银行交易欺诈检测模型分析
项目介绍
1.1 项目背景与目标
确保经济交易的安全性和完整性是首要任务。随着在线交易和数字银行活动的日益增多,欺诈交易已成为对银行及其客户的重大威胁。欺诈活动(如未授权账户访问、身份盗用和可疑交易模式)会导致经济损失并损害客户信任。
为应对这一日益严重的问题,银行正在寻求实时检测和预防欺诈交易的解决方案。这包括分析历史交易记录(包括账户信息、交易金额、商家数据和时间戳),以识别表明欺诈行为的模式。目标是构建一个强大的欺诈检测系统,能够区分合法交易和潜在欺诈交易,同时将误报降至最低。数据集获取
1.2 数据集详情
1.2.1 数据字段说明
以下是用于欺诈检测分析的数据集字段详细说明:
| 列名 | 描述 |
|---|---|
| Customer_ID | 银行系统中每个客户的唯一标识符 |
| Customer_Name | 进行交易的客户姓名 |
| Gender | 客户性别(例如:男、女、其他) |
| Age | 客户在交易时的年龄 |
| State | 客户居住的州 |
| City | 客户居住的城市 |
| Bank_Branch | 客户持有账户的具体银行分支机构 |
| Account_Type | 客户持有的账户类型(例如:储蓄账户、支票账户) |
| Transaction_ID | 每笔交易的唯一标识符 |
| Transaction_Date | 交易发生的日期 |
| Transaction_Time | 交易发起的具体时间 |
| Transaction_Amount | 交易的财务价值 |
| Merchant_ID | 参与交易的商家的唯一标识符 |
| Transaction_Type | 交易性质(例如:取款、存款、转账) |
| Merchant_Category | 商家类别(例如:零售、在线、旅游) |
| Account_Balance | 交易后客户账户的余额 |
| Transaction_Device | 客户用于执行交易的设备(例如:移动设备、桌面设备) |
| Transaction_Location | 交易的地理位置(例如:纬度、经度) |
| Device_Type | 用于交易的设备类型(例如:智能手机、笔记本电脑) |
| Is_Fraud | 二元指示器(1或0),表示交易是否为欺诈交易 |
| Transaction_Currency | 交易使用的货币(例如:USD、EUR) |
| Customer_Contact | 客户的联系电话 |
| Transaction_Description | 交易的简要描述(例如:购买、转账) |
| Customer_Email | 与客户账户关联的电子邮件地址 |
这些列描述提供了将用于欺诈检测分析的数据的清晰理解。
1.3 环境准备
在开始之前,请确保安装了以下必要的库:
环境准备
在开始之前,请确保安装了以下必要的库:
pip install pandas numpy matplotlib seaborn scikit-learn xgboost
一、数据加载与初步探索
首先需要加载数据集并查看基本信息,了解数据的结构和质量。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.compose import make_column_transformer
from sklearn.preprocessing import OneHotEncoder
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, recall_score, f1_score, roc_auc_score, classification_report
import xgboost as xgb# 加载数据集
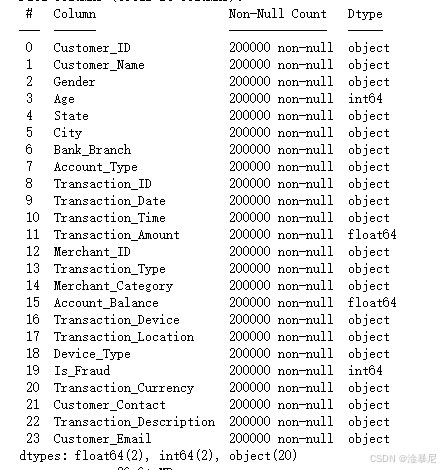
data = pd.read_csv('Bank_Transaction_Fraud_Detection.csv')# 查看数据基本信息
print(data.info())
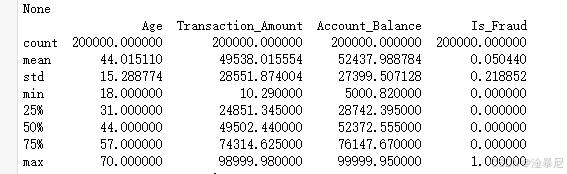
print(data.describe())# 检查缺失值
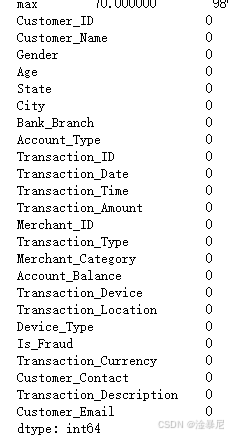
print(data.isnull().sum())
代码原理解释
首先,通过导入必要的库为后续分析做准备,因为欺诈检测需要数据处理、可视化和模型构建等多个环节。之前在环境准备部分已经安装了这些库,所以现在可以直接导入。
通过pd.read_csv()函数加载银行交易数据集,这是数据分析的基础步骤。因为只有加载数据后,才能进行后续的探索和建模。
使用data.info()查看数据类型和非空值情况,通过data.describe()获取数值特征的统计描述,这两个操作可以帮助我们初步了解数据的分布和质量。因为在构建模型前,了解数据的基本情况是必要的,可以发现潜在的问题如异常值或缺失值。
通过data.isnull().sum()检查各列的缺失值数量,因为缺失值会影响模型的准确性,所以需要在数据预处理阶段进行处理。如果存在大量缺失值,可能需要考虑删除或填充这些值。
二、数据可视化分析
数据可视化是理解数据分布和特征关系的重要手段,通过图表可以直观发现欺诈交易的模式。
2.1 欺诈交易分布
# 设置中文显示
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams["axes.unicode_minus"] = False # 解决负号显示问题# 1. 欺诈样本分布
plt.figure(figsize=(8, 6))
fraud_distribution = data['Is_Fraud'].value_counts()
ax = sns.barplot(x=fraud_distribution.index, y=fraud_distribution.values)
plt.title('欺诈交易分布')
plt.xlabel('是否欺诈 (0: 正常, 1: 欺诈)')
plt.ylabel('交易数量')# 添加数据标签
for p in ax.patches:ax.annotate(f'{p.get_height()}', (p.get_x() + p.get_width() / 2., p.get_height()),ha='center', va='bottom', fontsize=12)
plt.show()
代码原理解释
首先,设置中文显示参数,因为之前的环境可能默认不支持中文,这会导致图表中的中文标签显示为乱码。通过修改plt.rcParams字典,指定中文字体和解决负号显示问题,确保可视化结果清晰可读。
之前已经加载了数据集并检查了基本信息,现在通过sns.barplot()创建柱状图展示欺诈与正常交易的数量分布。因为了解样本分布是欺诈检测的基础,不平衡的样本分布会影响模型性能,需要后续处理。
通过data['Is_Fraud'].value_counts()获取两类样本的数量,使用plt.title()、plt.xlabel()和plt.ylabel()设置图表标题和坐标轴标签,使图表信息完整。通过循环添加数据标签,直观显示每个类别的具体数量,因为数值标签能帮助更精确地理解分布差异。
最后调用plt.show()显示图表,完成欺诈交易分布的可视化。这个图表能直观反映数据集中欺诈样本的比例,为后续模型选择提供依据,比如是否需要处理类别不平衡问题。

2.2 数值特征相关性热图
# 2. 数值特征相关性热图
plt.figure(figsize=(12, 10))
numeric_data = data.select_dtypes(include=['float64', 'int64'])
correlation = numeric_data.corr()
sns.heatmap(correlation, annot=True, cmap='coolwarm', fmt='.2f', linewidths=0.5)
plt.title('数值特征相关性热图')
plt.show()
代码原理解释
首先,通过data.select_dtypes()筛选出数值型特征,因为相关性分析主要针对连续变量,分类变量需要其他方法处理。之前的数据加载步骤已经确保数据可用,现在专注于数值特征间的关系分析。
使用numeric_data.corr()计算数值特征的相关系数矩阵,相关系数反映变量间的线性关系强度。因为欺诈检测中,了解特征间的相关性有助于识别冗余特征和潜在的风险因素,比如交易金额与欺诈可能性的关系。
通过sns.heatmap()绘制热图,设置annot=True显示具体相关系数值,cmap='coolwarm'使用冷暖色调区分正负相关性,fmt='.2f'保留两位小数。这些参数设置使热图既美观又信息丰富,便于快速识别强相关特征。
添加标题后调用plt.show()显示热图,该图表帮助发现特征间的多重共线性问题,因为高度相关的特征可能会影响模型的稳定性和解释性,需要在特征工程阶段考虑降维或选择代表性特征。
2.3 交易金额分布对比
# 3. 交易金额分布对比
plt.figure(figsize=(10, 6))
sns.histplot(data=data, x='Transaction_Amount', hue='Is_Fraud', kde=True, element='step', bins=30)
plt.title('交易金额分布对比 (欺诈 vs 正常)')
plt.xlabel('交易金额')
plt.ylabel('频率')
plt.legend(['正常', '欺诈'])
plt.show()
代码原理解释
首先,使用sns.histplot()绘制交易金额的分布直方图,因为交易金额是欺诈检测中的关键特征,不同类型交易的金额分布可能存在显著差异。之前的相关性分析可能已暗示金额与欺诈的关系,这里进一步可视化验证。
通过hue='Is_Fraud'参数将数据按欺诈状态分组,kde=True添加核密度估计曲线,使分布形状更清晰。element='step'和bins=30优化直方图的视觉效果,平衡细节和可读性。
设置标题和坐标轴标签后,通过plt.legend()手动指定图例标签,解决中文显示问题。因为默认图例可能使用变量值而非中文描述,手动设置确保读者理解图表内容。
调用plt.show()显示图表,该图能直观比较欺诈与正常交易的金额分布差异,比如欺诈交易是否更集中在特定金额区间,这对特征工程和模型构建有直接指导意义,例如是否需要对金额特征进行分箱处理。
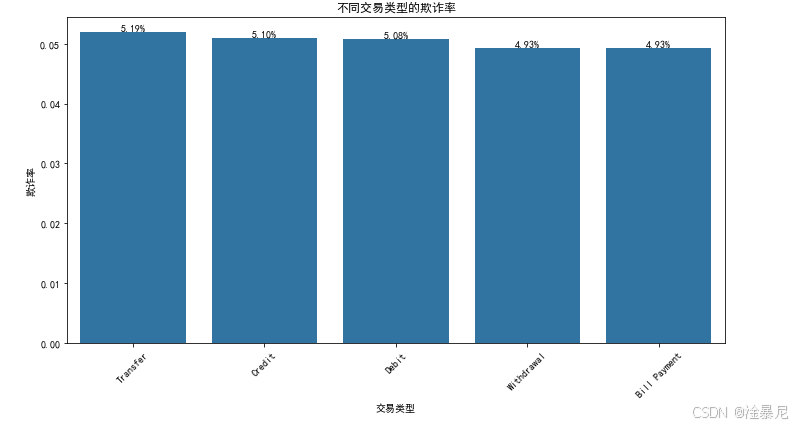
2.4 不同交易类型的欺诈率
# 4. 不同交易类型的欺诈率
plt.figure(figsize=(10, 6))
transaction_fraud = data.groupby('Transaction_Type')['Is_Fraud'].mean().sort_values(ascending=False)
ax = sns.barplot(x=transaction_fraud.index, y=transaction_fraud.values)
plt.title('不同交易类型的欺诈率')
plt.xlabel('交易类型')
plt.ylabel('欺诈率')
plt.xticks(rotation=45)# 添加数据标签
for p in ax.patches:ax.annotate(f'{p.get_height():.2%}', (p.get_x() + p.get_width() / 2., p.get_height()),ha='center', va='bottom', fontsize=10)
plt.tight_layout()
plt.show()
代码原理解释
首先,通过data.groupby('Transaction_Type')['Is_Fraud'].mean()计算各交易类型的欺诈率,因为不同交易类型的风险水平可能差异很大,例如转账和购物的欺诈概率不同。之前的分析关注整体分布,现在深入到类别型特征的风险分析。
使用sns.barplot()绘制柱状图,按欺诈率降序排列,使高风险交易类型一目了然。设置plt.xticks(rotation=45)旋转x轴标签,避免长类别名称重叠,确保可读性。
通过循环添加百分比格式的数据标签,使用:.2%将小数转换为带两位小数的百分比,因为百分比比小数更直观反映欺诈率高低。plt.tight_layout()自动调整布局,防止标签被截断。
最后显示图表,该图帮助识别高风险交易类型,为业务决策提供依据,比如对特定交易类型加强验证措施。同时,这也提示在特征工程中应保留交易类型信息,可能需要通过独热编码转化为模型可用的特征。
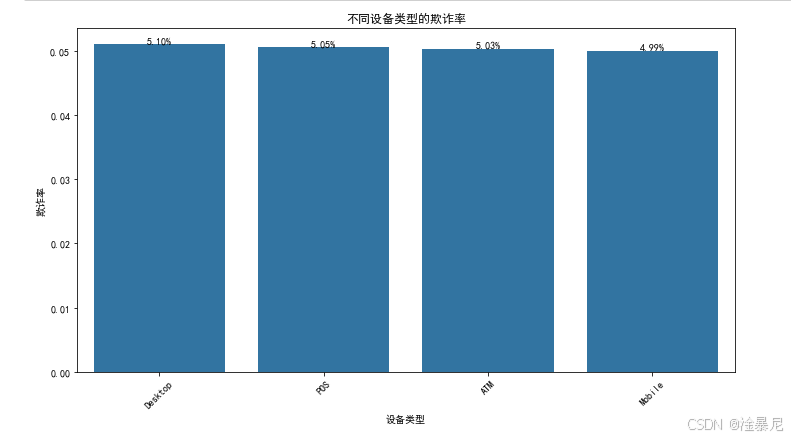
2.5 不同设备类型的欺诈率
# 5. 不同设备类型的欺诈率
plt.figure(figsize=(10, 6))
device_fraud = data.groupby('Device_Type')['Is_Fraud'].mean().sort_values(ascending=False)
ax = sns.barplot(x=device_fraud.index, y=device_fraud.values)
plt.title('不同设备类型的欺诈率')
plt.xlabel('设备类型')
plt.ylabel('欺诈率')
plt.xticks(rotation=45)# 添加数据标签
for p in ax.patches:ax.annotate(f'{p.get_height():.2%}', (p.get_x() + p.get_width() / 2., p.get_height()),ha='center', va='bottom', fontsize=10)
plt.tight_layout()
plt.show()
代码原理解释
首先,与交易类型分析类似,通过groupby('Device_Type')['Is_Fraud'].mean()计算不同设备类型的欺诈率,因为设备信息是识别欺诈的重要维度,例如某些设备可能更容易被黑客控制。之前的交易类型分析已展示类别特征的价值,这里进一步扩展到设备维度。
使用相同的柱状图绘制方法,按欺诈率降序排列设备类型,旋转x轴标签并添加百分比数据标签,确保图表清晰易读。因为代码结构与交易类型分析相似,可以复用之前的可视化逻辑,但关注不同的业务维度。
通过比较设备类型的欺诈率,可能发现某些设备类型的风险显著高于其他类型,这为风控策略提供方向,比如对高风险设备增加额外验证步骤。同时,这也验证了设备类型作为模型特征的重要性,应在特征工程中妥善处理。
三、数据预处理
数据预处理是提高模型准确性的关键步骤,主要包括缺失值处理和特征标准化等操作。
3.1 缺失值处理
# 处理缺失值(示例:数值列填充中位数,分类列填充众数)
numeric_cols = data.select_dtypes(include=['float64', 'int64']).columns.drop('Is_Fraud')
categorical_cols = data.select_dtypes(include=['object']).columnsfor col in numeric_cols:data[col].fillna(data[col].median(), inplace=True)for col in categorical_cols:data[col].fillna(data[col].mode()[0], inplace=True)
代码原理解释
首先,通过data.select_dtypes()分别筛选出数值型和分类型特征列,因为不同类型的特征需要采用不同的缺失值处理方法。之前的可视化分析已经揭示了数据分布特征,现在需要确保数据质量以满足建模要求。
之前检查缺失值时发现数据中存在缺失值,因此需要进行填充。对于数值型特征,使用中位数填充,因为中位数对异常值不敏感,能更好地保持数据分布特征。通过循环遍历每个数值列,调用fillna()方法并传入该列的中位数。
对于分类型特征,使用众数填充,因为分类变量没有数值意义,众数(出现频率最高的值)是最具代表性的填充值。通过data[col].mode()[0]获取众数并填充缺失值。
通过inplace=True参数直接修改原数据框,避免创建副本节省内存。完成缺失值处理后,数据将更适合后续的特征工程和模型训练,因为大多数机器学习算法无法处理缺失值。
四、特征工程
特征工程是将原始数据转化为模型可理解特征的过程,直接影响模型性能。主要包括特征与目标分离、数据集划分和特征预处理。
4.1 特征与目标变量分离
# 特征工程:分离特征和目标变量
X = data.drop('Is_Fraud', axis=1)
y = data['Is_Fraud']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
代码原理解释
首先,通过data.drop('Is_Fraud', axis=1)将特征数据(X)与目标变量(y)分离,因为机器学习模型需要输入特征和对应的标签进行训练。之前的预处理步骤已确保数据质量,现在需要明确模型的输入和预测目标。
之前处理的完整数据集包含特征和标签,通过drop('Is_Fraud', axis=1)移除标签列得到特征集X,直接提取’Is_Fraud’列作为目标变量y。这种分离是监督学习的基本要求,使模型能学习从特征到标签的映射关系。
使用train_test_split将数据划分为训练集(80%)和测试集(20%),设置test_size=0.2控制比例。因为需要用训练集训练模型,用独立的测试集评估泛化能力,避免模型过拟合训练数据。
通过stratify=y确保分层抽样,使训练集和测试集中的欺诈样本比例与原始数据一致。因为之前的可视化显示欺诈样本可能不平衡,分层抽样能保证评估指标的可靠性。random_state=42固定随机种子,确保结果可复现。
4.2 特征预处理管道构建
# 定义预处理步骤:
# 1. 数值特征 - 标准化
# 2. 分类特征 - 独热编码,但限制最大类别数(防止内存爆炸)# 设置最大类别数(根据内存调整,典型值10-100)
max_categories = 20 preprocessor = make_column_transformer((StandardScaler(), numeric_cols), # 数值列标准化(OneHotEncoder(max_categories=max_categories, drop='first', # 避免多重共线性sparse_output=False, # 如果内存允许,设为False更快handle_unknown='infrequent_if_exist'), # 处理未见类别categorical_cols),remainder='drop' # 忽略其他列
)
代码原理解释
首先,创建预处理管道统一处理不同类型特征,因为数值特征和分类特征需要不同的转换方法。之前已分离数值列(numeric_cols)和分类列(categorical_cols),现在需要对它们分别应用标准化和编码。
通过StandardScaler()对数值特征进行标准化,将特征转换为均值为0、标准差为1的分布。因为许多机器学习算法(如逻辑回归、SVM)对特征尺度敏感,标准化能加速模型收敛并提高准确性。
对于分类特征,使用OneHotEncoder进行独热编码,将类别变量转换为二进制向量。设置max_categories=20限制最大类别数,因为高基数分类特征会导致维度爆炸,增加内存消耗和过拟合风险。
通过drop='first'移除每个分类特征的第一列,避免多重共线性问题;sparse_output=False生成密集矩阵,加快后续模型训练速度(需权衡内存使用);handle_unknown='infrequent_if_exist'指定对测试集中未见类别的处理策略,增强模型鲁棒性。
使用make_column_transformer整合这些转换,自动将不同处理应用于对应列。remainder='drop'确保只处理指定列,忽略其他可能存在的无关特征。这个预处理管道将嵌入到模型训练流程中,确保数据转换的一致性和可复现性。
五、模型训练与评估
模型训练与评估是验证欺诈检测效果的关键步骤,我们将对比多种机器学习算法的性能并选择最优模型。
5.1 模型定义与训练
# 更新模型字典(移除了SVM,因为在高维特征下表现不佳)
models = {'Random Forest': RandomForestClassifier(random_state=42),'Logistic Regression': LogisticRegression(max_iter=1000, random_state=42),'XGBoost': XGBClassifier(random_state=42, eval_metric='logloss')
}# 存储评估指标
results = {'Model': [],'Accuracy': [],'Recall': [],'F1 Score': [],'AUC': []
}# 训练和评估每个模型
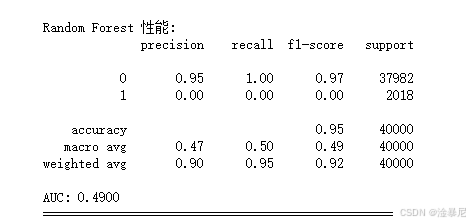
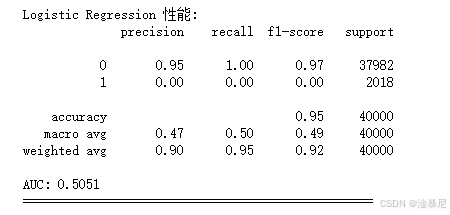
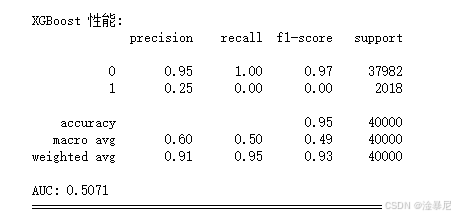
for name, model in models.items():print(f"\n=== 训练模型: {name} ===")# 创建管道pipeline = Pipeline([('preprocessor', preprocessor),('classifier', model)])# 训练模型pipeline.fit(X_train, y_train)# 预测y_pred = pipeline.predict(X_test)y_prob = pipeline.predict_proba(X_test)[:, 1]# 计算指标accuracy = accuracy_score(y_test, y_pred)recall = recall_score(y_test, y_pred)f1 = f1_score(y_test, y_pred)auc = roc_auc_score(y_test, y_prob)# 存储结果results['Model'].append(name)results['Accuracy'].append(accuracy)results['Recall'].append(recall)results['F1 Score'].append(f1)results['AUC'].append(auc)# 打印评估结果print(f"\n{name} 性能:")print(classification_report(y_test, y_pred))print(f"AUC: {auc:.4f}")print("="*50)
代码原理解释
首先,定义模型字典包含三种算法:随机森林、逻辑回归和XGBoost。之前在特征工程中提到高维特征可能带来挑战,因此移除了SVM模型,因为它在高维空间中计算成本高且性能不佳。选择这三种模型是因为它们在分类任务中表现优异:随机森林能处理非线性关系,逻辑回归可解释性强,XGBoost对不平衡数据敏感。
创建空字典results存储评估指标,因为需要对比多个模型的性能。包含准确率、召回率、F1分数和AUC四种指标,因为欺诈检测中不仅要关注整体准确率,更要重视召回率(减少漏检欺诈)和AUC(衡量区分能力)。
通过循环遍历每个模型,使用Pipeline将之前定义的preprocessor和当前模型串联。因为管道能确保预处理步骤(如标准化、编码)只在训练集上拟合,避免信息泄露到测试集,这是之前特征工程中强调的关键原则。
调用pipeline.fit(X_train, y_train)同时完成数据预处理和模型训练,简化工作流程。预测阶段生成类别预测(y_pred)和概率预测(y_prob),分别用于计算分类指标和AUC。
通过accuracy_score、recall_score等函数计算评估指标,其中召回率(Recall)是欺诈检测的核心指标,因为漏检欺诈(假阴性)比误判正常交易(假阳性)的代价更高。将结果存入results字典,最后打印详细评估报告,帮助分析各模型的优缺点。
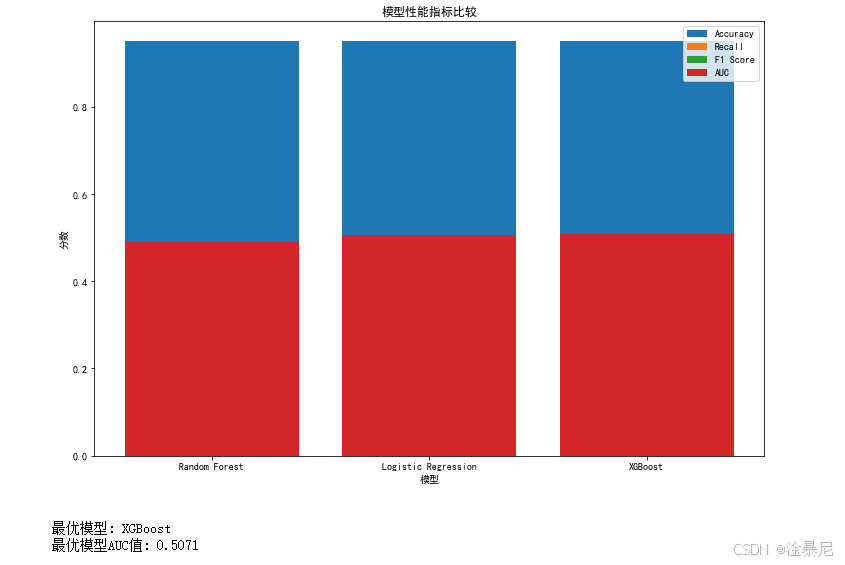
5.2 模型性能比较与可视化
# 转换为DataFrame查看比较结果
results_df = pd.DataFrame(results)
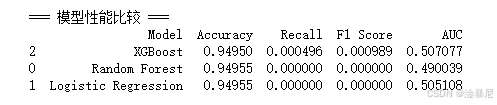
print("\n=== 模型性能比较 ===")
print(results_df.sort_values('Recall', ascending=False))# 可视化比较
plt.figure(figsize=(12, 8))
metrics = ['Accuracy', 'Recall', 'F1 Score', 'AUC']
for metric in metrics:plt.bar(results_df['Model'], results_df[metric], label=metric)
plt.title('模型性能指标比较')
plt.xlabel('模型')
plt.ylabel('分数')
plt.legend()
plt.show()# 选择最优模型(示例:选择AUC最高的模型)
best_model_idx = results_df['AUC'].idxmax()
best_model = results_df.loc[best_model_idx, 'Model']
print(f"\n最优模型: {best_model}")
print(f"最优模型AUC值: {results_df.loc[best_model_idx, 'AUC']:.4f}")
代码原理解释
首先,将results字典转换为DataFrame并按召回率降序排列,因为之前的评估强调召回率对欺诈检测的重要性,排序后能直观看到各模型在关键指标上的表现。DataFrame格式使结果更易读,支持后续分析和可视化。
通过循环绘制四种指标的柱状图,使用不同颜色区分各指标。因为单一指标不足以全面评价模型,同时展示准确率、召回率、F1分数和AUC能提供更完整的性能画像。图表标题和标签清晰标注,确保读者能快速理解各模型的优势领域。
选择AUC最高的模型作为最优模型,因为AUC衡量模型区分正负样本的整体能力,不受阈值影响,比准确率更适合不平衡数据集。之前的可视化分析已显示欺诈样本比例可能较低,AUC能更好地反映模型的综合性能。
最后输出最优模型名称和AUC值,为后续部署提供明确依据。这一过程通过客观指标而非主观判断选择模型,确保结果的可靠性和可解释性,符合机器学习项目的最佳实践。