ESP32的ADF详解:6. Audio Processing的API
一、Downmix
1. 核心功能
将基础音频流和新加入音频流混合为单一输出流,支持动态增益控制和状态转换。输出声道数与基础音频一致,新加入音频自动转换声道匹配。
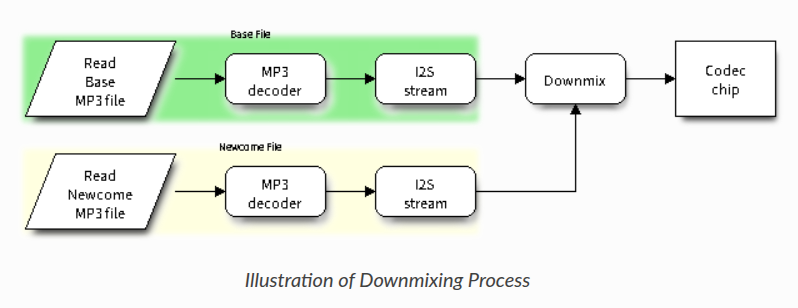
2. 关键特性
-
声道处理
- 输出声道数 = 基础音频声道数
- 新加入音频自动转换声道(如立体声→单声道取平均,单声道→立体声复制)
- 采样率必须一致,否则报错
-
三态工作流程
状态 行为 增益变化 Bypass Downmixing 仅处理基础音频流 基础音频增益恒定 Switch on Downmixing 1. 过渡期:两路增益渐变到目标值
2. 稳定期:共享相同目标增益基础增益: 原值→目标值新加入增益: 0→目标值Switch off Downmixing 1. 过渡期:增益回退到原始值
2. 稳定期:恢复独立增益后进入Bypass基础增益: 目标值→原值新加入增益: 目标值→0 -
增益控制
- 独立控制两路音频增益
- 过渡期支持线性/非线性渐变
- 稳定期两路共享相同增益值
3. 典型应用场景
- 智能音箱:语音提示混入背景音乐
- 车载系统:导航提示与娱乐音频混合
- 直播系统:麦克风人声与背景音混合
- 多语言播报:基础音轨+实时语言叠加
关键约束:输入音频必须采样率一致,否则API返回错误码
ESP_ERR_INVALID_ARG
4. API
1. 核心配置与初始化
| API/结构体 | 功能描述 | 关键参数/成员 |
|---|---|---|
downmix_init(downmix_cfg_t *) | 初始化Downmix音频元素 | downmix_info(工作模式/输出类型)、max_sample(每帧采样数)、out_rb_size等 |
downmix_cfg_t | 配置结构体 | - esp_downmix_info_t downmix_info- 任务栈大小/核心/优先级 - 缓冲区大小 |
DEFAULT_DOWNMIX_CONFIG() | 生成默认配置宏 | 预定义任务栈(4KB)、优先级(5)、核心(1)、缓冲区大小(2KB) |
2. 输入输出控制
| API | 功能描述 | 关键参数 |
|---|---|---|
downmix_set_input_rb() | 设置输入环形缓冲区 | rb(缓冲区句柄)、index(输入流索引,0/1) |
downmix_set_input_rb_timeout() | 设置输入缓冲区超时时间 | ticks_to_wait(RTOS tick数) |
downmix_set_output_type() | 设置输出声道类型 | output_type(仅支持MONO或DUAL) |
downmix_set_out_ctx_info() | 传递输出流的上下文信息 | out_ctx(如各声道独立控制标志) |
3. 工作模式与状态控制
| API | 功能描述 | 关键参数 |
|---|---|---|
downmix_set_work_mode() | 设置工作模式 | mode:- BYPASS(直通)- ON(开启混音)- OFF(关闭混音) |
downmix_set_transit_time_info() | 设置状态切换的过渡时间 | transit_time(毫秒)、index(输入流索引) |
4. 音频流参数配置
| API | 功能描述 | 关键参数 |
|---|---|---|
downmix_set_source_stream_info() | 设置输入流的采样率和声道数 | rate(必须一致)、ch(仅支持1/2声道)、index(输入流索引) |
source_info_init() | 批量初始化多路输入流信息 | source_info(结构体数组,含采样率/声道数/增益等) |
5. 增益控制
| API | 功能描述 | 关键参数 |
|---|---|---|
downmix_set_gain_info() | 设置输入流的增益值 | gain(数组[原增益, 目标增益],范围[-100dB,100dB]) |
6. 数据结构与宏定义
| 类型/宏定义 | 说明 |
|---|---|
esp_downmix_info_t | 工作模式(work_mode) + 输出类型(output_type) |
esp_downmix_input_info_t | 输入流信息(采样率/声道数/增益/过渡时间) |
DOWNMIX_TASK_STACK | 默认任务栈大小(4KB) |
DM_BUF_SIZE | 内部缓冲区大小(默认1024样本) |
/*** @brief 下混配置结构体,用于配置下混处理的各种参数。*/
struct downmix_cfg_t {esp_downmix_info_t downmix_info; ///< 下混信息int max_sample; ///< 每次下混处理的样本数int out_rb_size; ///< 环形缓冲区大小int task_stack; ///< 任务栈大小int task_core; ///< 任务运行的核心(0 或 1)int task_prio; ///< 任务优先级(基于 FreeRTOS 的优先级)bool stack_in_ext; ///< 是否尝试在外部内存中分配栈
};7. 关键约束与注意事项
- 采样率一致性:所有输入流必须相同,否则返回
ESP_ERR_INVALID_ARG。 - 声道支持:仅支持单声道(
MONO)和双声道(DUAL),其他声道数需预处理。 - 增益范围:
-100dB至100dB,超出范围可能导致 clipping。 - 实时性:过渡时间(
transit_time)影响状态切换平滑度,需根据应用场景调整。
8. 典型调用流程
// 1. 初始化配置
downmix_cfg_t cfg = DEFAULT_DOWNMIX_CONFIG();
cfg.downmix_info.work_mode = ESP_DM_BYPASS;
cfg.downmix_info.output_type = ESP_DM_DUAL_OUTPUT;// 2. 创建句柄
audio_element_handle_t downmixer = downmix_init(&cfg);// 3. 设置输入流参数
downmix_set_source_stream_info(downmixer, 44100, 2, 0); // 基础流
downmix_set_source_stream_info(downmixer, 44100, 1, 1); // 新加入流(自动转立体声)// 4. 配置增益
float gains[2] = {0.0f, -6.0f}; // [基础增益, 目标增益]
downmix_set_gain_info(downmixer, gains, 0);// 5. 启动混音
downmix_set_work_mode(downmixer, ESP_DM_ON);
downmix_set_transit_time_info(downmixer, 500, 0); // 500ms过渡
二、Equalizer
1. 功能概述
-
Equalizer 是 ESP ADF 提供的一个强大的音频均衡器模块,支持 10 个频段和多种采样率,适用于音频增强、音效定制等场景。通过
equalizer_cfg和equalizer_set_gain_info()函数,开发者可以灵活调整音频信号的频率响应,满足不同的音频处理需求。 -
Equalizer 支持:
- 固定频段数量:10 个频段。
- 支持的采样率:11025 Hz、22050 Hz、44100 Hz 和 48000 Hz。
- 默认增益:每个频段的默认增益为 -13 dB。
2. 频段中心频率
Equalizer 的 10 个频段的中心频率如下表所示:
| 频段索引 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| 频率 | 31 Hz | 62 Hz | 125 Hz | 250 Hz | 500 Hz | 1 kHz | 2 kHz | 4 kHz | 8 kHz | 16 kHz |
3. 使用场景
Equalizer 适用于需要调整音频信号频率响应的场景,例如:
- 音频增强:提升低频或高频部分的音量。
- 音效定制:根据不同需求调整音频特性,如增强低音或高音。
- 噪声消除:通过调整特定频段的增益来减少噪声。
4. 示例代码
以下是一个简单的示例,展示如何使用 Equalizer:
#include "esp_adf.h"
// 初始化 Equalizer
equalizer_cfg_t eq_cfg = {.bands = {{ .gain = -10 }, // 31 Hz 频段增益为 -10 dB{ .gain = -5 }, // 62 Hz 频段增益为 -5 dB// 其他频段可以按需设置},.band_count = 10
};
// 创建 Equalizer 实例
equalizer_handle_t eq_handle = equalizer_create(&eq_cfg);
// 设置单个频段的增益
equalizer_set_gain_info(eq_handle, 3, -8); // 设置 250 Hz 频段增益为 -8 dB
// 应用 Equalizer
audio_element_handle_t audio_src = ...; // 音频源
audio_element_handle_t audio_dest = ...; // 音频目标
audio_element_link(audio_src, eq_handle);
audio_element_link(eq_handle, audio_dest);
5. API
1. 核心配置与初始化
| API/结构体 | 功能描述 | 关键参数/成员 |
|---|---|---|
equalizer_init(equalizer_cfg_t *) | 初始化均衡器音频元素 | samplerate(支持11025/22050/44100/48000Hz)、channel(单/双声道)、set_gain(增益数组) |
equalizer_cfg_t | 配置结构体 | - task_stack(默认4KB)- out_rb_size(输出缓冲区大小)- stack_in_ext(外部内存分配) |
DEFAULT_EQUALIZER_CONFIG() | 生成默认配置宏 | 预定义任务栈、优先级(5)、核心(1)、缓冲区大小(2KB) |
2. 参数设置
| API | 功能描述 | 关键参数 |
|---|---|---|
equalizer_set_info() | 设置采样率和声道数 | rate(必须为特定值)、ch(1或2) |
equalizer_set_gain_info() | 设置指定频段的增益 | index(频段索引)、value_gain(增益值)、is_channels_gain_equal(双声道同步) |
3. 数据结构与宏定义
| 类型/宏定义 | 说明 |
|---|---|
EQUALIZER_TASK_STACK | 默认任务栈大小(4KB) |
EQUALIZER_RINGBUFFER_SIZE | 环形缓冲区大小(默认2KB) |
equalizer_cfg_t | 包含采样率、声道数、增益数组等配置参数 |
4. 关键特性详解
频段分布(不同采样率下)
| 采样率 | 支持的10个频段中心频率(Hz) |
|---|---|
| 11025Hz | 31, 62, 125, 250, 500, 1000, 2000, 3000, 4000, 5500 |
| 22050Hz | 31, 62, 125, 250, 500, 1000, 2000, 4000, 8000, 11000 |
| 44100Hz | 31, 62, 125, 250, 500, 1000, 2000, 4000, 8000, 16000 |
| 48000Hz | 同44100Hz |
增益控制规则
-
单声道(MONO)
- 10个可调频段(索引0~9)
- 示例:
equalizer_set_gain_info(self, 3, 5, true)→ 设置第4个频段(250Hz)增益为5dB
-
双声道(DUAL)
- 独立控制(
is_channels_gain_equal=false):20个频段(左声道09,右声道1019)// 设置左声道第2频段(62Hz)增益为3dB equalizer_set_gain_info(self, 1, 3, false); // 设置右声道第5频段(1kHz)增益为-2dB equalizer_set_gain_info(self, 14, -2, false); - 同步控制(
is_channels_gain_equal=true):10个频段(左右声道联动)// 同时设置左右声道的第7频段(4kHz)增益为6dB equalizer_set_gain_info(self, 6, 6, true);
- 独立控制(
5. 典型调用流程
// 1. 初始化配置
equalizer_cfg_t cfg = DEFAULT_EQUALIZER_CONFIG();
cfg.samplerate = 44100;
cfg.channel = 2; // 立体声
int gains[20] = {0}; // 默认所有频段增益为0dB
cfg.set_gain = gains;// 2. 创建均衡器实例
audio_element_handle_t eq = equalizer_init(&cfg);// 3. 设置个性化增益
// 提升低频(左声道125Hz +5dB)
equalizer_set_gain_info(eq, 2, 5, false);
// 衰减高频(右声道8kHz -3dB)
equalizer_set_gain_info(eq, 17, -3, false);
// 同步调整中频(左右声道1kHz +2dB)
equalizer_set_gain_info(eq, 5, 2, true);
6. 约束与注意事项
- 采样率限制:仅支持11025/22050/44100/48000Hz,其他值返回
ESP_ERR_INVALID_ARG。 - 频段索引范围:
- 单声道:0~9
- 双声道独立控制:019(左09,右10~19)
- 增益范围:未明确限制,但建议在[-12dB, +12dB]内避免失真。
- 实时性:修改增益会立即生效,可能导致音频瞬态变化,建议在静音时调整。
三、Resample Filter
- 重采样滤波器是一种音频元素,旨在对输入的数据流进行降采样或升采样,同时还可以在立体声和单声道之间转换数据。
1. API
1. 核心配置与初始化
| API/结构体 | 功能描述 | 关键参数/成员 |
|---|---|---|
rsp_filter_init(rsp_filter_cfg_t *) | 初始化重采样音频元素 | src_rate/dest_rate(Hz)、src_ch/dest_ch(1/2)、mode(编码/解码模式) |
rsp_filter_cfg_t | 配置结构体 | - type(自动/上采样/下采样)- complexity(1-5级精度)- prefer_flag(CPU/RAM优化倾向) |
DEFAULT_RESAMPLE_FILTER_CONFIG() | 生成默认配置宏 | 预定义任务栈(4KB)、优先级(5)、核心(1)、缓冲区大小(2KB) |
2. 参数动态设置
| API | 功能描述 | 关键参数 |
|---|---|---|
rsp_filter_set_src_info() | 设置输入流的采样率和声道数 | src_rate(Hz)、src_ch(1/2) |
rsp_filter_change_src_info() | 动态修改输入流参数(含位宽) | src_bit(支持8/16/24/32bit) |
3. 工作模式与特性
重采样模式(esp_resample_mode_t)
| 模式 | 行为特性 |
|---|---|
| RESAMPLE_DECODE_MODE | 自动从audio_element_getinfo获取输入参数,输出长度可变 |
| RESAMPLE_ENCODE_MODE | 需手动配置输入/输出参数,输出长度固定(需设置out_len_bytes) |
重采样类型(esp_resample_type_t)
| 类型 | 说明 |
|---|---|
| RESAMPLE_AUTO | 自动判断上/下采样 |
| RESAMPLE_UP | 强制上采样(如44.1kHz→48kHz) |
| RESAMPLE_DOWN | 强制下采样(如48kHz→16kHz) |
复杂度控制(complexity)
| 等级 | 性能表现 | 适用场景 |
|---|---|---|
| 1 | 最快速度,最低精度 | 低功耗实时处理 |
| 3 | 平衡速度与精度 | 通用场景(默认) |
| 5 | 最慢速度,最高精度 | 高保真音频处理 |
4. 声道处理规则
| 转换场景 | 处理方式 |
|---|---|
| 单声道→立体声 | 复制单声道数据到双声道(可设置down_ch_idx指定源声道) |
| 立体声→单声道 | 默认混合左右声道,或通过down_ch_idx选择左/右声道(0:左, 1:右) |
5. 数据结构与宏定义
| 类型/宏定义 | 说明 |
|---|---|
RSP_FILTER_TASK_STACK | 默认任务栈大小(4KB) |
RSP_FILTER_RINGBUFFER_SIZE | 环形缓冲区大小(默认2KB) |
esp_rsp_prefer_type_t | 资源偏好: - ESP_RSP_PREFER_CPU- ESP_RSP_PREFER_MEM |
/*** @brief 重采样滤波器配置结构体。* 此结构体用于配置重采样滤波器的参数。*/
struct rsp_filter_cfg_t {int src_rate; /**< 源 PCM 文件的采样率(单位:Hz) */int src_ch; /**< 源 PCM 文道的通道数(单声道=1,立体声=2) */int dest_rate; /**< 目标 PCM 文件的采样率(单位:Hz) */int dest_bits; /**< 目标 PCM 数据样本的位宽。当前支持:16 位。 */int dest_ch; /**< 目标 PCM 文件的通道数(单声道=1,立体声=2) */int src_bits; /**< 源 PCM 数据样本的位宽。支持的位宽:8 位、16 位、24 位、32 位。 */esp_resample_mode_t mode; /**< 重采样模式(编码或解码)。解码模式具有恒定的输入 PCM 长度;编码模式具有恒定的输出 PCM 长度。 */int max_indata_bytes; /**< 输入 PCM 的最大缓冲区大小(单位:字节) */int out_len_bytes; /**< 输出流数据的缓冲区长度。此参数必须在编码模式下配置。 */esp_resample_type_t type; /**< 重采样类型(自动、升采样、降采样) */int complexity; /**< 指示重采样的复杂度。在使用 FIR 滤波器时有效。范围:[1, 5];1 表示最低复杂度(最低精度,最快速度);5 表示最高复杂度(最高精度,最慢速度)。小于 1 的值会被设置为 1,大于 5 的值会被设置为 5。 */int down_ch_idx; /**< 指示所选的通道(右或左)。仅当复杂度设置为 0 且输入文件的通道从立体声变为单声道时有效。 */esp_rsp_prefer_type_t prefer_flag;/**< 选择标志,用于选择较低的 CPU 使用率或较低的 INRAM 使用率。请参阅 esp_resample.h 获取详情。 */int out_rb_size; /**< 输出环形缓冲区大小 */int task_stack; /**< 任务栈大小 */int task_core; /**< 任务运行的核心 */int task_prio; /**< 任务优先级 */bool stack_in_ext; /**< 尝试在外部内存中分配栈的标志 */
};6. 典型调用流程
// 1. 初始化配置(48kHz立体声→16kHz单声道)
rsp_filter_cfg_t cfg = DEFAULT_RESAMPLE_FILTER_CONFIG();
cfg.src_rate = 48000;
cfg.src_ch = 2;
cfg.dest_rate = 16000;
cfg.dest_ch = 1;
cfg.mode = RESAMPLE_ENCODE_MODE;
cfg.complexity = 3; // 平衡模式// 2. 创建重采样实例
audio_element_handle_t resampler = rsp_filter_init(&cfg);// 3. 动态修改输入参数(切换为24bit输入)
rsp_filter_change_src_info(resampler, 44100, 1, 24); // 44.1kHz单声道24bit
7. 约束与注意事项
- 位宽支持:
- 输入:8/16/24/32bit
- 输出:仅16bit
- 采样率限制:输入/输出采样率需在ESP-ADF支持的范围内(通常8kHz-48kHz)
- 实时性要求:高复杂度(
complexity=5)可能增加处理延迟,需测试实际性能 - 内存占用:选择
ESP_RSP_PREFER_MEM可减少INRAM使用,但会增加CPU负载
8. 应用场景示例
| 场景 | 推荐配置 |
|---|---|
| 语音通话降采样 | dest_rate=8kHz、complexity=1、prefer_flag=ESP_RSP_PREFER_CPU |
| 高保真音乐格式转换 | complexity=5、prefer_flag=ESP_RSP_PREFER_MEM |
| 实时音频流处理 | mode=RESAMPLE_DECODE_MODE、type=RESAMPLE_AUTO |
四、Sonic
1. Sonic组件核心功能
-
三维音频处理
- 变速不变调:调整播放速度(
speed) - 变调不变速:调整音高(
pitch) - 插值算法:平衡处理速度与音质
- 变速不变调:调整播放速度(
-
参数调节范围
参数 类型 示例值 说明 speedfloat 0.5(半速)~2.0(倍速) 1.0为原始速度 pitchfloat 0.5(低八度)~2.0(高八度) 1.0为原始音高 interpolationenum LINEAR/FIR 线性插值(快) vs FIR插值(准) -
典型应用场景
- 音频书籍变速播放
- 音乐音高修正
- 实时语音速度调整
-
特性对比
插值类型 处理速度 音质精度 适用场景 线性(Linear) ⚡️ 快 中等 实时处理/低功耗设备 FIR ⏳ 慢 高 后期制作/高保真需求
2. 调用示例
// 初始化
sonic_cfg_t cfg = DEFAULT_SONIC_CONFIG();
audio_element_handle_t sonic_processor = sonic_init(&cfg);// 设置为2倍速播放(保持原音高)
sonic_set_pitch_and_speed_info(sonic_processor, 1.0, 2.0);// 启用高精度FIR插值
sonic_set_interpolation_type(sonic_processor, SONIC_INTERPOLATION_FIR);
3. 注意事项
- 速度/音高参数建议范围:
0.5~2.0,极端值可能导致失真 - FIR插值会增加20-30%的CPU负载
- 处理立体声音频时两个声道会同步调整
4. API
1. 核心配置与初始化
| API/结构体 | 功能说明 | 关键参数/成员 |
|---|---|---|
sonic_init(sonic_cfg_t *) | 初始化Sonic音频处理器 | sonic_info(采样率/声道数)、out_rb_size(输出缓冲区大小) |
sonic_cfg_t | 配置结构体 | - task_stack(默认4KB)- task_prio(优先级5)- stack_in_ext(外部内存) |
DEFAULT_SONIC_CONFIG() | 生成默认配置宏 | 预定义环形缓冲区(2KB)、任务核心(1)、插值模式(线性) |
2. 参数动态设置
| API | 功能描述 | 参数范围/说明 |
|---|---|---|
sonic_set_info() | 设置输入流采样率和声道数 | rate(Hz)、ch(1/2) |
sonic_set_pitch_and_speed_info() | 设置音高和速度比例因子 | pitch[0.2,4.0]speed[0.1,8.0](0=保持原值) |
3. 处理模式控制
| 配置项 | 选项 | 性能影响 |
|---|---|---|
| 插值算法 ( resample_linear_interpolate) | 1:线性插值 | ⚡️ 处理速度快,适合实时场景 |
0:FIR插值 | 🎵 音质更优,CPU负载增加约30% |
4. 结构体
/*** @brief 结构体用于存储音频文件的信息和Sonic处理所需的配置参数。*/
struct sonic_info_t {int samplerate; /**< 音频文件的采样率(单位:Hz) */int channel; /**< 音频文件的通道数(单声道=1,立体声=2) */int resample_linear_interpolate; /**< 是否使用简单的线性插值。1表示使用,0表示不使用 */float pitch; /**< 音频文件的音高缩放因子。例如,0.3表示降低音高,1.3表示提高30%的音高 */float speed; /**< 音频文件的速度缩放因子。例如,0.3表示降低70%的速度,1.3表示提高30%的速度 */
};/*** @brief Sonic配置结构体,用于配置Sonic处理音频的参数。*/
struct sonic_cfg_t {struct sonic_info_t sonic_info; /**< Sonic处理所需的音频信息 */int out_rb_size; /**< 输出环形缓冲区的大小 */int task_stack; /**< 任务栈大小 */int task_core; /**< 任务运行的核心 */int task_prio; /**< 任务优先级 */bool stack_in_ext; /**< 是否尝试在外部内存中分配栈 */
};
5. 典型调用流程
// 1. 初始化配置(44.1kHz立体声)
sonic_cfg_t cfg = DEFAULT_SONIC_CONFIG();
cfg.sonic_info.samplerate = 44100;
cfg.sonic_info.channel = 2;
cfg.sonic_info.resample_linear_interpolate = 0; // 启用FIR插值// 2. 创建处理器实例
audio_element_handle_t sonic = sonic_init(&cfg);// 3. 设置为1.5倍速播放并升调20%
sonic_set_pitch_and_speed_info(sonic, 1.2f, 1.5f);// 4. 动态修改采样率(切换至16kHz单声道)
sonic_set_info(sonic, 16000, 1);
6. 实践
-
参数安全范围:
- 音高(
pitch):建议0.5~2.0(超出可能失真) - 速度(
speed):建议0.5~4.0(极端值影响流畅性)
- 音高(
-
资源消耗:
配置组合 CPU占用 适用场景 线性插值 + 中等变速 低 实时语音处理 FIR插值 + 高精度变调 高 音乐后期制作 -
内存管理:
- 启用
stack_in_ext可减少内部RAM占用 - 输出缓冲区(
out_rb_size)建议≥4KB处理高码率音频
- 启用