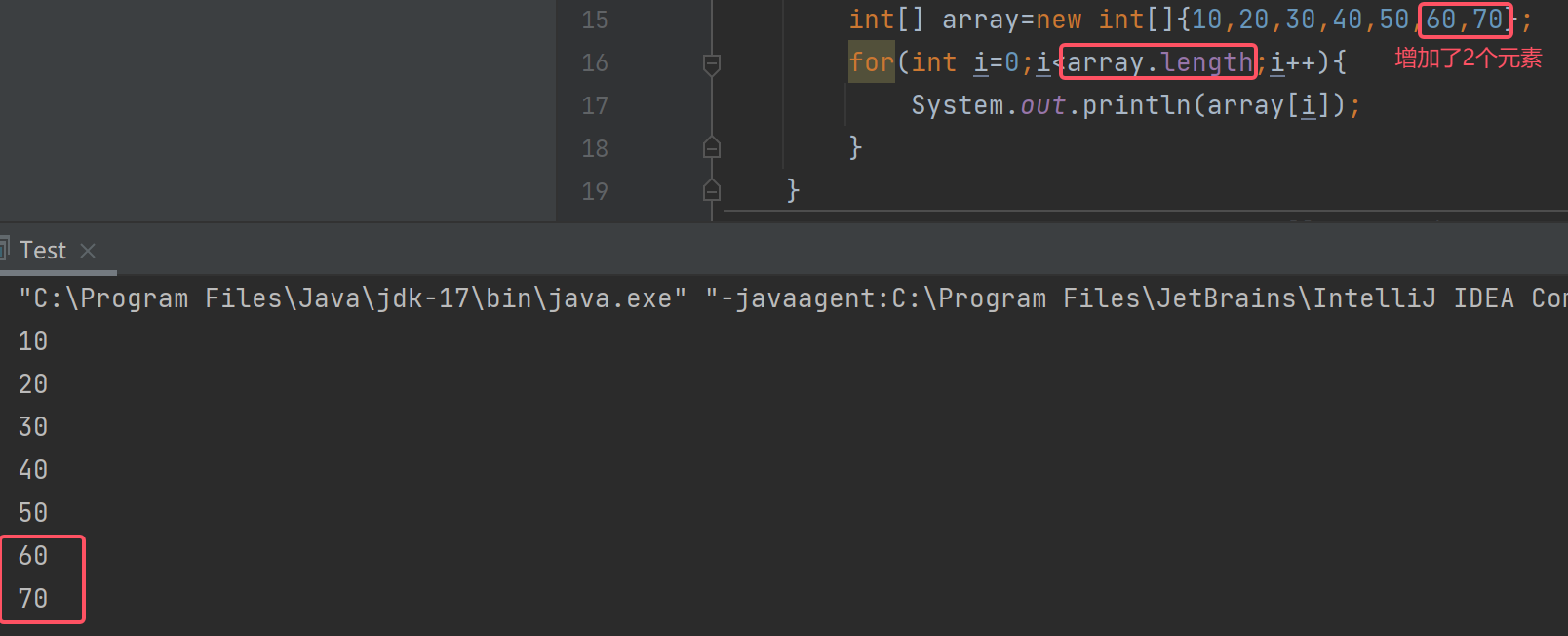
如果不想要换行就去掉println中的ln,再+一个空格(使数字之间有间隔)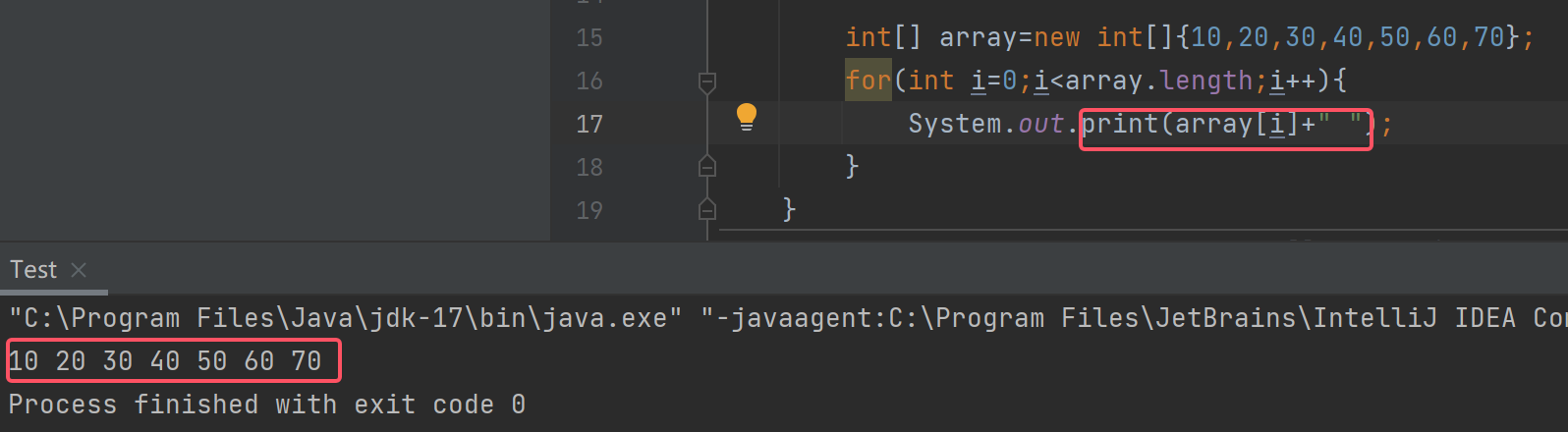
for-each的方式遍历数组
也可以使用for-each遍历数组,for-each是for循环的另一种使用方式,能够更方便的完成对数组的遍历,可以避免循环条件和更新语句写错
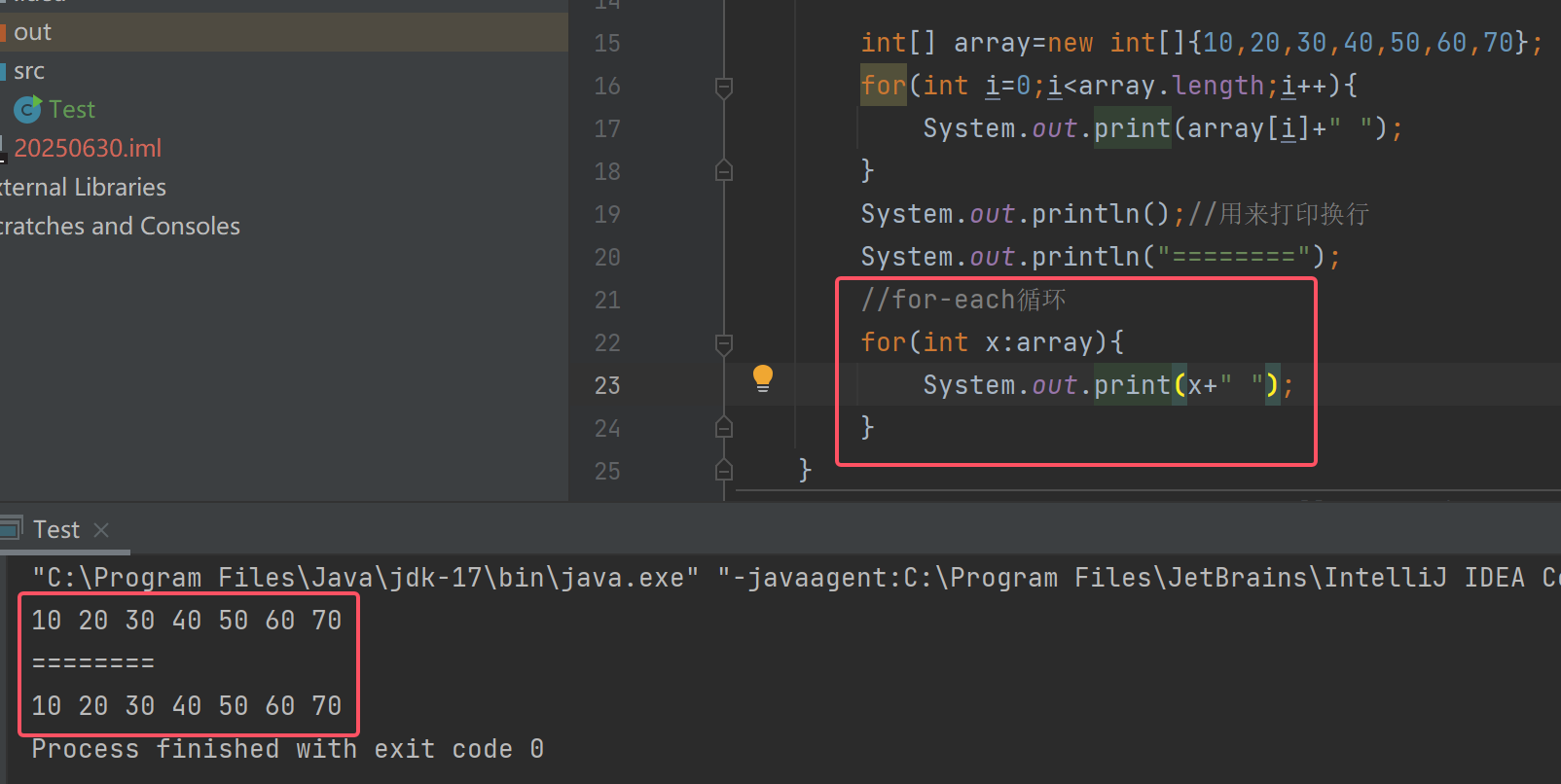
for(:)冒号右边要写要操作的数组名,因为数组的的每个元素是整型,所以左边用int x接收(可以认为这种方法是遍历array这个数组,取出每个元素,放到x里面,取一个打印一个,取一个打印一个)最后用输出将x中每个元素打印出来
这两种循环有什么区别呢?
区别就是:for-each循环是无法获取到对应的下标
用工具类的方式遍历数组
还有一种遍历方式:用操作数组的工具类去做(感受下Java中提供的封装好的工具)
这个操作数组的工具类叫做Arrays
要用Arrays的话,就要先导包

在Arrays这个类中有个方法叫toString()
Arrays.toString();
括号里要写参数,参数就是要操作的数组
Arrays.toString(array);
我们也可以看看toString的源码:按住Ctrl,鼠标点击toString
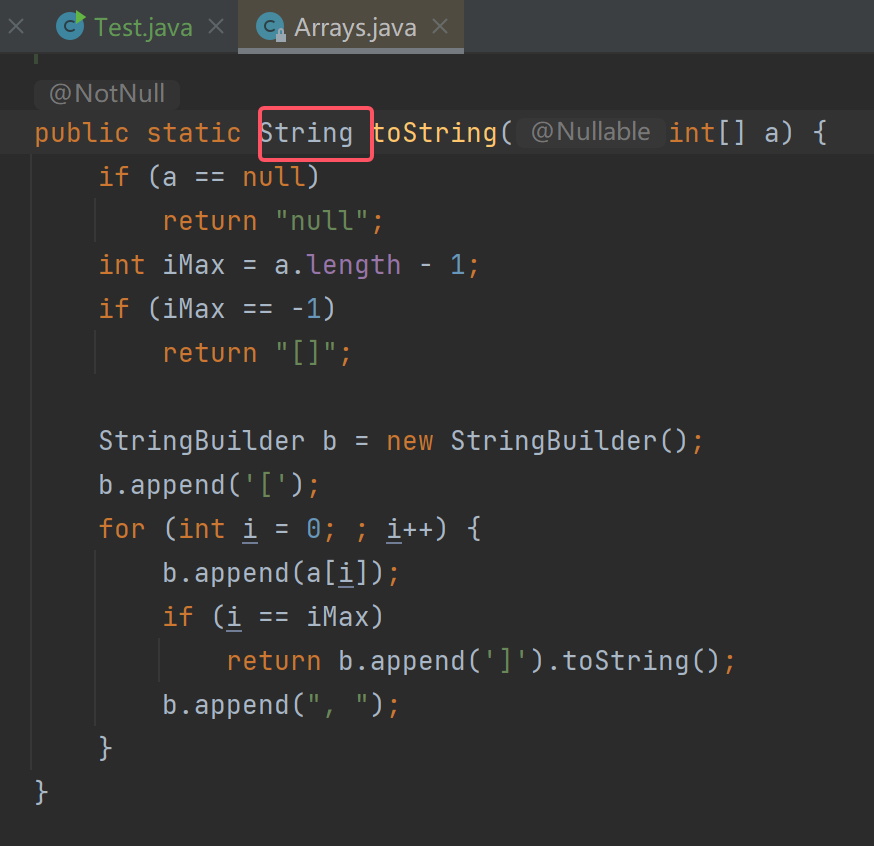
可以明显看到toString是一个返回值为String类型的方法。
所以我们可以用String类型接收返回值
String ret=Arrays.toString(array);
再打印返回值
String ret=Arrays.toString(array);
System.out.println(ret);
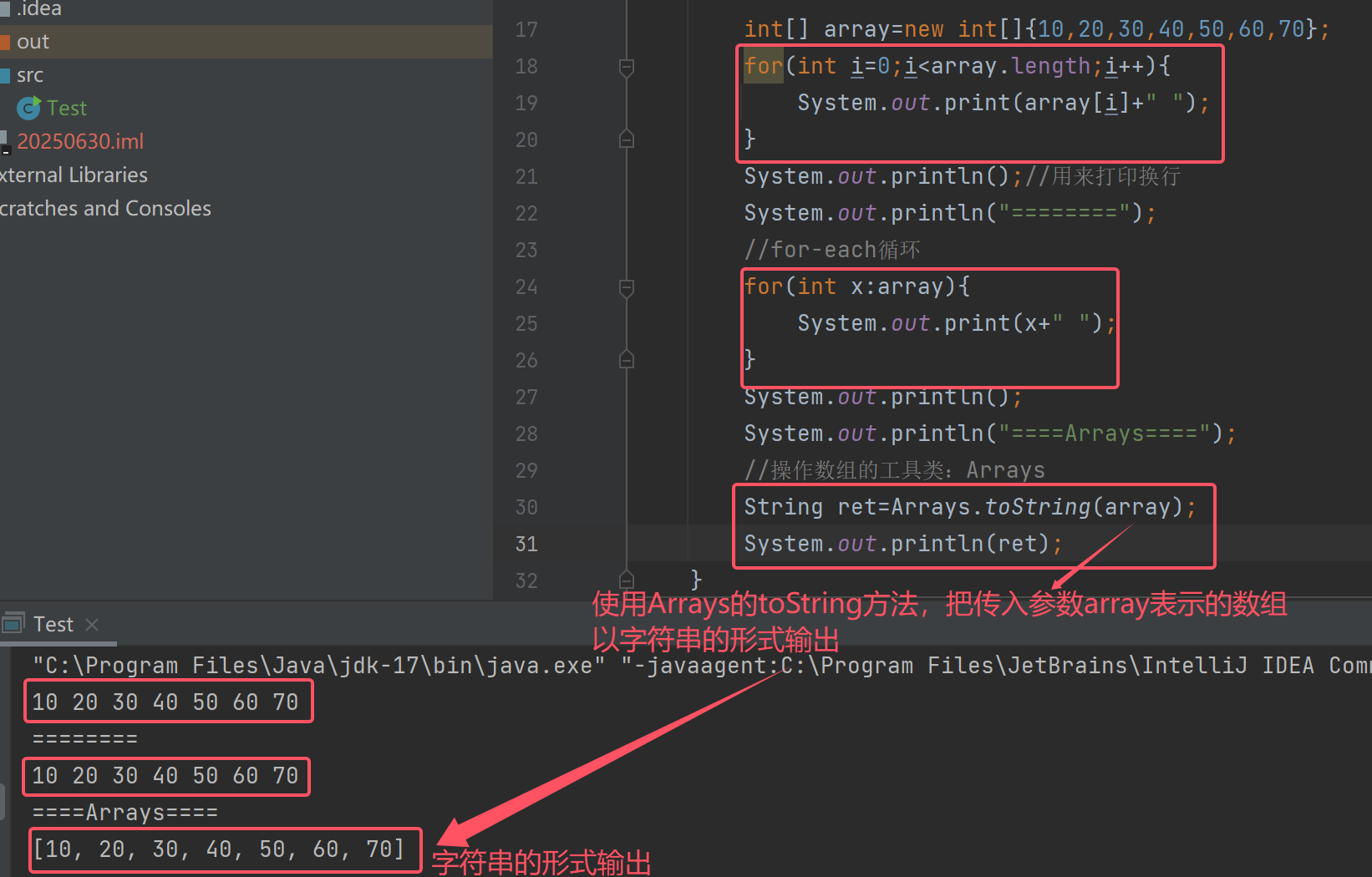
最终输出的[10,20,30,40,50,60,70]就是一个字符串
数组是引用类型
我们首先定义一个数组:
public static void main(String[] args) {int[] array={1,2,3,4,5};}
当我们输出array的时候可以观察到:
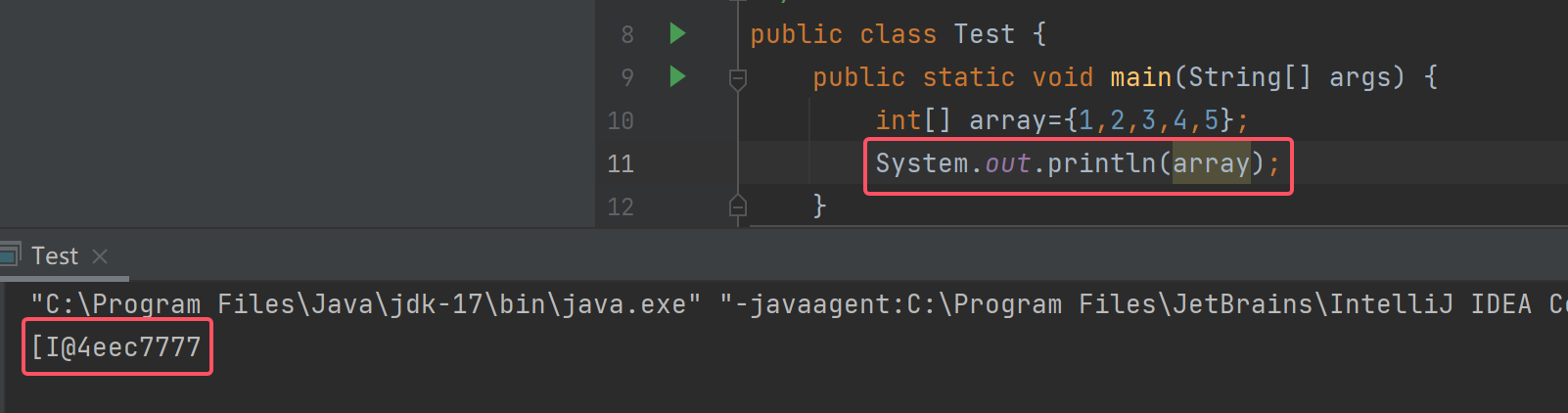
输出的值非常奇怪,这是什么呢?
[:代表输出的是个数组I:代表数组的类型是整型@:这个符号起了分割的作用4eec7777:以目前的知识来说可以把它当作为一个简单的地址
当我们定义一个整型变量a的时候
public static void main(String[] args) {int[] array={1,2,3,4,5};int a=10;}
它在内存中是这样:a里面存的整型数据10
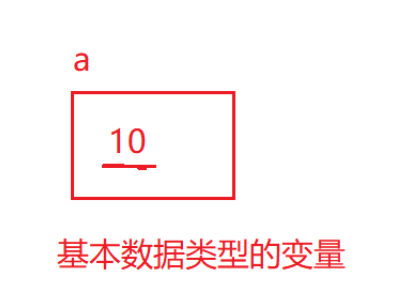
所以我们把a叫做基本数据类型的变量
而array里面存的是一个地址:4eec7777

所以把array叫做引用类型的变量,简称引用
即int[] array={1,2,3,4,5}中的int[]称为引用类型

初始JVM的内存分布
内存是一段连续的存储空间,主要用来存储程序运行时数据的。比如:
- 程序运行时代码需要加载到内存
- 程序运行时产生的中间数据要存放在内存
- 程序中的常量也要保存
- 有些数据可能需要长时间存储,而有些数据当方法运行结束后就要被销毁
如果对内存中存储的数据不加区分的随意存储,那对内存管理起来将会非常麻烦。
所有的程序都会运行在JVM(Java虚拟机)上。因此,JVM对所使用的内存进行了不同的划分。
那么为什么要划分内存呢?
我们可以看这张图,给人的感觉是非常的乱:衣服、垃圾到处都是,都不在各自该有的位置

如果对房间进行了划分,就会变得很规整:书在书架上、衣服在衣柜里…

同理,对内存也会进行划分,会大概划分为这样的5块:
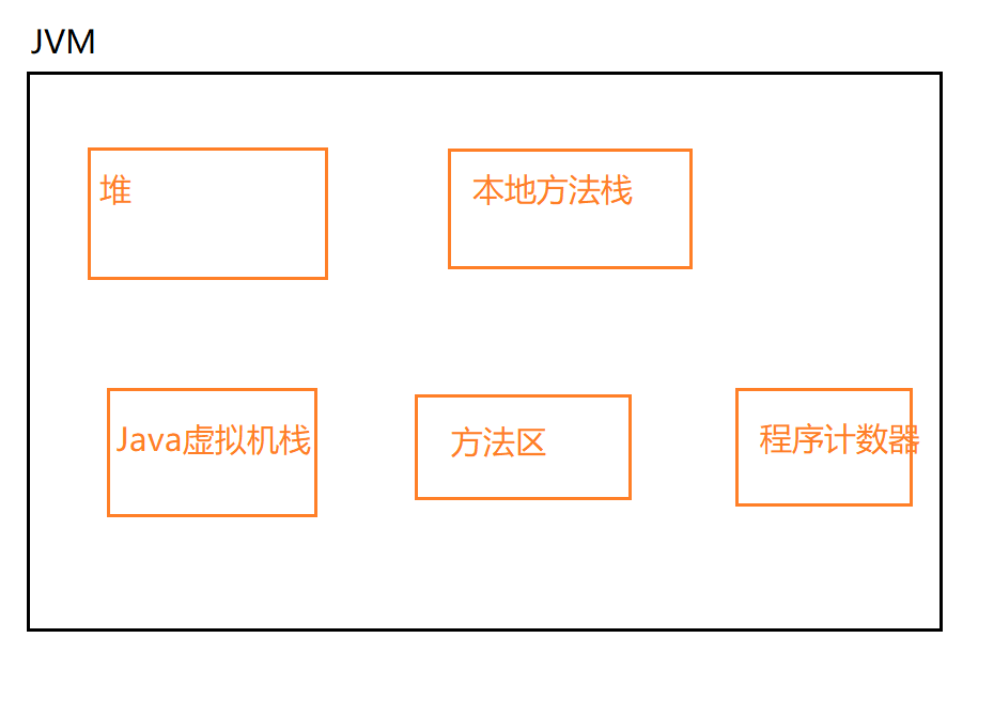
这样以来,不同的数据就会放在相应的内存空间里进行不同的管理。在数据很多的情况下,数据在整个内存中是在对应的位置上的,找数据的时候就会很好找(可以对数据实现更好的管理)
以上5块区域都各司其职,用来存放不同的数据。
那么为什么会有两个栈呢?本地方法栈与Java虚拟机栈有什么区别呢?
- 本地方法栈:会执行一些底层是由C/C++代码实现的方法
- Java虚拟机栈:就是平时嘴里所说的栈。例如:将局部变量放在栈里面、这个变量在栈上开辟内存…此时这个栈就是Java虚拟机栈。
以下是5个区域的简单说明:
- 程序计数器 (PC Register): 只是一个很小的空间, 保存下一条执行的指令的地址
- 虚拟机栈(JVM Stack): 与方法调用相关的一些信息,每个方法在执行时,都会先创建一个栈帧,栈帧中包含有:局部变量表、操作数栈、动态链接、返回地址以及其他的一些信息,保存的都是与方法执行时相关的一些信息。比如:局部变量。当方法运行结束后,栈帧就被销毁了,即栈帧中保存的数据也被销毁了。
- 本地方法栈(Native Method Stack): 本地方法栈与虚拟机栈的作用类似. 只不过保存的内容是Native方法的局部变量. 在有些版本的 JVM 实现中(例如HotSpot), 本地方法栈和虚拟机栈是一起的
- 堆(Heap): JVM所管理的最大内存区域. 使用 new 创建的对象都是在堆上保存 (例如前面的
new int[]{1, 2, 3}),堆是随着程序开始运行时而创建,随着程序的退出而销毁,堆中的数据只要还有在使用,就不会被销毁 - 方法区(Method Area): 用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据. 方法编译出的的字节码就是保存在这个区域
现在我们只简单关心堆 和 虚拟机栈这两块空间
看第五节课25:53——在堆和栈中,引用与对象的关系
基本类型变量与引用类型变量的区别
(从这开始看第五节课视频23:52)
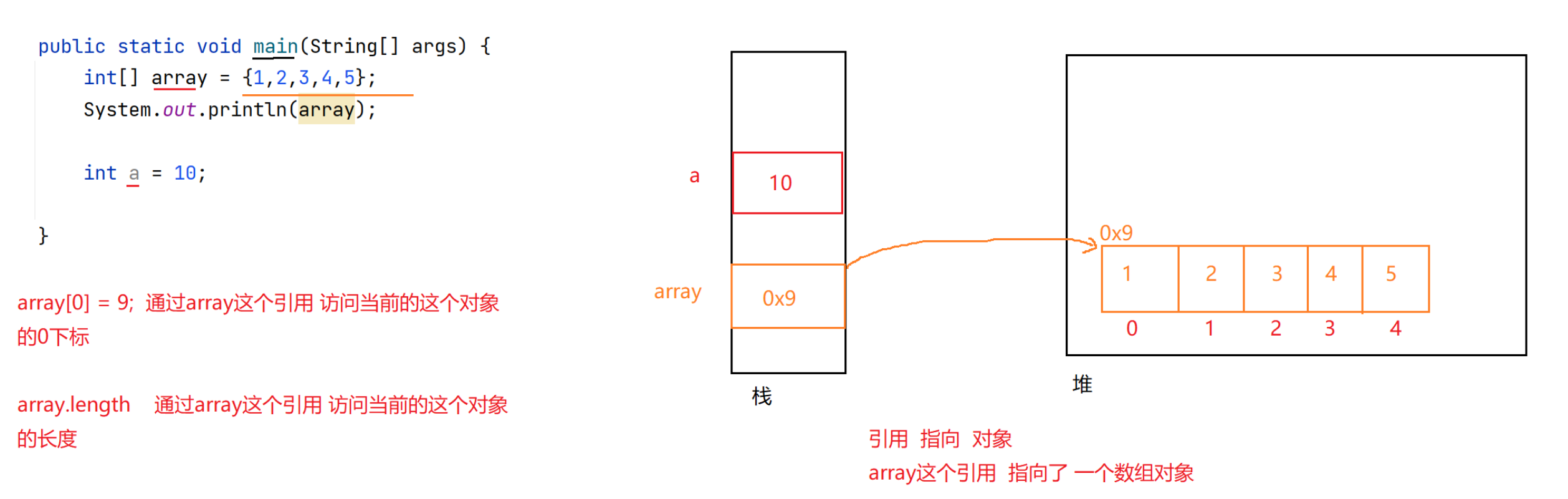
基本数据类型创建的变量,称为基本变量,该变量空间中直接存放的是其所对应的值;
而引用数据类型创建的变量,其空间中存储的是对象所在空间的地址。
引用变量并不直接存储对象本身,可以简单理解成存储的是对象在堆中空间的起始地址。通过该地址,引用变量便可以去操作对象。有点类似C语言中的指针,但是Java中引用要比指针的操作更简单
数组练习
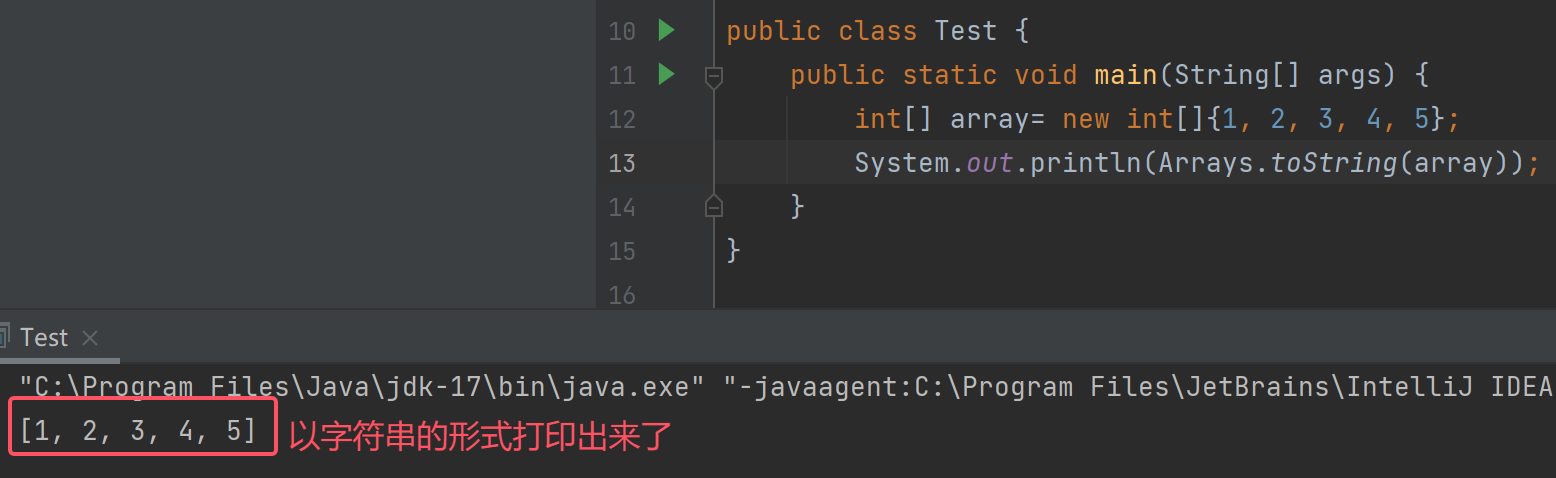
数组转字符串
我们可以使用Arrays.toSTring(array)把数组array中的数据以字符串的形式打印出来
那么我们可不可以自己写个myToString来将数组以字符串的形式输出呢?
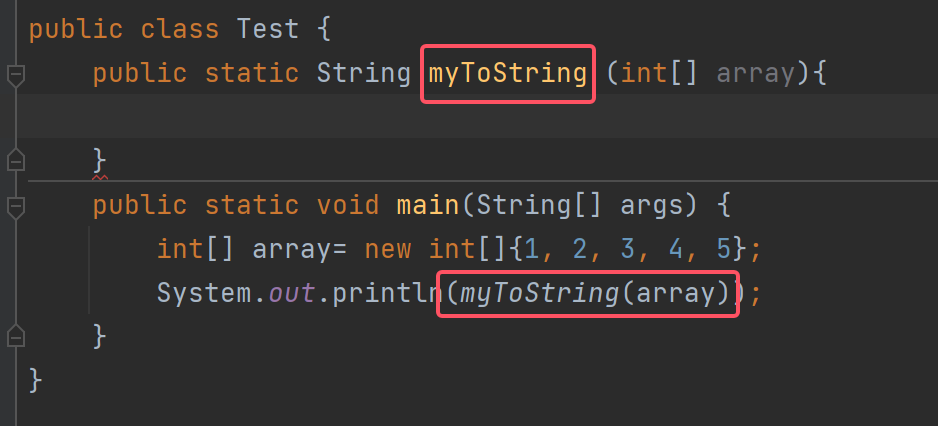
解法:
public class Test {public static String myToString (int[] array){String str="[";for (int i = 0; i < array.length; i++) {if(i==array.length-1){str=str+array[i];}else{str=str+array[i]+",";}}str=str+"]";return str;}public static void main(String[] args) {int[] array= new int[]{1, 2, 3, 4, 5};System.out.println(myToString(array));}
}
求数组中元素的平均值
给定一个整型数组,求平均值
public static double average(int[] array){int sum=0;for (int i = 0; i <array.length ; i++) {sum+=array[i];}double ret=(double)sum/(double)array.length;return ret;
}
public static void main(String[] args) {int[] array={1,2,3,4,5,6};double ret=average(array);System.out.println(ret);
}
需要注意的是,这些元素的平均值是小数,所以最后我们需要强转为double(也可以乘1.0),这样最后得到的结果才能是小数
查找数组中指定元素(顺序查找)
若这个数组中我们要查找6,找到6后返回它的下标
写出代码:
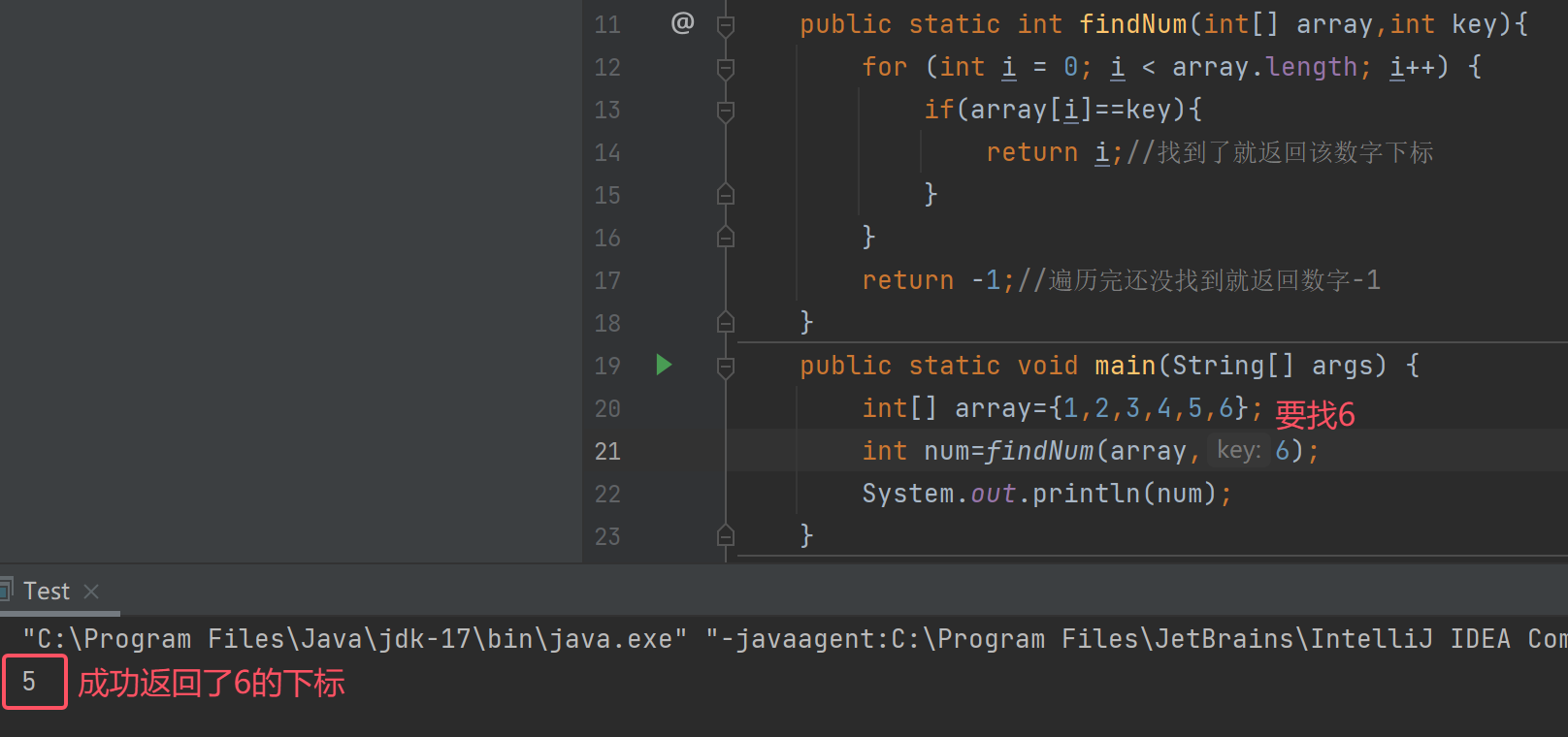
若要找9,可是数组里并没有9,所以返回-1
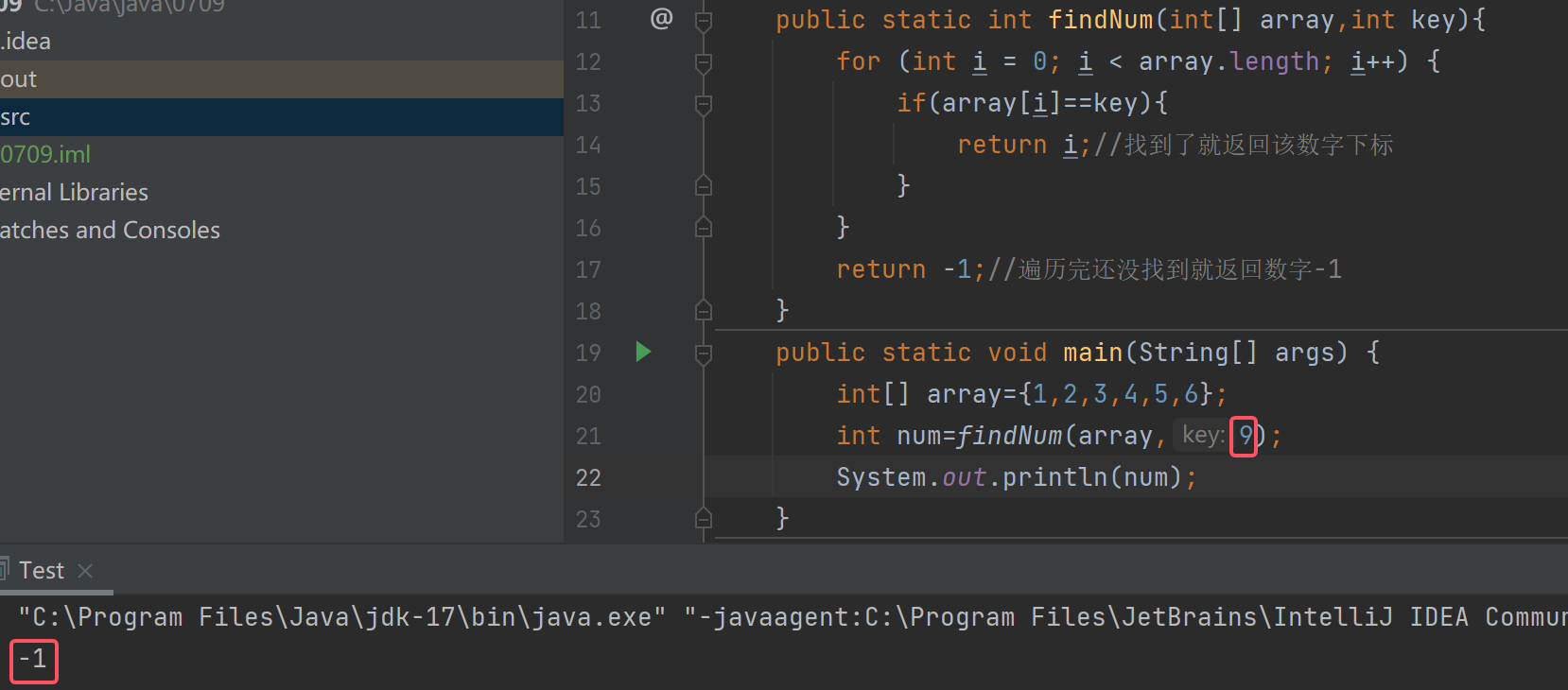
这种查找虽然能实现需求,但是从第一个开始找,万一找的数是最后一个,那么就要全部遍历完,这种查找的效率是很低的,所以我们可以用二分查找
二分查找
二分查找有个前提:必须是有序的数字
二分查找的好处:效率高
public class Test {public static int binarySearch(int[] array,int key){int left=0;int right=array.length-1;while(left<=right){int mid=(left+right)/2;if(array[mid]==key){return mid;}else if(array[mid]>key){right=mid-1;}else{left=mid+1;}}return -1;//若找不到就返回-1}public static void main(String[] args) {int[] array={1,2,3,4,5};int index=binarySearch(array,5);System.out.println(index);}
}
二分查找必须建立在数组是有序的情况,那么无序时还想使用二分查找binarySearch进行排序该怎么办呢?
Java的操作类叫做Arrays,在Arrays里包含了非常多的操作数组的工具类,例如Arrays.sort()可以对数组进行排序
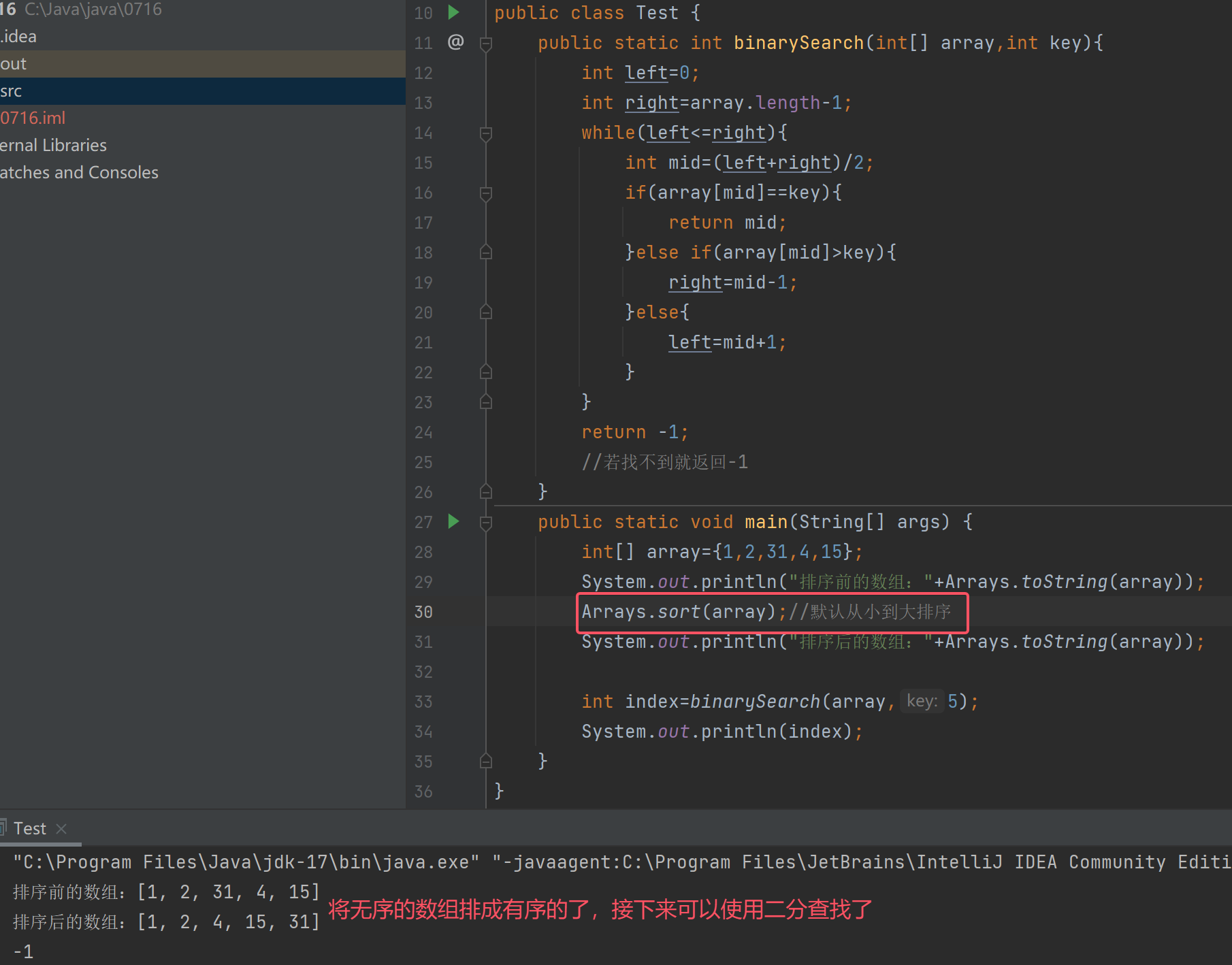
以上的二分查找是我们自己写的,其实Java也提供了二分查找:Arrays.binarySearch()
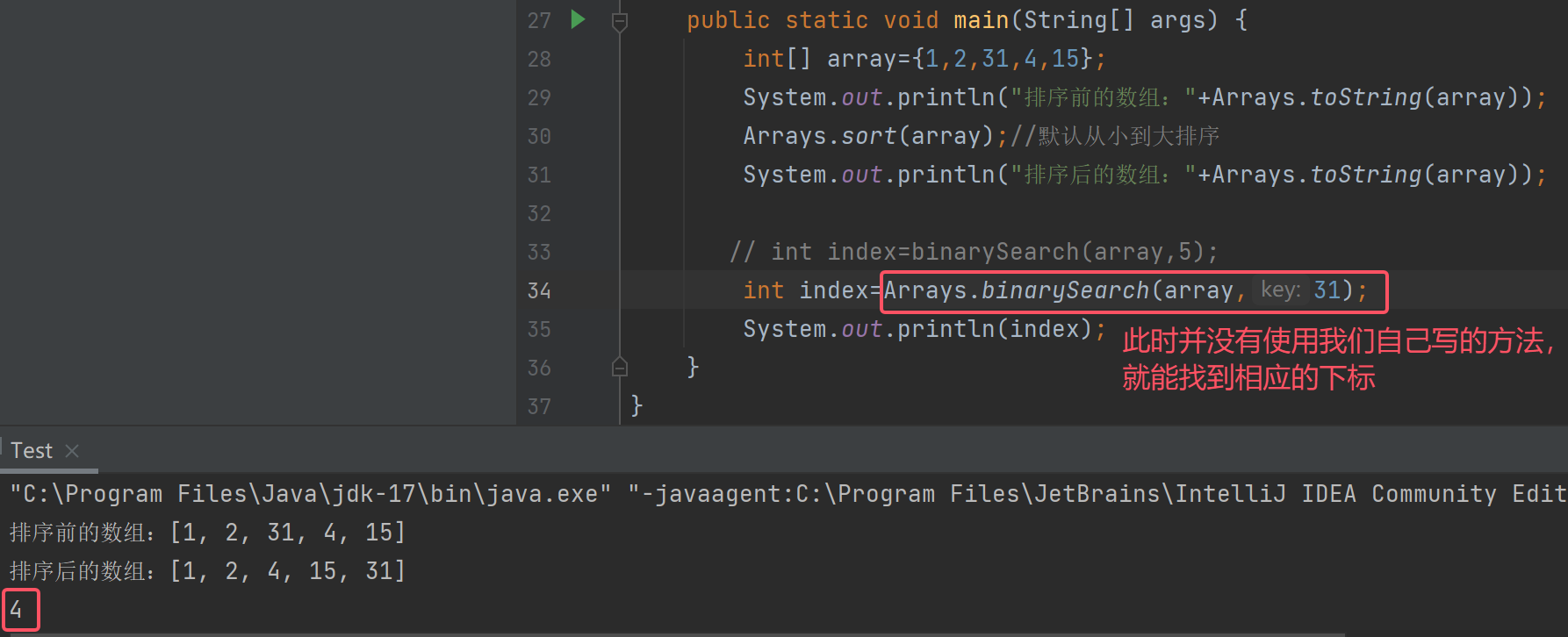
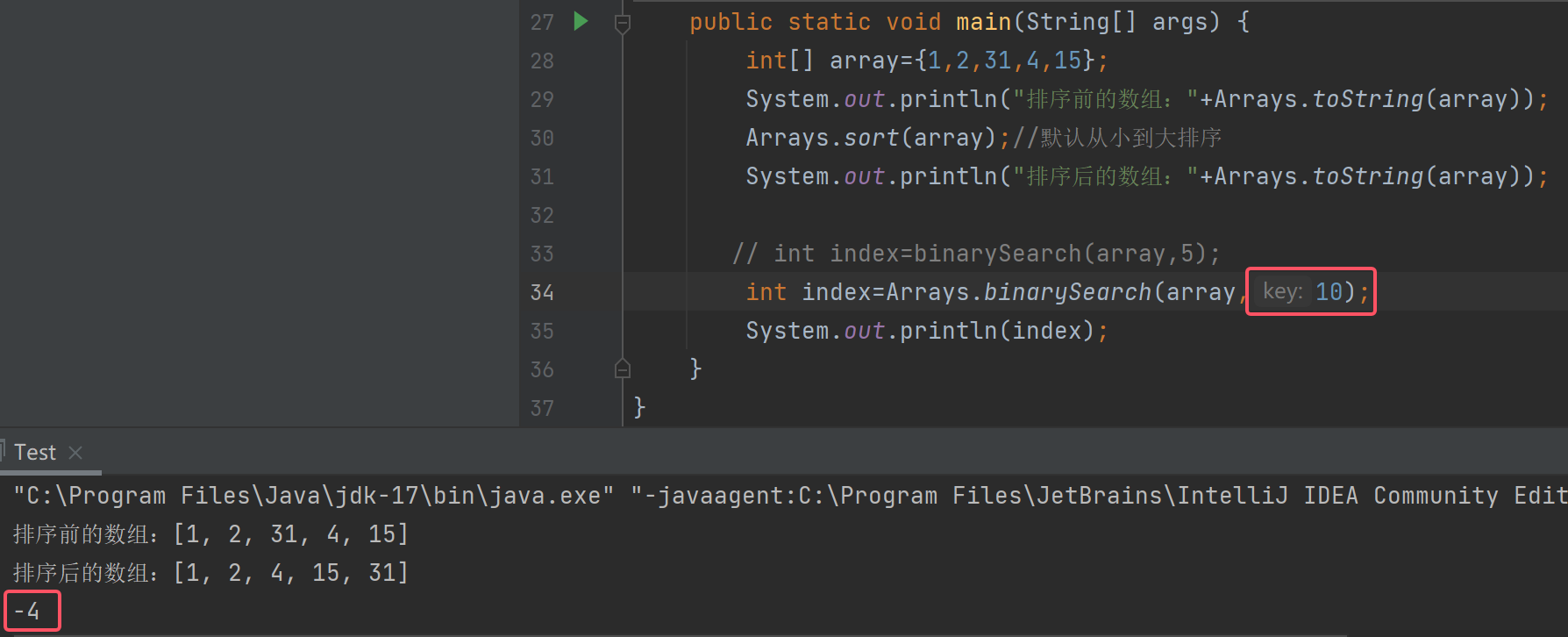
注意:如果想要找的数字在数组中不存在,那么就会返回一个负数,那么为什么会是-4呢?
我们看源码:
binarySearch()中又用了binarySearch0,所以再从binarySearch0点进去

- 我们仔细观察下源码,发现跟我们写的方法差不多
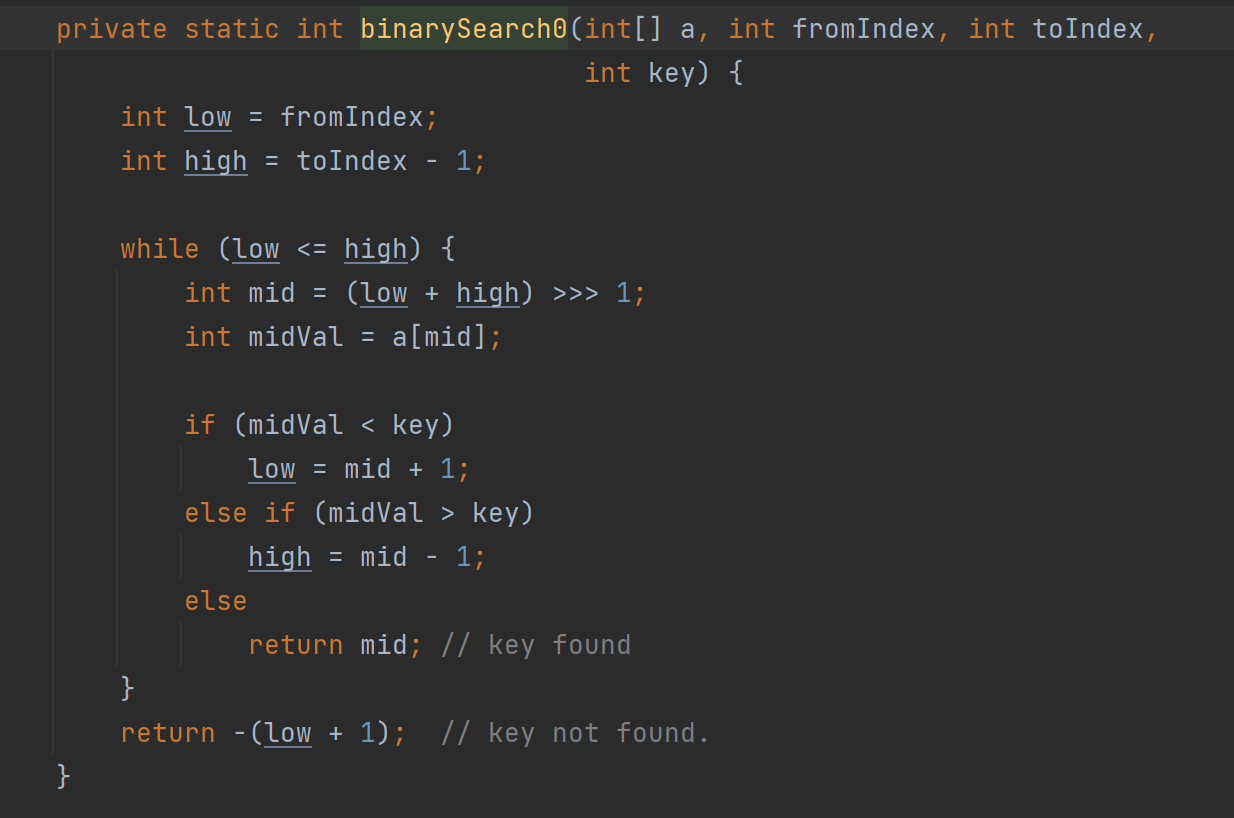
只不过我们是/,源码用的是无符号右移;
返回的是最后low的位置,再加上一个1
并且我们在写代码的时候,发现Java给了二分查找很多重载,那么二分查找的功能就会大大的扩展
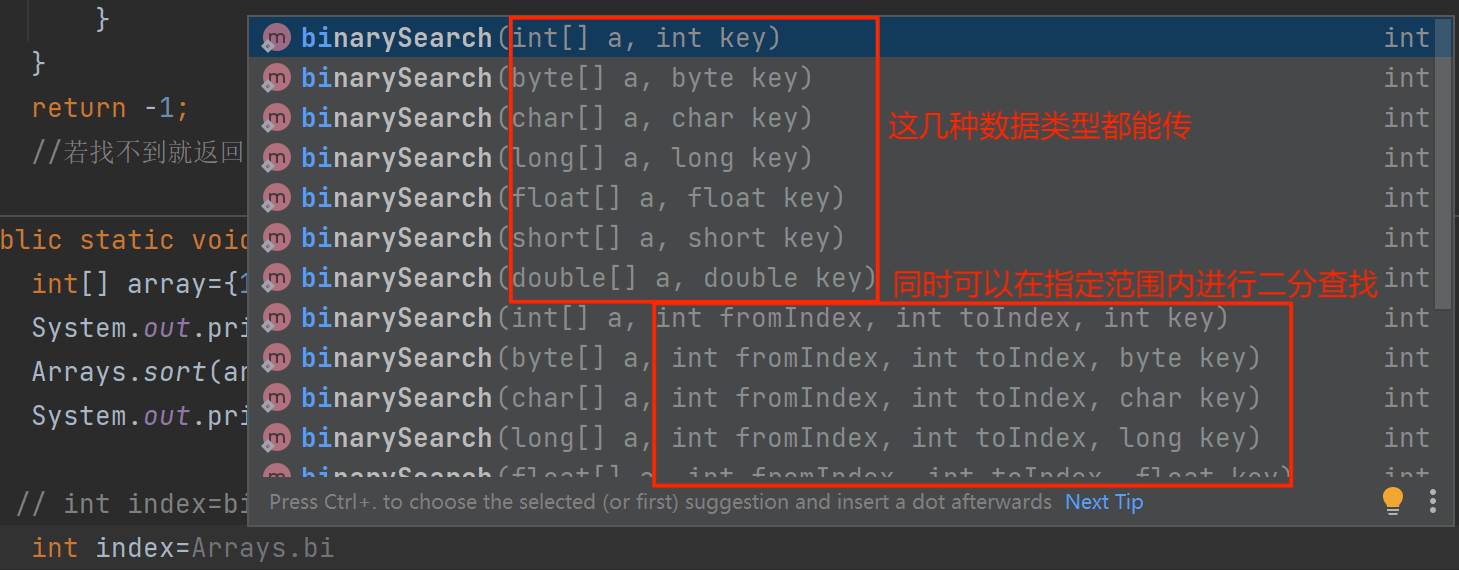
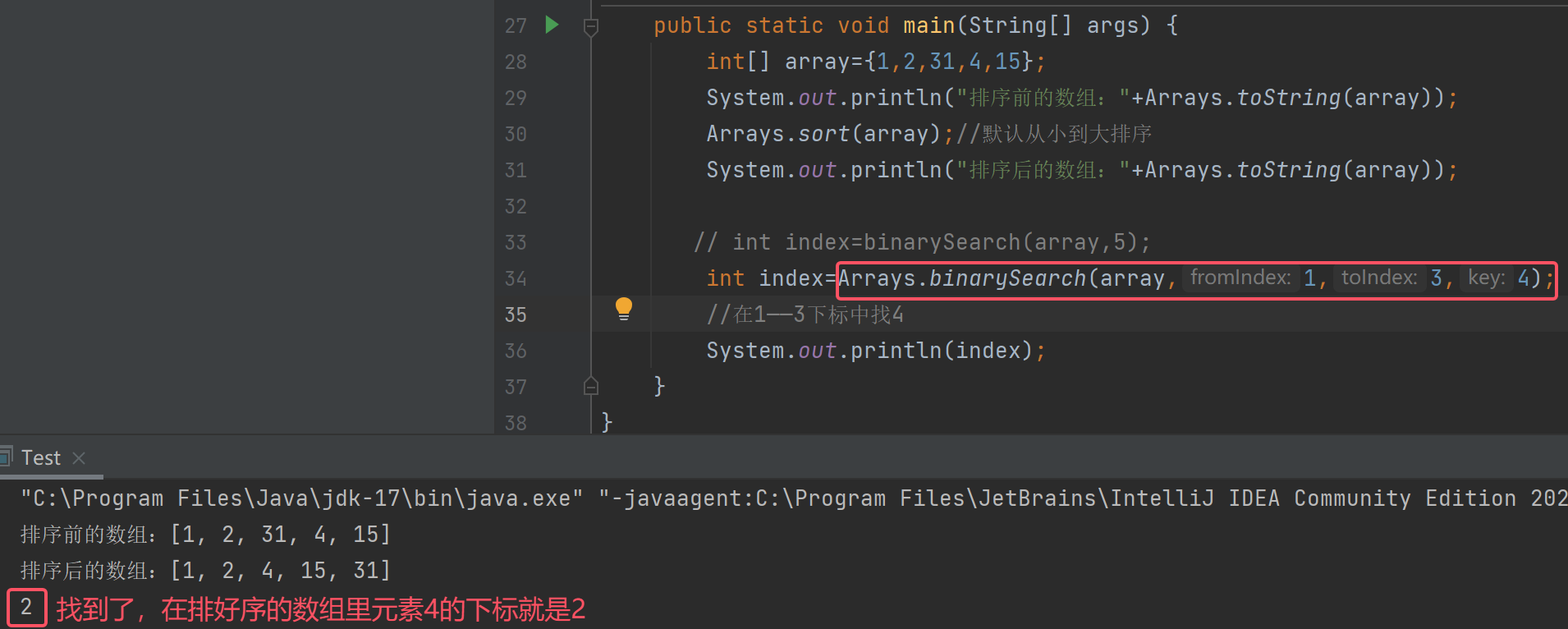
当我们找元素15时却找不到了
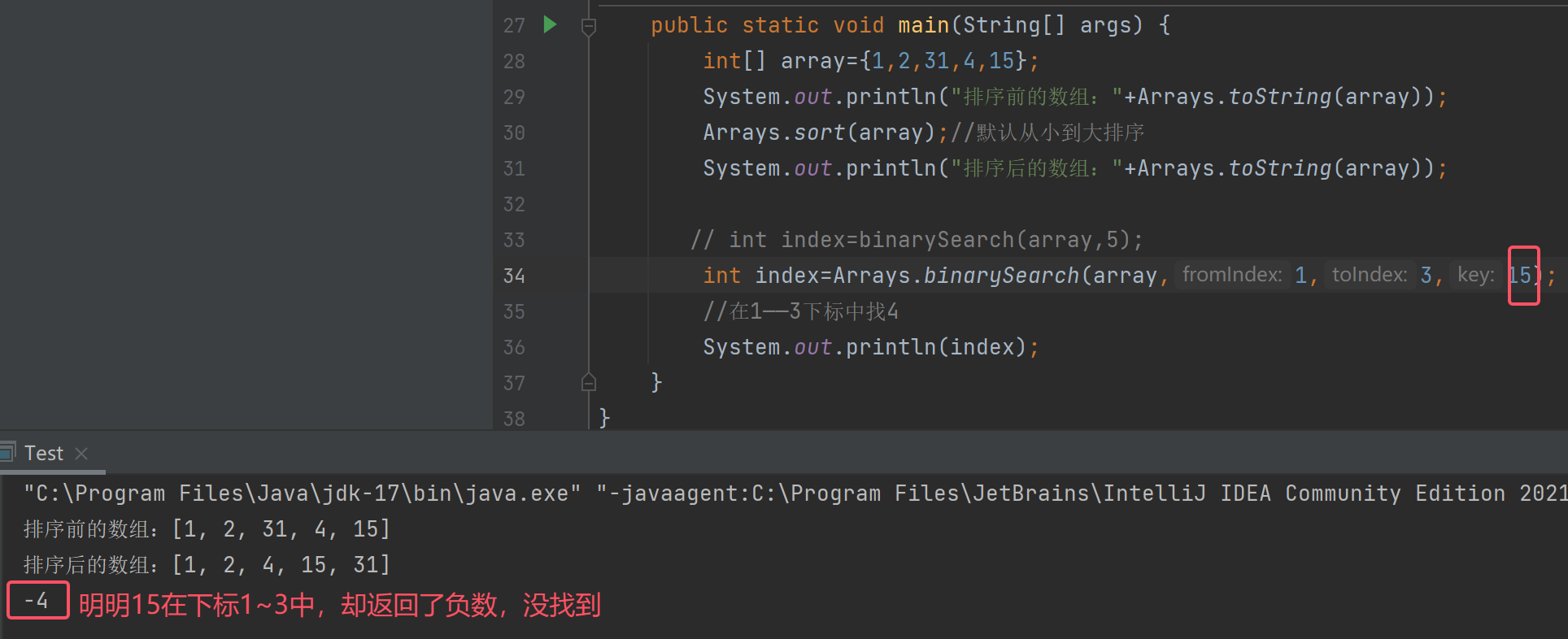
这是因为在Java中,所有fromIndex,toIndex都是左闭右开的[),也就是不包含3下标,所以找不到元素15
冒泡排序
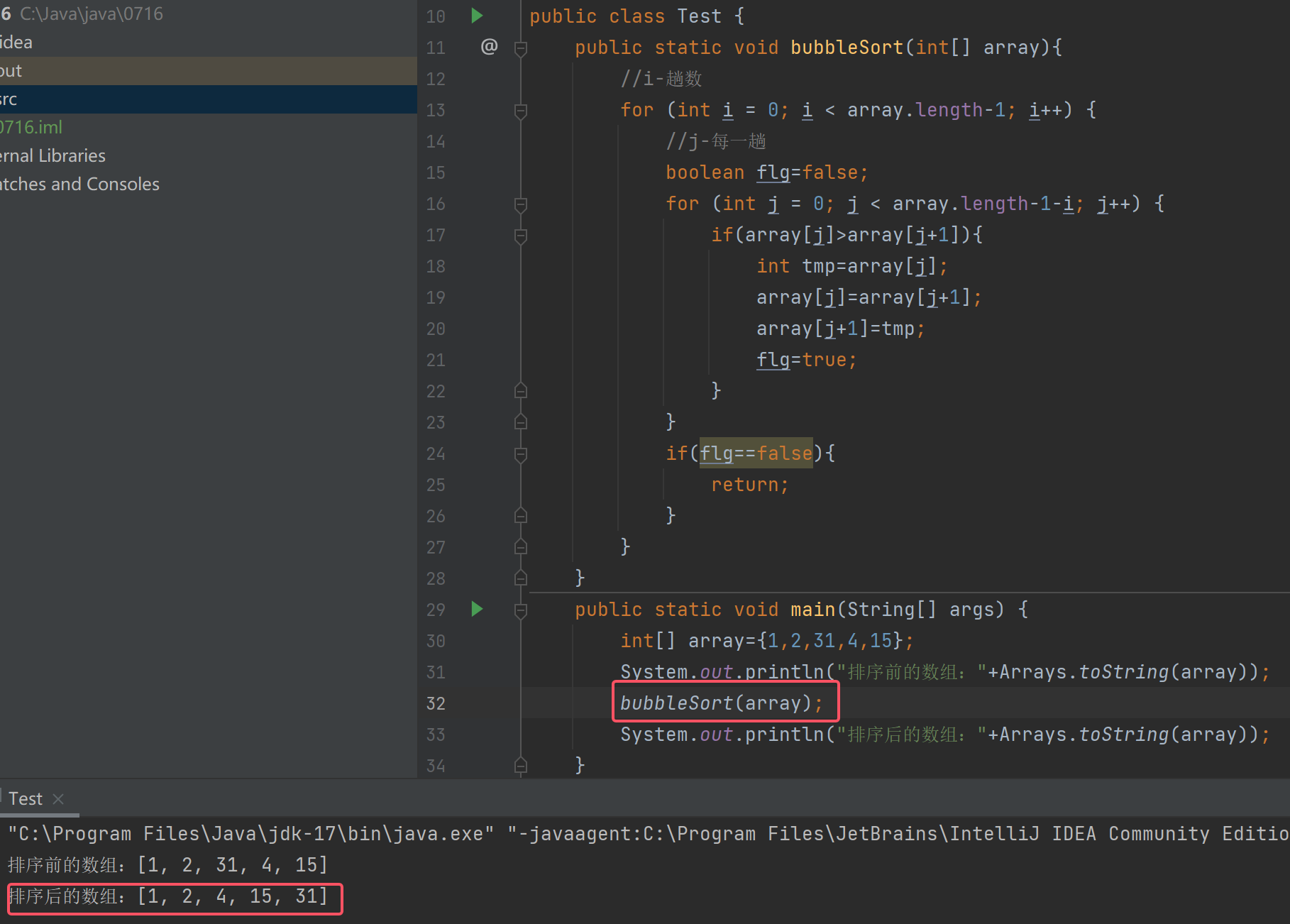
数组拷贝
指把原来的数组拷贝一份,修改副本不会影响到原来的数据。
我们自己实现一个数组的拷贝:
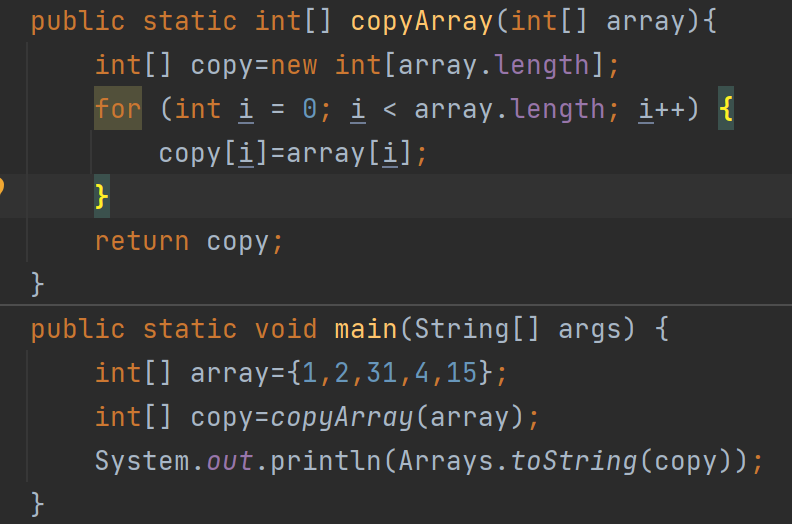
第一种拷贝方法
其实Java中就有现成的拷贝数组的方法Arrays.copyOf(数组,数组长度)(这个方法有两个参数)
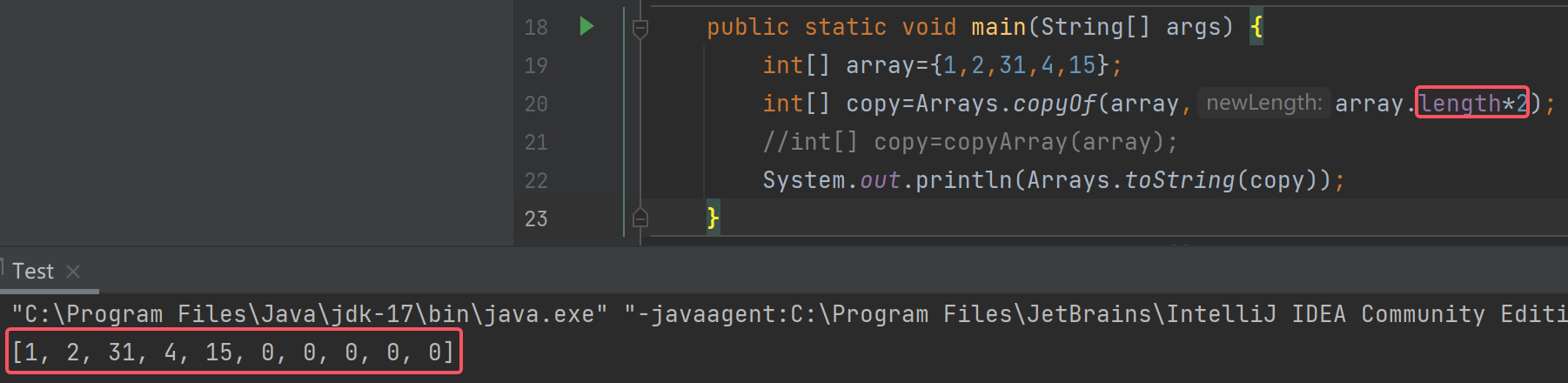
这个方法还可以扩容:
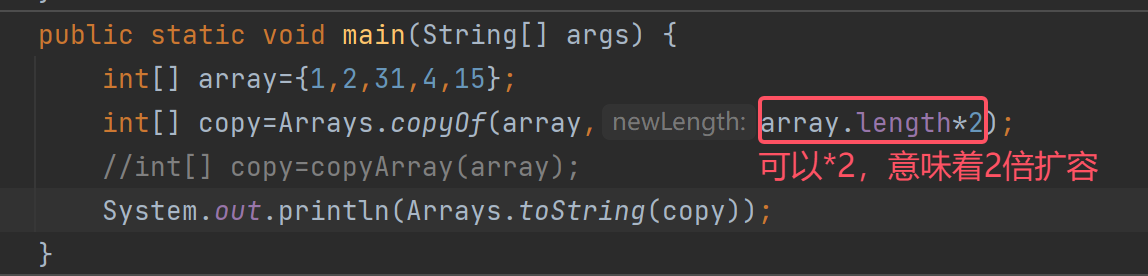
原本这个数组的长度是5个元素,扩容后变为10个元素
- 第一个参数:是要拷贝(扩容)的数组
- 第二个参数:新的数组长度
第二种拷贝方法
若我们要拷贝这个数组的一部分,该怎么办呢?
我们可以看到有很多这个方法的重载:
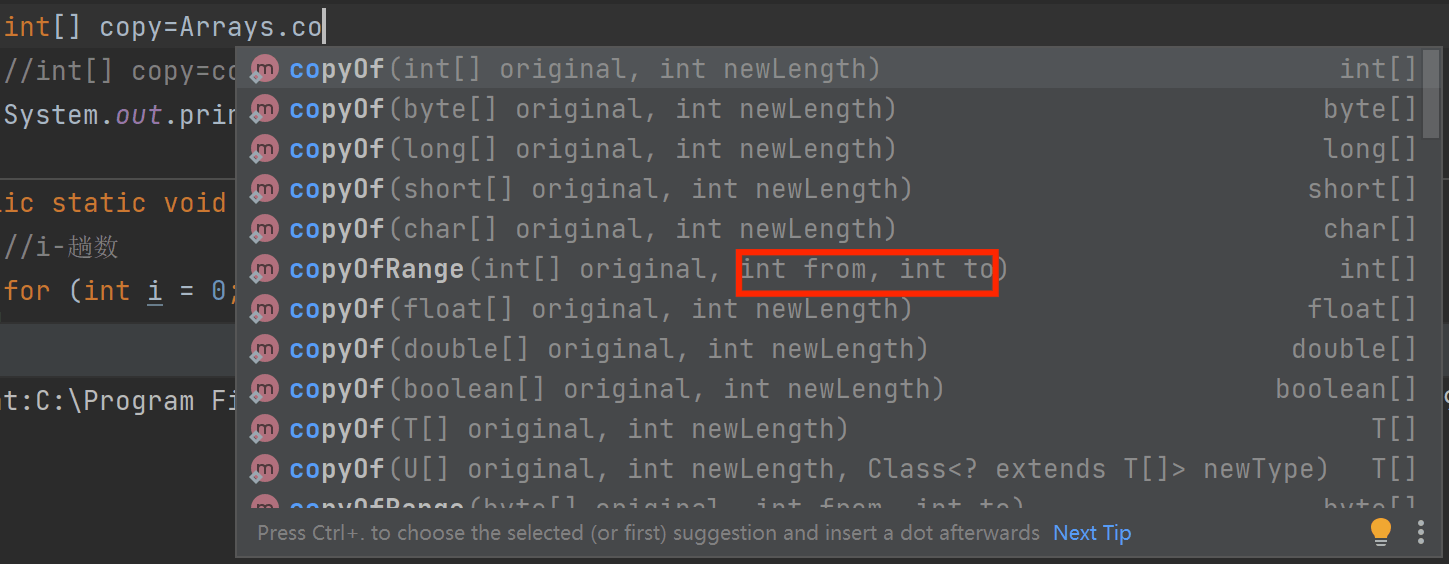
拷贝1~3下标:
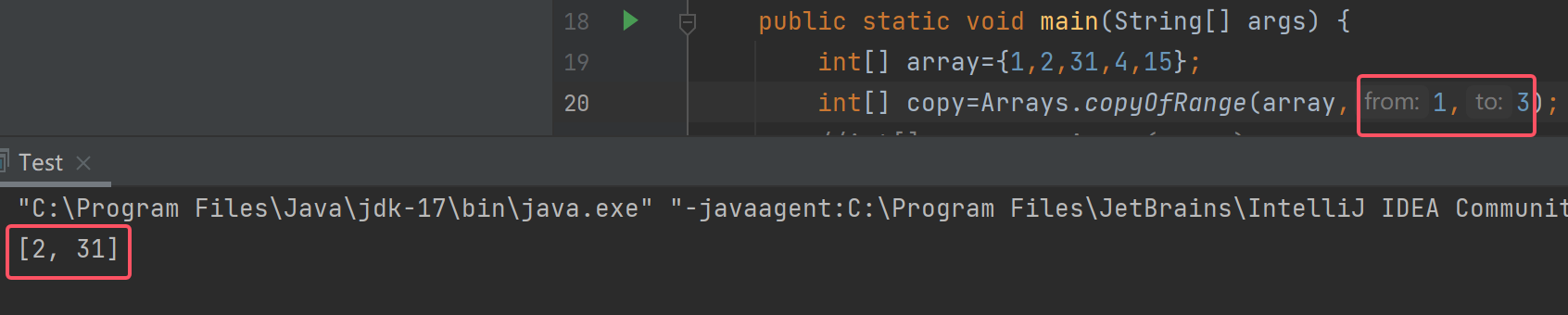
第三种拷贝方法
我们还可以用System.arraycopy()方法拷贝数组(有5个参数)

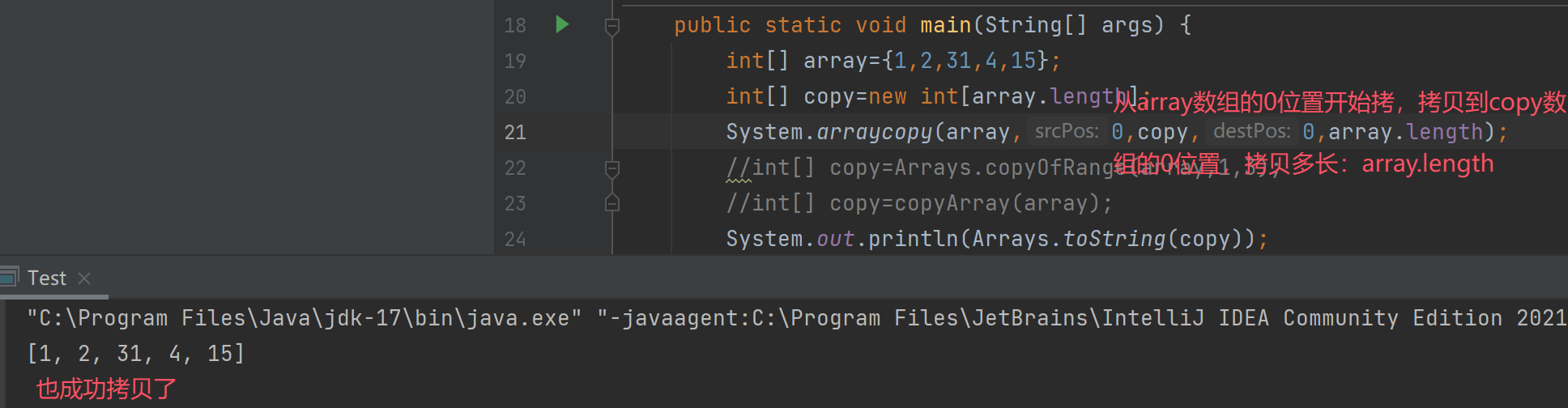
注意:这个方法被native修饰了,被native修饰的方法被称为本地方法。也就是这个方法被C/C++代码实现的,我们看不到。优点:速度快!!!(C/C++代码速度非常快)
equals方法
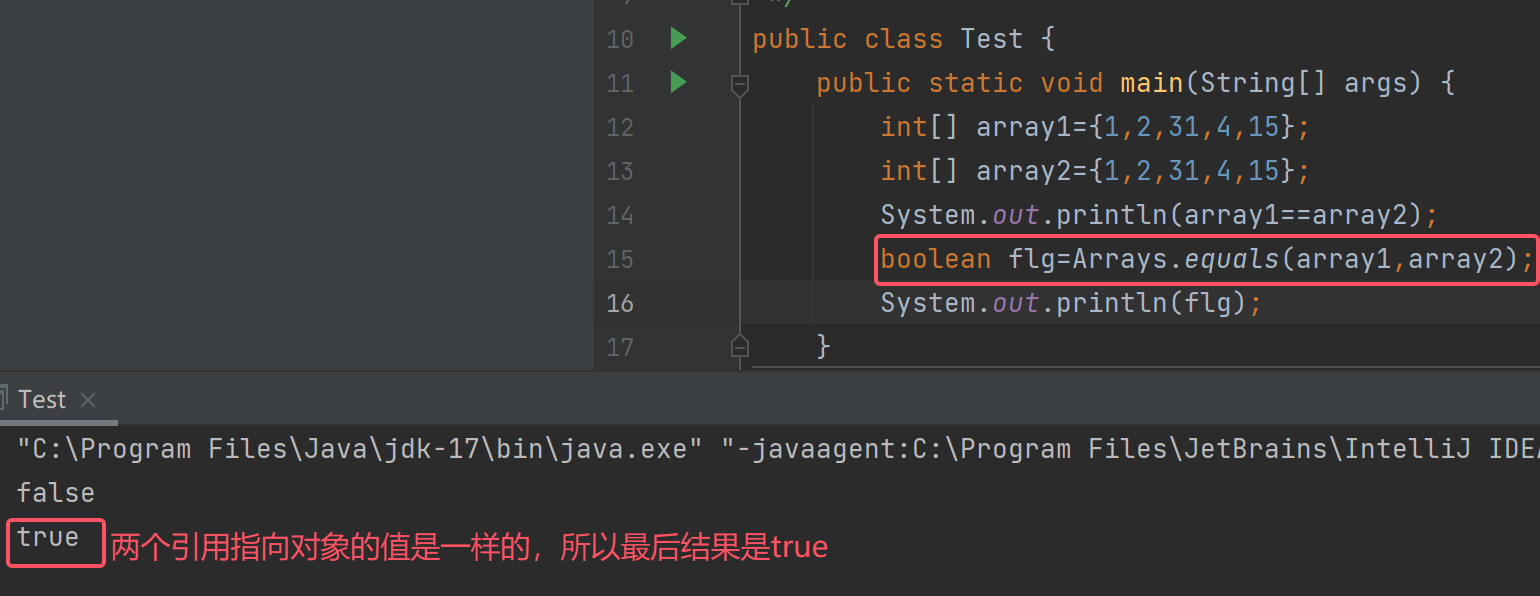
我们先写段代码:
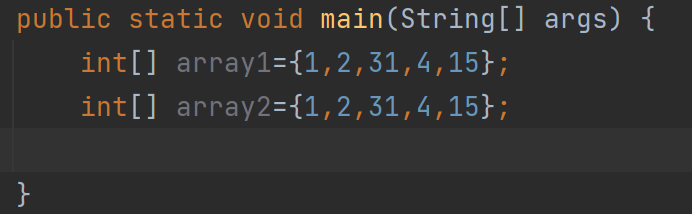
这两个数组一样吗?
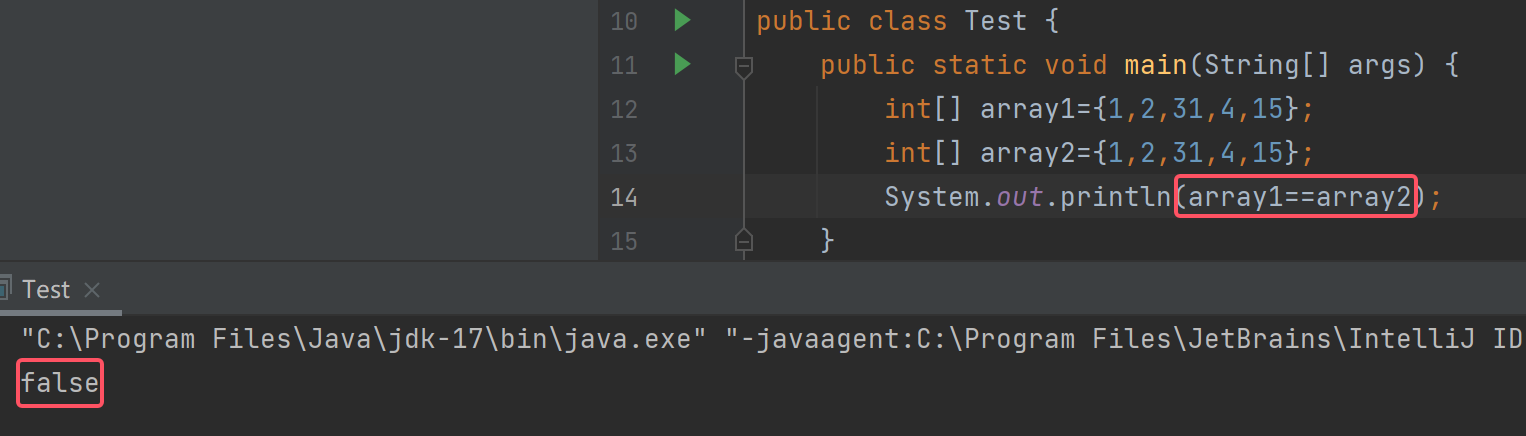
可以看到打印出来的结果是false,所以它俩是不一样的。
这两个引用指向对象的值是一样的,但是存的对象的地址是不一样的,所以是false
若我们要想比较这两个引用指向对象的内容,该怎么比较呢?
可以通过Arrays.equals()方法进行比较
将这两个引用进行比较:
equals方法——比较两个数组中的值
fill方法
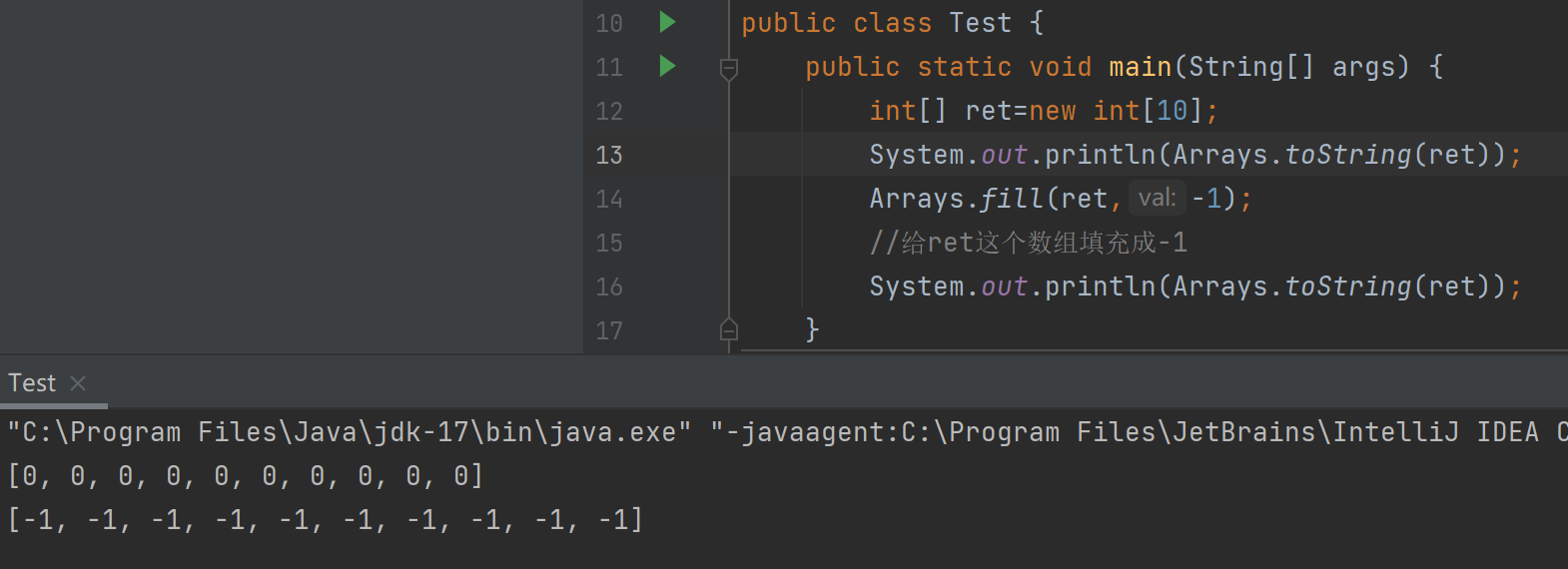
我们定义一个引用ret
int[] ret=new int[10];
此时这个引用里面的值全是0,若我们想把这10个元素全填充成5,通常是写for循环进行填充。
而通过Arrays.fill()方法就可以直接实现

代码举例:
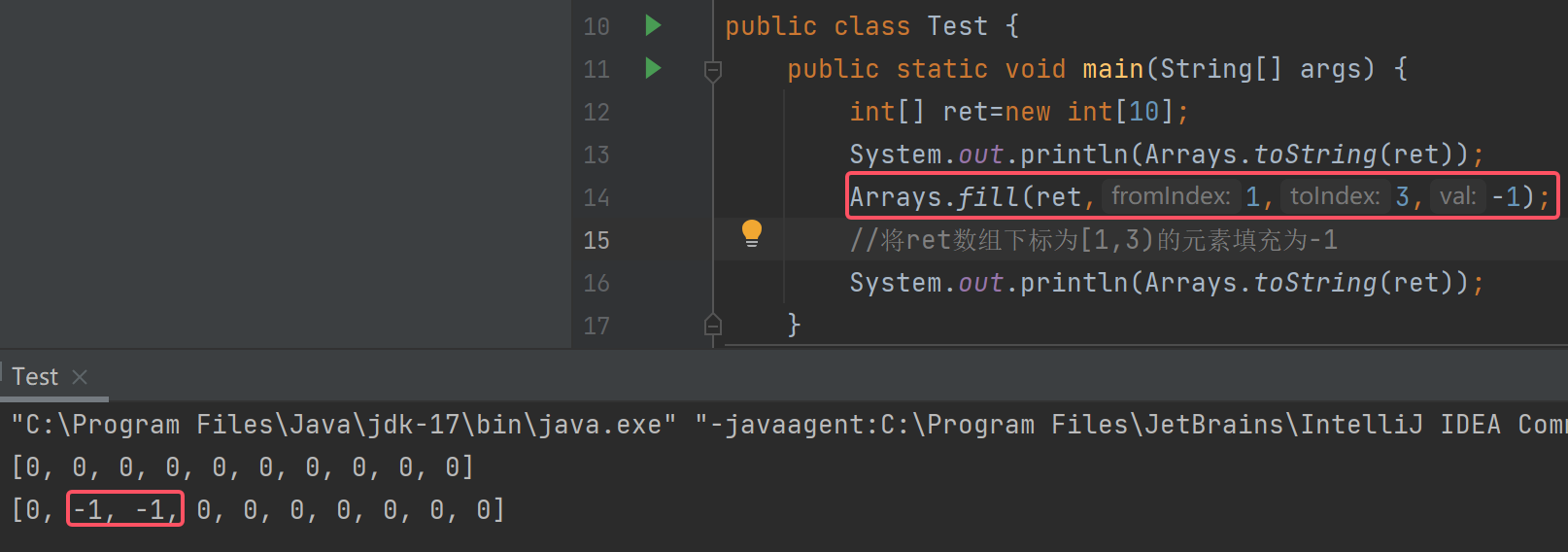
还可以指定范围

二维数组
二维数组本质上也就是一维数组, 只不过每个元素是一个一维数组
基本语法:
数据类型[][] 数组名称=new 数据类型[行数][列数]{初始化数据};
-
第一种定义方式:
在C语言中我们给二维数组一些值是可以自动区分行和列,但是Java不可以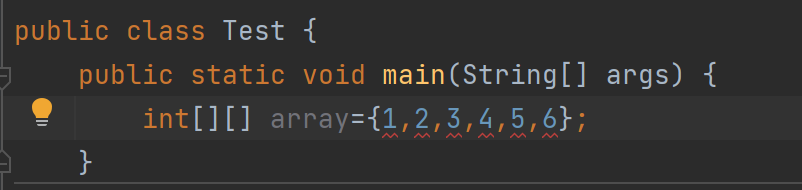
我们必须手动区别行、列

这种写法是第一种定义方式 -
第二种定义方式:
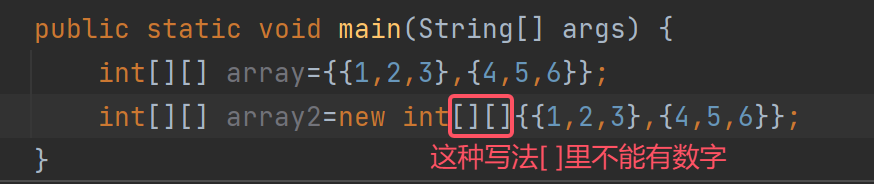
-
第三种定义方式:
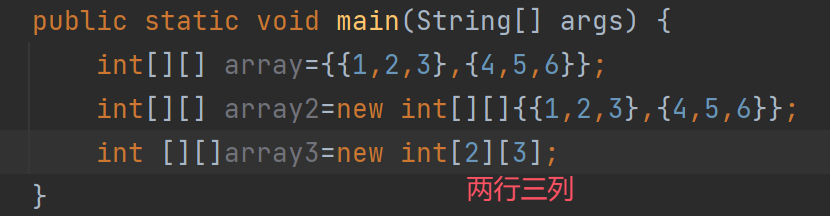
这里面的数据默认都是0 -
第四种定义方式——不规则二维数组
C语言中数组可以不写行,Java中数组可以不写列,但是不能省略行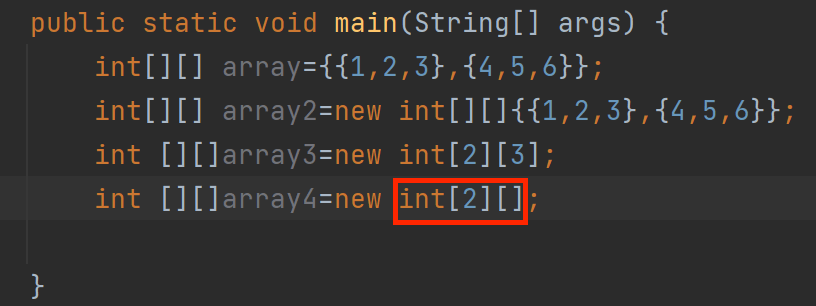
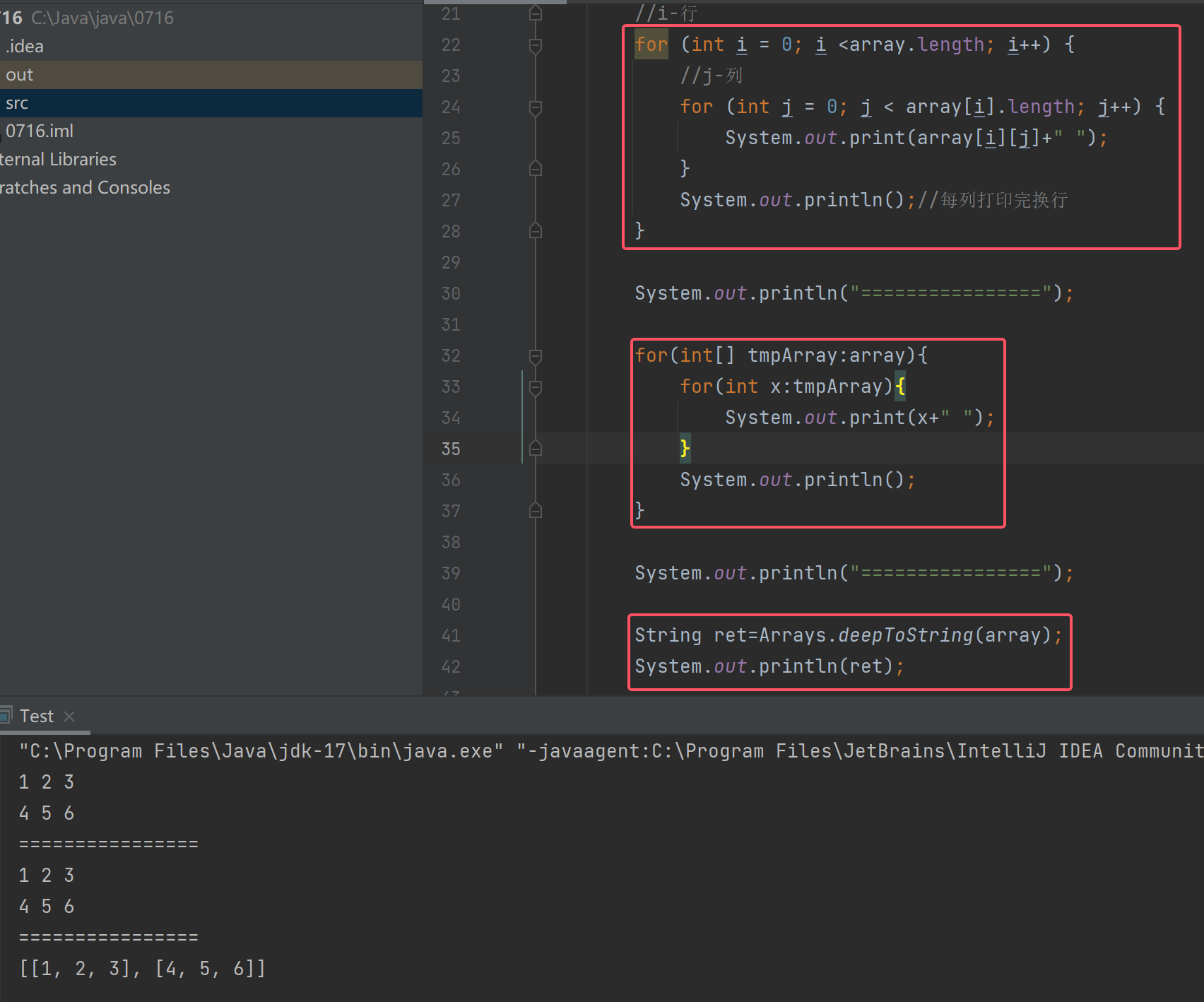
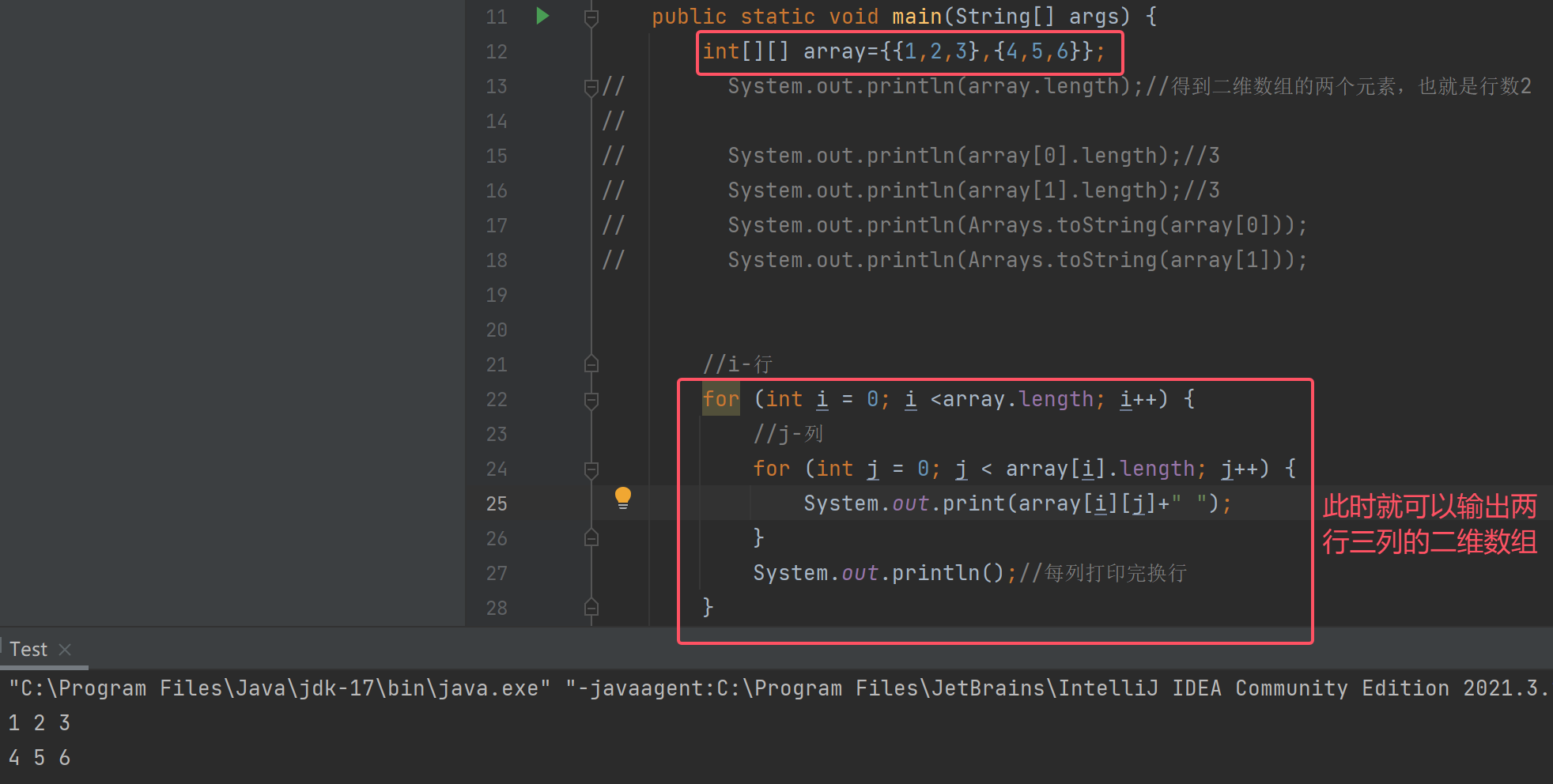
for循环遍历二维数组
我们对array数组的常规理解是这样的:
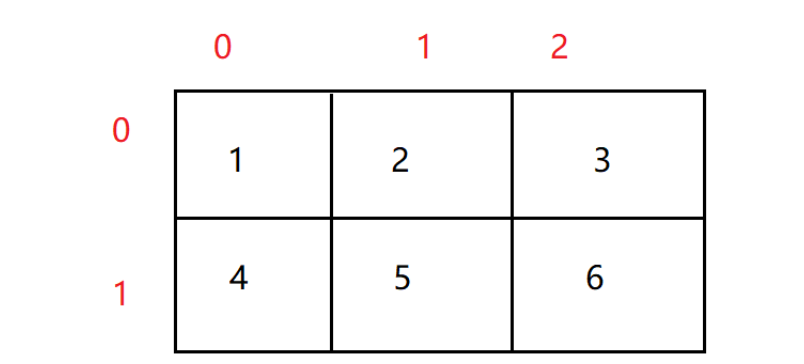
如果我们要遍历这个二维数组该怎么遍历呢?
我们一般会使用for循环写出这样的代码:
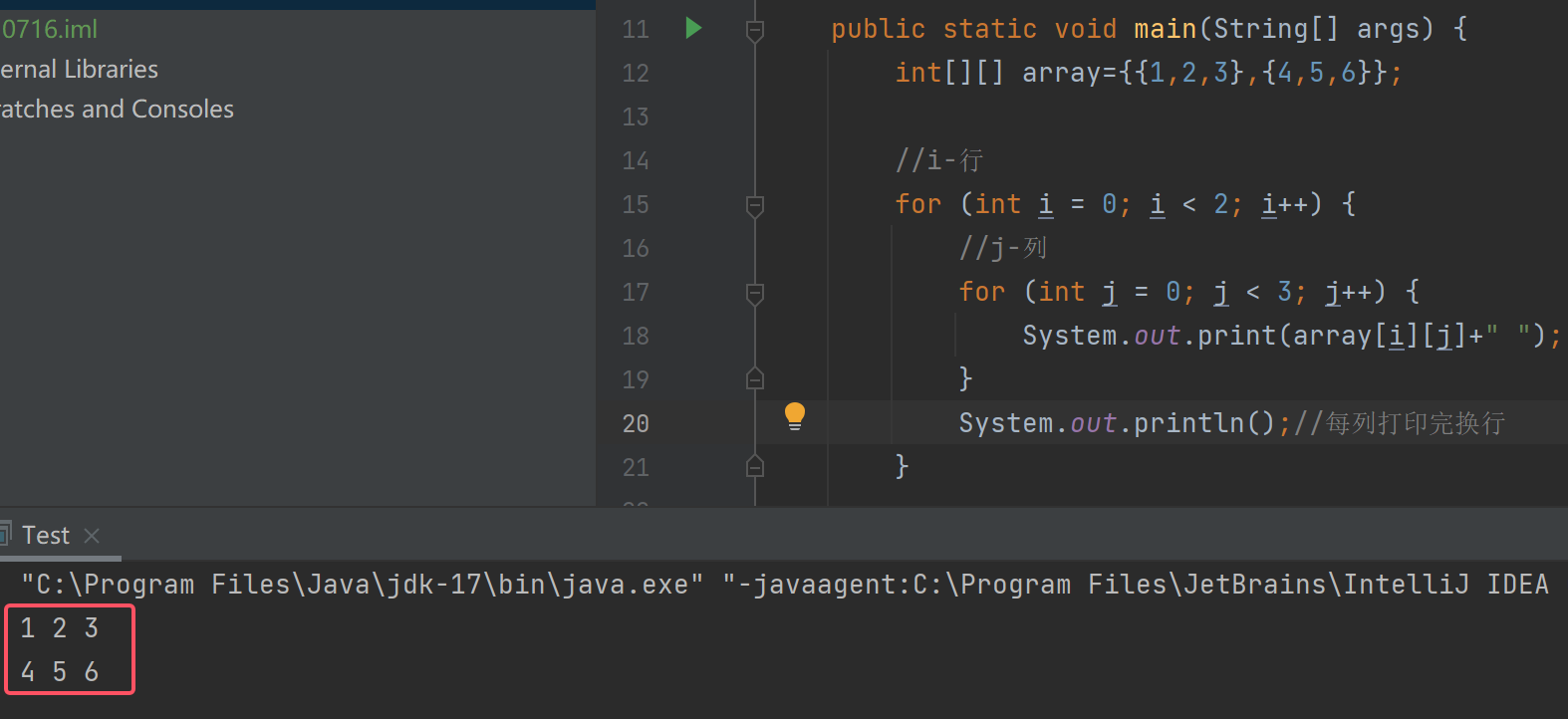
问题来了:以后想遍历二维数组的话,都得数几行几列写进for循环吗?
当然不是,二维数组就是一个特殊的一维数组
如何理解这句话呢?
写段代码:
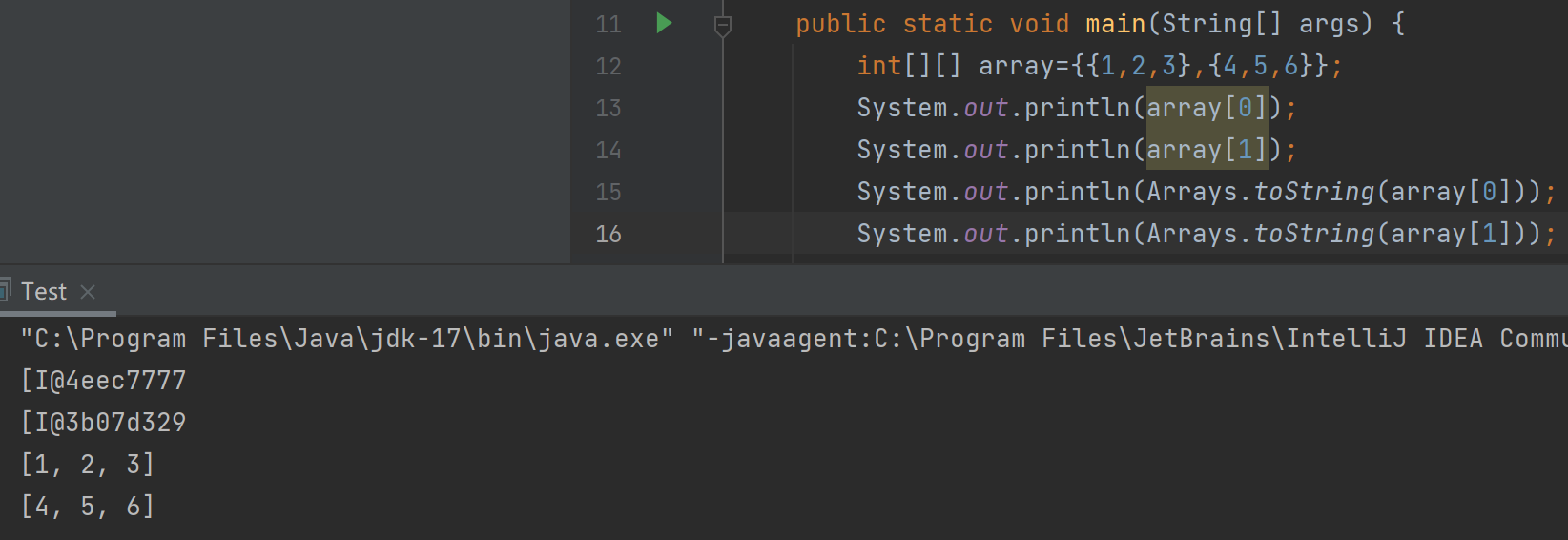
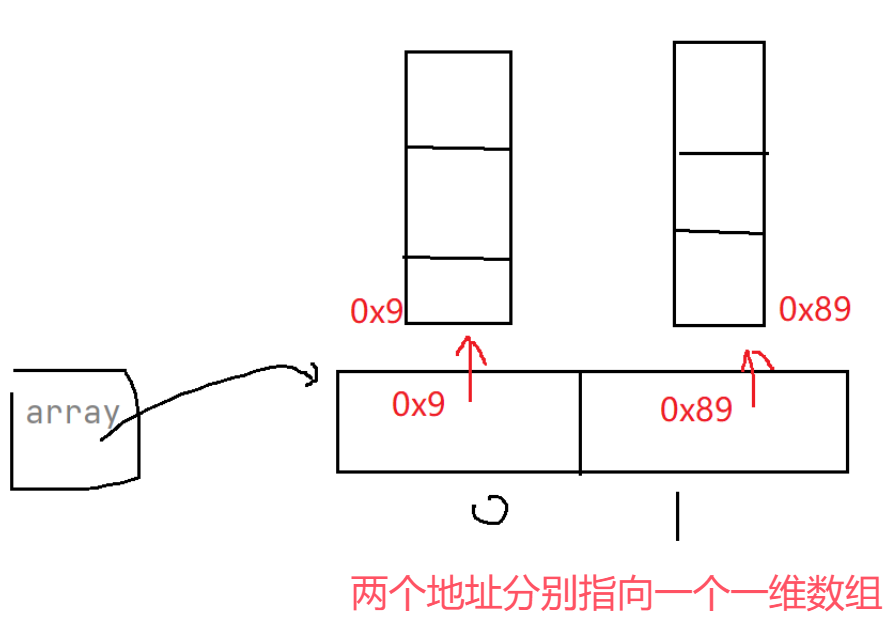
进一步说明了二维数组就是一个特殊的一维数组
所以我们可以像一维数组一样写array.length等等
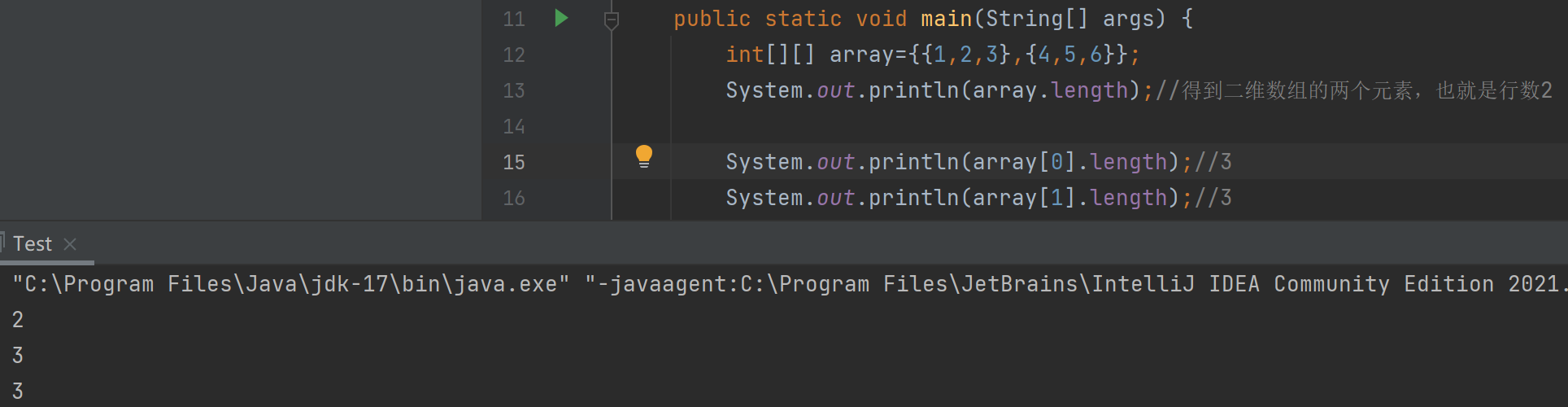
就像这幅图:
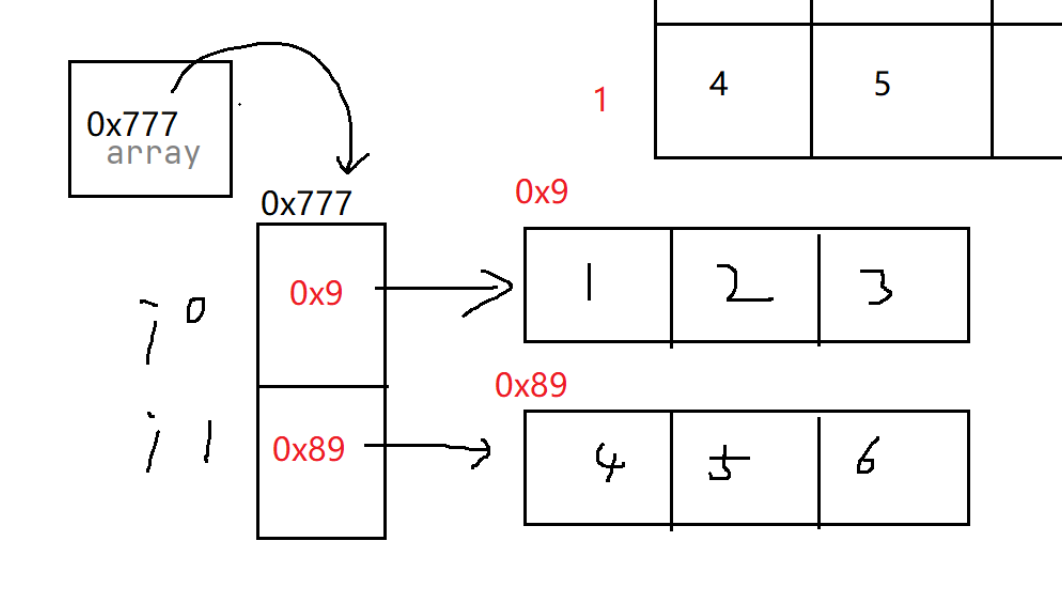
假如array这个引用里存的地址是0x777,那么array这个引用指向地址为0x777的这个对象…
回到这段代码:
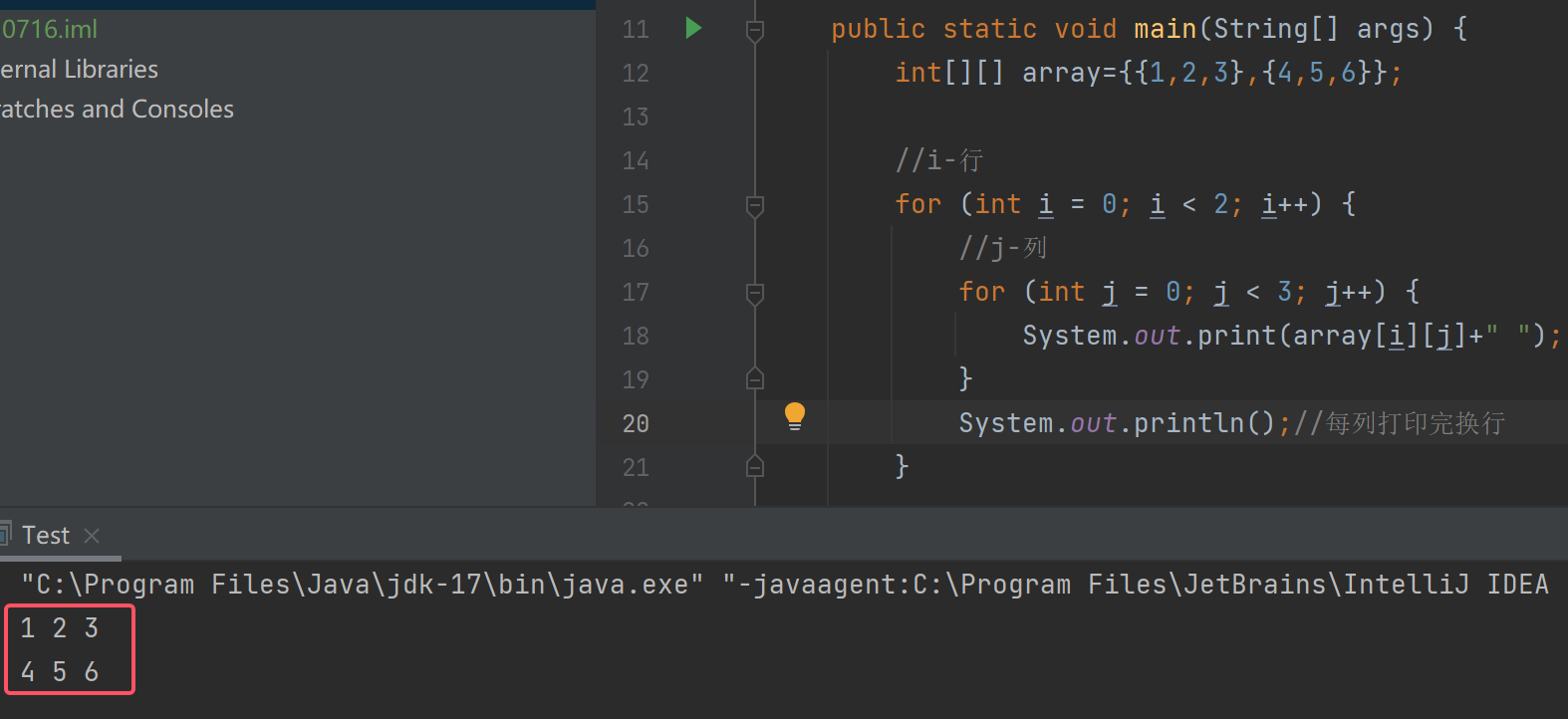
此时for循环的行也就是array.length,列数也就是array[i].length
for-each来遍历二维数组
冒号的右边是要操作的数组array,因为二维数组的每个元素是一维数组,所以冒号的左边应该用int[] 数组名来接收
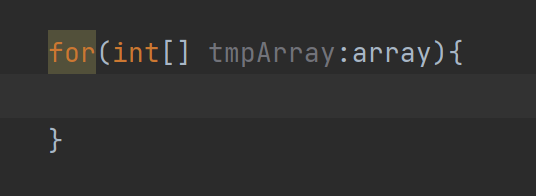
取出二维数组里的一维数组后,想要遍历,还得取出一维数组里的每个int元素。
要从一维数组tmpArray中取出元素,所以要写成这样
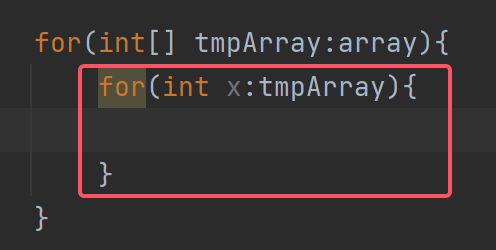
注:一维数组里的每个元素是int类型,所以冒号左边用int x来接收
完整代码:
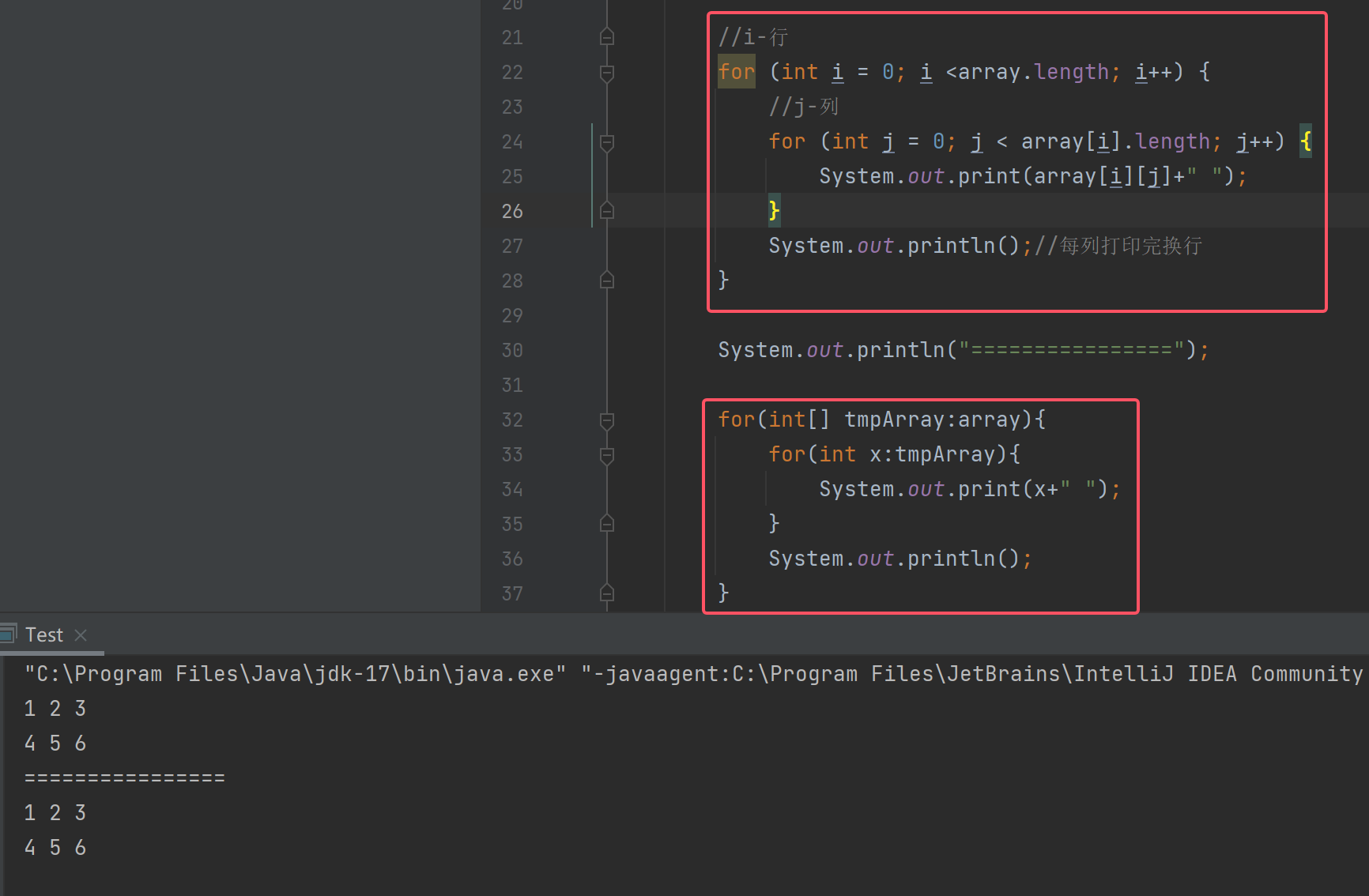
这两种方法都实现了对二维数组的遍历
使用Java方法
用Arrays.toString()可以将一维数组以字符串的形式打印出来;用Arrays.deepToString()可以将二维数组里的数据以字符串的形式打印出来