深度学习-计算机视觉-微调 Fine-tune
1. 迁移学习
迁移学习(transfer learning)是一种机器学习方法,通过将源数据集(如ImageNet)上训练得到的模型知识迁移到目标数据集(如特定场景的椅子识别任务)。这种方法的核心在于利用预训练模型已学习到的通用特征,提升目标任务的性能,尤其是在数据量有限的情况下。
ImageNet等大规模数据集虽然包含多样化的图像类别(如动物、植物、人造物体等),但在此类数据集上训练的模型能够自动学习低层次和高层次的通用视觉特征。这些特征包括但不限于:
- 边缘检测:识别图像中的轮廓和边界。
- 纹理分析:捕捉不同材质的表面特性。
- 形状建模:提取物体的几何结构。
- 对象组合关系:理解多物体间的空间和语义关联。
尽管ImageNet可能不直接包含大量椅子图像,但模型学习到的上述特征仍然能够有效支持椅子识别任务。例如,椅子的边缘结构与动物轮廓可能共享相似的检测模式,而木质或布艺椅子的纹理特征可能与其他物体(如家具或服饰)的纹理分析机制高度相关。
通过迁移学习,目标任务无需从零开始训练模型,从而显著减少计算资源和时间成本。此外:
- 在目标数据集较小的情况下,迁移学习能够避免过拟合问题
- 预训练模型的高层次特征提取能力可提升目标任务的泛化性能
- 适用于跨领域应用,如医学影像分析、自动驾驶等场景
2. 微调
迁移学习中的常见技巧:微调(fine-tuning)。
微调包括以下四个步骤。
在源数据集(例如ImageNet数据集)上预训练神经网络模型,即源模型。
创建一个新的神经网络模型,即目标模型。这将复制源模型上的所有模型设计及其参数(输出层除外)。我们假定这些模型参数包含从源数据集中学到的知识,这些知识也将适用于目标数据集。我们还假设源模型的输出层与源数据集的标签密切相关;因此不在目标模型中使用该层。
向目标模型添加输出层,其输出数是目标数据集中的类别数。然后随机初始化该层的模型参数。
在目标数据集(如椅子数据集)上训练目标模型。输出层将从头开始进行训练,而所有其他层的参数将根据源模型的参数进行微调。
微调中的 权重初始化:
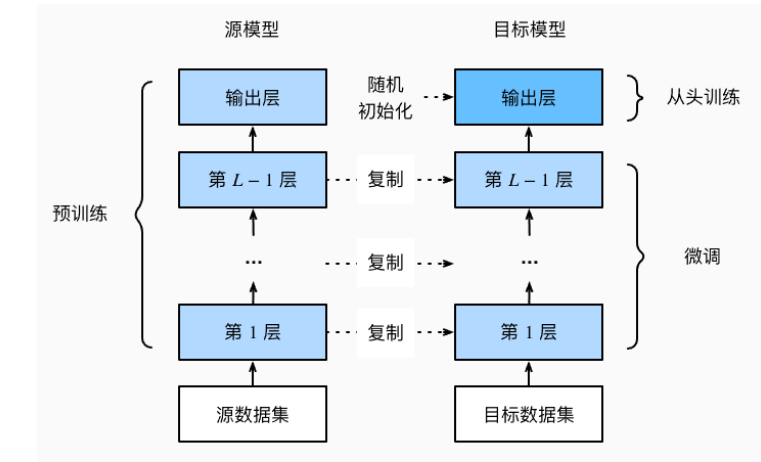

迁移学习将从源数据集中学到的知识迁移到目标数据集,微调是迁移学习的常见技巧。
除输出层外,目标模型从源模型中复制所有模型设计及其参数,并根据目标数据集对这些参数进行微调。
但是,目标模型的输出层需要从头开始训练。
通常,微调参数使用较小的学习率,而从头开始训练输出层可以使用更大的学习率。
3. 代码实现
%matplotlib inline
import os
import torch
import torchvision
from torch import nn
from d2l import torch as d2l#@save
d2l.DATA_HUB['hotdog'] = (d2l.DATA_URL + 'hotdog.zip','fba480ffa8aa7e0febbb511d181409f899b9baa5')data_dir = d2l.download_extract('hotdog')train_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'))
test_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'))下面显示了前8个正类样本图片和最后8张负类样本图片。
正如所看到的,图像的大小和纵横比各有不同。
hotdogs = [train_imgs[i][0] for i in range(8)]
not_hotdogs = [train_imgs[-i - 1][0] for i in range(8)]
d2l.show_images(hotdogs + not_hotdogs, 2, 8, scale=1.4);
数据增广:
对于RGB(红、绿和蓝)颜色通道,我们分别标准化每个通道。 具体而言,该通道的每个值减去该通道的平均值,然后将结果除以该通道的标准差。
# 使用RGB通道的均值和标准差,以标准化每个通道
normalize = torchvision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])train_augs = torchvision.transforms.Compose([torchvision.transforms.RandomResizedCrop(224),torchvision.transforms.RandomHorizontalFlip(),torchvision.transforms.ToTensor(),normalize])test_augs = torchvision.transforms.Compose([torchvision.transforms.Resize([256, 256]),torchvision.transforms.CenterCrop(224),torchvision.transforms.ToTensor(),normalize])查看源模型:
我们使用在ImageNet数据集上预训练的ResNet-18作为源模型。
在这里,我们指定pretrained=True以自动下载预训练的模型参数。 如果首次使用此模型,则需要连接互联网才能下载。
预训练的源模型实例包含许多特征层和一个输出层fc。 此划分的主要目的是促进对除输出层以外所有层的模型参数进行微调。
下面给出了源模型的成员变量fc。
pretrained_net = torchvision.models.resnet18(pretrained=True)
pretrained_net.fc输出:
Linear(in_features=512, out_features=1000, bias=True)定义目标模型finetune_net:【换输出层】
finetune_net = torchvision.models.resnet18(pretrained=True)载入 在 ImageNet 上预训练好的 ResNet-18 网络(权重已固定,特征提取器已具备通用视觉能力)。finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2)把 ResNet-18 最后的 1000 类全连接层 替换成 只有 2 个输出的新层(二分类任务)。in_features保留原模型提取到的特征维度(512)。输出维度改为 2,对应新任务的类别数。
finetune_net = torchvision.models.resnet18(pretrained=True)
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2)
nn.init.xavier_uniform_(finetune_net.fc.weight);首先,我们定义了一个训练函数train_fine_tuning,该函数使用微调,因此可以多次调用。
其中特征提取层学习率低,最后一层输出层学习率高。
# 如果param_group=True,输出层中的模型参数将使用十倍的学习率
def train_fine_tuning(net, learning_rate, batch_size=128, num_epochs=5,param_group=True):train_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'), transform=train_augs),batch_size=batch_size, shuffle=True)test_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'), transform=test_augs),batch_size=batch_size)devices = d2l.try_all_gpus()loss = nn.CrossEntropyLoss(reduction="none")if param_group:params_1x = [param for name, param in net.named_parameters()if name not in ["fc.weight", "fc.bias"]]trainer = torch.optim.SGD([{'params': params_1x},{'params': net.fc.parameters(),'lr': learning_rate * 10}],lr=learning_rate, weight_decay=0.001)else:trainer = torch.optim.SGD(net.parameters(), lr=learning_rate,weight_decay=0.001)d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,devices)我们使用较小的学习率,通过微调预训练获得的模型参数。
train_fine_tuning(finetune_net, 5e-5)输出:
loss 0.220, train acc 0.915, test acc 0.939
999.1 examples/sec on [device(type='cuda', index=0), device(type='cuda', index=1)]为了进行比较,我们定义了一个相同的模型,但是将其所有模型参数初始化为随机值。
由于整个模型需要从头开始训练,因此我们需要使用更大的学习率。
scratch_net = torchvision.models.resnet18()
scratch_net.fc = nn.Linear(scratch_net.fc.in_features, 2)
train_fine_tuning(scratch_net, 5e-4, param_group=False)输出:
loss 0.374, train acc 0.839, test acc 0.843
1623.8 examples/sec on [device(type='cuda', index=0), device(type='cuda', index=1)]