微服务架构实战指南:从单体应用到云原生的蜕变之路

🌟 Hello,我是蒋星熠Jaxonic!
🌈 在浩瀚无垠的技术宇宙中,我是一名执着的星际旅人,用代码绘制探索的轨迹。
🚀 每一个算法都是我点燃的推进器,每一行代码都是我航行的星图。
🔭 每一次性能优化都是我的天文望远镜,每一次架构设计都是我的引力弹弓。
🎻 在数字世界的协奏曲中,我既是作曲家也是首席乐手。让我们携手,在二进制星河中谱写属于极客的壮丽诗篇!
摘要
在这篇文章中,我将分享我在微服务架构实践中的经验和教训,包括如何科学地进行服务拆分、如何设计高效的服务间通信机制、如何构建强大的微服务治理平台,以及如何应对分布式系统带来的各种挑战。我相信,无论你是正在考虑微服务转型的架构师,还是已经踏上微服务之路的开发者,这篇文章都能为你提供一些有价值的参考和启发。
1. 微服务架构的演进与思考
1.1 从单体到微服务的痛点
单体应用在初创阶段有其不可替代的优势:开发简单、部署方便、调试直接。但随着业务的增长和团队的扩大,单体应用的弊端逐渐显现:
- 扩展性受限:整个应用只能作为一个整体进行扩展,无法针对不同模块的负载特性进行差异化扩展
- 技术栈固化:整个应用通常使用同一种技术栈,难以针对不同业务场景选择最适合的技术
- 团队协作困难:多团队在同一代码库上工作,容易产生冲突和依赖问题
- 部署风险高:任何小改动都需要重新部署整个应用,增加了发布风险
// 单体应用中的代码耦合示例
public class OrderService {private UserRepository userRepository;private ProductRepository productRepository;private PaymentService paymentService;private LogisticsService logisticsService;private NotificationService notificationService;@Transactionalpublic OrderResult createOrder(OrderRequest request) {// 验证用户信息User user = userRepository.findById(request.getUserId());if (user == null || !user.isActive()) {throw new BusinessException("用户不存在或已被禁用");}// 检查商品库存Product product = productRepository.findById(request.getProductId());if (product == null || product.getStock() < request.getQuantity()) {throw new BusinessException("商品不存在或库存不足");}// 创建订单Order order = new Order();order.setUserId(user.getId());order.setProductId(product.getId());order.setQuantity(request.getQuantity());order.setAmount(product.getPrice().multiply(new BigDecimal(request.getQuantity())));order.setStatus(OrderStatus.CREATED);orderRepository.save(order);// 扣减库存product.setStock(product.getStock() - request.getQuantity());productRepository.save(product);// 处理支付PaymentResult paymentResult = paymentService.processPayment(user, order);if (!paymentResult.isSuccess()) {throw new BusinessException("支付失败: " + paymentResult.getMessage());}// 创建物流单LogisticsOrder logisticsOrder = logisticsService.createLogisticsOrder(order);// 发送通知notificationService.sendOrderNotification(user, order);return new OrderResult(order.getId(), logisticsOrder.getTrackingNumber());}
}
上面的代码展示了单体应用中常见的问题:一个服务方法中包含了用户、商品、订单、支付、物流、通知等多个领域的逻辑,这些领域在微服务架构中通常会被拆分为独立的服务。
1.2 微服务架构的核心理念
微服务架构是一种将应用程序构建为一系列小型、自治服务的方法,每个服务运行在自己的进程中,通过轻量级机制通信。核心理念包括:
- 单一职责:每个服务专注于解决特定业务领域的问题
- 自治性:服务可以独立开发、测试、部署和扩展
- 去中心化:避免中心化的数据管理和治理
- 领域驱动设计:基于业务领域边界进行服务划分
- 容错性:服务故障不应级联传播,而应该优雅降级
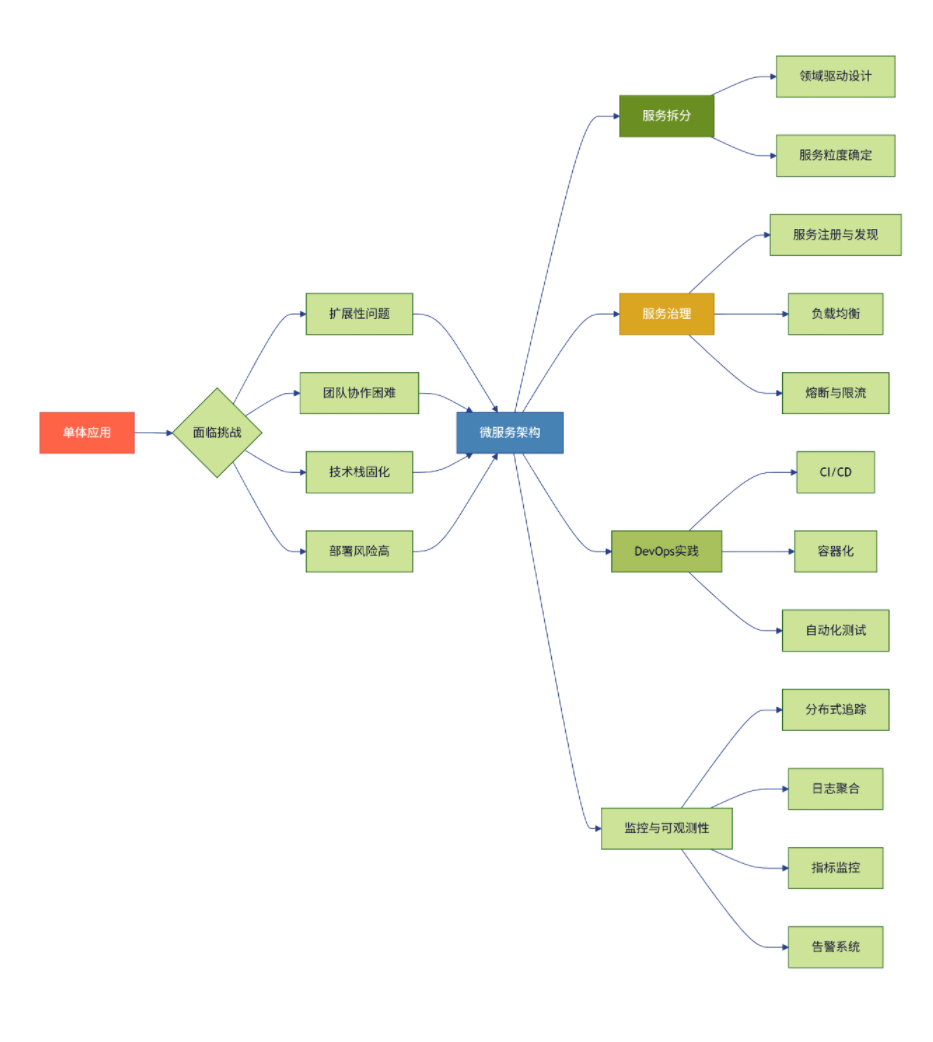
图1:微服务架构演进流程图 - 展示从单体应用到微服务架构的转变过程
1.3 何时选择微服务架构
微服务架构并非银弹,它适合一些特定的场景:
- 业务复杂度高:业务领域清晰可分,各模块之间边界明确
- 团队规模大:多团队并行开发,需要明确的责任边界
- 差异化扩展需求:不同模块有不同的扩展需求和资源消耗特点
- 技术异构需求:不同业务场景需要使用不同的技术栈
“不要为了微服务而微服务。如果你的团队规模小,业务相对简单,单体应用可能是更好的选择。微服务的复杂性可能会超过它带来的收益。” —— Martin Fowler
2. 微服务拆分策略与实践
2.1 领域驱动设计在服务拆分中的应用
领域驱动设计(DDD)为微服务拆分提供了理论基础,它强调基于业务领域进行系统设计。
// 使用DDD思想拆分后的订单服务
@Service
public class OrderService {private final OrderRepository orderRepository;private final UserServiceClient userServiceClient;private final ProductServiceClient productServiceClient;private final PaymentServiceClient paymentServiceClient;private final LogisticsServiceClient logisticsServiceClient;private final EventPublisher eventPublisher;@Transactionalpublic OrderResult createOrder(OrderRequest request) {// 调用用户服务验证用户UserDTO user = userServiceClient.getUser(request.getUserId());if (user == null || !user.isActive()) {throw new BusinessException("用户不存在或已被禁用");}// 调用商品服务检查库存ProductDTO product = productServiceClient.getProduct(request.getProductId());if (product == null || product.getStock() < request.getQuantity()) {throw new BusinessException("商品不存在或库存不足");}// 创建订单(核心领域逻辑)Order order = new Order();order.setUserId(user.getId());order.setProductId(product.getId());order.setQuantity(request.getQuantity());order.setAmount(product.getPrice().multiply(new BigDecimal(request.getQuantity())));order.setStatus(OrderStatus.CREATED);orderRepository.save(order);// 发布订单创建事件,由其他服务异步处理eventPublisher.publish(new OrderCreatedEvent(order));return new OrderResult(order.getId());}
}
在这个拆分后的示例中,订单服务只负责核心的订单领域逻辑,通过服务客户端调用其他微服务,并通过事件发布机制实现服务间的解耦。
2.2 服务粒度的确定
服务粒度是微服务设计中的关键问题,粒度过粗会失去微服务的优势,粒度过细则会增加系统复杂性。
确定服务粒度的原则:
- 业务内聚性:服务应该围绕特定业务能力构建
- 数据自治:服务应该拥有自己的数据,减少跨服务数据依赖
- 团队结构:考虑康威定律,服务边界应与团队边界一致
- 变更频率:经常一起变更的功能应该在同一个服务中
| 服务名称 | 核心职责 | 数据资源 | 团队 | 变更频率 |
|---|---|---|---|---|
| 用户服务 | 用户注册、认证、信息管理 | 用户表、角色表 | 用户团队 | 中等 |
| 商品服务 | 商品管理、库存管理、类目管理 | 商品表、库存表、类目表 | 商品团队 | 高 |
| 订单服务 | 订单创建、状态管理、订单查询 | 订单表、订单项表 | 订单团队 | 中等 |
| 支付服务 | 支付处理、退款处理、账单管理 | 支付表、账单表 | 支付团队 | 低 |
| 物流服务 | 物流订单创建、物流状态跟踪 | 物流订单表、物流轨迹表 | 物流团队 | 低 |
2.3 拆分过程中的数据处理策略
微服务拆分过程中,数据处理是一个关键挑战。主要策略包括:
- 数据库拆分:每个服务使用独立的数据库或schema
- 数据复制:通过事件驱动的方式在服务间复制必要的数据
- 数据访问API:提供统一的数据访问API,避免直接跨库查询
- CQRS模式:将命令和查询责任分离,优化不同场景的数据访问
// 使用事件驱动的数据同步示例
@Service
public class ProductInventoryEventHandler {private final ProductRepository productRepository;@EventListenerpublic void handleOrderCreatedEvent(OrderCreatedEvent event) {// 接收订单创建事件,更新商品库存Product product = productRepository.findById(event.getProductId());product.setStock(product.getStock() - event.getQuantity());productRepository.save(product);// 发布库存变更事件eventPublisher.publish(new InventoryChangedEvent(product.getId(), product.getStock()));}
}
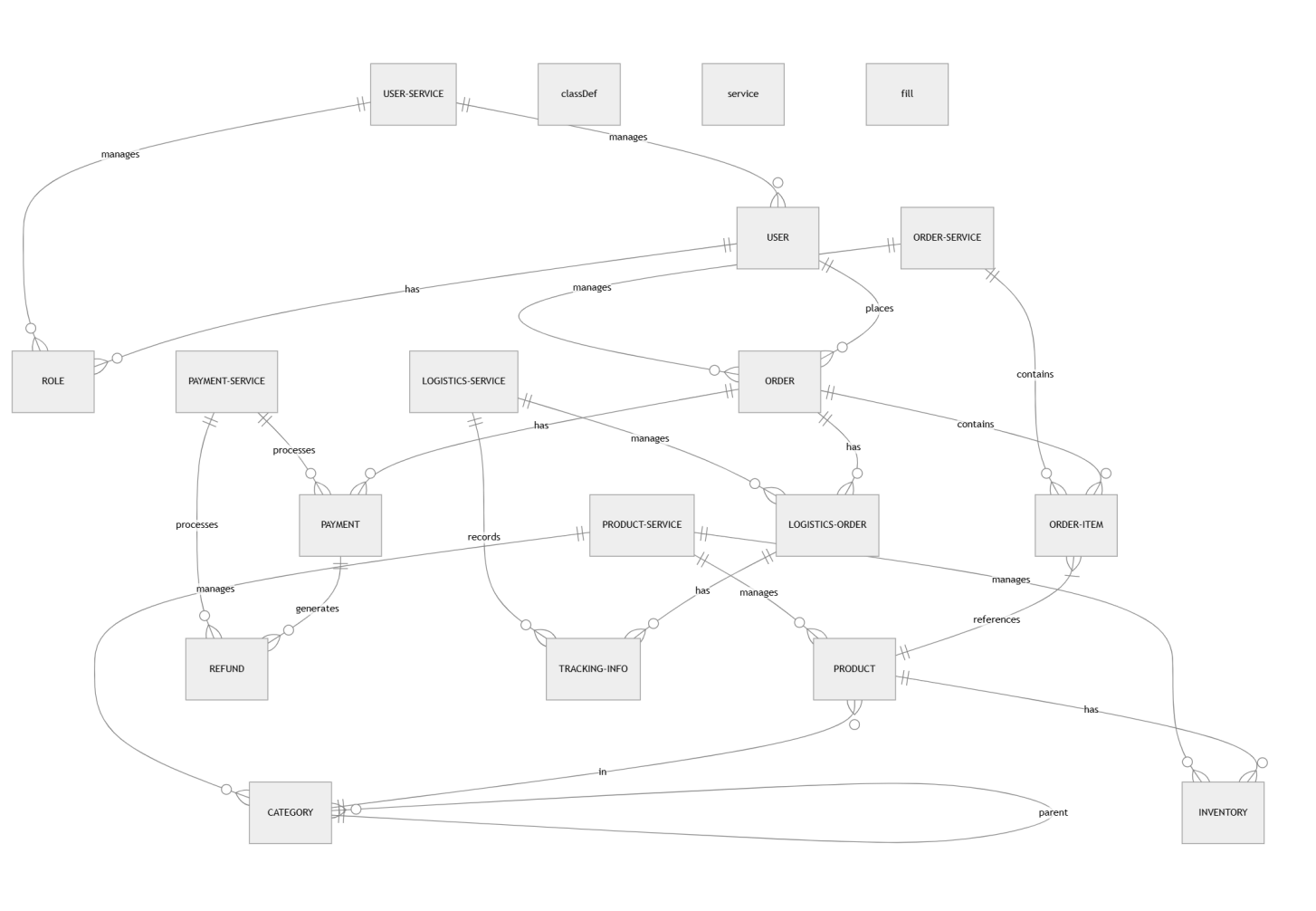
图2:微服务数据模型实体关系图 - 展示各微服务的数据边界
3. 微服务通信与API设计
3.1 同步通信与异步通信的选择
微服务间通信主要有同步和异步两种方式,各有优缺点:
-
同步通信:
- REST API:简单直观,适合请求-响应模式
- gRPC:高性能,支持强类型接口定义,适合服务间高频调用
- GraphQL:灵活的数据查询,减少网络往返
-
异步通信:
- 消息队列:Kafka、RabbitMQ等,实现服务解耦
- 事件驱动:发布-订阅模式,提高系统弹性
- 流处理:处理实时数据流
// gRPC服务定义示例
syntax = "proto3";package com.example.product;service ProductService {rpc GetProduct(ProductRequest) returns (ProductResponse) {}rpc CheckStock(StockRequest) returns (StockResponse) {}rpc UpdateStock(UpdateStockRequest) returns (UpdateStockResponse) {}
}message ProductRequest {string product_id = 1;
}message ProductResponse {string id = 1;string name = 2;string description = 3;double price = 4;int32 stock = 5;string category_id = 6;
}message StockRequest {string product_id = 1;int32 quantity = 2;
}message StockResponse {bool available = 1;int32 current_stock = 2;
}message UpdateStockRequest {string product_id = 1;int32 quantity = 2;string operation = 3; // "INCREASE" or "DECREASE"
}message UpdateStockResponse {bool success = 1;int32 new_stock = 2;string error_message = 3;
}
3.2 API网关的设计与实现
API网关是微服务架构中的重要组件,它提供了统一的API入口,并处理横切关注点:
- 路由与负载均衡:将请求路由到相应的微服务
- 认证与授权:统一的身份验证和权限控制
- 限流与熔断:保护后端服务不被过载
- 请求转换:协议转换、请求聚合等
- 监控与日志:收集API调用的指标和日志
// Spring Cloud Gateway路由配置示例
@Configuration
public class GatewayConfig {@Beanpublic RouteLocator customRouteLocator(RouteLocatorBuilder builder) {return builder.routes()// 用户服务路由.route("user-service", r -> r.path("/api/users/**").filters(f -> f.rewritePath("/api/users/(?<segment>.*)", "/users/${segment}").addRequestHeader("X-Gateway-Source", "api-gateway").requestRateLimiter(c -> c.setRateLimiter(redisRateLimiter()).setKeyResolver(userKeyResolver()))).uri("lb://user-service"))// 商品服务路由.route("product-service", r -> r.path("/api/products/**").filters(f -> f.rewritePath("/api/products/(?<segment>.*)", "/products/${segment}").circuitBreaker(c -> c.setName("productCircuitBreaker").setFallbackUri("forward:/fallback/products"))).uri("lb://product-service"))// 订单服务路由.route("order-service", r -> r.path("/api/orders/**").filters(f -> f.rewritePath("/api/orders/(?<segment>.*)", "/orders/${segment}").retry(c -> c.setRetries(3).setStatuses(HttpStatus.INTERNAL_SERVER_ERROR))).uri("lb://order-service")).build();}@Beanpublic RedisRateLimiter redisRateLimiter() {return new RedisRateLimiter(10, 20); // 令牌桶算法参数}@Beanpublic KeyResolver userKeyResolver() {return exchange -> Mono.just(Optional.ofNullable(exchange.getRequest().getHeaders().getFirst("X-User-ID")).orElse("anonymous"));}
}
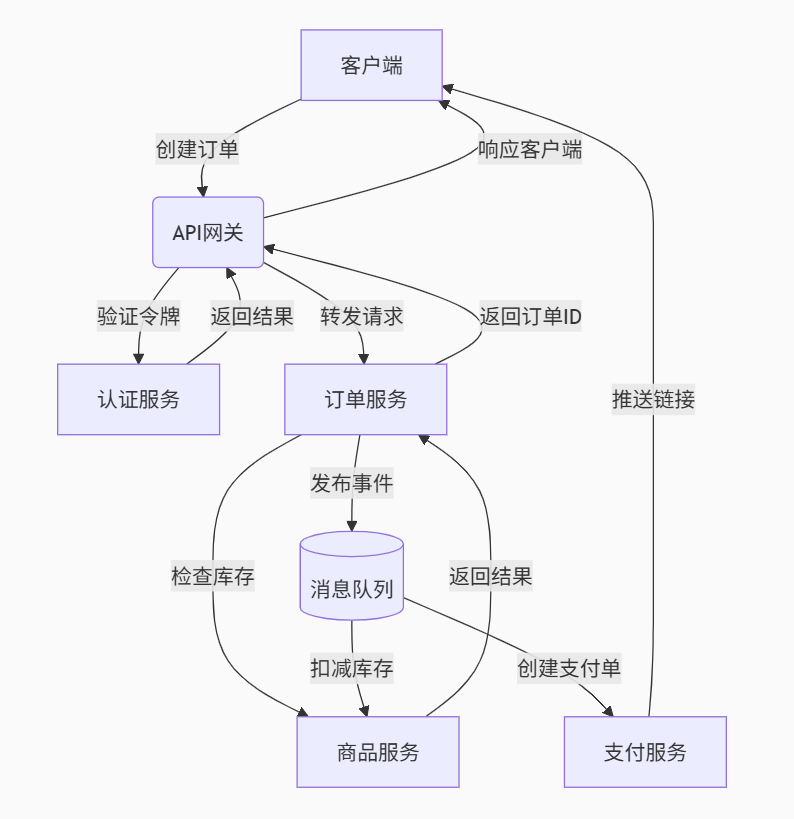
图3:微服务通信时序图 - 展示订单创建流程中的服务间通信
3.3 API版本控制与兼容性策略
在微服务环境中,API版本控制至关重要,它允许服务独立演进而不破坏现有客户端:
- URI版本控制:在URI中包含版本号,如
/api/v1/users - 请求参数版本控制:通过查询参数指定版本,如
/api/users?version=1 - HTTP头版本控制:使用自定义HTTP头指定版本,如
X-API-Version: 1 - 内容协商版本控制:使用Accept头指定版本,如
Accept: application/vnd.company.app-v1+json
// Spring MVC中的API版本控制示例
@RestController
@RequestMapping("/api/products")
public class ProductController {@GetMapping(value = "/{id}", headers = "X-API-Version=1")public ProductResponseV1 getProductV1(@PathVariable String id) {Product product = productService.getProduct(id);return convertToV1Response(product);}@GetMapping(value = "/{id}", headers = "X-API-Version=2")public ProductResponseV2 getProductV2(@PathVariable String id) {Product product = productService.getProduct(id);ProductDetails details = productService.getProductDetails(id);return convertToV2Response(product, details);}// 默认版本,向后兼容@GetMapping("/{id}")public ProductResponseV1 getProductDefault(@PathVariable String id) {return getProductV1(id);}
}
4. 微服务治理与可观测性
4.1 服务注册与发现
服务注册与发现是微服务架构的基础设施,它解决了服务实例动态变化的问题:
- 服务注册中心:如Eureka、Consul、Nacos等,维护服务实例的注册表
- 服务注册:服务启动时向注册中心注册自己的位置和健康状态
- 服务发现:客户端通过注册中心查询服务实例的位置
- 健康检查:定期检查服务实例的健康状态,剔除不健康的实例
// Spring Cloud中的服务注册与发现配置
@SpringBootApplication
@EnableDiscoveryClient
public class ProductServiceApplication {public static void main(String[] args) {SpringApplication.run(ProductServiceApplication.class, args);}
}// application.yml
spring:application:name: product-servicecloud:nacos:discovery:server-addr: nacos-server:8848namespace: prodgroup: DEFAULT_GROUPcluster-name: beijingmetadata:version: v1weight: 100
4.2 熔断、限流与降级策略
在分布式系统中,故障是不可避免的,需要采取措施防止故障级联传播:
- 熔断器模式:当服务调用失败率达到阈值时,快速失败而不是继续等待
- 限流策略:控制请求速率,防止服务过载
- 降级策略:在高负载或故障情况下,提供有损但可用的服务
- 舱壁模式:隔离不同的服务调用,防止一个服务的问题影响其他服务
// 使用Resilience4j实现熔断和限流
@Service
public class ProductServiceClient {private final WebClient webClient;private final CircuitBreakerRegistry circuitBreakerRegistry;private final RateLimiterRegistry rateLimiterRegistry;public ProductDTO getProduct(String productId) {CircuitBreaker circuitBreaker = circuitBreakerRegistry.circuitBreaker("productService");RateLimiter rateLimiter = rateLimiterRegistry.rateLimiter("productService");Supplier<Mono<ProductDTO>> supplier = () -> webClient.get().uri("/products/{id}", productId).retrieve().bodyToMono(ProductDTO.class);// 应用熔断和限流return Mono.fromSupplier(CircuitBreaker.decorateSupplier(circuitBreaker, RateLimiter.decorateSupplier(rateLimiter, () -> supplier.get().block()))).onErrorReturn(this::getFallbackProduct).block();}private ProductDTO getFallbackProduct(Throwable t) {// 返回降级的商品信息return new ProductDTO("default", "暂时无法获取商品信息", BigDecimal.ZERO, 0);}
}
4.3 分布式追踪与日志聚合
在微服务架构中,一个请求可能跨越多个服务,这使得问题排查变得困难。分布式追踪和日志聚合是解决这个问题的关键:
- 分布式追踪:如Zipkin、Jaeger、SkyWalking等,跟踪请求在各服务间的流转
- 日志聚合:如ELK Stack、Loki等,集中收集和分析各服务的日志
- 指标监控:如Prometheus、Grafana等,收集和可视化服务的运行指标
- 告警系统:基于指标和日志设置告警规则,及时发现问题
// 使用Spring Cloud Sleuth和Zipkin进行分布式追踪
@SpringBootApplication
@EnableDiscoveryClient
public class OrderServiceApplication {public static void main(String[] args) {SpringApplication.run(OrderServiceApplication.class, args);}@Beanpublic Sampler defaultSampler() {// 采样率设置为100%,生产环境可以调低return Sampler.ALWAYS_SAMPLE;}
}// application.yml
spring:application:name: order-servicesleuth:sampler:probability: 1.0zipkin:base-url: http://zipkin-server:9411sender:type: web

图4:微服务技术选型决策矩阵 - 基于业务价值和实现复杂度的四象限分析
5. 微服务部署与DevOps实践
5.1 容器化与容器编排
容器化是微服务部署的最佳实践,它提供了一致的运行环境和高效的资源利用:
- Docker容器:轻量级、可移植的应用打包方式
- Kubernetes:容器编排平台,管理容器的部署、扩展和运维
- 服务网格:如Istio、Linkerd,提供服务间通信的基础设施
- Helm:Kubernetes的包管理工具,简化应用部署
# Kubernetes部署清单示例
apiVersion: apps/v1
kind: Deployment
metadata:name: order-servicenamespace: microservices
spec:replicas: 3selector:matchLabels:app: order-servicetemplate:metadata:labels:app: order-servicespec:containers:- name: order-serviceimage: company/order-service:v1.2.3ports:- containerPort: 8080resources:requests:memory: "512Mi"cpu: "500m"limits:memory: "1Gi"cpu: "1000m"readinessProbe:httpGet:path: /actuator/health/readinessport: 8080initialDelaySeconds: 30periodSeconds: 10livenessProbe:httpGet:path: /actuator/health/livenessport: 8080initialDelaySeconds: 60periodSeconds: 15env:- name: SPRING_PROFILES_ACTIVEvalue: "prod"- name: JAVA_OPTSvalue: "-Xms256m -Xmx512m"volumeMounts:- name: config-volumemountPath: /app/configvolumes:- name: config-volumeconfigMap:name: order-service-config
---
apiVersion: v1
kind: Service
metadata:name: order-servicenamespace: microservices
spec:selector:app: order-serviceports:- port: 80targetPort: 8080type: ClusterIP
5.2 CI/CD流水线构建
持续集成和持续部署(CI/CD)是微服务开发的关键实践,它实现了快速、可靠的软件交付:
- 持续集成:频繁地将代码集成到主干,自动化构建和测试
- 持续部署:自动化部署到生产环境
- 基础设施即代码:使用代码管理基础设施,确保环境一致性
- 自动化测试:单元测试、集成测试、端到端测试等
# GitLab CI/CD流水线配置示例
stages:- build- test- package- deploy-dev- integration-test- deploy-prodvariables:MAVEN_OPTS: "-Dmaven.repo.local=.m2/repository"DOCKER_REGISTRY: "registry.example.com"cache:paths:- .m2/repositorybuild:stage: buildimage: maven:3.8-openjdk-11script:- mvn clean compileartifacts:paths:- target/unit-test:stage: testimage: maven:3.8-openjdk-11script:- mvn testartifacts:reports:junit: target/surefire-reports/TEST-*.xmlpackage:stage: packageimage: maven:3.8-openjdk-11script:- mvn package -DskipTests- docker build -t ${DOCKER_REGISTRY}/order-service:${CI_COMMIT_SHA} .- docker push ${DOCKER_REGISTRY}/order-service:${CI_COMMIT_SHA}only:- master- developdeploy-dev:stage: deploy-devimage: bitnami/kubectl:latestscript:- kubectl set image deployment/order-service order-service=${DOCKER_REGISTRY}/order-service:${CI_COMMIT_SHA} -n microservices-devenvironment:name: developmentonly:- developintegration-test:stage: integration-testimage: postman/newman:alpinescript:- newman run tests/integration/order-service-collection.json -e tests/integration/dev-environment.jsononly:- developdeploy-prod:stage: deploy-prodimage: bitnami/kubectl:latestscript:- kubectl set image deployment/order-service order-service=${DOCKER_REGISTRY}/order-service:${CI_COMMIT_SHA} -n microservices-prodenvironment:name: productionwhen: manualonly:- master
5.3 配置管理与环境隔离
在微服务架构中,配置管理是一个关键挑战,特别是在多环境部署的情况下:
- 配置中心:如Spring Cloud Config、Apollo、Nacos等,集中管理配置
- 环境隔离:开发、测试、预发布、生产等环境的隔离策略
- 敏感信息管理:密码、密钥等敏感信息的安全管理
- 动态配置:支持配置的动态更新,无需重启服务
// Spring Cloud Config客户端配置示例
@SpringBootApplication
@EnableDiscoveryClient
public class OrderServiceApplication {public static void main(String[] args) {SpringApplication.run(OrderServiceApplication.class, args);}
}// bootstrap.yml
spring:application:name: order-servicecloud:config:uri: http://config-server:8888fail-fast: trueretry:initial-interval: 1000max-interval: 2000max-attempts: 6label: ${GIT_BRANCH:master}profile: ${SPRING_PROFILES_ACTIVE:dev}
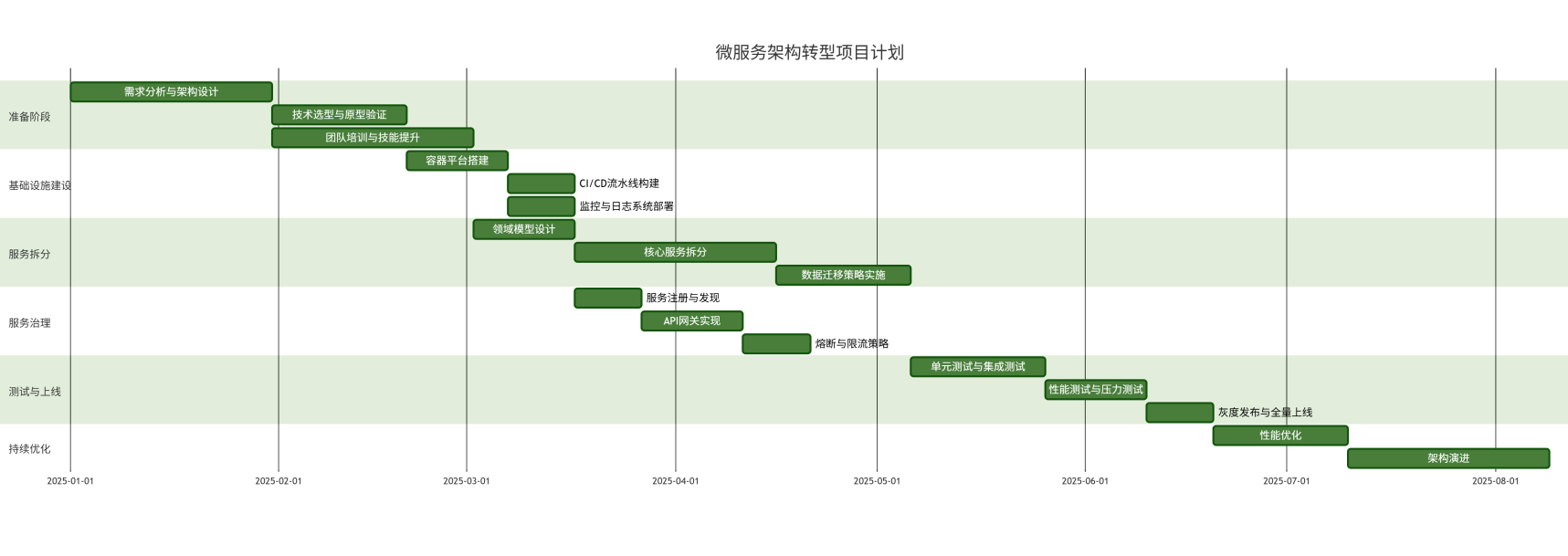
图5:微服务架构转型项目计划甘特图 - 展示项目各阶段时间安排
6. 微服务架构的挑战与应对策略
6.1 分布式事务处理
在微服务架构中,一个业务操作可能跨越多个服务,这带来了分布式事务的挑战:
- 最终一致性:通过事件驱动和补偿机制实现最终一致性
- Saga模式:将分布式事务拆分为一系列本地事务和补偿事务
- TCC模式:Try-Confirm-Cancel模式,实现两阶段提交
- 可靠消息队列:通过消息队列实现事务消息的可靠传递
// Saga模式实现示例
@Service
public class OrderSaga {private final OrderService orderService;private final PaymentService paymentService;private final InventoryService inventoryService;private final NotificationService notificationService;@Transactionalpublic OrderResult createOrder(OrderRequest request) {// 1. 创建订单(本地事务)Order order = orderService.createOrder(request);try {// 2. 扣减库存(远程调用)InventoryResult inventoryResult = inventoryService.reduceInventory(order.getProductId(), order.getQuantity());if (!inventoryResult.isSuccess()) {// 补偿:取消订单orderService.cancelOrder(order.getId(), "库存不足");return OrderResult.fail("库存不足");}// 3. 处理支付(远程调用)PaymentResult paymentResult = paymentService.processPayment(order.getId(), order.getAmount());if (!paymentResult.isSuccess()) {// 补偿:恢复库存inventoryService.increaseInventory(order.getProductId(), order.getQuantity());// 补偿:取消订单orderService.cancelOrder(order.getId(), "支付失败");return OrderResult.fail("支付失败");}// 4. 发送通知(远程调用)notificationService.sendOrderNotification(order.getId());return OrderResult.success(order.getId());} catch (Exception e) {// 发生异常,执行补偿操作// 实际实现中可能需要更复杂的补偿逻辑和重试机制orderService.cancelOrder(order.getId(), "系统异常");return OrderResult.fail("系统异常");}}
}
6.2 数据一致性与查询效率
微服务架构中,数据分散在不同的服务中,这带来了数据一致性和查询效率的挑战:
- CQRS模式:将命令和查询责任分离,优化不同场景的数据访问
- 数据复制:在需要的服务中复制必要的数据,提高查询效率
- 数据视图服务:专门的服务聚合多个服务的数据,提供统一的查询接口
- 事件溯源:通过事件重放构建数据视图,确保数据一致性
// CQRS模式实现示例
@Service
public class OrderQueryService {private final OrderRepository orderRepository;private final ProductRepository productRepository;private final UserRepository userRepository;// 查询服务,聚合多个领域的数据public OrderDetailDTO getOrderDetail(String orderId) {// 查询订单基本信息Order order = orderRepository.findById(orderId).orElseThrow(() -> new NotFoundException("订单不存在"));// 查询关联的商品信息Product product = productRepository.findById(order.getProductId()).orElse(null);// 查询关联的用户信息User user = userRepository.findById(order.getUserId()).orElse(null);// 组装完整的订单详情DTOreturn OrderDetailDTO.builder().orderId(order.getId()).orderStatus(order.getStatus()).orderAmount(order.getAmount()).orderTime(order.getCreatedTime()).productName(product != null ? product.getName() : "未知商品").productImage(product != null ? product.getImageUrl() : null).userName(user != null ? user.getName() : "未知用户").userContact(user != null ? user.getPhone() : null).build();}
}
6.3 服务依赖与版本管理
随着微服务数量的增加,服务间的依赖关系变得复杂,版本管理也面临挑战:
- 语义化版本控制:遵循主版本.次版本.修订号的版本命名规范
- 契约测试:确保服务间接口的兼容性
- 依赖图可视化:监控和可视化服务间的依赖关系
- 渐进式发布:通过蓝绿部署、金丝雀发布等策略降低风险
// 契约测试示例(使用Spring Cloud Contract)
@RunWith(SpringRunner.class)
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.MOCK)
@AutoConfigureMessageVerifier
public class OrderServiceContractTest {@Autowiredprivate OrderService orderService;@Testpublic void validate_orderCreatedEvent() {// 准备测试数据OrderRequest request = new OrderRequest();request.setUserId("user123");request.setProductId("product456");request.setQuantity(2);// 执行被测方法orderService.createOrder(request);// 契约验证会自动检查发出的消息是否符合契约定义}
}
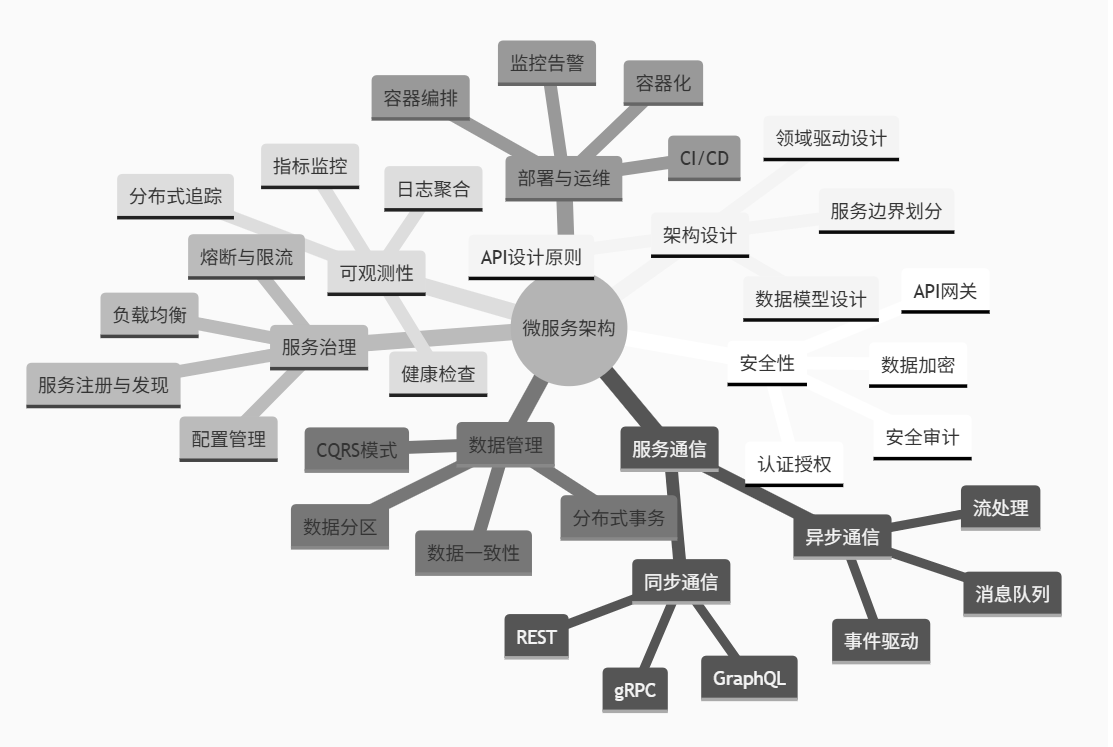
图6:微服务架构思维导图 - 展示微服务架构的核心要素
7. 微服务架构的演进与未来趋势
7.1 从微服务到云原生
微服务架构正在向云原生架构演进,云原生强调充分利用云平台的能力:
- 容器化:使用容器打包应用及其依赖
- 动态编排:自动化部署、扩展和管理容器化应用
- 微服务:将应用程序设计为松耦合的服务
- 声明式API:通过声明式API定义和管理应用
# Kubernetes自定义资源定义(CRD)示例
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:name: microservices.example.com
spec:group: example.comnames:kind: Microserviceplural: microservicessingular: microserviceshortNames:- msscope: Namespacedversions:- name: v1served: truestorage: trueschema:openAPIV3Schema:type: objectproperties:spec:type: objectproperties:serviceName:type: stringimage:type: stringreplicas:type: integerminimum: 1resources:type: objectproperties:cpu:type: stringmemory:type: stringdependencies:type: arrayitems:type: string
7.2 服务网格与Istio
服务网格是微服务通信的基础设施层,它解决了服务间通信的复杂性:
- 流量管理:智能路由、负载均衡、流量分割
- 安全通信:服务间的身份验证和加密通信
- 可观测性:请求跟踪、指标收集、日志记录
- 策略执行:访问控制、速率限制、配额管理
# Istio虚拟服务配置示例
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:name: order-servicenamespace: microservices
spec:hosts:- order-servicehttp:- match:- headers:x-api-version:exact: v2route:- destination:host: order-servicesubset: v2- route:- destination:host: order-servicesubset: v1
---
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:name: order-servicenamespace: microservices
spec:host: order-servicetrafficPolicy:loadBalancer:simple: ROUND_ROBINsubsets:- name: v1labels:version: v1- name: v2labels:version: v2trafficPolicy:loadBalancer:simple: LEAST_CONN
7.3 Serverless与函数计算
Serverless架构是微服务的进一步演进,它专注于业务逻辑而无需关心基础设施:
- 函数即服务(FaaS):如AWS Lambda、Azure Functions、阿里云函数计算等
- 事件驱动:函数由事件触发,如HTTP请求、消息队列、定时器等
- 自动扩展:根据负载自动扩展,空闲时不消耗资源
- 按使用付费:只为实际执行的计算资源付费
// AWS Lambda函数示例
public class OrderProcessor implements RequestHandler<APIGatewayProxyRequestEvent, APIGatewayProxyResponseEvent> {private final ObjectMapper objectMapper = new ObjectMapper();private final AmazonDynamoDB dynamoDB = AmazonDynamoDBClientBuilder.standard().build();private final String tableName = System.getenv("ORDERS_TABLE");@Overridepublic APIGatewayProxyResponseEvent handleRequest(APIGatewayProxyRequestEvent input, Context context) {try {// 解析请求OrderRequest orderRequest = objectMapper.readValue(input.getBody(), OrderRequest.class);// 生成订单IDString orderId = UUID.randomUUID().toString();// 创建订单项Map<String, AttributeValue> item = new HashMap<>();item.put("id", new AttributeValue(orderId));item.put("userId", new AttributeValue(orderRequest.getUserId()));item.put("productId", new AttributeValue(orderRequest.getProductId()));item.put("quantity", new AttributeValue().withN(String.valueOf(orderRequest.getQuantity())));item.put("status", new AttributeValue("CREATED"));item.put("createdAt", new AttributeValue(Instant.now().toString()));// 保存到DynamoDBdynamoDB.putItem(new PutItemRequest().withTableName(tableName).withItem(item));// 返回成功响应Map<String, String> responseBody = new HashMap<>();responseBody.put("orderId", orderId);responseBody.put("status", "CREATED");return new APIGatewayProxyResponseEvent().withStatusCode(201).withBody(objectMapper.writeValueAsString(responseBody)).withHeaders(Collections.singletonMap("Content-Type", "application/json"));} catch (Exception e) {context.getLogger().log("Error processing request: " + e.getMessage());// 返回错误响应Map<String, String> errorBody = new HashMap<>();errorBody.put("error", "Failed to process order");errorBody.put("message", e.getMessage());try {return new APIGatewayProxyResponseEvent().withStatusCode(500).withBody(objectMapper.writeValueAsString(errorBody)).withHeaders(Collections.singletonMap("Content-Type", "application/json"));} catch (JsonProcessingException ex) {return new APIGatewayProxyResponseEvent().withStatusCode(500).withBody("{\"error\":\"Internal Server Error\"}");}}}
}
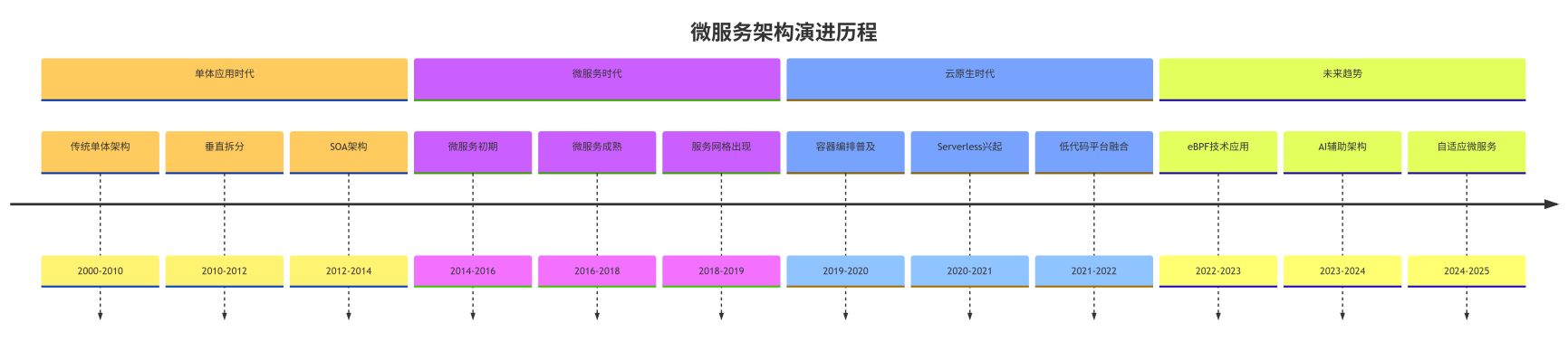 图7:微服务架构演进历程时间线 - 展示微服务架构的发展历程
图7:微服务架构演进历程时间线 - 展示微服务架构的发展历程
总结与展望
回顾我们从单体应用迁移到微服务架构的旅程,这是一段充满挑战但也收获颇丰的经历。微服务架构帮助我们解决了单体应用面临的扩展性、团队协作和技术栈固化等问题,但同时也带来了分布式系统的复杂性。通过领域驱动设计进行服务拆分,采用合适的服务通信机制,建立完善的服务治理体系,以及实践DevOps文化,我们成功地构建了一个灵活、可扩展、高可用的微服务架构。
在这个过程中,我深刻体会到微服务架构不仅仅是一种技术选择,更是一种组织结构和开发文化的变革。康威定律告诉我们,系统设计反映了组织的沟通结构。因此,微服务架构的成功实施需要组织结构、团队文化、技术实践三者的协同演进。
展望未来,微服务架构将继续向云原生方向发展,服务网格、Serverless、低代码平台等新技术将进一步降低微服务的开发和运维复杂性。人工智能和机器学习技术也将在服务治理、自动扩展、异常检测等方面发挥越来越重要的作用。
无论技术如何演进,微服务架构的核心理念——关注点分离、单一职责、自治性、弹性设计——将继续指导我们构建下一代分布式系统。作为架构师和开发者,我们需要不断学习和适应新技术,同时保持对基本原则的坚守,在复杂性和简单性之间找到平衡点,构建真正能够为业务创造价值的系统。
■ 我是蒋星熠Jaxonic!如果这篇文章在你的技术成长路上留下了印记
■ 👁 【关注】与我一起探索技术的无限可能,见证每一次突破
■ 👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
■ 🔖 【收藏】将精华内容珍藏,随时回顾技术要点
■ 💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
■ 🗳 【投票】用你的选择为技术社区贡献一份力量
■ 技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!
参考链接
- 微服务架构设计模式
- Spring Cloud官方文档
- Kubernetes官方文档
- Martin Fowler关于微服务的文章
- Istio服务网格文档
关键词标签
#微服务架构 #领域驱动设计 #服务治理 #DevOps #云原生