分布式高可用架构核心:复制、冗余与生死陷阱——从主从灾难到无主冲突的避坑指南
分布式高可用架构核心:复制、冗余与生死陷阱——从主从灾难到无主冲突的避坑指南
万字拆解脑裂防护、读写策略与容灾黄金法则,附可运行避坑代码
引言:穿越分布式复制的生死线
当我们谈论分布式系统的高可用,实则是行走在复制的钢丝上:
- 主从复制像精密瑞士表,却在异步模式下化身定时炸弹
- 多主复制如量子纠缠般优雅,却暗藏跨洋数据冲突的致命杀机
- 无主复制似拥有无限韧性,却在QUORUM配置的数学陷阱里埋葬了无数系统
复制是分布式世界的永生咒语,却也是最危险的潘多拉魔盒。当我们疯狂复制数据时,也在疯狂复制故障的温床——监控缺失、脑裂爆发、冲突肆虐,每个陷阱都能让十年技术积累一夜归零。
本文将带您解剖三大复制模式的核心器官:
- 拆解主从切换时脑裂防护的神经反射弧
- 破译多活架构中冲突解决的基因密码
- 绘制无主系统中读修复的量子纠缠图谱
惨痛案例:某金融系统主从切换引发的2.4亿损失
故障时间线分析
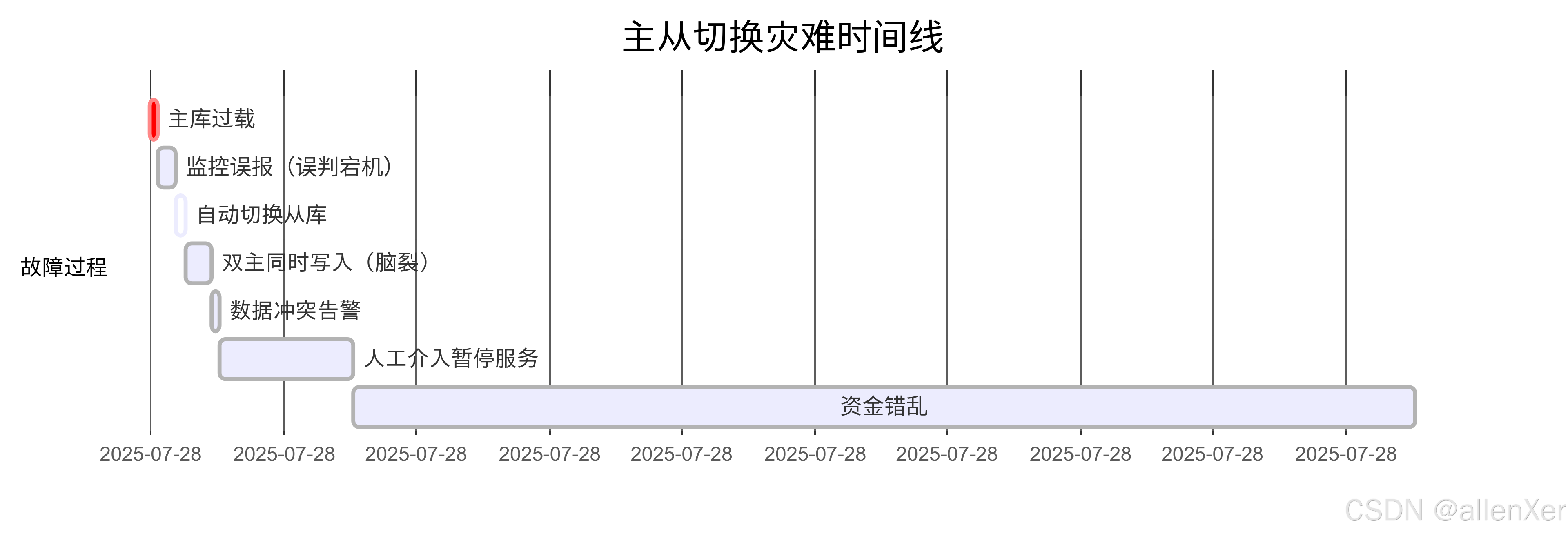
事故根本原因分析:
- 复制延迟监控缺失(未检测
Seconds_Behind_Master) - 缺乏防脑裂的fencing机制
- 切换前未强制旧主只读
一、复制机制全景解析与陷阱地图
1. 主从复制:金融系统的双刃剑
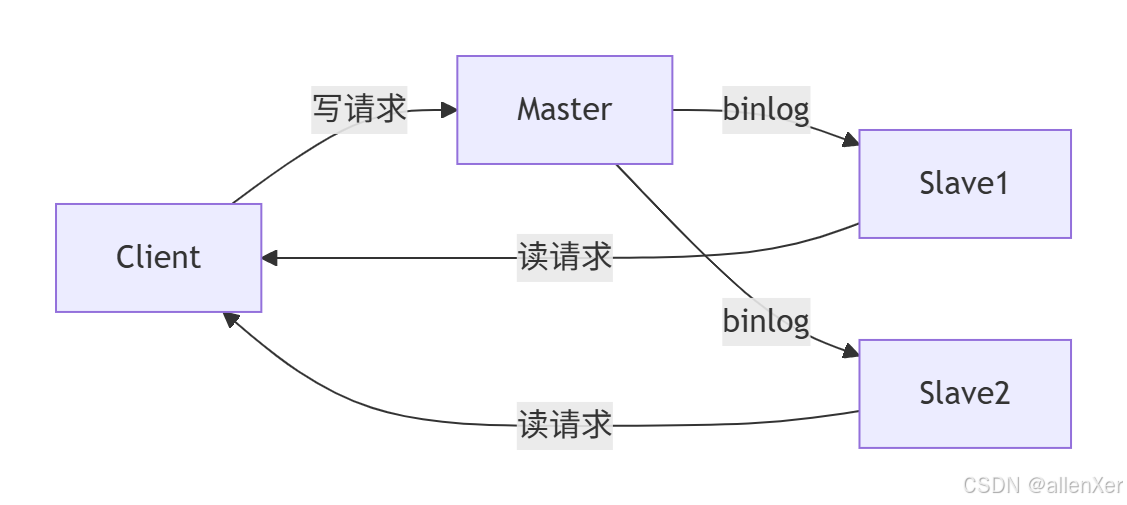
▶ 致命陷阱:异步复制的数据黑洞
# 模拟异步复制数据丢失
import threading
import timeclass Master:def __init__(self):self.data = {}self.slaves = []def write(self, key, value):print(f"[Master] 写入数据 {key}={value}")self.data[key] = value# 异步复制(非阻塞)for slave in self.slaves:threading.Thread(target=slave.replicate, args=(key, value)).start()def add_slave(self, slave):self.slaves.append(slave)class Slave:def __init__(self, name):self.name = nameself.data = {}self.replication_delay = 2 # 模拟复制延迟def replicate(self, key, value):# 模拟网络延迟time.sleep(self.replication_delay)print(f"[{self.name}] 复制数据 {key}={value}")self.data[key] = value# 测试场景
if __name__ == "__main__":master = Master()slave1 = Slave("Slave-1")slave2 = Slave("Slave-2")master.add_slave(slave1)master.add_slave(slave2)# 写入后立即主库宕机master.write("balance", 1000)print("⚠️ 主库突发宕机,从库尚未完成复制!")print(f"Slave1余额: {slave1.data.get('balance', '无数据')}")print(f"Slave2余额: {slave2.data.get('balance', '无数据')}")
# 运行结果:
[Master] 写入数据 balance=1000
⚠️ 主库突发宕机,从库尚未完成复制!
Slave1余额: 无数据
Slave2余额: 无数据
[Slave-1] 复制数据 balance=1000 # 已无法恢复正确状态
[Slave-2] 复制数据 balance=1000避坑清单:
✅ 关键业务必须使用半同步复制
✅ 设置rpl_semi_sync_master_wait_for_slave_count=2
✅ 启用复制延迟监控告警
2. 多主复制:跨境业务的暗雷阵[图3:多主复制冲突场景]
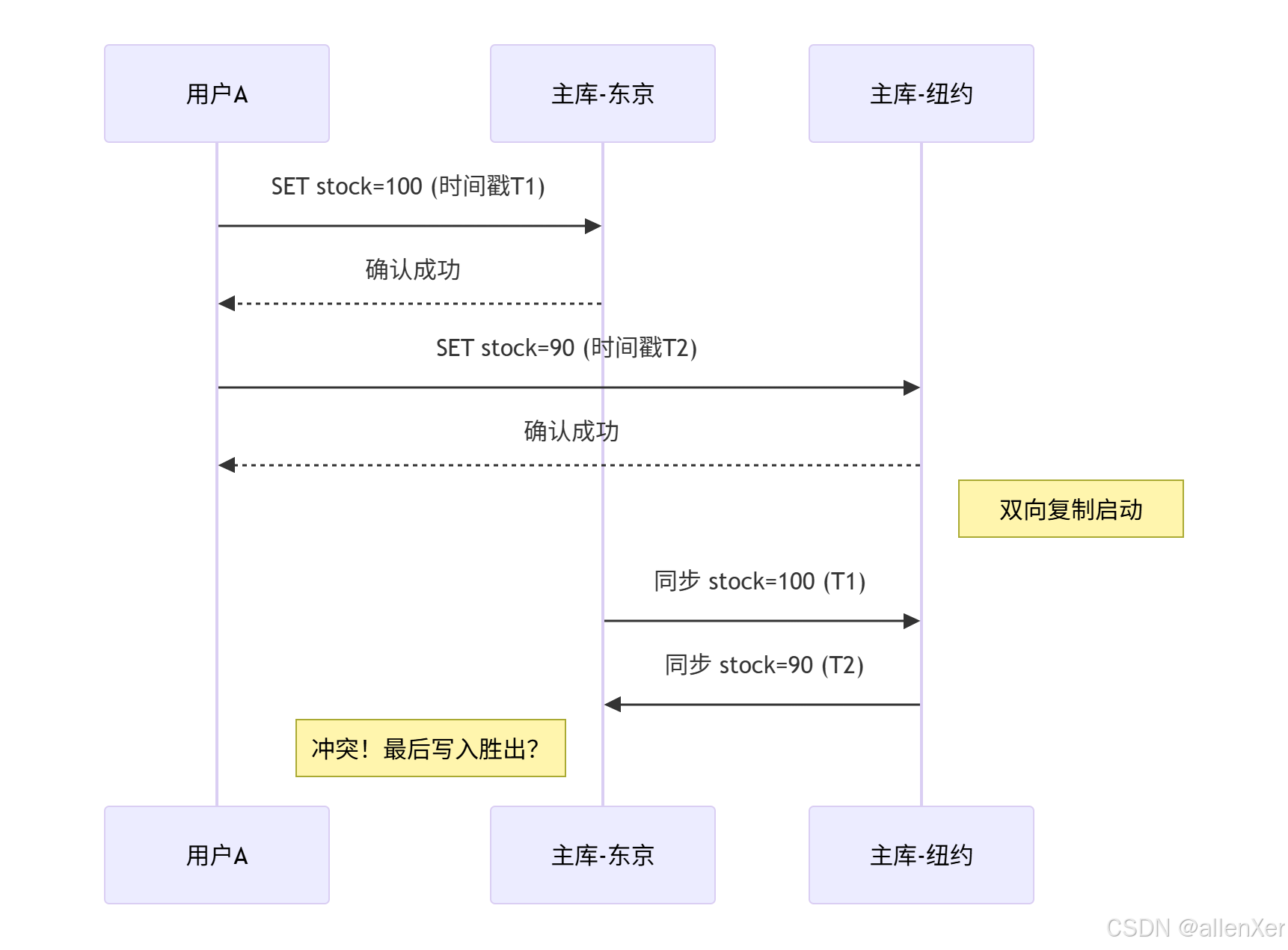
某跨境电商血案:
- 东京和纽约数据中心均接受库存扣减
- 双向复制延迟导致超卖:
理论库存100 -> 东京卖出20 -> 纽约卖出90 -> 实际库存-10
冲突解决代码方案:
// 向量时钟冲突解决
public class VectorClock {private Map<String, Long> versions = new HashMap<>();public void update(String nodeId, long timestamp) {versions.put(nodeId, Math.max(versions.getOrDefault(nodeId, 0L), timestamp));}public ResolutionResult resolveConflict(DataVersion v1, DataVersion v2) {boolean v1Dominates = true;boolean v2Dominates = true;for (String node : versions.keySet()) {long ts1 = v1.versions.getOrDefault(node, 0L);long ts2 = v2.versions.getOrDefault(node, 0L);if (ts1 < ts2) v1Dominates = false;if (ts2 < ts1) v2Dominates = false;}if (v1Dominates) return ResolutionResult.USE_V1;if (v2Dominates) return ResolutionResult.USE_V2;return ResolutionResult.CONFLICT; // 需要人工介入}
}3. 无主复制:亿级流量的残酷选择
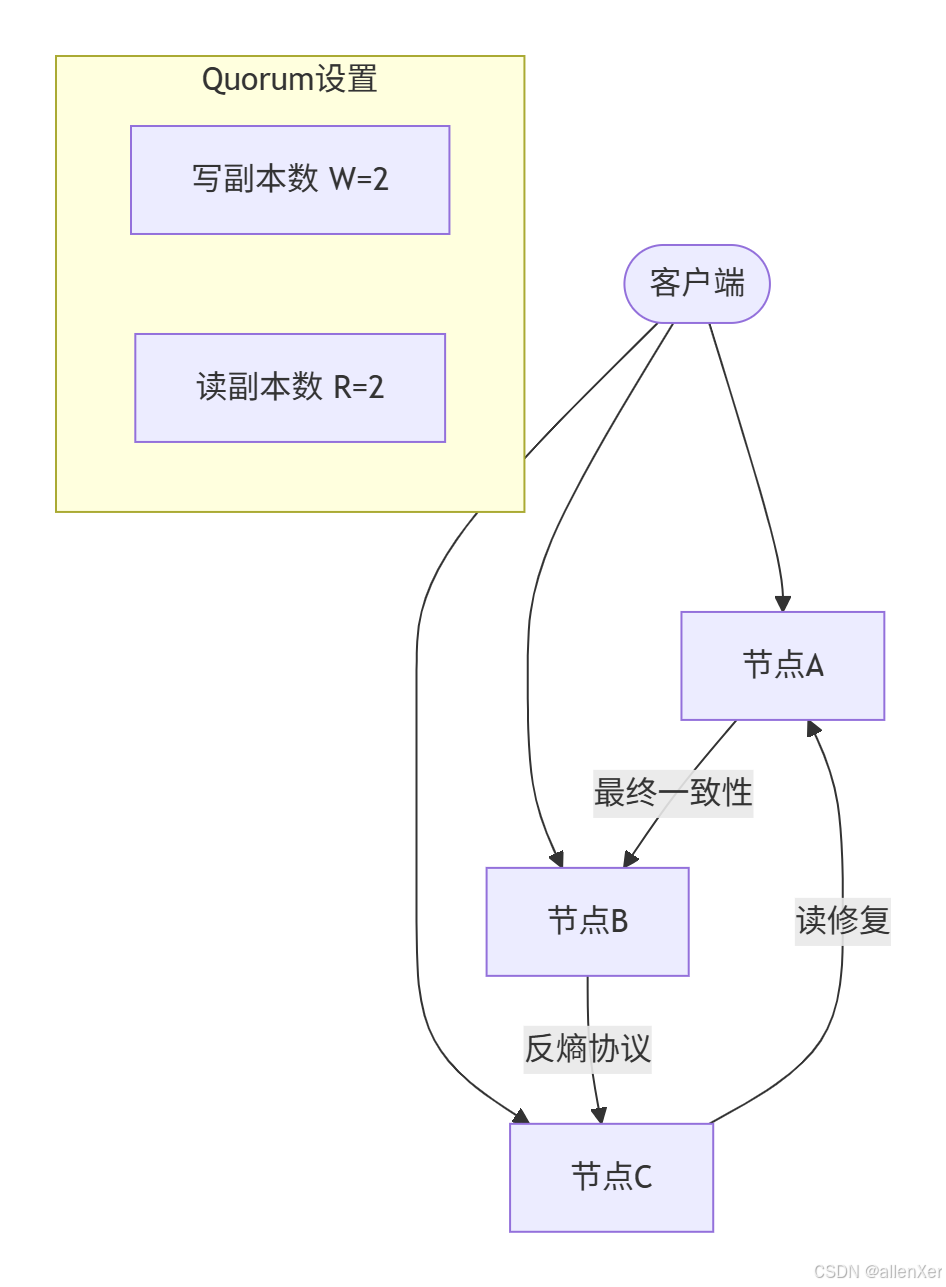
读写策略生死表:
| 策略组合 | 可用性 | 一致性 | 危险场景 |
|---|---|---|---|
| W=1,R=1 | 最高 | 最低 | 丢数据风险>40% |
| W=N/2+1 | 平衡 | 中等 | 节点宕机时延迟高 |
| W=N,R=1 | 最低 | 最高 | 写入超时率达30% |
读修复伪代码:
func Read(key string) (Value, error) {// 1. 并发读取N个副本results := make(chan ReadResult, len(nodes))for _, node := range nodes {go func(n Node) {results <- n.Get(key)}(node)}// 2. 等待R个响应responses := []ReadResult{}for i := 0; i < R; i++ {resp := <-resultsresponses = append(responses, resp)}// 3. 版本比对latestVer := findMaxVersion(responses)if !allVersionsMatch(responses) {// 4. 触发异步修复go func() {for _, node := range nodes {node.Repair(key, latestVer)}}()}return latestVer.value, nil
}二、复制实战避坑十大黄金法则
法则1:永远预防脑裂
# Kubernetes脑裂防护配置
apiVersion: v1
kind: Pod
metadata:name: mysql
spec:affinity:podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues: ["mysql"]topologyKey: "kubernetes.io/hostname"terminationGracePeriodSeconds: 30 # 优雅终止时间窗法则2:读写分离的隐藏成本
/* MySQL读写分离陷阱验证 */
START TRANSACTION;
INSERT INTO orders (...) VALUES (...);
SELECT LAST_INSERT_ID(); /* 从库可能查不到! */-- 解决方案:同一会话路由到主库
/*#mycat:db_type=master*/ SELECT LAST_INSERT_ID();法则3:跨数据中心复制的延迟监控
# 多数据中心延迟检测脚本
#!/bin/bash
DC1="db-eu-1"
DC2="db-us-1"while true
do# 写入时戳ts=$(date +%s%3N)mysql -h $DC1 -e "INSERT INTO latency_test(ts) VALUES($ts)"# 跨区查询us_ts=$(mysql -h $DC2 -Ne "SELECT ts FROM latency_test ORDER BY id DESC LIMIT 1")latency=$(( $(date +%s%3N) - us_ts ))echo "EU->US复制延迟: ${latency}ms"# 触发告警阈值if [ $latency -gt 5000 ]; thensend_alert "跨区复制延迟超5秒!"fisleep 10
done三、容灾冗余配置生死清单
存储层冗余:
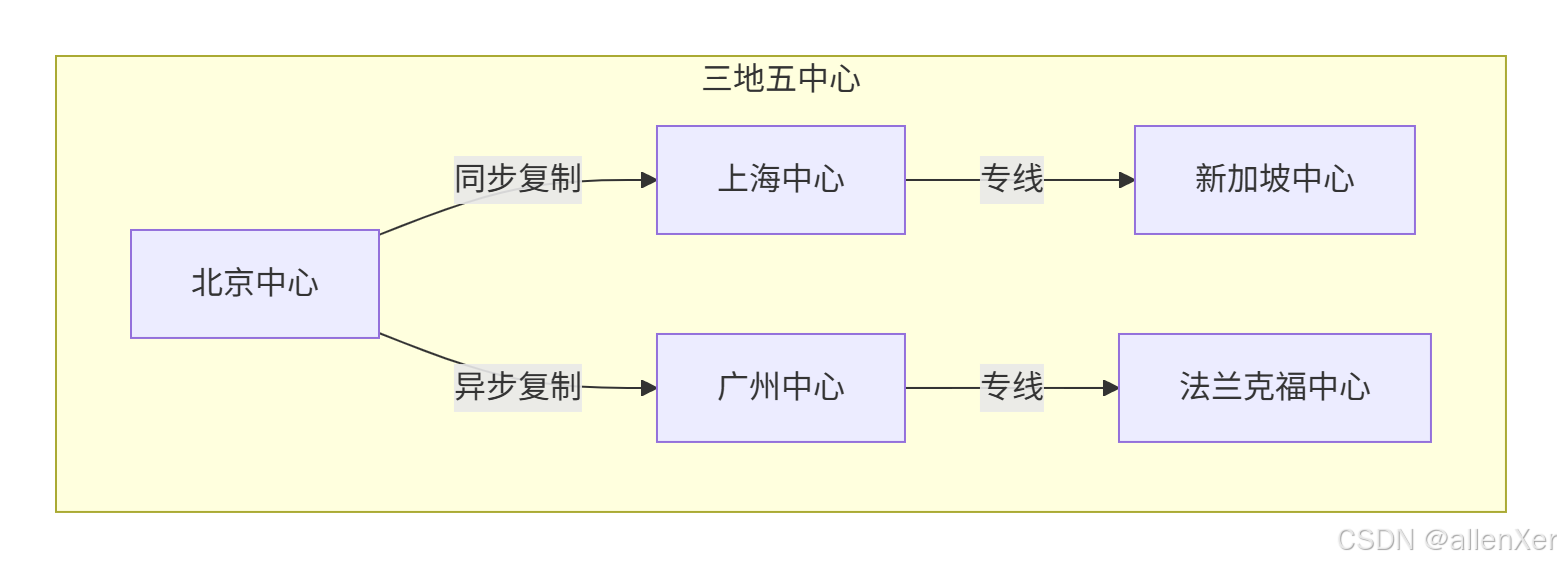
服务层冗余检查表:
- 单节点故障域隔离:
物理机/机架/AZ级冗余 - 心跳检测间隔 <
服务超时的1/3 - 过载保护:
max_connections = 理论峰值×2 - 故障注入测试:
每月模拟区域故障 - 逃生开关:
强制只读/降级开关
思考题
- 在跨洋多活架构中,如何设计购物车服务避免商品超卖?
- 当监控显示半同步复制卡在
Waiting for semi-sync ACK时的应急步骤? - 如何为无主数据库设计安全的账户余额操作(伪代码)?
结语:复制的哲学
"分布式复制的艺术不在于追求完美同步
而在于在数据一致性与可用性之间
为具体业务找到最佳平衡点"
—— Amazon Dynamo设计原则
灾难启示录:
- 某8同城2015年:主从不一致导致300万用户数据错乱
- Azure 2017:跨区延迟引发全球存储服务中断
- 某交易所2020:无主复制配置错误造成清算失败