论文略读:REMEDY: RECIPE MERGING DYNAMICS IN LARGE VISION-LANGUAGE MODELS
ICLR 2025
- 模型合并能够将多个任务特定模型整合成一个统一模型,实现跨任务能力迁移
- 任务算术(task arithmetic)通过加权任务向量实现知识迁移
- 后续的 TIES-Merging 和 AdaMerging 又进一步利用模型剪枝与合并系数自适应机制,提升了视觉模型中的多样性与适应性。
但在 LVLM 上的模型合并仍未被充分探索,其面临两大挑战:
模型规模巨大
LVLM 通常包含三个模块:视觉编码器(visual encoder)、投影器(projector)、大型语言模型(LLM)。
例如 LLaVA 1.5 包含 3 亿视觉编码器参数和 70 亿或 130 亿 LLM 参数。
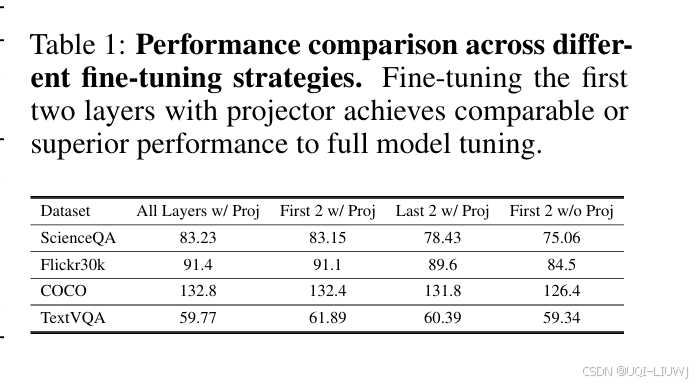
在任务特定数据有限(如 ScienceQA 仅有 1696 对图像-问题样本)的情况下,全面微调这些模块代价极高。
因此,寻找高效子模块以进行知识迁移成为关键。
视觉语言任务具有异质性
LVLM 的输入同时包含视觉与语言数据,任务差异可能来自图像模态、语言模态,或两者兼具。
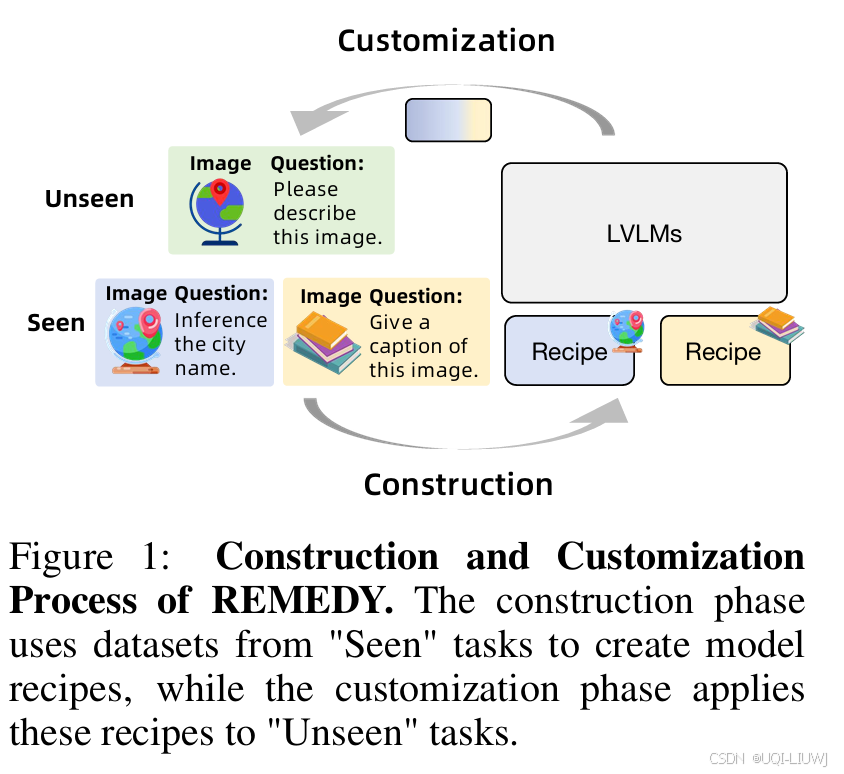
如图 1 所示,同一张地球图片在不同任务中可能需要生成不同输出(如识别城市名 vs. 生成图像描述)
在零样本泛化任务中,LVLM 被期望处理新的视觉-语言组合,其挑战远超传统单模态任务的零样本学习。
——>为了解决上述挑战,本文提出了REcipe MErging DYnamics(REMEDY),一个针对 LVLM 的模型合并新范式,解决传统视觉模型合并方法的局限性。
REMEDY 包括两个核心步骤:
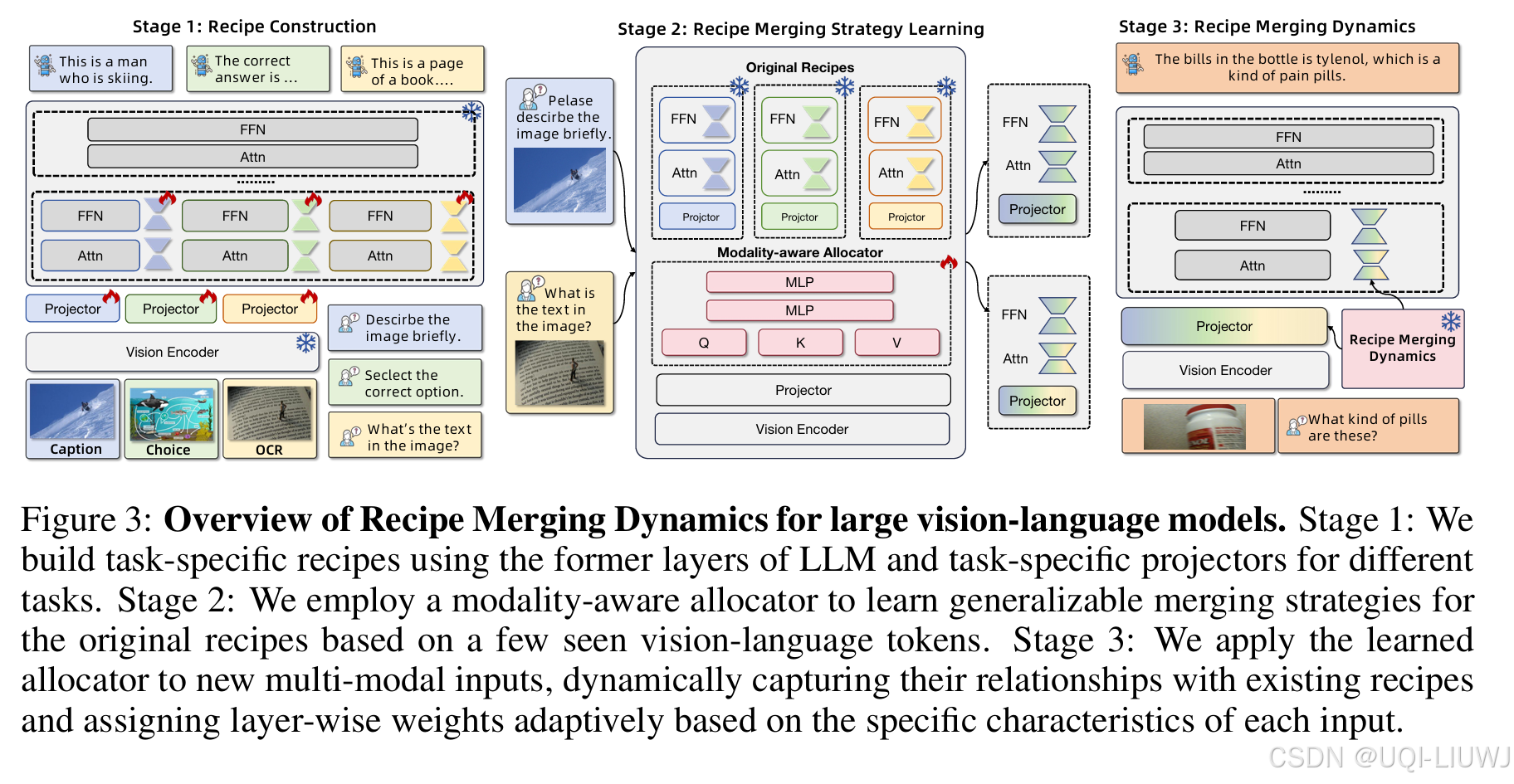
Recipe 构建(Recipe Construction)
将模型中的可复用模块(如 projector 与 LLM 的浅层)定义为 recipes
通过在多个 LVLM 上的大量实验,我们发现这些模块:
显著提升了视觉感知能力;
改进了图文交互理解;
并非只是“模仿输出风格”,而是真正增强了任务迁移能力
Recipe 合并(Recipe Merging)
在构建完 recipe 后,提出一种模态感知的分配器(modality-aware allocator);
该分配器利用**少量示例(few-shot learning)**判断输入图文与现有 recipe 的相关性;
然后执行一次性权重分配(one-shot weight allocation);
该动态融合机制可适应多模态输入,实现跨任务、跨模态知识的有效整合。