糖尿病数据分析:血压与年龄关系可视化
一、查看数据信息
import matplotlib.pyplot as plt
import pandas as pd
import matplotlib.font_manager as fm
from sklearn.feature_selection import SelectKBest,chi2
plt.rcParams['font.sans-serif']=['SimHei']
#数据探索
data = pd.read_excel(r"D:\Python\健康医学数据分析\第9章 医学实践综合案例源代码\案例4:糖尿病致病因素数据分析与可视化\diabetes.xlsx") # 读取文件
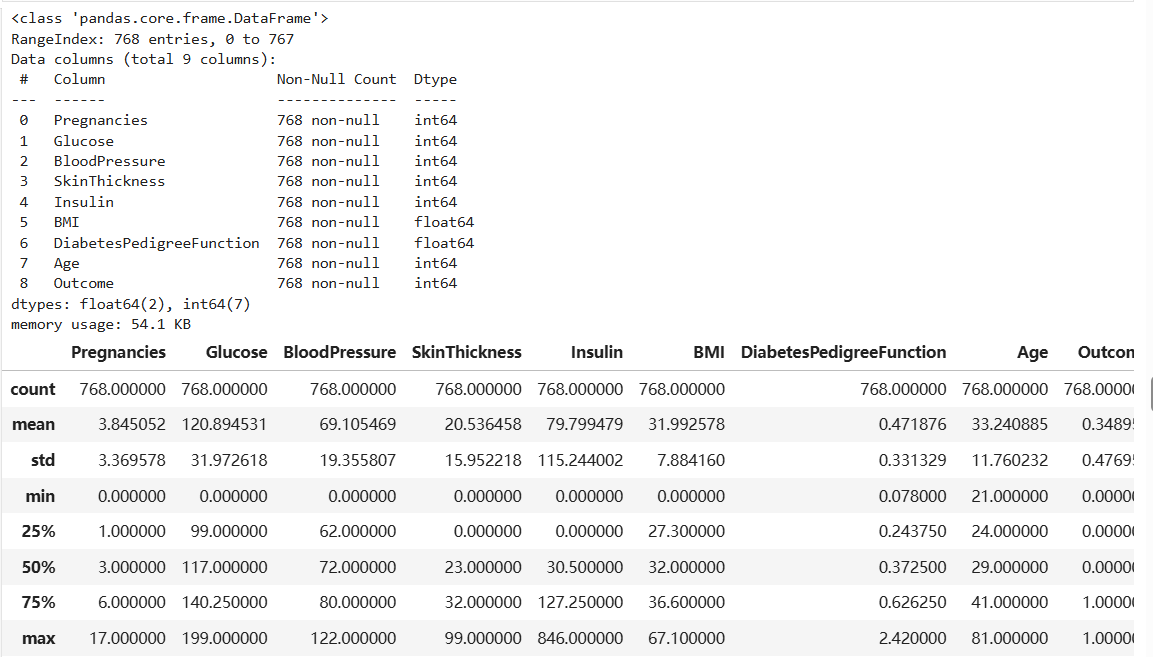
data.info() # 查看数据信息
data.describe()代码解析:
导入库:
matplotlib.pyplot:用于数据可视化pandas:用于数据处理和分析matplotlib.font_manager:用于管理字体sklearn.feature_selection:用于特征选择(虽然导入但未使用)
字体设置:
plt.rcParams['font.sans-serif']=['SimHei']:设置matplotlib使用黑体(SimHei)显示中文,避免中文乱码
数据加载:
- 使用
pd.read_excel()从指定路径读取Excel文件 - 文件路径指向一个糖尿病数据集(
diabetes.xlsx)
- 使用
数据探索:
data.info():显示数据的基本信息,包括:- 列名和数据类型
- 非空值数量
- 内存使用情况
data.describe():显示数据的统计摘要,包括:- 计数(count)
- 均值(mean)
- 标准差(std)
- 最小值(min)
- 四分位数(25%, 50%, 75%)
- 最大值(max)
运行结果:
二、 绘制箱线图查看异常值
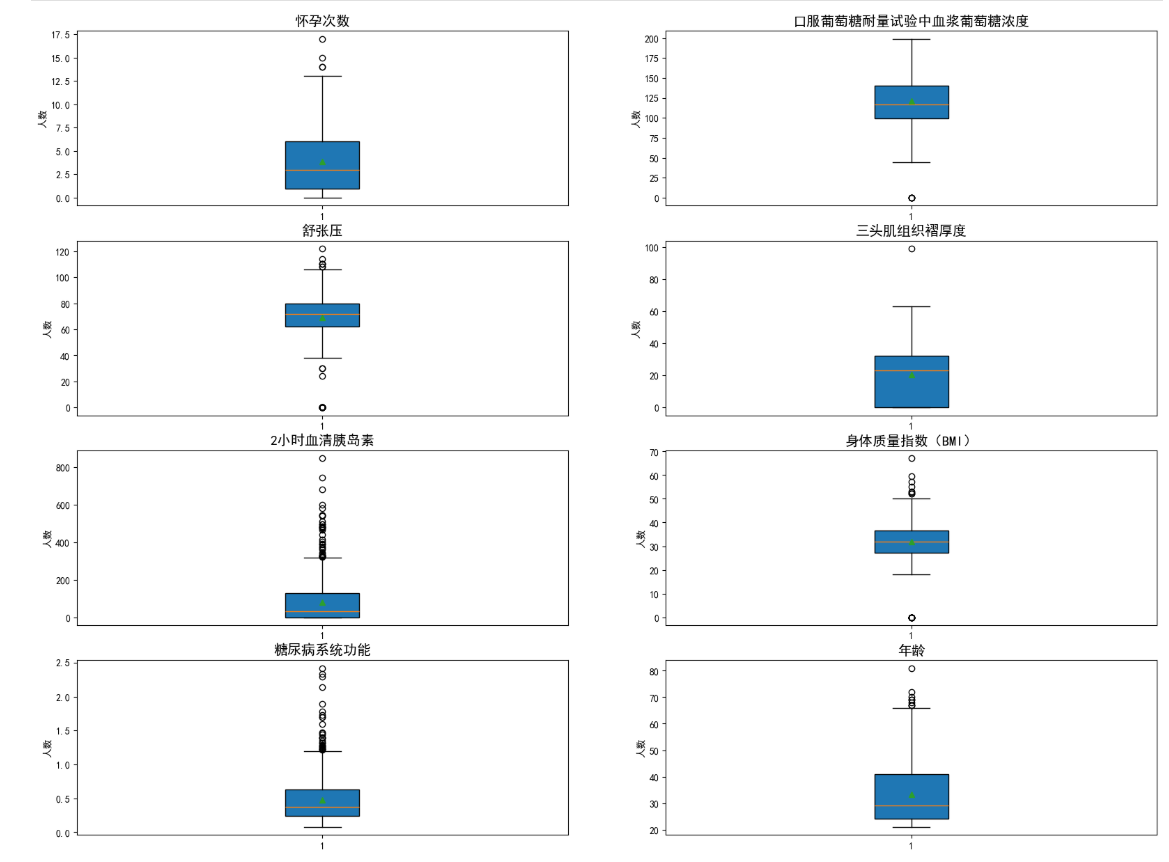
# 绘制箱线图查看异常值
fig = plt.figure(figsize=(20, 15))
plt.subplot(421)
plt.boxplot(data['Pregnancies'],showmeans=True,patch_artist='bule')
plt.title('怀孕次数',fontsize='x-large')
plt.ylabel('人数')plt.subplot(422)
plt.boxplot(data['Glucose'],showmeans=True,patch_artist='bule')
plt.title('口服葡萄糖耐量试验中血浆葡萄糖浓度',fontsize='x-large')
plt.ylabel('人数')plt.subplot(423)
plt.boxplot(data['BloodPressure'],showmeans=True,patch_artist='bule')
plt.title('舒张压',fontsize='x-large')
plt.ylabel('人数')plt.subplot(424)
plt.boxplot(data['SkinThickness'],showmeans=True,patch_artist='bule')
plt.title('三头肌组织褶厚度',fontsize='x-large')
plt.ylabel('人数')plt.subplot(425)
plt.boxplot(data['Insulin'],showmeans=True,patch_artist='bule')
plt.title('2小时血清胰岛素',fontsize='x-large')
plt.ylabel('人数')plt.subplot(426)
plt.boxplot(data['BMI'],showmeans=True,patch_artist='bule')
plt.title('身体质量指数(BMI)',fontsize='x-large')
plt.ylabel('人数')plt.subplot(427)
plt.boxplot(data['DiabetesPedigreeFunction'],showmeans=True,patch_artist='bule')
plt.title('糖尿病系统功能',fontsize='x-large')
plt.ylabel('人数')plt.subplot(428)
plt.boxplot(data['Age'],showmeans=True,patch_artist='bule')
plt.title('年龄',fontsize='x-large')
plt.ylabel('人数')
plt.show()创建画布:
fig = plt.figure(figsize=(20, 15)) # 设置画布大小(宽20英寸,高15英寸)- 通过
figsize调整整体图形大小,适合同时展示多个子图。
绘制子图:
- 使用
plt.subplot(421)到plt.subplot(428)将画布分为 4行2列共8个子图,每个子图对应一个特征:Pregnancies(怀孕次数)Glucose(葡萄糖浓度)BloodPressure(舒张压)SkinThickness(皮肤厚度)Insulin(胰岛素)BMI(身体质量指数)DiabetesPedigreeFunction(糖尿病遗传函数)Age(年龄)
箱线图参数:
plt.boxplot(data['列名'], showmeans=True, patch_artist='bule')showmeans=True:显示均值(绿色三角标记)。patch_artist='bule':试图设置箱体颜色为蓝色,但参数有误(正确应 为patch_artist=True, boxprops={'facecolor':'blue'})。
标题和标签:
每个子图添加中文标题(如 '怀孕次数')和纵轴标签('人数'),字体大小设为 x-large。
显示图形:
plt.show()运行结果:
三、将0值用平均值替换
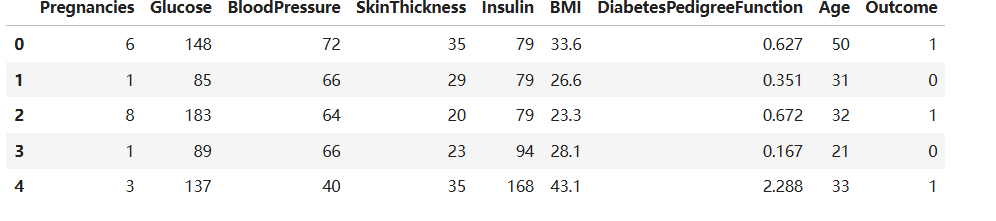
#将0值用平均值替换
for i in range(6):value = int(data.iloc[:,i].mean())data.iloc[:,i].replace(0,value=value,inplace=True)
data.head()遍历前 6 列数据:
for i in range(6): # 处理前6列(0到5列)- 假设数据集的前 6 列是数值型特征(如
Pregnancies,Glucose等)。
计算列的平均值:
value = int(data.iloc[:, i].mean()) # 取整后的列均值data.iloc[:, i]选择第i列的所有行。.mean()计算该列的平均值,并用int()取整。
替换 0 值为均值:
data.iloc[:, i].replace(0, value=value, inplace=True)- 将当前列中所有 0 值替换为
value(均值)。 inplace=True直接修改原数据,无需重新赋值。
查看处理后的数据:
data.head() # 显示前5行,验证替换结果运行结果:
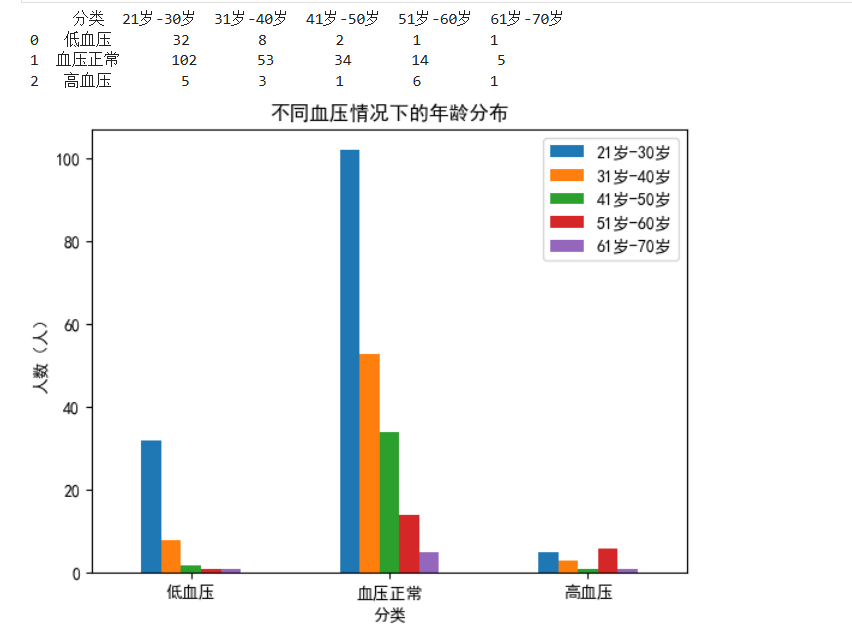
四、查看不同年龄段血压情况,多重柱状图—血压
#查看不同年龄段血压情况,多重柱状图—血压
row=0;num1=0;num2=0;num3=0;num20=0;num30=0;num40=0;num50=0;num60=0;num21=0;num31=0;num41=0;num51=0;num61=0;num22=0;num32=0;num42=0;num52=0;num62=0
for i in data.loc[:,"Outcome"]:if i==0:continuerow+=1else:if data.loc[row,"BloodPressure"]<=60:num1+=1if 20<data.loc[row,"Age"]<=30:num20+=1elif 30<data.loc[row,"Age"]<=40:num30+=1elif 40<data.loc[row,"Age"]<=50:num40+=1elif 50<data.loc[row,"Age"]<=60:num50+=1else:num60+=1elif 60<data.loc[row,"BloodPressure"]<=90:num2+=1if 20<data.loc[row,"Age"]<=30:num21+=1elif 30<data.loc[row,"Age"]<=40:num31+=1elif 40<data.loc[row,"Age"]<=50:num41+=1elif 50<data.loc[row,"Age"]<=60:num51+=1else:num61+=1else:num3+=1if 20<data.loc[row,"Age"]<=30:num22+=1elif 30<data.loc[row,"Age"]<=40:num32+=1elif 40<data.loc[row,"Age"]<=50:num42+=1elif 50<data.loc[row,"Age"]<=60:num52+=1else:num62+=1row+=1
dataplot = pd.DataFrame({'分类': ['低血压','血压正常','高血压'],'21岁-30岁':[num20,num21,num22],'31岁-40岁':[num30,num31,num32],'41岁-50岁':[num40,num41,num42],'51岁-60岁':[num50,num51,num52],'61岁-70岁':[num60,num61,num62]})
print(dataplot)
dataplot.plot(x='分类', kind='bar')
plt.xticks(rotation=360)
plt.ylabel('人数(人)', fontproperties='simhei')
plt.title("不同血压情况下的年龄分布")
plt.legend()
plt.show()- 目标:统计糖尿病患者中,不同血压范围(低血压、正常血压、高血压)在各年龄段的人数。
- 血压分组:
- 低血压(≤60 mmHg)
- 血压正常(60-90 mmHg)
- 高血压(>90 mmHg)
- 年龄分组:
- 21-30岁
- 31-40岁
- 41-50岁
- 51-60岁
- 61-70岁
- 实现方式:
- 通过循环遍历每一行数据,手动统计每个血压和年龄组合的人数。
- 使用多个变量(如
num20,num21等)记录计数结果。 - 最后将结果整理成表格并绘制柱状图。
优化代码:
# 筛选糖尿病患者
diabetic_data = data[data['Outcome'] == 1].copy()# 创建血压分组
bp_bins = [0, 60, 90, float('inf')]
bp_labels = ['低血压', '血压正常', '高血压']
diabetic_data['血压分组'] = pd.cut(diabetic_data['BloodPressure'], bins=bp_bins, labels=bp_labels)# 创建年龄分组
age_bins = [20, 30, 40, 50, 60, 70]
age_labels = ['21-30岁', '31-40岁', '41-50岁', '51-60岁', '61-70岁']
diabetic_data['年龄分组'] = pd.cut(diabetic_data['Age'], bins=age_bins, labels=age_labels)# 创建交叉表
cross_tab = pd.crosstab(diabetic_data['血压分组'], diabetic_data['年龄分组'])
print(cross_tab)# 绘制分组柱状图
ax = cross_tab.plot(kind='bar', figsize=(12, 8), rot=0)
plt.title("糖尿病患者血压与年龄分布", fontsize=14)
plt.ylabel("人数(人)")
plt.xlabel("血压分类")
plt.legend(title="年龄段")# 添加数据标签
for p in ax.patches:height = p.get_height()if height > 0: # 只添加非零值的标签ax.annotate(f"{int(height)}", (p.get_x() + p.get_width() / 2, height), ha='center', va='bottom', xytext=(0, 3),textcoords='offset points')plt.tight_layout()
plt.show()代码分析:
简化数据处理:
- 使用
pd.cut()函数代替手动分类,更高效且不易出错 - 直接筛选糖尿病患者 (
data[data['Outcome'] == 1])
- 使用
改进分组逻辑:
- 血压分组:
- 低血压 (≤60 mmHg)
- 血压正常 (60-90 mmHg)
- 高血压 (>90 mmHg)
- 年龄分组:
- 21-30岁
- 31-40岁
- 41-50岁
- 51-60岁
- 61-70岁
- 血压分组:
高效计数:
- 使用
pd.crosstab()创建交叉表,替代手动计数变量 - 自动处理分组间的计数关系
- 使用
可视化优化:
- 添加数据标签,提高图表可读性
- 优化图例标题 ("年龄段")
- 调整图表尺寸和布局
- 添加图表标题和轴标签
错误修复:
- 原代码中
continue语句导致索引错误的问题已解决 - 正确处理边界值 (如 60, 61 的处理)
- 原代码中
运行结果:
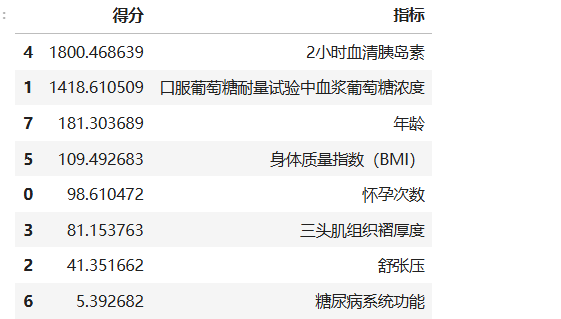
五、找出对患糖尿病影响最大的因素
# 找出对患糖尿病影响最大的因素
x = data.iloc[:,0:8]
y = data.iloc[:,8:9]
bestfeatures = SelectKBest(score_func=chi2,k = len(x.columns))
fit = bestfeatures.fit(x,y)
df_scores = pd.DataFrame(fit.scores_)
df_columns = pd.DataFrame(['怀孕次数','口服葡萄糖耐量试验中血浆葡萄糖浓度','舒张压','三头肌组织褶厚度','2小时血清胰岛素','身体质量指数(BMI)','糖尿病系统功能','年龄'])
df_feature_scores = pd.concat([df_scores,df_columns],axis = 1)
df_feature_scores.columns = ["得分","指标"]
df_sort =df_feature_scores.sort_values(by = "得分",ascending= False)
df_sort数据准备:
x = data.iloc[:, 0:8] # 选取前8列作为特征(怀孕次数、血糖等)
y = data.iloc[:, 8:9] # 选取第9列(Outcome)作为目标变量x:包含所有特征(自变量)。y:包含标签(因变量,是否患糖尿病)。
卡方检验:
bestfeatures = SelectKBest(score_func=chi2, k=len(x.columns))
fit = bestfeatures.fit(x, y)SelectKBest:选择得分最高的k个特征。score_func=chi2:使用卡方检验计算特征重要性(适用于分类问题)。k=len(x.columns):评估所有特征,不进行筛选。
整理结果:
df_scores = pd.DataFrame(fit.scores_) # 卡方检验得分
df_columns = pd.DataFrame(['怀孕次数', '葡萄糖浓度', '舒张压', '皮肤厚度', '胰岛素', 'BMI', '糖尿病遗传函数', '年龄'])
df_feature_scores = pd.concat([df_scores, df_columns], axis=1)
df_feature_scores.columns = ["得分", "指标"]排序输出:
df_sort = df_feature_scores.sort_values(by="得分", ascending=False)- 按得分从高到低排序,得分越高表示特征对糖尿病的影响越大。
卡方检验的原理
- 用途:检验分类变量之间的独立性(此处是特征与糖尿病结果的关联性)。
- 得分计算:卡方统计量越高,特征与目标变量的相关性越强。
- 适用条件:特征必须是非负的(如计数、频率、二值化数据)。如果数据包含负数或连续值,需先进行分箱(离散化)。
运行结果: