涉及实验(随机分组)的一些概念
本推文仅针对实验、准实验、自然实验、准自然实验四个概念进行区分。这些方法主要用于探索因果关系,区别主要在于是否随机分组、干预是否人为控制等维度。
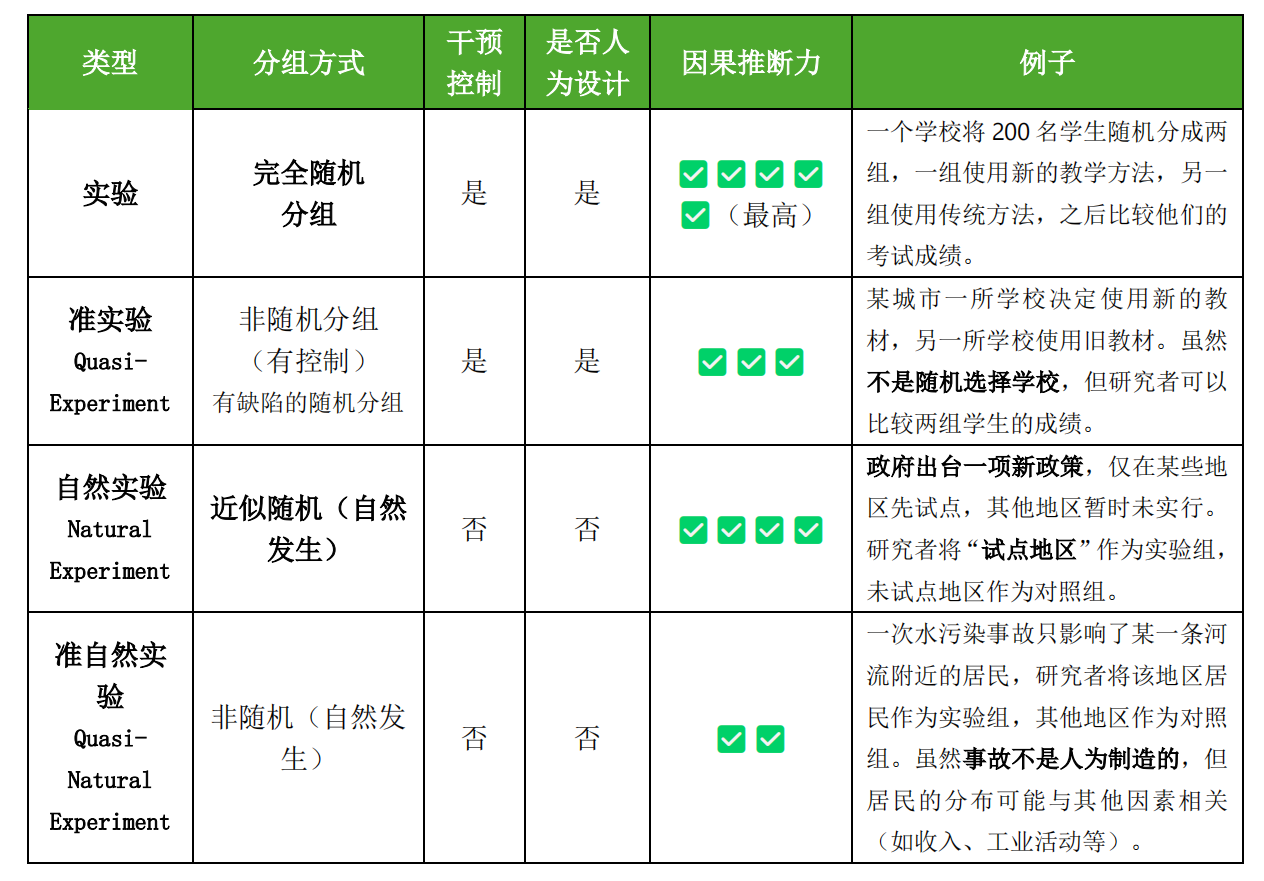
一、实验(Randomized Controlled Trial, RCT,随机分组实验)
✅ 定义:
一种标准的因果推断方法,研究者完全控制实验过程,尤其是对样本的随机分组。
✅ 特点:
- 随机分组:研究对象被随机分配到实验组和对照组。
- 干预人为可控:研究者施加某种可控干预(如政策、药物等)。
- 控制混杂变量能力强,因果推断的黄金标准。
二、准实验(Quasi-Experiment,非随机分组)
✅ 定义:
不完全随机分组的实验设计。研究者控制了部分实验过程(如施加干预),但无法完全做到随机分组。
✅ 特点:
- 没有真正的随机分组,但有实验组与对照组。
- 研究者可以控制干预。
- 有可能存在选择偏误(比如实验组和对照组在起点上就不同)。
- 需要依赖统计方法控制混杂因素(如回归、倾向得分匹配等)。
三、自然实验(Natural Experiment)
✅ 定义:
自然界或社会中“自发”发生的事件作为实验干预,研究者并不控制干预或分组过程。
✅ 特点:
- 干预不是研究者设计的,而是“自然”发生的。
- 实验组和对照组的分组近似随机(通常是由于政策变更、地理边界、突发事件等造成的“类随机性”)。
- 可以用来做因果推断,但需要强有力的识别策略。
四、准自然实验(Quasi-Natural Experiment)
✅ 定义:
看起来像自然实验,但分组不是完全随机或随机性存在缺陷。干预仍然是“自然”发生的(而非研究者控制)。
✅ 特点:
- 干预非研究者控制。
- 分组“接近随机”但存在问题,比如人为因素参与其中,或者制度安排造成样本选择偏误。
- 研究者依然需要额外的识别策略来保证因果解释的合理性。
五、联系
- 四者都用于因果推断,是实验设计的重要组成。
- 从“控制力”来看:实验 > 准实验 > 自然实验 > 准自然实验
- 准实验、自然实验和准自然实验常在无法进行RCT的现实情境中使用。
- 研究者常用统计技术(回归不连续设计、双重差分、工具变量等)增强自然/准自然实验的识别效力。