第五章:进入Redis的Hash核心
redis小知识:
Redis 所有的 key 都是字符串,但 value 的类型存在差异,且一般来说遇到乱码问题的概率更小。Redis 中的字符串直接按二进制数据方式存储,不会做任何编码转换,存啥取啥,不仅能存储整数、普通文本字符串、JSON、xml,还能存储图片、视频、音频等二进制数据。而像 MySQL,若使用默认的拉丁文字符集,插入中文就会失败。需要注意的是,音频视频类二进制数据体积可能较大,Redis 对 string 类型限制了大小最大为 512M,并且 Redis 采用单线程模型,期望进行的操作都能比较快速。
一. redis内部编码
字符串类型的内部编码有 3 种:
• int:8 个字节的长整型。
• embstr:小于等于 39 个字节的字符串。
• raw:大于 39 个字节的字符串。
Redis 会根据当前值的类型和长度动态决定使用哪种内部编码实现。
整型类型示例如下:
127.0.0.1:6379> set key 6379
OK
127.0.0.1:6379> object encoding key
"int"短字符串示例如下:
# 一般⼩于等于 39 个字节的字符串
# 不要记数字,要根据业务场景灵活应对
127.0.0.1:6379> set key "hello"
OK
127.0.0.1:6379> object encoding key
"embstr"长字符串示例如下:
# ⼤于 39 个字节的字符串
# 不要记数字,要根据业务场景灵活应对
127.0.0.1:6379> set key "one string greater than 39 bytes ........"
OK
127.0.0.1:6379> object encoding key
"raw"二,关于redis的经典应用场景
2.1缓存(Cache)功能
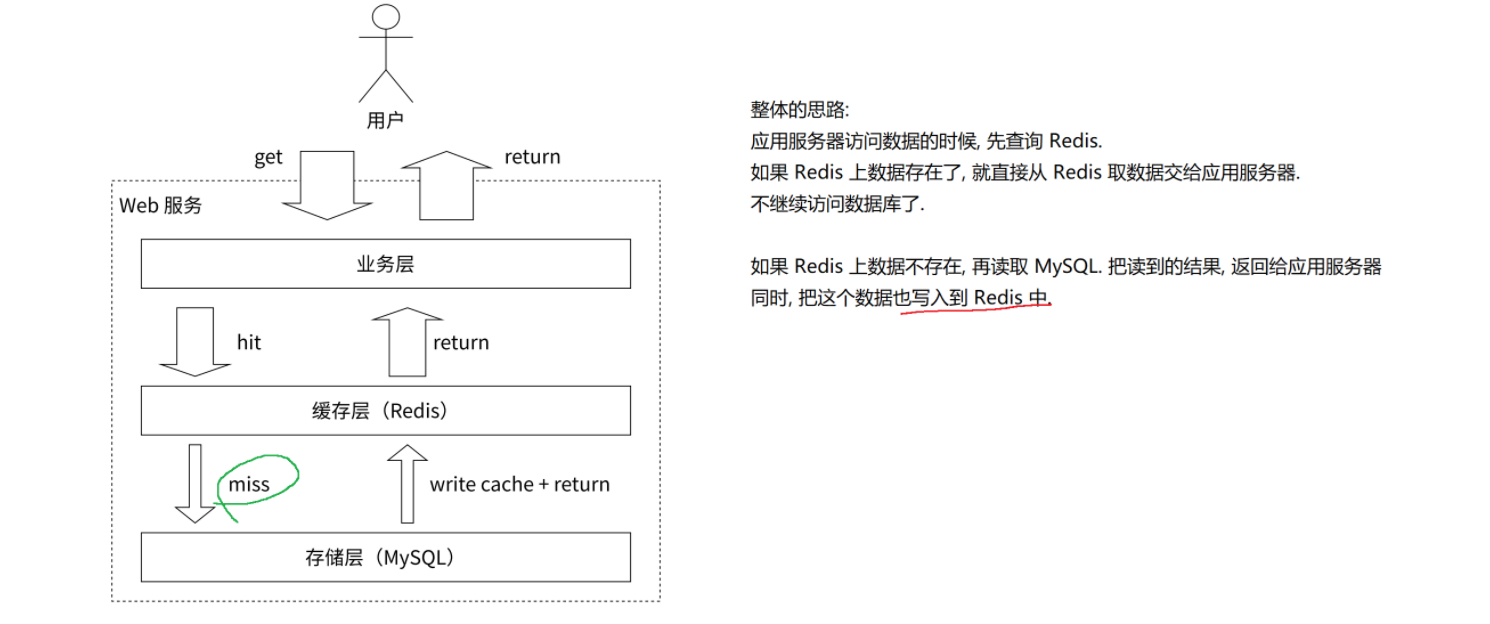
- 整体思路:
- 应用服务器访问数据时,先查询 Redis。
- 如果 Redis 上数据存在,直接从 Redis 取数据交给应用服务器,不再访问数据库。
- 如果 Redis 上数据不存在,读取 MySQL,将读到的结果返回给应用服务器,同时把这个数据写入到 Redis 中。
- Redis 缓存特点:
- Redis 这样的缓存,经常用来存储 “热点” 数据,即高频使用的数据。
- 这个定义方式结合业务场景有很多种方式,刚才上述描述的过程相当于把最近使用到的数据作为热点数据(暗含假设:某个数据一旦被用到,很可能在最近这段时间被反复用到)。
- 缓存问题及解决:
- 上述缓存存在明显问题:随着时间推移,会有越来越多的 key 在 redis 上访问不到,从而从 mysql 读取并写入 redis,导致 redis 中的数据越来越多。
- 解决方法:
- 在把数据写给 redis 的同时,给这个 key 设置一个过期时间。
- Redis 在内存不足时,提供了淘汰策略(后面再细说)。
Redis + MySQL 组成的缓存存储架构
举个栗子~
企业收集用户数据主要是为了统计,以此进一步明确用户需求,进而根据需求改进和迭代产品。不过 Redis 并不擅长数据统计,比如在上述 Redis 中统计播放量前 100 的视频就很麻烦,而用 mysql 存储数据一个 sql 就能搞定。以视频网站为例,其从视频存储获取视频数据,执行 Redis 命令(如 incr "video:5253")返回数据,同时将播放量异步同步到统计数据仓库(统计数据仓库可能是 mysql 或 hdfs 等),这里写入统计数据仓库的步骤是异步的,并非来一个播放请求就立即写一个数据。在实际中,开发成熟、稳定的真实计数系统面临诸多挑战,像防作弊、按不同维度计数、避免单点问题、数据持久化到底层数据源等,需要根据实际业务需求场景来应对。
2.1共享会话(Session)
⼀个分布式 Web 服务将用户的 Session 信息(例如用户登录信息)保存在各⾃的服务器中,但这样会造成⼀个问题:出于负载均衡的考虑,分布式服务会将⽤⼾的访问请求均衡到不同的服务器上,并且通常⽆法保证用户每次请求都会被均衡到同⼀台服务器上,这样当用户刷新⼀次访问是可能会发现需要重新登录,这个问题是用户⽆法容忍的。
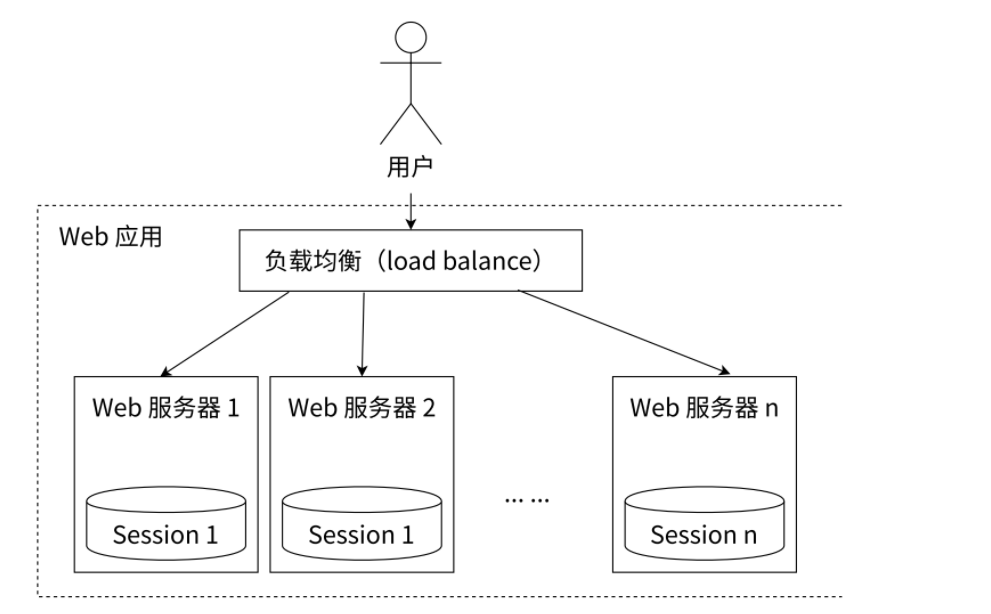
如果每个应用服务器,维护自己的会话数据,此时彼此之间不共享,用户请求访问到不同的服务器上,就可能会出现一些不能正确处理的情况了~~
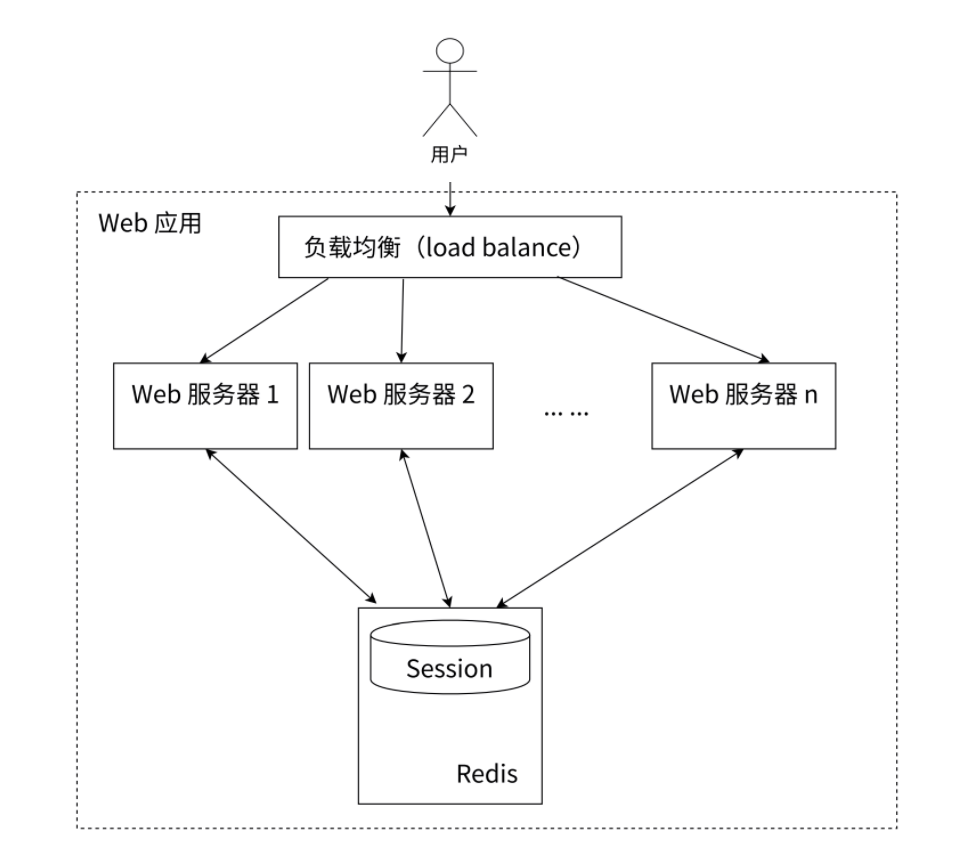
为了解决这个问题,可以使用 Redis 将用户的 Session 信息进⾏集中管理,如上所示,在这种模式下,只要保证 Redis 是高可用和可扩展性的,⽆论用户被均衡到哪台 Web 服务器上,都集中从Redis 中查询、更新 Session 信息。
2.2手机验证码
此功能可以⽤以下伪代码说明基本实现思路
String 发送验证码(phoneNumber) {key = "shortMsg:limit:" + phoneNumber;// 设置过期时间为 1 分钟(60 秒)// 使⽤ NX,只在不存在 key 时才能设置成功bool r = Redis 执⾏命令:set key 1 ex 60 nxif (r == false) {// 说明之前设置过该⼿机的验证码了long c = Redis 执⾏命令:incr keyif (c > 5) {// 说明超过了⼀分钟 5 次的限制了// 限制发送return null;}}// 说明要么之前没有设置过⼿机的验证码;要么次数没有超过 5 次String validationCode = ⽣成随机的 6 位数的验证码();validationKey = "validation:" + phoneNumber;// 验证码 5 分钟(300 秒)内有效Redis 执⾏命令:set validationKey validationCode ex 300;// 返回验证码,随后通过⼿机短信发送给⽤⼾return validationCode ;
}
// 验证⽤⼾输⼊的验证码是否正确
bool 验证验证码(phoneNumber, validationCode) {validationKey = "validation:" + phoneNumber;String value = Redis 执⾏命令:get validationKey;if (value == null) {// 说明没有这个⼿机的验证码记录,验证失败return false;}if (value == validationCode) {return true;} else {return false;}
}2.2计数(Counter)功能
许多应用都会使用Redis 作为计数的基础⼯具,它可以实现快速计数、查询缓存的功能,同时数据可以异步处理或者落地到其他数据源。如图 2-11 所⽰,例如视频⽹站的视频播放次数可以使⽤ Redis 来完成:⽤⼾每播放⼀次视频,相应的视频播放数就会⾃增 1。
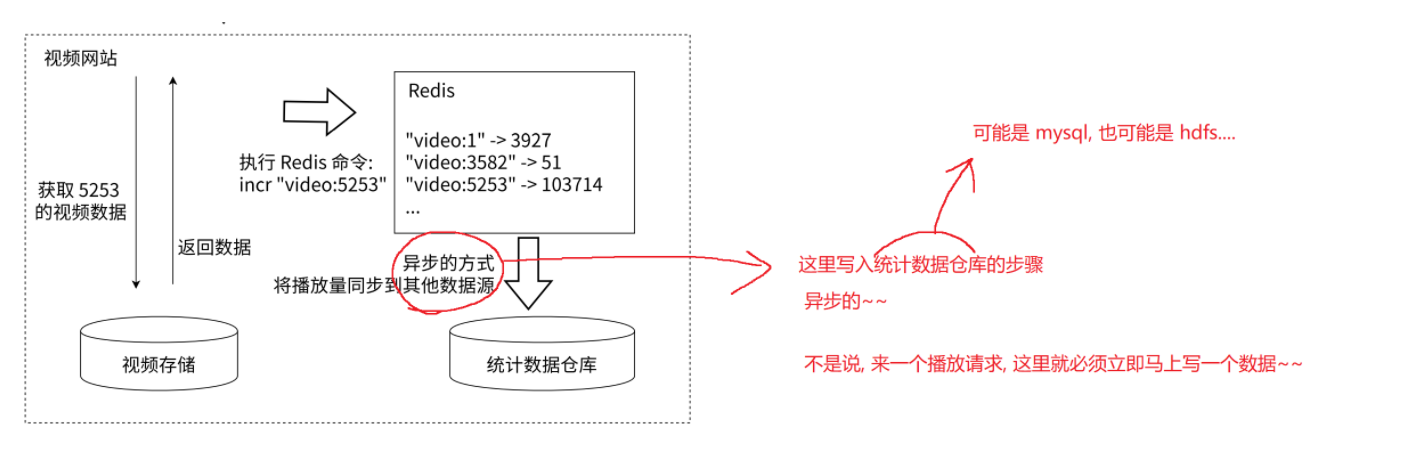
这张图展示了视频网站播放量统计的一个流程。视频网站从视频存储获取视频数据,然后通过执行 Redis 命令(如 incr "video:5253")来记录视频的播放量,Redis 中存储着各个视频的播放量数据。之后,会以异步的方式将播放量同步到统计数据仓库,统计数据仓库可能是 mysql 或者 hdfs 等。这里的写入步骤是异步的,并不是每来一个播放请求就立即写入数据
三.Redis 哈希类型核心命令汇总
Redis 自身的键值对就是通过哈希的方式来组织的。
把 key 这一层组织完成之后,到了 value 这一层,value 的其中一种类型还可以再是哈希。
注意:
哈希类型中的映射关系通常称为 field-value,用于区分 Redis 整体的键值对(key-value),注意这⾥的 value 是指 field 对应的值,不是键(key)对应的值,请注意 value 在不同上下⽂的作用
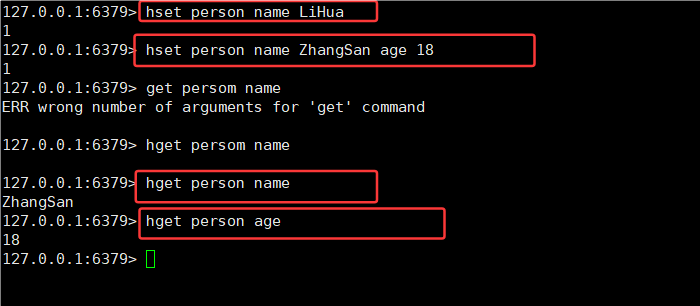
3.1HSET HGET
HSET命令:设置 hash 中指定的字段(field)的值(value) (可以传多组)
HGET命令:获取 hash 中指定字段的值。
返回值是设置成功的键值对(field - value)的个数。
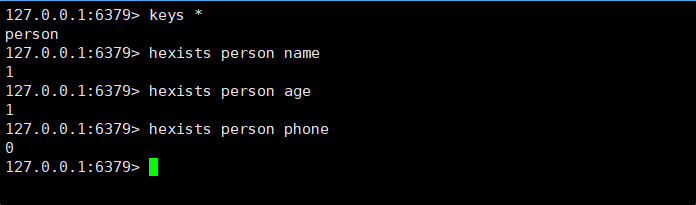
3.2HEXISTS
HEXISTS命令:判断 hash 中是否有指定的字段
HEXISTS key field时间复杂度:O(1)
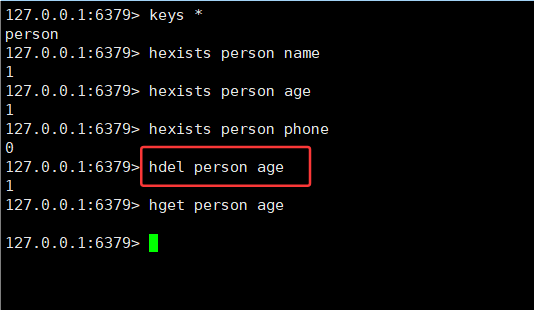
3.3HDEL
删除 hash 中指定的字段。
返回值是本次操作删除的字段个数。
HDEL key field [field ...]注意:
del删除的是 key,hdel删除的是 field。
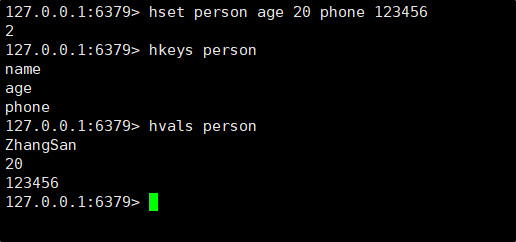
3.4HKEYS 和 HVALS
HKEYS命令:获取 hash 中的所有字段
先根据 key 找到对应的 hash,O (1),然后再遍历 hash,O (N),N 是 hash 的元素个数。
HVALS 命令:获取 hash 中的所有的值
和 hkeys 相对,能够获取到 hash 中的所有 value
3.5HGETALL 和 HMGET
HGETALL命令:获取 hash 中的所有字段以及对应的值
HMGET 命令: ⼀次获取 hash 中多个字段的值
类似于之前的 MGET,可以一次查询多个 field,而 HGET 一次只能查一个 field。
HMGET key field [field ...]时间复杂度:只查询⼀个元素为 O(1), 查询多个元素为 O(N), N 为查询元素个数.
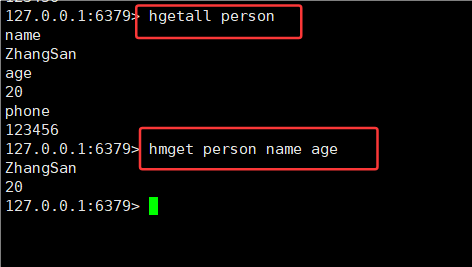
注意,多个 value 的顺序和 field 的顺序是匹配的。
有没有 hmmset,一次设置多个 field 和 value 呢?有,但是,并不需要使用,hset 已经支持一次设置多个 field 和 value 了。一条命令,都能完成所有的遍历操作。
上述 hkeys,hvals,hgetall 都是存在一定风险的,hash 的元素个数太多,执行的耗时会比较长,从而阻塞 redis。
补充:
hscan 遍历 redis 的 hash,但是它属于 “渐进式遍历”,敲一次命令,遍历一小部分,再敲一次,再遍历一小部分,…… 连续执行多次,就可以完成整个的遍历过程了,时间就是可控的。这个哈希表在扩容的时候,也是按照化整为零的方式进行的!
ConcurrentHashMap是线程安全的哈希表。
3.6HLEN
HLEN:获取 hash 中的所有字段的个数 。
类似于 setnx,不存在的时候,才能设置成功,如果存在,则失败。
HLEN key时间复杂度:O(1)

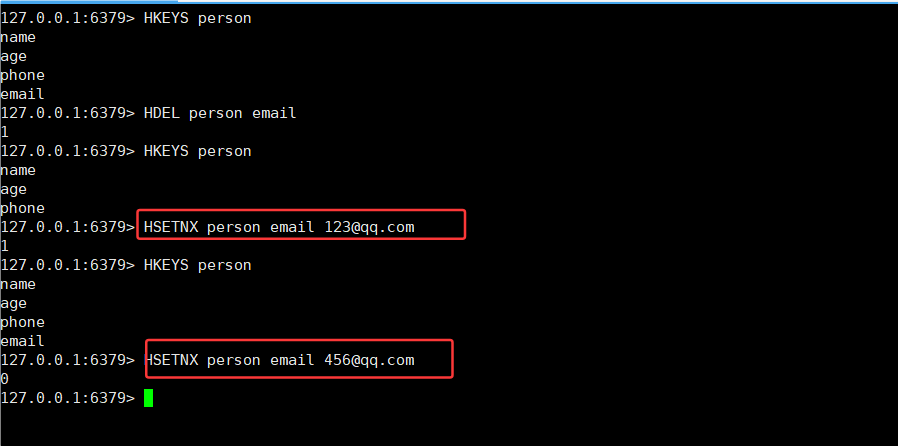
3.7HSETNX
HSETNX命令:在字段不存在的情况下,设置 hash 中的字段和值
类似于 setnx,不存在的时候,才能设置成功,如果存在,则失败
返回值:1 表示设置成功,0 表示失败。
3.8HINCRBY 和 HINCRBYFLOAT
HINCRBY 命令:将 hash 中字段对应的数值添加指定的值
HINCRBY key field increment时间复杂度:O(1)
HINCRBYFLOAT命令:HINCRBY 的浮点数版本
时间复杂度:O(1)
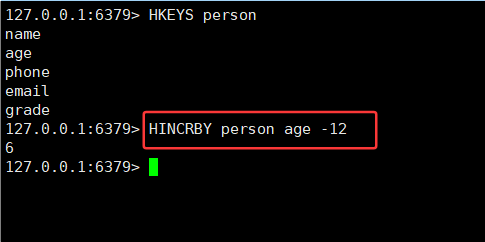
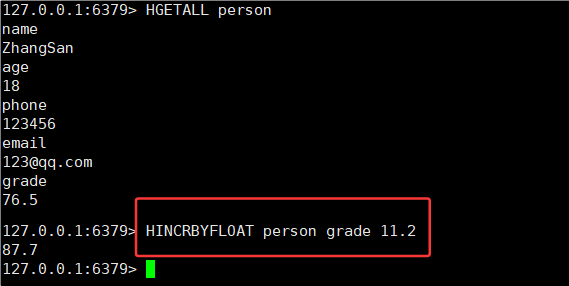
hash 这里的 value,也可以当做数字来处理。
hincrby 就可以加减整数,hincrbyfloat 就可以加减小数。
使用频率不算很高,redis 没有提供类似于 incr decr
总结:
四.hset的内部编码
4.1ziplist与hashtable
- ziplist(压缩列表):当哈希类型元素个数小于 hash-max-ziplist-entries 配置(默认 512 个)同时所有值都小于 hash-max-ziplist-value 配置(默认 64 字节)时,Redis 会使用 ziplist 作为哈希的内部实现,ziplist 使⽤更加紧凑的结构实现多个元素的连续存储,所以在节省内存方面比hashtable 更加优秀。
- hashtable(哈希表):当哈希类型⽆法满⾜ ziplist 的条件时,Redis 会使⽤ hashtable 作为哈希 的内部实现,因为此时 ziplist 的读写效率会下降,而hashtable 的读写时间复杂度为 O(1)。
- 压缩相关
- 常见压缩算法有 rar、zip、gzip、7z 等,压缩本质是对数据重新编码。不同数据有不同特点,结合这些特点精妙设计重新编码后可缩小体积。
- 举例:如字符串 “abbbccddddddeeeee” 可重新编码为 “1a2b3c4d5e”;对于含大量重复字符 “0” 的文件内容,可编码为更简洁形式,像 “abcd0 [100] efgh”。
- ziplist
- ziplist 原理与压缩类似,内部数据结构精心设计,目的是节省内存空间。表示普通哈希表可能会浪费一定空间(哈希表是数组,部分位置可能无元素),但 ziplist 进行读写元素操作时速度较慢,元素个数少影响不明显,个数多则影响较大。
4.2哈希类型存储策略
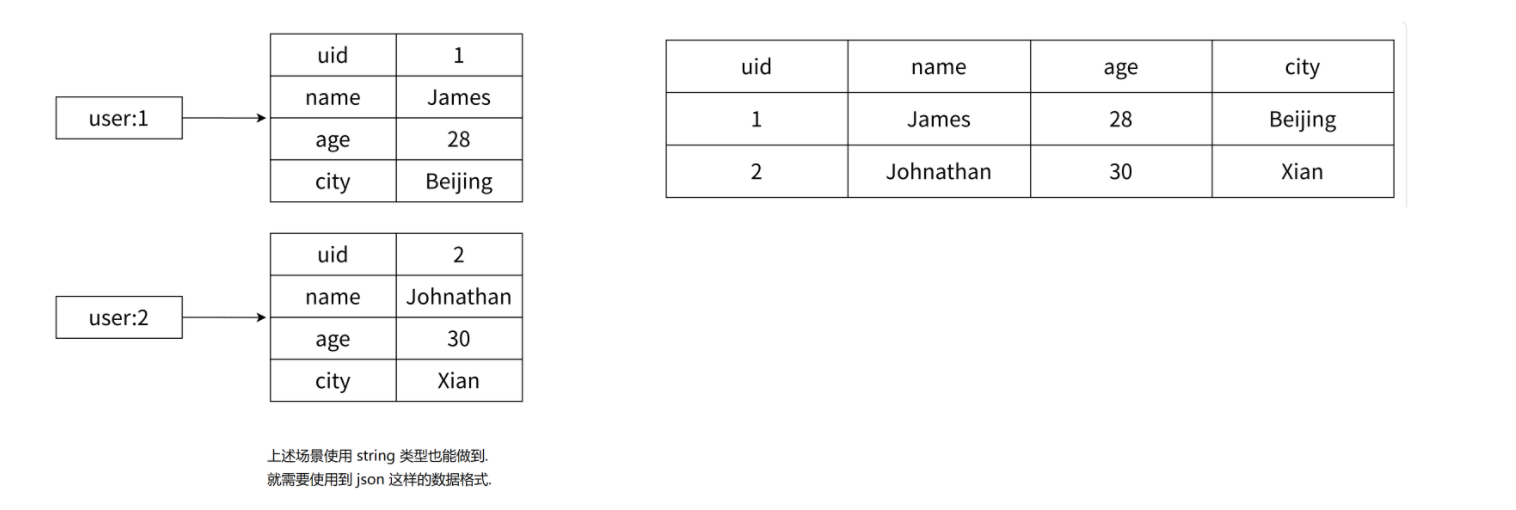
- 字符串作为缓存
- string 也可以作为缓存使用,但存储结构化的数据,使用 hash 类型更合适一些,类似于数据库表结构。
- 例如存储用户信息,用 string 类型需使用 json 格式,若想获取或修改其中某个字段,需读取整个 json 解析成对象操作后再写回;而用 hash 类型,可方便操作每个字段。
- 哈希作为缓存
- 使用 hash 的方式表示 UserInfo,就可以使用 field 表示对象的每个属性(数据表的每个列),此时就可以非常方便的修改 / 获取任何一个属性的值。
- 使用 hash 的方式,确实读写 field 更直观高效,但是付出的是空间的代价,需要控制哈希在 ziplist 和 hashtable 两种内部编码的转换,可能会造成内存的较大消耗。
缓存方式对比:
set user:1:name James
set user:1:age 23
set user:1:city Beijing
1 set user:1 经过序列化后的⽤⼾对象字符串
hmset user:1 name James age 23 city Beijing
4.3原生字符串类型与高内聚低耦合
- 原生字符串类型
- 使用字符串类型,每个属性一个键,这种方式相当于把同一个数据的各个属性,给分散开表示,低内聚,写代码 / 管理数据 => 高内聚。
- 高内聚低耦合
- 高内聚:把有关联的东西放在一起,最好能放在指定的地方。
- 低耦合:两个模块 / 代码之间的关联关系越小,越容易相互影响,追求的是 “低耦合”,避免 “牵一发而动全身”。
- 举例:;高耦合如女朋友生病住院,“我” 会推掉所有事去照顾;低耦合如 “我” 的前女友住院,“我” 不会有任何影响甚至还会给她朋友圈点赞。
- 关于用户信息存储中 uid 的思考
- 思考用户信息存储中 uid 是否必要,若不存 uid 在工程实践中一般也会再存一份,方便后续相关代码使用。
