yolo_RK3588系列(三)
一、前言
接着上一篇,大概讲解了使用在主机上使用yolov训练好了自己的模型,接下来讲解如何将模型部署到RK3588上。
二、格式转换
2.1 转化成.onnx格式
我们使用yolo训练出来的权重文件格式是.pt格式,但是部署到rk3588上所需要的格式是.rknn格式,这里的话就需要进行格式转换,但是.pt格式使用工具的话没有直接转成.rknn格式的工具,这里只有先将其转化成通用的权重格式.onnx格式。
yolo官方提供了export.py文件用于进行权重格式的转换,下面是运行权重文件的入口参数,这个和训练文件大同小异,我们只需要关注“--data” “--weights”,'--imgsz',其他的参数按照自己的需要进行修改。
最重要的'--include'里面的default=['onnx']。
def parse_opt():parser = argparse.ArgumentParser()parser.add_argument('--data', type=str, default=ROOT / './data/finger.yaml', help='dataset.yaml path')parser.add_argument('--weights', nargs='+', type=str, default=ROOT / './runs/train/exp10/weights/yolov5s_finger_2480.pt', help='model.pt path(s)')parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[480, 480], help='image (h, w)')parser.add_argument('--batch-size', type=int, default=1, help='batch size')parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')parser.add_argument('--half', action='store_true', help='FP16 half-precision export')parser.add_argument('--inplace', action='store_true', help='set YOLOv5 Detect() inplace=True')parser.add_argument('--keras', action='store_true', help='TF: use Keras')parser.add_argument('--optimize', action='store_true', help='TorchScript: optimize for mobile')parser.add_argument('--int8', action='store_true', help='CoreML/TF INT8 quantization')parser.add_argument('--dynamic', action='store_true', help='ONNX/TF/TensorRT: dynamic axes')parser.add_argument('--simplify', action='store_true', help='ONNX: simplify model')parser.add_argument('--opset', type=int, default=12, help='ONNX: opset version')parser.add_argument('--verbose', action='store_true', help='TensorRT: verbose log')parser.add_argument('--workspace', type=int, default=4, help='TensorRT: workspace size (GB)')parser.add_argument('--nms', action='store_true', help='TF: add NMS to model')parser.add_argument('--agnostic-nms', action='store_true', help='TF: add agnostic NMS to model')parser.add_argument('--topk-per-class', type=int, default=100, help='TF.js NMS: topk per class to keep')parser.add_argument('--topk-all', type=int, default=100, help='TF.js NMS: topk for all classes to keep')parser.add_argument('--iou-thres', type=float, default=0.45, help='TF.js NMS: IoU threshold')parser.add_argument('--conf-thres', type=float, default=0.25, help='TF.js NMS: confidence threshold')parser.add_argument('--include',nargs='+',default=['onnx'],help='torchscript, onnx, openvino, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs')parser.add_argument('--rknpu', action='store_true', help='RKNN npu platform')opt = parser.parse_args()print_args(vars(opt))return opt然后执行命令,这里转换成功后就会生成上图的.onnx格式的权重文件。
python ./export.py --rknpu
2.2 转化成.rknn格式
1、rk官方github提供了相关的demo资料,可以在去下面地址下载:
https://github.com/airockchip/rknn-toolkit2
2、文件的大概目录如下,在文件里面有如图所示的test.py文件,里面就有转化为.rknn的例子并且顺便对图片进行推理的完整流程。
3、在test.py文件中
# Model from https://github.com/airockchip/rknn_model_zoo
ONNX_MODEL = './yolov5s_finger_2480.onnx'
RKNN_MODEL = './yolov5s_finger_2480_nq.rknn'
IMG_PATH = './out_2216.jpg'
DATASET = './dataset.txt'ONNX_MODEL 就是上面pt格式转化成onnx格式的权重文件
RKNN_MODEL 就是转化生成的.onnx权重文件
IMG_PATH 推理图片的路径
DATASET 也是推理图片的名称
然后运行生成后即可生成.rknn格式权重文件,以及图片的推理结果,结果如下:

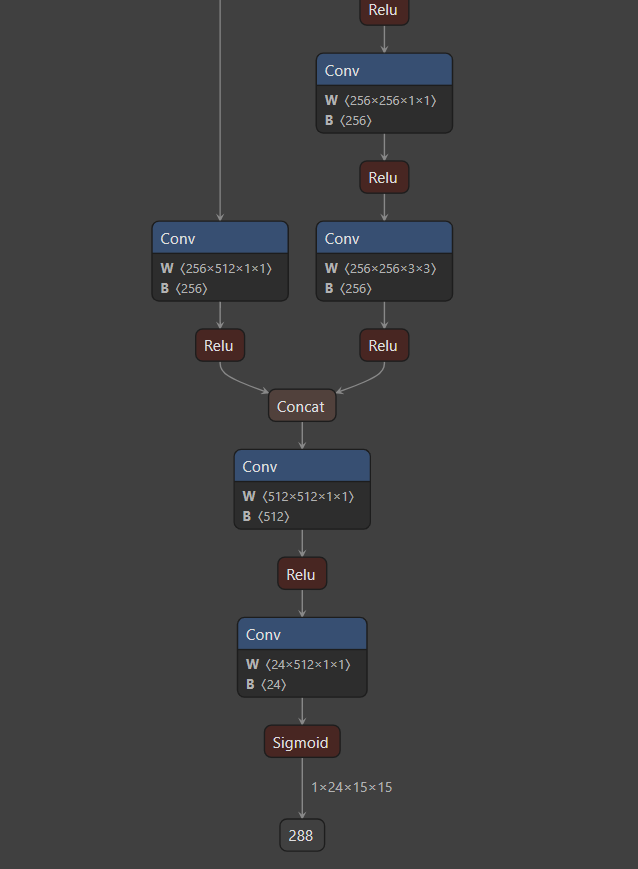
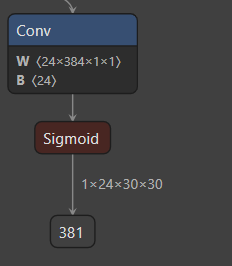
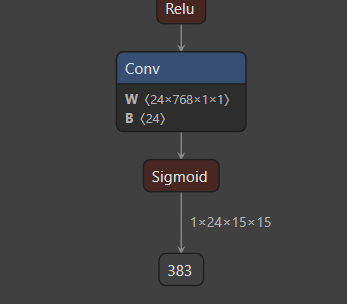
4、这里有一点需要确认,在生成.onnx格式权重文件的时候,可以看在VScode使用netron工具参看自己的网络模型,特别是输出端的参数维度是否和他提供的demo一直,不然在板端推理处理数据的时候肯定会有问题,模型的输出如下(一个输出):
三、模型的板端部署
1、NPU驱动版本确认
查询命令:
dmesg | grep-i rknpu
或
cat /sys/kernel/debug/rknpu/version
或
cat /sys/kernel/debug/rknpu/driver_version
或
cat /proc/debug/rknpu/driver_version
查询结果:
RKNPU driver: vX.X.X15
Rockchip的固件均自带RKNPU驱动。若以上命令均查询不到NPU驱动版本,则可能为第三方固件未安装RKNPU驱动,需要打开kernel config文件的“CONFIG_ROCKCHIP_RKNPU=y”选项,重新编译内核驱动并烧录。建议RKNPU驱动版本>=0.9.2。
2、检查 RKNPU2 环境是否安装
如果能够启动 rknn_server 服务,则代表板端已经安装 RKNPU2 环境
# 启动
rknn_serverrestart_rknn.sh
如果出现以下输出信息,则代表启动rknn_server服务成功,即已经安装RKNPU2环境
start rknn server, version: x.x.x
3、检查版本是否一致
# 查询rknn_server版本
strings /oem/usr/bin/rknn_server | grep-i"rknn_server version"
# 查询librknnmrt.so库版本
strings /oem/usr/lib/librknnmrt.so | grep-i"librknnmrt version"
如果出现以下输出信息,则代表rknn_server版本为 x.x.x,librknnmrt.so 的版本为 x.x.x
rknn_server version: x.x.x
librknnmrt version: x.x.x
4、运行demo代码推理
在main.cc文件中可以看到,入口参数1是.rknn权重文件的路径,参数2是需要推理的图片路径。
还有一个out_path,是推理结果图片文件路径名。
if (argc < 3){printf("Usage: %s <rknn model> <input_image_path> <resize/letterbox> <output_image_path>\n", argv[0]);return -1;}int ret;rknn_context ctx;size_t actual_size = 0;int img_width = 0;int img_height = 0;int img_channel = 0;const float nms_threshold = NMS_THRESH; // 默认的NMS阈值const float box_conf_threshold = BOX_THRESH; // 默认的置信度阈值struct timeval start_time, stop_time;char *model_name = (char *)argv[1];char *input_path = argv[2];std::string option = "letterbox";std::string out_path = "./out.jpg";if (argc >= 4){option = argv[3];}if (argc >= 5){out_path = argv[4];}在postprocess.h文件中:
NMS阈值和BOX阈值根据直接的需要进行更改,还有自己模型的类别数量需要修改。
#define OBJ_NAME_MAX_SIZE 16
#define OBJ_NUMB_MAX_SIZE 64
#define OBJ_CLASS_NUM 3
#define NMS_THRESH 0.45
#define BOX_THRESH 0.35
#define PROP_BOX_SIZE (5 + OBJ_CLASS_NUM)关键点:
一定要核对好推理出来的输出数据参数和你自己权重文件输出的参数是对应的,不然就需要自己去处理推理后的数据,然后画框还原了。
四、推理结果
下面是运行demo程序显示的一些信息,里面会显示该模型三个输出的纬度,输入的格式为NHWC
root@ATK-DLRK3588:/rknn/yolov5# ./rknn_yolov5_finger_image ./yolov5s_finger_480.rknn ./frame_2.jpg
post process config: box_conf_threshold = 0.60, nms_threshold = 0.70
Loading mode...
sdk version: 1.5.2 (c6b7b351a@2023-08-23T15:28:22) driver version: 0.9.2
model input num: 1, output num: 3
index=0, name=images, n_dims=4, dims=[1, 480, 480, 3], n_elems=691200, size=691200, w_stride = 480, size_with_stride=691200, fmt=NHWC, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003922
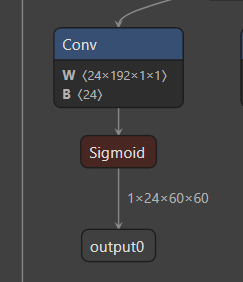
index=0, name=output0, n_dims=4, dims=[1, 24, 60, 60], n_elems=86400, size=86400, w_stride = 0, size_with_stride=122880, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003891
index=1, name=286, n_dims=4, dims=[1, 24, 30, 30], n_elems=21600, size=21600, w_stride = 0, size_with_stride=30720, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003835
index=2, name=288, n_dims=4, dims=[1, 24, 15, 15], n_elems=5400, size=5400, w_stride = 0, size_with_stride=7680, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003606
model is NHWC input fmt
model input height=480, width=480, channel=3
Read ./frame_2.jpg ...
img width = 480, img height = 800
resize image with letterbox
once run use 15.981000 ms
loadLabelName ./finger_labels_list.txt
two @ (58 223 338 474) 0.591172
save detect result to ./out.jpg
loop count = 10 , average run 11.136900 ms
三个模型输出的纬度就我们训练好的权重一致:
画框结果:

最后,其实demo也提供了视频流的识别,通过运行该demo就可以完成视频实时的识别,以及后续的相关应用了。