1,需求
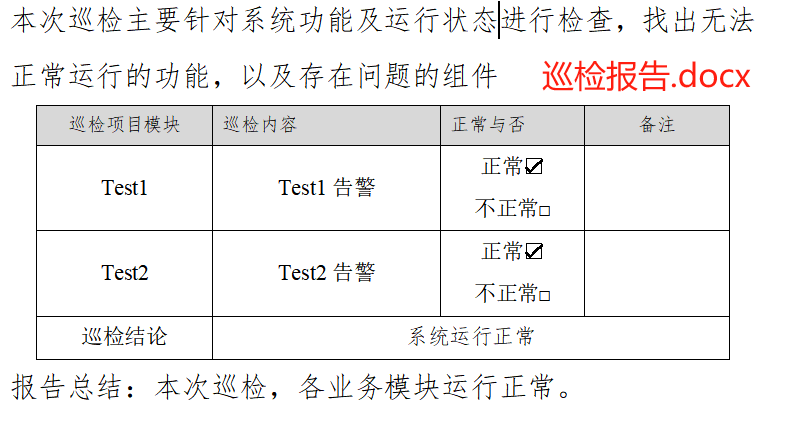
- 根据word模板文件,生成多个带日期后缀的word文件
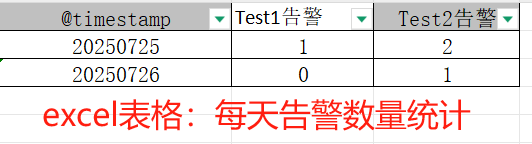
- 根据excel-每日告警统计数量,逐个修改当日的文档
2,实现
- shell脚本:根据word模板文件,生成多个带日期后缀的word文件
#!/bin/bash
baogao_doc_prename="巡检报告"
baogao_doc=$baogao_doc_prename".docx"
dest_dir=".\\"
start_date=$(date -d "20250725" +%Y%m%d)
end_date=$(date -d "20250726" +%Y%m%d)
holidays=("20240101"
)
current_sec=$(date -d "$start_date" +%s)
end_sec=$(date -d "$end_date" +%s)
day_count=0echo "近一年日期(排除节假日):"
while [ "$current_sec" -le "$end_sec" ]; docurrent_date=$(date -d "@$current_sec" +%Y%m%d)cp $baogao_doc $dest_dir/$baogao_doc_prename"-$current_date.docx"if [[ ! " ${holidays[@]} " =~ " $current_date " ]]; thenecho "$current_date"((day_count++))ficurrent_sec=$((current_sec + 86400))
doneecho "生成完成!有效日期数: $day_count"
- python脚本:根据excel-每日告警统计数量,逐个修改当日的文档
import pandas as pd
from docx import Document
from docx.table import _Cell
from docx.text.paragraph import Paragraph
import os
import re
from datetime import datetime, timedeltadef get_previous_day_filename(filename):date_pattern = r'(\d{8})' match = re.search(date_pattern, filename)if not match:print("错误: 文件名中未找到日期部分!")return Nonedate_str = match.group(1)try:date_obj = datetime.strptime(date_str, '%Y%m%d')except ValueError:print(f"错误: 日期格式不正确,应为YYYYMMDD,但得到了{date_str}")return Noneprevious_day = date_obj - timedelta(days=1)previous_day_str = previous_day.strftime('%Y%m%d')previous_day_filename = re.sub(date_pattern, previous_day_str, filename)return previous_day_filename
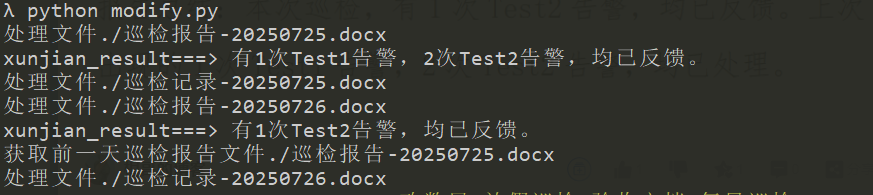
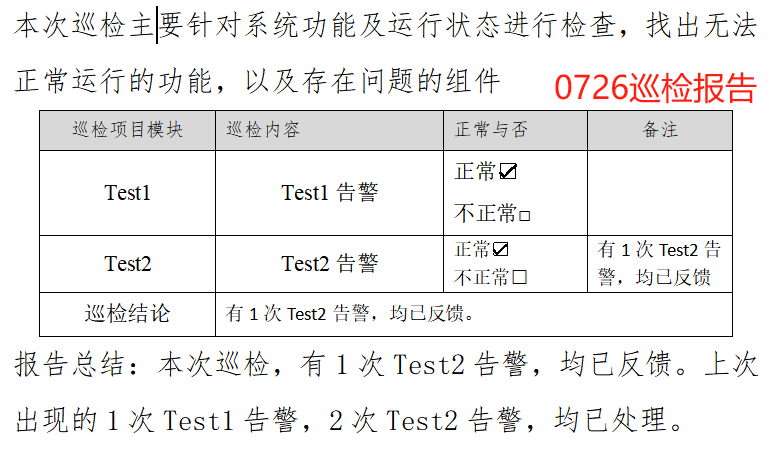
def replact_word_item( doc, replacements ):for paragraph in doc.paragraphs:for key, value in replacements.items():if key in paragraph.text:inline = paragraph.runsfor run in inline:run.text = run.text.replace(key, str(value) )def edit_xjbaogao_table(doc, excel_row, word_filename):inspection_table = doc.tables[0]total_result=[]for table_row in inspection_table.rows[1:]: system = table_row.cells[0].text.strip() feature = table_row.cells[1].text.strip() if system == 'Test1':alertCnt=int(excel_row['Test1告警'])if alertCnt > 0:result=str(alertCnt)+"次Test1告警"table_row.cells[3].text = "有"+ result +",均已反馈"#有xx告警,均已反馈 table_row.cells[2].text = "\r正常□\r不正常☑"total_result.append(result)if system == 'Test2':alertCnt=int(excel_row['Test2告警'])if alertCnt > 0:result=str(alertCnt)+"次Test2告警"table_row.cells[3].text = "有"+ result +",均已反馈"#有xx告警,均已反馈 table_row.cells[2].text = "\r正常□\r不正常☑"total_result.append(result)strresult = ",".join(total_result)xunjian_result="有"+strresult+",均已反馈。"# 有xx1告警,xx2告警,均已反馈 if system == '巡检结论' and "告警" in xunjian_result: table_row.cells[1].text = xunjian_result print("xunjian_result===>",xunjian_result) former_word_filename= get_previous_day_filename(word_filename) former_result=''if os.path.exists(former_word_filename):print(f"获取前一天巡检报告文件{former_word_filename}")try:doc_former = Document(former_word_filename)except FileNotFoundError:print(f"未找到文件: {former_word_filename},跳过处理")inspection_table_former = doc_former.tables[0] for table_row in inspection_table_former.rows[1:]: system = table_row.cells[0].text.strip() if system == '巡检结论': former_result=table_row.cells[1].text former_result=former_result.replace("有", "上次出现的").replace("均已反馈", "均已处理")xunjian_result+= former_result replacements = {"各业务模块运行正常。": xunjian_result} if "告警" in xunjian_result:replact_word_item( doc, replacements ) def update_word_remarks(excel_path, word_dir, word_file_prefix):"""从Excel读取数据,更新对应时间戳的Word文件备注栏:param excel_path: Excel文件路径:param word_dir: Word文件所在目录"""df = pd.read_excel(excel_path, sheet_name='sheet1')for _, excel_row in df.iterrows():timestamp = str(excel_row['@timestamp'])f1=word_file_prefix[0]word_filename = f"{word_dir}/{f1}-{timestamp}.docx" if os.path.exists(word_filename):print(f"处理文件{word_filename}")try:doc = Document(word_filename)except FileNotFoundError:print(f"未找到文件: {word_filename},跳过处理")continue edit_xjbaogao_table(doc, excel_row, word_filename)doc.save(word_filename)if __name__ == "__main__":EXCEL_PATH = "告警统计.xlsx" WORD_DIRECTORY = "." word_file_prefix = ["巡检报告" ]update_word_remarks(EXCEL_PATH, WORD_DIRECTORY,word_file_prefix)
3,结果
4,合并多个word文件
import os,re
from docx import Document
from docxcompose.composer import Composerdef extract_date_from_filename(filename):"""从文件名中提取日期,支持多种格式如:2024-03-15, 20240315, report_2024_03_15.docx"""basename = os.path.splitext(filename)[0]patterns = [r'(\d{4})[-_]?(\d{2})[-_]?(\d{2})', ]for pattern in patterns:match = re.search(pattern, basename)if match:year, month, day = match.groups()return f"{year}-{month}-{day}"return "未知日期"def merge_word_files_with_titles(source_dir, output_file="merged_document.docx"):"""合并指定目录下所有.docx文件,并在每个文档内容前添加原文件名作为标题:param source_dir: 包含待合并Word文件的目录路径:param output_file: 合并后的输出文件名"""files = [os.path.join(source_dir, f) for f in os.listdir(source_dir) if f.endswith(".docx")]files.sort(key=lambda x: extract_date_from_filename(x))if not files:print("目录中未找到.docx文件")returnmaster = Document()composer = Composer(master)for file_path in files:file_name = os.path.splitext(os.path.basename(file_path))[0]title_doc = Document()title_doc.add_heading(file_name, level=1) composer.append(title_doc)content_doc = Document(file_path)composer.append(content_doc)if file_path != files[-1]:page_break = Document()page_break.add_page_break()composer.append(page_break)composer.save(output_file)print(f"合并完成!文件已保存至: {output_file}")
if __name__ == "__main__":merge_word_files_with_titles(source_dir=r"./old2", output_file="./old-合并报告.docx")