ECCV | 2024 | LocalMamba:具有窗口选择性扫描的视觉状态空间模型
文章目录
- ECCV | 2024 | LocalMamba:具有窗口选择性扫描的视觉状态空间模型
- 本文贡献
- 摘要
- 引言
- 预备知识
- 状态空间模型
- 离散化
- 选择性状态空间模型
- 方法
- 视觉表征的局部扫描
- 自适应扫描的搜索
- 搜索空间
- 架构变体
- 实验
- ImageNet 分类
- 消融实验
ECCV | 2024 | LocalMamba:具有窗口选择性扫描的视觉状态空间模型
- 论文:https://arxiv.org/abs/2403.09338
- 代码:https://github.com/hunto/LocalMamba
- 会议:ECCV
- 时间:2024
本文贡献
开发的模型 LocalVim 和 LocalVMamba 结合了普通结构和分层结构,与先前的方法相比有显著增强。本研究的主要贡献包括:
- 为 SSMs 引入了一种新颖的扫描方法,包括在不同窗口内的局部扫描,结合全局上下文,显著增强了模型捕捉详细局部信息的能力。
- 开发了一种跨不同网络层搜索扫描方向的方法,使我们能够识别和应用最有效的扫描组合,从而提高网络性能。
- 提出了两种模型变体,分别采用普通结构和分层结构。
摘要
-
本文认为,提升视觉 Mamba(ViM)性能的关键在于优化序列建模的扫描方向。
-
传统的 ViM 方法在将空间令牌扁平化时,忽略了对局部二维依赖性的保留,从而拉长了相邻令牌之间的距离。

-
引入了一种新颖的局部扫描策略,将图像划分为不同的窗口,在保持全局视角的同时有效捕捉局部依赖性。
-
此外,考虑到不同网络层对扫描模式的偏好不同,提出了一种动态方法,为每一层独立搜索最优扫描选择,显著提高了性能。
引言
- 图像中二维空间模式的非因果性质与 SSMs 的因果处理框架存在内在冲突。
- 如图 1 所示,将空间数据扁平化为一维令牌的传统方法破坏了自然的局部二维依赖性,削弱了模型准确解释空间关系的能力。

图1:扫描方法示意图。(a)和(b):先前的方法Vim [60]和VMamba [32]遍历整个行或列轴,导致在捕捉同一语义区域内相邻像素之间的依赖关系时存在显著距离(例如,图像中的左眼)。(c)我们引入了一种新颖的扫描方法,将令牌划分为不同的窗口,便于在每个窗口内进行遍历(此处窗口大小为3×3)。这种方法增强了捕捉局部依赖关系的能力。
- 尽管 VMamba [32] 引入了二维扫描技术,通过在水平和垂直方向上扫描图像来解决这个问题,但它仍然难以在扫描序列中保持原本相邻令牌的接近性,而这对于有效的局部表示建模至关重要。
 - 引入了一种新方法来改进视觉 Mamba(ViM)中的局部表示,方法是将图像分割为多个不同的局部窗口。在进行跨窗口遍历之前,每个窗口都被单独扫描,确保同一二维语义区域内的令牌被紧密处理在一起。
- 引入了一种新方法来改进视觉 Mamba(ViM)中的局部表示,方法是将图像分割为多个不同的局部窗口。在进行跨窗口遍历之前,每个窗口都被单独扫描,确保同一二维语义区域内的令牌被紧密处理在一起。

图2:通过在原始扫描的基础上扩展我们的局部扫描机制,我们的方法在保持相近计算量(FLOPs)的情况下,显著提高了Vim [60]在ImageNet数据集上的准确率。
- 通过整合传统的全局扫描方向和局部扫描技术来设计基础块,使模型能够吸收全面的全局信息和细微的局部信息。
- 此外,为了更好地聚合来自这些不同扫描过程的特征,我们提出了一个空间和通道注意力模块 SCAttn,旨在识别和强调有价值的信息,同时过滤冗余信息。
- 考虑到扫描方向对特征表示的不同影响(例如,窗口大小为 3 的局部扫描擅长捕捉较小的物体或细节,而窗口大小为 7 的则更适合较大的物体),引入了一种方向搜索方法来选择最佳扫描方向。 这种可变性在不同的层和网络深度中尤为明显。受 DARTS [29] 的启发,我们从离散选择转向连续域,由一个可学习的因子表示,以便在单个网络中整合多个扫描方向。在该网络训练完成后,通过识别那些被分配最高概率的方向来确定最有效的扫描方向。
预备知识
状态空间模型
结构化状态空间模型(SSMs)是深度学习中的一类序列模型,其特征是能够通过中间潜在状态h(t)∈RNh(t) \in \mathbb{R}^Nh(t)∈RN 将一维序列 x(t)∈RLx(t) \in \mathbb{R}^Lx(t)∈RL 映射到 y(t)∈RLy(t) \in \mathbb{R}^Ly(t)∈RL:
h′(t)=Ah(t)+Bx(t),y(t)=Ch(t),(1)h'(t) = A h(t) + B x(t), \\ y(t) = C h(t),\tag{1}h′(t)=Ah(t)+Bx(t),y(t)=Ch(t),(1)
其中,系统矩阵A∈RN×NA \in \mathbb{R}^{N \times N}A∈RN×N、B∈RN×1B \in \mathbb{R}^{N \times 1}B∈RN×1和C∈RN×1C \in \mathbb{R}^{N \times 1}C∈RN×1分别控制动态和输出映射。
离散化
在实际应用中,为了便于实现,需要对式(1)所描述的连续系统进行离散化。这里采用零阶保持假设,在特定的采样时间尺度Δ∈R>0\Delta \in \mathbb{R}>0Δ∈R>0下,将连续时间参数(A,B)(A, B)(A,B)转换为离散时间参数(A‾,B‾)(\overline{A}, \overline{B})(A,B),转换公式如下:
A‾=eΔAB‾=(ΔA)−1(eΔA−I)⋅ΔB(2)\overline{A}=e^{\Delta A} \\ \overline{B}=(\Delta A)^{-1}\left(e^{\Delta A}-I\right) \cdot \Delta B \tag{2}A=eΔAB=(ΔA)−1(eΔA−I)⋅ΔB(2)由此得到离散化的模型表达式:
ht=A‾ht−1+B‾xt,yt=Cht(3)\begin{aligned} h_{t} &=\overline{A} h_{t-1}+\overline{B} x_{t}, \\ y_{t} &=C h_{t} \tag{3} \end{aligned}htyt=Aht−1+Bxt,=Cht(3)
为提高计算效率,式(3)所描述的迭代过程可通过并行计算加速,具体方式是采用全局卷积操作:
y=x⊛K‾其中K‾=(CB‾,CAB‾,…,CA‾L−1B‾)(4)\begin{aligned} y &=x \circledast \overline{K} \\ \text{其中}\quad \overline{K} &=\left(C \overline{B}, C \overline{A B}, \ldots, C \overline{A}^{L-1} \overline{B}\right) \tag{4} \end{aligned}y其中K=x⊛K=(CB,CAB,…,CAL−1B)(4)
式中,⊛\circledast⊛表示卷积操作,K‾∈RL\overline{K} \in \mathbb{R}^{L}K∈RL是 SSM 的核。这种方法借助卷积同时对序列上的输出进行合成,从而提高了计算效率和可扩展性。
选择性状态空间模型
传统S4模型虽具线性时间复杂度,但因参数静态,序列上下文捕捉能力有限。 Mamba作为选择性状态空间模型,引入动态选择性机制,采用输入依赖的参数化方式,从输入序列直接计算参数,实现更丰富的序列感知,在序列长度上有线性可扩展性且在语言建模中表现出色。 (详情可见——NeurlPS 2024 | MILA | 揭开视觉领域中 Mamba 的神秘面纱:基于线性注意力视角的分析)
方法
视觉表征的局部扫描
将空间令牌扁平化的传统策略破坏了局部二维依赖关系的完整性,从而降低了模型有效识别空间关系的能力。(Vim [60] 使用的扁平化方法破坏了这些局部依赖关系,显著增加了垂直相邻令牌之间的距离,阻碍了模型捕捉局部细节的能力。虽然 VMamba [32] 尝试通过在水平和垂直两个方向扫描图像来解决这个问题,但在单次扫描中仍然无法全面处理空间区域。)

为了克服这一限制,我们提出了一种新颖的图像局部扫描方法。 通过将图像划分为多个不同的局部窗口,我们的方法确保相关局部令牌的排列更紧密,增强了局部依赖关系的捕捉。
我们通过整合四个方向的选择性扫描机制来构建基础块:原始方向(a)和(c),以及它们的翻转版本(从尾到头扫描)(Vim 和 VMamba 都采用了翻转方向,以更好地建模非因果图像令牌)。

图 3 所示,我们的块通过四个不同的选择性扫描分支处理每个输入图像特征。这些分支独立捕捉相关信息,随后合并为一个统一的特征输出。为了增强不同特征的整合并消除无关信息,我们在合并前引入了一个空间和通道注意力模块。如图 3(b)所示,该模块自适应地对每个分支特征内的通道和令牌进行加权,包含两个关键组件:通道注意力分支和空间注意力分支。
- 通道注意力分支通过在空间维度上对输入特征进行平均来聚合全局表征,随后应用线性变换来确定通道权重。
- 相反,空间注意力机制通过将每个令牌的特征与全局表征相结合来评估令牌级别的重要性,实现精细化的、基于重要性加权的特征提取。(更多扫描策略:CVPR | 2025 | Visual Mamba 综述(更新中))
自适应扫描的搜索
结构化状态空间模型(SSM)在捕捉图像表征方面的效能因扫描方向而异。要实现最佳性能,需要在多个方向上进行多次扫描,类似于我们前面讨论的 4 分支局部选择性扫描块。然而,这种方法会显著增加计算需求。
搜索空间
为了定制每个层的扫描过程,我们引入了一组包含 8 个候选扫描方向的集合。这些方向包括水平和垂直扫描(包括标准和翻转版本),以及窗口大小为 2 和 7 的局部扫描(也包括标准和翻转版本)。为了与现有模型保持一致的计算预算,我们为每个层从这 8 个方向中选择 4 个。这种方法产生了一个庞大的搜索空间(C84)K(C_{8}^{4})^{K}(C84)K,其中 K 表示块的总数。
基于 DARTS [29] (具体参考原文)的原理,我们的方法对扫描方向应用可微分搜索机制,采用连续松弛来处理分类选择。这种方法将离散选择过程转换为连续域,允许使用 softmax 概率来表示扫描方向的选择:
y(l)=∑s∈Sexp(αs(l))∑s′∈Sexp(αs′(l))SSMs(x(l))(5)y^{(l)}=\sum_{s \in \mathcal{S}} \frac{\exp \left(\alpha_{s}^{(l)}\right)}{\sum_{s' \in \mathcal{S}} \exp \left(\alpha_{s'}^{(l)}\right)} \text{SSM}_{s}\left(x^{(l)}\right) \tag{5}y(l)=s∈S∑∑s′∈Sexp(αs′(l))exp(αs(l))SSMs(x(l))(5)
其中α(l)\alpha^{(l)}α(l)表示每个层 lll 的一组可学习参数,反映所有潜在扫描方向上的 softmax 概率。
我们将整个搜索空间构建为一个超网络,按照标准训练协议同时优化网络参数和架构变量 α\alphaα 。训练完成后,通过选择具有最高 softmax 概率的四个方向来得出最优方向选项。我们在图 4 中可视化了模型的搜索方向。

架构变体
为了全面评估我们方法的有效性,我们基于平原结构 [60] 和分层结构 [32] 引入了架构变体,分别命名为 LocalVim 和 LocalVMamba。这些架构的配置详见表 1。

表1:架构变体。我们遵循Vim和VMamba的原始结构设计,其中Vim采用平原结构,其补丁嵌入的步长为16;而VMamba构建了分层结构,其状态空间模型(SSM)阶段的步长分别为4、8、16和32。
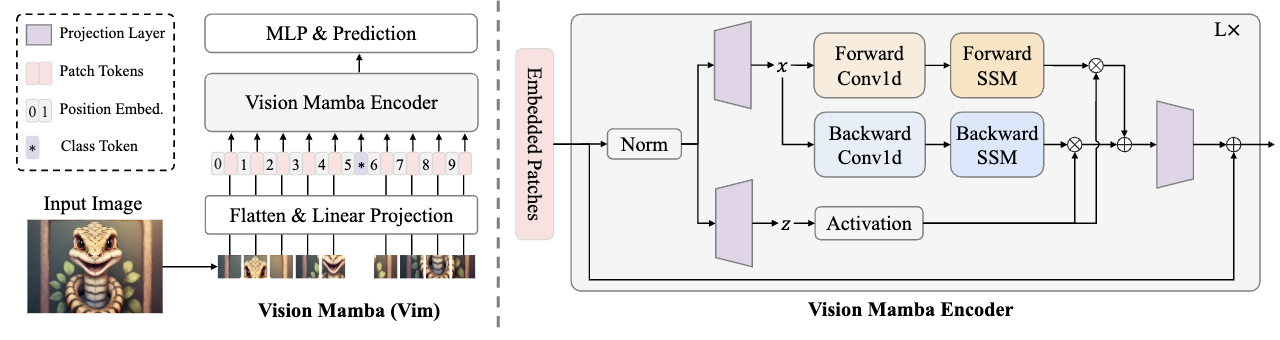
具体来说,在 LocalVim 中,标准 SSM 块(上图)被我们的 LocalVim 块取代,如图 3(下图) 所示。

考虑到原始 Vim 块包含两个扫描方向(水平和翻转水平),而我们的 LocalVim 引入了四个扫描方向,因此计算开销会增加。为了保持相似的计算预算,我们将 Vim 块的数量从 24 个调整为 20 个。对于本身具有四个扫描方向(与我们的模型相似)的 LocalVMamba,我们直接替换块而不改变结构配置。
实验
ImageNet 分类

表 2:不同骨干网络在 ImageNet-1K 分类任务上的对比。∗:未进行扫描方向搜索的我们的模型。
消融实验
- 局部扫描的效果:我们评估了局部扫描技术的影响,实验详情见表 5。用我们的局部扫描替换 Vim-T 的传统水平扫描,比基准提高了 1% 的性能。在 LocalVim-T∗中,在受限 FLOP 预算下组合扫描方向,准确率又提高了 1.1%。这些结果强调了不同窗口大小的扫描(将水平扫描视为窗口大小为 14×14 的局部扫描)对图像识别的不同影响,而这些扫描的融合进一步提高了性能。

- SCAttn 的效果:在表 5 中,将 SCAttn 整合到最终的 LocalVim 块中,准确率又提高了 0.6%,验证了策略性组合不同扫描方向的有效性。这突出了 SCAttn 通过自适应融合扫描方向来提高性能的作用。
- 扫描方向搜索的效果:我们的实证评估(如表 2 所示)证实,在最终的 LocalVim 模型中,扫描方向搜索策略带来了显著收益。这些模型相比仅融合水平扫描、2×2 局部扫描及其镜像版本的模型有明显改进。例如,LocalVim-T 比 LocalVim-T∗高出 0.4%。这种性能提升可归因于在每个层选择扫描组合的方法,提供了多种优化模型效能的选项。