中国大学排名爬取与数据分析案例总结
一、案例概述
本案例展示了如何通过爬虫技术获取中国大学排名数据,并使用Python的pandas和可视化库进行数据预处理和分析的全过程。案例来源于高三网的中国大学排名一览表。
二、数据爬取部分
1.任务描述
目标网站:高三网中国大学排名一览表
爬取字段:学校名称、总分、全国排名、星级排名、办学层级
数据存储格式:CSV文件(school.csv)
二、数据预处理
数据预处理阶段主要处理了"总分"列中的空值问题,采用了四种不同的处理方法:
1.删除包含空字段的行
直接删除含有缺失值的整行数据,简单直接但可能导致数据量减少。
2.用指定内容替换空字段
例如用"无数据"或特定值(如0)填充缺失值,适用于某些特定场景。
3.计算列的均值替换空单元格
使用总分列的平均值填充缺失值,保持数据的统计特性。
4.计算列的中位数替换空单元格
使用中位数填充缺失值,对异常值不敏感。
实战案例爬取:
import requests
from bs4 import BeautifulSoup
import csv
def get_html(url, time=3):try:r = requests.get(url, timeout=time)r.encoding = r.apparent_encodingr.raise_for_status()return r.textexcept Exception as error:print(error)return None
def parser(html):soup = BeautifulSoup(html, "lxml")out_list = []for row in soup.select("table>tbody>tr"):td_html = row.select("td")row_data = [td_html[1].text.strip(),td_html[2].text.strip(),td_html[3].text.strip(),td_html[4].text.strip(),td_html[5].text.strip(),]out_list.append(row_data)return out_list
def save_csv(data, path):with open(path, "w+", newline='', encoding="utf-8") as f:csv_write = csv.writer(f)csv_write.writerows(data)
if __name__ == "__main__":url = "http://www.bspider.top/gaosan/"html = get_html(url)if html:out_list = parser(html)save_csv(out_list, "school.csv")
三、可视化方法
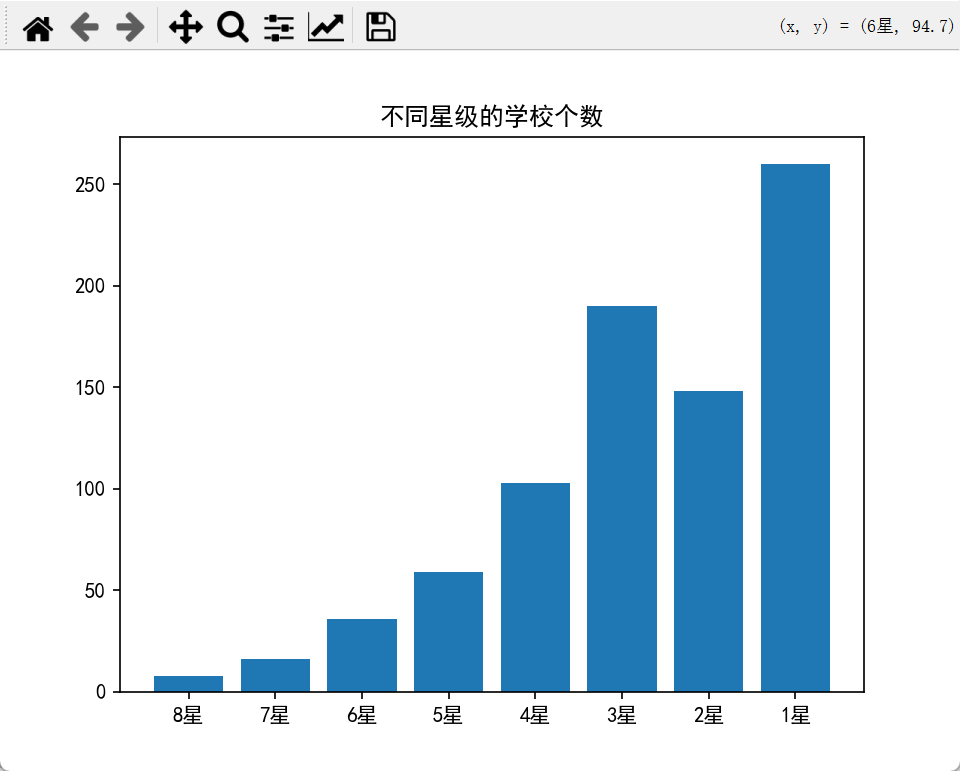
1.柱形图
适合展示各星级学校的数量对比,直观显示数量分布情况。
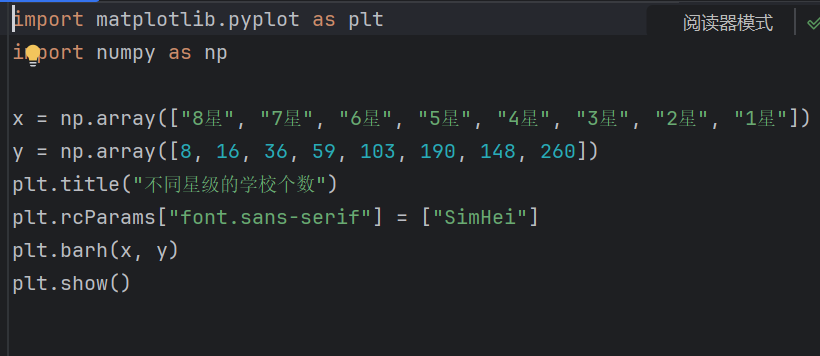
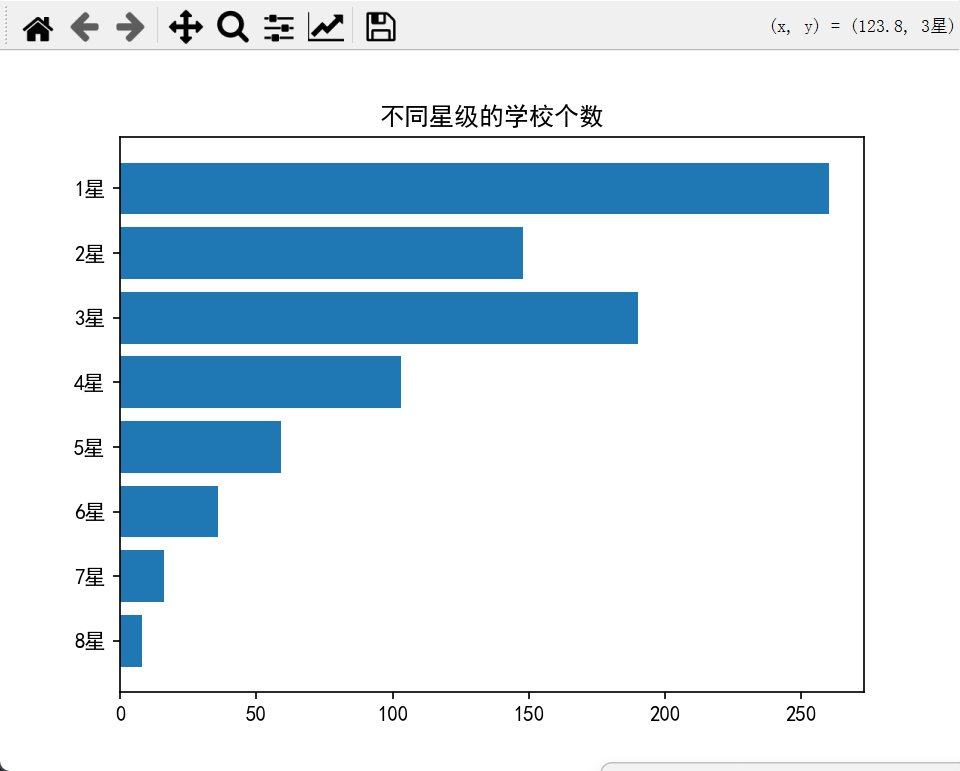
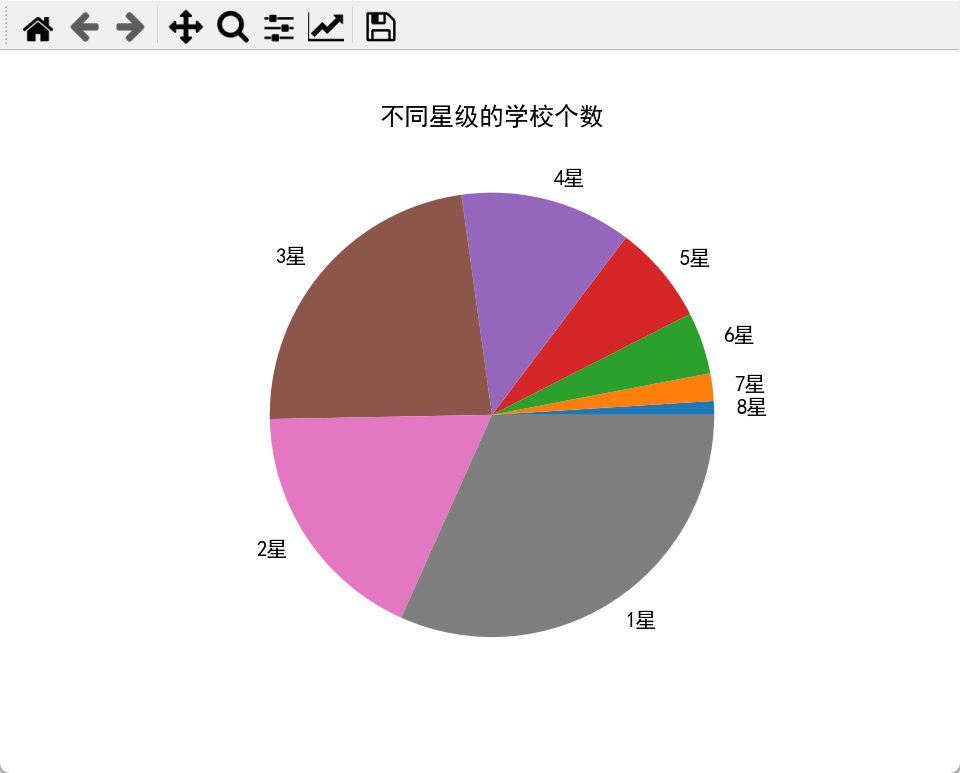
2.饼图
适合展示各星级学校所占比例,清晰呈现整体构成。
四、技术要点总结
1.爬虫技术
网页数据抓取 结构化数据提取 CSV文件存储
2.数据处理
Pandas缺失值处理 多种填充策略选择 数据统计计算
3.数据可视化
Matplotlib/Seaborn绘图 柱形图和饼图应用场景 数据比例展示技巧
五、实际应用价值
本案例展示了从数据获取到分析展示的完整流程,适用于:
教育行业研究
大学排名分析
学生择校参考
数据科学学习案例
通过这样的分析,我们可以清晰地了解中国高校的星级分布情况,为教育决策提供数据支持。