【AI论文】MegaScience:推动科学推理后训练数据集的前沿发展
摘要:科学推理对于培养人工智能科学家以及助力人类科研人员推进自然科学发现的前沿领域而言至关重要。然而,开源社区主要聚焦于数学和编程领域,却忽视了科学领域,这在很大程度上是由于缺乏开放、大规模、高质量且可验证的科学推理数据集。为填补这一空白,我们首先推出了TextbookReasoning,这是一个开放数据集,其中的真实参考答案提取自1.2万本大学水平科学教材,包含65万个涵盖7个科学学科的推理问题。我们还进一步介绍了MegaScience,这是一个大规模的高质量开源数据集混合体,总计125万个样本。该数据集是通过系统的消融研究开发的,这些研究评估了各种数据选择方法,以确定每个公开可用科学数据集的最优子集。与此同时,我们构建了一个全面的评估系统,该系统涵盖15个基准测试中的多样化学科和问题类型,并融入全面的答案提取策略,以确保评估指标的准确性。我们的实验表明,与现有的开源科学数据集相比,我们的数据集在响应长度更简洁的情况下,实现了更优的性能和训练效率。此外,我们在MegaScience上对Llama3.1、Qwen2.5和Qwen3系列基础模型进行了训练,这些模型在平均性能上显著优于相应的官方指令微调模型。此外,MegaScience对规模更大、性能更强的模型效果更佳,这表明其在科学微调方面具有规模效益。我们将数据整理流程、评估系统、数据集以及七个训练好的模型向社区开源发布,以推动科学推理研究的发展。Huggingface链接:Paper page,论文链接:2507.16812
研究背景和目的
研究背景
随着大型语言模型(LLMs)的发展,它们已经从单纯的知识检索系统演变为具备认知推理能力的系统,这标志着向人工通用智能(AGI)迈出的重要一步。尽管数学和编程领域的推理模型已经取得了显著进展,但科学推理作为另一项关键能力,在开源社区中仍然相对滞后。这主要是因为缺乏开放、大规模、高质量且可验证的科学推理数据集。现有的科学推理数据集存在诸多问题,如不可靠的基准评估、不严格的数据去重、低质量的参考答案以及浅层次的知识提炼等,这些问题严重制约了科学推理模型的发展。
研究目的
本研究旨在填补科学推理数据集领域的空白,推动科学推理模型的发展。具体目标包括:
- 构建高质量的科学推理数据集:通过提取大学水平科学教材中的真实参考答案,构建一个开放的高质量科学推理数据集TextbookReasoning。
- 开发大规模混合数据集:通过系统研究不同数据选择方法,开发一个包含多个公共数据集最优子集的大规模混合数据集MegaScience。
- 设计全面的评估系统:构建一个涵盖多学科和问题类型的全面评估系统,以确保评估指标的准确性。
- 推动科学推理研究:通过开源数据集、评估系统和训练好的模型,促进科学推理领域的研究和发展。
研究方法
数据集构建
- TextbookReasoning数据集构建:
- 教材收集与数字化:从网络上爬取PDF格式的教材,并通过Llama3.3-70B-Instruct模型自动分类教材的主题和学术水平,确保教材为大学水平。最终收集了12,800本学术书籍,涵盖七个学科。
- 问答对提取:将教材分割成4096个token的块,通过Llama3.3-70B-Instruct模型使用高标准和低标准两种标准提取问答对。高标准要求问题需要多步推理,且源文档包含完整的解决方案;低标准仅要求完整的问题和答案。
- 问答对精炼与过滤:使用DeepSeek-V3模型对提取的问答对进行精炼,确保问题包含所有必要的上下文信息,答案提供全面的解释。同时,使用Llama3.3-70B-Instruct模型过滤掉有缺陷的问答对。
- 去重与去污染:使用LLM-based方法进行严格的去重和去污染,确保数据集的完整性和可靠性。
- MegaScience数据集构建:
- 数据集收集:选择NaturalReasoning、Nemotron-Science和TextbookReasoning作为源数据集。
- 去重与去污染:对NaturalReasoning和Nemotron-Science应用与TextbookReasoning相同的去重和去污染方法。
- 数据选择:设计了三种数据选择方法,包括响应长度选择、难度选择和随机选择,以确定每个数据集的最优子集。
评估系统设计
- 开放评估工具包:开源了用于可重复评估的代码库,确保实验结果的可重复性。
- 多维度评估:评估框架涵盖了一般科学知识和专业学科领域,包括多种问题格式,如选择题和计算题。
- 答案提取策略:设计了多种答案提取策略,以确保最终评估指标的准确性。
模型训练与评估
- 模型训练:使用LLaMA-Factory对Qwen2.5、Qwen3和Llama3系列基础模型在MegaScience数据集上进行监督微调。
- 性能评估:使用设计的评估系统对训练好的模型进行评估,比较其在不同基准测试上的性能。
研究结果
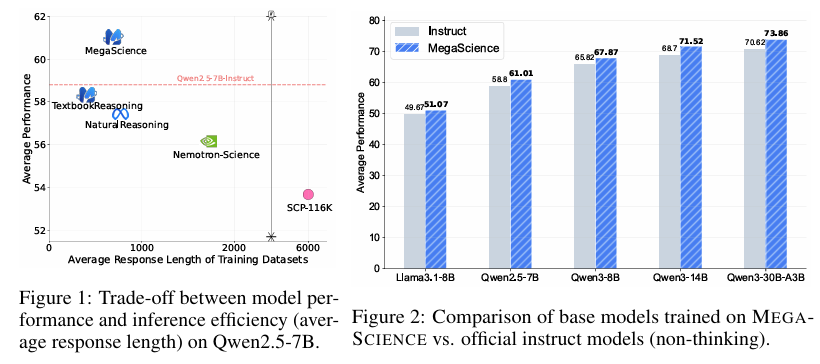
- TextbookReasoning数据集性能:TextbookReasoning在大多数基准测试上表现优于其他开源科学数据集,特别是在计算推理任务上表现突出。例如,在SciBench和OlympicArena上分别比Nemotron-Science高出20.62%和5.23%。
- MegaScience数据集性能:MegaScience在14个基准测试中的7个上实现了最佳性能,并在另外3个基准测试上获得了第二好的性能。与Qwen2.5-7B-Instruct模型相比,MegaScience训练的模型平均性能提高了2.21%。
- 模型性能提升:在MegaScience上训练的Qwen2.5、Qwen3和Llama3系列模型显著优于相应的官方指令微调模型。特别是对于更大更强的模型,MegaScience表现出更大的有效性,表明其在科学微调方面具有规模效益。
研究局限
- 数据集覆盖范围有限:尽管MegaScience是一个大规模混合数据集,但仍然无法涵盖所有科学领域和问题类型。未来需要进一步扩展数据集的覆盖范围,以满足更广泛的研究需求。
- 评估系统的局限性:尽管设计的评估系统涵盖了多学科和问题类型,但仍然可能存在某些未考虑到的评估维度。未来需要不断完善评估系统,以提高评估的全面性和准确性。
- 模型依赖性问题:本研究中使用的基线模型可能存在一定的局限性,不同架构、参数规模和代际更新的模型在性能上存在显著差异。未来需要探索更多类型的模型,以验证MegaScience数据集的普适性和有效性。
未来研究方向
- 扩展数据集覆盖范围:未来工作可以进一步扩展MegaScience数据集的覆盖范围,包括增加更多科学领域和问题类型的数据集,以满足更广泛的研究需求。
- 改进评估系统:不断完善评估系统,增加新的评估维度和指标,以提高评估的全面性和准确性。同时,探索更高效的答案提取策略,以进一步提高评估效率。
- 探索多模态数据集:结合文本、图像和视频等多模态信息,构建更丰富的科学推理数据集。多模态数据集可以提供更全面的科学知识表示,有助于提升模型的推理能力。
- 强化学习应用:探索将强化学习应用于科学推理任务,通过奖励机制引导模型生成更长的思维链(CoT),从而提高模型的推理能力和效率。
- 跨领域推理研究:研究如何将科学推理能力迁移到其他领域,如医学、工程学等,以推动跨领域推理模型的发展。通过构建跨领域数据集和评估系统,验证模型的泛化能力和适应性。