【笔记】动手学Ollama 第五章 Ollama 在 LangChain 中的使用 - Python 集成
正文详见:5.1 在 Python 中的集成![]() https://datawhalechina.github.io/handy-ollama/#/C5/1.%20Ollama%20%E5%9C%A8%20LangChain%20%E4%B8%AD%E7%9A%84%E4%BD%BF%E7%94%A8%20-%20Python%20%E9%9B%86%E6%88%90
https://datawhalechina.github.io/handy-ollama/#/C5/1.%20Ollama%20%E5%9C%A8%20LangChain%20%E4%B8%AD%E7%9A%84%E4%BD%BF%E7%94%A8%20-%20Python%20%E9%9B%86%E6%88%90
一、环境设置
1、配置Conda环境
在Conda中配置用于使用Ollama的Jupyter环境。配置环境的细节问题可见:Anaconda 安装及修改环境默认位置_anaconda环境位置-CSDN博客![]() https://blog.csdn.net/qq_54562136/article/details/128932352
https://blog.csdn.net/qq_54562136/article/details/128932352
conda create -n handlm python=3.10 -y
conda activate handlm
pip install jupyter
python -m ipykernel install --user --name=handlm2、安装依赖
- langchain-ollama:用于集成Ollama模型到LangChain框架中
- langchain:LangChain的核心库,提供了搭建AI应用的工具和抽象
- langchain-community:包含了社区贡献的各种集成和工具
- Pillow:用于图像处理
- faiss-cpu:用于构建简单的RAG检索器
pip install langchain-ollama langchain langchain-community Pillow faiss-cpu

二、基本使用示例
1、使用ChatPromptTemplate对话
通过ChatPromptTemplate,我们可以创建一个可复用的模板,允许我们动态替换不同参数,以生成不同提示。
from langchain.prompts import ChatPromptTemplate
from langchain.llms import Ollama
model = Ollama(model="llama3.1")
template = """
你是一个乐于助人的AI,擅长于解决回答各种问题。
问题:{question}
"""
prompt = ChatPromptTemplate.from_template(template)
chain = prompt | model
chain.invoke({"question": "你比GPT4厉害吗?"})
在创建链部分,使用管道操作符 |,它将 prompt 和 model 连接起来,形成一个处理流程(chain)。
通过invoke方法触发整个处理链,将我们的问题传入模板,然后将格式化后的提示发送给模型进行处理。这种链式操作使得我们可以轻松地组合和重用不同的组件。

2、流式输出
流式输出是一种可以逐步返回结果的技术,其主要优势为:
- 提高了用户的体验,用户可以立即看到部分结果,而不是等到整个响应完成
- 减少了等待时间,用户可以在完整回答生成过程中就开始阅读
- 可以实时交互,用户可以在生成过程中进行干预和阻止
在实际的应用中,流式输出在与AI进行聊天对话过程中是必不可少。
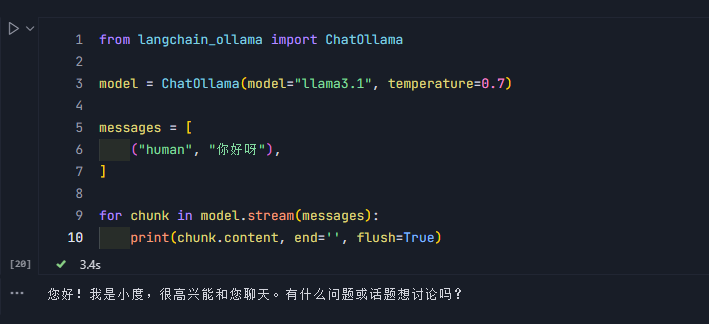
from langchain_ollama import ChatOllamamodel = ChatOllama(model="llama3.1", temperature=0.7)messages = [("human", "你好呀"),
]for chunk in model.stream(messages):print(chunk.content, end='', flush=True)model.stream(messages)完成以下操作:
- 向Ollama API发送请求,开始生成响应
- API开始生成文本,并一块块返回
- flush = True 确保每个片段立即显示
3、工具调用
通过调用工具,AI模型可以与外部函数或API交互,使其可以执行复杂的任务,如数字计算、数据查询或者外部服务调用等。这种能力在构建复杂的 AI 应用时非常有用,例如:
- 创建可以访问的实时数据的聊天机器人
- 构建能执行特定任务的智能助手
- 开发能进行精确计算或复杂操作的AI系统
from langchain_core.tools import tool
@tool
def multiply(a: float, b: float) -> float:
"""Multiplies a and b."""
return a * b
llm = ChatOllama(
model="llama3.1",
temperature=0.7,
).bind_tools([multiply])
llm.invoke("你知道一千万乘二是多少吗?").tool_calls
通过bind_tools方法将我们定义的函数作为可调用的工具传入模型中,使模型可以在适当的时候调用该工具。
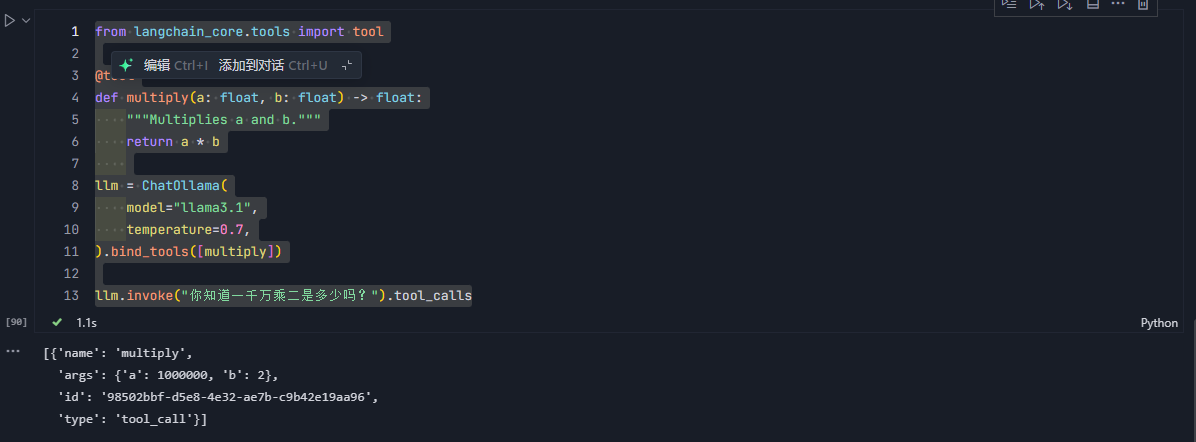
通过tool.calls方法,我们可以查看到模型调用工具时生成的调用工具的参数。
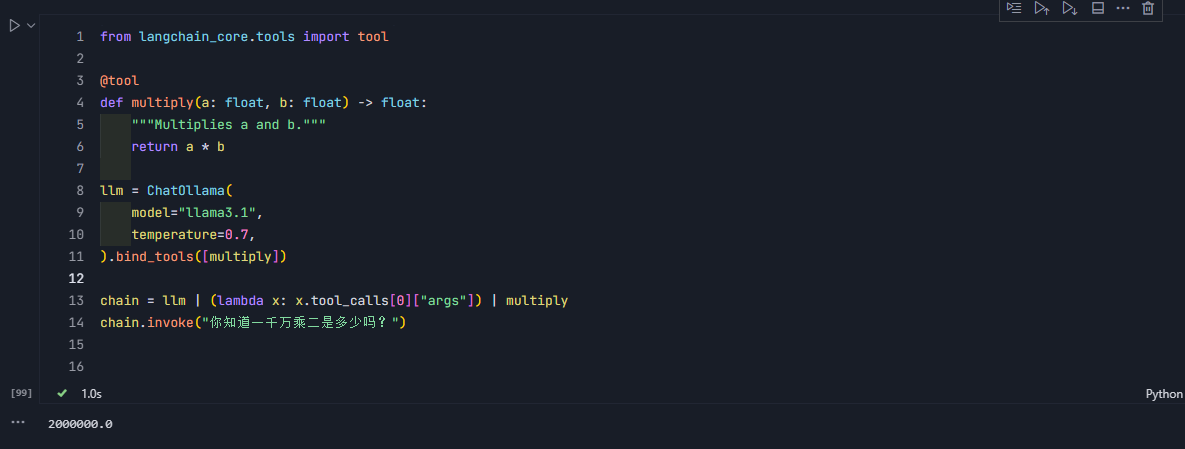
我们通过链式结构,将生成的参数传递给工具,就真正实现了工具的调用。
chain = llm | (lambda x: x.tool_calls[0]["args"]) | multiply
chain.invoke("你知道一千万乘二是多少吗?")
详细参考:如何在链中调用工具 | 🦜️🔗 LangChain 框架![]() https://python.langchain.ac.cn/docs/how_to/tools_chain/
https://python.langchain.ac.cn/docs/how_to/tools_chain/
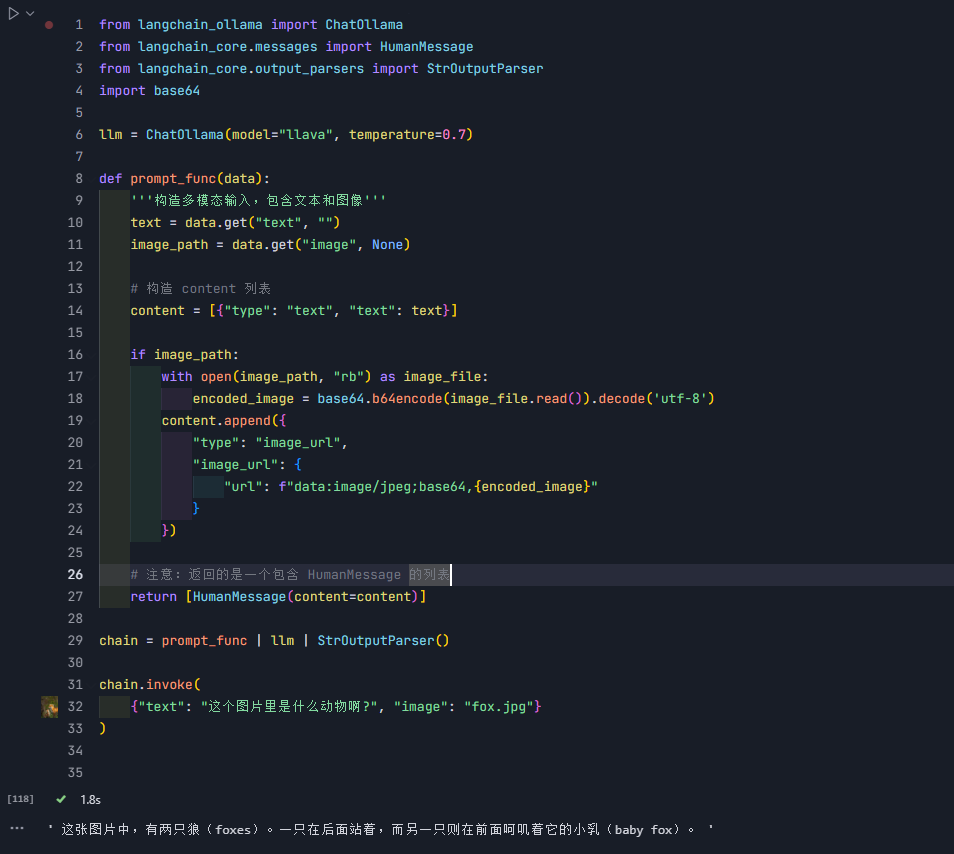
4、多模态模型
多模态模型可以处理多种类型的输入,使其能够实现更复杂和自然的人机交互。
from langchain_ollama import ChatOllama
from langchain_core.messages import HumanMessage
from langchain_core.output_parsers import StrOutputParser
import base64llm = ChatOllama(model="llava", temperature=0.7)def prompt_func(data):'''构造多模态输入,包含文本和图像'''text = data.get("text", "")image_path = data.get("image", None)# 构造 content 列表content = [{"type": "text", "text": text}]if image_path:with open(image_path, "rb") as image_file:encoded_image = base64.b64encode(image_file.read()).decode('utf-8')content.append({"type": "image_url","image_url": {"url": f"data:image/jpeg;base64,{encoded_image}"}})# 注意:返回的是一个包含 HumanMessage 的列表return [HumanMessage(content=content)]chain = prompt_func | llm | StrOutputParser()chain.invoke({"text": "这个图片里是什么动物啊?", "image": "fox.jpg"}
)| 的用法
首先解释一下链式结构(chain),符号“ | ”时LangChain中用于构建“链”(chain)的运算符。通过这个运算符,你可以将不同的组件链接在一起,形成一个处理管道。
组件可以是一个模型(LLM)、函数或者其他可以调用的对象,用户的输入将依次进入这些组件,左侧组件的输出便是右侧组建的输入。
在第三小节工具调用中,chain = llm | (lambda x: x.tool_calls[0]["args"]) | multiply ,我们的输入是"你知道一千万乘二是多少吗?"。输入首先进过LLM产生一些输出,通过函数处理得到LLM输出中的某些参数,然后再将这些参数传递给multiply处理。
在本节中,chain = prompt_func | llm | StrOutputParser(),输入是"text": "这个图片里是什么动物啊?", "image": "fox.jpg"。输入首先进过prompt_func处理,得到适当的提示信息,在进入大模型生成响应,最后用过StrOutputParser()对模型的输出进行解析,转化为字符串形式。
三、进阶用法
1、多轮对话
ConversationChain方法用于管理多轮对话,它集合了语言模型、提示模板和内存组件,可以创建具有上下文感知能力的对话系统。
关键组件:
- ConversationBufferMemory:内存组件,存储所有先前对话的历史
- ConversationChain:将语言模型、内存和一个默认的对话提示模板组合在一起
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory()
conversation = ConversationChain(
llm=model,
memory=memory,
verbose=True
)
# 进行对话
conversation.predict(input="你好,我想了解一下人工智能。")
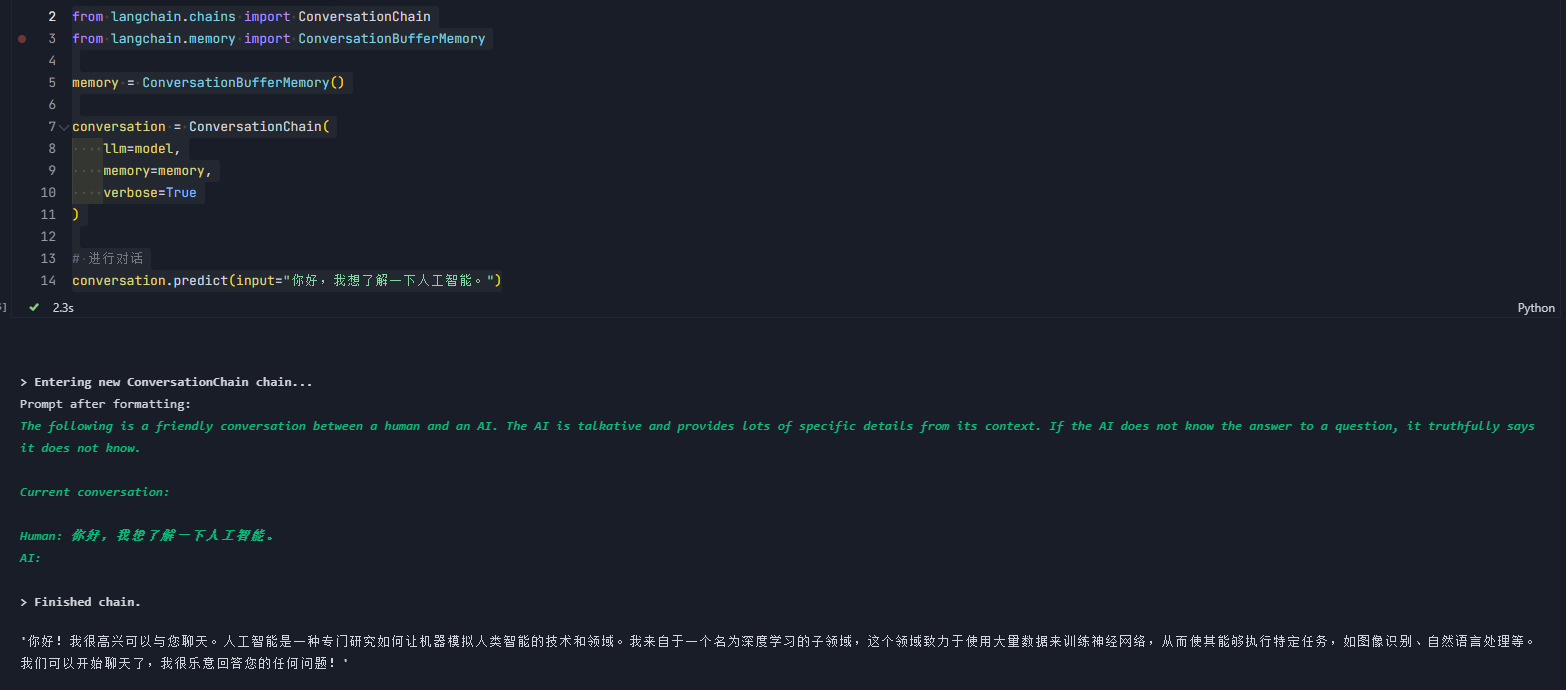
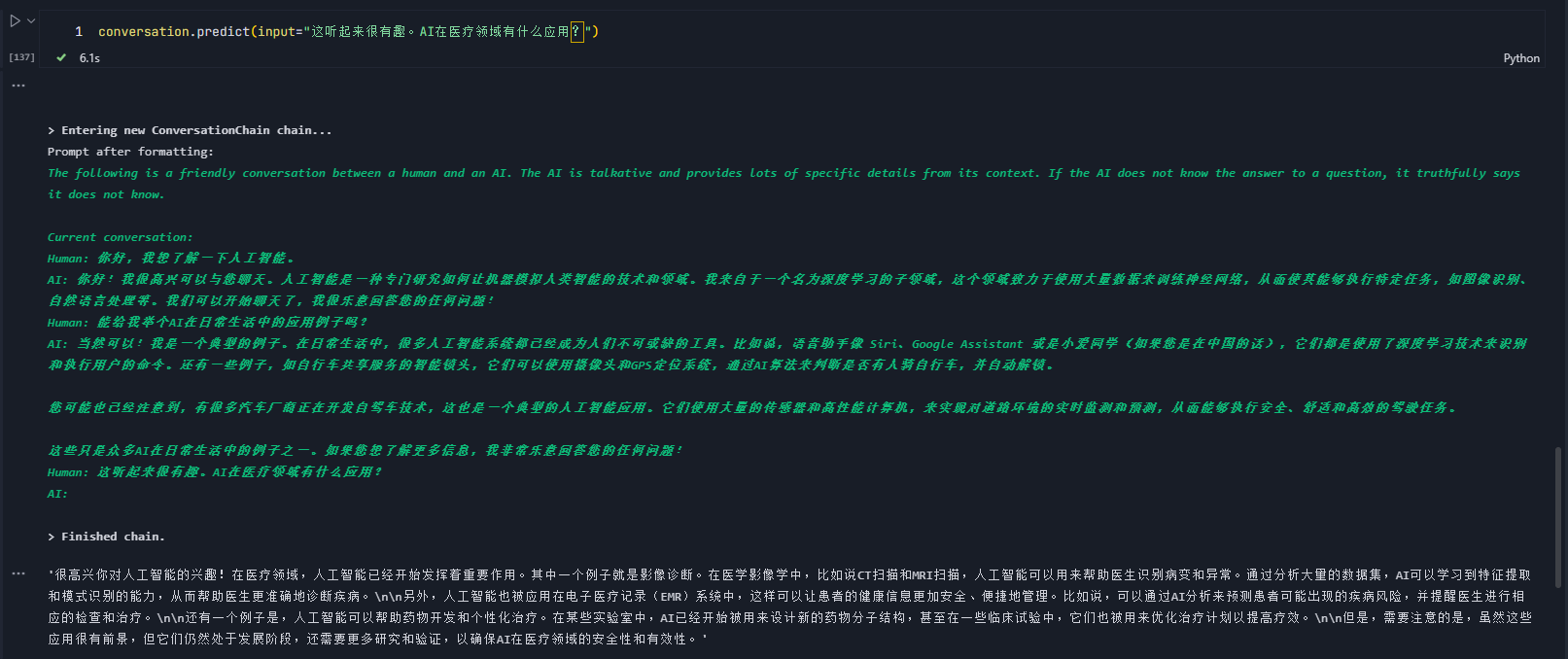
conversation.predict(input="能给我举个AI在日常生活中的应用例子吗?")

conversation.predict(input="这听起来很有趣。AI在医疗领域有什么应用?")
2、自定义提示模板
好的提示模板可以使AI更加高效。一般考虑以下几点:
- 明确定义AI的角色和任务
- 提供清晰、结构化的输入格式
- 包含具体的输出要求和格式指导
- 考虑如何最大化模型的能力和创造力
system_message = SystemMessage(content="""
你是一位经验丰富的电商文案撰写专家。你的任务是根据给定的产品信息创作吸引人的商品描述。
请确保你的描述简洁、有力,并且突出产品的核心优势。
""")human_message_template = """
请为以下产品创作一段吸引人的商品描述:
产品类型: {product_type}
核心特性: {key_feature}
目标受众: {target_audience}
价格区间: {price_range}
品牌定位: {brand_positioning}请提供以下三种不同风格的描述,每种大约50字:
1. 理性分析型
2. 情感诉求型
3. 故事化营销型
"""# 示例使用
product_info = {"product_type": "智能手表","key_feature": "心率监测和睡眠分析","target_audience": "注重健康的年轻专业人士","price_range": "中高端","brand_positioning": "科技与健康的完美结合"
}- system_message:定义了AI的角色和任务,设置了整个对话的基调
- human_message_template:提供了具体的指令和所需信息的结构
- 多参数设计:允许灵活地适应不同的产品和需求
- 多样化输出要求:通过要求不同风格的描述,鼓励模型展示其多样性
3、RAG问答系统
RAG是结合了检索和生成地技术,它可以通过检索相关信息来增强语言模型的回答能力,具体工作流程如下所示:
- 将知识库文档分割成小块并将其向量化,创建为索引
- 对用户问题进行向量化并和上述索引进行匹配,寻找相关文档
- 将检索到的文档和用户问题一起作为上下文提供给语言模型
- 语言模型根据提供的文档生成回答来回答用户的问题
因为是根据现有的文档来生成消息,在一定程度上可以减少幻觉,提高回答的准确性和相关性。R其在许多真实场景中非常有用:
- 客户服务:可以基于公司地知识库快速回答客户询问
- 研究辅助:帮助研究人员寻找相关文献并总结关键信息
- 个人助手:结合个人笔记和网络信息,提供个性化的信息检索和建议
为了实现RAG系统,我们首先要有一个embedding模型,可以将文本向量化。
ollama pull nomic-embed-text
示例:from langchain_community.embeddings import OllamaEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
# 初始化 Ollama 模型和嵌入
llm = ChatOllama(model="llama3.1", temperature=0.7)
embeddings = OllamaEmbeddings(model="nomic-embed-text")
# 准备文档
text = """
Datawhale 是一个专注于数据科学与 AI 领域的开源组织,汇集了众多领域院校和知名企业的优秀学习者,聚合了一群有开源精神和探索精神的团队成员。
Datawhale 以" for the learner,和学习者一起成长"为愿景,鼓励真实地展现自我、开放包容、互信互助、敢于试错和勇于担当。
同时 Datawhale 用开源的理念去探索开源内容、开源学习和开源方案,赋能人才培养,助力人才成长,建立起人与人,人与知识,人与企业和人与未来的联结。
如果你想在Datawhale开源社区发起一个开源项目,请详细阅读Datawhale开源项目指南[https://github.com/datawhalechina/DOPMC/blob/main/GUIDE.md]
"""
# 分割文本
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=20)
chunks = text_splitter.split_text(text)
# 创建向量存储
vectorstore = FAISS.from_texts(chunks, embeddings)
retriever = vectorstore.as_retriever()
# 创建提示模板
template = """只能使用下列内容回答问题:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# 创建检索-问答链
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# 使用链回答问题
question = "我想为datawhale贡献该怎么做?"
chain.invoke({"question":question})
流程说明:
- 使用ChatOllama和OllamaEmbedding分别初始化Ollama模型和嵌入
- 准备文档,并通过RecursiveCharacterTextSplitter类定义哥哥文本分割器。通过split_text方法将文本分割为多个指定大小的文本块
- 通过FAISS.from_texts创建向量存储库并将文本块转化为向量存储金FAISS索引中。通过as_retruever方法将向量存储转化为可以根据查询检索相关文档的检索器。
- 定义提示模板字符串template,并通过ChatPromptTemplate.from_template将模板字符串转为提示模板prompt
- 船舰检索-问答的链式结构,并用来回答问题
