【C++篇】哈希扩展:位图和布隆过滤器+哈希切割
文章目录
- 位图
- 面试题
- 位图解决
- 模拟实现位图
- 1. set
- 2. reset
- 3. test
- 海量数据面试题(位图应用)
- 布隆过滤器
- 布隆过滤器实现
- 哈希切割
位图
所谓位图,就是用内存的每个比特位来存放某种状态, 适用于海量的整数数据,通常是用
来判断某个数据存不存在。
我们库中是有这个容器的:bitset文档介绍
使用需包头文件:include<bitset>
常用接口:
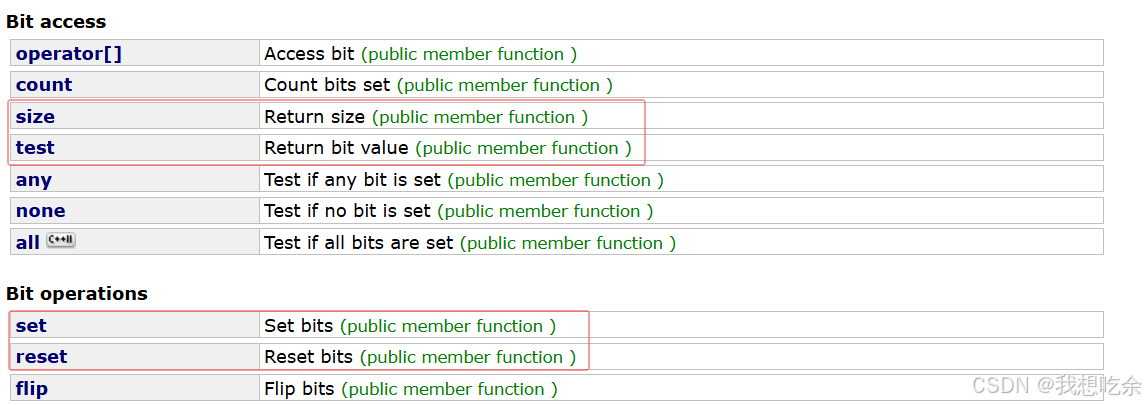
| 接口 | 功能 |
|---|---|
| size | 返回容器大小(单位:比特) |
| test | 返回给定数据对应比特位的状态(为1返回true,为0返回false) |
| set | 将给定数据映射的的比特位设为1 |
| reset | 将给定数据映射的的比特位设为0 |
面试题
面试题:
给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在
这40亿个数中。【腾讯】
常规查找方法可以吗?
比如:
- 用set解决?
- 排序+二分查找?
答案是不行!
我们来算算如果用常规的整数去处理,需要多少空间?
40亿个整数大概占160亿比特位,也就是16个G左右,非常的夸张。
位图解决
数据是否在给定的整形数据中,结果是在或者不在,刚好是两种状态,那么可以使用一个二进制比特位来代表数据是否存在的信息,如果二进制比特位为1,代表存在,为0则代表不存在。
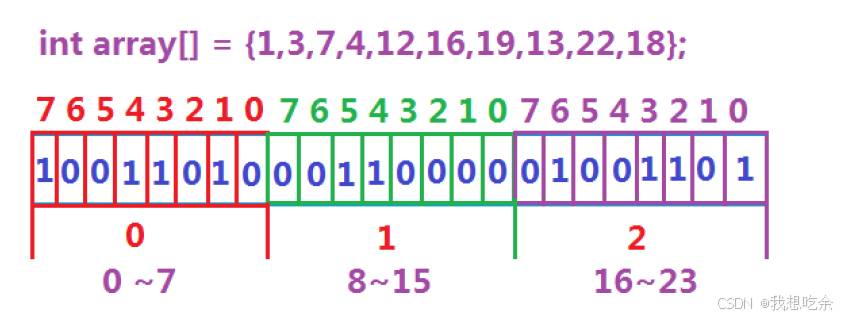
将数据集
{1, 3, 7,4,12, 16, 19, 13, 22, 18}映射到位图(本质上是一个vector<char>的一个对象)中:
最后判断一个数在不在,看其映射的byte位的值即可。
模拟实现位图
对于比特位数据的操作,无非就是0和1直接修改或判断。因此,位图的实现的核心思想是位运算。
本文我们用vector<int>,作为载体,实现位图:

template<size_t N>
class Bitset
{
public:Bitset(){_a.resize(N / 32 + 1);//开好空间,默认初始空间位32位}//…………
private:vector<int> _a;
};
1. set
具体逻辑:
- 查找该比特位在哪个整数中
i = x%32 - 查找该比特位在整数的第几位
j = x/32 - 将该整数与对应比特位为1且其余为0的整数按位或
_a[i] |= 1<<j

void set(size_t x){int i = x / 32;int j = x % 32;_a[i] |= (1 << j);}
2. reset
具体逻辑:
- 查找该比特位在哪个整数中
i = x%32 - 查找该比特位在整数的第几位
j = x/32 - 将该整数与对应比特位为0且其余为1的整数按位与
_a[i] &= (~(1<<j))

void reset(size_t x)
{int i = x / 32;int j = x % 32;_a[i] &= (~(1 << j));
}
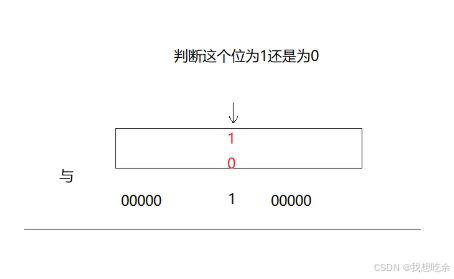
3. test
- 查找该比特位在哪个整数中
i = x%32 - 查找该比特位在整数的第几位
j = x/32 - 返回将该整数与对应比特位为1且其余为0的整数按位与的结果
return _a[i] & 1<<j
bool test(size_t x)
{int i = x / 32;int j = x % 32;//非零则为真return _a[i] & (1 << j);
}
海量数据面试题(位图应用)
位图的功能:
- 快速查找某个数据是否在一个集合中
- 排序 + 去重
- 求两个集合的交集、并集等
- 操作系统中磁盘块标记
- 给定100亿个整数,设计算法找到只出现一次的整数?
具体逻辑:
用两个比特位:遍历标记,每出现一次就+1,当为10(3)时,就无需+1了。最后遍历找01(1)即可。
用双位图实现:
void Test2()
{int a[] = { 1,2,3,3,4,4,4,4,4,2,3,6,3,1,5,5,8,9 };Bitset<10> bs1;Bitset<10> bs2;//遍历标记,每出现一次就+1,当为10(3)时,就无需+1了。最后遍历找01(1)即可for (auto e : a){//00->01if (!bs1.test(e) && !bs2.test(e)){bs2.set(e);}//01->10else if (!bs1.test(e) && bs2.test(e)){bs1.set(e);bs2.reset(e);}}//遍历找01for (auto e : a){if (!bs1.test(e) && bs2.test(e)){cout << e << " ";}}cout << endl;}
- 给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
具体逻辑:
应用位图功能之一:去重
双位图解决问题:
1. 将两文件的数据分别映射到两个位图中
2. 若两位图对应的byte皆为1,则该对应的数是交集的
void Test3()
{int a1[] = { 1,2,3,3,4,4,4,4,4,2,3,6,3,1,5,5,8,9 };int a2[] = { 8,4,8,4,1,1,1,1 };Bitset<10> bs1;Bitset<10> bs2;// 去重for (auto e : a1){bs1.set(e);}// 去重for (auto e : a2){bs2.set(e);}for (int i = 0; i < 10; i++){if (bs1.test(i) && bs2.test(i)){cout << i << " ";}}cout << endl;}布隆过滤器
位图虽然强大,但却只能用于整数数据,那对于字符串数据呢?
其实,我们可以用一些字符串哈希函数将字符串其转换为整数数据,然后再用位图解决问题。
字符串哈希算法
但还是存在很大的问题:
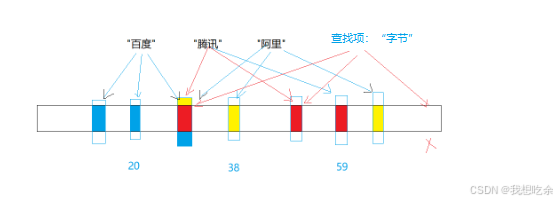
假设经过字符串哈希算法计算后,“百度”对应20,“腾讯”对应59,“阿里”对应38,映射结果如下:
问查找“字节”(假设对应59)的结果如何?
查找结果:“字节”是存在的,因为腾讯也是59。
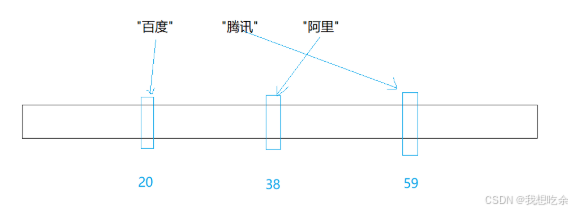
但实际上,“字节”是不存在的。
由此我们可以得出结论:
- 判断数据存在是不准确的:可能因为冲突而导致误判。
- 判断数据不存在是准确的
那能否降低误判率呢?
布隆过滤器正是解决此问题的!
布隆过滤器原理:它是用多个字符串哈希算法,将一个数据映射到位图结构中。
比如,我们用三个字符串哈希算法,将一个数据对应3个整数,查找时,需要对应的3个整数在位图中映射都为1,才能判定该数据存在。
【注意】
- 布隆过滤器只是降低误判的概率(可以做到大幅度降低),但误判是无可避免的。
- 一般情况下不能从布隆过滤器中删除元素,因为可能会影响其他数据。
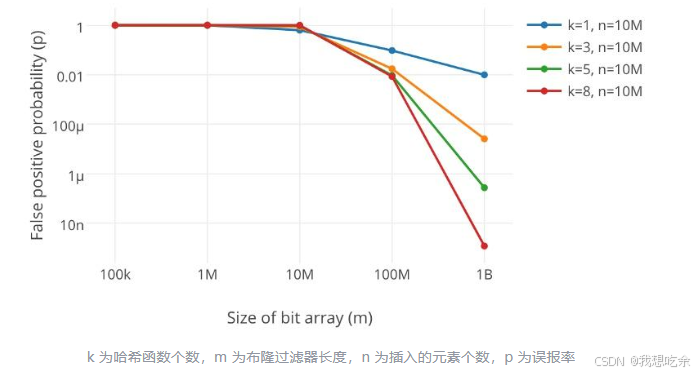
- 误判率与哈希函数个数和所给空间大小有关
参考文献:详解布隆过滤器的原理,使用场景和注意事项
布隆过滤器实现
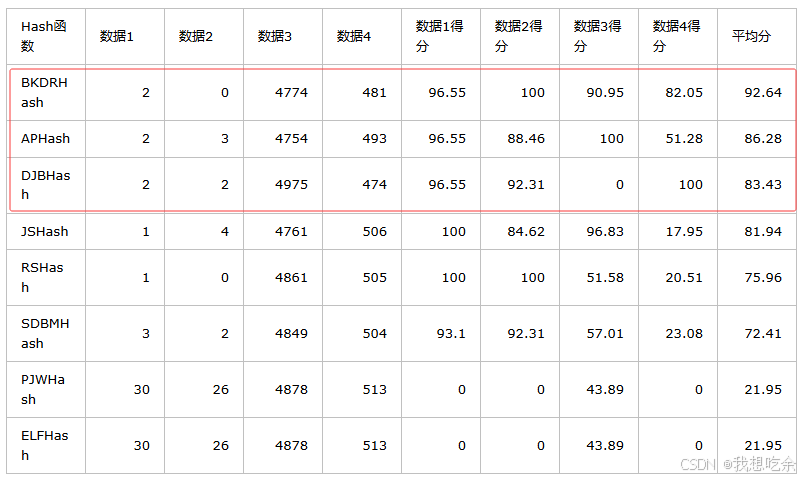
我选用了三个评分最高的哈希函数来实现hhh
实现逻辑非常简单,对bitset进行封装即可
将哈希函数写为仿函数。
set:
用3个哈希函数来计算数据对应的整数,然后用set到位图中即可
test:
用3个哈希函数来计算数据对应的整数,然后判断各个整数在位图中是否为1
//BKDR哈希算法
struct BKDRHash
{size_t operator()(const string& str){size_t hash = 0;for (auto ch : str){hash = hash * 131 + ch;}return hash;}
};//AP哈希算法
struct APHash
{size_t operator()(const string& str){size_t hash = 0;for (size_t i = 0; i < str.size(); i++){size_t ch = str[i];if ((i & 1) == 0){hash ^= ((hash << 7) ^ ch ^ (hash >> 3));}else{hash ^= (~((hash << 11) ^ ch ^ (hash >> 5)));}}return hash;}
};//DJB哈希算法
struct DJBHash
{size_t operator()(const string& str){size_t hash = 5381;for (auto ch : str){hash += (hash << 5) + ch;}return hash;}
};template<size_t N, class K = string, class Hash1 = BKDRHash, class Hash2 = APHash, class Hash3 = DJBHash>
class BloomFilter
{
public:void set(const K& key){size_t hash1 = Hash1()(key) % N;_bt.set(hash1);size_t hash2 = Hash2()(key) % N;_bt.set(hash2);size_t hash3 = Hash3()(key) % N;_bt.set(hash3);}bool test(const K& key){size_t hash1 = Hash1()(key) % N;if (!_bt.test(hash1))return false;size_t hash2 = Hash2()(key) % N;if (!_bt.test(hash2))return false;size_t hash3 = Hash3()(key) % N;if (!_bt.test(hash3))return false;return true;}
private:bitset<N> _bt;
};
哈希切割
面试题1:
给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法。
此处近似算法可以用布隆过滤器解决,但精确算法得用哈希切割。
何为哈希切割?
用哈希函数将一组数据进行分类,就是哈希切割。
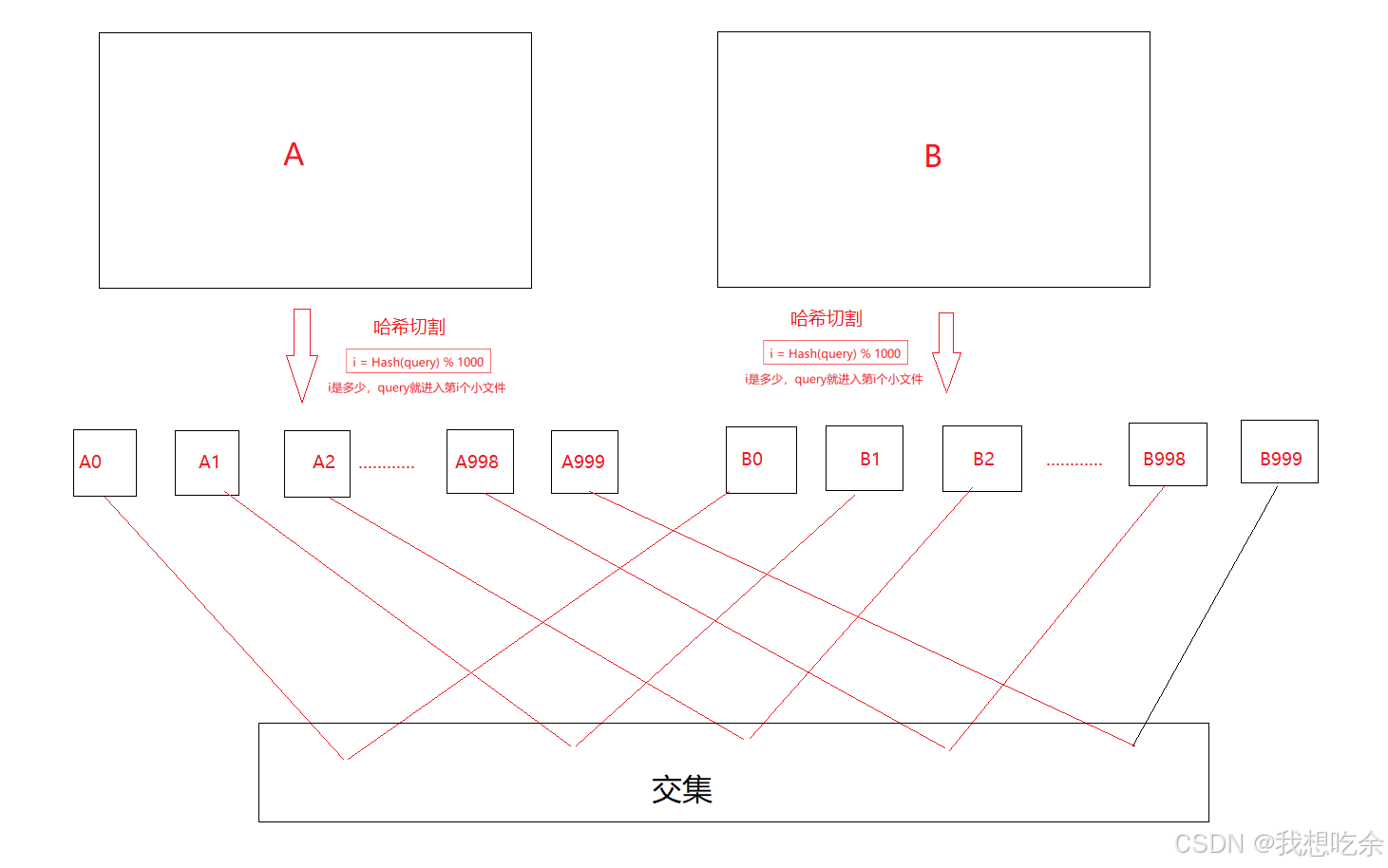
本题我们可以分别将两个海量数据文件分割为1000份:
假设两文件分别为A和B
A被分为(A0,A1,A2,……,A998,A999)
B被分为(B0,B1,B2,……,B998,B999)
i = Hash(query) % 1000
i是多少,query就进入第i个小文件
最后依次找Ai和Bi的交集即可。
💡:切割后的每个小文件就像哈希表的桶
图解:
找交集方法:将Ai读出来放到一个set,然后再用这个set去查找Bi的query在不在,在就是交集。
如果是平均切割为1000份,每份的大小约为300MB,但是哈希切分并非平均切分,在冲突较为极端的情况下,会导致其中某个Ai文件太大,超过1G,那就不符合题意了。
那怎么办呢?
哈希冲突太多有两个情况:
- 大半部分都是相同的query
- 大多数的query都是冲突
解决方案:
先把Ai的query读到一个set,
- 如果set的insert报错抛异常(bad_alloc),说明是大多数的query都是冲突,在换一个哈希函数,再次进行哈希切割。
- 如果Ai能够全部被读取insert到set中,那就锁门ai中有大量重复的query。
面试题2
给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址?
与上题同样的方式进行哈希切割,相同的IP地址一定在一个小文件中,用map去分别统计每个小文件中IP出现的次数即可。