李宏毅NLP-11-语音合成
目录
源起

VODER(Voice Operation DEmonstratoR),它是人类历史上早期的电子语音合成器,由贝尔实验室在 1939 年研发:
- 时间:1939 年(距今 85 年),属于电子管时代的语音合成先驱。
- 意义:首次用电子设备模拟人类语音,比现代 TTS(文本转语音)早数十年,是语音合成技术的里程碑。
VODER 通过手动控制多个滤波器和调制器,模拟人类语音的 “基频、共振峰、音高” 等特征,生成简单语音(如单词、短语)。
-
操作方式:人物通过操作台面的旋钮、按键(类似电子乐器的控制器),调节语音的频率、振幅等参数,合成目标语音。
-
技术突破:证明 “电子设备可合成人类语音”,为后续语音合成(如声码器、现代 TTS)奠定基础。
-
科普价值:1939 年纽约世界博览会上展示,让公众首次接触 “机器说话”,引发对语音技术的关注。

1961 年贝尔实验室John Larry Kelly Jr利用 IBM 计算机实现的早期电子语音合成,使用IBM 计算机(1960 年代的大型主机,体积庞大、算力有限)合成语音。这是计算机辅助语音合成的早期实践,比现代 TTS 早数十年,是语音技术发展的重要节点。
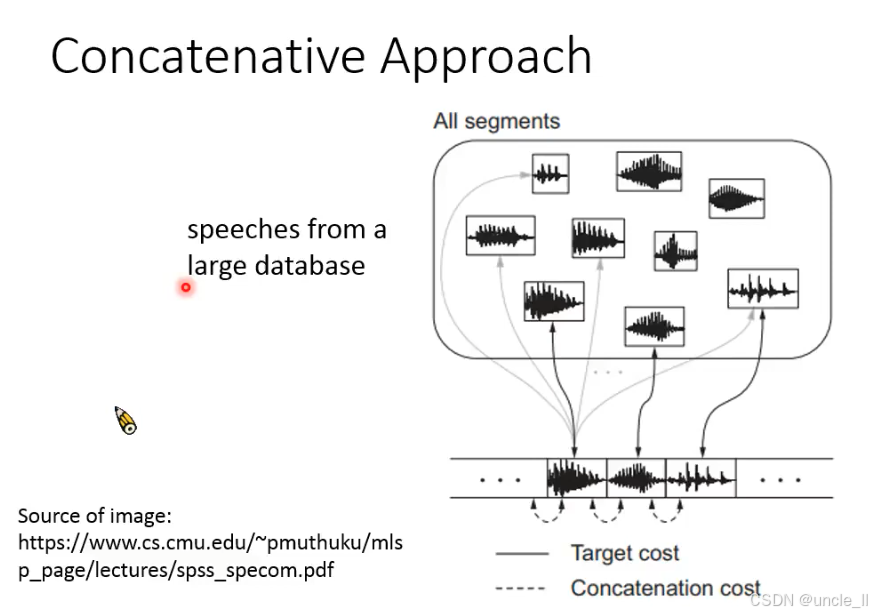
拼接式语音合成(Concatenative Speech Synthesis)** 的核心原理,这是现代 TTS(文本转语音)的早期主流方法,以下是关键解读:
一、核心思想:从数据库中 “拼接语音片段”
- 语音数据库(speeches from a large database):
预先录制大量语音片段(如单个音素、音节、单词),存储为波形(图中上方的小方框)。 - 拼接过程(Concatenation):
根据输入文本(如 “你好世界”),从数据库中选择合适的片段(如 “你”“好”“世”“界”),按顺序拼接成完整语音(图中下方的长波形)。
二、关键成本:确保拼接自然
为避免拼接后语音 “生硬、不连贯”,需优化两个成本:
- 目标成本(Target cost):
衡量 “选中的片段与目标文本的匹配度”(如音素、声调是否一致),确保语义正确。 - 拼接成本(Concatenation cost):
衡量 “相邻片段的衔接自然度”(如频谱、音高是否平滑过渡),避免拼接处出现 “咔嗒声” 或 “突变”。
三、优缺点:拼接式合成的特性
(1)优点
- 音质自然:直接使用真实人录音片段,保留人类语音的自然韵律(比早期电子合成更自然)。
- 简单可控:通过数据库和成本函数,可手动优化拼接效果。
(2)缺点
- 数据依赖:需录制海量语音片段(覆盖所有可能的文本组合),否则会出现 “找不到匹配片段” 的问题。
- 灵活性低:难以合成 “数据库外的内容”(如生僻词、特殊发音),且无法灵活改变语音风格(如情绪、语速)。
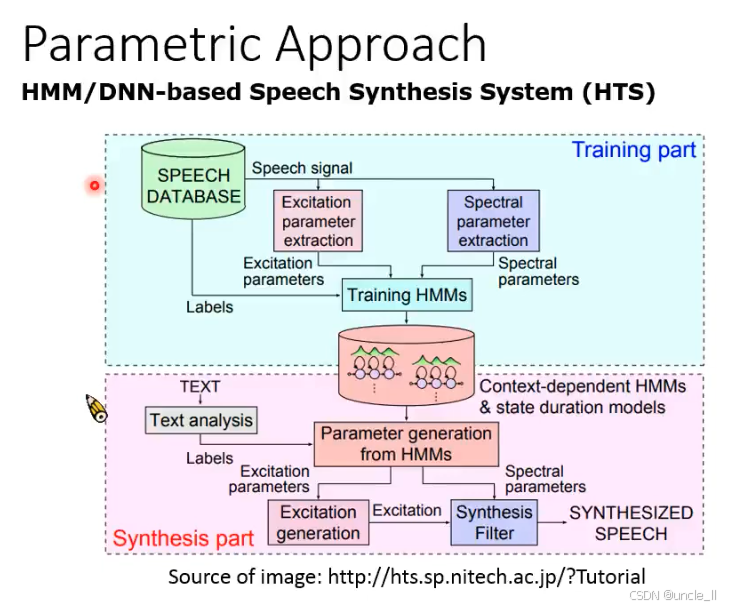
参数化语音合成方法(Parametric Approach) 中的HMM/DNN-based 语音合成系统(HTS,Hidden Markov Model-based Speech Synthesis System),是继拼接式合成之后的主流技术,核心通过统计模型生成语音参数而非直接拼接波形。
一、系统架构:训练(Training)与合成(Synthesis)两阶段
(1)训练阶段(Training part)
- 输入:语音数据库(SPEECH DATABASE)+ 文本标签(Labels,如音素、声调、上下文信息)。
- 特征提取:
- 激励参数(Excitation parameters):提取语音的基频(F0)、声门脉冲等 “声源特征”;
- 频谱参数(Spectral parameters):提取梅尔倒谱系数(MFCC)、线谱对(LSP)等 “声道滤波特征”。
- 模型训练:
- 用 HMM(隐马尔可夫模型)或 DNN(深度神经网络)学习 “文本标签→语音参数” 的映射关系,得到上下文相关 HMM(Context-dependent HMMs) 和状态时长模型(state duration models)。
(2)合成阶段(Synthesis part)
-
输入:目标文本(TEXT)。
-
文本分析(Text analysis):将文本转换为音素序列、上下文标签(如前后音节、语速)。
-
参数生成(Parameter generation from HMMs):
- 基于训练好的 HMM/DNN,从文本标签生成激励参数和频谱参数。
-
语音合成:
- 激励生成(Excitation generation):根据激励参数生成声源信号(如脉冲串或噪声);
- 合成滤波(Synthesis Filter):用频谱参数控制滤波器,对声源信号滤波,生成最终语音(SYNTHESIZED SPEECH)。
-
HMM 的作用:将语音参数建模为 “状态序列”,通过转移概率和输出概率描述语音的动态变化(如音素的过渡),解决拼接式合成的 “数据依赖” 和 “拼接不连贯” 问题。
-
DNN 的改进:后期 HTS 引入 DNN 替代 HMM 的参数生成模块,通过深度网络学习更复杂的 “文本 - 语音” 映射关系,提升合成语音的自然度。
-
激励参数:模拟声带振动(浊音为周期脉冲,清音为白噪声),决定语音的音高和清浊特性;
-
频谱参数:模拟声道共鸣(口腔、鼻腔的形状变化),决定语音的音色和元音 / 辅音特征。
两者通过 “源 - 滤波模型”(Source-Filter Model)结合,生成完整语音信号。
优缺点:参数化合成的特性
(1)优点
- 数据效率高:无需海量语音片段,通过少量数据训练模型即可合成任意文本;
- 灵活性强:可灵活调整语音参数(如音高、语速、情感),支持个性化定制(如改变说话人性别、年龄)。
(2)缺点
- 音质限制:生成的参数化语音(尤其早期 HMM-TTS)常带有 “金属音” 或 “模糊感”,自然度低于拼接式合成;
- 模型复杂度:HMM 状态对齐和参数优化难度高,需专业知识调优。
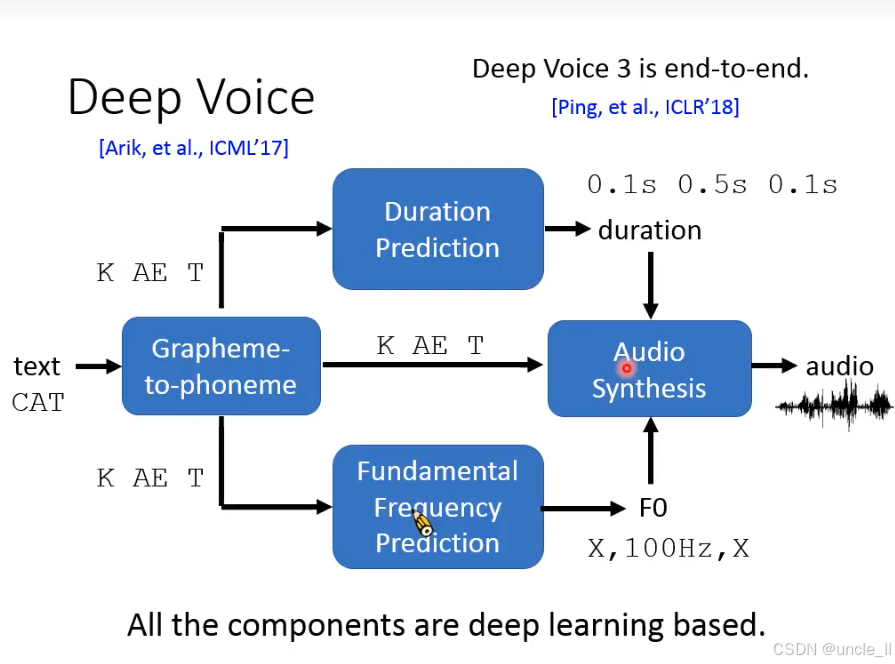
Deep Voice的是由 Arik 等人在 ICML 2017 提出的端到端神经语音合成系统(Neural TTS)
一、核心目标:文本→语音的直接映射
输入任意文本(text),输出对应的合成语音(audio),通过模块化设计实现自然语音生成,替代传统参数化合成(如 HMM-TTS)。
二、四大模块的协同
(1)字符转音素(Grapheme-to-phoneme)
- 作用:将文本中的字符(Grapheme,如字母、汉字) 转换为音素(Phoneme,如国际音标),解决不同语言的发音规则(如英语 “ough” 的多种发音)。
- 意义:统一文本的 “发音表示”,为后续语音合成提供基础。
(2)时长预测(Duration Prediction)
- 作用:预测每个音素的持续时长(duration),决定语音的 “语速” 和 “韵律节奏”(如元音拖长、辅音短促)。
- 创新:用神经网络学习 “文本 - 时长” 的映射,替代传统 HMM 的状态时长模型,更灵活适配自然语音的节奏。
(3)基频预测(Fundamental Frequency Prediction)
- 作用:预测语音的基频(F0,Fundamental Frequency),决定语音的 “音高”(如疑问句结尾音高上升)。
- 意义:控制语音的情感和语调,让合成语音更自然(传统方法常忽略 F0 的动态变化)。
(4)音频合成(Audio Synthesis)
- 输入:音素序列 + 时长 + F0 → 生成最终语音波形。
- 核心:通过神经网络(如 WaveNet、声码器)学习 “音素 + 韵律参数→波形” 的映射,直接生成高质量语音。
创新点:模块化端到端设计
- 解耦优化:将 “发音、时长、音高、波形生成” 拆分为独立模块,可分别优化(如单独调优时长预测提升韵律)。
- 跨语言适配:字符转音素模块支持多语言(如英语、中文),只需替换该模块即可适配新语言,无需重新训练整个系统。
Deep Voice 是工业级神经 TTS 的早期代表(后被 Google Tacotron、Microsoft VALL-E 等继承发展),证明了 “模块化神经设计” 在语音合成中的可行性,推动了 TTS 从 “参数化” 向 “自然语音级” 的跨越。
tracotron 端到端tts

Tacotron是 Google 提出的端到端神经语音合成系统(Neural TTS)初稿发表于 INTERSPEECH 2017([Wang, et al., INTERSPEECH’17]);修订版发表于 ICASSP 2018([Shen, et al., ICASSP’18])。
Tacotron 的历史地位
-
端到端突破:首次实现 **“文本→波形” 的直接映射 **,无需传统 TTS 的 “字符转音素→韵律预测→声码器” 多阶段流程。
-
工业级影响:是现代神经 TTS(如 Tacotron 2、VITS)的基石,Google Assistant 的语音合成曾基于此优化。
-
*These authors really like tacos.:标*的作者喜欢玉米卷(呼应 Tacotron 命名); -
†These authors would prefer sushi.:标†的作者更喜欢寿司(趣味分组)。
Tacotron 的核心是注意力机制(Attention) + 循环网络(RNN),学习文本和语音的对齐关系,直接生成梅尔频谱(Mel-spectrogram),再通过 WaveNet 等声码器转波形。后续 Tacotron 2 引入双向注意力和更强大的解码器,进一步提升自然度。

在 Tacotron(2017)提出前,已有研究尝试用神经网络实现 **“文本→语音参数 / 波形” 的直接映射 **,但未达到工业级自然度,却为 Tacotron 铺路。
(1)Tacotron 的早期形态(未命名阶段)
- 输入:字符(character,如字母、汉字)
- 输出:线性频谱(linear spectrogram)
- 意义:首次尝试 “字符→频谱” 的端到端映射,虽未正式命名,但已是 Tacotron 的雏形。
(2)参数化 TTS 的第一步(First Step Towards End-to-end Parametric TTS)
- 输入:音素(phoneme,如国际音标)
- 输出:STRAIGHT 声码器的声学特征(acoustic features)
- 论文:[Wang, et al., INTERSPEECH’16]
- 局限:依赖 “音素→特征” 的映射,需先做字符转音素(G2P),未完全端到端;但证明神经网络可学习 “发音→声学特征” 的关系。
(3)Char2wav
- 输入:字符(character)
- 输出:SampleRNN 声码器的声学特征
- 论文:[Sotelo, et al., ICLR workshop’17]
- 创新:跳过 “音素转换”,直接从字符生成特征,更接近 “端到端”;但生成的语音自然度仍低(声码器技术限制)。
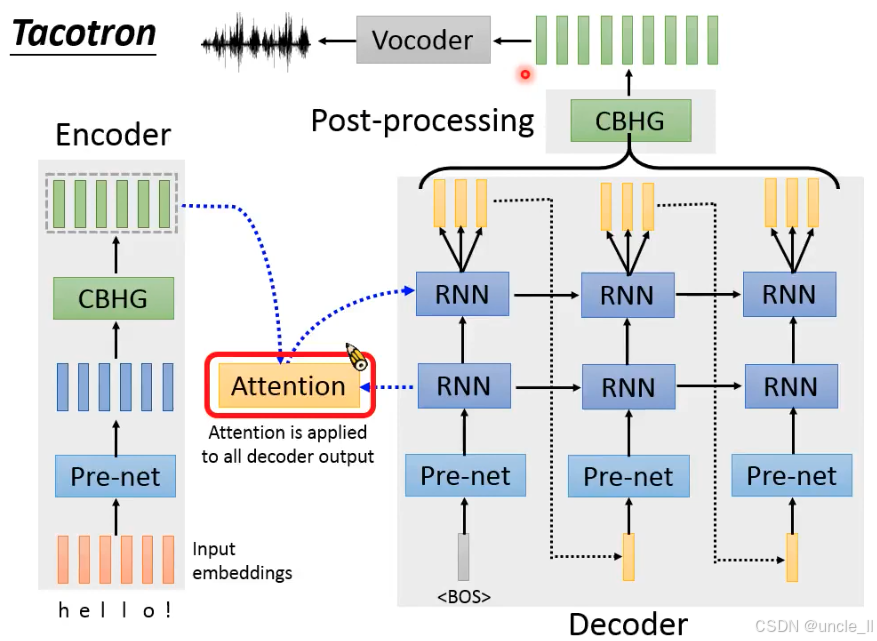
Tacotron 架构,通过 “编码器提取文本特征→注意力对齐→解码器生成频谱→声码器转波形” 的流程,实现了 “文本→语音” 的端到端合成。核心是注意力机制的动态对齐,让神经 TTS 真正具备自然语音的韵律和质量,成为现代语音合成的基石。
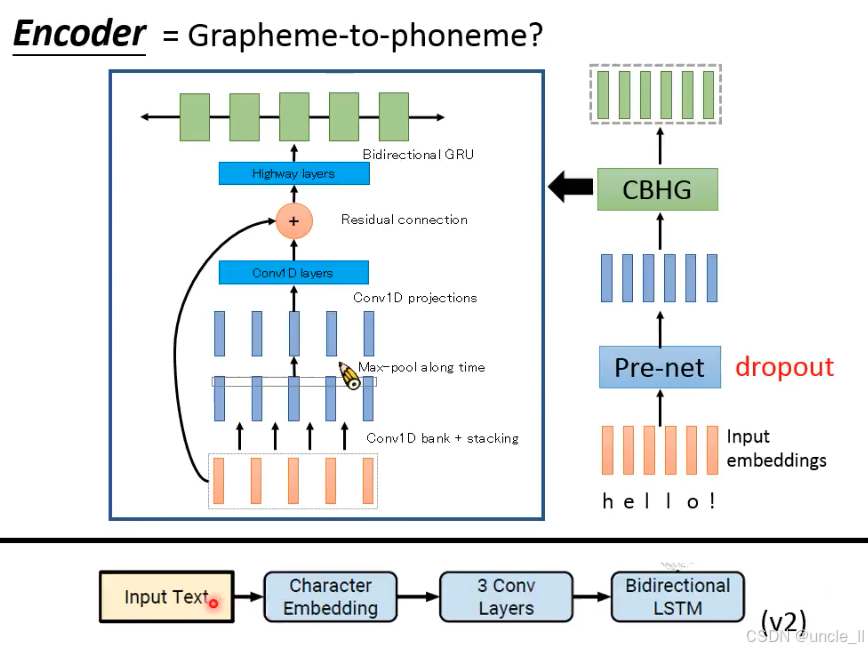
CBHG(Convolution Bank + Highway + GRU):
- 卷积银行(Convolution Bank):用多组卷积核(1~16)提取不同长度的局部特征(如字母组合的发音模式);
- 高速网络(Highway):传递关键特征,避免梯度消失;
- 双向 GRU:捕捉文本的长时依赖(如 “hello” 中 “l” 的重复发音)。
- 输出:文本的高维特征序列(绿色长条),为注意力机制提供输入。
第二版中就不一样了。
 注意力机制(Attention):学习 “文本特征→语音特征” 的动态对齐(如 “h” 对应语音的起始部分,“o” 对应结尾部分)。对解码器的所有输出应用注意力(Attention is applied to all decoder output),确保每个时间步的语音都能找到对应的文本位置,解决长文本的 “节奏匹配” 难题。
注意力机制(Attention):学习 “文本特征→语音特征” 的动态对齐(如 “h” 对应语音的起始部分,“o” 对应结尾部分)。对解码器的所有输出应用注意力(Attention is applied to all decoder output),确保每个时间步的语音都能找到对应的文本位置,解决长文本的 “节奏匹配” 难题。
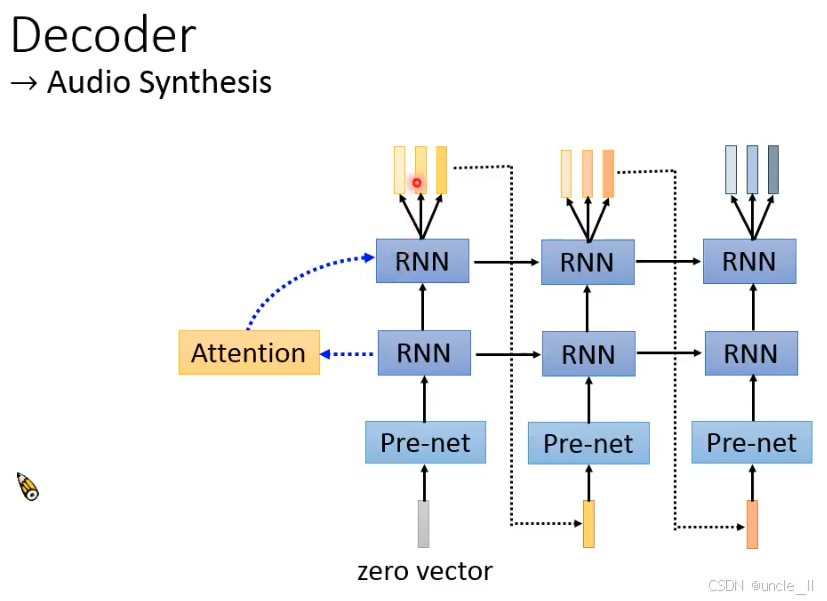
解码器(Decoder):特征→梅尔频谱
- 输入:注意力对齐后的文本特征 + 开始标记(,Begin of Speech)。
- Pre-net:与编码器的 Pre-net 结构类似,对输入特征降维、增加非线性。
- 多层 RNN:用堆叠的 RNN(循环神经网络)学习 “文本特征→梅尔频谱” 的映射,生成梅尔频谱序列。
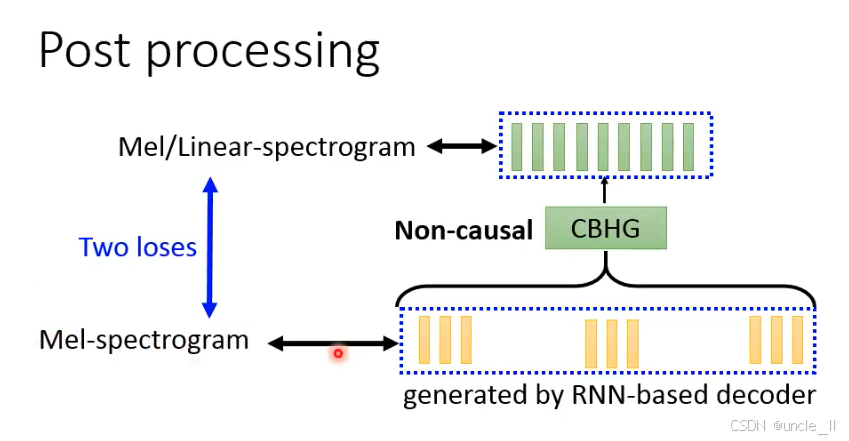
(1)RNN 解码器输出
RNN 解码器生成的初步梅尔频谱存在局限性(如依赖时序建模导致的局部韵律缺陷、频谱不光滑),需后处理优化。
(2)非因果 CBHG(Non-causal CBHG)
- 非因果(Non-causal):区别于编码器的 “因果 CBHG”(仅依赖历史 / 当前特征),非因果 CBHG 可访问未来时间步的特征(双向信息),更全面地优化频谱。
- CBHG 结构:与编码器一致(卷积银行 + 高速网络 + 双向 GRU),提取多尺度频谱特征,修复局部缺陷(如元音的共振峰不清晰、辅音的能量突变)。
(3)双损失优化(Two losses) - 梅尔频谱损失:直接优化 “初步梅尔频谱→优化后梅尔频谱” 的重建损失,确保基础频谱质量;
- 线性频谱损失:将优化后的梅尔频谱转换为线性频谱(更接近原始语音的频谱表示),进一步约束频谱细节,提升声码器生成波形的自然度。

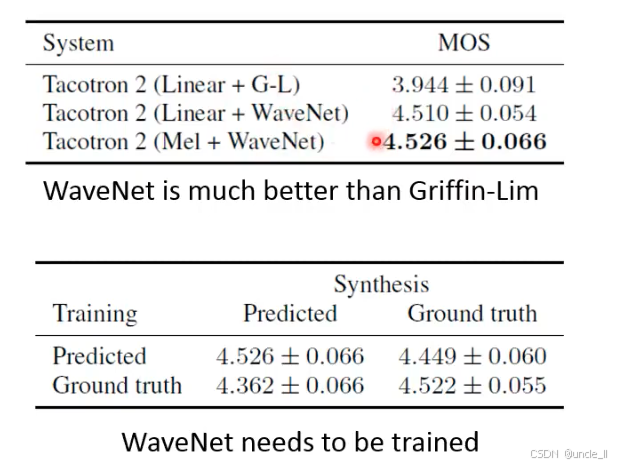
声码器(Vocoder):将优化后的梅尔频谱转换为时域波形(如 WaveNet、Griffin-Lim 算法),输出最终音频。
(1)Tacotron v1:Griffin-Lim 算法
- 原理:传统 “相位重建” 算法,通过迭代优化相位信息,从梅尔频谱恢复线性频谱,最终生成波形。
- 局限:
- 依赖 “相位猜测”,生成的语音常带有金属音、模糊感(相位信息丢失严重);
- 计算量大,难以实时合成。
(2)Tacotron v2:WaveNet 声码器
- 原理:深度学习声码器,直接学习 “梅尔频谱→波形” 的映射,生成高质量时域信号。
- 突破:
- 利用自回归模型捕捉波形的细微特征(如气流声、喉音),音质接近真人;
- 结合 Tacotron 的注意力机制,实现 “端到端” 高质量合成,摆脱传统声码器的缺陷。

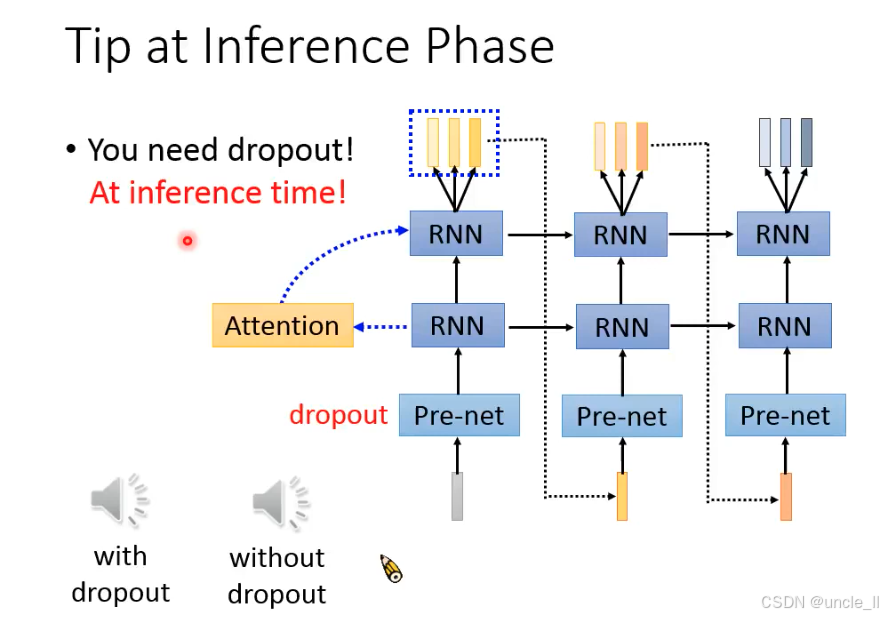
Tacotron 在推理阶段必须保留 dropout,通过在 Pre-net 输入中引入微小随机扰动,解决自回归生成中的 “注意力对齐失败” 和 “生成中断” 问题。
(1)With dropout
语音生成流畅,注意力对齐稳定(如每个文本字符对应正确的语音片段),无重复或中断。
(2)Without dropout
易出现注意力坍缩(如多个语音时间步锁定同一文本字符),导致语音重复(某音节无限循环)或提前终止(未生成完整文本)。
tracotron之外的方法
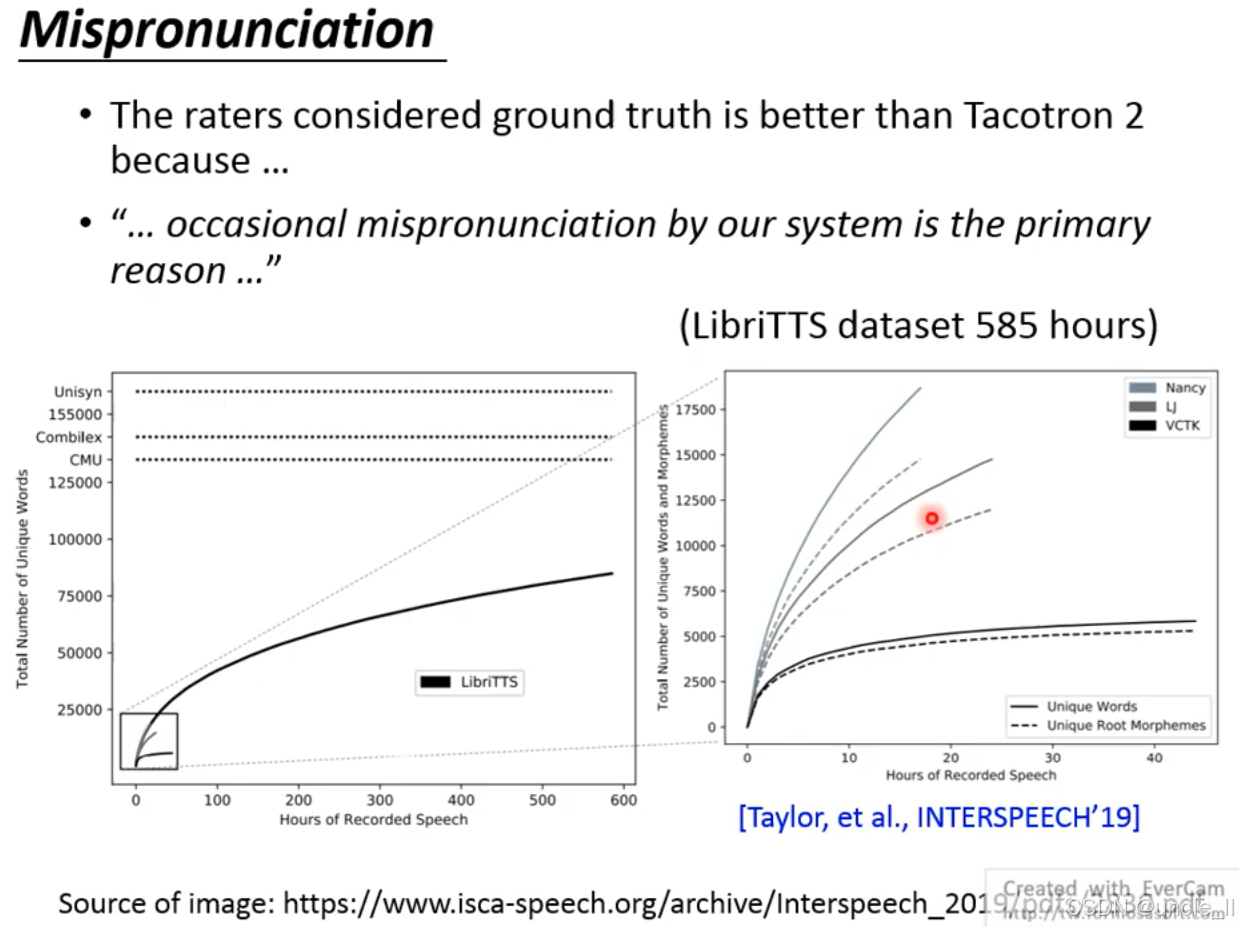
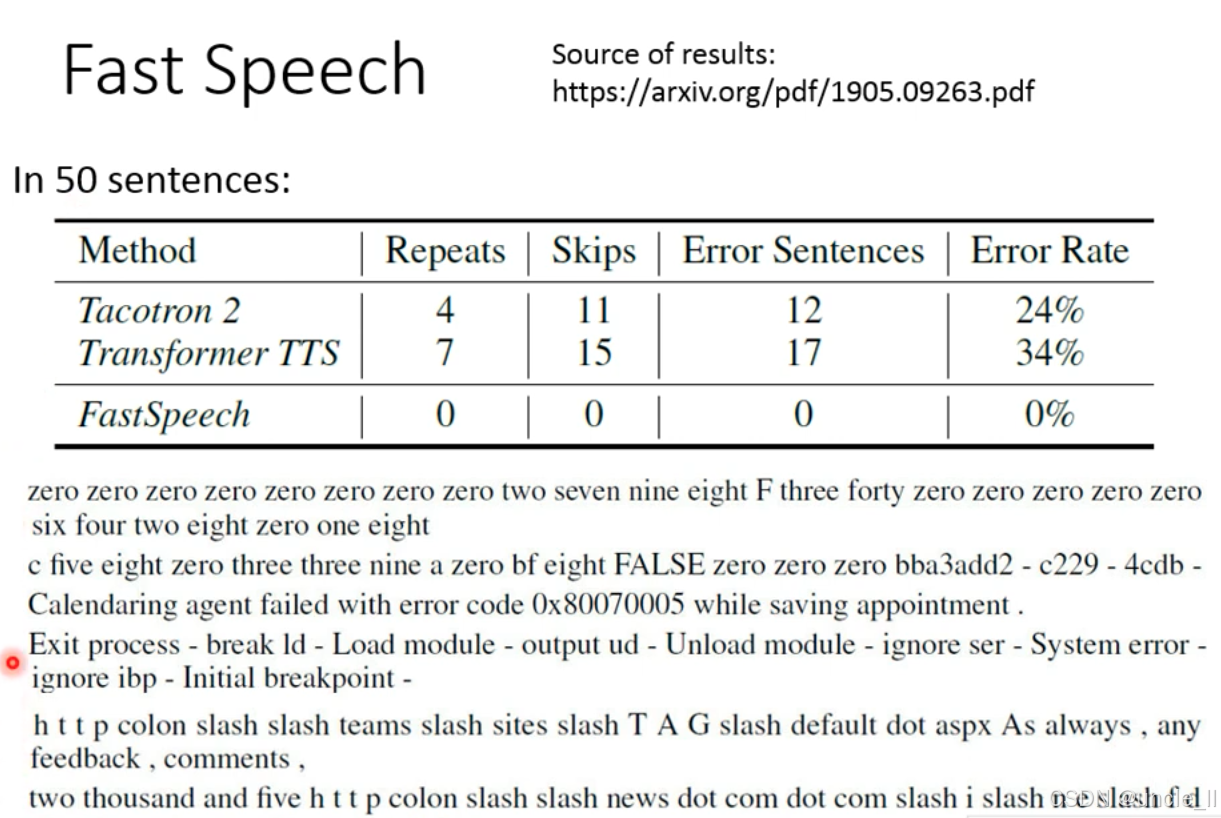
Tacotron 2 在语音合成中的 “发音错误(Mispronunciation)” 问题,导致其音质自然度低于真实录音(ground truth)。根本原因是模型对 “生僻词、复杂发音规则” 的学习不足,本质是训练数据的发音覆盖度有限。
随着录音时长增加,LibriTTS 数据集的 “唯一单词数” 逐渐饱和(曲线趋于平缓),但离覆盖所有英语单词(如 Unisyn、CMU 发音词典的单词量)仍有差距。即使增加录音时长,“词根 / 词素” 的覆盖度增长也会放缓,说明数据集难以覆盖语言的所有形态变化(如动词的时态变化、名词的复数形式)。
Tacotron 2 是数据驱动的端到端模型,其发音能力完全依赖训练数据:
- 若数据集中缺乏某单词的发音(如生僻词、专业术语),模型会 “猜发音”,导致错误;
- 复杂语言的形态变化(如英语的不规则动词、法语的连读)难以被有限的数据集完全覆盖。

使用发音词典(lexicon)将单词转换为音素序列(如 “What→W AH T”“is→IH Z”),再将音素作为 Tacotron 的输入,避免模型直接从字符学习发音规则。显式引入标准发音知识,减少 “猜发音” 导致的错误;解决拼写不规则语言(如英语)的发音问题(如 “through” 与 “tough” 的不同发音)。
问题是当遇到词典中不存在的词(如专业术语 “nCoV”、新造词、外来词)时,系统无法生成音素,导致发音失败。
改进方案:字符 - 音素混合输入(Hybrid Input)
同时输入字符(Character) 和音素(Phoneme),让模型同时学习:
- 字符的拼写模式(解决 OOV 词的发音猜测);
- 音素的标准发音(提升已知词的发音准确性)。
混合输入方案的核心是 “动态切换输入类型”—— 对已知词用音素(保证准确性),对 OOV 词用字符(保证可处理性),让模型在 “标准发音” 和 “泛化猜测” 间找到平衡。
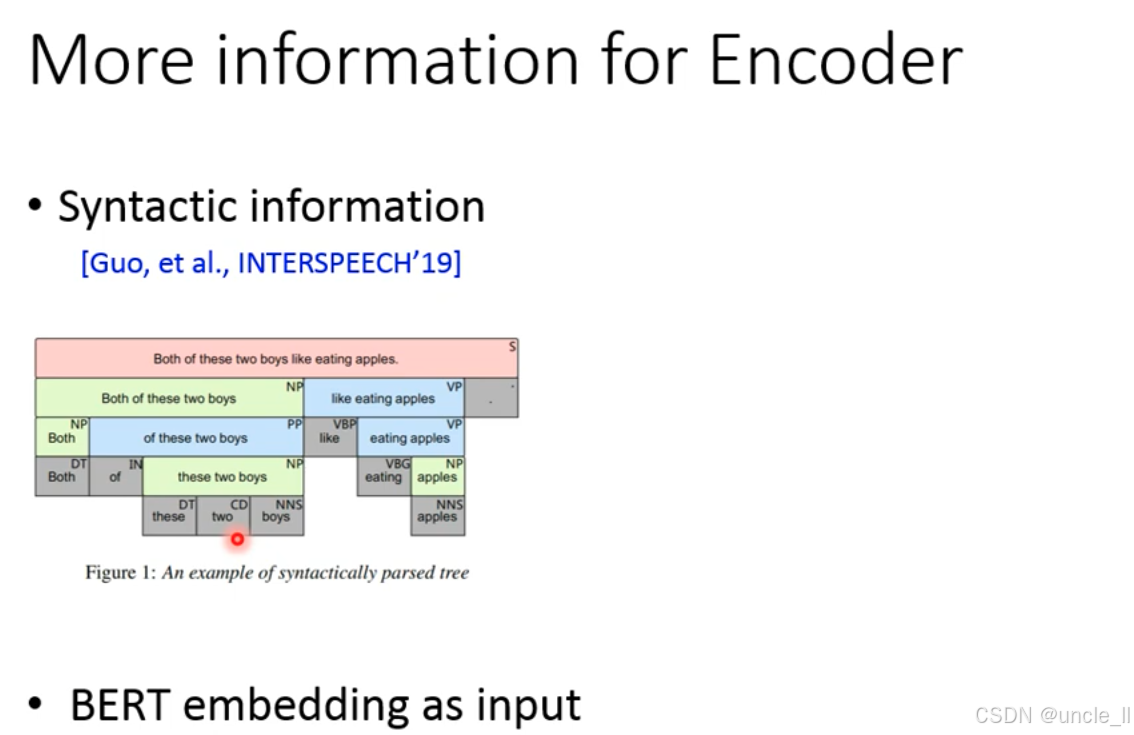
为 TTS 编码器(Encoder)注入更多信息,核心是通过引入句法信息(Syntactic information) 和BERT 语义嵌入(BERT embedding) 提升编码器对文本的理解,以下是详细解析:
TTS 的编码器需将文本转换为语音特征,但传统编码器仅依赖字符 / 音素信息,缺乏对语法结构、语义关联的理解。注入更多信息可:
- 提升语音合成的韵律自然度(如正确停顿、重音);
- 解决歧义句的正确发音(如 “Can you read ‘bass’ as a fish or a instrument?” 需根据语法判断重音)。
策略 1:注入句法信息(Syntactic information)
通过句法分析树(syntactically parsed tree) 提取文本的语法结构(如主谓宾、定状补),将语法标签(如 NP 名词短语、VP 动词短语)作为额外特征输入编码器。
示例解析(句子 “Both of these two boys like eating apples.”)
- 句法树分层标注:
- 顶层:S(句子)→ 分解为 NP(名词短语,主语 “Both of these two boys”)+ VP(动词短语,谓语 “like eating apples”);
- 底层:细化到词法标签(如 DT 限定词 “these”、CD 数词 “two”、NNS 名词复数 “boys”)。
- 编码器输入:字符 / 音素 + 句法标签,让模型学习 “语法结构→韵律” 的映射(如 NP 通常对应语音的重音部分,VP 对应谓语的流畅连读)。
策略 2:注入 BERT 语义嵌入(BERT embedding as input)
BERT 是预训练语言模型,可提取文本的深度语义特征(如词与词的关联、上下文歧义消解)。将 BERT 生成的词嵌入(word embedding)作为编码器输入,让模型利用大规模语料的语义知识。
- 解决语义歧义:如 “bank” 在 “river bank” 和 “bank account” 中的不同语义,BERT 嵌入可区分;
- 提升韵律与语义的匹配:如疑问句的句尾音高上升,BERT 可捕捉 “疑问语义” 并指导编码器生成对应韵律。
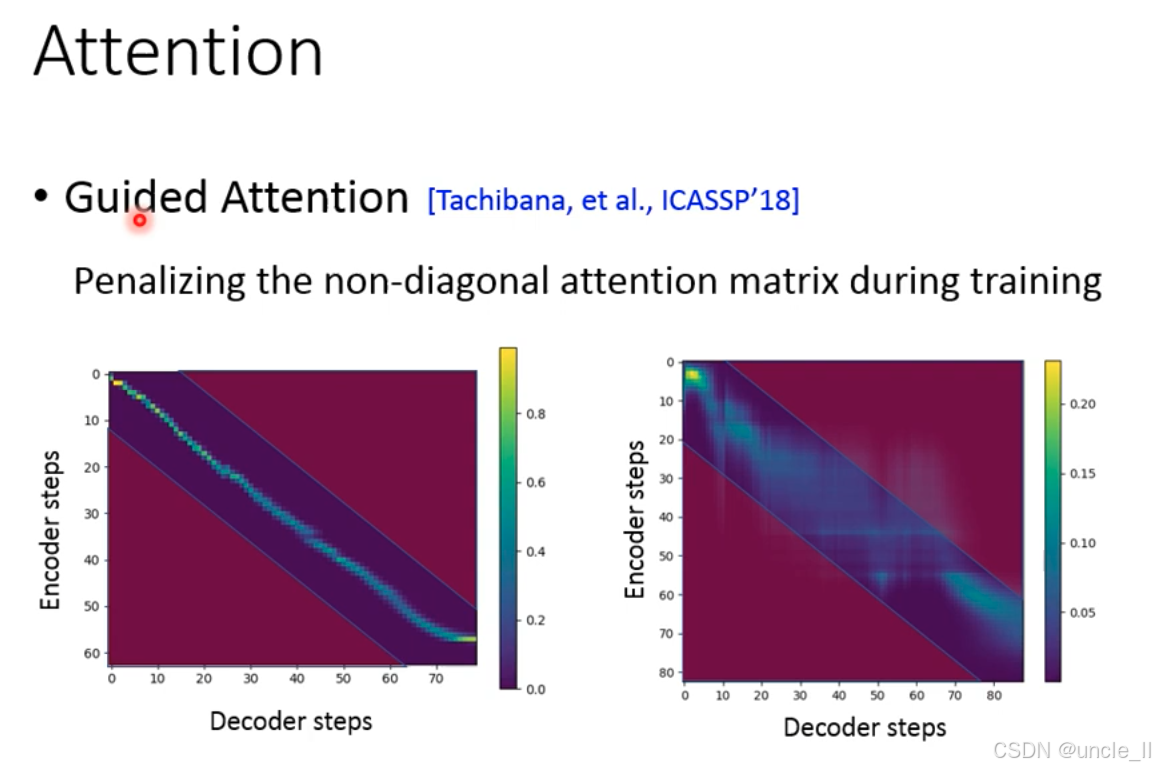
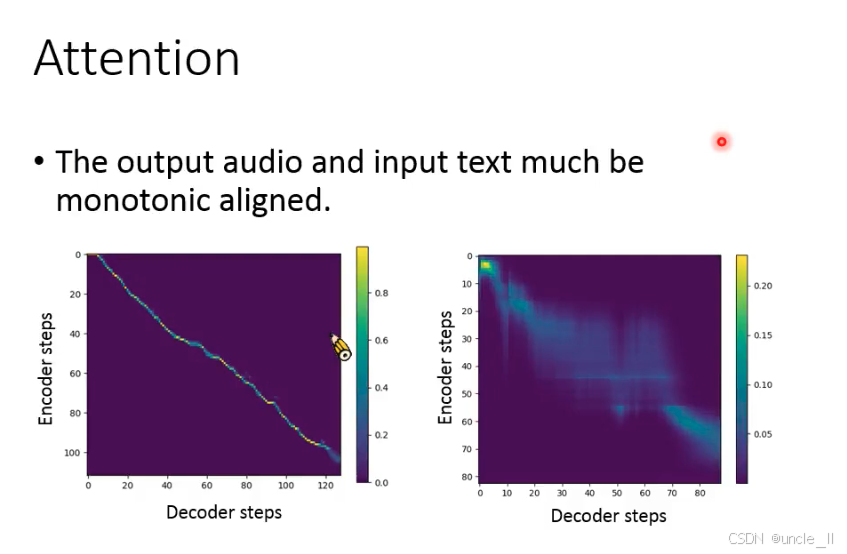
Tacotron 的注意力机制需学习 “编码器时间步(文本特征)” 与 “解码器时间步(语音特征)” 的对齐关系(对角线区域为理想对齐)。但训练初期,注意力可能随机分散(非对角线区域激活),导致:
- 语音生成重复 / 中断(如解码器时间步锁定错误的编码器时间步);
- 模型收敛慢,甚至无法对齐长文本。
引导注意力(Guided Attention),训练时显式惩罚非对角线区域的注意力权重,强制模型优先对齐对角线区域(理想的文本 - 语音时序对应)。
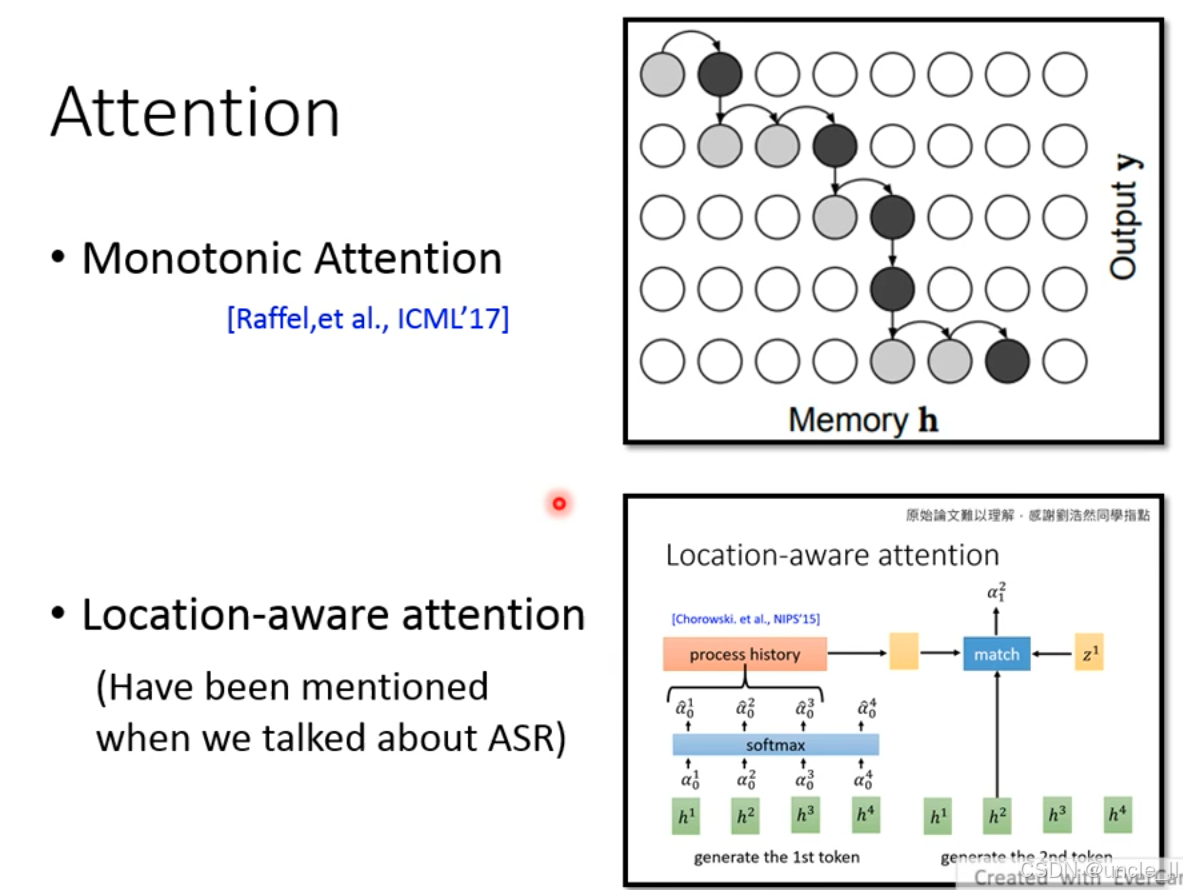
另外两种重要的注意力机制优化策略 ——单调注意力(Monotonic Attention) 和位置感知注意力(Location-aware attention),核心解决 “文本 - 语音 / 语音 - 文本对齐” 的稳定性问题:
一、策略 1:单调注意力(Monotonic Attention)
强制注意力权重单调递增移动(如解码器时间步只能从左到右遍历编码器时间步,不能回退),适用于严格时序对齐的任务(如语音合成、语音识别)。
-
Memory h:编码器输出的文本 / 语音特征序列(横轴);
-
Output:解码器生成的语音 / 文本特征序列(纵轴);
-
黑色节点:注意力权重的移动路径,严格沿对角线从左上到右下,体现 “单调递增” 的对齐约束。
-
优势:避免注意力 “来回跳转” 导致的生成重复 / 中断,对齐稳定;
-
局限:仅适用于 “严格时序对应” 的任务(如朗读式 TTS),无法处理 “灵活韵律”(如诗歌的倒装句)。
二、策略 2:位置感知注意力(Location-aware attention)
在计算注意力权重时,显式引入 “历史注意力位置” 作为特征,让模型学习 “注意力应该关注的位置趋势”,解决以下问题:
-
ASR 中:语音帧的时序波动(如说话人语速变化);
-
TTS 中:文本韵律的灵活变化(如长句的停顿位置)。
-
h¹~h⁴:编码器生成的语音特征(横轴,对应 “generate the 1st token”);
-
α̂:原始注意力权重,通过softmax 归一化;
-
process history:历史注意力位置的特征(如前一时间步关注 h²,当前更倾向关注 h³);
-
match:结合历史位置与当前特征,生成新的注意力权重(如 z¹ 对应生成第 2 个 token 时的对齐)。
将 “位置感知” 机制迁移到 TTS,让解码器在生成语音时:
-
参考 “历史注意力位置”(如前一个音素的对齐位置);
-
灵活调整当前注意力的关注区域(如长元音的拖尾、短辅音的快速跳过)。
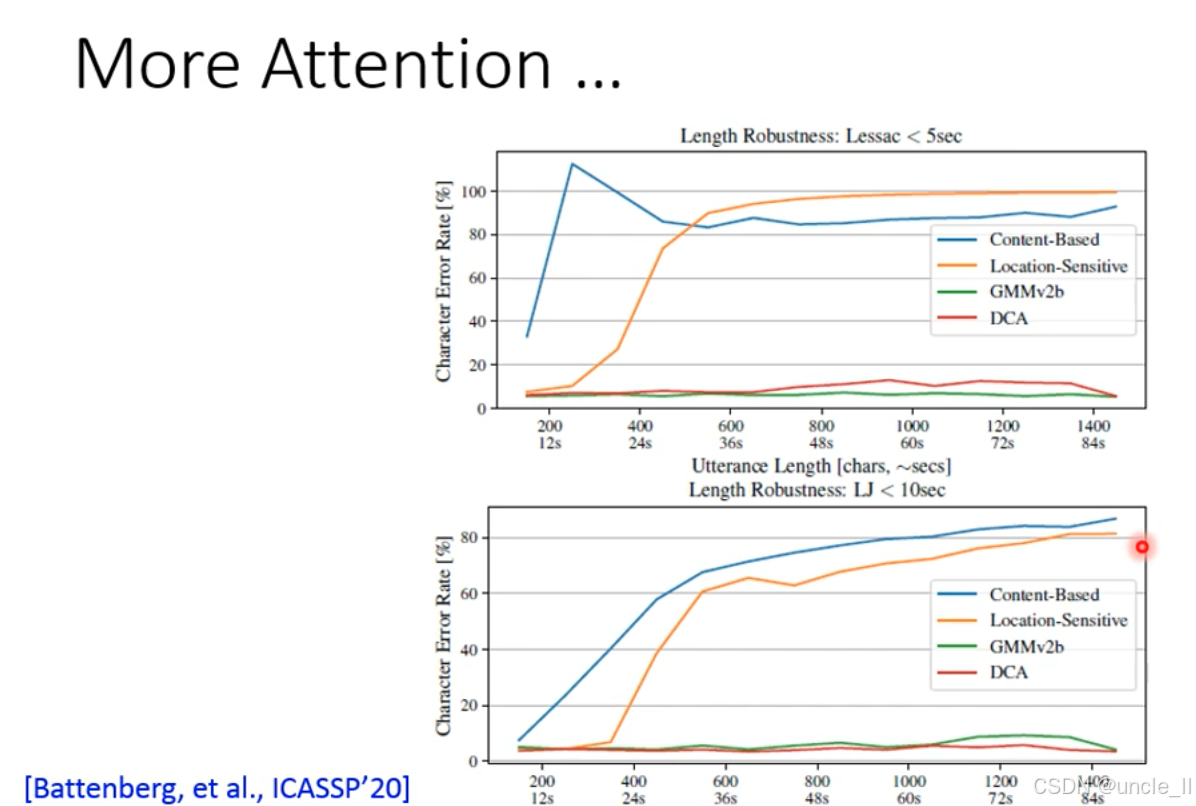
(1)数据集 -
Lessac <5sec:短文本数据集(最长约 1400 字符,84 秒);
-
LJ <10sec:较长文本数据集(最长约 1400 字符,84 秒)。
(2)注意力策略
- Content-Based:纯内容驱动的注意力(无显式位置约束);
- Location-Sensitive:位置敏感注意力(参考历史位置,如前图的 Location-aware);
- GMMv2b:基于高斯混合模型的注意力;
- DCA:动态卷积注意力(Dynamic Convolution Attention,更复杂的位置约束)。
GMMv2b/DCA:CER 始终维持在低水平,证明强位置约束的注意力更适合长文本。
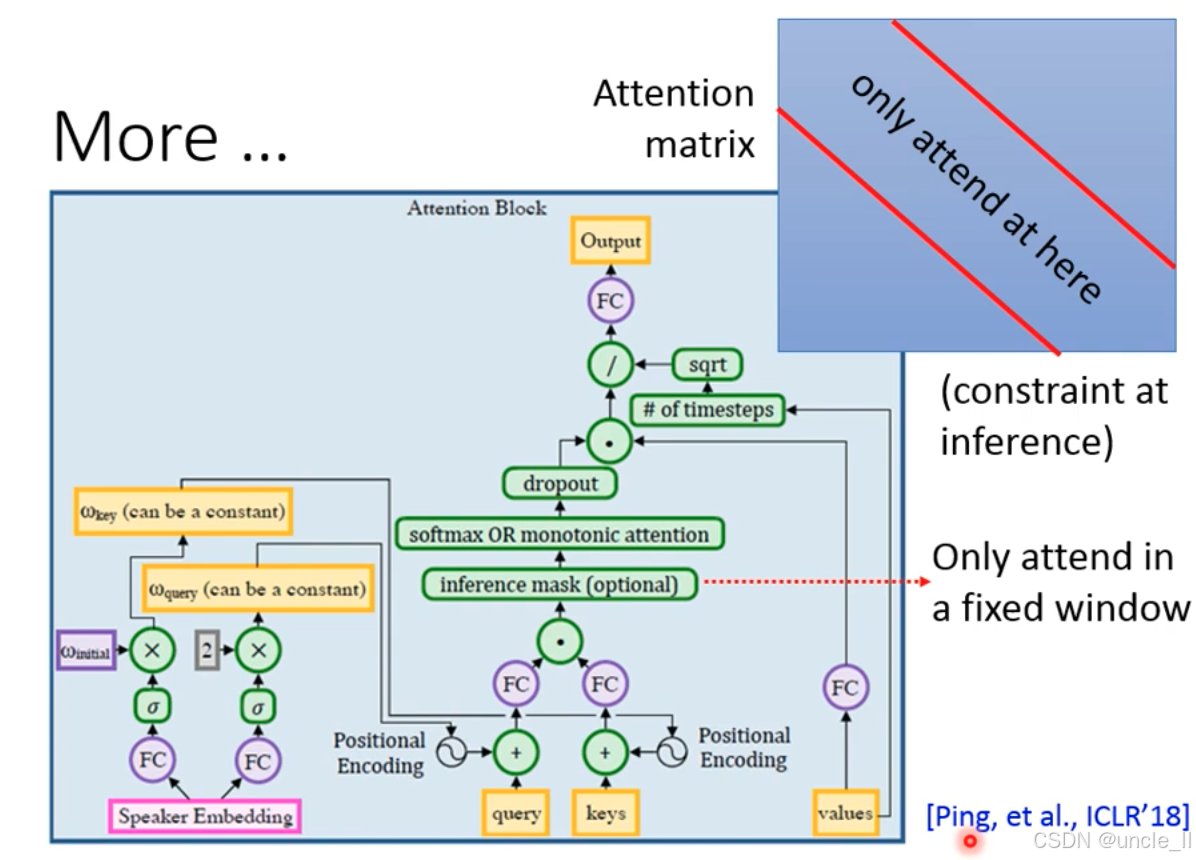
推理时通过inference mask限制注意力范围,仅允许在固定窗口(fixed window) 内对齐(如右侧蓝色框 “only attend at here”),解决长文本对齐漂移问题。
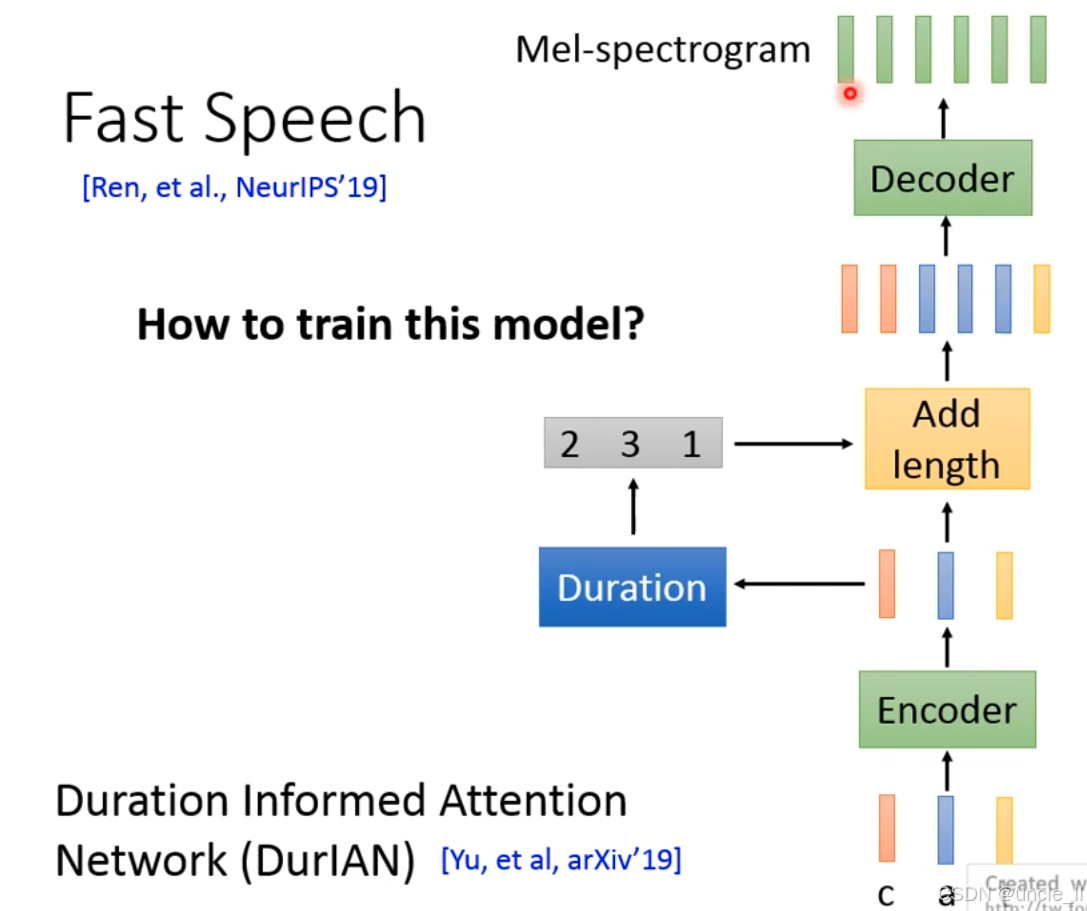
FastSpeech(核心是通过时长信息(Duration) 实现非自回归语音合成,解决传统 TTS 的 “生成速度慢” 问题。
传统 TTS(如 Tacotron)是自回归模型(解码器逐时间步生成语音,速度慢),FastSpeech 通过非自回归设计(一次性生成所有语音特征)实现实时合成,
-
编码器(Encoder):输入文本(字符 / 音素),生成文本特征序列(图中 “c a t” 等字符的高维表示)。
-
时长预测(Duration)
-
预测每个文本单元(如音素、字符)的持续时长(如 “c” 对应 2 帧,“a” 对应 3 帧,“t” 对应 1 帧);
-
输出时长序列(如 [2, 3, 1]),决定语音的 “语速” 和 “韵律节奏”。
-
-
添加时长(Add length)
-
根据时长序列,将编码器输出的文本特征扩展到对应长度(如 “c” 的特征重复 2 次,“a” 重复 3 次,“t” 重复 1 次);
-
生成 “扩展后的文本特征序列”,为解码器提供非自回归的输入。
-
-
解码器(Decoder):接收扩展后的文本特征,一次性生成完整的梅尔频谱(Mel-spectrogram),无需逐时间步依赖。
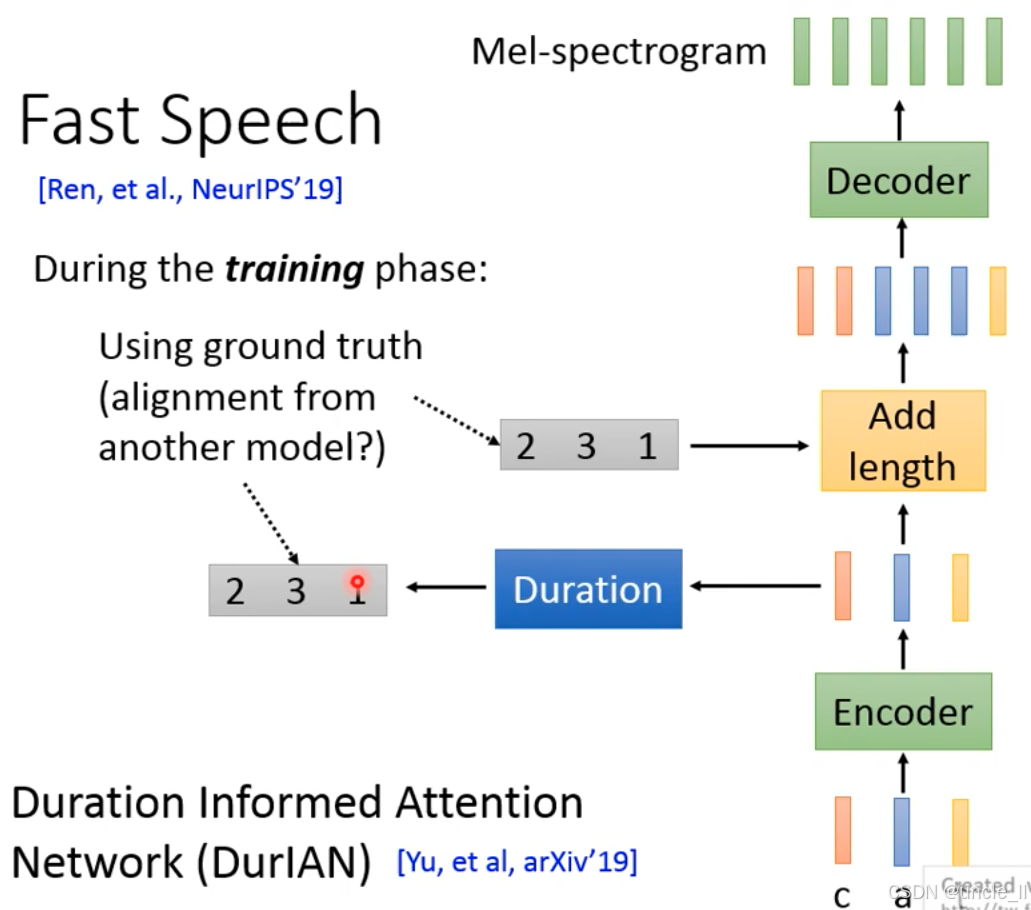
FastSpeech的训练阶段细节的核心是如何通过 “真实时长标注(ground truth duration)” 训练模型学习 “文本→语音时长” 的映射,解决非自回归合成的 “时长预测难题”。
(1)真实时长的来源(ground truth duration)
- 传统方法:用自回归 TTS 模型(如 Tacotron) 生成 “文本→语音” 的对齐关系(Attention Matrix),从中提取每个文本单元的真实时长(如 “c” 对应 2 帧,“a” 对应 3 帧,“t” 对应 1 帧);
- 暗示真实时长需依赖其他模型(如 Tacotron)的对齐结果,这是 FastSpeech 训练的 “间接监督” 特点。
(2)时长预测与监督
- Duration 模块:预测每个文本单元的时长(如 [2, 3, 1]);
- 监督信号:用 “真实时长标注”(从 Tacotron 对齐中提取)监督 Duration 模块的训练,让模型学习 “文本→真实时长” 的映射。
(3)添加时长(Add length)
-
根据预测的时长(或真实时长,训练阶段),将编码器输出的文本特征扩展到对应长度(如 “c” 的特征重复 2 次,“a” 重复 3 次);
-
扩展后的特征输入解码器,生成梅尔频谱(Mel-spectrogram)。
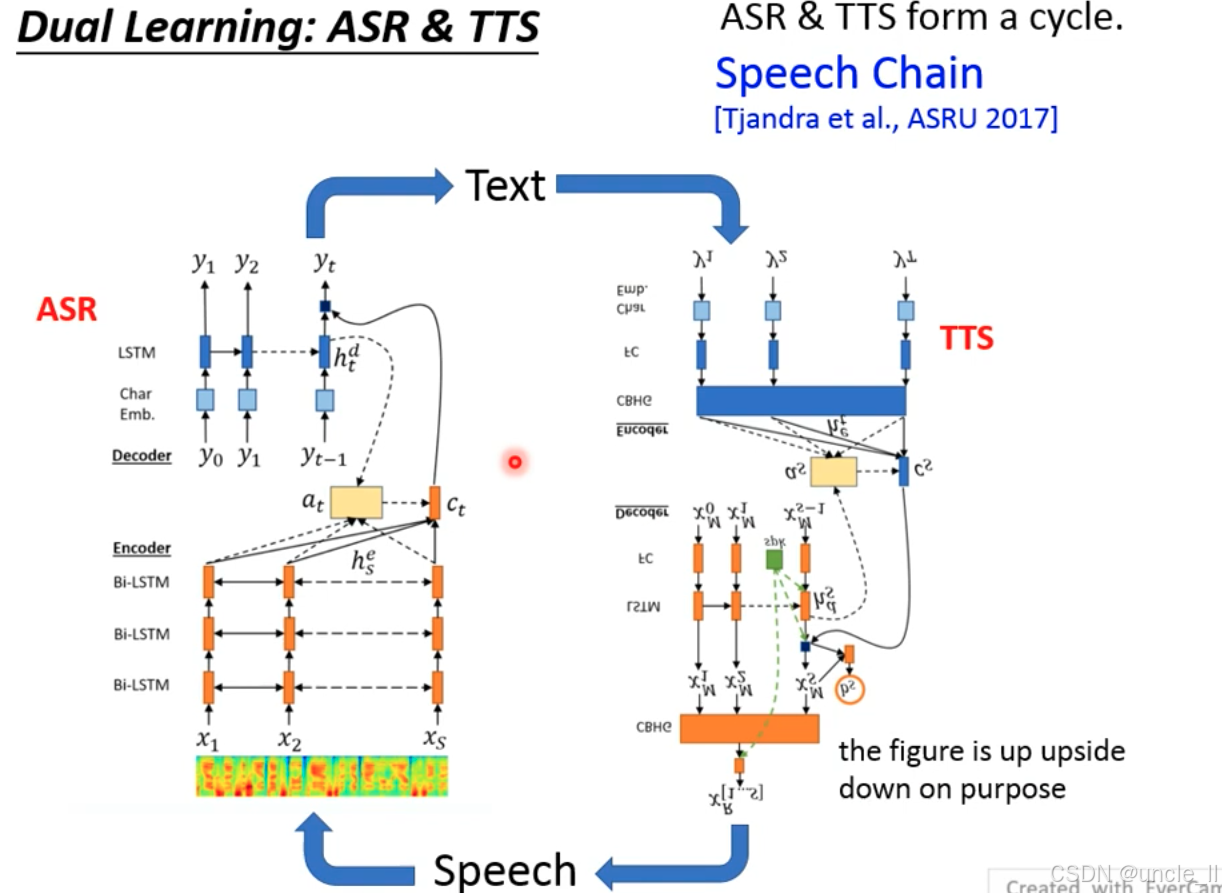
双学习(Dual Learning)框架下的 ASR 与 TTS 循环,核心模拟人类的 “语音链(Speech Chain)”——ASR 将语音转文本,TTS 将文本转语音,形成闭环,通过 ASR 和 TTS 的循环,让模型学习: -
ASR:从语音(Speech)中提取文本(Text);
-
TTS:从文本(Text)中生成语音(Speech);
-
闭环优化:用 TTS 生成的语音反馈优化 ASR,反之亦然。
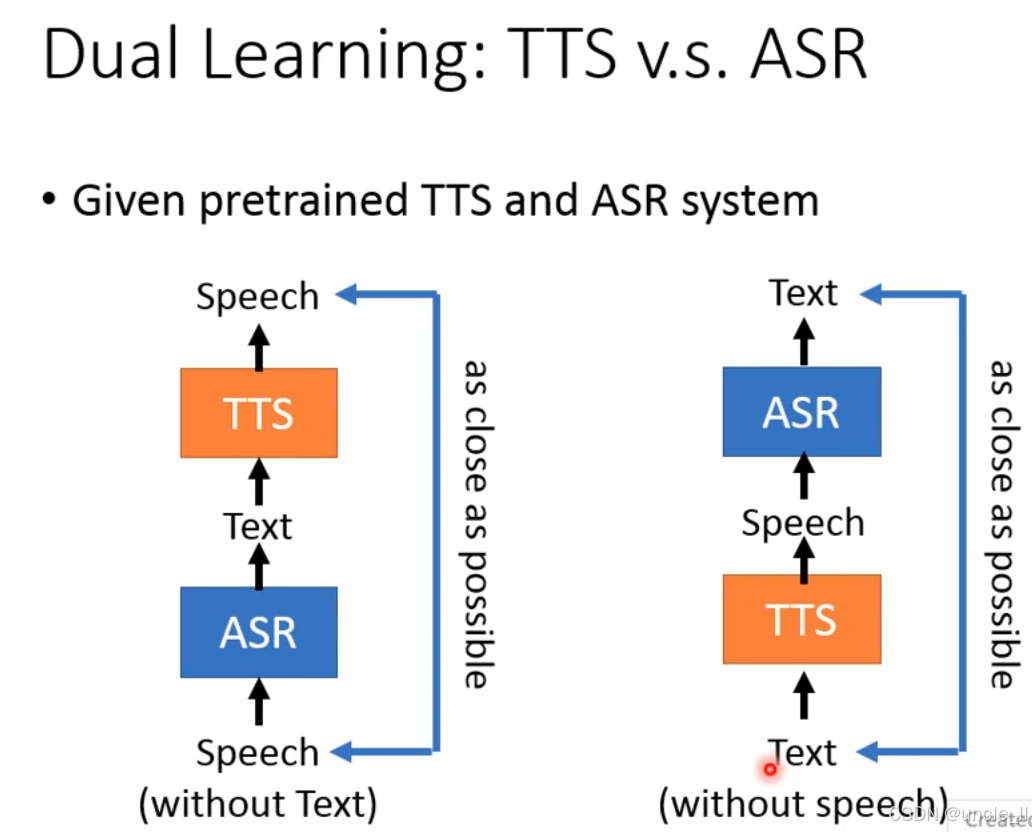
双学习的前提是预训练的基础模型:
- 先用少量标注数据预训练 TTS 和 ASR;
- 再用双学习的闭环,在无标注数据上持续优化,实现 “小数据→大数据” 的自监督扩展。
可被控制的TTS
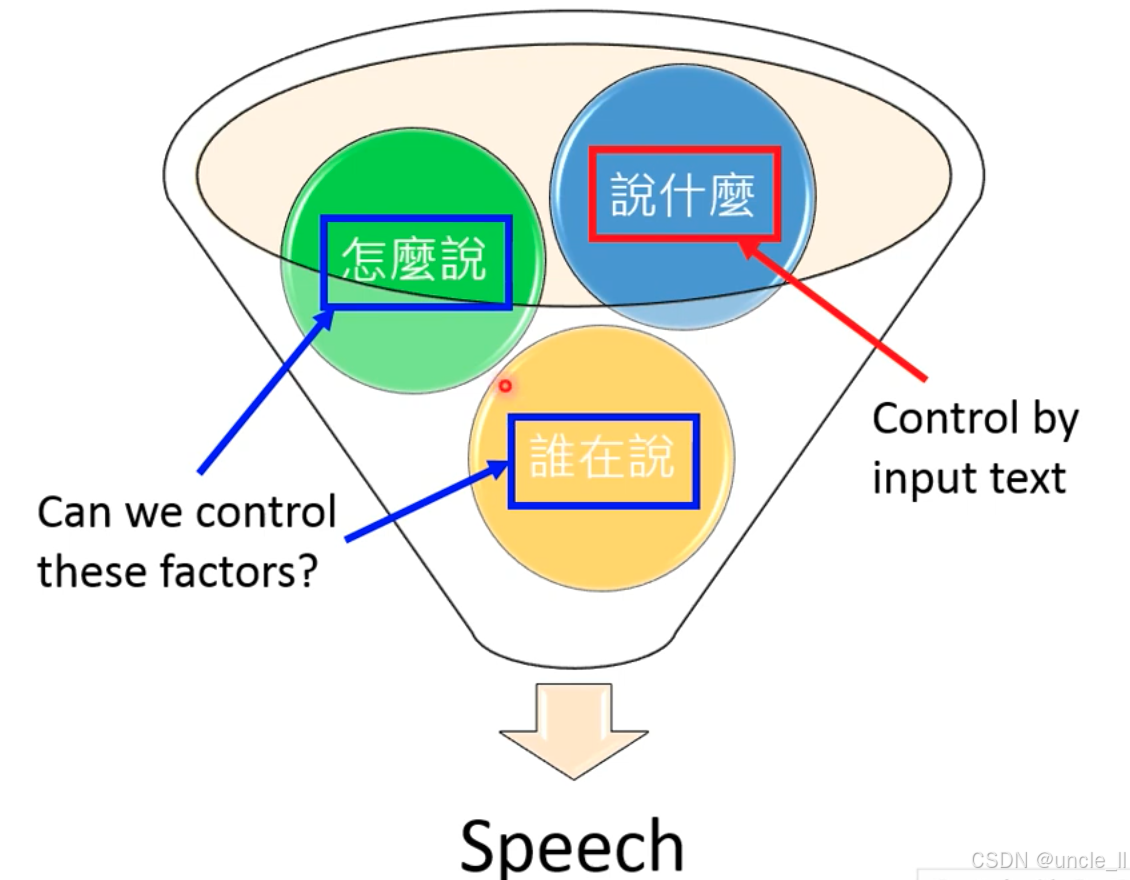

可控文本转语音(Controllable TTS) 的两大核心问题 ——“谁在说?(说话人控制)” 和 “怎么说?(韵律控制)”:
**一、核心问题 1:“谁在说?”—— 说话人克隆(**Voice Cloning)
生成特定说话人的语音(如克隆某人的音色、口音),实现个性化 TTS(如语音助手模仿用户音色)。
- 数据稀缺:训练高质量单说话人模型需要大量高质量录音(如 10 小时以上),但实际中难获取;
- 泛化性:小数据训练的模型易过拟合,导致合成语音不自然或无法适配新文本。
二、核心问题 2:“怎么说?”—— 韵律控制(Prosody Control)
控制维度
- 语调(Intonation):语音的高低变化(如疑问句尾音高上升);
- 重音(Stress):语音的强弱变化(如 “我爱中国” 中 “爱” 的重音);
- 韵律(Rhythm):语音的节奏变化(如诗歌的押韵、停顿);
- 整体韵律(Prosody):上述要素的综合,决定语音的 “情感与风格”(如悲伤时语调低沉、节奏缓慢)。
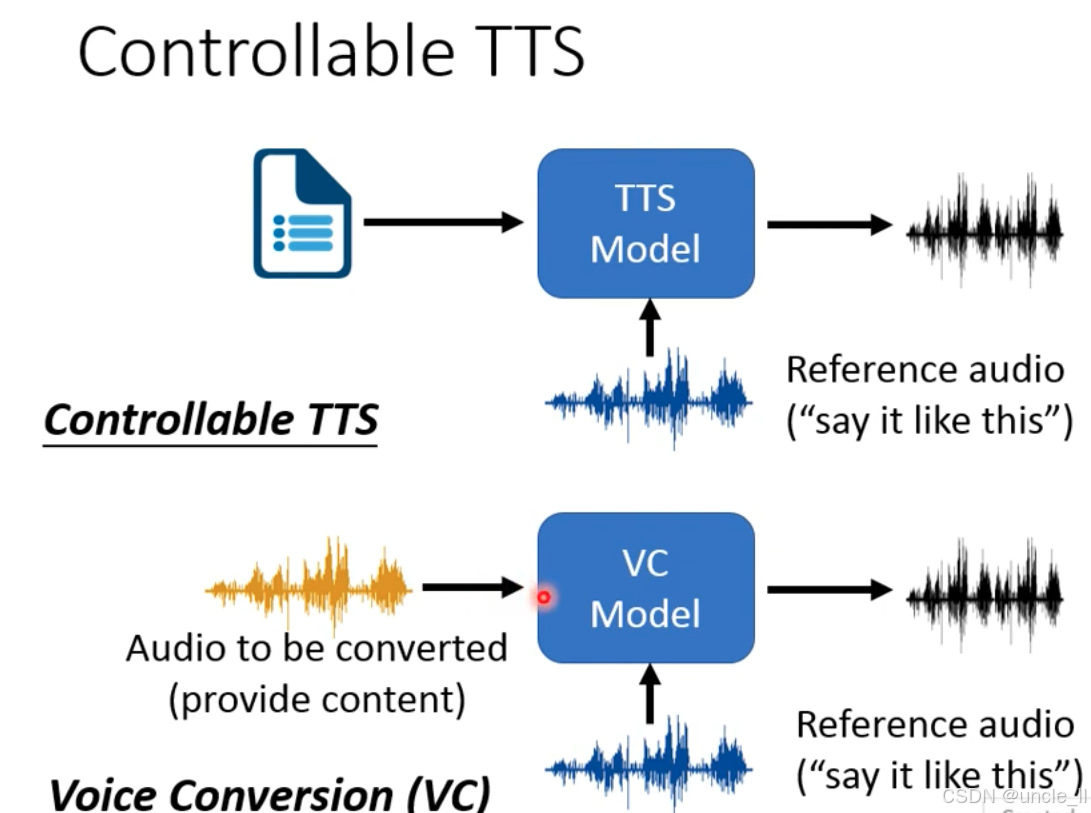
可控 TTS vs 语音转换(VC)
两者都通过参考音频控制语音的 “风格 / 音色 / 韵律”,但输入和目标不同:
| 技术 | 输入 | 目标 | 核心逻辑 |
|---|---|---|---|
| 可控 TTS | 文本(Text)+ 参考音频 | 生成 “文本内容 + 参考音频风格” 的语音 | 文本→语音,风格由参考音频控制 |
| 语音转换(VC) | 音频(Audio)+ 参考音频 | 转换 “原有音频内容 + 参考音频风格” 的语音 | 音频→音频,保留内容、替换风格 |
可控 TTS
-
输入
-
文本(Text):需要合成的内容(如 “今天天气很好”);
-
参考音频(Reference audio):包含目标风格(如 “温柔的语调”“特定人的音色”),标注为 “say it like this”。
-
-
流程:TTS 模型接收 “文本 + 参考音频”,生成 “文本内容按参考风格合成的语音”(如 “今天天气很好” 用 “温柔语调” 说出)。
语音转换(VC)
-
输入
-
待转换音频(Audio to be converted):包含原始内容(如某人说 “今天天气很好” 的音频);
-
参考音频(Reference audio):包含目标风格(如 “温柔的语调”“特定人的音色”),标注为 “say it like this”。
-
-
流程:VC 模型接收 “原有音频内容 + 参考音频风格”,生成 保留原始内容、替换为参考风格” 的语音(如把 “今天天气很好” 的 “生硬语调” 换成 “温柔语调”)。
两者都基于 “内容与风格解耦” 的思想:
- 内容:TTS 中是文本,VC 中是原有音频的语义;
- 风格:由参考音频提供,通过模型解耦并重组,实现 “内容不变、风格可控”。
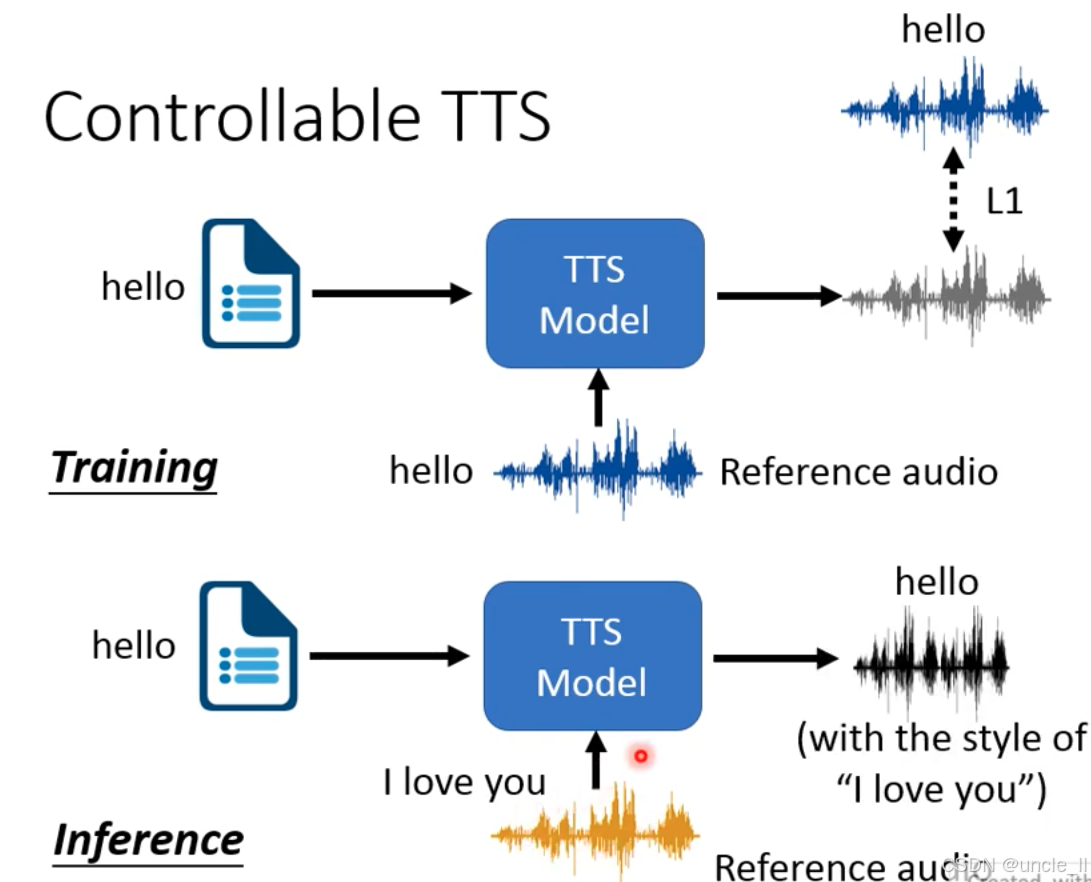
训练阶段(Training):学习风格映射
-
输入
-
文本:相同内容(如 “hello”);
-
参考音频:对应文本的目标风格音频(如 “hello” 的温柔语调音频)。
-
-
流程: TTS 模型接收 “文本 + 参考音频”,学习 “文本内容→参考风格音频” 的映射。
-
优化目标:通过L1 损失让模型生成的音频尽可能接近参考音频,学习到风格特征(如语调、韵律)。
推理阶段(Inference):风格迁移
-
输入
-
新文本:内容不同(如 “hello”);
-
参考音频:风格不同的音频(如 “I love you” 的兴奋语调音频)。
-
-
流程:TTS 模型接收 “新文本 + 参考音频”,生成 “新文本内容按参考风格合成的语音”(如 “hello” 用 “ I love you” 的兴奋语调说出)。
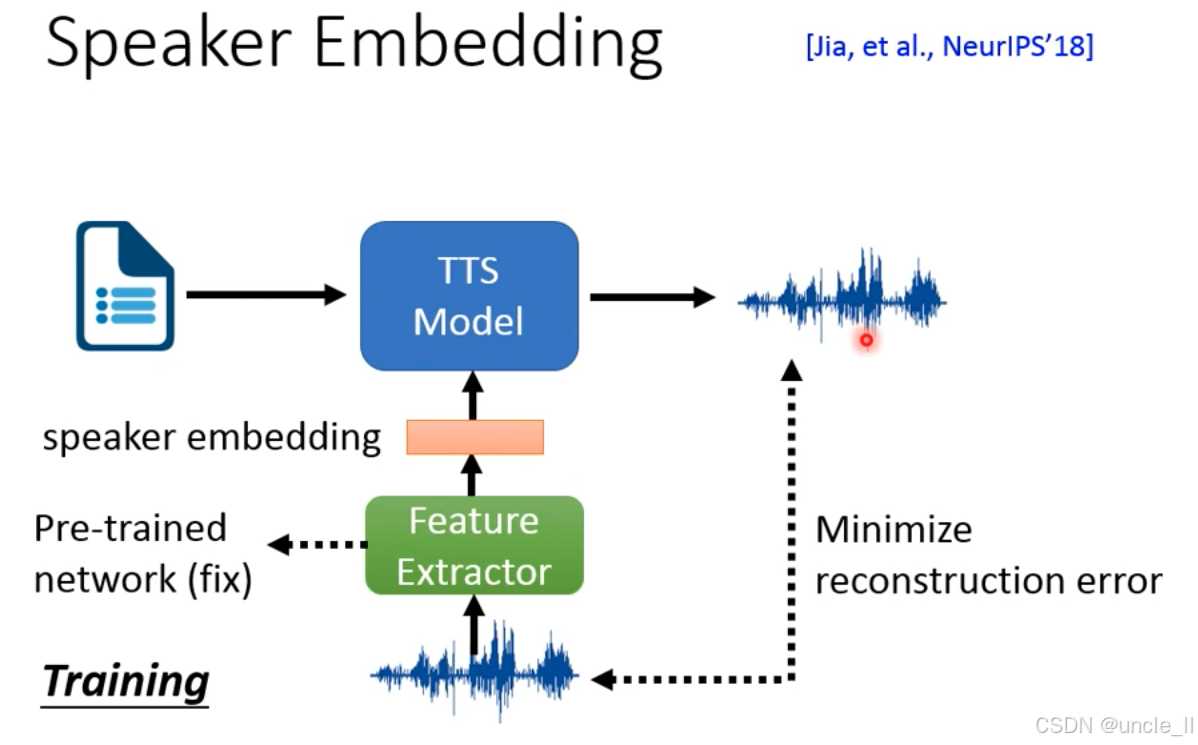
让 TTS 模型生成特定说话人的语音(如模仿用户音色),通过 “说话人嵌入” 编码说话人特征。
-
模块组成
-
Feature Extractor:预训练的特征提取网络(如说话人识别模型,参数固定),提取语音的说话人嵌入(speaker embedding);
-
TTS Model:文本转语音模型,接收 “文本 + 说话人嵌入”,生成对应语音;
-
Pre-trained network:预训练的说话人识别模型,提供稳定的特征提取能力。
-
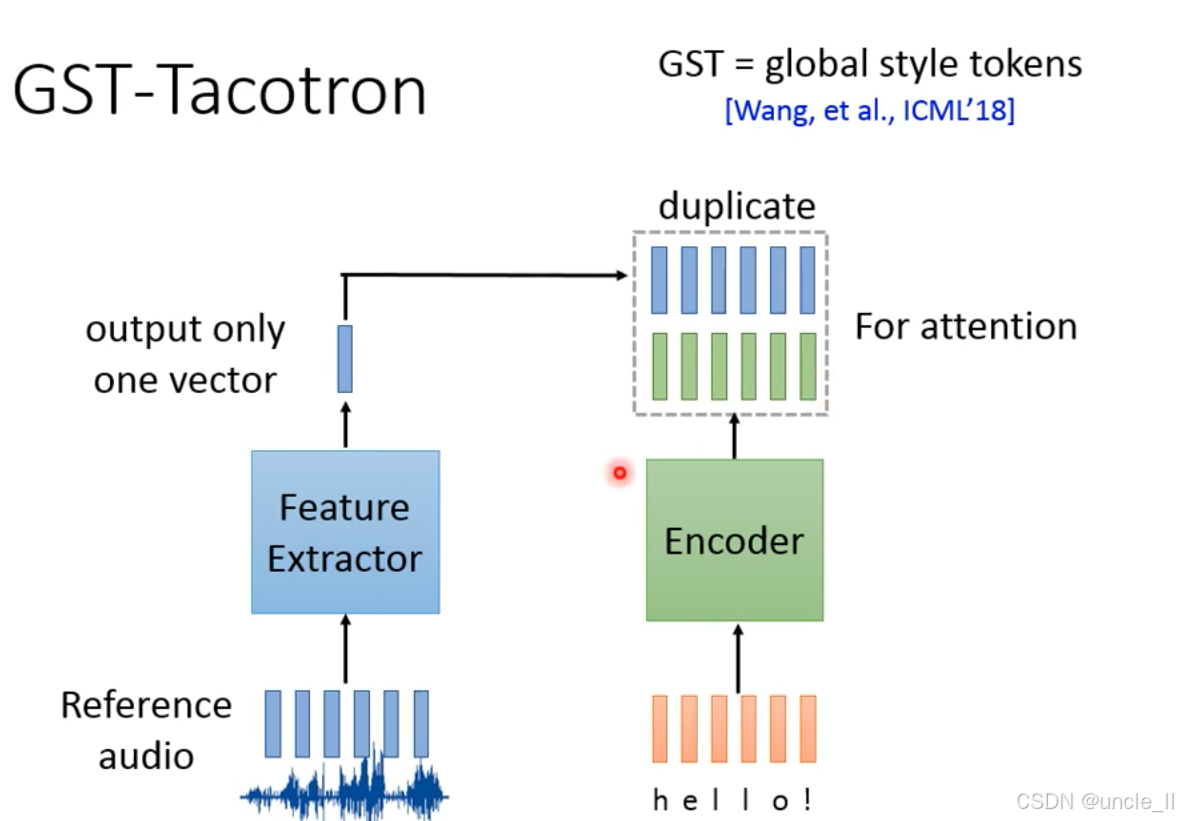
GST-Tacotron的核心模块 ——全局风格令牌(Global Style Tokens, GST),用于控制 TTS 的语音风格,以下
模块组成:
-
风格特征提取(Feature Extractor)
-
输入:参考音频(如一段温柔语调的语音);
-
输出:一个风格向量(output only one vector),编码参考音频的风格特征(如温柔、欢快)。
-
-
文本编码(Encoder)
-
输入:文本(如 “hello!”);
-
输出:文本的高维特征,为注意力机制做准备。
-
-
风格令牌复制(duplicate)
-
将提取的单个风格向量复制为多组风格令牌(图中蓝色、绿色向量组);
-
作用:为注意力机制提供多组风格参考,让模型学习 “文本特征→风格特征” 的对齐。
-
-
注意力机制(For attention)
- 风格令牌与文本特征通过注意力机制对齐,让 TTS 生成的语音同时匹配文本内容和参考风格。
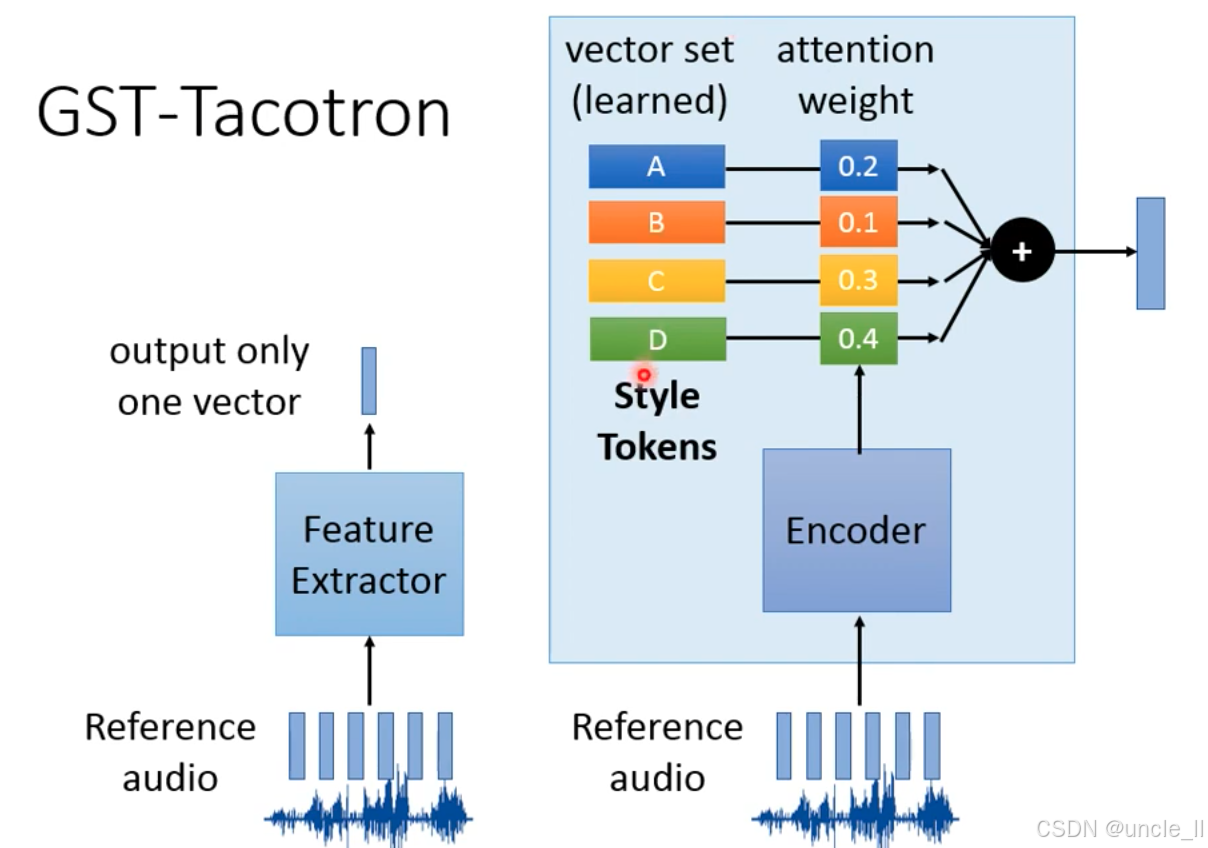
通过预定义的风格令牌(Style Tokens) 和注意力权重,让模型学习 “参考音频→风格令牌混合→语音风格” 的映射,实现灵活的风格控制。
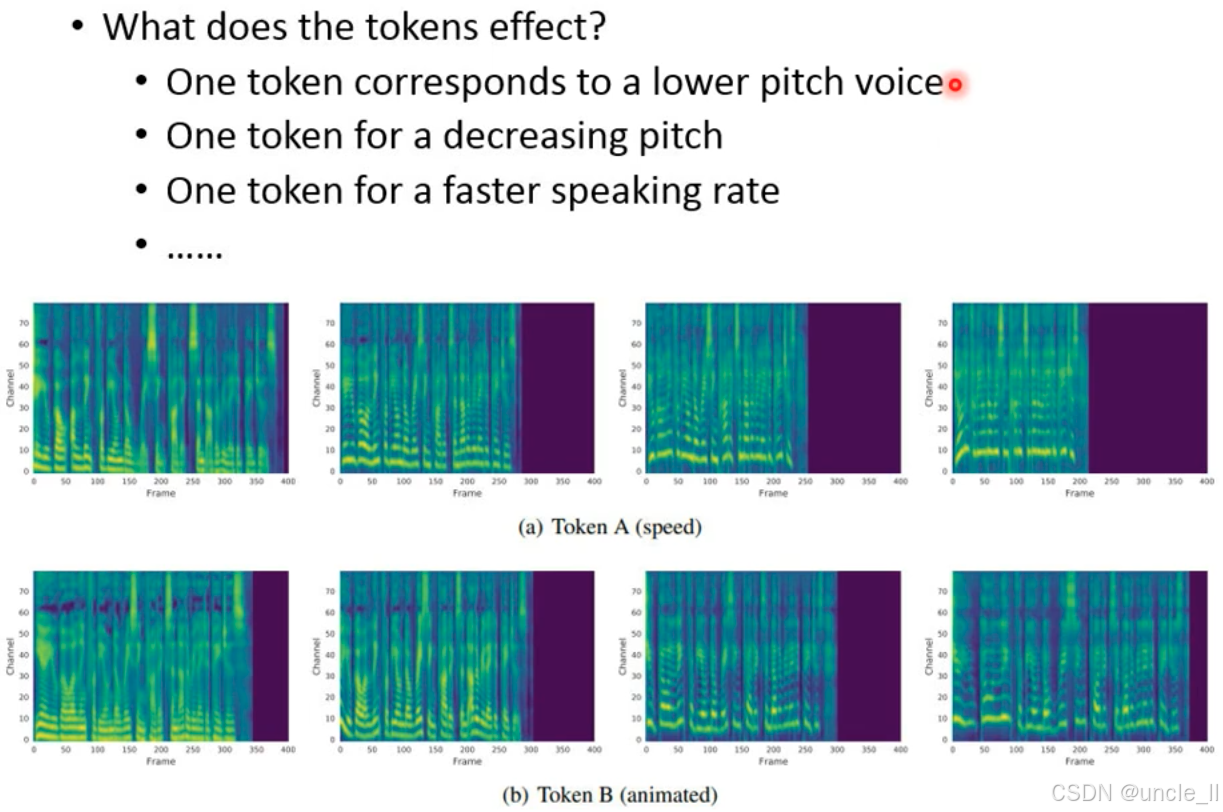
- 风格令牌与文本特征通过注意力机制对齐,让 TTS 生成的语音同时匹配文本内容和参考风格。
每个风格令牌学习到特定语音特征的控制维度:
- 语速(speed):控制语音的时间压缩 / 拉伸;
- 音调(pitch):控制语音的高低变化;
- 生动度(animated):控制语音的情感表达强度。
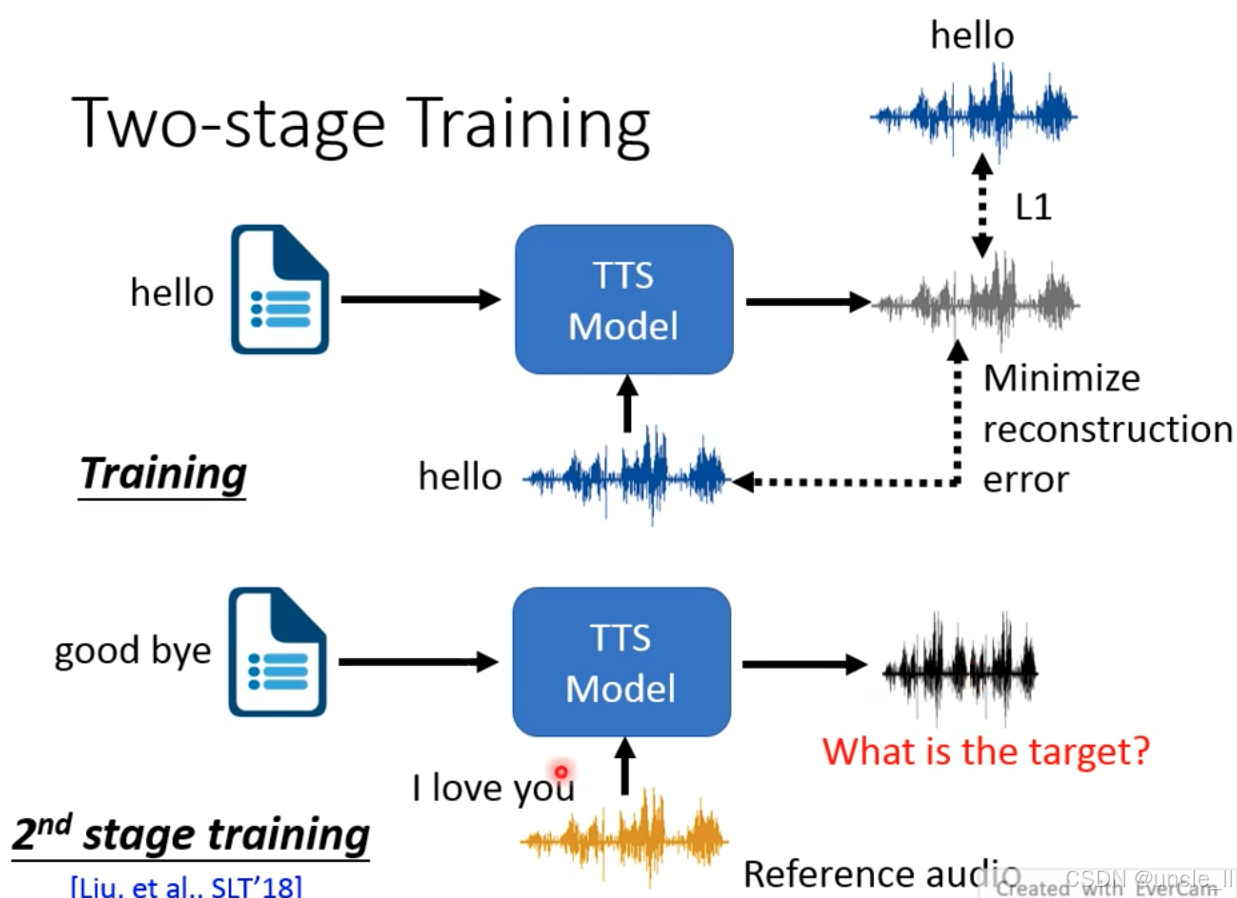
第一阶段训练(Training):基础 TTS 训练
-
输入
-
文本:与参考音频内容一致(如 “hello”);
-
参考音频:对应文本的语音(如 “hello” 的录音)。
-
-
流程
- TTS 模型学习 “文本→参考音频” 的映射,通过最小化重建误差(合成音频与参考音频的差异)优化模型,目标是让模型生成与参考音频一致的语音。
第二阶段训练(2nd stage training):跨文本风格迁移
-
输入
-
新文本:内容不同(如 “good bye”);
-
参考音频:风格不同的语音(如 “I love you” 的录音)。
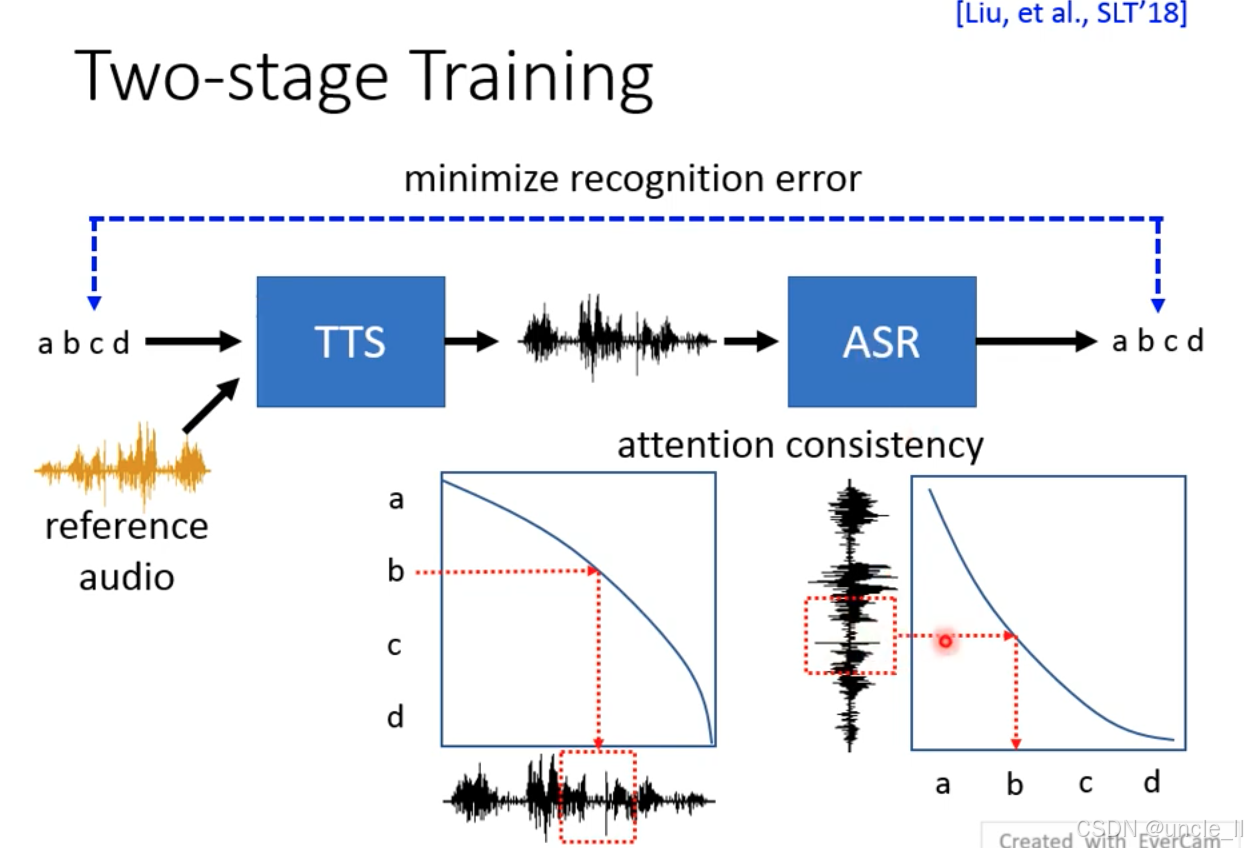
-
-
流程:
- 通过ASR(自动语音识别)构建闭环监督,解决跨文本风格迁移的 “目标不明确” 问题