数据处理分析环境搭建+Numpy使用教程
环境搭建
数据分析常用开源库
- Numpy
- NumPy(Numerical Python) 是 Python 语言的一个扩展程序库。
- 是一个运行速度非常快的数学库,主要用于数组计算
- 包含:
- 一个强大的N维数组对象 ndarray
- 广播功能函数
- 整合 C/C++/Fortran 代码的工具
- 线性代数、傅里叶变换、随机数生成等功能
- Pandas
- Pandas是一个强大的分析结构化数据的工具集
- 它的使用基础是Numpy(提供高性能的矩阵运算)
- 用于数据挖掘和数据分析,同时也提供数据清洗功能
- “利器”:
- Pandas利器之 Series,是一种类似于一维数组的对象
- Pandas利器之 DataFrame,是Pandas中的一个表格型的数据结构
- Matplotlib
- Matplotlib 是一个功能强大的数据可视化开源Python库
- 功能:
- Python中使用最多的图形绘图库
- 可以创建静态, 动态和交互式的图表
- Seaborn
- Seaborn是一个Python数据可视化开源库
- 特点:
- 建立在matplotlib之上,并集成了pandas的数据结构
- Seaborn通过更简洁的API来绘制信息更丰富,更具吸引力的图像
- 面向数据集的API,与Pandas配合使用起来比直接使用Matplotlib更方便
- Sklearn
- scikit-learn 是基于 Python 语言的机器学习工具
- 介绍:
- 简单高效的数据挖掘和数据分析工具
- 可供大家在各种环境中重复使用
- 建立在 NumPy ,SciPy 和 matplotlib 上
安装Anaconda
1. 介绍
- anaconda是最流行的数据分析平台,全球两千多万人在使用
- 特点:
- Anaconda 附带了一大批常用数据科学包
- Anaconda 是在 conda(一个包管理器和环境管理器)上发展出来的
- 可以帮助你在计算机上安装和管理数据分析相关包
- 包含了虚拟环境管理工具
2.安装
- Anaconda 可用于多个平台( Windows、Mac OS X 和 Linux)
- 安装:
- 可以在官网上下载对应平台的安装包
- 如果计算机上已经安装了 Python,安装不会对你有任何影响
- 安装的过程很简单,一路下一步即可
- https://www.anaconda.com/products/individual
3.界面
图形化使用
主界面:
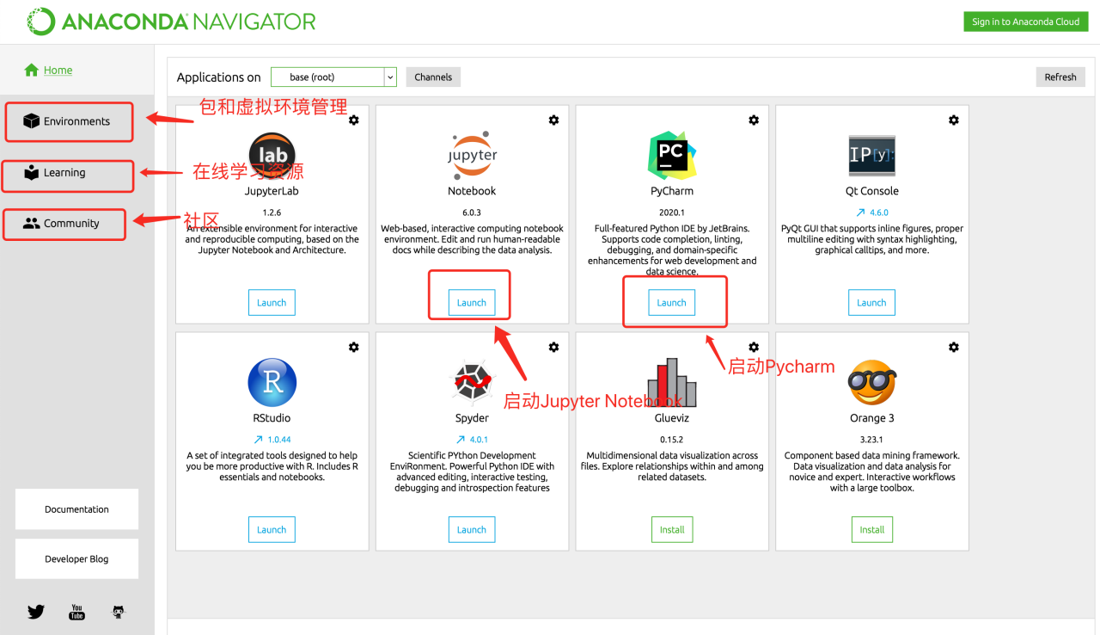
包和虚拟环境管理:
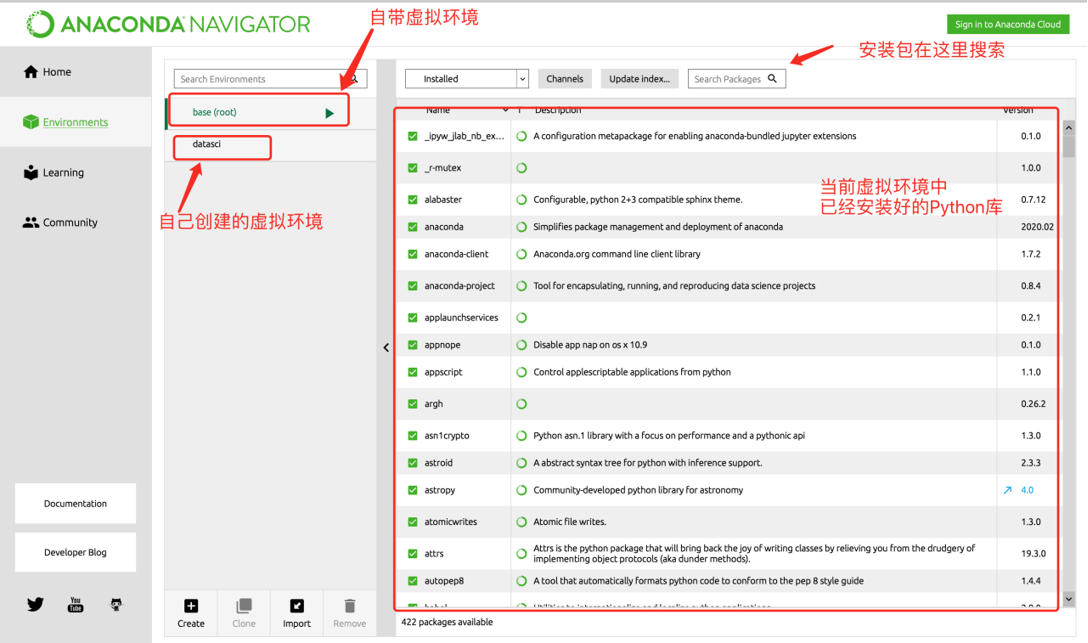
命令行方式使用
- 下载包
- conda install 包名字
- pip install 包名字
- 注意,使用pip时最好指定安装源:
- 阿里云:https://mirrors.aliyun.com/pypi/simple/
- 豆瓣:https://pypi.douban.com/simple/
- 清华大学:https://pypi.tuna.tsinghua.edu.cn/simple/
- 中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/
举例:pip install 包名 -i https://mirrors.aliyun.com/pypi/simple/ #通过阿里云镜像安装
- 注意,使用pip时最好指定安装源:
- 虚拟环境管理
- conda create -n 虚拟环境名字 python=python版本 #创建虚拟环境
- conda activate 虚拟环境名字 #进入虚拟环境
- conda deactivate #退出虚拟环境
- conda remove -n 虚拟环境名字 --all #删除虚拟环境
虚拟环境的作用
- 很多开源库版本升级后API有变化,老版本的代码不能在新版本中运行
- 将不同Python版本/相同开源库的不同版本隔离
- 不同版本的代码在不同的虚拟环境中运行
有兴趣的话也可以应用一下Jupyter Notebook,在处理数据时可以更加直观的查看数据,不过在实际项目开发中还是使用pycharm居多。
Numpy入门
简介:
1.介绍
NumPy(Numerical Python)是Python数据分析必不可少的第三方库
NumPy的出现一定程度上解决了Python运算性能不佳的问题,同时提供了更加精确的数据类型,使其具备了构造复杂数据类型的能力。
本身是由C语言开发,是个很基础的扩展,NumPy被Python其它科学计算包作为基础包,因此理解np的数据类型对python数据分析十分重要。
NumPy重在数值计算,主要用于多维数组(矩阵)处理的库。用来存储和处理大型矩阵,比Python自身的嵌套列表结构要高效的多
2. 功能
-
高性能科学计算和数据分析的基础包
-
ndarray,多维数组,具有矢量运算能力,快速、节省空间
-
矩阵运算,无需循环,可完成类似Matlab中的矢量运算
-
用于读写磁盘数据的工具以及用于操作内存映射文件的工具
3. 属性
NumPy的数组类被称作ndarray,通常被称作数组。
- ndarray对象属性有:
- ndarray.ndim ——对象维度
- ndarray.shape ——对象形状
- ndarray.size ——对象元素个数
- ndarray.dtype ——对象元素类型
- ndarray.itemsize ——对象每个元素字节数
数组的维度。这是一个指示数组在每个维度上大小的整数元组。例如一个n排m列的矩阵,它的shape属性将是(n,m),这个元组的长度显然是秩,即维度或者ndim属性。
示例:
import numpy as np # 后续省略导包
a = np.arange(15).reshape(3,5)
print(f"数组对象:{a}")
print(f"数组的维度:{a.shape}")
print(f"数组轴的个数(维度数):{a.ndim}")
print(f"数组元素的类型:{a.dtype}")
print(f"数组中每个元素的字节大小:{a.itemsize}")
print(f"数组元素的总个数:{a.size}")
print(f"数组类型:{type(a)}")
输出结果:
数组对象:[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]]
数组的维度:(3, 5)
数组轴的个数(维度数):2
数组元素的类型:int32
数组中每个元素的字节大小:4
数组元素的总个数:15
数组类型:<class ‘numpy.ndarray’>
创建ndarray
NumPy数组是一个多维的数组对象(矩阵),称为ndarray,具有矢量算术运算能力和复杂的广播能力,并具有执行速度快和节省空间的特点。注意:ndarray的下标从0开始,且数组里的所有元素必须是相同类型。
1.array()
最基础的创建方式将列表转换为数组
示例:
a = np.array([2,3,4])
print(f"数组a;{a}")
print(f"数组a的类型:{type(a)}")
print(f"数组a的元素类型:{a.dtype}")
b = np.array([1.2,3.5,4.5])
print(f"数组b;{b}")
print(f"数组b的类型:{type(b)}")
print(f"数组b的元素类型:{b.dtype}")
输出结果:
数组a;[2 3 4]
数组a的类型:<class ‘numpy.ndarray’>
数组a的元素类型:int32
数组b;[1.2 3.5 4.5]
数组b的类型:<class ‘numpy.ndarray’>
数组b的元素类型:float64
2.zeros()、ones()、empty()
函数zeros创建一个全是0的数组,函数ones创建一个全是1的数组,函数empty创建一个内容随机并且依赖于内存状态的数组。默认创建的数组类型(dtype)都是float64
示例:
zeros1 = np.zeros((3,4))
print(f"zeros1对象:{zeros1}")
ones1 = np.ones((2,3,4))
print(f"ones1对象:{ones1}")
empty1 = np.empty((2,3))
print(f"empty1对象:{empty1}")
输出结果:
zeros1对象:[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]]
ones1对象:[[[1. 1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]][[1. 1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]]]
empty1对象:[[0. 0. 0.]
[0. 0. 0.]] ——也可能全是‘1.’,具体看当前内存状态
3.arange()
arange()类似python中的range(),创建一个一维ndarray数组
示例:
# 创建一维数组
arange1 = np.arange(1,10,2,dtype=int)
print(f"arange1对象:{arange1}")
print(f"arange1的元素类型:{arange1.dtype}")
print(f"arange1的类型:{type(arange1)}")
# 创建多维数组
arange2 = np.arange(1,24,2).reshape(2,3,2)
print(f"arange2对象:{arange2}")
输出结果:
arange1对象:[1 3 5 7 9]
arange1的元素类型:int32
arange1的类型:<class ‘numpy.ndarray’>
arange2对象:[[[ 1 3]
[ 5 7]
[ 9 11]][[13 15]
[17 19]
[21 23]]]
4.matrix()
matrix()是ndarray的子类,只能生成二维矩阵
示例:
#%%
matrix1 = np.mat("1 2 ;3 4")
print(f"matrix1对象:{matrix1}")
matrix2 = np.mat("1,2;3,4")
print(f"matrix2对象:{matrix2}")
matrix3 = np.matrix([[1,2],[3,4]])
print(f"matrix3对象:{matrix3}")
执行结果:
matrix1对象:[[1 2]
[3 4]]
matrix2对象:[[1 2]
[3 4]]
matrix3对象:[[1 2]
[3 4]]
5.创建随机数矩阵random()、randint()、rand()
示例:
# 生成指定维度大小(3行4列)的随机多维浮点数类型(二维),rand固定区间0-1
rand1 = np.random.rand(3,4)
print(f"rand1对象:{rand1}")
print(f"rand1对象类型:{type(rand1)}")
# 生成指定维度大小(3行4列)的随机多维整型类型(二维),randint可指定区间
randint2 = np.random.randint(-1,5,size=(3,4))
print(f"randint2对象:{randint2}")
print(f"randint2对象类型:{type(randint2)}")
# 生成指定维度大小(3行4列)的随机多维浮点类型(二维),uniform()可指定区间产生区间内的均匀分布的样本值
randbool3 = np.random.uniform(-1,5,size=(3,4))
print(f"randbool3对象:{randbool3}")
print(f"randbool3对象类型:{type(randbool3)}")
输出结果:
rand1对象:[[0.51657543 0.46933998 0.54730841 0.59782747]
[0.27987993 0.81272003 0.1197689 0.3966129 ]
[0.80375874 0.85541626 0.70941071 0.90645264]]
rand1对象类型:<class ‘numpy.ndarray’>
randint2对象:[[0 4 2 1]
[2 2 2 1]
[4 3 0 3]]
randint2对象类型:<class ‘numpy.ndarray’>
randbool3对象:[[ 3.04256546 0.81151277 3.75742076 2.05055554]
[ 1.43728236 -0.51144312 3.93002313 3.23797794]
[ 4.33968391 4.09649474 -0.05946382 2.73362253]]
randbool3对象类型:<class ‘numpy.ndarray’>
6.等比、等差数列 logspace()、linspace()
- 等比数列(geometric sequence):
使用 np.logspace() 函数创建等比数列
语法:np.logspace(start, stop, num, base)- start: 起始指数
- stop: 结束指数
- num: 生成元素个数
- base: 底数,默认为10
示例:
# 创建以10为底,指数从0到0的等比数列(10^0 = 1),共10个元素,所有元素都是1
a = np.logspace(0,0,10)
print(f"a对象:{a}")# 创建以10为底,指数从0到9的等比数列(10^0, 10^1, ..., 10^9),共10个元素
a = np.logspace(0,9,10)
print(f"a对象:{a}")# 创建以2为底,指数从0到9的等比数列(2^0, 2^1, ..., 2^9),共10个元素
a = np.logspace(0,9,10,base=2)
print(f"a对象:{a}")
输出结果:
a对象:[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
a对象:[1.e+00 1.e+01 1.e+02 1.e+03 1.e+04 1.e+05 1.e+06 1.e+07 1.e+08 1.e+09]
a对象:[ 1. 2. 4. 8. 16. 32. 64. 128. 256. 512.]
- 等差数列(arithmetic sequence):
使用 np.linspace() 函数创建等差数列
语法:np.linspace(start, stop, num, endpoint)- start: 起始值
- stop: 结束值
- num: 生成元素个数
- endpoint: 是否包含结束值,默认为True
示例:
# 创建从1到10的等差数列,不包含终点值10,共10个元素
# 实际生成1, 1.9, 2.8, ..., 9.1(不包含10)
a = np.linspace(1,10,10,endpoint=False)
print(f"a对象:{a}")# 创建从1到10的等差数列,包含终点值10,共10个元素
# 生成1, 2, 3, ..., 10
a = np.linspace(1,10,10)
print(f"a对象:{a}")
输出结果:
a对象:[1. 1.9 2.8 3.7 4.6 5.5 6.4 7.3 8.2 9.1]
a对象:[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
7.补充(ndarray的数据类型)
- dtype参数,指定数组的数据类型,类型名+位数,如float64, int32
- astype方法,转换数组的数据类型
示例:
# 初始化3行4列数组,数据类型为float64
arr = np.zeros((3,4),dtype=np.float64)
print(f"arr对象:{arr}")
print(f"arr.dtype对象:{arr.dtype}")
# astype()转换数据类型,将已有的数组的数据类型转换为int32
arr = arr.astype(np.int32)
print(f"arr对象:{arr}")
print(f"arr.dtype对象:{arr.dtype}")
输出结果:
arr对象:[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]]
arr.dtype对象:float64
arr对象:[[0 0 0 0]
[0 0 0 0]
[0 0 0 0]]
arr.dtype对象:int32
Numpy内置函数
1.基本函数
- np.ceil(): 向上最接近的整数,参数是 number 或 array
- np.floor(): 向下最接近的整数,参数是number 或 array
- np.rint(): 四舍五入,参数是 number 或 array
- np.isnan():判断元素是否为 NaN(Not a Number),参数是 number 或 array
- np.multiply(): 元素相乘,参数是number 或 array
- np.divide(): 元素相除,参数是 number 或 array
- np.abs():元素的绝对值,参数是 number 或 array
- np.where(condition, x, y):三元运算符,x if condition else y
示例:
# randn()返回具有标准正太分布的序列
arr = np.random.randn(2,3)
print(f"arr对象:{arr}")
print(f"向上最接近的整数:{np.ceil(arr)}")
print(f"向下最接近的整数:{np.floor(arr)}")
print(f"四舍五入:{np.rint(arr)}")
print(f"是否为NaN:{np.isnan(arr)}")
print(f"元素相乘:{np.multiply(arr,2)}")
print(f"元素相除:{np.divide(arr,2)}")
print(f"元素的绝对值:{np.abs(arr)}")
print(f"三元运算符:{np.where(arr>0,arr,0)}")
输出结果:(由于数组是随机生成,结果可能不一致,可自行尝试)
arr对象:[[-0.30998461 -0.47490616 -0.71112109]
[-0.30427226 -0.0176675 0.63126093]]
向上最接近的整数:[[-0. -0. -0.]
[-0. -0. 1.]]
向下最接近的整数:[[-1. -1. -1.]
[-1. -1. 0.]]
四舍五入:[[-0. -0. -1.]
[-0. -0. 1.]]
是否为NaN:[[False False False]
[False False False]]
元素相乘:[[-0.61996921 -0.94981233 -1.42224219]
[-0.60854452 -0.03533501 1.26252186]]
元素相除:[[-0.1549923 -0.23745308 -0.35556055]
[-0.15213613 -0.00883375 0.31563046]]
元素的绝对值:[[0.30998461 0.47490616 0.71112109]
[0.30427226 0.0176675 0.63126093]]
三元运算符:[[0. 0. 0. ]
[0. 0. 0.63126093]]
2.统计函数
- np.mean(), np.sum():所有元素的平均值,所有元素的和,参数是 number 或 array
- np.max(), np.min():所有元素的最大值,所有元素的最小值,参数是 number 或 array
- np.std(), np.var():所有元素的标准差,所有元素的方差,参数是 number 或 array
- np.argmax(), np.argmin():最大值的下标索引值,最小值的下标索引值,参数是 number 或 array
- np.cumsum(), np.cumprod():返回一个一维数组,每个元素都是之前所有元素的 累加和 和 累乘积,参数是 number 或 array
多维数组默认统计全部维度,axis参数可以按指定轴心统计,值为0则按列统计,值为1则按行统计。
示例:
arr = np.arange(12).reshape(3,4)
print(f"arr对象:{arr}")
print(f"平均值:{arr.mean()}")
print(f"行平均值:{arr.mean(axis=1)}")
print(f"列平均值:{arr.mean(axis=0)}")
print(f"求和:{arr.sum()}")
print(f"最大值:{arr.max()}")
print(f"行最大值:{arr.max(axis=1)}")
print(f"列最大值:{arr.max(axis=0)}")
print(f"最小值:{arr.min()}")
print(f"标准差:{arr.std()}")
print(f"方差:{arr.var()}")
print(f"argmax最大值索引值:{arr.argmax()}")
print(f"argmin最小值索引值:{arr.argmin()}")
print(f"cumsum累计求和:{arr.cumsum()}")
print(f"cumprod累计乘积:{arr.cumprod()}")
输出结果:
arr对象:[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
平均值:5.5
行平均值:[1.5 5.5 9.5]
列平均值:[4. 5. 6. 7.]
求和:66
最大值:11
行最大值:[ 3 7 11]
列最大值:[ 8 9 10 11]
最小值:0
标准差:3.452052529534663
方差:11.916666666666666
argmax最大值索引值:11
argmin最小值索引值:0
cumsum累计求和:[ 0 1 3 6 10 15 21 28 36 45 55 66]
cumprod累计乘积:[0 0 0 0 0 0 0 0 0 0 0 0]
3.比较函数
假如我们想要知道矩阵a和矩阵b中所有对应元素是否相等,我们需要使用all方法,假如我们想要知道矩阵a和矩阵b中对应元素是否有一个相等,我们需要使用any方法。
- np.any(): 至少有一个元素满足指定条件,返回True
- np.all(): 所有的元素满足指定条件,返回True
示例:
arr = np.random.randn(2,3)
print(f"arr对象:{arr}")
print(f"any:{np.any(arr>0)}")
print(f"all:{np.all(arr>0)}")
输出结果:(注意随机生成,结果不唯一)
arr对象:[[-0.10424761 0.07216956 -0.56395871]
[-1.69753658 1.27939205 -0.43498833]]
any:True
all:False
4.去重函数
np.unique():找到唯一值并返回排序结果,类似于Python的set集合
示例:
arr = np.array([[1,2,1],[2,3,4]])
print(f"arr对象:{arr}")
print(f"去重后arr对象:{np.unique(arr)}")
输出结果:
arr对象:[[1 2 1]
[2 3 4]]
去重后arr对象:[1 2 3 4]
5.排序函数
对数组元素进行排序
示例:
arr = np.array([4,2,3,5,1])
print(f"arr对象:{arr}")
# np.sort()函数排序,返回排序后的副本
sortarr1 = np.sort(arr)
print(f"np.sort(arr)对象:{sortarr1}")
print(f"使用np.sort()后的arr对象:{arr}")
# ndarray直接调用sort,在原数据上进行修改
arr.sort()
print(f"ndarray直接调用sort后的arr对象:{arr}")
输出结果:(注意区分两种排序的区别)
arr对象:[4 2 3 5 1]
np.sort(arr)对象:[1 2 3 4 5]
使用np.sort()后的arr对象:[4 2 3 5 1]
ndarray直接调用sort后的arr对象:[1 2 3 4 5]
Numpy运算
1.基本运算
数组的算数运算是按照元素的。新的数组被创建并且被结果填充。
示例:
# numpy基础
a = np.array([1,2,3])
b = np.array([4,5,6])
c = a - b
d = a + b
print(f"a对象:{a}")
print(f"b对象:{b}")
print(f"c对象:{c}")
print(f"d对象:{d}")
输出结果:
a对象:[1 2 3]
b对象:[4 5 6]
c对象:[-3 -3 -3]
d对象:[5 7 9]
2.矩阵乘法
- 行列数相同时
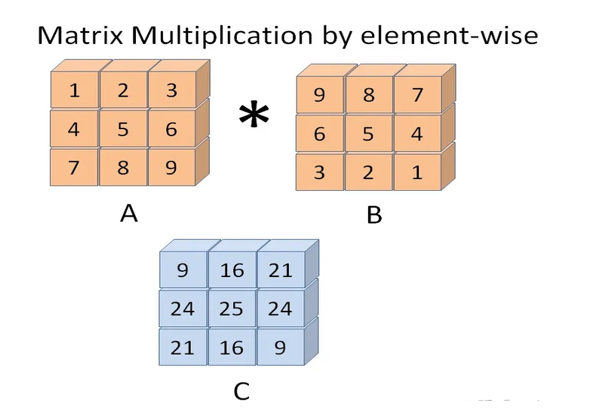
示例:
a = np.array([[1,2,3],[4,5,6]])
b = np.array([[7,8,9],[10,11,12]])
c = a * b
print(f"a对象:{a}")
print(f"b对象:{b}")
print(f"c对象:{c}")
输出结果:
a对象:[[1 2 3]
[4 5 6]]
b对象:[[ 7 8 9]
[10 11 12]]
c对象:[[ 7 16 27]
[40 55 72]]
- 行列数不同时
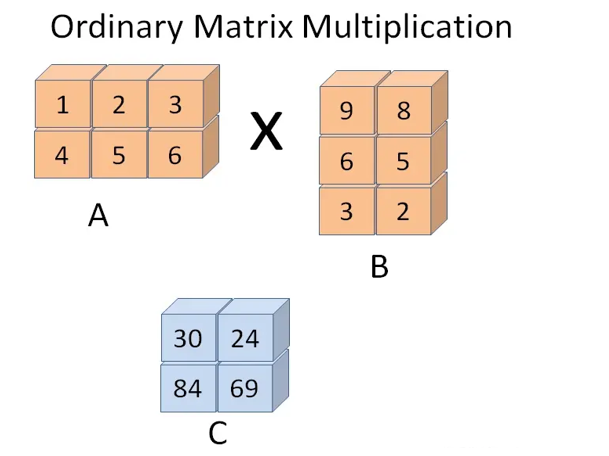
计算方法:
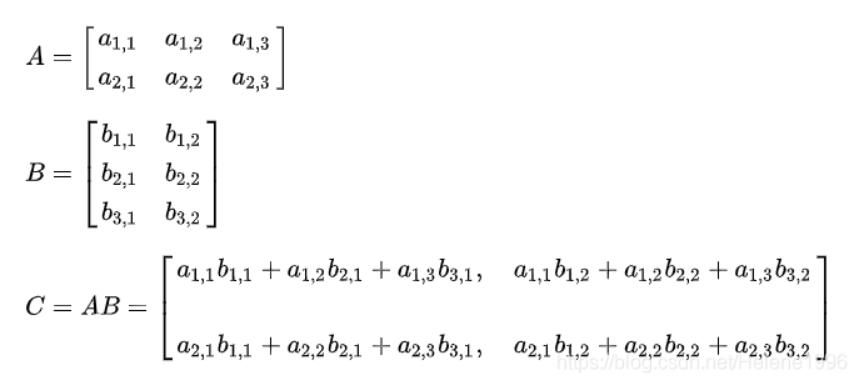
示例:
a = np.array([[1,2,3],[4,5,6]])
b = np.array([[7,8],[9,10],[11,12]])
c = a.dot(b) # 此时不能用a*b,因为a和b的行数和列数不同
print(f"a对象:{a}")
print(f"b对象:{b}")
print(f"c对象:{c}")
输出结果:
a对象:[[1 2 3]
[4 5 6]]
b对象:[[ 7 8]
[ 9 10]
[11 12]]
c对象:[[ 58 64]
[139 154]]
有关矩阵的更多计算可自行学习线性代数相关知识,这里不多做补充。