代码解读:微调Qwen2.5-Omni 实战
Diffusion models代码解读:入门与实战
前言:Qwen2.5-Omini发布已经几个月了,但是网上实战微调的教程比较少,特别是如何准备数据如何调参等经验性技巧依旧比较难获得。这篇博客从实战出发,介绍如何微调Qwen2.5-Omni以及微调过程中的一些经验。
目录
Qwen-Omni简介
主要特点
模型架构
微调实战
推理代码
微调环境准备
数据集准备
训练
常见问题
Qwen-Omni简介
https://github.com/QwenLM/Qwen2.5-Omni
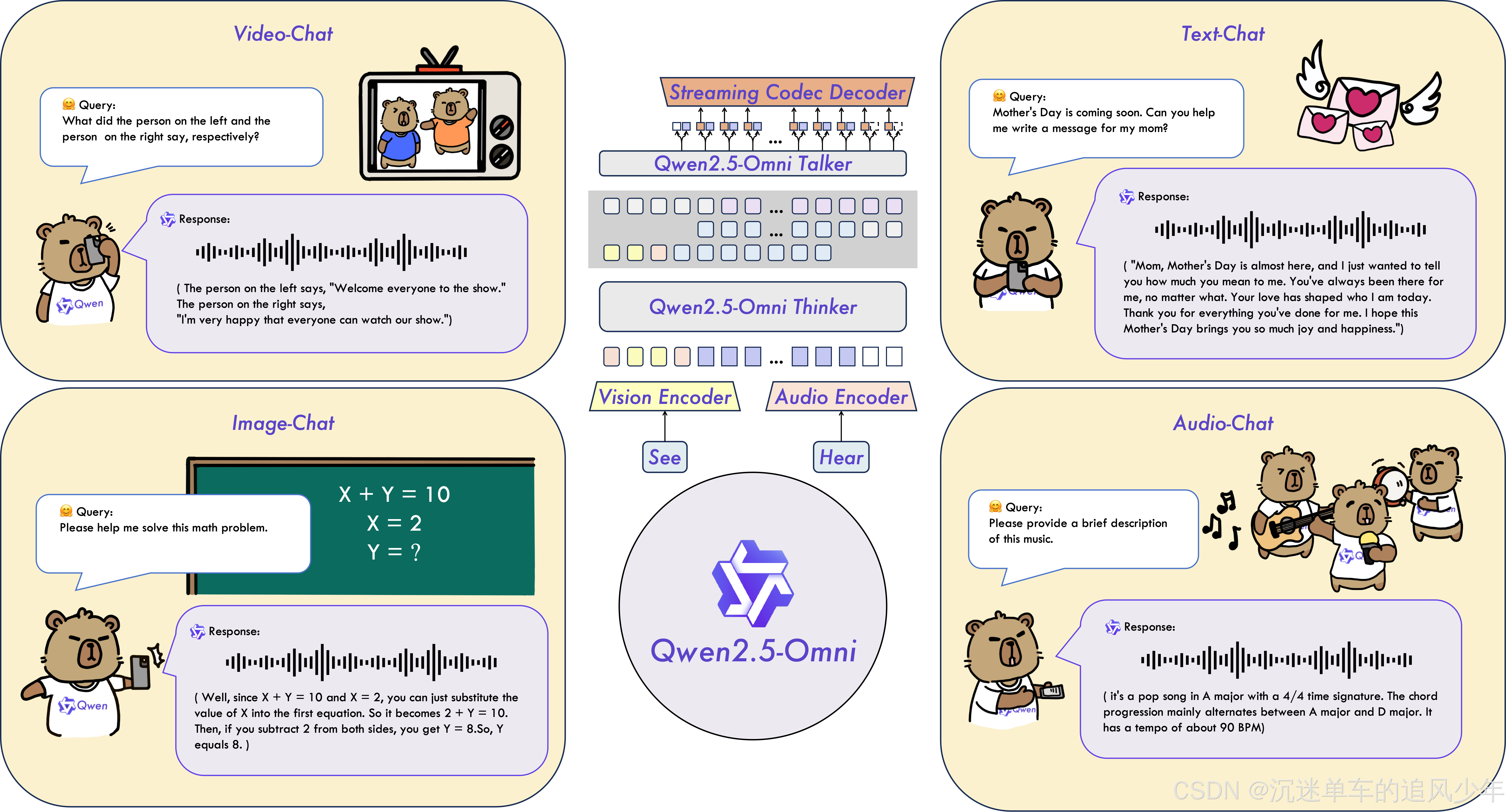
Qwen2.5-Omni 是一个端到端的多模态模型,旨在感知多种模态,包括文本、图像、音频和视频,同时以流式方式生成文本和自然语音响应。
主要特点
-
全方位且新颖的架构:我们提出了“思考者-谈话者”架构,这是一种端到端的多模态模型,旨在感知包括文本、图像、音频和视频在内的多种模态,同时以流式传输的方式生成文本和自然语音响应。我们提出了一种名为 TMRoPE(时间对齐多模态 RoPE)的新颖位置嵌入,用于同步视频输入和音频的时间戳。
-
实时语音和视频聊天:专为完全实时交互而设计的架构,支持分块输入和即时输出。
-
自然而强大的语音生成:超越许多现有的流式和非流式替代方案,在语音生成方面表现出卓越的鲁棒性和自然性。
-
跨模态性能强劲:与类似大小的单模态模型进行基准测试时,在所有模态中均表现出色。Qwen2.5-Omni 在音频功能方面优于类似大小的 Qwen2-Audio,并达到了与 Qwen2.5-VL-7B 相当的性能。
-
出色的端到端语音指令跟踪:Qwen2.5-Omni 在端到端语音指令跟踪方面表现出色,可与文本输入的有效性相媲美,MMLU 和 GSM8K 等基准测试证明了这一点。
模型架构
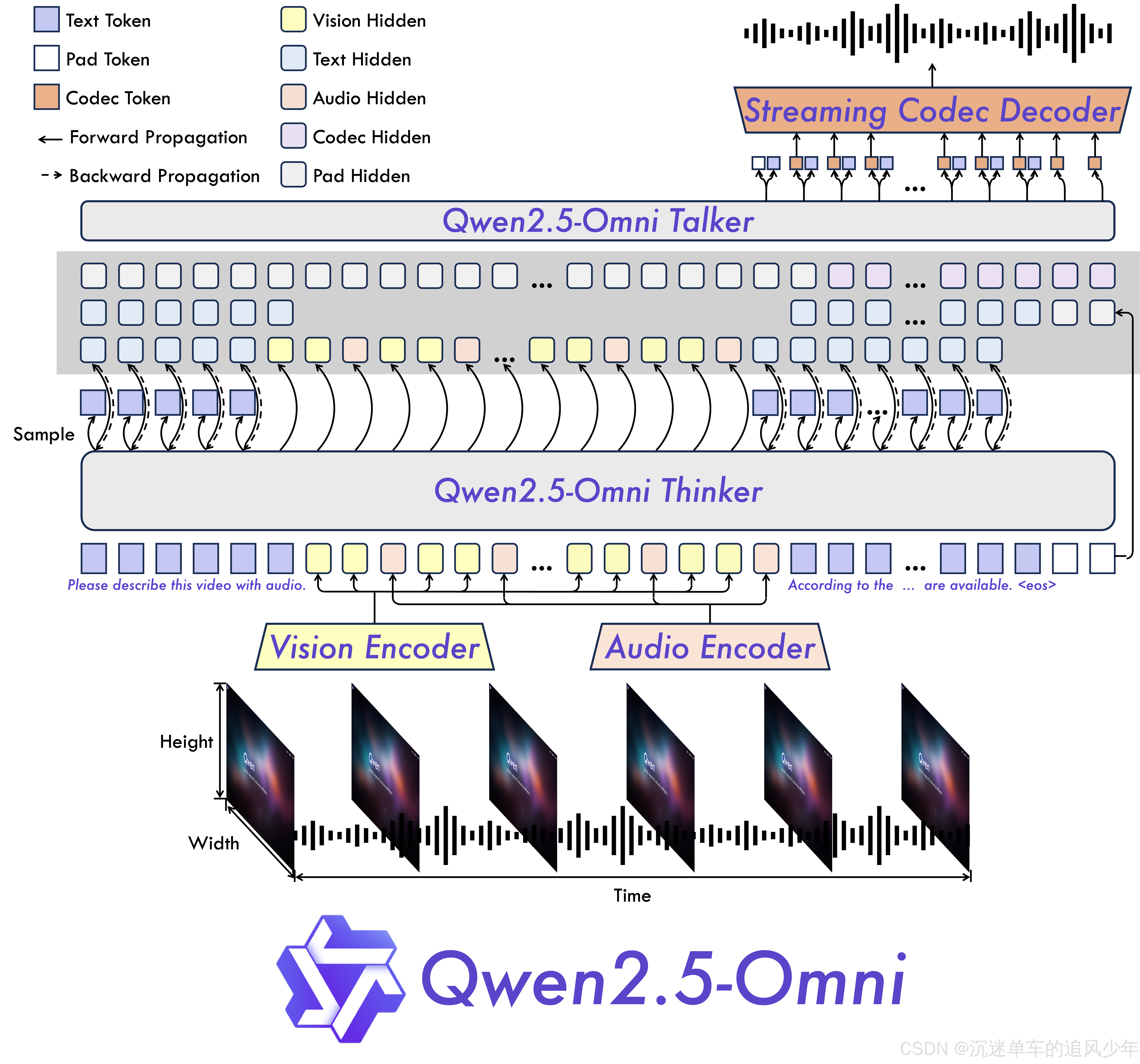
微调实战
推理代码
下面是官方给出的推理代码,可以直接跑通:
import soundfile as sffrom transformers import Qwen2_5OmniForConditionalGeneration, Qwen2_5OmniProcessor
from qwen_omni_utils import process_mm_info# default: Load the model on the available device(s)
model = Qwen2_5OmniForConditionalGeneration.from_pretrained("Qwen/Qwen2.5-Omni-7B", torch_dtype="auto", device_map="auto")# We recommend enabling flash_attention_2 for better acceleration and memory saving.
# model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
# "Qwen/Qwen2.5-Omni-7B",
# torch_dtype="auto",
# device_map="auto",
# attn_implementation="flash_attention_2",
# )processor = Qwen2_5OmniProcessor.from_pretrained("Qwen/Qwen2.5-Omni-7B")conversation = [{"role": "system","content": [{"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}],},{"role": "user","content": [{"type": "video", "video": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/draw.mp4"},],},
]# set use audio in video
USE_AUDIO_IN_VIDEO = True# Preparation for inference
text = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)
audios, images, videos = process_mm_info(conversation, use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = processor(text=text, audio=audios, images=images, videos=videos, return_tensors="pt", padding=True, use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = inputs.to(model.device).to(model.dtype)# Inference: Generation of the output text and audio
text_ids, audio = model.generate(**inputs, use_audio_in_video=USE_AUDIO_IN_VIDEO)text = processor.batch_decode(text_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(text)
sf.write("output.wav",audio.reshape(-1).detach().cpu().numpy(),samplerate=24000,
)微调环境准备
我们用最常用的ms-swift用来微调,安装环境的教程如下:
pip install ms-swift -U
数据集准备
其实在ms-swift的官方手册中,对视频支持的部分比较含糊其辞,按照博主下面的json文件格式准备数据即可:
[{"messages": [{"role": "user","content": "In this video, Determine whether the mouth movements of the characters speaking in the video correspond one-to-one with their voices?"},{"role": "assistant","content": "No."}],"videos": ["./0001f2bb9ca6a3a8e21e8c8d37f35700.mp4"]},{"messages": [{"role": "user","content": "In this video, are there any blurriness or artifacts in each frame?"},{"role": "assistant","content": "No."}],"videos": ["./0001f2bb9ca6a3a8e21e8c8d37f35700.mp4"]},{"messages": [{"role": "user","content": "In the video, is the movement of the characters in the video natural and smooth?"},{"role": "assistant","content": "No."}],"videos": ["./0001f2bb9ca6a3a8e21e8c8d37f35700.mp4"]}
]训练
准备好标注的数据集,如下所示,可以参考博主的脚本启动训练:
MAX_PIXELS=1003520 \
CUDA_VISIBLE_DEVICES="3,4,5,6" \
swift sft \--model ./pretrained_models/Qwen2.5-Omni-7B \--dataset ./xxx.json \--train_type lora \--torch_dtype bfloat16 \--num_train_epochs 100 \--per_device_train_batch_size 1 \--per_device_eval_batch_size 1 \--learning_rate 1e-4 \--lora_rank 32 \--lora_alpha 128 \--target_modules all-linear \--freeze_vit true \--gradient_accumulation_steps 16 \--eval_steps 50 \--save_steps 100 \--save_total_limit 100 \--logging_steps 5 \--max_length 3072 \--output_dir ../ms-swift-data/outputs/ \--warmup_ratio 0.05 \--dataloader_num_workers 4常见问题
最常见的错误就是如果视频比较长,tokens的数量会很多,导致显存爆炸,可以调整max_length 这个参数,根据自己的显存减少。
博主的环境中80GB显存,使用3072或者4096可以顺利运行。