【Tech Arch】Apache Pig大数据处理的高效利器
今天我们深入探索一个在 Hadoop 生态中堪称 “数据魔法师” 的强大工具 ——Apache Pig。在实际工作中,许多开发者面对 MapReduce 繁杂的 Java 编程模型常常感到力不从心,从环境搭建、代码编写到调试优化,每一个环节都需要耗费大量精力,即便经验丰富的工程师,也可能在复杂的分布式逻辑中陷入困境。而 Apache Pig 正是为解决这些难题而生,它通过简洁的脚本语言,将原本复杂的数据处理任务化繁为简,极大提升了开发效率。接下来,我们将从 Apache Pig 的定义与起源讲起,深入解析其底层架构,再结合具体案例展示实战用法,全方位揭开 Pig 在大数据处理中的核心价值。

一、什么是 Pig?
Apache Pig 是一个高级数据分析平台,它提供了一种类 SQL 的脚本语言(Pig Latin),用于对大规模数据集进行提取、转换和加载(ETL)操作。简单来说,Pig 是 Hadoop 生态中的 “数据处理中间层”,它允许开发者通过简洁的脚本描述数据处理逻辑,而无需直接编写复杂的 MapReduce 程序。
Pig 的核心定位是 “让大数据处理更简单”。它将用户编写的 Pig Latin 脚本自动转换为 MapReduce、Tez 或 Spark 等底层计算引擎的执行计划,从而屏蔽了底层框架的技术细节,让数据分析师和开发者能更专注于业务逻辑而非技术实现。
二、Pig 的诞生背景
要理解 Pig 的价值,必须回到 Hadoop 发展的早期阶段。2004 年,Hadoop 的雏形在 Yahoo 诞生,其核心组件 MapReduce 成为分布式计算的主流框架。但在实际应用中,开发者很快发现了 MapReduce 的痛点:
- 编程门槛高:MapReduce 需要用 Java 编写,且必须严格遵循 “Map-Combiner-Shuffle-Reduce” 的编程范式,即使是简单的数据处理任务(如过滤、分组)也需要编写大量代码。
- 开发效率低:数据处理逻辑与底层计算细节高度耦合,开发者需要手动优化 Shuffle 策略、处理数据倾斜等问题,导致开发周期长。
- 适配性有限:对于非 Java 开发者(如数据分析师、Python 工程师),MapReduce 几乎难以使用;对于复杂的多步骤数据转换,代码可读性极差。
为解决这些问题,Yahoo 的工程师在 2006 年开始研发 Pig。最初,Pig 只是 Yahoo 内部的工具,旨在让数据分析师能通过简单脚本处理 Hadoop 上的海量数据。2007 年,Yahoo 将 Pig 捐赠给 Apache 软件基金会,随后成为 Apache 顶级项目。如今,Pig 已广泛应用于电商、金融、社交等领域的大数据处理场景。
三、Pig 的架构设计
Pig 的架构采用分层设计,清晰地实现了 “用户接口 - 逻辑处理 - 底层执行” 的分离。其核心架构包含以下组件:
1. 前端层(Frontend)
- Pig Latin 解析器(Parser):负责将用户编写的 Pig Latin 脚本解析为抽象语法树(AST),并进行语法校验。
- 逻辑优化器(Logical Optimizer):对 AST 进行优化,例如合并过滤条件、消除冗余操作、调整执行顺序等,生成优化后的逻辑计划。
- 物理计划生成器(Physical Planner):将逻辑计划转换为物理计划,即具体的操作步骤(如 Map 阶段、Reduce 阶段的任务分配)。
2. 执行引擎层(Execution Engine)
Pig 本身不直接执行计算,而是依赖底层分布式计算引擎:
- 默认引擎:MapReduce(Hadoop 的原生计算引擎)。
- 可选引擎:Tez(更高效的 DAG 计算引擎,支持复杂任务的流水线执行)、Spark(内存计算引擎,适合迭代型任务)。
3. 数据模型层
Pig 采用灵活的数据模型,支持多种数据类型:
- 基础类型:int、long、float、double、chararray(字符串)、bytearray(字节数组)。
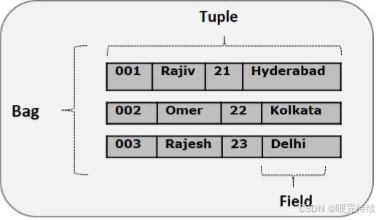
- 复杂类型:tuple(元组,类似行数据)、bag(包,类似表数据,由多个 tuple 组成)、map(键值对集合)。
这种灵活的数据模型使其能轻松处理结构化、半结构化甚至非结构化数据(如日志、JSON)。
4. 交互接口
- Grunt Shell:命令行交互工具,支持逐行执行 Pig Latin 命令。
- 脚本文件:将 Pig Latin 代码写入.pig文件,通过pig script.pig批量执行。
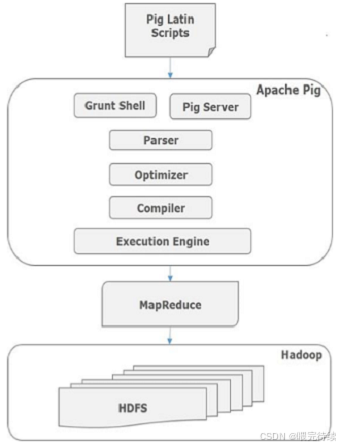
- Java API:允许通过 Java 程序调用 Pig 功能,实现自定义扩展。
四、Pig 解决的核心问题
在大数据处理场景中,Pig 针对性地解决了以下痛点:
1. 降低大数据编程门槛
MapReduce 需要手动编写 Map 和 Reduce 函数,甚至处理 Shuffle 阶段的细节,而 Pig Latin 通过声明式语法(如FILTER、GROUP BY、JOIN)描述 “要做什么”,而非 “怎么做”。例如,实现一个简单的数据过滤和分组统计,用 Pig Latin 只需 3-5 行代码,而用 MapReduce 可能需要数十行 Java 代码。
2. 提升开发与迭代效率
Pig 的逻辑优化器能自动优化执行计划,例如将多个过滤条件合并为一个 Map 任务,减少数据传输量;开发者无需手动调优底层细节,大幅缩短开发周期。对于频繁变更的数据分析需求,Pig 脚本的修改和测试成本远低于 MapReduce 程序。
3. 支持复杂数据处理流程
实际业务中,数据处理往往是多步骤的(如清洗→转换→聚合→关联)。Pig Latin 支持通过管道操作(=符号)将多个步骤串联:
raw_data = LOAD 'logs' USING PigStorage(',') AS (id:int, time:chararray, url:chararray);
filtered_data = FILTER raw_data BY time >= '2023-01-01';
grouped_data = GROUP filtered_data BY url;
result = FOREACH grouped_data GENERATE group AS url, COUNT(filtered_data) AS visit_count;这种线性的脚本结构让复杂流程的可读性和可维护性显著提升。
4. 适配多类型数据与计算引擎
Pig 支持 CSV、JSON、Parquet 等多种数据格式,且能无缝对接 MapReduce、Tez、Spark 等引擎。开发者无需修改脚本,只需通过参数指定执行引擎(如-x tez或-x spark),即可享受不同引擎的性能优势。
五、Pig 的关键特性
Pig 能在 Hadoop 生态中立足,离不开以下核心特性:
1. 易用的 Pig Latin 语言
Pig Latin 的语法设计贴近自然语言,且借鉴了 SQL 的核心思想,学习成本极低。例如:
- LOAD:加载数据;
- FILTER:过滤数据;
- GROUP BY:分组聚合;
- JOIN:关联多个数据集;
- FOREACH...GENERATE:数据转换与投影。
即使是非 Java 开发者,也能快速上手编写数据处理脚本。
2. 强大的优化能力
Pig 的优化器(如 Column Pruning、Predicate Pushdown)能自动对脚本进行优化。例如,当脚本中引用了数据集的部分字段时,优化器会只加载必要的字段(列裁剪),减少 I/O 开销;当存在多轮过滤时,优化器会将过滤逻辑尽可能推到 Map 阶段执行,避免无用数据进入 Shuffle 过程。
3. 灵活的扩展性
- 用户自定义函数(UDF):支持通过 Java、Python 等语言编写 UDF,扩展 Pig 的功能(如自定义数据清洗逻辑、复杂计算函数)。
- 存储函数(Storage Functions):可自定义数据加载和存储方式,适配特殊格式的数据(如 XML、Avro)。
4. 完善的调试与测试支持
- EXPLAIN:查看 Pig 生成的逻辑计划和物理计划,帮助分析执行流程。
- ILLUSTRATE:对小型数据集模拟执行脚本,快速验证逻辑正确性,无需等待全量数据处理完成。
- DESCRIBE:查看数据集的 schema 信息,便于调试数据结构问题。
5. 与 Hadoop 生态无缝集成
Pig 天然支持 HDFS(数据存储)、HBase(NoSQL 数据库)、Hive(数据仓库)等组件。可直接读取 Hive 表中的数据:
hive_data = LOAD 'hive://default/user_info' USING HCatLoader();六、与同类产品对比
在大数据处理领域,Pig 常与 MapReduce、Hive、Spark SQL 等工具对比,它们各有侧重:
1. Pig vs MapReduce
- 抽象层次:Pig 是高层抽象,MapReduce 是底层计算框架。
- 开发效率:Pig 脚本简洁,开发速度快;MapReduce 需手动编写 Java 代码,效率低。
- 灵活性:MapReduce 可完全控制计算细节,适合极致优化;Pig 受限于自动优化,灵活性稍低。
- 适用场景:Pig 适合快速开发和复杂 ETL;MapReduce 适合对性能有极致要求的底层任务。
2. Pig vs Hive
- 定位:Pig 更偏向数据处理(ETL),Hive 更偏向数据仓库(支持 SQL 查询和数据分析)。
- 语言:Pig 使用 Pig Latin,Hive 使用 HQL(类 SQL)。
- 元数据管理:Hive 有完善的元数据服务(Metastore),支持表结构管理;Pig 对元数据依赖较少,更灵活。
- 适用人群:Hive 适合熟悉 SQL 的分析师;Pig 适合需要更灵活数据处理的开发者。
3. Pig vs Spark SQL
- 执行引擎:Pig 默认依赖 MapReduce/Tez,Spark SQL 基于 Spark 引擎。
- 性能:Spark SQL 基于内存计算,性能通常优于 Pig(尤其迭代任务)。
- 功能:Spark SQL 支持更丰富的 SQL 特性和 DataFrame API;Pig 在复杂数据类型处理上更灵活。
- 生态整合:Spark SQL 是 Spark 生态的一部分,适合端到端的大数据处理;Pig 更适配 Hadoop 传统生态。
Pig 的核心优势在于 “灵活性 + 开发效率”,尤其适合处理半结构化数据和复杂 ETL 流程;若需 SQL 兼容性或数据仓库功能,选 Hive;若追求极致性能,选 Spark SQL。
七、Pig 的使用方法
接下来,我们通过一个实际案例演示 Pig 的基本用法。假设我们有一份电商用户行为日志(user_behavior.log),格式为:user_id,item_id,behavior_type,time,需要统计不同行为类型(点击、收藏、购买)的数量。
1. 环境准备
- 安装 Hadoop(确保 HDFS 和 YARN 正常运行)。
- 下载 Pig 安装包(Apache Pig 官网),解压后配置环境变量PIG_HOME和PATH。
2. 启动 Grunt Shell
pig # 默认以MapReduce为引擎启动Grunt Shell
# 或指定Tez引擎:pig -x tez
# 或指定本地模式(非分布式,用于测试):pig -x local3. 编写 Pig Latin 脚本
步骤 1:加载数据
-- 加载日志数据,指定分隔符为逗号,并定义字段schema
raw_behavior = LOAD '/user/data/user_behavior.log' USING PigStorage(',') AS (user_id:int, item_id:int,
behavior_type:chararray, time:chararray);步骤 2:数据清洗(可选)
-- 过滤无效数据(如behavior_type为空)
valid_behavior = FILTER raw_behavior BY behavior_type IS NOT NULL;步骤 3:分组统计
-- 按行为类型分组
grouped_behavior = GROUP valid_behavior BY behavior_type;-- 计算每种行为的数量
behavior_count = FOREACH grouped_behavior GENERATE group AS behavior_type, -- 分组键(行为类型)COUNT(valid_behavior) AS count; -- 统计数量步骤 4:存储结果
-- 将结果存储到HDFS的/output/behavior_count目录
STORE behavior_count
INTO '/output/behavior_count'
USING PigStorage('\t'); -- 使用制表符分隔输出步骤 5:执行脚本
- 若在 Grunt Shell 中逐行输入上述命令,输入RUN即可执行。
- 若将命令保存为behavior_analysis.pig脚本,可通过以下命令执行:
pig behavior_analysis.pig步骤 6:查看结果
hdfs dfs -cat /output/behavior_count/part-r-00000输出结果类似:
click 150000
favorite 20000
buy 100004. 常用调试命令
- DESCRIBE raw_behavior;:查看数据集的 schema。
- ILLUSTRATE valid_behavior;:展示数据样例,验证过滤逻辑。
- EXPLAIN behavior_count;:查看执行计划,分析优化后的步骤。
文末
Apache Pig 作为 Hadoop 生态中的经典工具,凭借其简单易用的脚本语言、灵活的数据模型和高效的开发体验,至今仍在大数据处理领域发挥着重要作用。它的核心价值不在于 “性能极致”,而在于 “平衡效率与复杂度”—— 让开发者能用最少的代码完成复杂的数据处理任务。
如果经常需要处理海量半结构化数据,或对 MapReduce 的繁琐编程感到困扰,不妨尝试 Pig。掌握它,能让你在大数据开发中效率倍增。