【图像算法 - 15】智能行李识别新高度:基于YOLO12实例分割与OpenCV的精准检测(附完整代码)
摘要: 从机场托运行李到智能行李箱追踪,行李检测是智慧交通与物联网的关键环节。本文将带您利用YOLO12实例分割模型结合OpenCV,实现对行李箱的像素级精准识别与轮廓提取。我们将完成从环境搭建、模型推理到结果可视化与信息量化的全流程,代码清晰,即学即用!
关键词: YOLO12, 实例分割, 行李箱检测, OpenCV, 计算机视觉, 深度学习, Python
【图像算法 - 15】智能行李识别新高度:基于YOLO12实例分割与OpenCV的精准检测(附完整代码)
1. 引言:行李检测的智能化需求
在机场、火车站、物流中心等场景中,对行李的自动化识别、追踪和管理需求日益增长。传统的基于目标检测(Bounding Box)的方法虽然能定位行李,但无法精确描述其真实形状、大小和姿态。
实例分割 (Instance Segmentation) 技术应运而生。它不仅能区分“行李箱”这一类别,还能为图像中的每一个行李箱实例生成精确的像素级掩码 (Mask)。这使得我们能够:
- 精确计算行李的实际面积和轮廓。
- 更好地处理重叠或遮挡的行李。
- 为后续的姿态估计、尺寸测量或路径追踪提供坚实基础。
本文将采用目前高效且强大的 YOLO12 分割模型,并利用 OpenCV 进行图像处理和结果可视化,构建一个完整的行李箱检测系统。
2. 技术栈解析:YOLO12 + OpenCV 的强强联合
- YOLO12 (You Only Look Once 12):
- 区域注意力机制 : 一种新的自注意力方法,可以有效地处理大型感受野。它将 特征图 分成 l 个大小相等的区域(默认为 4 个),水平或垂直,避免复杂的运算并保持较大的有效感受野。与标准自注意力相比,这大大降低了计算成本。
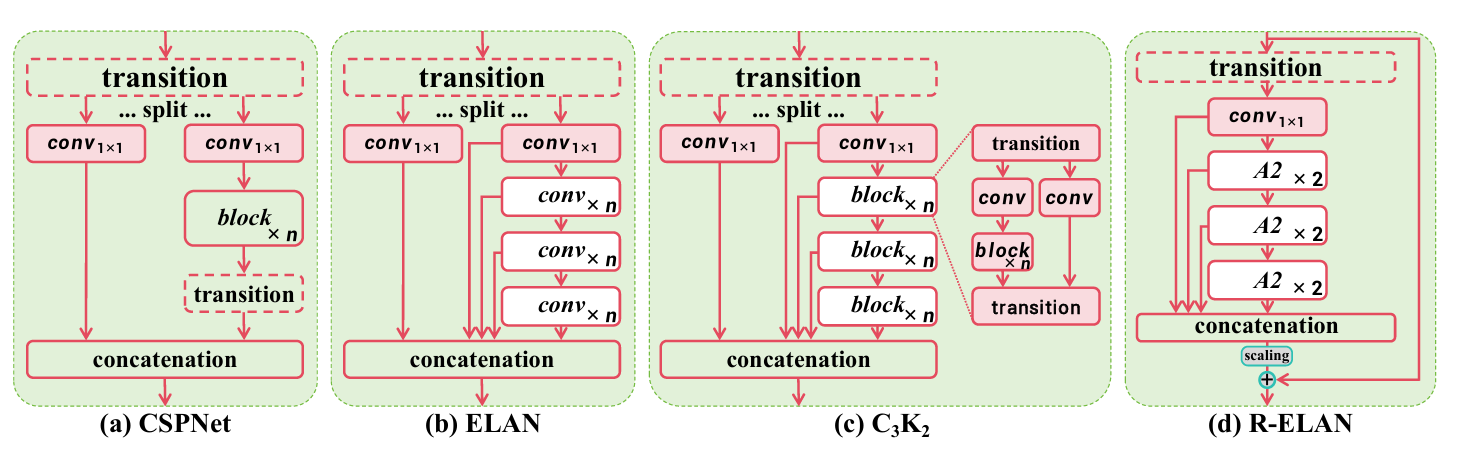
- 残差高效层聚合网络(R-ELAN):一种基于 ELAN 的改进的特征聚合模块,旨在解决优化挑战,尤其是在更大规模的以注意力为中心的模型中。R-ELAN 引入:
- 具有缩放的块级残差连接(类似于层缩放)。
- 一种重新设计的特征聚合方法,创建了一个类似瓶颈的结构。
- 优化的注意力机制架构:YOLO12 精简了标准注意力机制,以提高效率并与 YOLO 框架兼容。这包括:
- 使用 FlashAttention 来最大限度地减少内存访问开销。
- 移除位置编码,以获得更简洁、更快速的模型。
- 调整 MLP 比率(从典型的 4 调整到 1.2 或 2),以更好地平衡注意力和前馈层之间的计算。
- 减少堆叠块的深度以改进优化。
- 利用卷积运算(在适当的情况下)以提高其计算效率。
- 在注意力机制中添加一个7x7可分离卷积(“位置感知器”),以隐式地编码位置信息。
- 全面的任务支持:YOLO12 支持一系列核心计算机视觉任务:对象检测、实例分割、图像分类、姿势估计 和定向对象检测旋转框检测)。
- 增强的效率: 与许多先前的模型相比,以更少的参数实现了更高的准确率,从而证明了速度和准确率之间更好的平衡。
- 灵活部署: 专为跨各种平台部署而设计,从边缘设备到云基础设施。
- OpenCV (Open Source Computer Vision Library):
- 图像处理基石: 提供了强大的图像读取、显示、几何变换、绘图和形态学操作功能。
- 掩码处理: 可以方便地对YOLOv8输出的分割掩码进行填充、绘制轮廓、计算面积、进行形态学操作等。
- 结果融合: 将分割结果(掩码、轮廓)与原始图像进行融合可视化。

3. 环境准备与依赖安装
【图像算法 - 01】保姆级深度学习环境搭建入门指南:硬件选型 + CUDA/cuDNN/Miniconda/PyTorch/Pycharm 安装全流程(附版本匹配秘籍+文末有视频讲解)
4. 数据准备:高质量标注是成功的关键
数据是深度学习的基石。对于行李箱分割,我们需要带有像素级掩码标注的数据集。(资源下载)
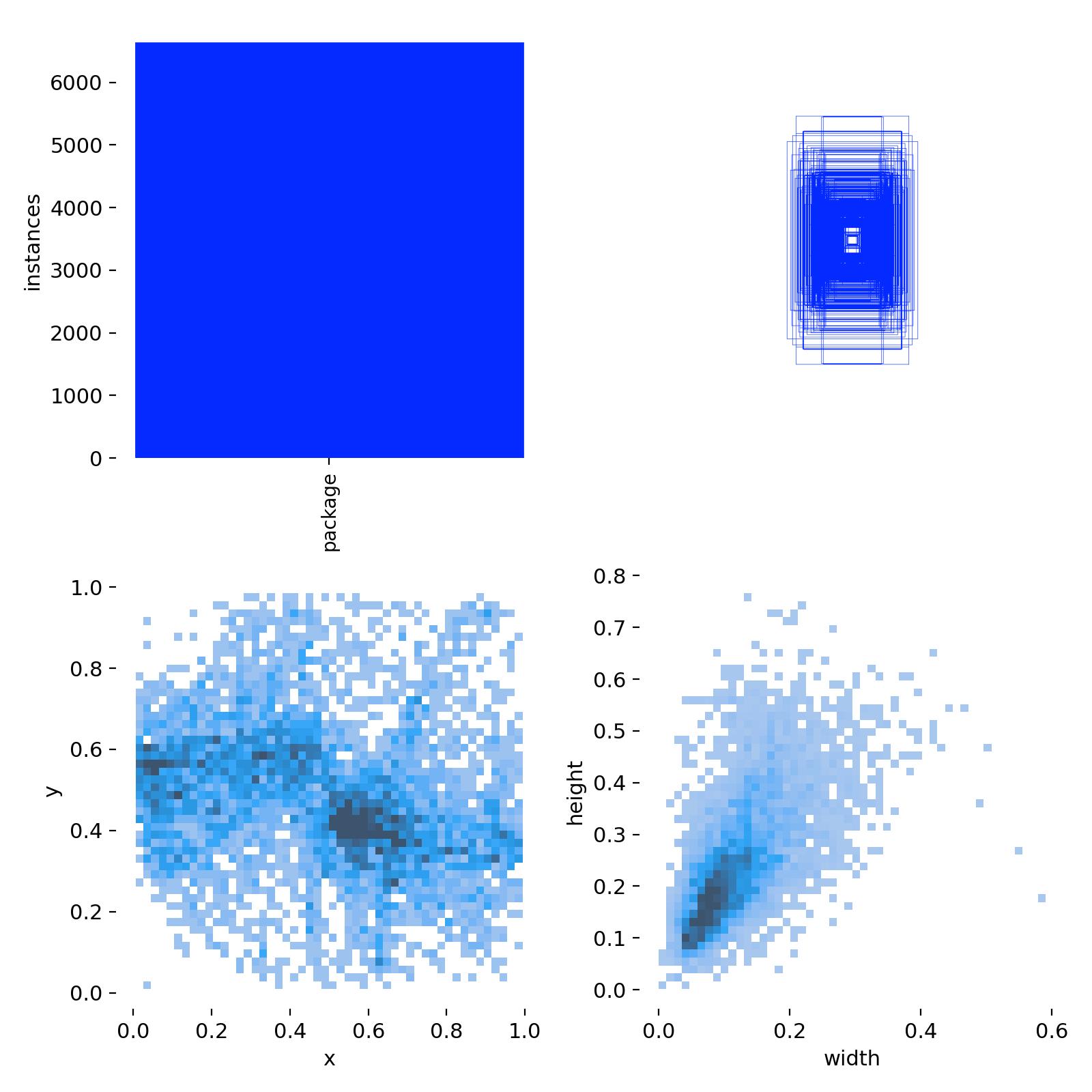
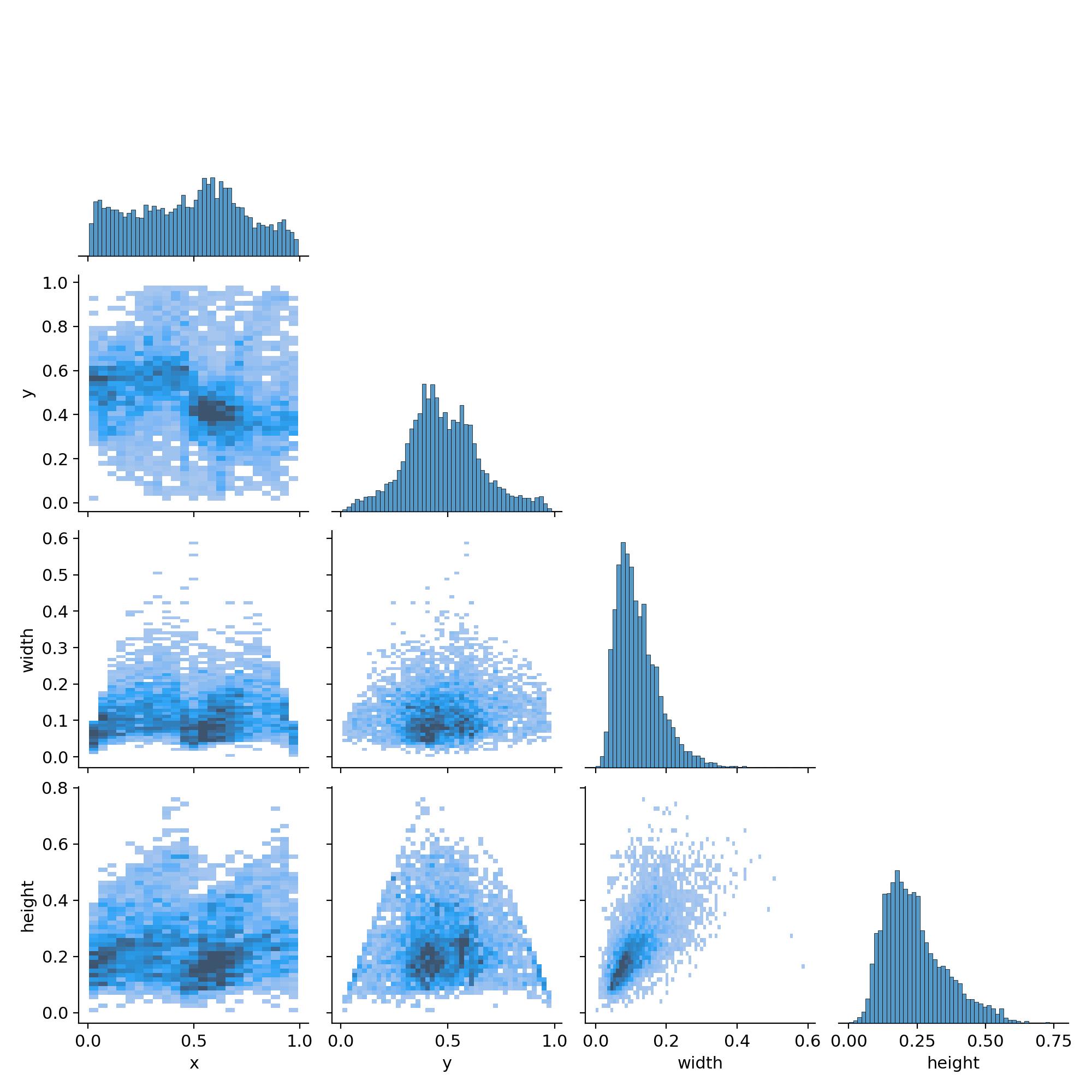
本次使用的行李箱分割数据集中的数据分布结构如下:
- 训练集: 包含 1920 张图像及其相应的注释。
- 测试集: 包含 89 张图像,每张图像都配有各自的标注。
- 验证集: 包含 188 张图像,每张图像都有相应的注释。
4.1 数据标注(如需)
- 工具推荐: LabelMe, CVAT, Roboflow。
- labelme数据标注保姆级教程:从安装到格式转换全流程,附常见问题避坑指南(含视频讲解)
- 标注要求: 为每一张图像中的每一个行李箱绘制精确的多边形轮廓(Polygon)。标注工具会生成对应的JSON或COCO格式的标注文件。
- 数据格式: YOLO12支持 COCO格式 或其自定义的 YOLO格式(文本文件,每行代表一个实例:
class_id center_x center_y width height+ 多个x y坐标对表示分割点)。我们通常使用COCO格式。
4.2 数据集划分与组织 将数据集划分为训练集(train)、验证集(val)和测试集(test)。典型的划分比例是 70%:15%:15% 或 80%:10%:10%。
组织目录结构如下:
crack_dataset/
├── images/
│ ├── train/ # 训练集图像
│ ├── val/ # 验证集图像
│ └── test/ # 测试集图像
└── labels/├── train/ # 训练集标签 (COCO JSON 或 YOLO txt)├── val/ # 验证集标签└── test/ # 测试集标签
4.3 数据增强 (Data Augmentation) Ultralytics YOLO12在训练时默认应用了强大的数据增强策略(如Mosaic, MixUp, 随机旋转、缩放、裁剪、色彩抖动等),这有助于提高模型的泛化能力,防止过拟合,尤其在数据量有限时效果显著。
- Mosaic
- 当你看到 mosaic: 1.0,这意味着在数据增强过程中使用了 Mosaic 技术,并且其强度或概率设置为最大值(1.0)。Mosaic 数据增强方法通过将四张图片随机裁剪并拼接成一张图片来创建新的训练样本。这有助于模型学习如何在不同的环境中识别目标,特别是当对象只占据了图像的一部分时。
- MixUp
- 对于 mixup: 0.0,这表示不使用 Mixup 方法或者该方法的应用概率为最低(0.0)。Mixup 是一种更温和的数据增强策略,它通过线性插值的方式在两张图片及其标签之间生成新的训练样本。例如,如果你有两张图片 A 和 B,Mixup 可能会生成一个新的图片 C,其中 C 的像素是 A 和 B 像素的加权平均值,
5. 核心代码实现:训练、检测、分割与可视化
5.1模型训练
5.1.1 配置文件 (package-seg.yaml) 创建一个 package-seg.yaml 文件,描述数据集路径和类别信息:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]path: ../datasets/package-seg # dataset root dir
train: images/train # train images (relative to 'path') 1920 images
val: images/val # val images (relative to 'path') 89 images
test: images/test # test images (relative to 'path') 188 images# Classesnames:0: package
5.1.2 开始训练 使用一行命令即可启动训练!Ultralytics提供了丰富的参数供调整。
from ultralytics import YOLO# 加载已训练的YOLO12分割模型
model = YOLO('yolo12-seg.yaml') # 推荐使用s或m版本在精度和速度间平衡# 开始训练
results = model.train(data='package-seg.yaml', # 指定数据配置文件epochs=100, # 训练轮数imgsz=640, # 输入图像尺寸batch=16, # 批次大小 (根据GPU显存调整)name='package_seg_v1', # 实验名称,结果保存在 runs/segment/package_seg_v1/device=0, # 使用GPU 0, 多GPU用 [0, 1, 2]# 以下为可选高级参数# optimizer='AdamW', # 优化器# lr0=0.01, # 初始学习率# lrf=0.01, # 最终学习率 (lr0 * lrf)# patience=20, # EarlyStopping 耐心值# augment=True, # 是否使用Mosaic等增强 (默认True)# fraction=1.0, # 使用数据集的比例# project='my_projects', # 结果保存的项目目录
)
训练结束后内容生成:
5.1.3 训练过程监控
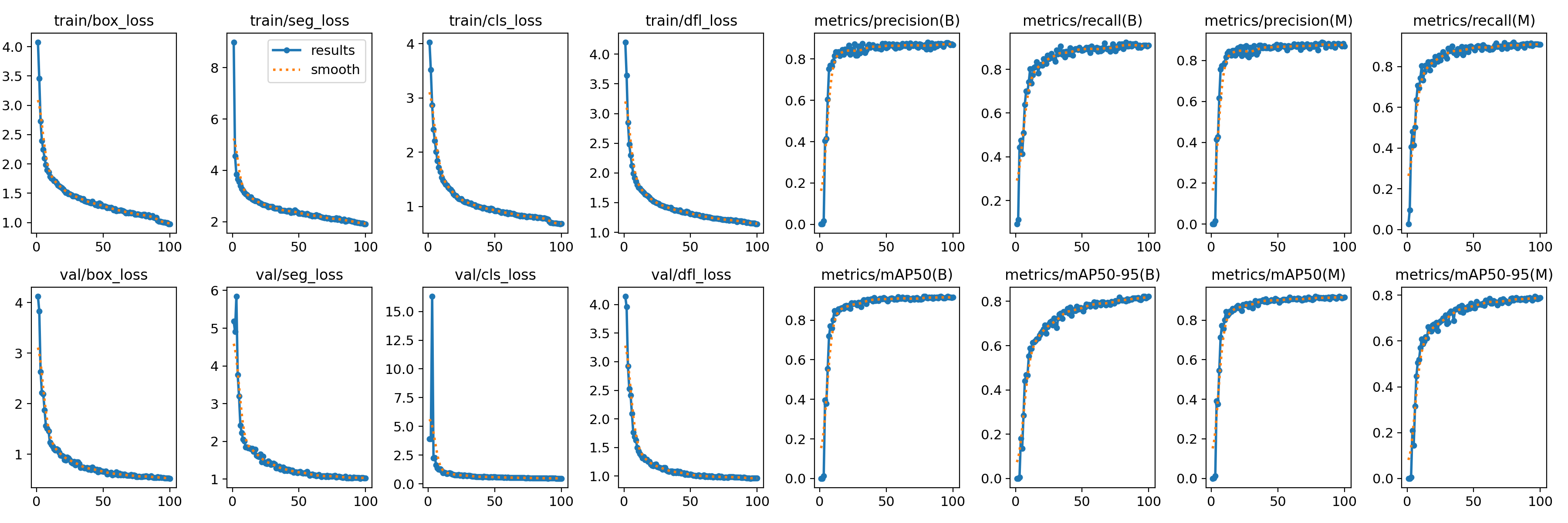
- 训练过程中,Ultralytics会实时打印损失值(
box_loss,seg_loss,cls_loss,dfl_loss)和评估指标(precision,recall,mAP50,mAP50-95)。 - 在
runs/segment/package_seg_v1/目录下会生成详细的训练日志、指标曲线图(如results.png)和最佳权重文件(weights/best.pt)。
5.2 检测、分割
图片推理
# 加载模型
model = YOLO('runs/segment/package_seg_v1/weights/best.pt')# 对单张图像进行预测
results = model('path/to/your/test_image.jpg', imgsz=640, conf=0.25) # conf: 置信度阈值# 结果可视化
for r in results:# 方法1: 使用Ultralytics内置的plot方法 (快速显示)im_array = r.plot() # 绘制边界框、分割掩码、标签im = Image.fromarray(im_array[..., ::-1]) # BGR to RGBim.show() # 显示图像# 方法2: 获取分割掩码进行自定义处理masks = r.masks # Segmentation masks objectif masks is not None:mask_array = masks.data.cpu().numpy() # 形状: (num_instances, H, W)# 对mask_array进行后续处理,如计算裂缝长度、宽度、面积等# 例如,计算每条裂缝的像素面积:for i, mask in enumerate(mask_array):area = mask.sum() # 像素面积print(f"Package {i} area: {area} pixels")
批量推理
# 对整个文件夹进行预测
results = model.predict(source='path/to/test_images_folder/', save=True, save_txt=True, imgsz=640, conf=0.25)
# save=True: 保存带标注的图像
# save_txt=True: 保存预测结果到txt文件 (可选)

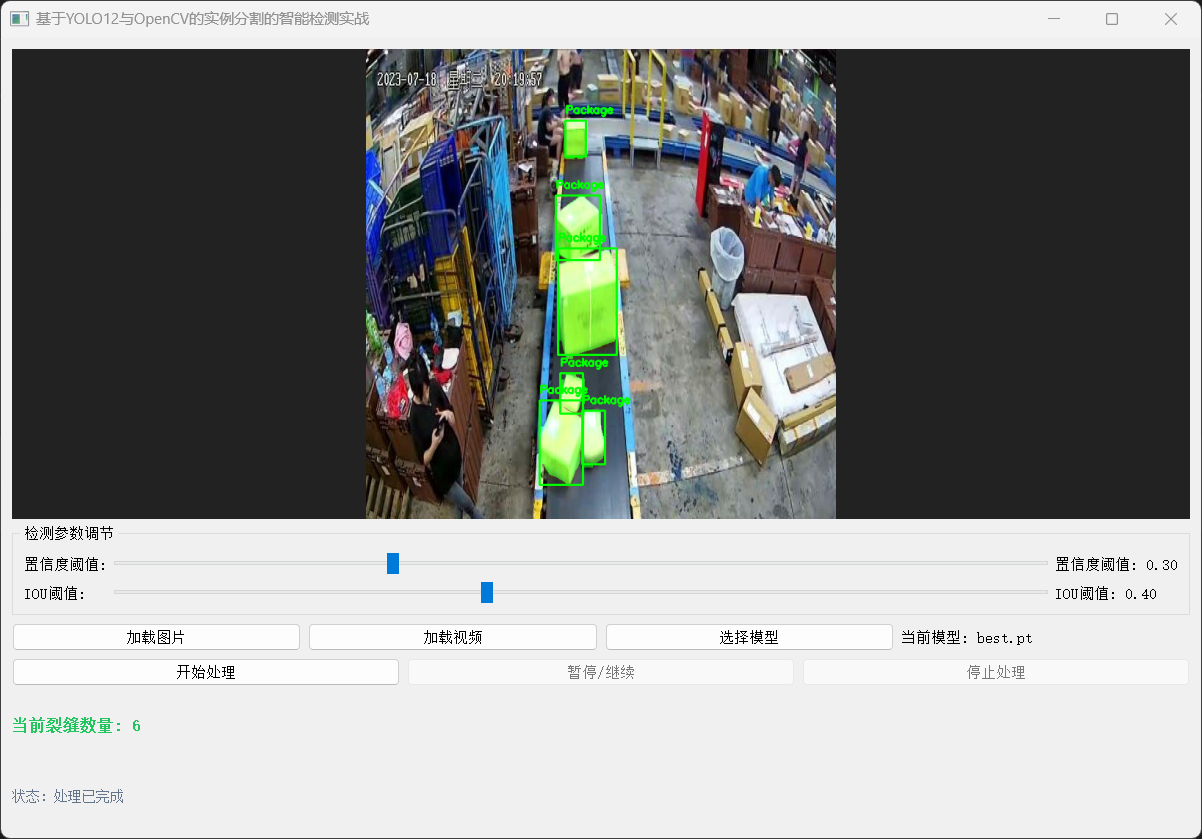
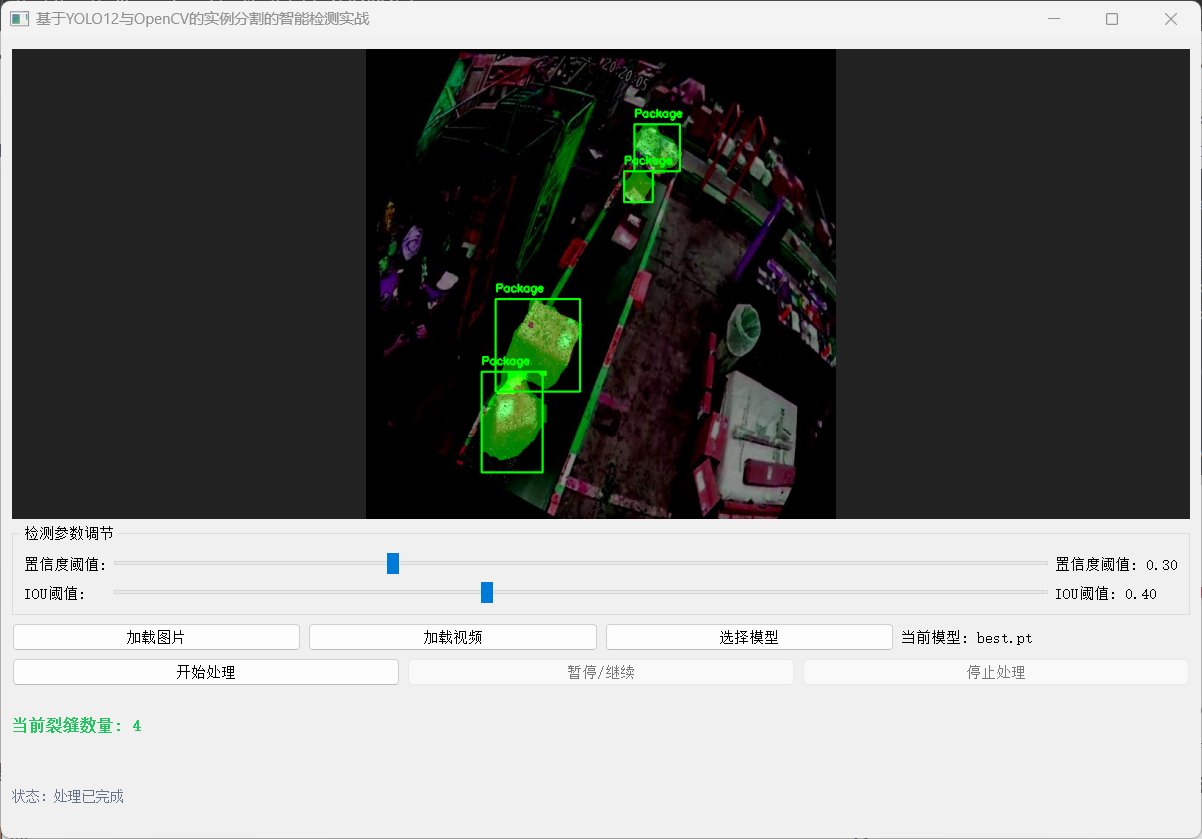
5.3 可视化操作界面
使用OpenCV结合PyQt5进行可视化的工作,当然我们还利用PyQt5实现用户模型推理交互的功能。使得用户能够实现在界面自主切换模型、调节参数、加载图片、视频等等。
def convert_frame_to_pixmap(self, frame):"""将OpenCV帧转换为QPixmap,特别优化mask显示"""if frame is None:return QPixmap()# 转换颜色空间(OpenCV的BGR转Qt的RGB)frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)# 确保数据类型正确if frame_rgb.dtype != np.uint8:frame_rgb = cv2.normalize(frame_rgb, None, 0, 255, cv2.NORM_MINMAX, dtype=cv2.CV_8U)# 确保内存连续性if not frame_rgb.flags.contiguous:frame_rgb = np.ascontiguousarray(frame_rgb)h, w, c = frame_rgb.shape# 创建QImage - 使用更可靠的参数qimg = QImage(frame_rgb.data,w,h,frame_rgb.strides[0], # 直接使用数组的步长QImage.Format_RGB888)# 确保图像不被修改时共享数据,提高性能qimg = qimg.copy()# 转换为QPixmap并按比例缩放pixmap = QPixmap.fromImage(qimg)return pixmap.scaled(self.display_label.width(),self.display_label.height(),Qt.KeepAspectRatio,Qt.SmoothTransformation)
实例分割可视化核心代码:利用了OpenCV的cv2.addWeighted函数,将转换后的mask和标签绘制在原图像之上。
# # ✅ 使用 masks.data 绘制掩码if i < len(masks): # 安全检查mask640 = masks[i] # (H, W),值为 0~1# mask = (mask > 0.5).astype(np.uint8) * 255 # 二值化mask = cv2.resize(mask640, (original_w, original_h), interpolation=cv2.INTER_NEAREST)mask = (mask > 0.5).astype(np.uint8) * 255## # 创建彩色掩码层color_mask = np.zeros_like(frame)color_mask[:, :, 1] = mask # 绿色通道# # 或者:color_mask[mask == 255] = color## # 叠加frame = cv2.addWeighted(frame, 1.0, color_mask, 0.5, 0)
界面可视化:
6. 代码详解与关键点
- 模型加载:
YOLO('runs/segment/package_seg_v1/weights/best.pt')加载自己训练的模型(如best.pt)。 - 掩码处理:
masks.data是一个Tensor,需要.cpu().numpy()转换为NumPy数组。- 掩码的尺寸可能与原图不同(取决于模型输入尺寸),使用
cv2.resize调整到原图尺寸 (width,height),插值方式必须用INTER_NEAREST以保证掩码的准确性。
- 可视化融合:
- 半透明填充: 使用
cv2.addWeighted将彩色掩码与原图混合,直观显示分割区域。 - 轮廓绘制: 使用
cv2.findContours找到掩码的边界,cv2.drawContours绘制,使边缘更清晰锐利。
- 半透明填充: 使用
- 信息量化:
mask.sum()直接计算二值掩码中“1”的数量,即该实例的像素面积,可用于后续分析。
7. 运行结果与应用
- 输出图像: 将显示原始图像,叠加了半透明的彩色分割区域、绿色边界框、黄色轮廓和类别标签。
- 控制台输出: 打印出每个检测到的行李实例的类别、置信度和像素面积。
- 应用场景:
- 智慧机场/车站: 自动化行李分拣、行李追踪、行李架占用分析。
- 智能安防: 监控区域内的遗留物检测(如无人看管的行李)。
- 机器人导航: 服务机器人识别并避开障碍物(行李)。
- 零售分析: 分析商场内顾客携带的包袋类型。
8. 总结
本文成功实现了利用 YOLO12实例分割模型 和 OpenCV 对行李箱进行精准检测与分割。通过结合两者的优势,我们不仅定位了行李,还获得了其精确的轮廓和面积信息,为更高阶的智能应用奠定了基础。
优势:
- 精度高: 像素级分割,结果精确。
- 速度快: YOLO12保证了良好的实时性能。
- 功能丰富: OpenCV提供了强大的后处理能力。
- 易于扩展: 代码框架清晰,可轻松应用于其他物体的分割任务。
改进方向:
- 自定义训练: 如果COCO预训练模型对特定行李(如某品牌行李箱)效果不佳,可以收集数据并进行微调(Fine-tuning)。
- 3D信息: 结合深度相机,可估算行李的实际尺寸和体积。
- 多目标追踪: 结合SORT或ByteTrack等算法,实现行李的跨帧追踪。