在本地部署Qwen大语言模型全过程总结
1. 理论计算
大语言模型要进行本地部署,先得选择一个与本地环境适配的模型。比如笔者这里选择的是Qwen1.5-7B-Chat,那么可以计算一下需要的存储空间大小:
- 这里的
7B代表7-billion,也就是7×10⁹参数。 - 每个参数是
4字节浮点型。 - 一次性加载所有参数需要
7×10⁹×4 Bytes的存储空间 7×10⁹×4 Bytes约等于28GB
入门消费级的显卡的显存是很少能满足这个存储要求的,比如笔者这里用的Nvidia GeForce RTX 4060 laptop只有8GB显存。为了能在这台机器上使用Qwen1.5-7B-Chat,就要进行量化。“量化”是个很专业的词汇,但其实没那么难理解,简单来说就是“压缩精度”,或者“降低分辨率”的意思。比如全精度的模型参数是4字节浮点型,将其重新映射到8位整型:
| 原始值(FP32) | 量化后(INT8) |
|---|---|
| 0.123 | 15 |
| -0.456 | -58 |
| 0.999 | 127 |
实现原理很简单,就是把一个浮点范围(比如-1.0到+1.0)划分成256个离散的等级(因为 8-bit可以表示2⁸=256个值),然后每个原始值“四舍五入”到最近的那个等级。这种处理办法在信号处理或者数字图形处理中也非常常见。
如果使用8-bit量化,那么7B模型大概只需要7GB显存,理论是可以在8GB显存的机器上部署的。不过实际上大模型运行不是只有模型权重参数这么简单,实际的显存占用=模型权重+中间缓存+ 优化器状态+输入输出等,所以最好还是使用4-bit量化。
2. 下载模型
一般开源的大模型都是托管在Hugging Face上,这里使用的Qwen1.5-7B-Chat也不例外。不过Hugging Face在国内因为网络问题连接不上,因此可以使用镜像站HF-Mirror。Hugging Face上的大模型数据可以使用git工具来下载,不过大模型的单个文件可能比较大,需要开启git lfs,使用起来还是有点麻烦。感觉git还是不太适合管理非代码项目,因此还是推荐使用Hugging Face 官方提供的命令行工具huggingface-cli来下载大模型。
首先是安装依赖:
pip install -U huggingface_hub
然后设置环境变量:
export HF_ENDPOINT=https://hf-mirror.com
最后下载模型:
huggingface-cli download --resume-download Qwen/Qwen1.5-7B-Chat --local-dir Qwen1.5-7B-Chat
3. 环境配置
需要说明的是因为部署大模型需要安装非常多的依赖包,它们之间的依赖关系可能不一致,所以有的时候会因为版本冲突安装不上。而且依赖库的源也一直在更新,现在不行说不定以后就可以了,只能讲讲大概的配置思路。
笔者这里使用的操作系统是Ubuntu Desktop 24.04 LTS,其实版本有点太新了,会导致低版本的CUDA或者PyTorch安装找不到相应的安装包。Linux的兼容性不像Windows那么强,有时候安装不上就只能重编译了。推荐使用Ubuntu 22.04版本可能会更好。
3.1 显卡驱动
安装显卡驱动:
sudo ubuntu-drivers autoinstall
笔者使用的是笔记本电脑,为了避免切换显卡的麻烦就在Ubuntu桌面的显卡设置中设置成独立显卡独占的模式。输入如下指令:
nvidia-smi
就会输出NVIDIA GPU的详细信息,包括使用的驱动版本、GPU温度、显存使用情况、功率消耗以及正在运行的进程等:
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.163.01 Driver Version: 550.163.01 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4060 ... Off | 00000000:01:00.0 Off | N/A |
| N/A 37C P8 3W / 55W | 189MiB / 8188MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------++-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 2699 G /usr/lib/xorg/Xorg 138MiB |
| 0 N/A N/A 3043 G /usr/bin/gnome-shell 40MiB |
| 0 N/A N/A 3227 G /opt/freedownloadmanager/fdm 2MiB |
+-----------------------------------------------------------------------------------------+
3.2 CUDA
安装CUDA除了要跟操作系统适配,还有个麻烦的地方就是不同的依赖包对CUDA版本的要求不一致。依赖包的冲突可以通过虚拟环境解决,但是CUDA版本冲突就有点麻烦;这里就介绍一下笔者的办法。
首先正常安装CUDA的某个版本,比如笔者先安装的是12.9。这时输入指令:
nvcc --version
可以检查是否安装好12.9的版本。然后输入指令:
which nvcc
这个指令是用来查询cuda在操作系统的具体路径。笔者显示的是:
/usr/local/cuda-12.9/bin/nvcc
那么操作系统是怎么找到这个路径地址的呢,一般是在安装CUDA的时候添加到~/.bashrc这个文件来实现的。~/.bashrc是Linux中一个非常重要的用户级shell配置文件,会在每次打开一个新的Bash终端时自动执行。打开这个文件夹,找到:
export PATH=/usr/local/cuda-12.9/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-12.9/lib64:$LD_LIBRARY_PATH
这部分配置,将其修改成:
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
/usr/local/cuda是个软链接,会指向/usr/local/cuda-12.9这个文件夹。我们的目标就是根据需要修改这个软链接,达到切换CUDA版本的目的。
接着安装CUDA的第二个版本,笔者这里安装的是CUDA 12.6。不太确定第二次安装是否会将软链接覆盖了,但是没有关系。安装好两个版本之后,如果要切换12.9版本:
sudo rm -f /usr/local/cuda
sudo ln -s /usr/local/cuda-12.9 /usr/local/cuda
如果要切换12.6版本:
sudo rm -f /usr/local/cuda
sudo ln -s /usr/local/cuda-12.6 /usr/local/cuda
切换完成之后可以通过指令nvcc --version查看是否修改成功:
charlee@charlee-pc:~$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2024 NVIDIA Corporation
Built on Fri_Jun_14_16:34:21_PDT_2024
Cuda compilation tools, release 12.6, V12.6.20
Build cuda_12.6.r12.6/compiler.34431801_0
3.3 库包
安装Anaconda的过程这里就不介绍了,使用Anaconda主要是为了配置Python虚拟环境,解决依赖库地狱的问题。安装完成后使用如下指令安装虚拟环境:
conda create --name llm python=3.11
然后激活虚拟环境:
conda activate llm
接下来就是安装开源深度学习框架PyTorch,这个包非常重要,并且一般不通过Python默认pip地址获取,在其官方网站提供了具体的下载指令。比如笔者使用的基于CUDA12.6的PyTorch 2.7.1版本:
pip install torch==2.7.1 torchvision==0.22.1 torchaudio==2.7.1 --index-url https://download.pytorch.org/whl/cu126
最后安装部署大模型需要的依赖包:
pip install bitsandbytes transformers accelerate
其中bitsandbytes是优化LLM推理和训练的开源工具库,这里用来进行4-bit量化。除了bitsandbytes,auto-gptq也可以4-bit量化,不过笔者第一次的环境中安装auto-gptq总是安装不上,就转成使用bitsandbytes了。应该是Python、显卡驱动或者CUDA的版本太高了不兼容。
4 进行对话
最后一步就是启动大语言模型与其对话了。其实可以使用像Ollama这样的工具来一键部署,或者使用Gradio来实现图形界面。不过这里这里还是简单的实现一轮对话的例子,因为笔者想以此来了解一点底层的东西。毕竟如果为了实现大模型对话,直接使用官方在线部署的大模型就可以了。具体的Python脚本如下所示:
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch# 修改为你的本地模型路径
model_id = "/home/charlee/work/Qwen1.5-7B-Chat"# 配置量化(可选)
quant_config = BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_compute_dtype=torch.float16
)# 从本地路径加载模型和分词器
model = AutoModelForCausalLM.from_pretrained(model_id,quantization_config=quant_config,device_map="auto",trust_remote_code=True
)tokenizer = AutoTokenizer.from_pretrained(model_id,trust_remote_code=True
)# 设置 pad_token
if tokenizer.pad_token is None:tokenizer.pad_token = tokenizer.eos_tokentokenizer.pad_token_id = tokenizer.eos_token_id# 构造对话输入
messages = [{"role": "user", "content": "用 Python 写一个快速排序"}]
inputs = tokenizer.apply_chat_template(messages,return_tensors="pt",add_generation_prompt=True
).to("cuda")# 生成 attention_mask
attention_mask = (inputs != tokenizer.pad_token_id).long()# 生成输出
outputs = model.generate(input_ids=inputs,attention_mask=attention_mask,max_new_tokens=512,temperature=0.6,top_p=0.9,do_sample=True,pad_token_id=tokenizer.eos_token_id,eos_token_id=tokenizer.eos_token_id
)# 只解码生成的部分
generated_ids = outputs[0][inputs.shape[-1]:]
response = tokenizer.decode(generated_ids, skip_special_tokens=True)
print(response)
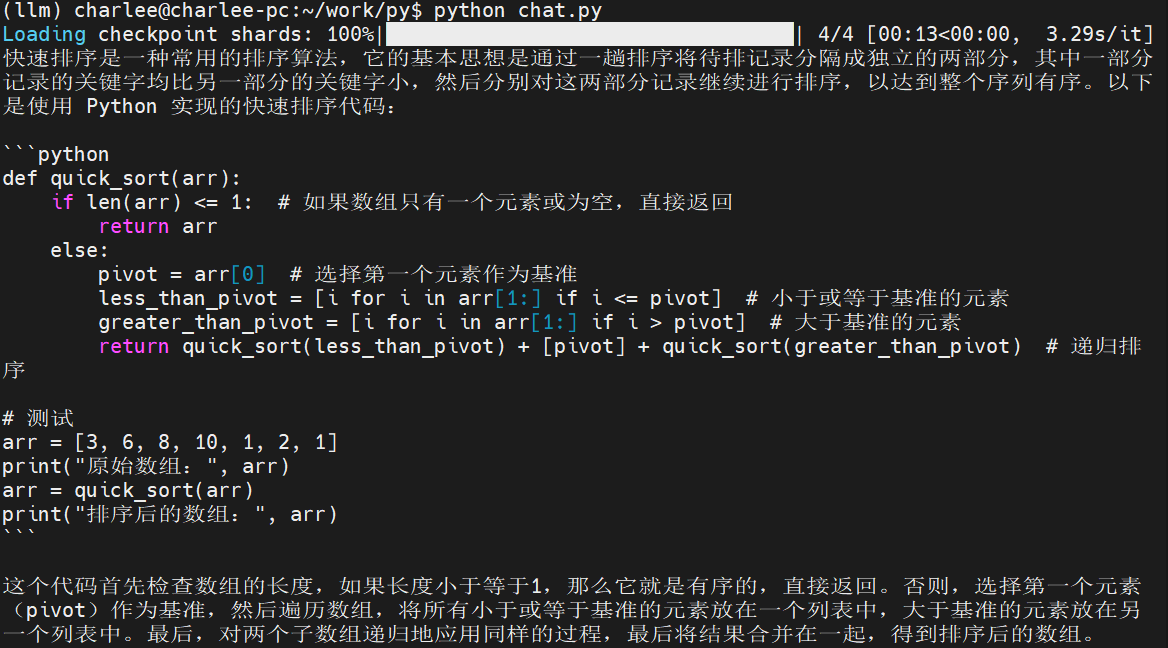
最终运行的结果如下所示: