【源力觉醒 创作者计划】对比与实践:基于文心大模型 4.5 的 Ollama+CherryStudio 知识库搭建教程
👍👉一起来轻松玩转文心大模型吧👉一文心大模型免费下载地址: https://ai.gitcode.com/theme/1939325484087291906
👍👉一起来轻松玩转文心大模型吧👉一文心大模型免费下载地址: https://ai.gitcode.com/theme/1939325484087291906
文章目录
- 基于文心大模型 4.5 的 Ollama + CherryStudio 知识库搭建教程
- 1、搭建方案概述与对比分析
- 1.1 文心大模型 4.5 的特性与应用场景
- 1.2 三种知识库搭建方案对比
- 1.3 本教程采用的方案与实施路径
- 2、环境准备与软件安装
- 2.1 系统要求与硬件准备
- 2.2 Ollama 安装与配置
- 2.3 CherryStudio 安装与配置
- 3、文心大模型 4.5 本地部署
- 3.1 文心大模型 4.5 版本选择与下载
- 3.2 在 Ollama 中部署文心大模型 4.5
- 4、CherryStudio 与文心大模型 4.5 集成
- 4.1 CherryStudio 连接 Ollama 服务
- 4.2 嵌入模型选择与配置
- 4.3 知识库创建与文档管理
- 5、知识库测试与优化
- 5.1 知识库功能测试
- 5.2 知识库性能优化
- 6、不同知识库搭建方法对比与选择
- 6.1 基于 Ollama 的本地知识库方案
- 6.2 基于 API 的云端知识库方案
- 6.3 混合部署方案
- 6.4 方案选择决策指南
- 7、发展趋势与优化方向
- 7.1 知识库技术发展趋势
- 7.2 文心大模型 4.5 知识库优化方向
- 7.3 未来工作建议
- 8、小结
- 8.1 本教程总结
- 8.2 知识库应用价值
- 8.3 未来展望
- 9.踩坑
基于文心大模型 4.5 的 Ollama + CherryStudio 知识库搭建教程
1、搭建方案概述与对比分析
1.1 文心大模型 4.5 的特性与应用场景
文心大模型 4.5 是百度推出的多模态基础大模型,具有以下特点:
-
多模态能力:实现文本、图像和视频的混合训练,支持视觉理解和多模态推理
-
高效部署:支持多种训练框架版本(Paddle/PyTorch)、精度类型(FP8/W4A8)和用途状态(Base / 微调)
-
性能卓越:在多个文本和多模态基准测试中达到 SOTA 水平,在指令遵循、世界知识记忆、视觉理解和多模态推理任务上效果突出
-
性价比高:输入价格为 0.004 元 / 千 tokens,输出 0.016 元 / 千 tokens,约为 GPT4.5 价格的 1%
文心大模型 4.5 在知识库搭建中的应用场景包括:
-
企业知识管理:构建企业内部知识库,支持文档问答、流程查询
-
个人知识管理:打造个人专属知识库,支持学习资料、研究文献的智能检索
-
垂直领域应用:如法律、医疗等专业领域的知识库构建与问答系统
1.2 三种知识库搭建方案对比
基于文心大模型 4.5,我们可以采用三种不同的知识库搭建方案,下面对它们进行详细对比:
| 搭建方案 | 核心组件 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|---|
| 方案一:文心大模型 4.5 + Ollama 本地部署 | 文心大模型 4.5 本地版 + Ollama + CherryStudio | 1. 数据隐私性强2. 响应速度快3. 可定制化程度高 | 1. 硬件要求高2. 部署复杂度高3. 模型更新需要手动操作 | 对数据安全要求高的企业、研究机构或个人 |
| 方案二:文心大模型 4.5 API + CherryStudio | 文心大模型 4.5 API + 火山引擎向量数据库 + CherryStudio | 1. 无需本地部署2. 开箱即用3. 可扩展性强 | 1. 依赖网络连接2. 长期成本较高3. 数据可能存在安全风险 | 快速验证需求、资源有限的个人或小型团队 |
| 方案三:混合部署方案 | 文心大模型 4.5 API(轻量任务)+ 文心大模型 4.5 本地版(复杂任务) + CherryStudio | 1. 平衡性能与成本2. 兼顾隐私与效率3. 资源利用更合理 | 1. 部署复杂度最高2. 需要更专业的技术能力 | 对性能、成本和安全都有较高要求的中型企业 |
1.3 本教程采用的方案与实施路径
本教程将重点介绍方案一:文心大模型 4.5 + Ollama 本地部署 + CherryStudio的知识库搭建方案,这是因为:
-
该方案提供最高的数据隐私保护
-
能充分发挥文心大模型 4.5 的性能优势
-
适合长期、稳定的知识库应用需求
实施路径主要包括以下步骤:
- 环境准备与软件安装
- Ollama 配置与文心大模型 4.5 本地部署
- CherryStudio 安装与配置
- 知识库创建与文档管理
- 知识库测试与优化
2、环境准备与软件安装
2.1 系统要求与硬件准备
在开始搭建之前,需要确保您的系统满足以下要求:
硬件要求:
-
CPU:建议至少 4 核以上处理器,主频 2.5GHz 以上
-
内存:至少 16GB RAM(建议 32GB 或更高,根据模型大小调整)
-
存储:至少 50GB 可用硬盘空间(根据模型大小和知识库规模调整)
-
GPU(可选但强烈推荐):
-
入门级:NVIDIA GeForce RTX 3060/4060(支持 FP16 精度,适用于小规模模型)
-
专业级:NVIDIA RTX 4090/RTX A6000(支持更高精度和更大模型)
-
企业级:NVIDIA H100/A100(适用于大规模模型和高并发场景)
软件要求:
-
操作系统:Windows 10/11(64 位)、macOS 12 + 或 Linux(推荐 Ubuntu 20.04+)
-
驱动程序:
-
Windows/macOS:确保已安装最新的显卡驱动程序
-
Linux:需要安装 NVIDIA 驱动和 CUDA 工具包(版本需与 GPU 兼容)
-
Python 环境:建议 Python 3.9 或更高版本
2.2 Ollama 安装与配置
Ollama 是一个便于在本地部署和管理开源大语言模型的应用框架,以下是安装步骤:
Ollama 安装步骤:
安装后记着安装路径哈:
C:\Users\Administrator\AppData\Local\Programs\Ollama
- 下载 Ollama 安装包:
-
访问 Ollama 官网下载页面:https://ollama.com/download
-
根据您的操作系统选择对应的安装包(Windows/macOS/Linux)
2.安装 Ollama:
- Windows:双击安装程序(OllamaSetup.exe),按照提示完成安装
-
macOS:双击.dmg 文件,将 Ollama 图标拖放到 Applications 文件夹
-
Linux:使用以下命令安装(以 Ubuntu 为例):
curl -fsSL https://ollama.com/install.sh | sudo bash
3.验证安装:
-
打开终端或命令提示符,输入以下命令:
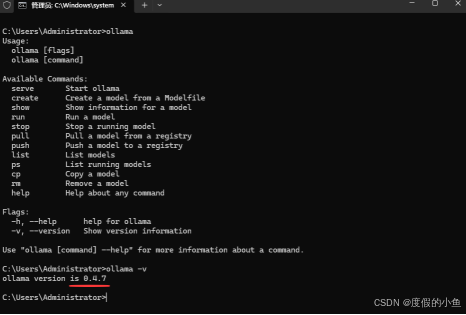
ollama -v -
如果输出版本号(例如 ollama version is 0.4.7),则说明安装成功,最新版本应该到Ollama v0.9.x 版本了
Ollama 配置建议:
1.设置 Ollama 服务开机自启(可选但推荐):
-
Windows:在任务管理器中找到 Ollama,右键选择 “属性”,设置为开机启动
-
macOS/Linux:编辑系统服务文件,将 Ollama 加入开机启动项
2.配置 Ollama 内存使用:
-
默认情况下,Ollama 会自动分配内存,但可以通过修改配置文件调整
-
在用户目录下创建.ollama/config.yaml文件,内容如下(示例):
memory: 16GB # 根据系统内存大小调整
3.启动 Ollama 服务:
- 在终端或命令提示符中输入:
ollama serve
- 每次使用 Ollama 前都需要先启动服务
2.3 CherryStudio 安装与配置
CherryStudio 是一款支持多模型服务的桌面客户端,用于创建和管理知识库:
CherryStudio 安装步骤:
1.下载 CherryStudio:
-
访问 CherryStudio 官网下载页面:https://cherryhq.github.io/cherry-studio/
-
根据您的操作系统选择对应的安装包(Windows/macOS/Linux)
2.安装 CherryStudio:
-
Windows:双击安装程序,按照提示完成安装
-
macOS:双击.dmg 文件,将 CherryStudio 图标拖放到 Applications 文件夹
-
Linux:解压下载的.tar.gz 文件,运行启动脚本
3.验证安装:
-
- 启动 CherryStudio,如能正常打开并显示界面,则说明安装成功
CherryStudio 配置建议:
1.基本设置:
-
打开 CherryStudio,进入 “设置” 界面
-
设置主题、语言、快捷键等基本参数
-
推荐启用 “自动保存对话历史” 和 “自动备份知识库” 功能
2.网络连接优化:
-
在 “设置”->“网络” 中,调整超时时间(建议设置为 30 秒以上)
-
启用 “网络代理”(如需要通过代理服务器访问网络)
3.模型服务配置:
- 在后续步骤中配置 Ollama 和文心大模型 4.5,此处暂时保持默认设置
3、文心大模型 4.5 本地部署
3.1 文心大模型 4.5 版本选择与下载
文心大模型 4.5 开源系列包含多个版本,需要根据您的硬件条件和需求选择合适的版本:
版本选择指南:
| 模型名称 | 参数量 | 适用场景 | 硬件要求 | 下载建议 |
|---|---|---|---|---|
| 文心 4.5-0.3B-pt | 0.3B | 入门测试、轻量级应用 | 无 GPU 要求,8GB 内存即可 | 推荐初学者选择 |
| 文心 4.5-21B-pt | 21B | 一般办公、知识问答 | 至少 16GB GPU 显存 | 适合大多数场景 |
| 文心 4.5-42B-pt | 42B | 专业研究、复杂推理 | 至少 24GB GPU 显存 | 适合专业场景 |
| 文心 4.5-42B-pt-4bit | 42B(4 位量化) | 性能优化、显存受限场景 | 至少 12GB GPU 显存 | 平衡性能与资源占用 |
| 文心 4.5-42B-pt-8bit | 42B(8 位量化) | 性能优化、显存受限场景 | 至少 16GB GPU 显存 | 平衡性能与资源占用 |
下载步骤:
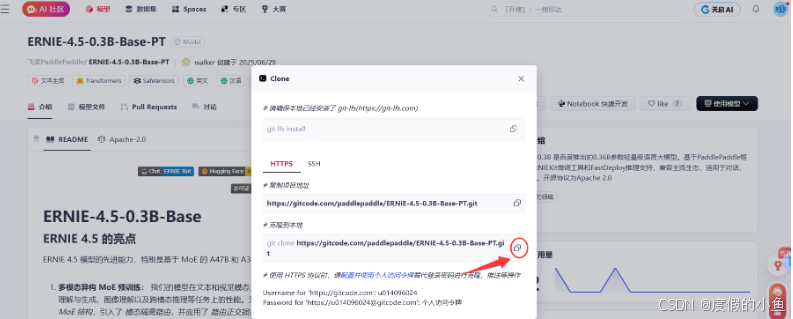
1.访问文心大模型 4.5 开源页面:
- GitCode 地址:https://ai.gitcode.com/theme/1939325484087291906
2.选择合适的模型版本:
-
根据硬件条件和需求,选择对应的模型版本
-
注意区分 PyTorch 版本(pt 后缀)和 PaddlePaddle 版本(paddle 后缀)
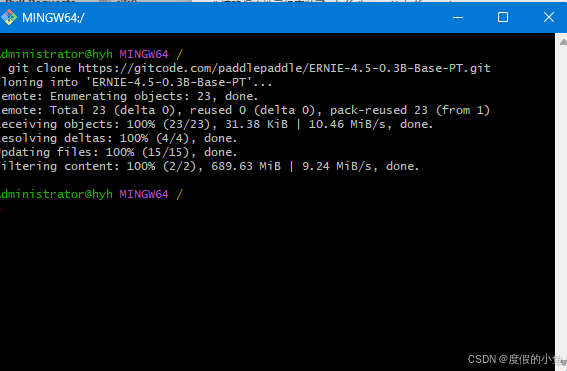
3.下载模型文件:
- 可以通过 Git 克隆整个仓库:
git clone https://gitcode.com/paddlepaddle/ERNIE-4.5-0.3B-Base-PT.git
- 也可以直接下载所需模型的压缩包,解压缩到指定目录
3.2 在 Ollama 中部署文心大模型 4.5
将下载的文心大模型 4.5 部署到 Ollama 中,需要以下步骤:
模型转换与适配:
1.模型格式转换(如需要):
-
文心大模型 4.5 原生使用飞桨框架,可能需要转换为 Ollama 支持的格式
-
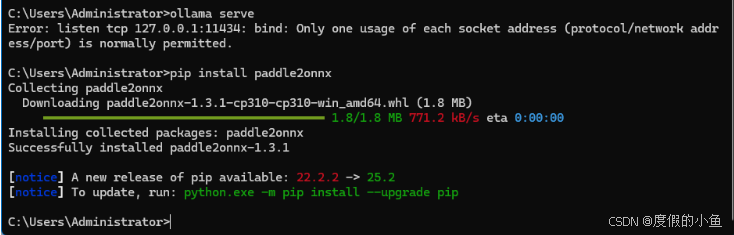
使用paddle2onnx工具将模型转换为 ONNX 格式:
pip install paddle2onnx pip install paddlepaddle==2.5.2 -i https://pypi.tuna.tsinghua.edu.cn/simplepaddle2onnx --model_dir ERNIE-4.5-0.3B-Base-PT --model_filename model.pdmodel --params_filename model.pdiparams --save_file ernie.onnx(指定 2.5.2 版本是为了保证与 paddle2onnx 的兼容性,使用清华源可加速下载)
- 验证安装
安装完成后,在 CMD 中输入python进入 Python 交互环境,执行以下命令:
import paddle
若没有报错,说明 PaddlePaddle 安装成功。exit()退出交换环境输入以上转换命令
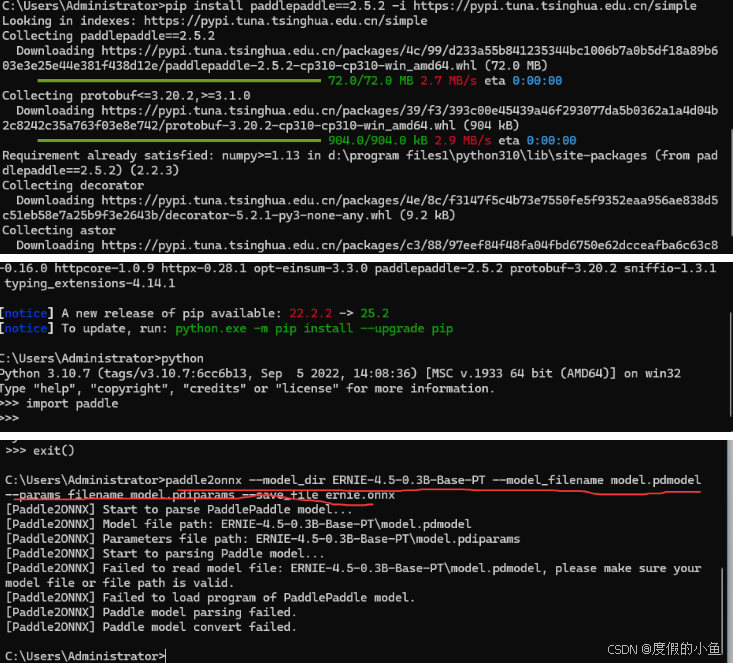
- 验证安装
2.创建 Ollama 模型配置文件:
-
在模型目录中创建modelfile文件(无文件扩展名)
-
文件内容如下(示例):
# 文心大模型4.5-21B配置文件 set MODEL=4.5-0.3B-Base-PT set PARAMETERS=21000M ernie.onnx
3.模型加载与测试:
1.启动 Ollama 服务:
- 在终端或命令提示符中输入:
ollama serve
2.加载文心大模型 4.5:
- 在新的终端或命令提示符中输入:
ollama run 4.5-0.3B-Base-PT
-
Ollama 会自动加载模型,如果是首次加载,会进行模型优化和缓存
-
3.测试模型运行:
-
模型加载完成后,可以在 Ollama 终端中输入文本进行测试:
ollama run 4.5-0.3B-Base-PT --prompt "你好,文心大模型4.5!"
- 如果模型返回正常响应,则说明部署成功
常见问题与解决方案:
- 内存不足问题:
-
错误提示:“Out of memory” 或 “CUDA out of memory”
-
解决方案:
-
减少模型参数(选择更小的模型版本)
-
启用模型量化(如 4 位或 8 位量化版本)
-
增加系统内存或使用更大显存的 GPU
2.模型加载失败:
-
错误提示:“Failed to load model”
-
解决方案:
-
检查模型文件是否完整
-
确认模型路径是否正确
-
尝试重新下载模型文件
3.性能不佳:
-
现象:响应速度慢,生成质量低
-
解决方案:
-
检查是否使用了 GPU 加速(确保 CUDA 和 cuDNN 正确安装)
-
调整模型参数(如 temperature、top_p 等)
-
尝试不同的模型版本,找到最适合的版本
4、CherryStudio 与文心大模型 4.5 集成
4.1 CherryStudio 连接 Ollama 服务
要在 CherryStudio 中使用本地部署的文心大模型 4.5,需要将 CherryStudio 连接到 Ollama 服务:
连接步骤:
- 启动 Ollama 服务:
- 在终端或命令提示符中输入:
ollama serve
- 打开 CherryStudio 配置界面:
-
启动 CherryStudio,点击界面左下角的 “设置” 图标
-
选择 “模型服务” 选项卡
- 添加 Ollama 服务:
-
点击 “添加模型服务” 按钮,选择 “Ollama”
-
输入 Ollama 服务的地址(默认为http://localhost:11434)
-
点击 “测试连接” 按钮,确保连接成功
- 添加文心大模型 4.5:
-
在 “模型服务” 界面,点击 “管理模型” 按钮
-
选择 Ollama 服务,搜索并添加文心大模型 4.5
-
等待模型加载完成,状态显示为 “可用”
配置优化建议:
- 设置默认模型:
-
在 “模型服务” 界面,将文心大模型 4.5 设置为默认模型
-
这样在创建新对话时会自动使用该模型
- 调整模型参数:
-
在 “模型服务” 界面,点击文心大模型 4.5 的 “设置” 按钮
-
调整参数如 temperature(推荐 0.7-1.0)、top_p(推荐 0.9)、max_tokens(推荐 2048)
-
根据实际需求调整其他参数,如 presence_penalty、frequency_penalty 等
- 设置多模型切换:
-
如果同时使用多个模型,可以在对话中轻松切换
-
在对话界面的右上角,点击模型名称即可切换模型
4.2 嵌入模型选择与配置
嵌入模型用于将文本转换为向量表示,是知识库构建的关键组件:
嵌入模型选择指南:
| 嵌入模型 | 维度 | 语言支持 | 特点 | 适用场景 |
|---|---|---|---|---|
| BAAI/bge-m3 | 1024 | 多语言(100 + 种) | 性能均衡,支持长文本 | 一般知识库 |
| BAAI/bge-large | 1024 | 多语言(100 + 种) | 精度更高,支持更长文本 | 专业知识库 |
| nomic-embed-text | 768 | 主要为英语 | 轻量级,速度快 | 英语为主的知识库 |
| 文心 - embedding-1.0 | 768 | 中文为主 | 中文理解更优 | 中文为主的知识库 |
嵌入模型安装与配置:
- 安装嵌入模型:
-
选择合适的嵌入模型(推荐 BAAI/bge-m3)
-
在终端或命令提示符中输入以下命令安装:
ollama pull bge-m3
- 在 CherryStudio 中添加嵌入模型:
-
打开 CherryStudio,进入 “管理” 界面
-
选择 “嵌入” 选项卡,点击 “添加” 按钮
-
选择之前安装的嵌入模型(如 bge-m3),点击 “确定”
- 设置默认嵌入模型:
-
在 “管理” 界面,点击嵌入模型的 “设置” 按钮
-
将其设置为默认嵌入模型
-
打开设置—模型服务,选择 ollama,点击开启,API 地址会自动出现,点击管理会自动添加嵌入模型
嵌入模型性能优化:
- 调整嵌入参数:
-
在嵌入模型的设置中,可以调整参数如 chunk_size(推荐 512-1024)、chunk_overlap(推荐 128-256)
-
根据文档大小和内容复杂度调整这些参数
- 使用 GPU 加速:
-
如果嵌入模型支持 GPU 加速,确保在设置中启用
-
这样可以显著提高向量化速度,特别是处理大量文档时
- 缓存嵌入结果:
-
启用嵌入结果缓存功能,避免重复处理相同文档
-
可以在设置中调整缓存大小和过期时间
4.3 知识库创建与文档管理
在 CherryStudio 中创建知识库并管理文档,是搭建知识库的核心步骤:
知识库创建步骤:
- 打开知识库管理界面:
-
在 CherryStudio 左侧导航栏中,点击 “知识库” 图标
-
进入知识库管理界面
- 创建新知识库:
-
点击 “添加” 按钮,弹出创建知识库对话框
-
输入知识库名称(如 “我的专业知识库”)
-
选择之前配置的嵌入模型(如 bge-m3)
-
点击 “确定” 完成创建
- 设置知识库参数:
-
在知识库管理界面,点击知识库名称进入设置
-
调整参数如 chunk_size(文档分块大小)、chunk_overlap(块重叠大小)
-
设置是否启用语义搜索、是否进行文档摘要等
文档添加与管理:
- 添加文档到知识库:
-
支持多种文档类型:PDF、DOCX、PPTX、XLSX、TXT、MD 等
-
点击 “添加文件” 按钮,选择本地文件或文件夹
-
也可以添加 URL、网站、笔记等作为知识库的来源
- 批量添加文档:
-
点击 “添加目录” 按钮,选择包含多个文档的文件夹
-
CherryStudio 会自动处理所有支持格式的文件
-
可选择是否递归处理子文件夹
- 管理已添加的文档:
-
在知识库管理界面,可以查看所有已添加的文档
-
对文档进行分类、标记、删除等操作
-
可以为文档添加自定义元数据,如标签、分类、作者等
文档预处理建议:
- 文档格式转换:
-
复杂格式的文档(如扫描件、加密文档)需要先转换为纯文本
-
推荐使用工具:Adobe Acrobat(PDF 处理)、Microsoft Word(DOCX 处理)
-
对于扫描件,使用 OCR 工具(如 Tesseract)转换为可搜索的 PDF
- 文档结构优化:
-
在添加文档前,优化文档结构(如添加标题、目录、段落分隔)
-
这样可以帮助模型更好地理解文档内容,提高检索准确率
- 文档去重与筛选:
-
避免重复文档或内容相似的文档
-
筛选出最相关、最权威的文档添加到知识库
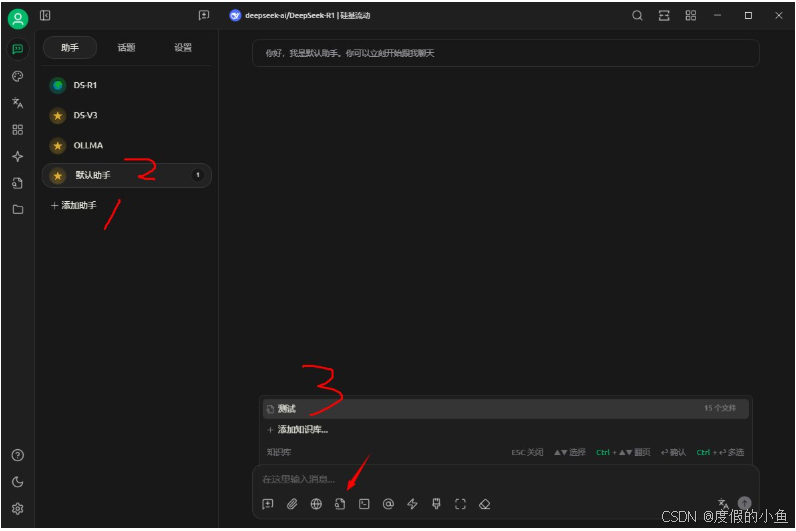
知识库入口: 在 CherryStudio 左侧工具栏,点击知识库图标,添加添加,即可进入管理页面;
重排模型:非必须。 重排模型用来给搜索结果“二次打分”,把最相关的内容挑出来排到前面,让答案更准、更顺。
添加文件:点击添加文件的按钮,打开文件选择;选择文件:选择支持的文件格式,如 pdf,docx,pptx,xlsx,txt,md,mdx 等,并打开;
向量化: 系统会自动进行向量化处理,当显示完成时(绿色 ✓),代表向量化已完成。这里我只能用攻略举例,政府文件来来是万万是不能对外的,大家可以自行添加文件测试。
目录: 可以添加整个文件夹目录,该目录下支持格式的文件会被自动向量化;
{% hint style=“info” %} 提示:
导入知识库的文档中的插图暂不支持转换为向量,需要手动转换为文本;
使用网址作为知识库来源时不一定会成功,有些网站有比较严格的反扒机制(或需要登录、授权等),因此该方式不一定能获取到准确内容。创建完成后建议先搜索测试一下。
一般网站都会提供 sitemap,如 CherryStudio 的 sitemap ,一般情况下在网站的根地址(即网址)后加/sitemap.xml 可以获取到相关信息。如 aaa.com/sitemap.xml 。
如果网站没提供 sitemap 或者网址比较杂可自行组合一个 sitemap 的 xml 文件使用,文件暂时需要使用公网可直接访问的直链的方式填入,本地文件链接不会被识别。
可以让 AI 生成 sitemap 文件或让 AI 写一个 sitemap 的 HTML 生成器工具;
直链可以使用 oss 直链或者网盘直链等方式来生成。如果没有现成工具也可到 ocoolAI 官网,登录后使用网站顶栏的免费文件上传工具来生成直链。 {% endhint %}
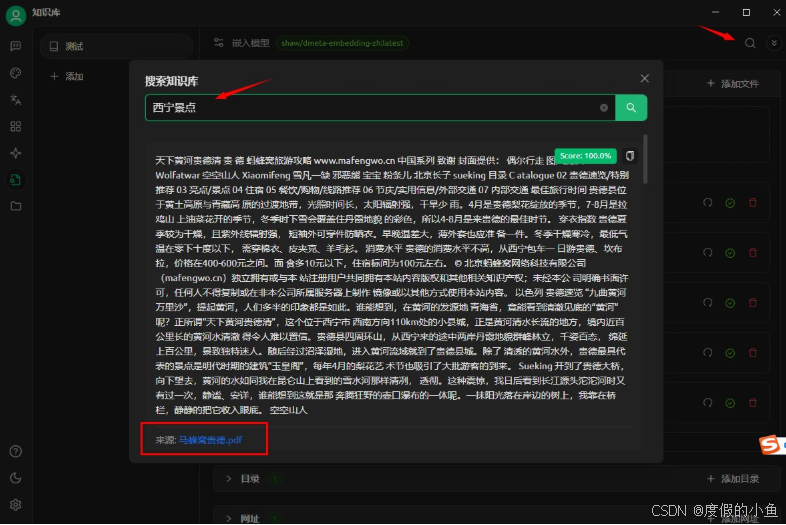
这里是用向量模型直接得到的结果,我们看到还是有瑕疵的,问西宁,给的是贵德的
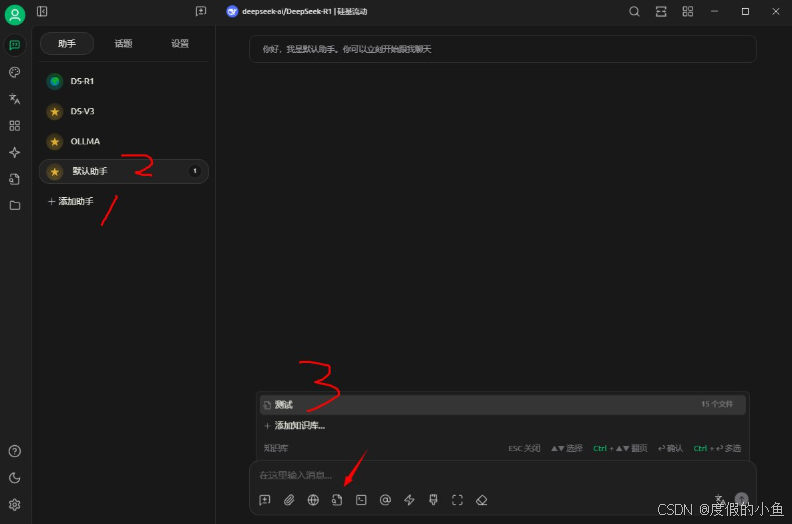
Cherry Studio 中创建一个新的助手,选择默认助手,在对话工具栏中,点击知识库,会展开已经创建的知识库列表,选择需要引用的知识库;
5、知识库测试与优化
5.1 知识库功能测试
在完成知识库搭建后,需要进行全面的功能测试,确保各项功能正常工作:
基础功能测试:
- 文档检索测试:
-
输入简单查询(如文档中的关键词),检查是否能正确检索到相关文档
-
测试不同查询词(如同义词、近义词)的检索效果
-
验证检索结果的准确性和相关性
- 问答功能测试:
-
输入基于知识库内容的问题,检查模型是否能正确回答
-
测试不同类型的问题(事实性问题、解释性问题、比较性问题)
-
验证回答的准确性、完整性和可读性
- 多文档关联测试:
-
输入涉及多个文档内容的复杂问题
-
检查模型是否能综合多个文档的信息进行回答
-
验证回答的一致性和连贯性
高级功能测试:
- 语义理解测试:
-
输入需要深入理解语义的问题(如隐含意义、隐喻、反讽)
-
检查模型是否能正确理解并给出合理回答
-
验证模型的语义理解能力
- 逻辑推理测试:
-
输入需要逻辑推理的问题(如因果关系、假设分析、结论推导)
-
检查模型是否能基于知识库内容进行合理推理
-
验证模型的逻辑推理能力
- 多语言支持测试:
-
如果知识库包含多种语言的文档,测试多语言查询能力
-
输入不同语言的查询,检查检索和回答的准确性
-
验证模型的多语言支持能力
5.2 知识库性能优化
通过优化,可以提升知识库的响应速度、检索准确率和回答质量:
检索性能优化:
- 向量数据库优化:
-
调整向量数据库的索引类型和参数
-
对于大规模知识库,考虑使用近似最近邻(ANN)索引
-
平衡检索速度和准确率,找到最佳平衡点
- 查询优化:
-
优化查询语句,提高查询效率
-
使用更精确的查询词,减少无关结果
-
测试不同查询方式(如布尔查询、短语查询、模糊查询)的效果
3 缓存策略优化:
-
启用查询结果缓存,提高重复查询的响应速度
-
设置合理的缓存大小和过期时间
-
定期清理无效缓存,释放内存资源
回答质量优化:
- 提示词优化:
-
设计更有效的提示词,引导模型生成更准确的回答
-
测试不同提示词结构(如问题前置、背景信息前置)的效果
-
添加示例问题和答案,引导模型学习特定的回答风格
- 上下文管理优化:
-
调整上下文窗口大小,平衡信息覆盖和性能
-
优化上下文内容选择策略,确保最相关的信息被包含
-
测试不同上下文长度(如 512、1024、2048 tokens)的效果
- 后处理优化:
-
对模型生成的回答进行后处理(如格式调整、内容筛选)
-
添加答案验证步骤,确保回答的准确性
-
实现引用来源自动标注,提高回答的可信度
性能监控与分析:
- 性能指标监控:
-
监控关键性能指标:响应时间、检索准确率、回答质量
-
使用工具(如 Prometheus、Grafana)进行性能监控和分析
-
定期生成性能报告,识别性能瓶颈
- 资源使用优化:
-
监控 CPU、内存、GPU 使用率
-
调整模型参数和资源分配,提高资源利用率
-
对于高负载场景,考虑分布式部署和负载均衡
- 定期性能测试:
-
定期进行性能测试,评估优化效果
-
对比不同优化策略的效果,选择最优方案
-
根据业务需求变化,动态调整优化策略
6、不同知识库搭建方法对比与选择
6.1 基于 Ollama 的本地知识库方案
优点:
-
数据安全性高:所有数据都存储在本地,避免了云端泄露风险
-
隐私保护好:完全控制数据访问权限,符合 GDPR 等隐私法规要求
-
响应速度快:无需网络传输,直接在本地处理,响应速度更快
-
定制化程度高:可以根据需求调整模型参数和知识库结构
-
长期成本低:一次性硬件投入后,长期运行成本较低
缺点:
-
硬件要求高:需要高性能 CPU/GPU 和大量内存,初始投入成本高
-
部署复杂度高:需要专业知识和技能来部署和维护系统
-
更新维护复杂:模型和知识库的更新需要手动操作
-
可扩展性有限:本地资源有限,难以处理大规模知识库或高并发请求
适用场景:
-
对数据安全和隐私要求极高的场景(如金融、医疗、政府)
-
需要处理敏感信息的企业或机构
-
网络条件有限或不稳定的环境
-
对响应速度要求极高的实时应用
-
长期、稳定的知识库应用需求
6.2 基于 API 的云端知识库方案
优点:
-
部署简单:无需本地部署,通过 API 即可快速接入
-
无需硬件投入:无需购买高性能服务器和 GPU,降低初始成本
-
可扩展性强:可以根据需求动态扩展资源,处理大规模请求
-
更新便捷:模型和服务由提供商维护,自动更新
-
多平台支持:可以在任何有网络连接的设备上使用
缺点:
-
数据安全风险:数据需要传输到云端,存在泄露风险
-
隐私问题:可能涉及第三方数据处理,不符合某些隐私法规
-
依赖网络连接:网络中断或延迟会影响服务质量
-
长期成本高:按调用次数付费,长期使用成本可能较高
-
定制化有限:无法修改模型参数和底层实现,灵活性较低
适用场景:
-
对数据安全和隐私要求不高的场景
-
快速验证需求、原型开发阶段
-
资源有限的个人或小型团队
-
需要跨平台访问的应用
-
临时性或短期的知识库应用需求
6.3 混合部署方案
优点:
-
平衡安全与效率:敏感数据在本地处理,非敏感数据使用云端服务
-
资源利用优化:根据任务复杂度和数据敏感性分配计算资源
-
弹性扩展能力:可以根据负载动态调整本地和云端资源分配
-
成本控制灵活:关键任务使用本地资源,非关键任务使用云端资源
-
适应不同场景:可以根据不同场景选择最适合的部署方式
缺点:
-
部署复杂度最高:需要同时管理本地和云端资源
-
技术要求高:需要掌握多种部署和集成技术
-
维护成本高:需要同时维护本地和云端系统
-
兼容性挑战:确保本地和云端系统之间的兼容性和一致性
-
管理复杂度增加:需要协调多个系统之间的交互和数据流动
适用场景:
-
对安全、性能、成本都有较高要求的中型企业
-
具有混合 IT 环境的大型企业
-
对数据安全和性能有不同要求的多场景应用
-
需要逐步从云端迁移到本地的过渡阶段
-
对成本敏感但又有一定安全要求的应用
6.4 方案选择决策指南
根据以下因素,选择最适合您的知识库搭建方案:
1. 数据安全与隐私要求:
-
高要求:选择基于 Ollama 的本地方案
-
中要求:考虑混合部署方案
-
低要求:可以选择基于 API 的云端方案
2. 性能需求:
-
高实时性要求:选择本地方案或混合方案中的本地部分
-
大规模并发请求:考虑云端方案或混合方案中的云端部分
-
中等性能需求:根据其他因素综合考虑
3. 成本预算:
-
高预算:可以考虑本地方案或混合方案
-
中等预算:混合方案可能是最佳选择
-
低预算:优先考虑云端方案
4. 技术能力:
-
具备专业技术团队:可以考虑本地方案或混合方案
-
技术能力有限:优先考虑云端方案
-
中等技术能力:混合方案可能更适合
5. 应用场景:
-
企业内部知识库:推荐本地方案或混合方案
-
面向公众的应用:推荐云端方案或混合方案
-
移动应用:推荐云端方案
6. 长期发展:
-
长期稳定应用:本地方案更具成本效益
-
短期或实验性项目:云端方案更灵活
-
不确定未来发展:混合方案提供更多灵活性
最终建议:
-
个人用户:优先考虑基于 API 的云端方案,成本低且易于使用
-
小型团队:根据数据敏感程度选择云端或混合方案
-
中型企业:推荐混合部署方案,平衡安全、性能和成本
-
大型企业:考虑本地方案或混合方案,尤其是对数据安全要求高的场景
-
政府机构 / 金融机构 / 医疗机构:强烈推荐基于 Ollama 的本地方案,确保数据安全和隐私保护
7、发展趋势与优化方向
7.1 知识库技术发展趋势
多模态知识库发展:
- 图像理解能力增强:未来的知识库将不仅支持文本,还能理解和处理图像内容
-
图像检索:通过图像内容检索相关文档
-
视觉问答:基于图像内容的问答能力
-
图文关联:建立文本与图像之间的语义关联
- 视频内容处理:
-
视频内容分析:自动提取视频中的文本、图像和音频信息
-
视频摘要生成:自动生成视频内容的文本摘要
-
视频问答:基于视频内容的问答能力
- 跨模态检索:
-
文本到图像检索:通过文本查询检索相关图像
-
图像到文本检索:通过图像查询检索相关文本
-
多模态融合检索:综合多种模态信息进行检索
大模型技术演进:
- 参数高效微调技术:
-
LoRA(Low-Rank Adaptation):通过低秩适应技术微调大模型
-
IA³(In-context Adaptation with Internal Attention):通过内部注意力机制进行上下文适应
-
PEFT(Parameter-Efficient Fine-Tuning):参数高效微调技术的综合应用
- 模块化大模型:
-
混合专家模型(MoE):多个专家模块协同工作,提高效率和性能
-
可插拔模块:根据任务需求动态加载和卸载模型模块
-
自适应架构:模型结构根据输入内容自动调整
- 模型压缩与加速技术:
-
量化技术:降低模型精度,减小模型体积
-
剪枝技术:去除冗余参数,提高推理速度
-
知识蒸馏:将大型教师模型的知识迁移到小型学生模型
知识库管理系统发展:
- 知识图谱增强:
-
知识库与知识图谱结合,提高语义理解能力
-
实体链接:将文档中的实体与知识图谱中的节点关联
-
关系抽取:自动提取文档中的实体关系,丰富知识图谱
- 主动学习与知识更新:
-
主动学习:系统主动发现知识缺口,提示用户补充信息
-
知识更新:自动检测文档更新,实时更新知识库
-
知识验证:验证知识库内容的准确性和时效性
- 智能知识推荐:
-
个性化推荐:根据用户行为和兴趣推荐相关知识
-
上下文感知推荐:根据当前任务和上下文推荐最相关的知识
-
预测性推荐:预测用户未来需求,提前推荐相关知识
7.2 文心大模型 4.5 知识库优化方向
模型性能优化方向:
- 模型量化与压缩:
-
探索更低精度的量化技术(如 2 位、4 位量化)
-
研究混合精度量化方法,平衡精度和性能
-
开发更高效的模型压缩算法,减小模型体积
- 模型并行与分布式推理:
-
研究模型并行策略,支持更大规模模型的推理
-
开发分布式推理框架,提高处理速度和吞吐量
-
优化模型分片策略,平衡各计算节点的负载
- 模型持续学习:
-
研究增量学习技术,使模型能够持续学习新的知识
-
开发知识遗忘控制机制,避免灾难性遗忘
-
设计有效的知识融合方法,将新知识融入现有模型
知识库管理优化方向:
- 智能文档处理:
-
开发更智能的文档解析器,理解复杂文档结构
-
研究文档内容的自动分类和标记技术
-
开发文档关系发现技术,建立文档之间的语义关联
- 知识质量评估:
-
建立知识库内容的质量评估体系
-
开发自动评估工具,检测内容的准确性和一致性
-
设计知识新鲜度评估机制,确保知识库内容的时效性
- 知识可视化:
-
开发知识图谱可视化工具,直观展示知识结构
-
设计文档关系可视化界面,帮助用户理解文档间关系
-
实现检索结果的可视化呈现,提高信息获取效率
应用场景扩展:
- 垂直领域深度应用:
-
医疗领域:开发医学知识库,支持临床决策支持
-
法律领域:构建法律知识库,支持法律检索和分析
-
金融领域:建立金融知识库,支持风险评估和投资决策
- 多语言知识服务:
-
开发跨语言知识检索和问答能力
-
建立多语言知识图谱,支持跨语言知识关联
-
提供多语言知识服务,满足全球化应用需求
- 实时知识更新:
-
开发实时知识获取和更新技术
-
建立知识变更通知机制,及时通知用户相关知识更新
-
实现知识版本管理,支持知识的历史版本查询和比较
7.3 未来工作建议
短期优化建议(3-6 个月):
- 模型性能优化:
-
对文心大模型 4.5 进行量化和剪枝,提高推理速度
-
优化 Ollama 和 CherryStudio 的集成,提高交互效率
-
实现模型参数的动态调整,根据任务复杂度自动调整参数
- 知识库管理系统优化:
-
改进文档预处理流程,提高文档解析准确性
-
优化检索算法,提高检索准确率和效率
-
开发知识库内容质量评估工具,确保知识质量
- 用户体验优化:
-
改进用户界面设计,提高交互效率
-
开发更智能的提示词建议功能,帮助用户构建更有效的查询
-
实现回答的自动引用和来源标注,提高回答可信度
中长期发展建议(1-3 年):
- 多模态知识库建设:
-
开发图像和视频内容的理解和检索能力
-
建立跨模态知识关联,实现多模态融合检索
-
开发基于多模态的问答系统,提高回答的丰富性和准确性
- 知识图谱与知识库融合:
-
构建领域知识图谱,增强语义理解能力
-
实现知识库与知识图谱的双向检索和推理
-
开发基于知识图谱的知识推理和解释能力
- 智能知识管理平台:
-
开发知识生命周期管理功能,支持知识的全流程管理
-
建立知识贡献和评价机制,鼓励用户参与知识建设
-
开发知识推荐和预警功能,提高知识的应用价值
技术研究方向:
- 小样本学习与知识迁移:
-
研究小样本学习技术,减少对大量标注数据的依赖
-
开发知识迁移方法,将一个领域的知识迁移到另一个领域
-
研究跨领域知识融合技术,提高知识库的通用性
- 主动学习与知识获取:
-
研究主动学习策略,提高知识获取效率
-
开发知识自动验证和纠正技术,提高知识准确性
-
研究知识更新和演化规律,建立知识更新模型
- 人机协同知识构建:
-
设计人机协同的知识构建工作流程
-
开发智能辅助工具,提高知识构建效率
-
研究人机交互模式,优化知识构建体验
通过以上优化和发展,基于文心大模型 4.5 的知识库系统将能够提供更高效、更准确、更智能的知识服务,为用户创造更大的价值。
8、小结
8.1 本教程总结
本教程详细介绍了基于文心大模型 4.5 的 Ollama + CherryStudio 知识库搭建方法,主要内容包括:
- 环境准备与软件安装:
-
系统要求与硬件准备
-
Ollama 安装与配置
-
CherryStudio 安装与配置
- 文心大模型 4.5 本地部署:
-
文心大模型 4.5 版本选择与下载
-
在 Ollama 中部署文心大模型 4.5
-
模型转换与适配技术
- CherryStudio 与文心大模型 4.5 集成:
-
CherryStudio 连接 Ollama 服务
-
嵌入模型选择与配置
-
知识库创建与文档管理
- 知识库测试与优化:
-
知识库功能测试
-
性能优化策略
-
性能监控与分析方法
- 不同知识库搭建方法对比与选择:
-
本地部署方案的优缺点与适用场景
-
云端 API 方案的优缺点与适用场景
-
混合部署方案的优缺点与适用场景
-
基于不同因素的方案选择决策指南
6 未来发展趋势与优化方向:
-
多模态知识库发展趋势
-
大模型技术演进方向
-
知识库管理系统发展趋势
-
文心大模型 4.5 知识库优化方向
通过本教程的学习,您应该能够:
-
理解基于文心大模型 4.5 的知识库搭建原理
-
掌握 Ollama 和 CherryStudio 的安装与配置方法
-
成功在本地部署文心大模型 4.5
-
创建和管理知识库,实现高效的知识检索和问答
-
根据自身需求选择最适合的知识库搭建方案
8.2 知识库应用价值
一个高效、安全、智能的知识库可以为个人和组织带来多方面的价值:
个人层面:
- 知识管理效率提升:
-
统一管理分散的知识资源,减少查找时间
-
快速检索所需信息,提高学习和工作效率
-
建立个人知识体系,促进知识积累和创新
- 学习能力增强:
-
个性化知识推荐,加速学习进程
-
智能问答辅助,解决学习中的疑惑
-
知识关联发现,拓展思维边界
- 生产力提升:
-
快速获取专业知识,支持决策和问题解决
-
自动化知识整理,减少重复性工作
-
持续学习和成长,提升个人竞争力
组织层面:
- 组织知识资产保护:
-
避免知识流失:员工离职不影响组织知识传承
-
知识沉淀:将个人知识转化为组织知识资产
-
-知识共享:促进组织内部知识流通和共享
- 业务效率提升:
-
快速响应客户需求:提高服务质量和客户满意度
-
标准化工作流程:减少错误和重复劳动
-
加速决策过程:提供准确、及时的信息支持
- 创新能力增强:
-
知识关联和融合:促进创新思维和解决方案
-
跨部门协作:打破信息孤岛,促进团队协作
-
持续改进:建立学习型组织文化,推动持续改进
8.3 未来展望
随着人工智能技术的不断发展,知识库系统将迎来更广阔的发展前景:
技术发展方向:
- 更强大的模型能力:
-
更大规模的模型参数:提高语义理解和生成能力
-
更高效的模型架构:降低计算资源需求
-
更先进的训练技术:提高模型泛化能力和适应性
- 更智能的知识处理:
-
自动知识发现:从海量数据中自动发现新知识
-
知识推理和演绎:基于现有知识进行推理和演绎
-
知识创造和创新:辅助人类进行知识创造和创新
- 更自然的人机交互:
-
多模态交互:支持语音、手势、表情等多种交互方式
-
上下文感知:理解用户意图和上下文信息
-
个性化服务:提供个性化的知识服务和体验
应用场景拓展:
- 垂直领域深度应用:
-
医疗健康:智能诊断辅助、个性化健康管理
-
金融服务:智能投资顾问、风险评估与管理
-
教育培训:个性化学习路径规划、智能辅导
2 智能助手与服务:
-
企业智能助手:提供一站式知识服务和业务支持
-
智能客服:理解客户需求,提供精准解决方案
-
智能办公:辅助日常工作,提高办公效率
- 智能决策支持:
-
战略决策支持:提供全面、准确的信息支持
-
运营决策支持:实时监控和分析业务数据
-
危机决策支持:快速响应突发事件,提供应急方案
社会价值创造:
- 知识普惠:
-
打破知识壁垒:使优质知识资源更广泛地共享
-
降低学习门槛:提供个性化、可访问的学习资源
-
促进教育公平:为不同地区、不同背景的人提供平等的学习机会
- 可持续发展:
-
知识循环利用:减少知识浪费,提高知识利用效率
-
智能资源管理:优化资源配置,减少资源消耗
-
创新驱动发展:促进创新和可持续发展
- 人类智能增强:
-
认知增强:辅助人类记忆、理解和思考
-
创造力提升:激发人类创造力和创新思维
-
决策优化:辅助人类做出更明智、更理性的决策
通过构建高效、安全、智能的知识库系统,我们能够更好地管理和利用知识资源,提高个人和组织的竞争力,推动社会的进步和发展。文心大模型 4.5 与 Ollama、CherryStudio 的结合,为这一目标提供了强大的技术支持和实现路径。希望本教程能够帮助您构建适合自己需求的知识库系统,实现知识的价值最大化。
最后,随着技术的不断进步和应用场景的不断拓展,知识库系统将在更多领域发挥重要作用,为人类的学习、工作和生活带来更多便利和价值。期待您在使用基于文心大模型 4.5 的知识库系统过程中,能够发现更多的应用场景和创新点,共同推动人工智能技术的发展和应用。
9.踩坑
模型路径问题