深层语义知识图谱:提升NLP文本预处理效果的关键技术
引言:超越“相关性”,探寻文本预处理的语义深度
自然语言处理(NLP)技术在过去十年取得了飞跃式发展,但其核心挑战之一——让机器真正“理解”语言——仍未完全解决。传统的文本预处理流程,包括数据清洗、文本规范化和词向量化,构成了所有下游任务的基石。然而,这些主流方法,如基于TF-IDF的特征提取或基于Word2Vec的词嵌入,在本质上依赖于统计共现(statistical co-occurrence)。它们能出色地捕捉词汇间的“相关性”,例如,“医生”和“医院”经常一同出现,但却难以洞察其背后更深层次的“因果性”——即一个事件或概念如何导致另一个的发生。这种局限性在处理复杂、含蓄或充满歧义的文本时尤为突出,模型往往会因虚假关联而做出错误判断。
问题的核心在于:我们如何能让机器在预处理的初始阶段,就跳出数据表面的关联,具备类似人类的逻辑推理能力,去理解文本背后隐藏的因果链条?这不仅是技术上的难题,更是通往强人工智能的关键一步。
为此,学术界和工业界将目光投向了一个新兴的解决方案——**因果知识图谱(Causal Knowledge Graph, CKG)**。作为一种“深层语义知识图谱”,CKG的革命性在于它不仅表示实体“是什么”以及它们“与什么相关”,更致力于揭示“为什么会发生”。它将图灵奖得主Judea Pearl的因果推理理论 (Judea Pearl的因果模型思想) 与知识图谱的结构化表示相结合,为文本预处理注入了前所未有的因果推理能力。这使得机器能够在处理文本的源头就辨别因果、消除混淆,从而为下游任务提供逻辑上更可靠、语义上更丰富的输入。
本文将系统性地阐述因果知识图谱如何赋能并革新文本预处理。我们将从其理论基础出发,深入剖析CKG在数据清洗、文本规范化、词向量化三大环节带来的革命性提升,并结合技术实现路径、前沿应用案例及未来发展趋势,全面描绘这一关键技术如何引领NLP迈向更深层次的语义理解新范式。
因果知识图谱:从关联到因果的理论飞跃
要理解因果知识图谱(CKG)的革命性,首先必须明确其与传统知识图谱(KG)的根本区别,并认识到这种区别如何为文本预处理带来质的飞跃。
定义与对比:CKG的核心价值
传统知识图谱(KG)是一个巨大的语义网络,通过节点(实体)和边(关系)来组织信息。这些关系通常是描述性的或分类性的,如is-a(苹果是一种水果)、part-of(引擎是汽车的一部分)或located-in(巴黎在法国)。它们有效地捕捉了世界知识的“关联性”,但本质上是静态和相关性的。(Zilliz, 2024)。
相比之下,因果知识图谱(CKG)是一种特殊的知识图谱,其核心是表示和推理因果关系。它专注于causes、leads-to、prevents等具有明确方向性和逻辑性的因果连结。CKG不仅是一个知识库,更是一个结构化的因果模型。其理论基石源于Judea Pearl的结构因果模型(SCM),强调通过图结构来表达变量间的因果依赖关系 (《人工智能中的推理:进展与挑战》, 2018)。CKG的核心价值在于它支持传统KG难以企及的两种高级推理:
- 干预(Intervention):回答“如果我们采取某个行动,会发生什么?”的问题。例如,在CKG中,我们可以模拟“如果提高利率”对“股市”的影响。
- 反事实(Counterfactuals):回答“如果过去发生了不同的事,现在会怎样?”的问题。例如,“如果当时没有进行药物干预,病人的情况会如何?”。
这种推理能力,使得CKG能够从“观察”数据(第一层级)跃升至“干预”(第二层级)和“反事实”(第三层级)的认知高度,这正是实现深度语义理解和鲁棒AI系统的关键 (因果推断的三个层级)。
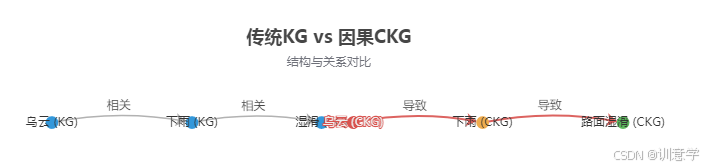
图1:传统知识图谱 (KG) 与因果知识图谱 (CKG) 的概念架构对比
为何CKG能革新文本预处理?
将CKG引入文本预处理,相当于为这个流程配备了一个外部的“逻辑与常识大脑”。其革新性体现在以下三个方面:
- 超越表面共现,赋予方向性理解:传统方法在文本中看到“乌云”和“下雨”频繁共现,只能学到它们强相关。而CKG能明确提供一条有向边:
乌云 causes 下雨。这种方向性知识至关重要,它帮助模型在预处理阶段就建立起正确的逻辑链,而不是模糊的关联。 - 提供逻辑支点,减少决策模糊性:在数据清洗、文本规范化等环节,传统方法依赖统计规则或启发式方法,常常面临歧义。CKG则为每一步操作提供了基于因果的决策依据。例如,在判断一个词是否为噪声时,可以查询CKG其是否是某个关键事件的已知原因或结果,从而做出更明智的决策。
- 增强模型可解释性与鲁棒性:基于因果关系进行的预处理,使得数据从源头就更加“干净”和“逻辑自洽”。这直接提升了下游模型(如分类、问答模型)的鲁棒性,因为模型更少地依赖数据中的虚假关联(spurious correlation)。当模型做出预测时,其决策路径可以追溯到CKG提供的因果链上,从而大大增强了可解释性 (CausalKG for Explainability, 2022)。
关键要点
因果知识图谱通过将因果关系作为一等公民(first-class links),实现了从“关联”到“因果”的理论飞跃。它为文本预处理提供了方向性、逻辑性和可解释性,使其不再是简单的文本操作,而是迈向了基于知识的智能推理第一步。
CKG赋能:文本预处理三大环节的革命性提升
因果知识图谱的理论优势最终要体现在对实际任务的改进上。本节将深入剖析CKG如何在数据清洗、文本规范化、词向量化这三个文本预处理的核心环节中,发挥其独特价值,实现革命性的效果提升。
1. 数据清洗:从盲目过滤到因果驱动的去噪
数据清洗的目标是识别并处理数据中的噪声、异常值和不一致性。传统方法通常基于统计分布(如3-sigma法则)或频率,这导致一个严重问题:可能会错误地将低频但至关重要的因果事件当作噪声剔除。例如,在金融交易数据中,“黑天鹅事件”的记录是罕见的,但却是风险分析的核心;在设备维护日志中,“系统宕机”的报告频率远低于“正常运行”,但其价值不可估量。
CKG的解决方案:因果合理性检验
CKG通过引入“因果合理性检验”机制,改变了噪声的定义。一个数据点是否为噪声,不再仅仅取决于其统计特性,更取决于其在因果网络中是否“合理”。具体而言,在判断一个数据点是否为噪声前,系统会查询CKG以评估其因果上下文。这一过程可被视为将数据去噪问题,从一个纯粹的统计问题,转化为一个因果推断中的“原因重构”问题 (Denoising as Cause Variable Reconstruction, 2024)。
案例分析:工业维护报告
在分析大量设备维护工单(Work Request Notification)时,存在许多信息噪音。一篇研究指出,可以通过构建因果图谱来过滤与因果语义无关的信息 (Causal knowledge extraction from maintenance documents)。

图2:数据清洗中传统方法与CKG辅助方法的对比
通过这种方式,CKG保护了数据中那些预示着重要变化的“弱信号”,使数据清洗过程更加智能和有洞察力,避免了“将婴儿与洗澡水一起倒掉”的错误。
2. 文本规范化:实现真正上下文感知的语义统一
文本规范化旨在将不同形式的文本转换为统一、标准的表示,主要包括分词、词形还原/词干提取和同义词合并。传统方法的机械性操作常常忽略上下文,导致语义信息的丢失或扭曲。
CKG的解决方案:基于因果路径的决策
CKG为文本规范化提供了深层语义约束,使得每一步操作都服务于保持和揭示文本的内在逻辑。
- 智能分词:尤其在中文等语言中,分词歧义是常见难题。例如,“企业创新”这个词,如果CKG中存在如“
数字经济 promotes 企业创新”和“企业创新 leads_to 市场竞争力提升”这样的结构化知识,模型在处理相关句子时,会倾向于将“企业创新”视为一个不可分割的语义单元,从而避免了错误的切分。这与基于图的模型进行联合分词和句法分析的思想一脉相承 (Graph-based Model for Joint Chinese Word Segmentation, 2020)。 - 因果感知的词形还原(Lemmatization):词形还原的目标是找到词的原型,但简单的规则会混淆词性。例如,“running”在“a long run”中是名词,在“running a company”中是动词(经营)。CKG可以提供语境判断。如果CKG中有
(经营公司, causes, 财务变化)这样的因果知识,模型在处理“The company is running a deficit”时,就能推断出“running”在此处与“经营”相关,从而选择更精确的词根或直接保留其特定形式,而不是粗暴地还原为“run”。 - 精准同义词替换:盲目地替换同义词可能破坏因果链。假设CKG中有一条关键知识:“
美联储加息(Fed raises rates) causes 美元升值(dollar appreciates)”。在处理一篇财经新闻时,如果模型试图将“加息”替换为同义词,它会查询CKG,评估哪个词最能保持这条因果逻辑。它可能会选择“提高利率”,但会避免使用“调整政策”这样模糊的词,因为后者会削弱因果关系的明确性。
图3:CKG辅助文本规范化的技术流程示意图
3. 词向量化:构建蕴含因果方向的语义空间
词向量化(Word Vectorization)是将词语转换为计算机可以处理的数值向量。以Word2Vec、GloVe为代表的传统嵌入模型基于“分布式假设”——相似上下文的词语具有相似的含义。这使得它们能学到词语间的“相关性”,但在向量空间中,“病毒”和“疾病”、“医生”和“护士”的向量会非常接近,却无法体现它们之间的致病关系或职业指导关系。这种缺陷不仅导致模型推理能力不足,也是产生偏见(如性别、种族偏见)的温床 (Word Embeddings via Causal Inference, 2022)。
CKG的解决方案:因果增强嵌入(Causal Embedding)
CKG通过为词向量空间注入因果结构,从根本上解决了上述问题。近期的研究,如CausE框架,正是这一方向的代表。
- 改进训练目标:在训练词向量时,引入因果约束作为新的优化目标。除了要求上下文相似的词向量彼此靠近外,还要求它们满足CKG中的因果三元组关系。例如,可以设计一个损失函数,使得
vector(原因) + vector(因果关系) ≈ vector(结果)。这种方法迫使模型学习到的向量不仅包含语义信息,还蕴含了逻辑方向 (CausE: Towards Causal Knowledge Graph Embedding, 2023)。 - 消除虚假关联与偏见:因果推断理论为消除偏见提供了强大工具。CKG可以帮助模型解耦(disentangle)概念。例如,在分析大量文本后,传统模型可能会学到“程序员”与“男性”的强关联。但CKG可以明确指出,“编程技能”是成为“程序员”的
原因,而“性别”不是。通过因果干预技术,可以在生成词向量时阻断“性别”到“程序员”的虚假因果路径,从而生成更公平、无偏见的表示。 - 构建结构化向量空间:经过CKG增强后,词向量空间不再是扁平、无序的,而是变成了一个具有因果方向性的结构化空间。在这个空间里,从“过度捕捞”到“海洋生态失衡”的向量方向,清晰地反映了它们之间的因果关系。这为需要逻辑推理的下游任务(如智能问答、推荐系统)提供了前所未有的能力。

图4:传统词向量空间与CKG增强的词向量空间对比
技术实现与应用场景:从理论到实践的路径
将CKG的理论优势转化为实际应用,需要一套完整的技术流水线来从非结构化文本中构建CKG,并将其部署到具体的业务场景中。近年来,随着NLP技术特别是大语言模型(LLM)的发展,这一过程变得越来越可行。
如何从文本中构建CKG
从海量文本(如新闻、财报、医疗记录、科学文献)中自动构建CKG,通常遵循一个端到端的框架。多项研究,如 `Text to Causal Knowledge Graph` 和 `KGGen`,已经探索并验证了这一路径 (Text to CKG Framework, 2023; KGGen, 2025)。其核心步骤如下:
- 因果关系抽取 (Causal Relation Extraction):这是构建CKG的第一步。利用先进的NLP模型(如微调的BERT或功能强大的LLM),在大量文本中识别并抽取出含有因果逻辑的句子或段落。例如,模型会重点关注包含“因为”、“导致”、“由于”、“因此”等因果触发词的句子。
- 因果三元组提取 (Causal Triple Extraction):在识别出的因果句中,需要进一步精确地标注出三个关键元素:
原因(Cause)、结果(Effect)和因果触发词(Trigger)。这是一个序列标注任务,模型需要准确地界定每个元素的文本范围。 - 图谱构建与融合 (Graph Construction & Fusion):将抽出的三元组
(Cause, causes, Effect)作为基本单元,连接成一个初始的图谱。为了提高图谱的质量和可用性,还需要进行以下处理:- 实体链接 (Entity Linking):将文本中的实体(如“苹果公司”)链接到标准知识库(如Wikidata)中的唯一ID,解决实体歧义问题。
- 实体与关系规范化:对相似的实体和关系进行聚类和统一。例如,将“股价上涨”、“价格攀升”等统一为“价格_上涨”关系,将“美联储”、“Fed”统一为同一个实体节点。
这一流程将杂乱无章的文本信息,转化为了结构化、可计算的因果知识网络。
典型应用场景案例分析
CKG驱动的文本预处理技术已在多个高价值领域展现出巨大潜力。
医疗健康:精准的临床决策支持
通过分析海量的电子病历(EHR)、医学文献和临床试验报告,可以构建一个大规模的医疗CKG。一篇关于临床CKG构建的研究指出,这样的图谱能够显著提升知识的完整性和准确性 (Causal knowledge graph for clinical decision, 2023)。
案例:在处理一名糖尿病患者的病历时,传统的预处理可能仅仅提取出“血糖高”、“用药A”、“肾功能下降”等孤立的关键词。而一个CKG增强的系统,在预处理阶段就能利用其内部知识(如 "长期高血糖" causes "肾脏微血管病变","药物A" has_side_effect "肾功能损伤")来构建一个因果假设链。这不仅能帮助医生区分疾病进展和药物副作用,还能为后续的个性化治疗方案推荐提供高质量、有逻辑的输入数据。
金融风控:洞察风险传导路径
金融市场的复杂性在于事件间的连锁反应。通过从新闻、公司公告、财报中构建金融事件CKG,可以有效地捕捉这些动态。有研究专门针对金融领域构建了本体引导的因果知识图谱FinCaKG-Onto (FinCaKG-Onto, 2025)。
案例:当一篇新闻报道“中东地区地缘政治紧张局势升级”时,一个仅基于关键词的系统可能只会将其标记为“地缘政治风险”。而一个拥有CKG的系统,在预处理时就能激活一条因果路径:"地缘政治紧张" leads_to "原油供应担忧" -> "原油供应担忧" causes "国际油价上涨" -> "油价上涨" increases "航空公司运营成本" -> "运营成本增加" negatively_impacts "航空公司股价"。这种深度的、结构化的信息提取,使得风险模型能够更早、更准确地评估事件对特定行业或公司的潜在冲击。
智能制造与ICT支持:加速根本原因分析
在制造业和信息通信技术(ICT)领域,快速定位故障根本原因是降本增效的关键。富士通(Fujitsu)在其白皮书中详细介绍了他们如何应用CKG解决这一难题 (Fujitsu Causal Knowledge Graph White Paper, 2024)。
案例:当网络运维中心收到大量关于“网络延迟高”的告警文本时,CKG可以整合来自设备手册、故障排除指南和历史告警记录的知识。在预处理阶段,系统就能识别出“特定型号交换机固件版本过低”与“处理高并发流量时性能下降”之间的因果关系,并最终链接到“网络延迟高”。这使得根本原因分析从数小时的人工排查,缩短为分钟级的自动推理,其基础正是在于预处理阶段就完成了因果知识的对齐与应用。
研究前沿与未来展望:因果知识图谱的下一站
因果知识图谱领域正处于高速发展期,其前沿研究主要围绕着与大语言模型(LLM)的深度融合、多模态扩展以及动态时序建模展开,同时也面临着一系列挑战。
与大语言模型(LLM)的深度融合
LLM与CKG的结合是当前最热门的研究方向,二者形成了互补增强的良性循环。
- LLM增强CKG构建 (LLM-augmented KGs):传统CKG构建依赖于复杂的NLP流水线和大量标注数据。现在,可以利用LLM强大的零样本/少样本(zero/few-shot)学习能力,直接从文本中高效、准确地抽取因果关系,甚至发现人类难以察觉的隐性因果链。研究表明,LLM在成对关系推断上表现出强大的竞争力 (Zero-shot Causal Graph Extrapolation via LLMs, 2023)。
- CKG增强LLM(Graph-RAG):这是解决LLM“幻觉”和逻辑推理能力不足问题的有效途径。通过检索增强生成(Retrieval-Augmented Generation, RAG)技术,当LLM处理一个需要因果知识的任务时,它会首先从外部的CKG中检索相关的因果路径作为可靠的上下文,然后再生成答案。这种“Causal-First Graph-RAG”方法,通过优先检索因果边,显著提升了模型在医疗问答等复杂推理任务上的准确性和可解释性 (Enhancing Complex Reasoning in Graph-Augmented LLMs, 2024)。
多模态与动态时序CKG
- 多模态因果知识图谱:现实世界的因果关系往往跨越多种信息模态。未来的研究将致力于融合文本、图像、视频、传感器数据等,构建更全面的因果知识体系。例如,通过结合交通事故的文本描述、现场照片和行车记录仪视频,共同推断事故的根本原因 (Multimodal Knowledge Graph Construction, 2024)。
- 动态与时序CKG:因果关系并非一成不变,它会随时间演变。例如,一项政策在初期和后期可能产生完全不同的社会效应。因此,构建能够捕捉和推理动态因果链的时序知识图谱(Temporal KG)是另一个重要前沿。已有研究开始探索如何将因果干预理论融入时序图表示学习中,以 disentangle 出真正的因果因素 (Causal Enhanced Graph Representation Learning for TKGR, 2024)。
面临的挑战
尽管前景广阔,CKG的发展仍面临诸多挑战:
- 知识的准确性与覆盖度:自动抽取的因果知识难免存在错误和偏差。如何保证大规模CKG的准确性,以及如何处理知识不完备(missing data)的问题,是其能否在关键领域(如医疗)可靠应用的前提 (Causal Inference for KGC, 2023)。
- 评估体系的建立:如何科学、全面地评估一个CKG的质量?如何量化它对下游任务性能的真实提升?目前尚缺乏统一的基准和评估框架,这限制了不同方法间的公平比较 (WikiCausal Evaluation Framework, 2024)。
- 计算成本与可扩展性:构建和推理大规模CKG,特别是与LLM结合时,需要巨大的计算资源。开发更高效的算法和模型,以应对数百万甚至数十亿节点规模的图谱,是实现技术普惠的关键。
结论:迈向更智能的文本理解新范式
本文系统地阐述了因果知识图谱(CKG)作为一种深层语义知识图谱,如何从根本上革新NLP的文本预处理流程。通过引入“因果”这一核心维度,CKG将预处理从一种机械的、基于表面统计相关性的文本操作,提升为一个智能的、基于内在逻辑的知识处理过程。在数据清洗、文本规范化和词向量化三个关键环节,CKG都展现了其无与伦比的优势:它能辨别真伪,保留关键的低频信号;能洞察语境,实现精准的语义统一;能构建结构化的向量空间,为下游任务注入逻辑推理的能力。
这种从“相关性”到“因果性”的转变,其意义远不止于对NLP技术栈的简单优化。它代表了人工智能发展的一个重要方向——推动AI向着更强的认知智能、更高的可解释性和更可靠的决策能力迈进。当模型不再仅仅是模仿数据的模式,而是开始理解模式背后的因果机制时,我们所构建的AI系统将变得更加鲁棒、公平和值得信赖。
当然,前路依然充满挑战。知识的获取、评估的标准化以及与大模型的深度协同,都是亟待解决的课题。但无论如何,因果知识图谱已经为我们打开了一扇通往更深层次机器理解的大门。
当机器真正开始理解‘为什么’,我们离通用人工智能还有多远?这或许是因果知识图谱带给我们的最深刻的启示。