从零开始学习大模型之文本数据处理
从零开始学习大模型之文本数据处理
- 0 总体概述
- 1 理解词嵌入
- 2 文本分词
- 3 将词元转换成词元ID
- 4 引入特殊上下文词元
- 5 BPE
- 6 使用滑动窗口进行数据采样
- 7 创建词元嵌入
- 8 编码单词位置信息
- 9 附录
- 9.1 正则表达式(Regular expression)
- 9.1.1 字符串匹配
- 9.1.2 字符串查找
- 9.1.3 字符串替换
- 9.1.4 字符串分割
- 9.1.5 字符串捕获
0 总体概述
数据处理是大模型中的第一步,其对后面的模型预测准确率起到关键的作用。
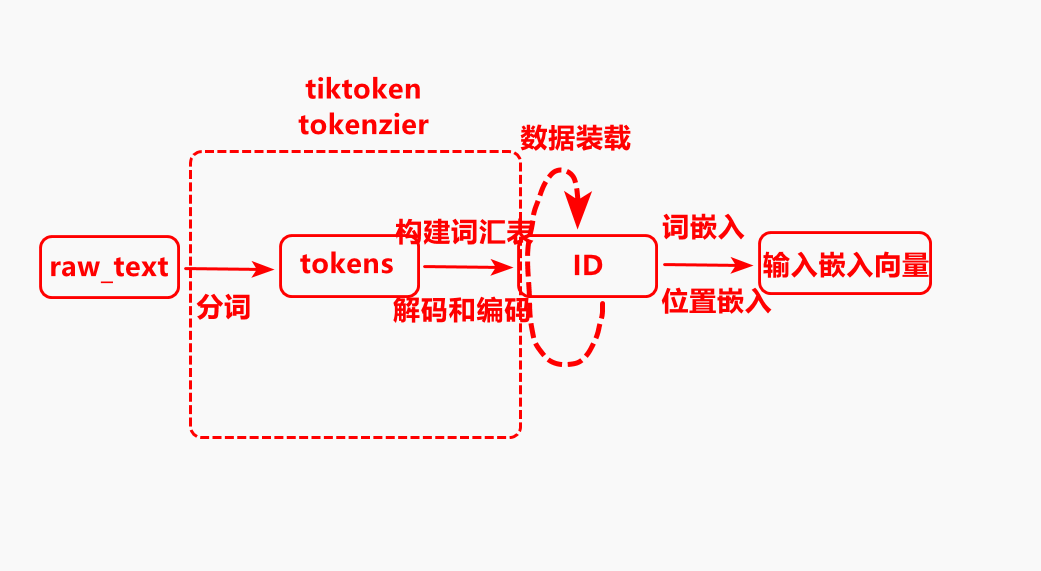
首先对输入的文本进行分词,分成每个token,然后依据词汇表对token进行ID编码,最后将ID进行词嵌入成词向量,加上位置向量形成一个完成的向量,最后通过数据加载和采样构建输入输出数据对。
1 理解词嵌入
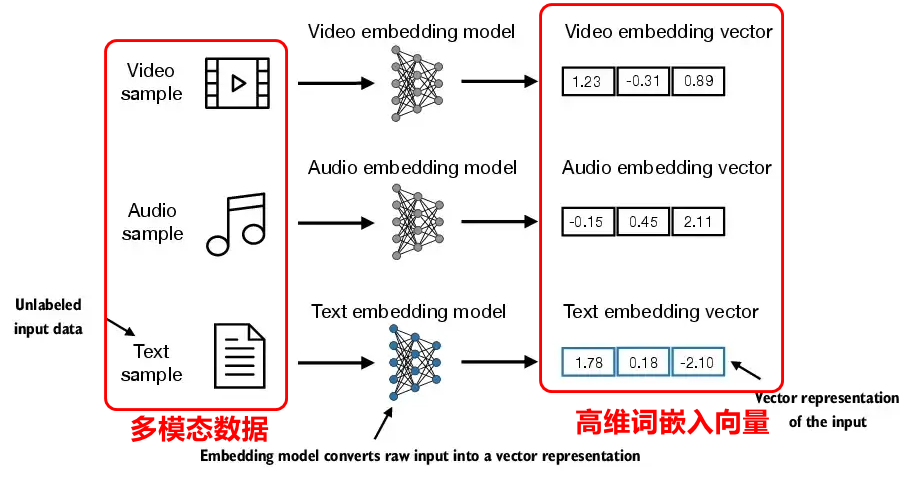
词嵌入是将文本单词编码成一个高维向量。词嵌入的目的是为了让计算机更好的理解人类语言,由于在计算机的世界是只有数字,而文字是人类的语言,词嵌入是建立两者的桥梁,方便后续计算机处理。
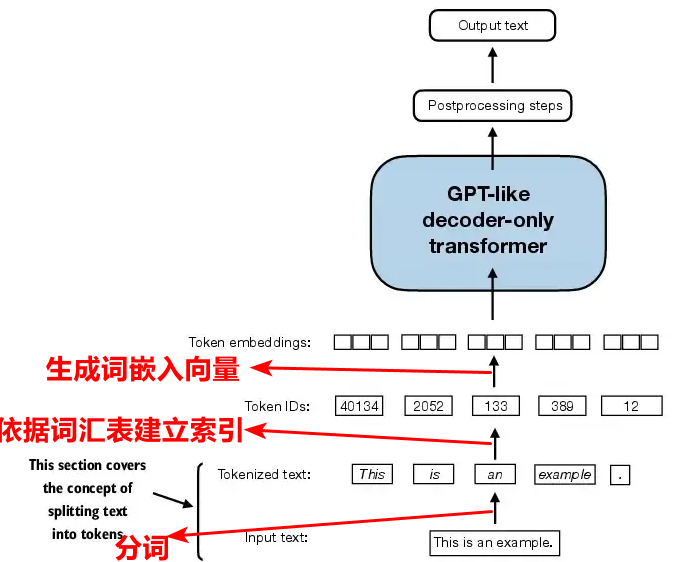
词嵌入具体的操作步骤是,首先将长文本序列分割成每个token(词元),依据建立的词汇表索引(行是每个token,列是每个token对应的ID),将每个token索引出一个ID唯一标识这个token,然后对每个ID进行向量生成,具体生成的方式先是以正态分布函数随机生成,后续是通过梯度下降算法进行反向传播更新。
2 文本分词
文本分词是将长序列文本分成单个token(也就是每个词元)。文本分词的目的是为了让计算机更好理解人类语言。下面会示范一个列子如何对文本分词,以Edith Wharton的短篇小说所有文本为分词对象。在进行文本分词前,有必要先了解python中的正则表达式的相关操作,具体详细的细节可以参考官网:https://docs.python.org/zh-cn/3/howto/regex.html,也可以看我的附录。
import re
with open("the-verdict.txt","r",encoding="utf-8") as f:raw_text = f.read()
print("Total number of character :",len(raw_text))
print(raw_text[0:99])
# text = "Hello, world.This ,is a test."
# result = re.split(r'(\s)',text)
# print(result)
preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', raw_text)
preprocessed =[item.strip() for item in preprocessed if item.strip()] #返回一个新字符串,去除原字符串开头和结尾的空白字符(默认包括空格、制表符\t、换行符\n等)
3 将词元转换成词元ID
将最第2步分词后的词元(token)转换成词元(token)ID。建立词元与ID之间的关系是为了,能够双向索引,即能够通过词元找到ID编号,同时也能通过ID编号反向索引词元,这通常对应于翻译模块的编码和解码过程。将词元转成词元ID的具体做法是首先对整个文本序列进行分词,即上面文本分词过程,将分词后得到的token词元按照字母顺序,并删除重复token首先建立词汇表,即
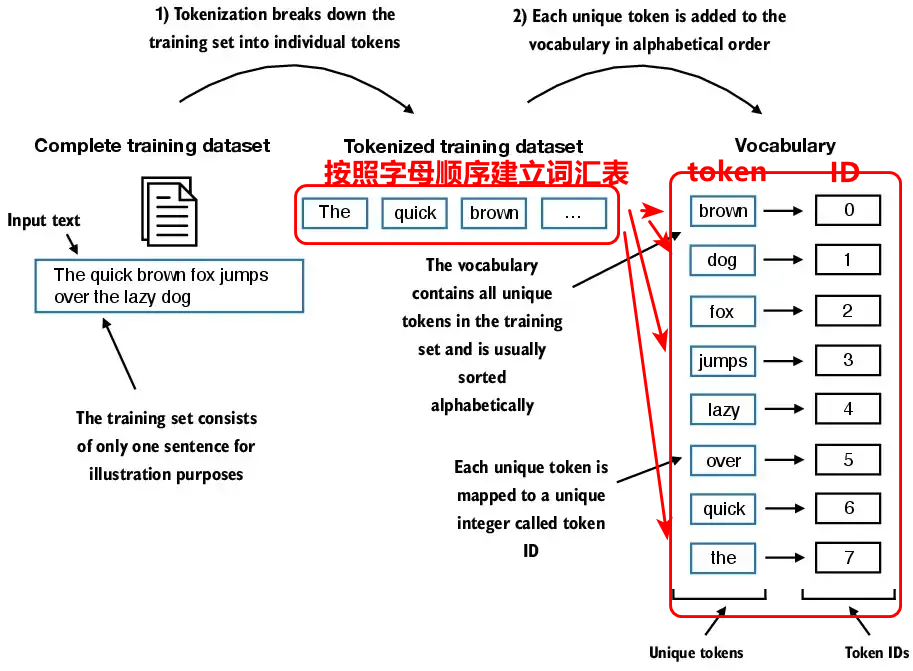
然后依据文本切割顺序,对每个token查找词汇表进行转成ID编号,每个ID编号唯一标识一个token。如上图中的the是文本切割顺序的第一个,但是在词汇表依据字母顺序排序是第八个,所以the这个token的编号就为7,依次类推就能对文本切割顺序后的所有token进行编号。相关代码如下:
all_words = sorted(set(preprocessed)) #去除文本序列中重复的token,并按照token字母的顺序进行升序排列
vocab = {token:integer for integer,token in enumerate(all_words)} #枚举去重复且升序排列的token,遍历索引和token,返回token:索引ID的键值对构建词汇表
class SimpleTokenizerV1: #自己写的简单文本分词器,能够实现双向,即能实现token到ID编号的双向映射def __init__(self, vocab):self.str_to_int = vocabself.int_to_str = {i:s for s,i in vocab.items()}def encode(self, text):preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text)preprocessed = [item.strip() for item in preprocessed if item.strip()]ids = [self.str_to_int[s] for s in preprocessed]return idsdef decode(self, ids):text = " ".join([self.int_to_str[i] for i in ids])# Replace spaces before the specified punctuationstext = re.sub(r'\s+([,.?!"()\'])', r'\1', text)return text
tokenizer = SimpleTokenizerV1(vocab)text = """"It's the last he painted, you know," Mrs. Gisburn said with pardonable pride."""
ids = tokenizer.encode(text)
print(ids)
tokenizer.decode(ids)
tokenizer.decode(tokenizer.encode(text))
4 引入特殊上下文词元
引入的特殊上下文词元分别是’<|unk|>‘,以及’<|endoftext|>‘,其中’<|unk|>‘指的是未知词元,即输入中含有改词元,但是之前训练的词汇表中不含有该词元;其中’<|endoftext|>‘是用来标识不同来源的上下文词元分界。通过引入特殊的上下文词元,能够增强模型的能力,从而更准确的识别输入。通常是将’<|unk|>‘以及’<|endoftext|>'加在词汇表的后面。
import re
with open("the-verdict.txt","r",encoding="utf-8") as f:raw_text = f.read()
preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', raw_text)
preprocessed =[item.strip() for item in preprocessed if item.strip()] #返回一个新字符串,去除原字符串开头和结尾的空白字符(默认包括空格、制表符\t、换行符\n等)
all_words = sorted(set(preprocessed)) #去除文本序列中重复的token,并按照token字母的顺序进行升序排列
all_words.extend(["<|unk|>","<|endoftext|>"]) #增加特殊上下文词元
vocab = {token:integer for integer,token in enumerate(all_words)} #枚举去重复且升序排列的token,遍历索引和token,返回token:索引ID的键值对构建词汇表
class SimpleTokenizerV2:#BPE,增加了特殊上下文字符的字节双向编码输入输出def __init__(self, vocab):self.str_to_int = vocabself.int_to_str = { i:s for s,i in vocab.items()}def encode(self, text):preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text)preprocessed = [item.strip() for item in preprocessed if item.strip()]preprocessed = [#如果输入的toKen在词汇表中找不到,就替换该单词为<|unk|>item if item in self.str_to_int else "<|unk|>" for item in preprocessed]ids = [self.str_to_int[s] for s in preprocessed]return idsdef decode(self, ids):text = " ".join([self.int_to_str[i] for i in ids])# Replace spaces before the specified punctuationstext = re.sub(r'\s+([,.:;?!"()\'])', r'\1', text)return text
5 BPE
BPE是BytePairEncode,即字节双向编码,是建立token词元与ID编号的双向映射关系,其中的映射关系是在词汇表,既能够通过token词元索引出其ID编号,同时也能通过ID编号索引出词元,上述SimpleTokenizerV2是简化版本的BPE,事实上,python中集成的BPE远比这个更复杂,在简化版本的字节对编码BPE中,我们对于未知的token词元是用进行替换,但是事实上在python中集成的基于BPE算法的tiktoken库中,对于未知的词元token,通常是将单词分解成更小的词单元甚至单个字符,对于频繁出现的字符合并为字词元,同时迭代构建词汇表,所以在这里词汇表是动态更新,比如BPE首先将a,b字符添加到词汇表中,然后将频繁同时出现的字符组合如ab合并成字词ab,再重新添加到词汇表中,从而能够处理词汇表之外的单词
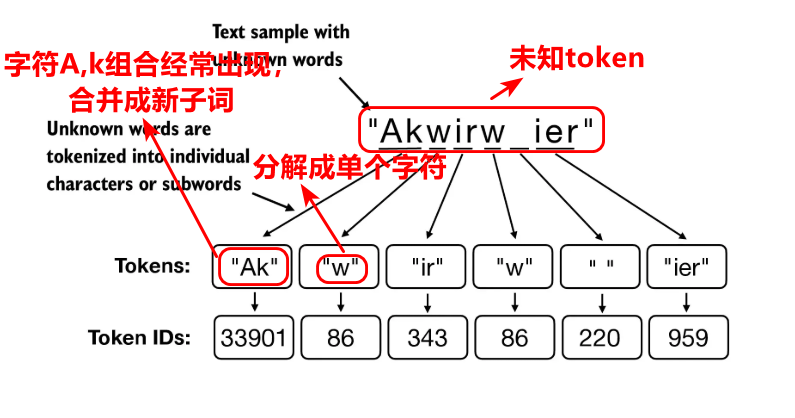
在python中,其集成了tiktoken库,高效的实现了BPE算法。在后续的环节我们直接使用python中集成的字节对编码BPE,即tiktoken库,而不使用简化版本字节对编码SimpleTokenizerV2,事实上tiktoken库封装了文本分词,词元编号,特殊上下文,以及双向编码encode和decode。
则上面相关代码可替换为:
import re
import tiktoken
with open("the-verdict.txt","r",encoding="utf-8") as f:raw_text = f.read()
tokenizer = tiktoken.get_encoding("gpt2")
intergers = tokenizer.encode(raw_text,allowed_special={"<|endoftext|>"})
string = tokenizer.decode(integers)
6 使用滑动窗口进行数据采样
数据可迭代对象
torch.utils.data DataSet,DataLoader
张量
1.构建输入输出数据集Dataset
2.数据加载器生成可迭代对象DataLoader
3.迭代生成的输入输出
# 迭代器学习
import re
import tiktoken
import torch
from torch.utils.data import Dataset, DataLoaderwith open("the-verdict.txt", "r", encoding="utf-8") as f:raw_text = f.read()
tokenizer = tiktoken.get_encoding("gpt2")# string = tokenizer.decode(intergers)
# 重写数据集 初始化中构建输入输出数据集对,同时重写__len__方法,以及__getitem__方法,其中__len__方法是获取输入输出的的长度,__getitem__方法是按照索引获取输入输出目标对
class TextDataset(Dataset): # 自己定义一个数据集要继承torch中的数据集类Datasetdef __init__(self, raw_text, tokenizer, max_length, stride):# 对原生raw_text使用分词器tokenizer进行分词产生编号all_tokens_ids = tokenizer.encode(raw_text, allowed_special={"<|endoftext|>"})# 定义输入-输出目标训练对self.input_ids = []self.output_ids = []# 通过滑动窗口的方法,所以会有滑动距离stride,以及窗口的长度max_length,最大滑行距离为len(all_token_ids)-max_length-1for i in range(0, len(all_tokens_ids) - max_length, stride):self.input_ids.append(torch.tensor(all_tokens_ids[i:i + max_length])) # 第i次滑动,每次滑动的窗口增加到输入中,并转换成张量self.output_ids.append(torch.tensor(all_tokens_ids[i + 1:i + max_length + 1])) # 第i次输出滑动是输入滑动再右移一位,并转换成张量def __len__(self): # 重写获取输入输出的长度获取return len(self.input_ids)def __getitem__(self, idx): # 重写索引每项的方法return self.input_ids[idx], self.output_ids[idx]# 获取输入输出对象
dataset = TextDataset(raw_text, tokenizer, max_length=4, stride=1)
# 尝试打印,输入输出的第一个训练对象
# 数据加载
dataloader = DataLoader(dataset, batch_size=4, shuffle=True, drop_last=True, num_workers=0)
# 迭代器获取数据
data_iter = iter(dataloader)
print(next(data_iter))
7 创建词元嵌入
词元嵌入是将token词元的ID编号(经过了数据格式转换的ID格式,batch_size*max_length)转换成高维度的嵌入向量。词元嵌入的目的是通过增加辨析两个token的维度,维度越高,就越容易区分两个token。词元嵌入的具体过程是首先生成嵌入层权重矩阵,该矩阵的行数等于词汇表的长度,列数等于嵌入向量的维数,每一行对应一个ID编号,该编号对应的是词汇表中的词元编号,如此一来便生成了每个词元的嵌入向量。特别说明的是,该嵌入层权重可以通过训练,进行反向传播生成更新。
max_length=4
torch.manual_seed(123)
embedding_layer = torch.nn.Embedding(vocab_size=50257, output_dim=256)
print(embedding_layer(input_ids))
8*4*256(8个batch_size)
8 编码单词位置信息
编码位置信息是对每个token增加位置信息。由于相同的词元ID总是生成相同的嵌入向量,也就是词元的含义与位置无关,显然这是不正确的,比如苹果手机放在苹果上这句话,两个都有苹果两个词,但是前面的苹果和后面的苹果含义是不同的,或者说我爱你和你爱我这句话含义不同,增加位置信息能够感知词元的位置和顺序,结合自注意力机制能够更好的理解上下文的含义,这是因为自注意力机制本身与位置无关,所以为了更好理解上下文语义,添加位置信息是非常有必要。
pos_embedding_layer = torch.nn.Embedding(max_length=4, output_dim=256)
pos_embeddings = pos_embedding_layer(torch.arange(max_length))
#在四个维度上,对每个id的256维度分别置为0,1,2,3. 4*256
input_embeddings = token_embeddings + pos_embeddings#输入嵌入=位置嵌入+词元嵌入9 附录
9.1 正则表达式(Regular expression)
正则表达式是python中对字符串进行操作的一个库,主要分为匹配,替换,查找,分割,提取。使用正则表达式能够很方便的对字符串进行操作。正则表达式常用的是通过建立一个匹配规则,通常包含元字符(并不匹配本身,比如“+”并不匹配+,而是表是前面的字符串重复n次)。因此了解常见的匹配函数和元字符的含义很有必要。
| 元字符 | 含义 |
|---|---|
| ^ | 匹配字符串开头 |
| $ | 匹配字符串的结尾 |
| [] | 匹配方括号内的任意一个字符 |
| + | 匹配前面的字符一次或多次 |
| * | 匹配前面字符0次或多次 |
| {m} | 匹配前面字符m次 |
| {m,n} | 匹配前面字符m次到n次 |
| \w | 匹配单词,相当于[a-zA-Z0-9_] |
| \s | 匹配空白字符 |
| \d | 匹配数字,等同[0-9] |
| () | 用于开始和结束,相当于^ $ |
9.1.1 字符串匹配
import re# 验证邮箱格式
email = "test@example.com"
pattern = r'^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$'if re.match(pattern, email):print("邮箱格式正确")
else:print("邮箱格式错误")
9.1.2 字符串查找
import re# 找出所有数字
text = "我今年25岁,身高175厘米"
pattern = r'\d+'numbers = re.findall(pattern, text)
print("找到的数字:", numbers) # 输出: ['25', '175']
9.1.3 字符串替换
import re# 将手机号中间4位替换为*
phone = "13812345678"
pattern = r'(\d{3})(\d{4})(\d{4})'masked_phone = re.sub(pattern, r'\1****\3', phone)
print("脱敏后的手机号:", masked_phone) # 输出: 138****5678
9.1.4 字符串分割
import re# 按非字母字符分割字符串
text = "Hello,world!Python@Programming"
pattern = r'[^a-zA-Z]+'words = re.split(pattern, text)
print("分割后的单词:", words) # 输出: ['Hello', 'world', 'Python', 'Programming']
9.1.5 字符串捕获
import re# 从URL中提取域名
url = "https://www.example.com/path/to/page"
pattern = r'https?://([^/]+)'match = re.search(pattern, url)
if match:domain = match.group(1)print("提取的域名:", domain) # 输出: www.example.com