企业级日志分析系统ELK
1.什么是 Elastic Stack
2.Elasticsearch 索引是什么?
Elasticsearch 索引指相互关联的文档集合。Elasticsearch 会以 JSON 文档的形式存储数据。每个文档都会在一组键(字段或属性的名称)和它们对应的值(字符串、数字、布尔值、日期、数值组、地理位置或其他类型的数据)之间建立联系。
Elasticsearch 使用的是一种名为倒排索引的数据结构,这一结构的设计可以允许十分快速地进行全文本搜索。倒排索引会列出在所有文档中出现的每个特有词汇,并且可以找到包含每个词汇的全部文档。
在索引过程中,Elasticsearch 会存储文档并构建倒排索引,这样用户便可以近实时地对文档数据进行搜索。索引过程是在索引 API 中启动的,通过此 API 您既可向特定索引中添加 JSON 文档,也可更改特定索引中的 JSON 文档。
3.Logstash 的用途是什么?
Logstash 是 Elastic Stack 的核心产品之一,可用来对数据进行聚合和处理,并将数据发送到 Elasticsearch。Logstash 是一个开源的服务器端数据处理管道,允许您在将数据索引到Elasticsearch 之前同时从多个来源采集数据,并对数据进行充实和转换。
4.Kinbana的用途是什么?
是适用于 Elasticsearch 的数据可视化和管理工具,可提供实时直方图、线形图、饼状图和地图 ;包含 Canvas(允许用户基于自身数据创建定制动态信息图表 )、Elastic Maps(对地理空间数据可视化 )等高级应用程序 。
总结如下:
5.Elasticsearch集群安装
cluster.name: my-application
node.name: node-1 #不唯一。在其他主机上需要更改不一样的名字 其他的都不变
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
discovery.seed_hosts: ["10.0.0.101", "10.0.0.102", "10.0.0.103"]
cluster.initial_master_nodes: ["10.0.0.101", "10.0.0.102", "10.0.0.103"]
xpack.security.enabled: false
xpack.security.enrollment.enabled: true
xpack.security.http.ssl:enabled: truekeystore.path: certs/http.p12
xpack.security.transport.ssl:enabled: trueverification_mode: certificatekeystore.path: certs/transport.p12truststore.path: certs/transport.p12
http.host: 0.0.0.0
curl 'http://127.0.0.1:9200/_cat/health' #查看es集群状态
curl -XPUT '127.0.0.1:9200/index2?pretty' #格式化输出
curl -XPUT '127.0.0.1:9200/index1' \
-H 'Content-Type: application/json' \
-d '{"settings": {"index": {"number_of_shards": 3,"number_of_replicas": 2}}
}'
curl -XPUT '127.0.0.1:9200/index1/_settings' \
-H 'Content-Type: application/json' \
-d '{"settings": {"number_of_replicas": 1}
}'6.Elasticsearch 插件
7.ES 文档路由
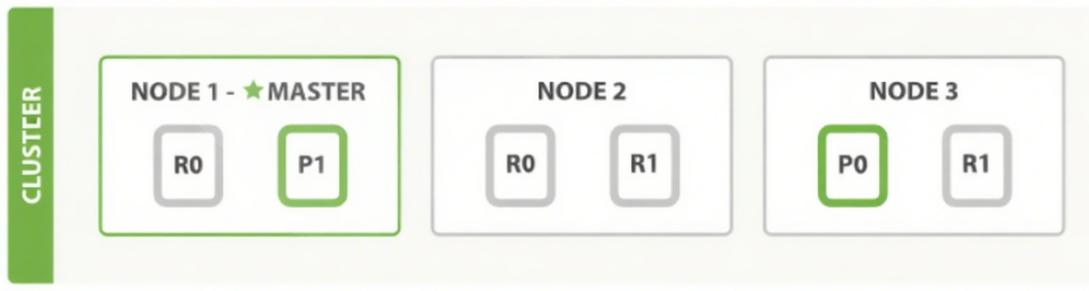
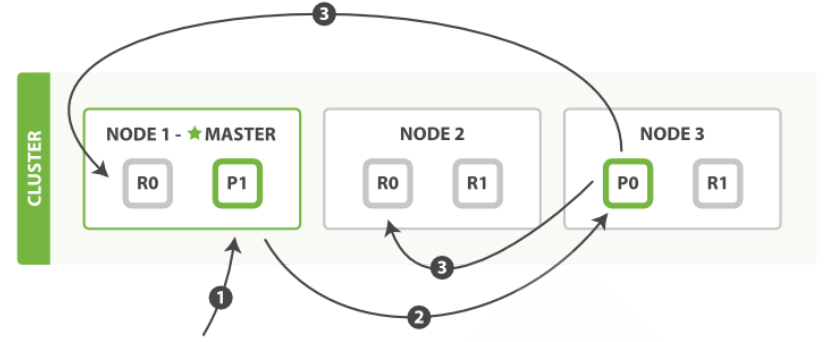
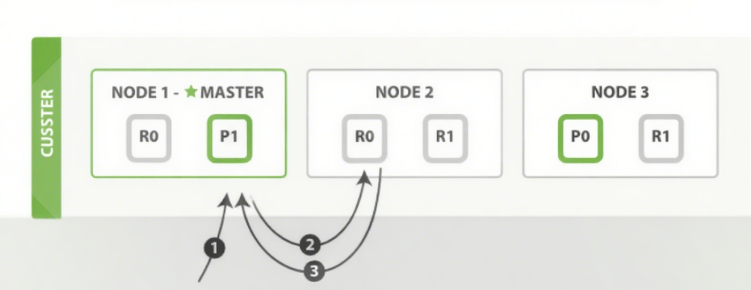
8.集群的扩缩容
9.Elasticsearch 数据冷热分离
- 热数据:刚产生的数据(如最近 1 天的日志),需要高频写入、实时查询、快速响应,因此对存储的IOPS(每秒输入输出次数)、延迟(读写响应时间)和计算能力(CPU、内存)要求极高。
- 冷数据:历史归档数据(如超过 30 天的日志),仅偶尔查询、几乎不写入,对存储性能要求低,但需要大容量、低成本的存储介质。
通过配置节点属性(node.attr),将集群节点划分为不同角色,明确数据存储的目标节点:
- 热节点:配置
node.attr.box_type: hot,通常搭载 SSD 存储(提供高 IOPS、低延迟),分配更多 CPU 和内存资源,优先处理写入和高频查询。 - 冷节点:配置
node.attr.box_type: cold,通常使用 HDD 存储(大容量、低成本),CPU 和内存配置较低,仅处理低频查询。
10.Beats 收集数据
关于:Beats 是一个免费且开放的平台,集合了多种单一用途数据采集器。它们从成百上千或成千上万台机器和系统向 Logstash 或 Elasticsearch 发送数据。 虽然利用 logstash 就可以收集日志,功能强大,但由于 Logstash 是基于Java实现,需要在采集日志的主机上安装JAVA环境。logstash运行时最少也会需要额外的500M的以上的内存,会消耗比较多的内存和磁盘空间,
11.Filebeat,Elasticsearch,Kibana 三者之间的关系
| 组件 | 核心角色 | 功能定位 | 在流程中的位置 |
|---|---|---|---|
| Filebeat | 轻量级数据采集器(日志为主) | 部署在产生日志的服务器 / 设备上,实时收集日志文件(如系统日志、应用日志),并转发到 Elasticsearch 或 Logstash。 | 数据入口(前端采集) |
| Elasticsearch | 分布式搜索引擎 / 数据库 | 接收并存储采集到的数据(日志、指标等),提供高效的全文检索、聚合分析能力(如按时间统计错误日志数量)。 | 数据存储与计算中心 |
| Kibana | 数据可视化与管理平台 | 连接 Elasticsearch,通过界面化工具(如仪表盘、图表、搜索框)展示数据,支持日志查询、趋势分析、告警配置等。 | 数据出口(用户交互与可视化) |
12.filebeat的一些相关配置和设置
filebeat.inputs:
- type: stdinenabled: truetags: ["stdin-tags", "myapp"] # 添加新字段名tags,可以用于判断不同类型的输入,实现不同的输出fields:status_code: "200" # 添加新字段名fields.status_code,可以用于判断不同类型的输入,实现不同的输出author: "becareful"output.console:pretty: trueenable: true
filebeat.inputs:
- type: stdinjson.keys_under_root: true # 解析JSON并将键提升到根级别output.console:pretty: truenihao,shuaige

13.案例: 从标准输入读取再输出至 Json 格式的文件
filebeat.inputs:
- type: stdinenabled: truejson.keys_under_root: true # 默认False会将json数据存储至message,true则会将数据以独立字段存储,并且删除message字段,如果是文本还是放在message字段中output.file:path: "/tmp"filename: "filebeat.log"filebeat -e -c /etc/filebeat/stdout_file.yml #执行操作
{"name" : "xiaoming", "age" : "18", "phone" : "0123456789"} #输入此项内容
apt -y install jq #Json格式整理
cat /tmp/filebeat.log-20250729.ndjson|jq #查看生成的Json数据 8.X版本
14.案例: 从文件读取再输出至标准输出
注意:当前filebeat-9.X 文件读出有bug
https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-input-log.html
filebeat.inputs:
- type: filestream # 此指令配置json.keys_under_root: true 也不支持Json格式解析# type: log # 旧版,将来废弃enabled: truepaths:# - /var/log/syslog- /var/log/test.logoutput.console:pretty: trueenable: true15.案例: 利用 Filebeat 收集系统日志到 ELasticsearch
#8.X新版
.ds-filebeat-<版本>-<时间>-<ID>
#旧版
filebeat-<版本>-<时间>-<ID>方法1:
filebeat.inputs:
- type: logjson.keys_under_root: trueenabled: true # 开启日志paths:- /var/log/syslog # 指定收集的日志文件# -------------------------- Elasticsearch output ------------------------------
output.elasticsearch:hosts: ["10.0.0.101:9200", "10.0.0.102:9200", "10.0.0.103:9200"] # 指定ELK集群任意节点的地址和端口,多个地址容错方法2:
#或者修改syslog.conf
[root@elk-web1 ~]#vim /etc/rsyslog.conf
*.* /var/log/system.log
[root@elk-web1 ~]#systemctl restart rsyslog.service
[root@elk-web1 ~]#vim /etc/filebeat/filebeat.yml
/var/log/system.log #指定收集的日志文件 唯一不一样的地方,其他同上
[root@elk-web1 ~]#systemctl enable --now filebeat.service