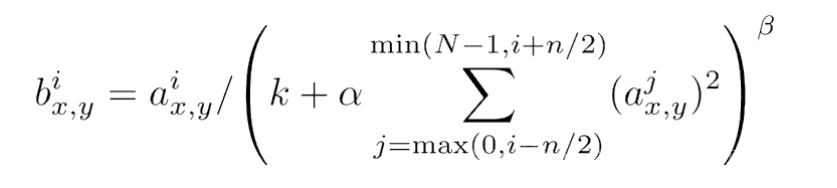CNN卷积神经网络之LeNet和AlexNet经典网络模型(三)
CNN卷积神经网络之LeNet和AlexNet经典网络模型(三)
文章目录
- CNN卷积神经网络之LeNet和AlexNet经典网络模型(三)
- 深度学习两大经典 CNN 模型速览
- 1. LeNet-5:CNN 的开山之作(1998)
- 2. AlexNet:深度学习里程碑(2012)
- 3. 核心差异对比
- 4. 可一键运行的 PyTorch 实现
- 4.1 LeNet-5(MNIST)
- 4.2 AlexNet(ImageNet 简化版,可在 CIFAR-10 上跑通)
- 5. 小结 & 面试高频问答
深度学习两大经典 CNN 模型速览
LeNet-5(1998)与 AlexNet(2012)——从 32×32 灰度手写数字到 224×224 彩色 ImageNet 的跨越
1. LeNet-5:CNN 的开山之作(1998)
1998年Yann LeCun等提出LeNets5 ,是第一个成功应用于手写数字识别问题并产生实际商业(邮政行业)价值的卷积神经网络

| 关键词 | 要点 |
|---|---|
| 任务 | MNIST 手写数字识别 |
| 输入 | 1×32×32 灰度图 |
| 结构 | 7 层:C1(6@28×28) → S2 → C3(16@10×10) → S4 → C5(120@1×1) → F6(84) → Output(10) |
| 卷积核 | 5×5 |
| 池化 | 2×2 平均池化 |
| 激活 | Sigmoid(历史版本) |
| 参数量 | ≈ 60 k |
| 创新 | 首次将 BP-CNN 成功用于商业(USPS 邮编) |
整体网络解读:
2. AlexNet:深度学习里程碑(2012)
| 关键词 | 要点 |
|---|---|
| 任务 | ImageNet 1000 类分类 |
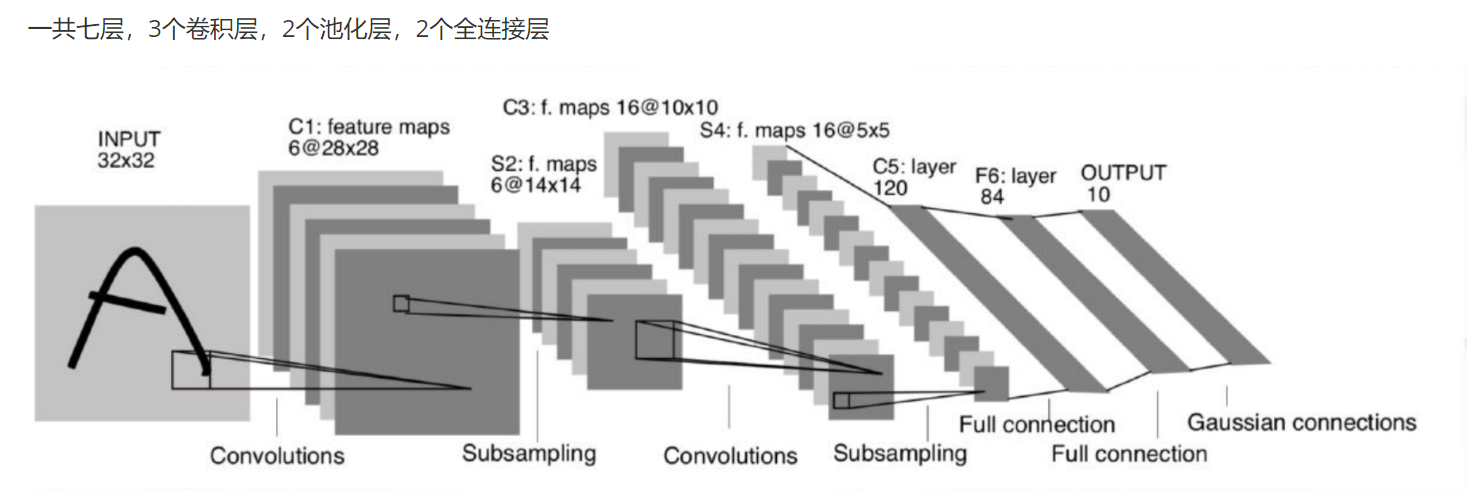
| 输入 | 3×224×224 |
| 结构 | 8 层:5 卷积 + 3 全连接 |
| 卷积核 | 11×11, 5×5, 3×3 |
| 池化 | 3×3 重叠最大池化 |
| 激活 | ReLU(首次大规模使用) |
| 正则 | Dropout 0.5、数据增强 |
| 归一化 | LRN(后被 BatchNorm 取代) |
| 训练 | 2×GTX 580 GPU(3 GB 显存) |
| 成绩 | Top-5 16.4 % → 15.3 %(7 模型融合) |
模型结构:
3. 核心差异对比
| 维度 | LeNet-5 | AlexNet |
|---|---|---|
| 输入尺寸 | 32×32 | 224×224 |
| 网络深度 | 7 层 | 8 层 |
| 激活函数 | Sigmoid | ReLU |
| GPU 训练 | 无 | 有(2 GPU 并行) |
| 数据集 | MNIST(60 k) | ImageNet(1.2 M) |
| 参数量 | 60 k | 60 M |
4. 可一键运行的 PyTorch 实现
环境:Python≥3.8,PyTorch≥1.12,torchvision
4.1 LeNet-5(MNIST)
# lenet5.py
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as Tclass LeNet5(nn.Module):def __init__(self, num_classes=10):super().__init__()self.features = nn.Sequential(nn.Conv2d(1, 6, 5), nn.Tanh(), # C1nn.AvgPool2d(2), # S2nn.Conv2d(6, 16, 5), nn.Tanh(), # C3nn.AvgPool2d(2), # S4nn.Conv2d(16, 120, 5), nn.Tanh() # C5)self.classifier = nn.Sequential(nn.Linear(120, 84), nn.Tanh(), # F6nn.Linear(84, num_classes) # Output)def forward(self, x):x = self.features(x)x = x.flatten(1)return self.classifier(x)def train_lenet():transform = T.Compose([T.Resize(32), T.ToTensor()])train_ds = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)train_dl = torch.utils.data.DataLoader(train_ds, batch_size=64, shuffle=True)net = LeNet5()opt = optim.Adam(net.parameters(), lr=1e-3)loss_fn = nn.CrossEntropyLoss()for epoch in range(3):for x, y in train_dl:opt.zero_grad()out = net(x)loss = loss_fn(out, y)loss.backward()opt.step()print(f"Epoch {epoch+1} loss={loss.item():.4f}")torch.save(net.state_dict(), 'lenet5.pth')if __name__ == "__main__":train_lenet()
4.2 AlexNet(ImageNet 简化版,可在 CIFAR-10 上跑通)
# alexnet_cifar.py
import torch, torchvision, torch.nn as nn, torch.optim as optim
from torchvision import transforms as Tclass AlexNet(nn.Module):def __init__(self, num_classes=10):super().__init__()self.features = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2),nn.Conv2d(64, 192, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2),nn.Conv2d(192, 384, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2),)self.classifier = nn.Sequential(nn.Dropout(0.5),nn.Linear(256*4*4, 4096), nn.ReLU(inplace=True),nn.Dropout(0.5),nn.Linear(4096, 4096), nn.ReLU(inplace=True),nn.Linear(4096, num_classes))def forward(self, x):x = self.features(x)x = torch.flatten(x, 1)return self.classifier(x)def train_alexnet():transform = T.Compose([T.Resize(64), T.ToTensor()])train_ds = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)train_dl = torch.utils.data.DataLoader(train_ds, batch_size=128, shuffle=True)net = AlexNet()opt = optim.SGD(net.parameters(), lr=0.01, momentum=0.9, weight_decay=5e-4)loss_fn = nn.CrossEntropyLoss()for epoch in range(10):for x, y in train_dl:opt.zero_grad()out = net(x)loss = loss_fn(out, y)loss.backward()opt.step()print(f"Epoch {epoch+1} loss={loss.item():.4f}")torch.save(net.state_dict(), 'alexnet_cifar.pth')if __name__ == "__main__":train_alexnet()
5. 小结 & 面试高频问答
| 问题 | 一句话答案 |
|---|---|
| LeNet-5 为何用 5×5? | 当时算力与感受野权衡下的最优。 |
| AlexNet 为何用 ReLU? | 解决 Sigmoid 梯度消失,加速 6× 训练时间。 |
| Dropout 的本质? | 训练时随机“掐掉”神经元,等价于多模型投票,减少过拟合。 |
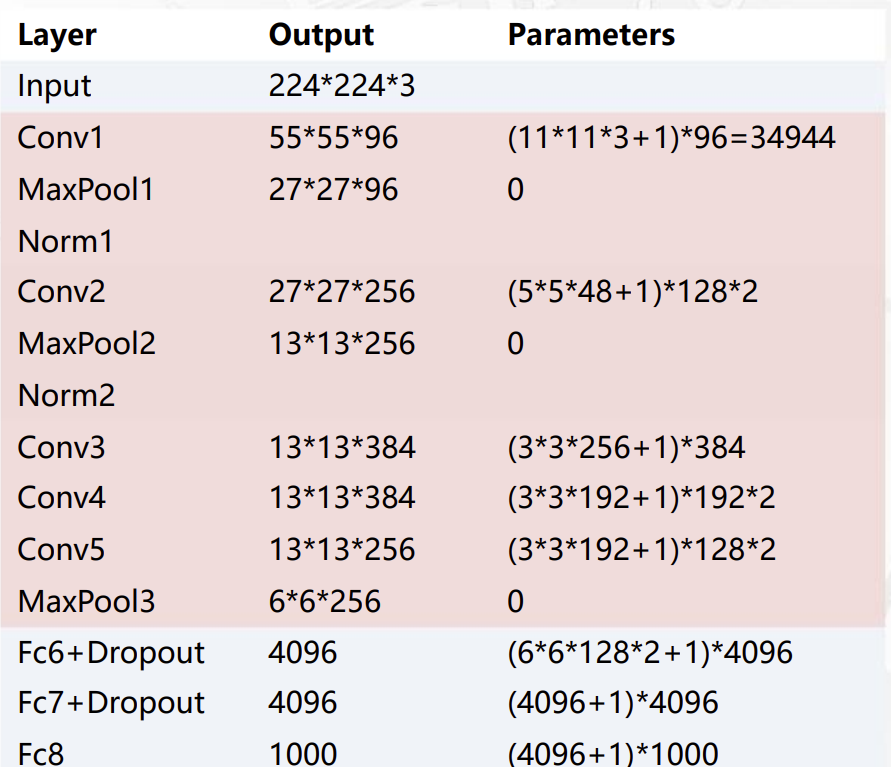
| LRN 现在还用吗? | 基本不用,BatchNorm 更稳定。 |
| 两个网络最大启示? | 更深、更大、更多数据 + GPU并行 是提升性能的核心路线。 |
1、Dropout:正则化方法,提高模型泛化能力。
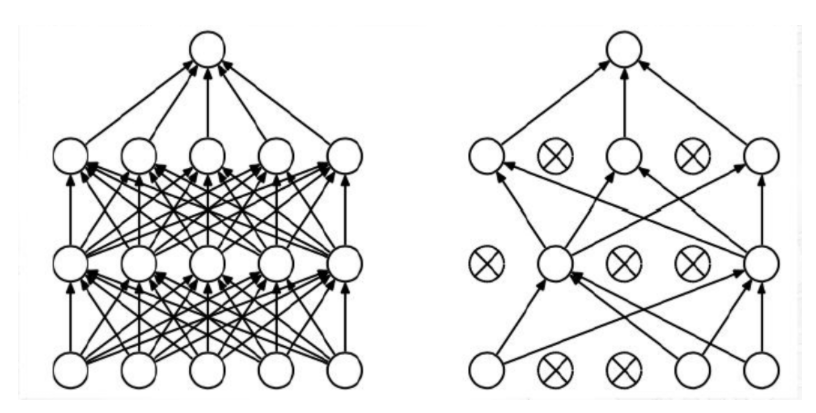
2、LRN:对于每个神经元,LRN会将其输出按照局部范围进行加权平均,然后将加权平均值除以一个尺度因子(通常为2),最后将结果取平方根并减去均值,得到归一化后的输出。