IO复用(多路转接)
IO复用(多路转接)


五种IO模型
-
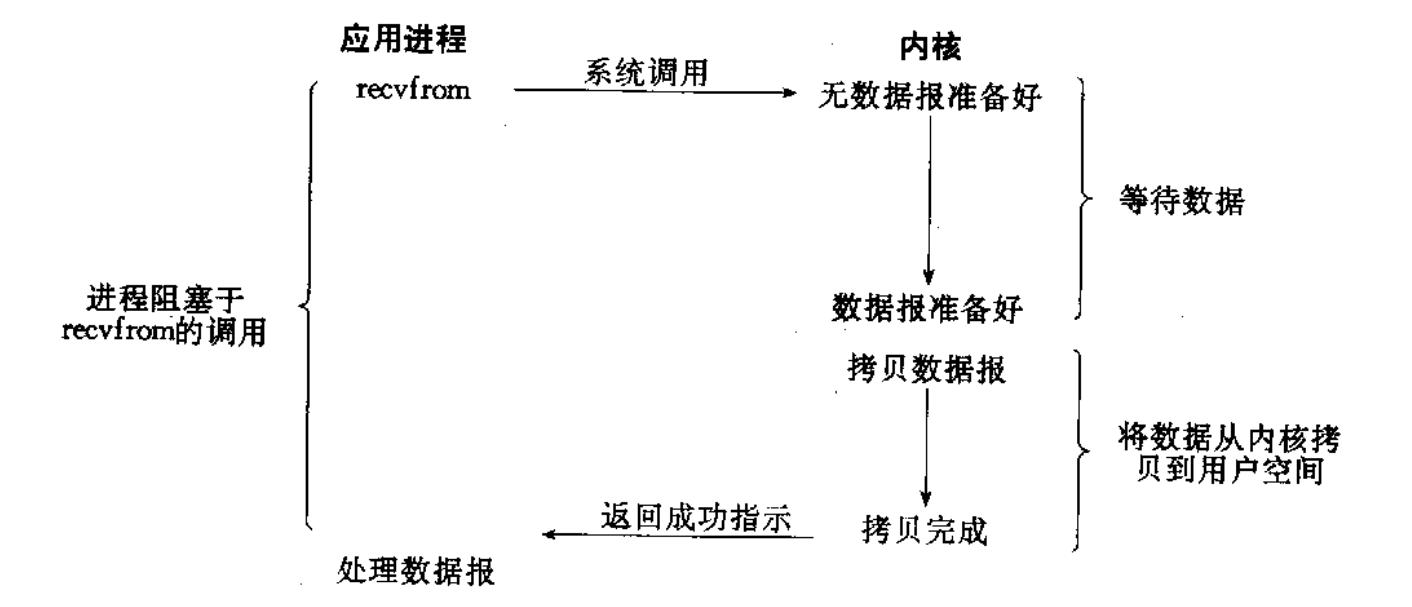
阻塞IO: 在内核将数据准备好之前, 系统调用会一直等待. 所有的套接字, 默认都是阻塞方式.
-
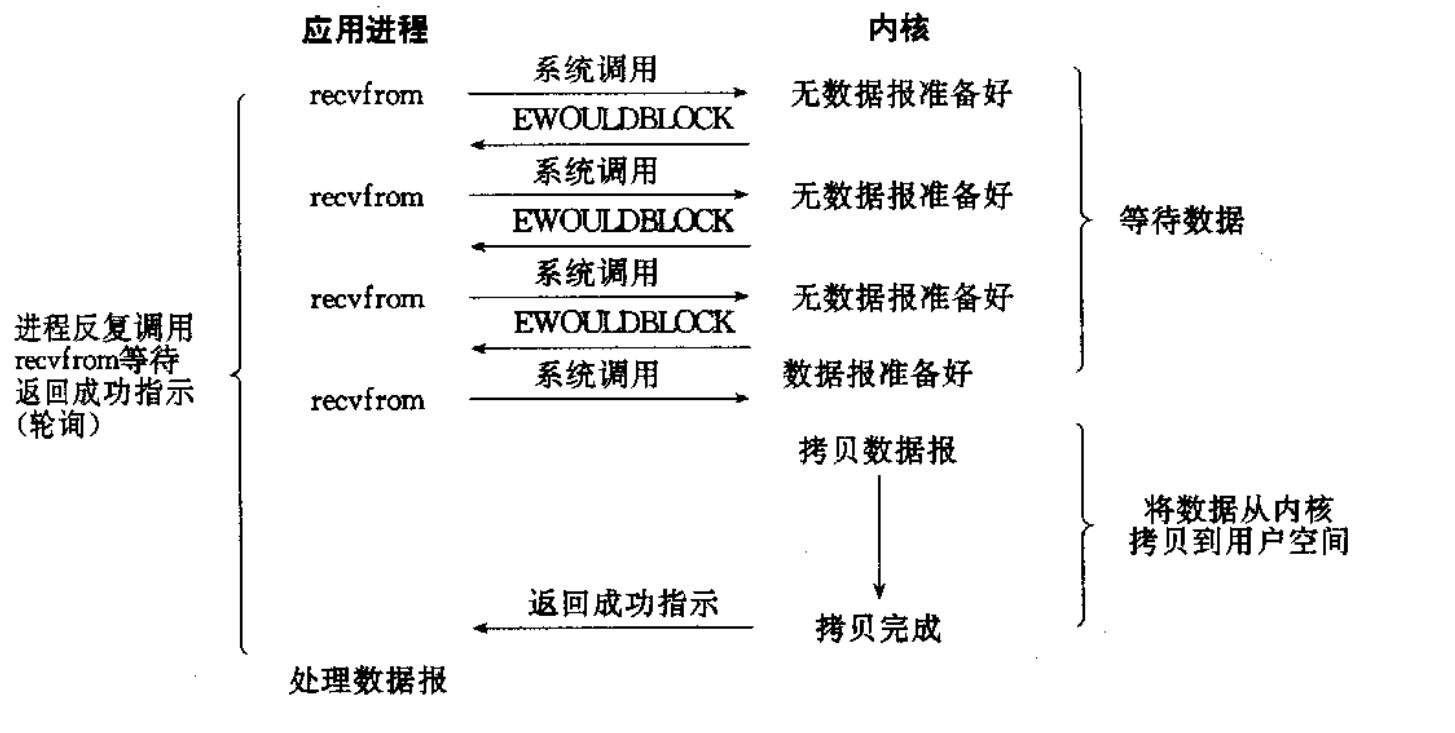
非阻塞IO: 非阻塞 IO: 如果内核还未将数据准备好, 系统调用仍然会直接返回, 并且返回EWOULDBLOCK 错误码.
-
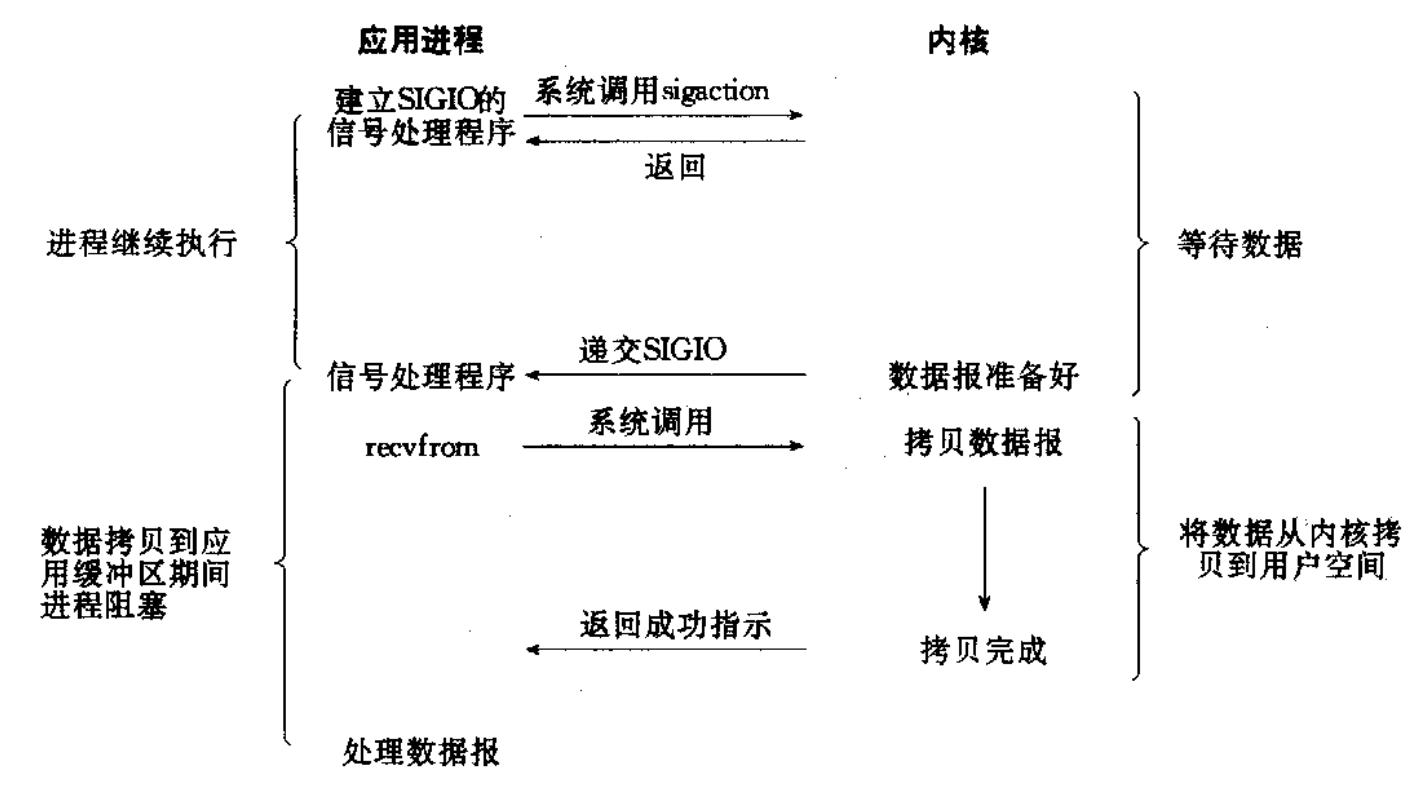
信号驱动IO: 内核将数据准备好的时候, 使用 SIGIO 信号通知应用程序进行 IO操作
-
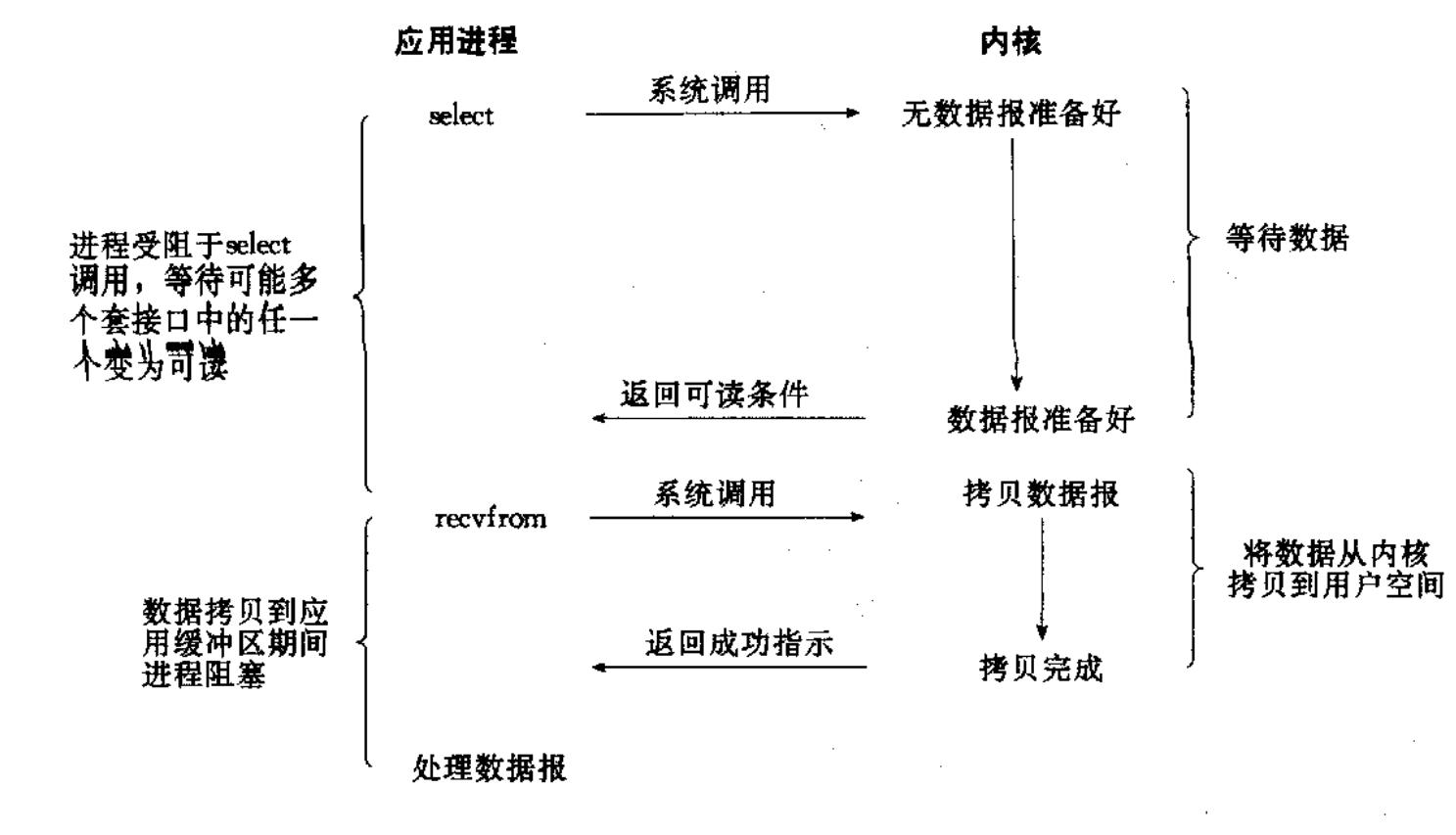
多路转接:: 虽然从流程图上看起来和阻塞 IO 类似. 实际上最核心在于 IO 多路转接能够同时等待多个文件描述符的就绪状态.
-
异步 IO: 由内核在数据拷贝完成时, 通知应用程序(而信号驱动是告诉应用程序何时可以开始拷贝数据).
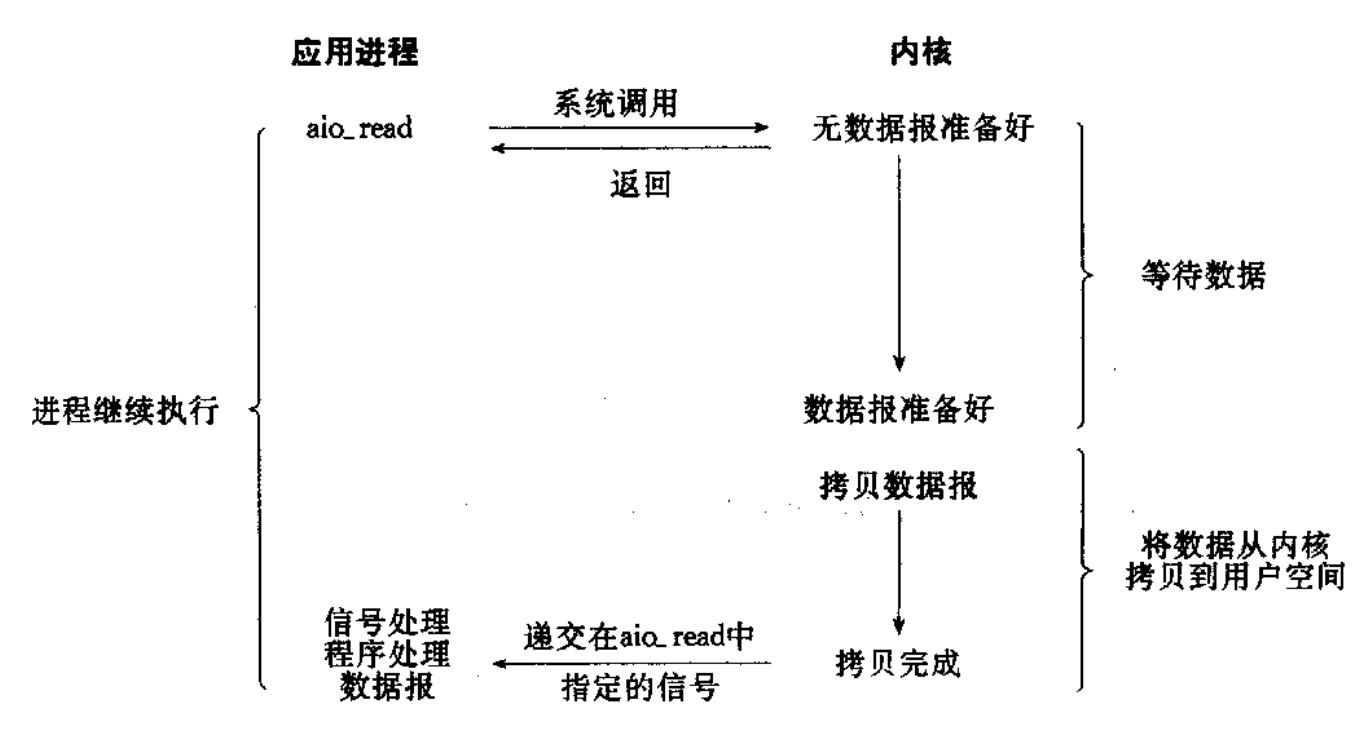
总结
IO的核心都是
等待 + IO, 日常中等待的时间远大于IO, 所以如何处理等待的时间就是我们处理IO需要考虑的问题。
如何将文件描述符设置成为非阻塞
由于Linux下一切皆文件, 所以我们这里考虑的是文件 + 特殊文件 + 套接字等等,由于对于文件描述符来说, 在Linux操作系统中通过struct file维护文件的基本的信息。默认情况下, 所有的文件都是设置成阻塞的。
文件属性操作的函数调用
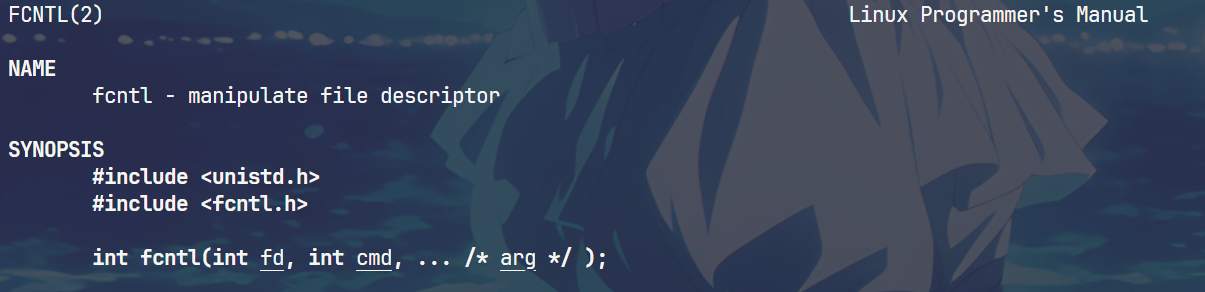
)
// 当然也可以设置成为宏
void setNoBlock(int fd)
{// 获取文件当前状态int fl = ::fcntl(fd,F_GETFL);if(fl < 0){perror("fcntl获取失败");return;}// 在原来的基础上将文件属性加上NO_BLOCKfcntl(fd,F_SETFL, fl | O_NONBLOCK); }
多路转接
本文主要还是讨论,如何使用多路转接的方式。那么我们如何更加直观的理解多路转接的思想呢?
场景:
如果我们使用TCP建立Web服务, 当我们的多个用户来到后, 会产生很多的通信套接字, 这个时候如果我们是
同步处理的服务,我们有很多种思路:
- 多线程 : 每个线程维护一个通信套接字,当通信结束后, 线程被线程池回收。但是缺点也很明显, 通信套接字通过三次握手建立成功后, 不一定获取,可能导致出现大量的不活跃的连接,这个时候,就会显著的浪费线程的资源。
- IO复用 : Linux内核帮助实现了IO复用模型,包括
poll epoll select,实现方式不同,但是思路都一样,帮助我们管理一群非阻塞文件描述符, 类似于养鱼,当我们的操作系统或不断地遍历判断每个文件描述符的状态,就和我们的养鱼人会不断检查鱼的情况,当某个文件描述符读写就绪后,也就是鱼长大了,就会通知用户层,可以处理了。
上面我们是通俗的介绍了多路复用的原理,但是Linux实现多路复用的接口也有三种select poll epoll
select
#include <sys/select.h>int select(int nfds, fd_set *readfds, fd_set *writefds,fd_set *exceptfds, struct timeval *timeout);void FD_CLR(int fd, fd_set *set);
int FD_ISSET(int fd, fd_set *set);
void FD_SET(int fd, fd_set *set);
void FD_ZERO(fd_set *set);
-
nfds : 是需要管理的文件描述符的个数 + 1
-
rdset,wrset,exset 分别对应于需要检测的可读文件描述符的集合,可写文件描述符的集 合及异常文件描述符的集合;
-
timeout : 表示select的等待时间
fd_set是位图的类型, 类似于C++里面的std::bitmap, 通过一个bit表示文件描述组的状态。 后面的四个函数都是帮助我们操作fd_set这种类型。
缺点明显:
-
每次调用 select, 都需要手动设置 fd 集合, 从接口使用角度来说也非常不便. • 每次调用 select,都需要把 fd 集合从用户态拷贝到内核态,这个开销在 fd 很多时会很大
-
同时每次调用 select 都需要在内核遍历传递进来的所有 fd,这个开销在 fd多时也很大
-
select 支持的文件描述符数量太小.
poll
struct pollfd {int fd; /* file descriptor */short events; /* requested events */short revents; /* returned events */
};int poll(struct pollfd *fds, nfds_t nfds, int timeout);
不同于 select 使用三个位图来表示三个 fdset 的方式,poll 使用一个 pollfd 的指针实现.
pollfd 结构包含了要监视的 event 和发生的 event,不再使用 select“参数-值”传
递的方式. 接口使用比 select 更方便. • poll 并没有最大数量限制 (但是数量过大后性能也是会下降)
poll 的缺点 :
poll 中监听的文件描述符数目增多时和select函数一样poll 返回后,需要轮询 pollfd 来获取就绪的描述符. • 每次调用 poll 都需要把大量的 pollfd 结构从用户态拷贝到内核中. 同时连接的大量客户端在一时刻可能只有很少的处于就绪状态, 因此随着监视
的描述符数量的增长, 其效率也会线性下降.
epoll
为了处理大量句柄而进行改进的poll
epoll很多时候叫做epoll模型, 提供了一组构建epoll模型的函数, 面相对象, 而不是和select和poll一样更多的是面向过程。
// 创建一个epoll模型
int epoll_create(int size)int epoll_ctl(int epfd, int op,int fd,struct epoll_event* event);epoll_ctl提供操作epoll模型的各种参数
-
op : 操作类型
- EPOLL_CTL_ADD : 注册新的fd
- EPOLL_CTL_MOD : 修改fd的事件
- EPOLL_CTL_DEL : 删除fd
-
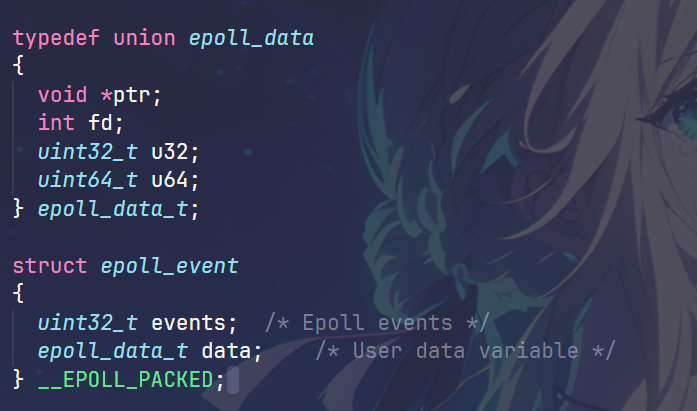
struct epoll_event
events的几个宏(我们主要关心读和写)
- EPOLLIN
- EPOLLOUT
epoll时间就绪
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
基于epoll模型实现的reactor反应堆模式(推广,epoll的使用场景)
reactor反应堆模式
总结select poll epoll的优缺点
-
select : select适合简单的应用场景(当我们需要管理的文件描述符比较少的时候), select是一个简单的不错的选择, 但是select频繁的将数据从内核到用户之间频繁拷贝, 当涉及到的描述符多了之后, 就会显著降低效率
-
poll : poll在select的基础之上进行了改进, 只能说在设计上更加的方便的, 但是轮询和用户内核之间的拷贝问题没有得到根本的解决
-
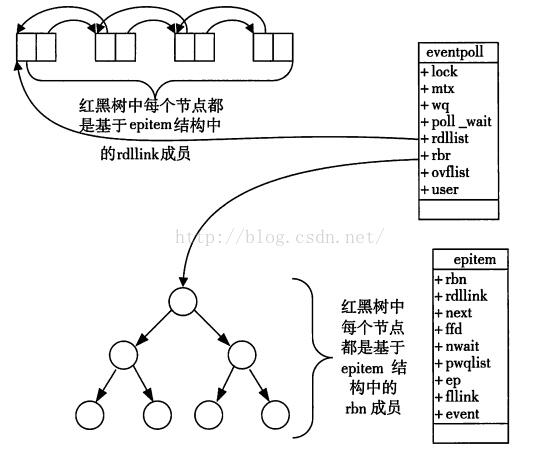
epoll : epoll模型是基于红黑树和嵌入式链表的设计的高效数据结构模型, 通过设置回调函数以及红黑树存储的机制, 使得通知用户层和拷贝进入内核的开销都得到了显著的降低(避免很多无用的拷贝)