数据结构初阶:排序算法(一)插入排序、选择排序
个人主页:胡萝卜3.0
🎬作者简介:C++研发方向学习者
📖个人专栏: 《C语言》《数据结构》 《C++干货分享》
⭐️人生格言:不试试怎么知道自己行不行

目录
正文
一、排序概念及运用
1.1 概念
1.2 运用
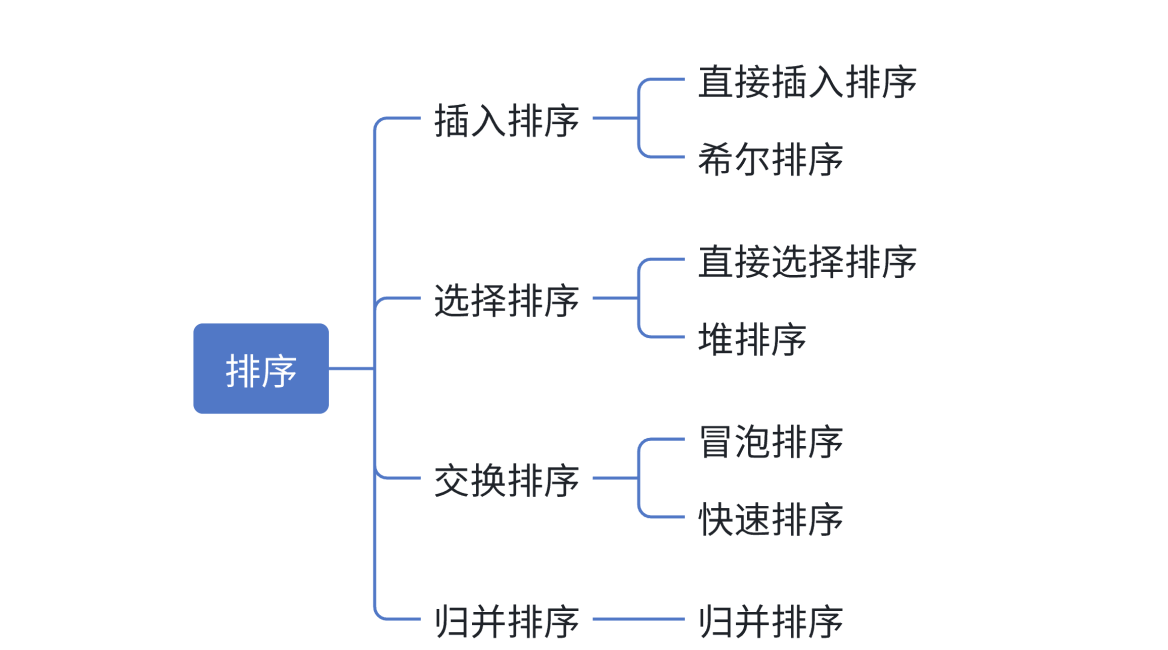
1.3 常见的排序算法
对比排序性能:测试代码
二、插入排序
2.1 直接插入排序
2.2 希尔排序
2.2.1 代码实现:
2.2,2 希尔排序的时间复杂度计算
2.2.3 希尔排序的特性
三、选择排序
3.1 直接选择排序
3.1.1 直接选择排序的思想
3.1.2 代码实现
3.1.3 直接选择排序的特性
3.2 堆排序
3.2.1 向下调整
3.2.2 堆排序的代码(使用向下调整建大堆)
3.2.3 堆排序时间复杂度计算
3.2.4 堆排序的特性
正文
一、排序概念及运用
1.1 概念
排序:所谓排序,就是使⼀串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。
1.2 运用
购物筛选排序
院校排名
1.3 常见的排序算法
比较排序:
除此之外,还有非比较的排序算法——计数排序。
对比排序性能:测试代码
代码演示:
//测试排序的性能对比
void TestOP()
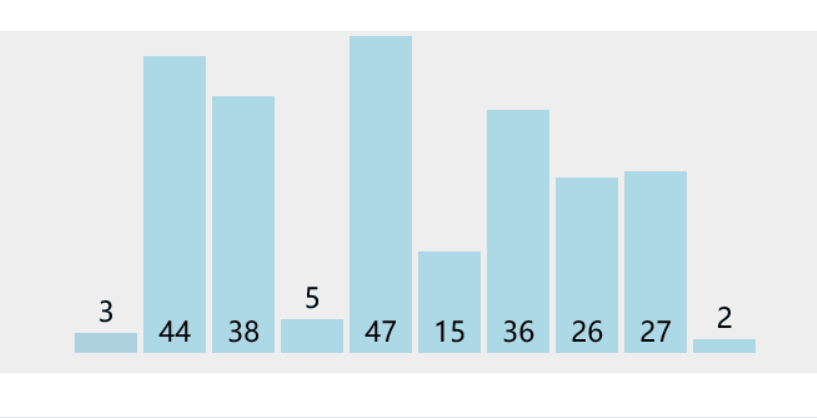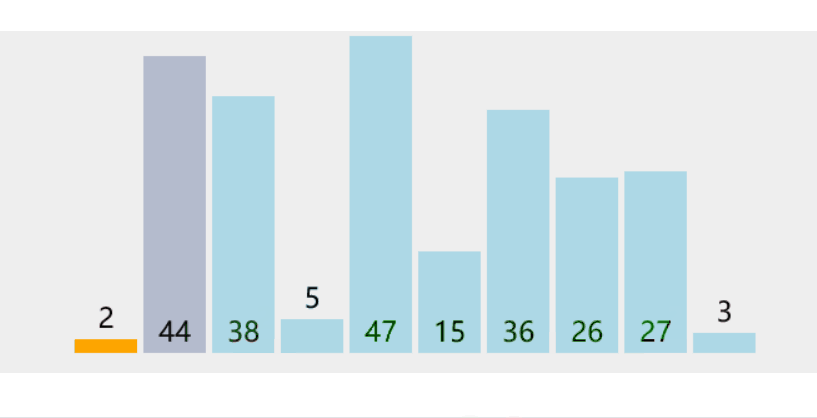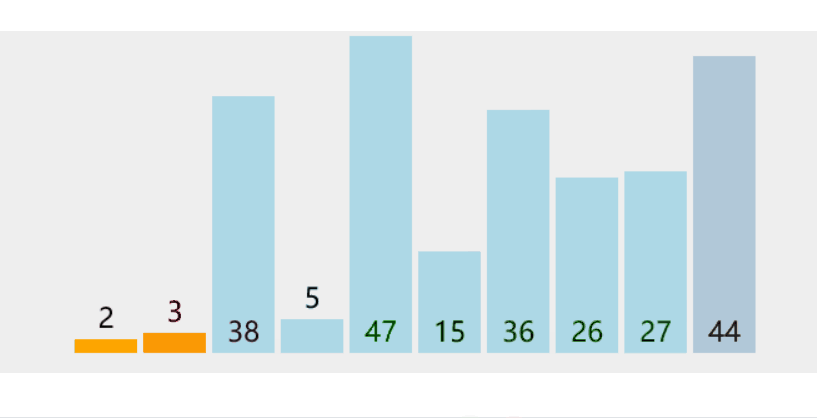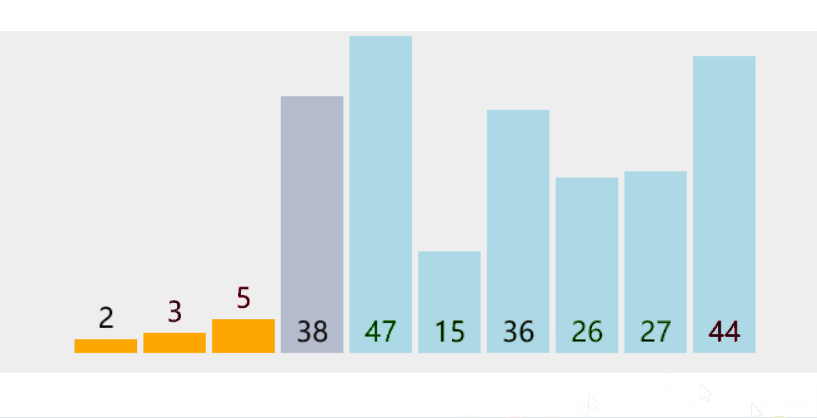
{srand(time(0));const int N = 100000;int* a1 = (int*)malloc(sizeof(int) * N);int* a2 = (int*)malloc(sizeof(int) * N);int* a3 = (int*)malloc(sizeof(int) * N);int* a4 = (int*)malloc(sizeof(int) * N);int* a5 = (int*)malloc(sizeof(int) * N);int* a6 = (int*)malloc(sizeof(int) * N);int* a7 = (int*)malloc(sizeof(int) * N);for (int i = 0; i < N; ++i){a1[i] = rand();a2[i] = a1[i];a3[i] = a1[i];a4[i] = a1[i];a5[i] = a1[i];a6[i] = a1[i];a7[i] = a1[i];}//begin和end的时间差就是int begin1 = clock();InsertSort(a1, N);int end1 = clock();int begin2 = clock();ShellSort(a2, N);int end2 = clock();int begin3 = clock();SelectSort(a3, N);int end3 = clock();int begin4 = clock();HeapSort(a4, N);int end4 = clock();int begin5 = clock();QuickSort(a5, 0, N - 1);int end5 = clock();int begin6 = clock();MergeSort(a6, N);int end6 = clock();int begin7 = clock();BubbleSort(a7, N);int end7 = clock();printf("InsertSort:%d\n", end1 - begin1);printf("ShellSort:%d\n", end2 - begin2);printf("SelectSort:%d\n", end3 - begin3);printf("HeapSort:%d\n", end4 - begin4);printf("QuickSort:%d\n", end5 - begin5);printf("MergeSort:%d\n", end6 - begin6);printf("BubbleSort:%d\n", end7 - begin7);free(a1);free(a2);free(a3);free(a4);free(a5);free(a6);free(a7);
}单位是毫秒(ms),1000 ms = 1s,和算法的时间复杂度挂钩。
接下来,让我们一起学习这些排序算法:
二、插入排序
基本思想:把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为止,得到一个新的有序序列。
ok,这说的是啥意思呢?简单来说就是将待排序的序列插入到已经排好序的序列中。
简单举个列子:
生活中,扑克牌应该都玩过吧,现在我的手里有一堆已经排好序的扑克牌,过了一会,我又摸了一张,那我是不是要将这张牌插入到已经排好序的牌中,使它又是一个有序的牌。通过上面的操作,我们就实现可插入排序

2.1 直接插入排序
直接插入排序是一种简单的插入排序算法,它的基本思路和插入排序的思路一样:把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为止,得到一个新的有序序列。
以从小到大排序为例
1、从第一个元素开始,可以看成一个有序序列
2、取出下一个元素,与前面已经排好序的元素进行比较,如果前面的元素大于此元素,就把前面的元素往后移,继续往前找,找到小于后等于的位置进行插入,直到找到最前面
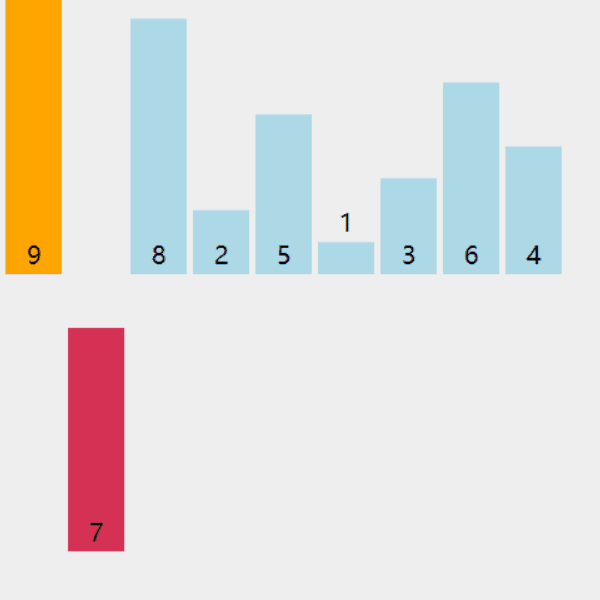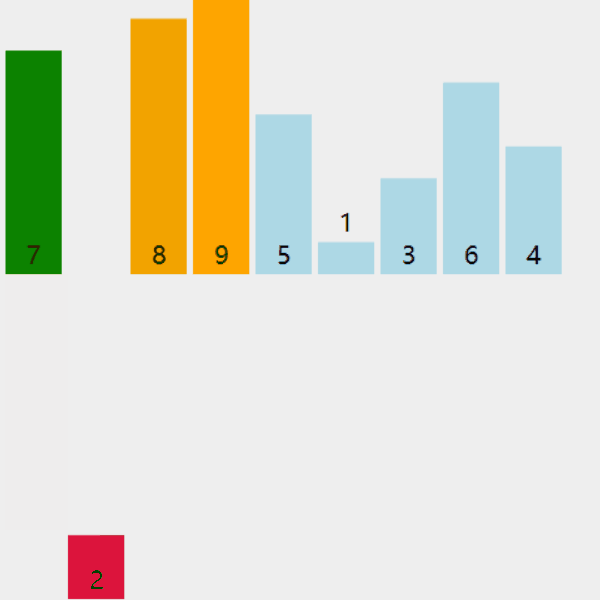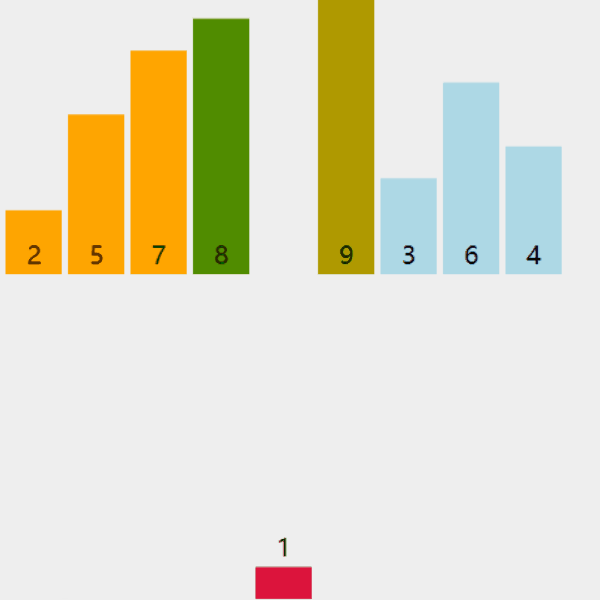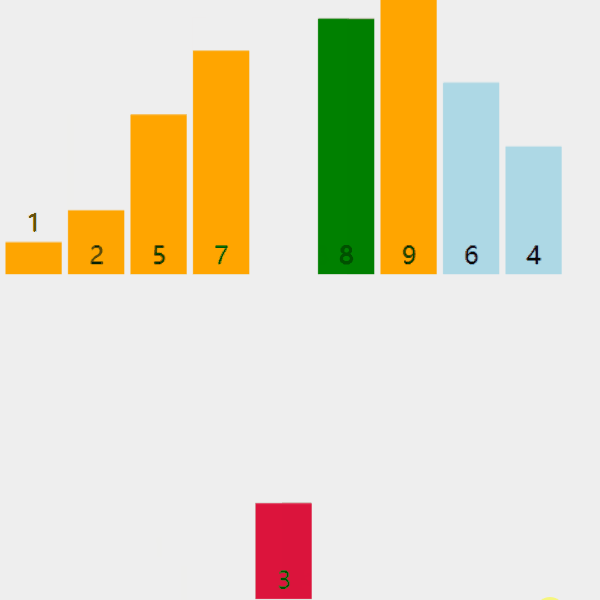
1、代码实现:
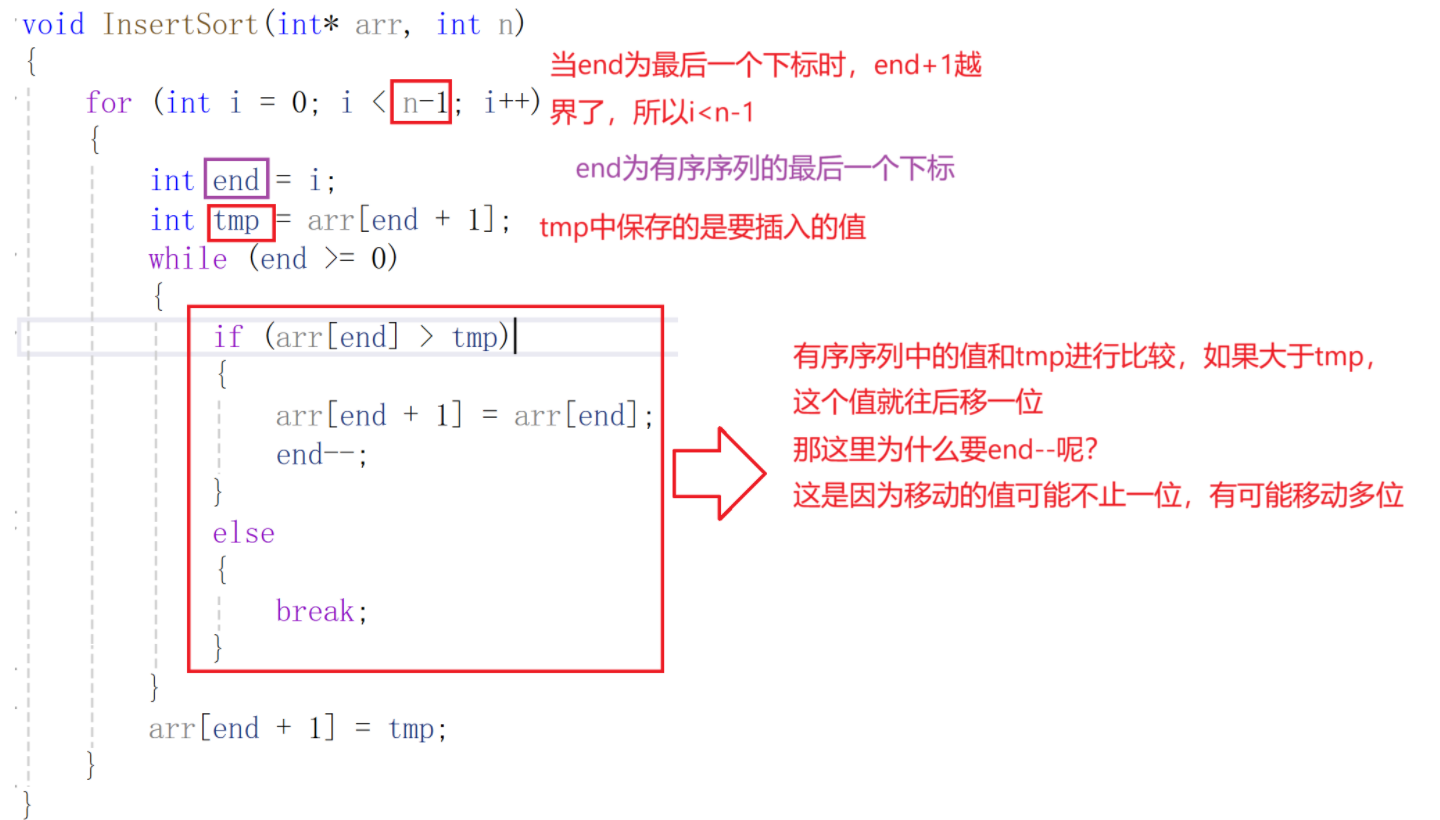
void InsertSort(int* arr, int n)
{for (int i = 0; i < n-1; i++){int end = i;int tmp = arr[end + 1];while (end >= 0){if (arr[end] > tmp){arr[end + 1] = arr[end];end--;}else{break;}}arr[end + 1] = tmp;}
}
2、直接插入排序的时间复杂度
直接插入排序的时间复杂度:O(n^2)
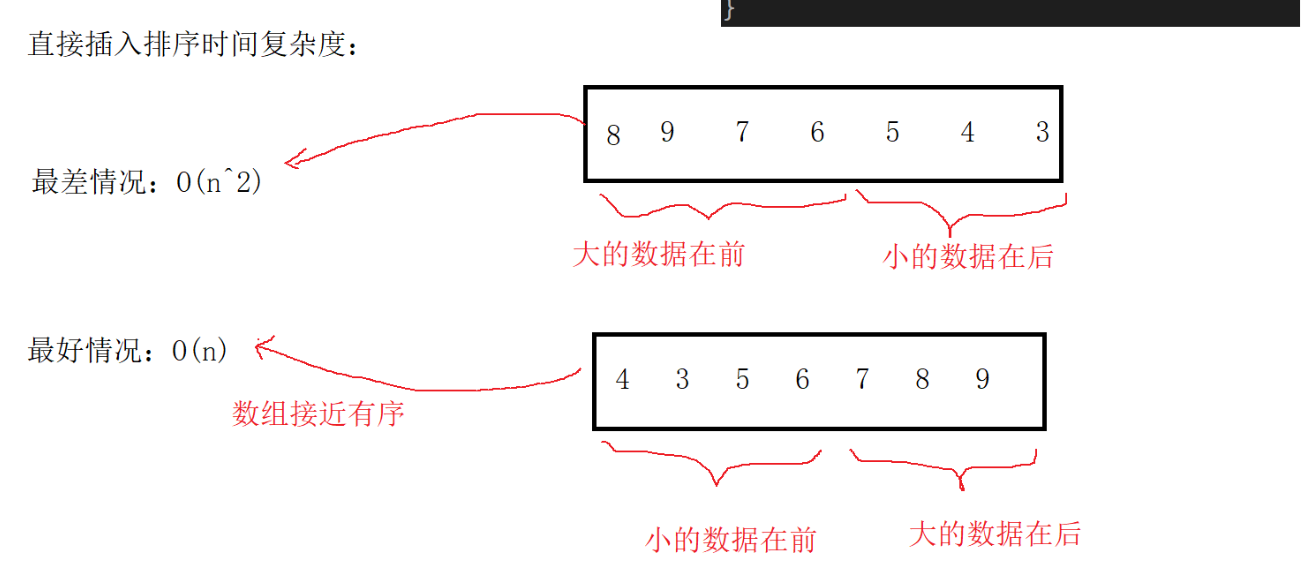
直接插入排序的特性总结:
1、元素集合越接近有序,直接插入排序算法的时间效率越高;
2、时间复杂度:O(N^2) ;
3、空间复杂度:O(1)。
不过虽然有所谓的最好情况O(N),但这种情况非常少见。
在前面的学习中,我们学习了冒泡排序,冒泡排序的时间复杂度也是O(n^2),这个时间复杂度是一个很差的情况,那我们可不可以优化一下呢?使这个时间复杂度降一下呢?哎,我们下面要介绍的另一种插入排序的方法——希尔排序——就登场了!!
2.2 希尔排序
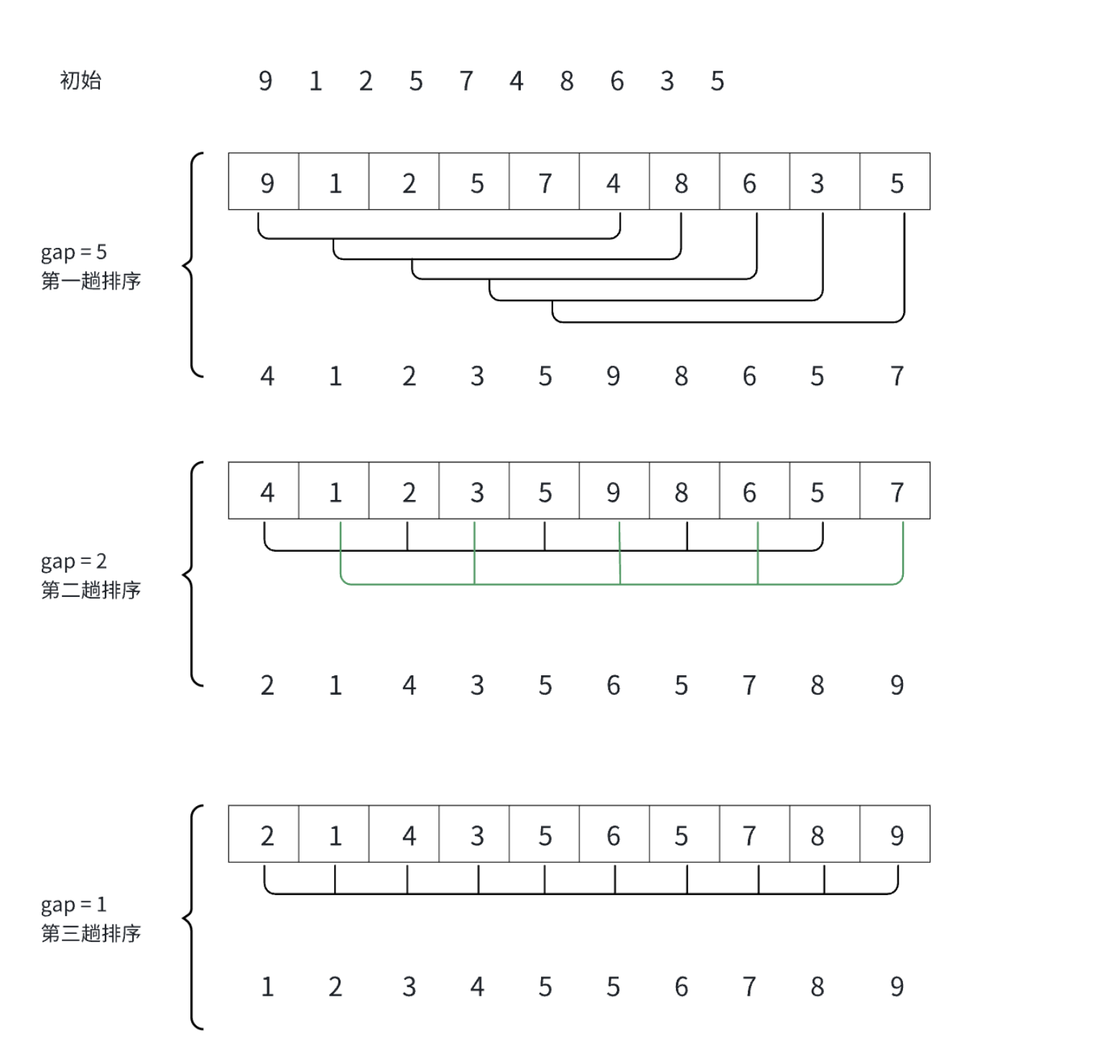
希尔排序法又称缩小增量法。希尔排序法的基本思想是:先选定一个整数(通常是gap=n/3+1),把待排序文件所有记录分成各组,所有距离相等的记录分在同一组内,并对每一组内的记录进行排序,然后gap=gap/3+1得到下一个整数,再将数组分成各组,进行插入排序,当gap=1时,就相当于直接插入排序。
它是在直接插⼊排序算法的基础上进行改进而来的,综合来说它的效率肯定是要高于直接插⼊排序算法的。
假设有一个数组arr = [9, 8, 3, 7, 5, 6, 4, 1],我们采用最简单的增量序列(每次减半)来进行希尔排序:
1. 初始增量d = 4,将数组分为4组,每组进行插入排序:[9, 7], [8, 5], [3, 6], [4, 1]
2. 增量d = 2,将数组分为2组,每组进行插入排序:[7, 5, 6, 1], [9, 8, 3, 4]
3. 增量d = 1,整个数组作为一组进行插入排序,得到最终结果:[1, 3, 4, 5, 6, 7, 8, 9]
接下来,我们通过下图进行解释希尔排序的思想:
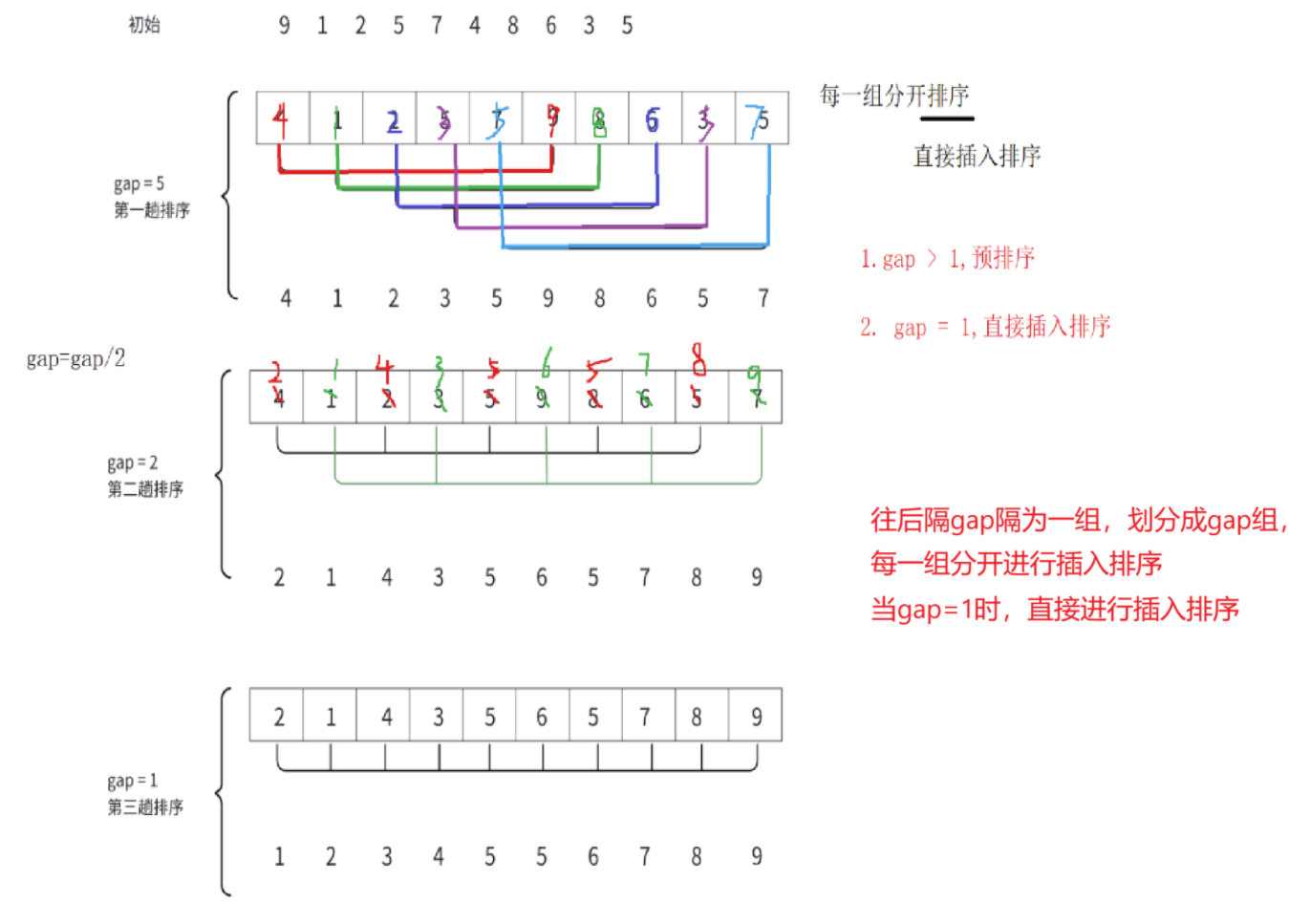
2.2.1 代码实现:
void ShellSort(int* arr, int n)
{int gap = n;while (gap > 1){gap = gap / 3 + 1;//一共分成了gap组for (int i = 0; i < gap; i++){//对一组进行插入排序for (int i = 0; i < n - gap; i += gap){int end = i;int tmp = arr[end + gap];while (end >= 0){if (arr[end] > tmp){arr[end + gap] = arr[end];end -= gap;}else{break;}}arr[end + gap] = tmp;}}}
}在上面的代码中,我们看到有4个循环,那可不可以降低循环的个数呢?这是可以的
改进代码:
void ShellSort(int* arr, int n)
{int gap = n;while (gap > 1){gap = gap / 3 + 1;//一共分成了gap组for (int i = 0; i < n - gap; i ++){int end = i;int tmp = arr[end + gap];while (end >= 0){if (arr[end] > tmp){arr[end + gap] = arr[end];end -= gap;}else{break;}}arr[end + gap] = tmp;}}
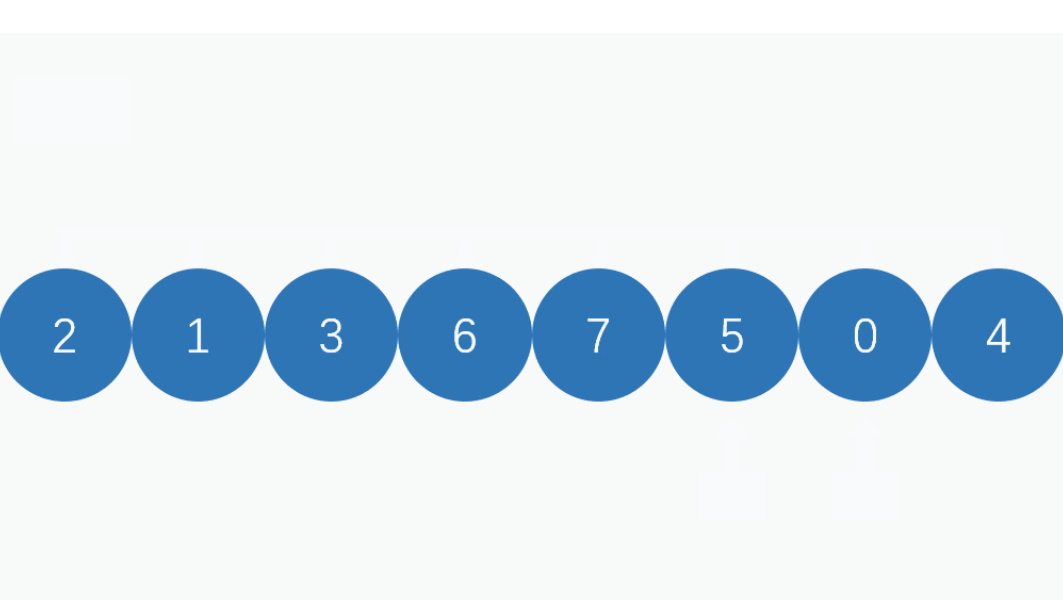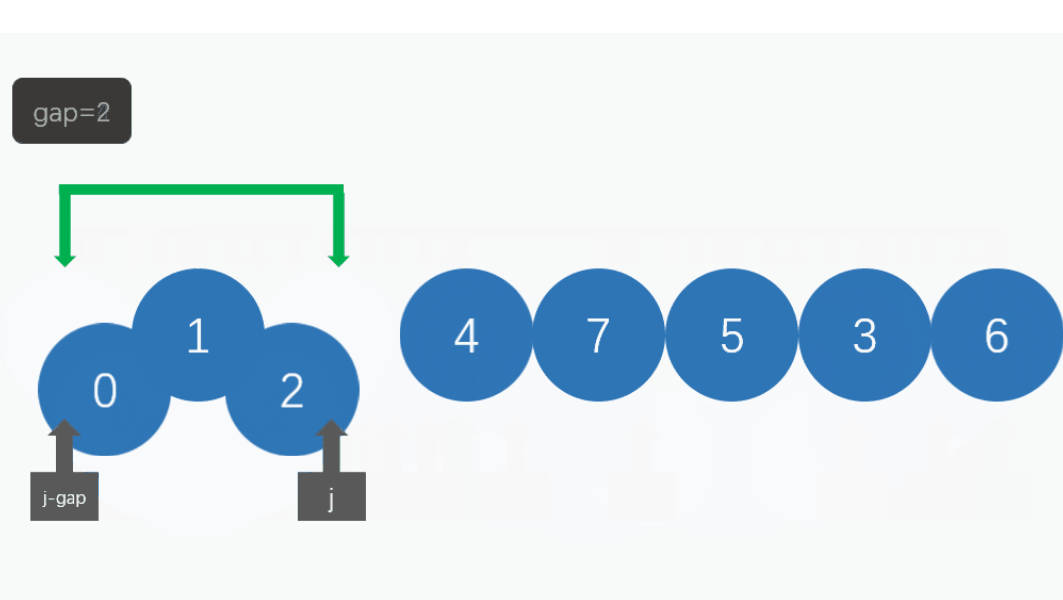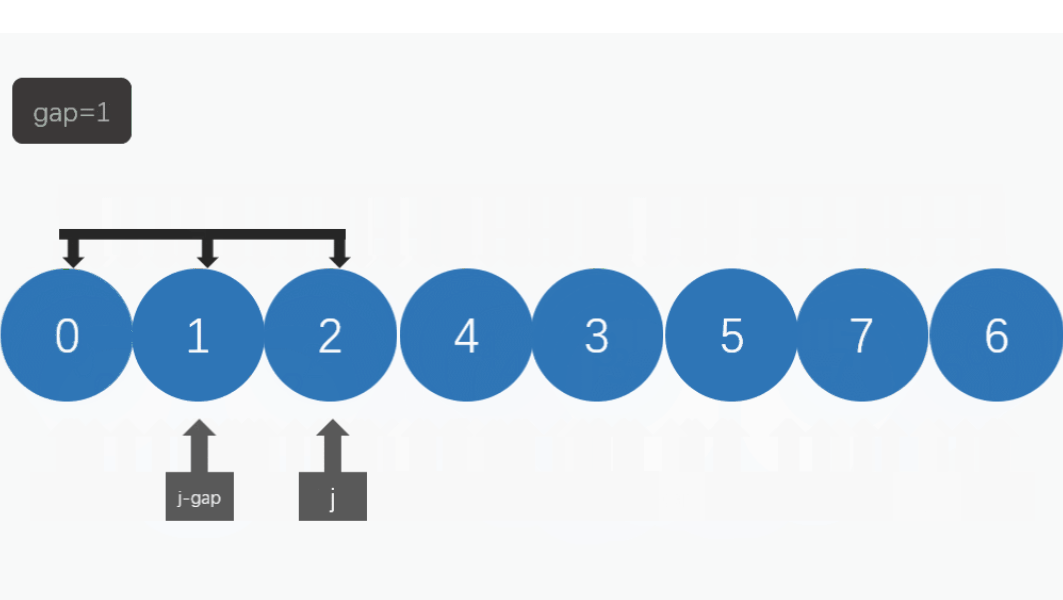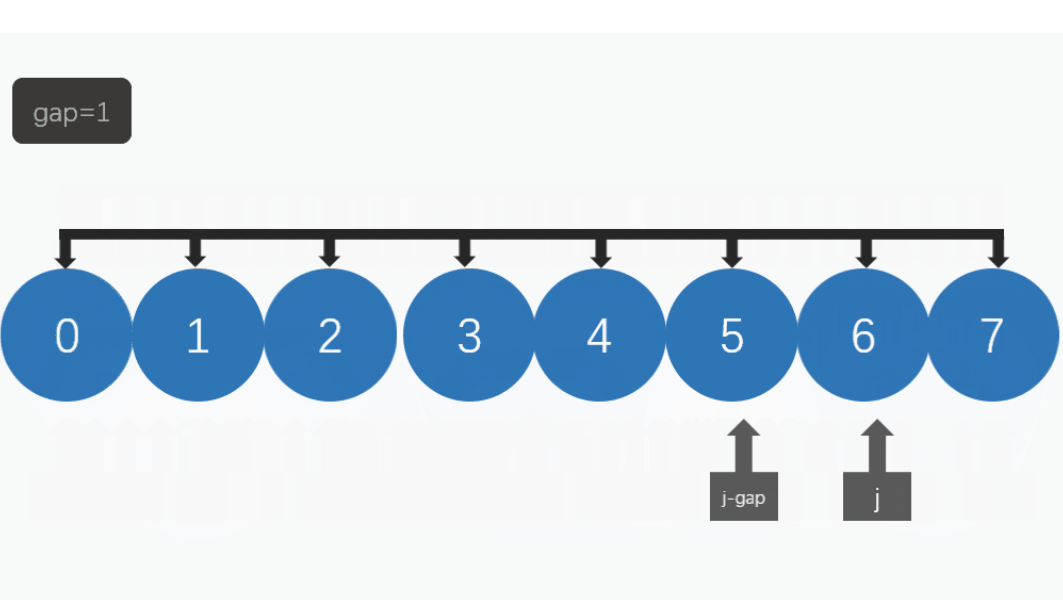
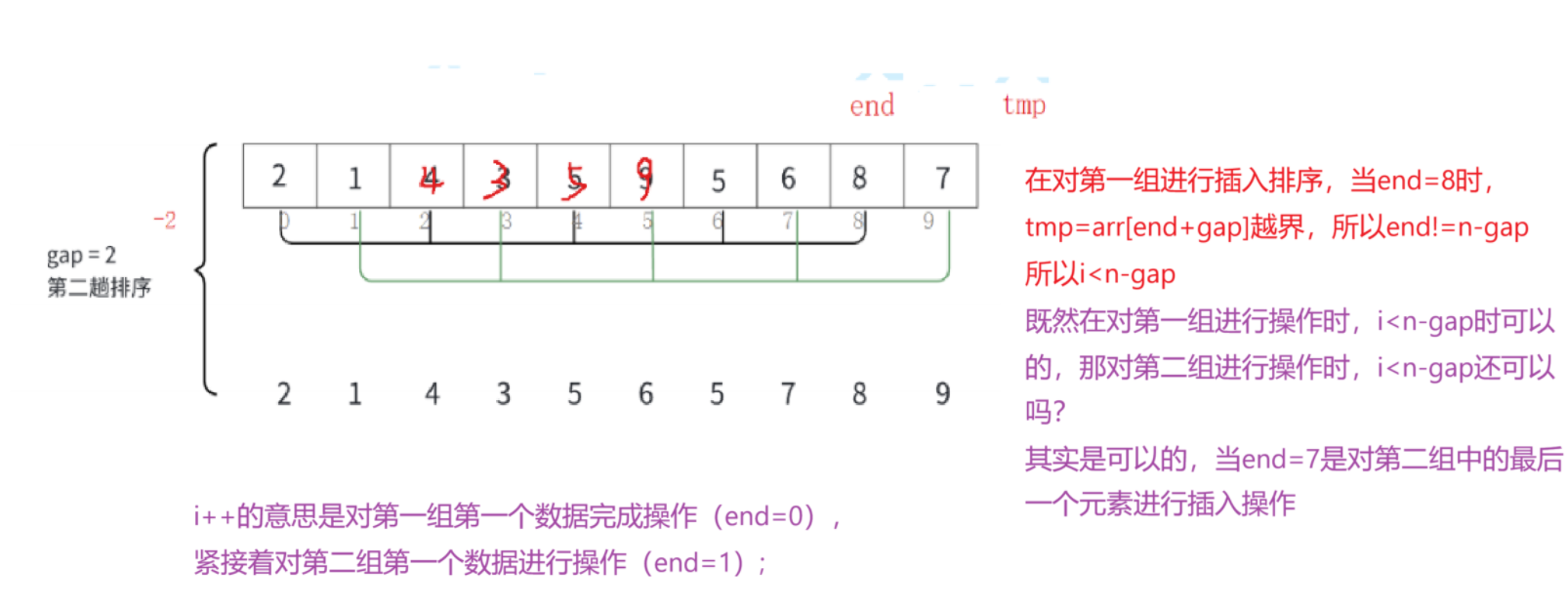
}我相信肯定会有很多小伙伴看到上面的代码会一脸懵,为什么gap = gap / 3 + 1;?为什么for (int i = 0; i < n - gap; i++)中的i<n-gap,i++?
问题1:为什么gap = gap / 3 + 1

问题2:为什么for (int i = 0; i < n - gap; i++)中的i<n-gap,i++?
2.2,2 希尔排序的时间复杂度计算
接下来我们来思考一下:希尔排序的时间复杂度是多少?
希尔循环有循环的嵌套,我们分外层循环和内层循环来展开分析一下——
外层循环:
外层循环的时间复杂度可以直接看出来:O(logn)(2为底)或者O((logn)(3为底),即O(logn)。
内层循环:
我们假设n = 9,若gap为3,则一共是gap组,每组有(n/gap)个数据。



通过我们上述的分析,可以画出这样的一个曲线图:
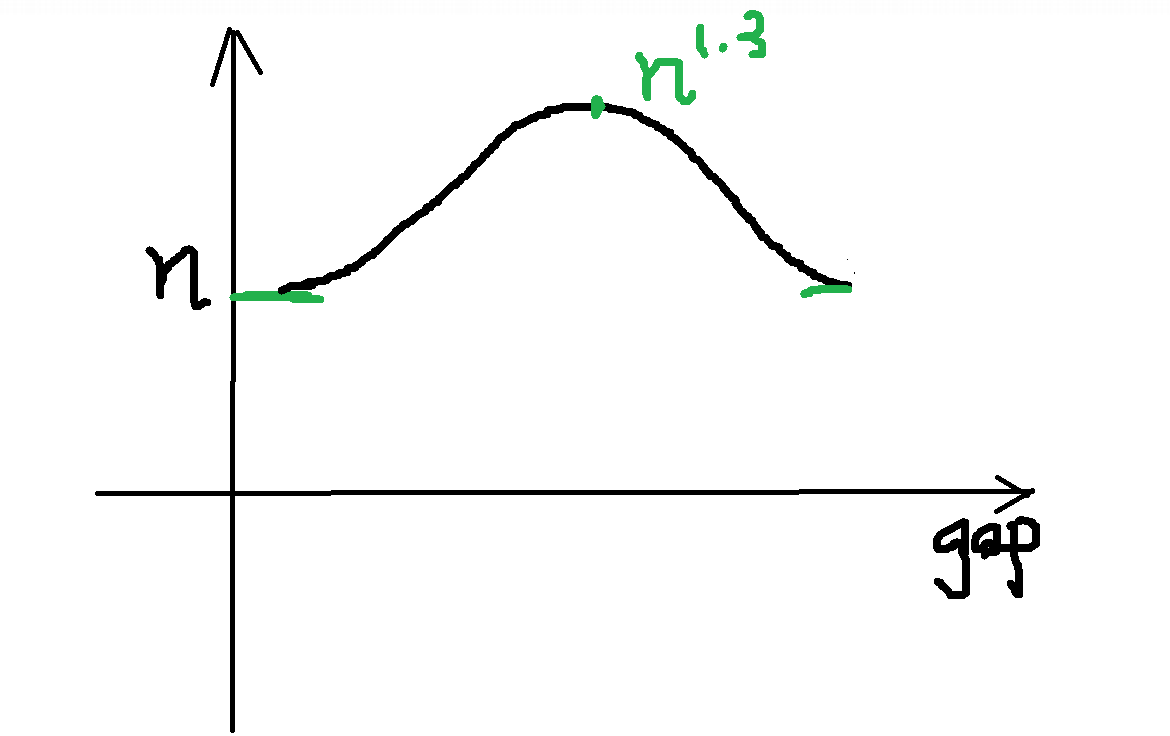
希尔排序时间复杂度不好计算,因为 gap 的取值非常多,导致我们很难去计算时间复杂度,因此很多书中给出的希尔排序的时间复杂度都不固定。
这里我们参考严蔚敏老师在他的《数据结构(C语言版)》一书中给出的时间复杂度:O(n^1.3)。

2.2.3 希尔排序的特性
1、希尔排序是对直接插入排序的优化;
2、当gap > 1时都是预排序,目的是让数组更接近于有序。当gap == 1时,数组已经接近有序的 了,这样就会很快。这样整体而言,可以达到优化的效果。我们实现后可以进行性能测试的对比;
3、希尔排序的时间复杂度不好计算,需要进行推导,推导出来平均时间复杂度: O(N^1.3— N^2);
4、稳定性:不稳定。
三、选择排序
3.1 直接选择排序
3.1.1 直接选择排序的思想
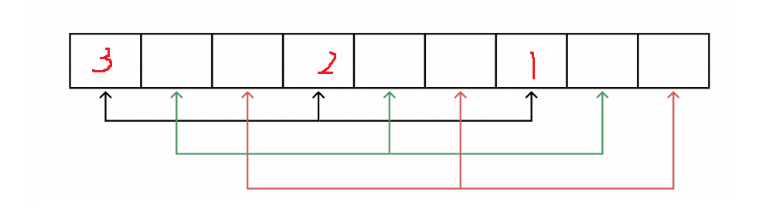
每次从待排序的数据中选择一个最小(最大)的元素放在序列起始位置,直到整个序列元素排序完毕
3.1.2 代码实现
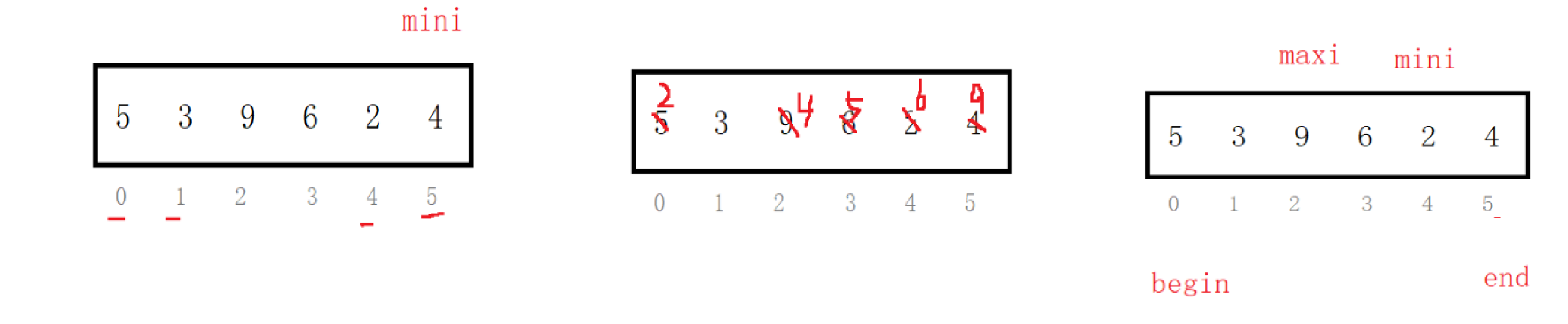
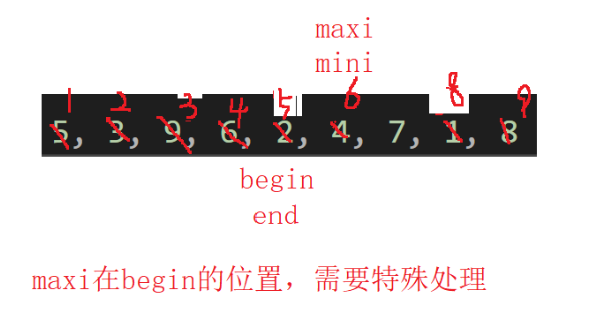
如果maxi==begin时,我们就要特殊处理一下:
代码1(只找最大值/最小值):
void swap(int* x, int* y)
{int tmp = *x;*x = *y;*y = tmp;
}
void SlectSort(int* arr, int n)
{//只找最小值for (int i = 0; i < n; i++){int mini = i;for (int j = i+1; j < n; j++){if (arr[j] < arr[mini]){mini = j;}}//跳出循环说明找到最小值swap(&arr[mini], &arr[i]);}
}那我们可不可以既找最小值,又找最大值呢?当然可以了
代码2(既找最小值,又找最大值):
void swap(int* x, int* y)
{int tmp = *x;*x = *y;*y = tmp;
}
void SlectSort(int* arr, int n)
{int begin = 0, end = n - 1;while (begin < end){int mini = begin;int maxi = begin;for (int i = begin+1; i <=end; i++){if (arr[i] > arr[maxi]) {maxi = i;}if (arr[i] < arr[mini]){mini = i;}}//当begin==maxi时 需要特殊处理if (begin == maxi){maxi = mini;}//跳出循环,说明找到最小值和最大值,交换swap(&arr[maxi], &arr[end]);swap(&arr[mini], &arr[begin]);begin++;end--;}
}3.1.3 直接选择排序的特性
直接选择排序的特性总结:
1、直接选择排序思考虽然非常好理解,但是因为效率不是很好。实际中我们很少去使用;
2、时间复杂度:O(N ^ 2);
3、空间复杂度:O(1)。
4、稳定性:不稳定
3.2 堆排序

堆排序用的是堆的思想,要学习堆排序,首先要学习堆的向下调整算法,因为要用堆排序,你首先得建堆,而建堆需要执行多次堆的向下调整算法。
3.2.1 向下调整
堆的向下调整算法(使用前提):
若想将其调整为小堆,那么根结点的左右子树必须都为小堆。
若想将其调整为大堆,那么根结点的左右子树必须都为大堆。
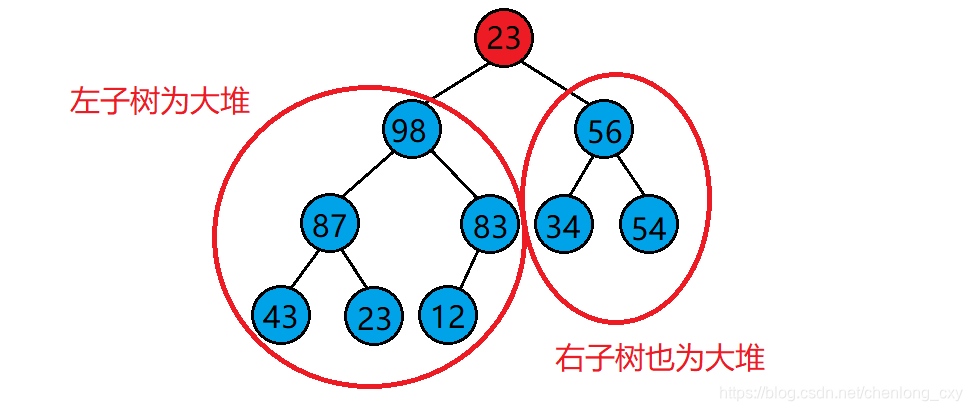
向下调整算法的基本思想(以建大堆为例):
1.从根结点处开始,选出左右孩子中值较大的孩子。
2.让大的孩子与其父亲进行比较。
若大的孩子比父亲还大,则该孩子与其父亲的位置进行交换。并将原来大的孩子的位置当成父亲继续向下进行调整,直到调整到叶子结点为止。
若大的孩子比父亲小,则不需处理了,调整完成,整个树已经是大堆了。
图片示例:
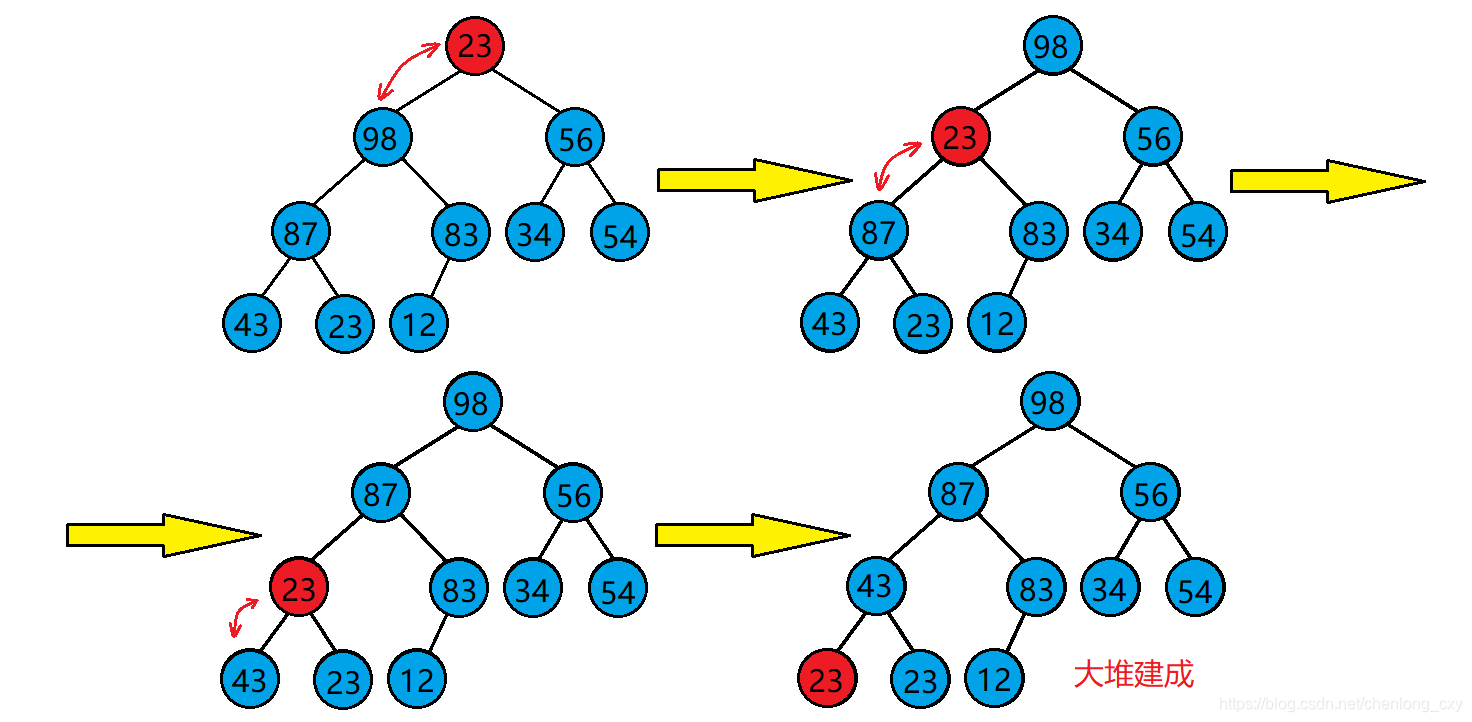
向下调整算法代码
void AdjustDown(int* arr, int parent, int n)
{int child = parent * 2 + 1;while (child < n){//比较左右孩子,得到较大的一个if (child+1<n && arr[child] < arr[child + 1]){child++;}//较大的孩子和父节点比较,大就交换,否则不交换if (arr[child] > arr[parent]){swap(&arr[child], &arr[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}使用堆的向下调整算法需要满足其根结点的左右子树均为大堆或是小堆才行,那么如何才能将一个任意树调整为堆呢?
答案很简单,我们只需要从最小的一棵子树开始调整,从后往前,按下标,依次作为根去向下调整即可。
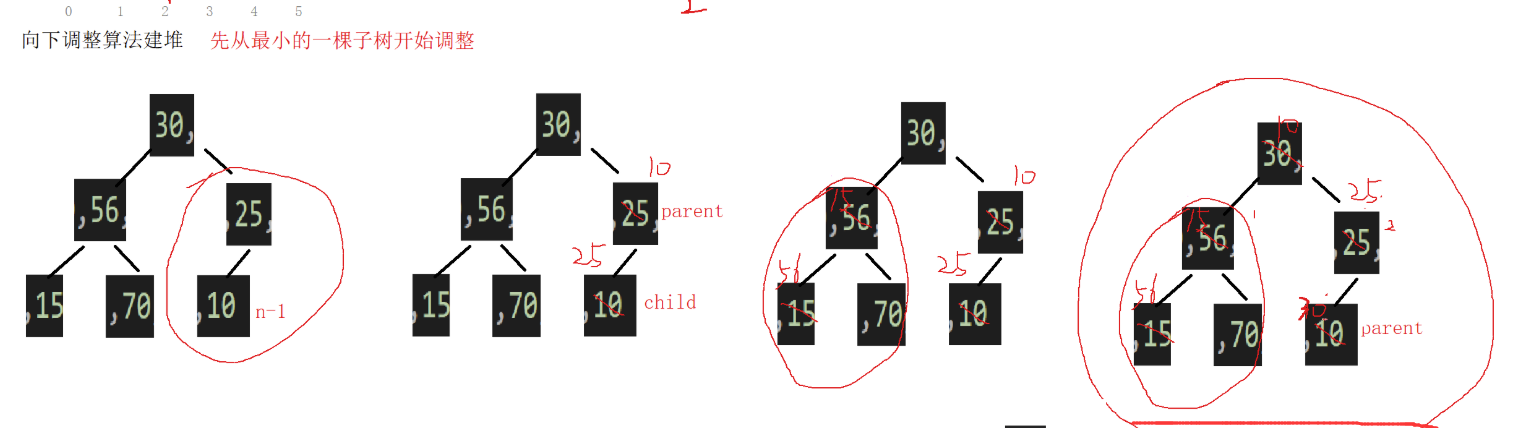
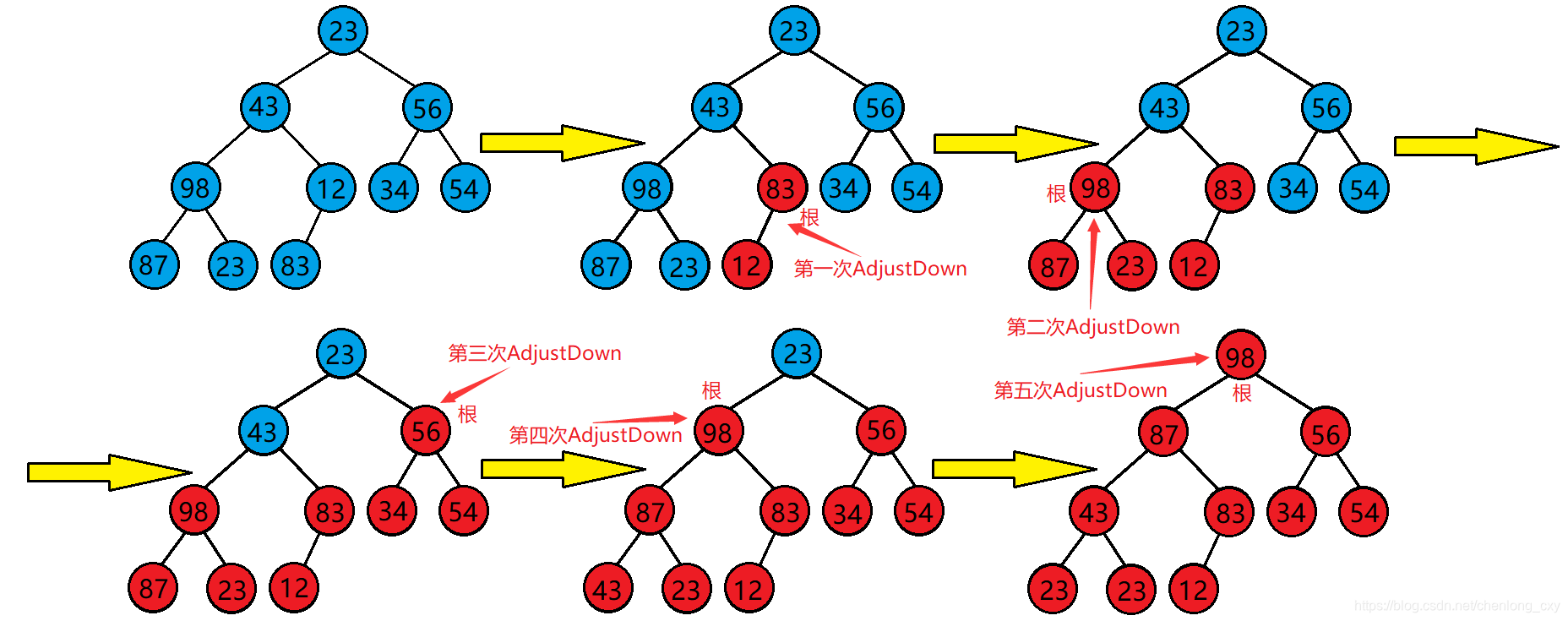
向下调整建堆的代码(大堆)
void AdjustDown(int* arr, int parent, int n)
{int child = parent * 2 + 1;while (child < n){//比较左右孩子,得到较大的一个if (child+1<n && arr[child] < arr[child + 1]){child++;}//较大的孩子和父节点比较,大就交换,否则不交换if (arr[child] > arr[parent]){swap(&arr[child], &arr[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}
for (int i = (n - 1 - 1)/2; i >= 0; i--)
{AdjustDown(arr, i, n);
}向下调整建堆的时间复杂度为O(n)
既然我们通过了向下调整建堆的方法,将数组建成了一个堆的形式,那我们该如何对堆中的数据进行排序呢?
步骤如下:
1、将堆顶数据和堆尾数据互换,堆尾数据出堆,然后对堆顶进行一次堆的向下调整(使其还是一个大堆),调整时被交换到最后的那个最大的数不参与向下调整(已经出堆)。
2、完成步骤1后,这棵树除最后一个数之外,其余数又成一个大堆,然后又将堆顶数据与堆的最后一个数据交换,这样一来,第二大的数就被放到了倒数第二个位置上,然后该数又不参与堆的向下调整…反复执行下去,直到堆中只有一个数据时便结束。此时该序列就是一个升序。

3.2.2 堆排序的代码(使用向下调整建大堆)
//升序--建大堆
//使用向下调整算法
void AdjustDown(int* arr, int parent, int n)
{int child = parent * 2 + 1;while (child < n){//比较左右孩子,得到较大的一个if (child+1<n && arr[child] < arr[child + 1]){child++;}//较大的孩子和父节点比较,大就交换,否则不交换if (arr[child] > arr[parent]){swap(&arr[child], &arr[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}
void HeapSort(int* arr, int n)
{for (int i = (n - 1 - 1)/2; i >= 0; i--){AdjustDown(arr, i, n);}int end = n - 1;while (end > 0)//当end=0时,数据已经有序{swap(&arr[0], &arr[end]);end--;AdjustDown(arr, 0, end + 1);}
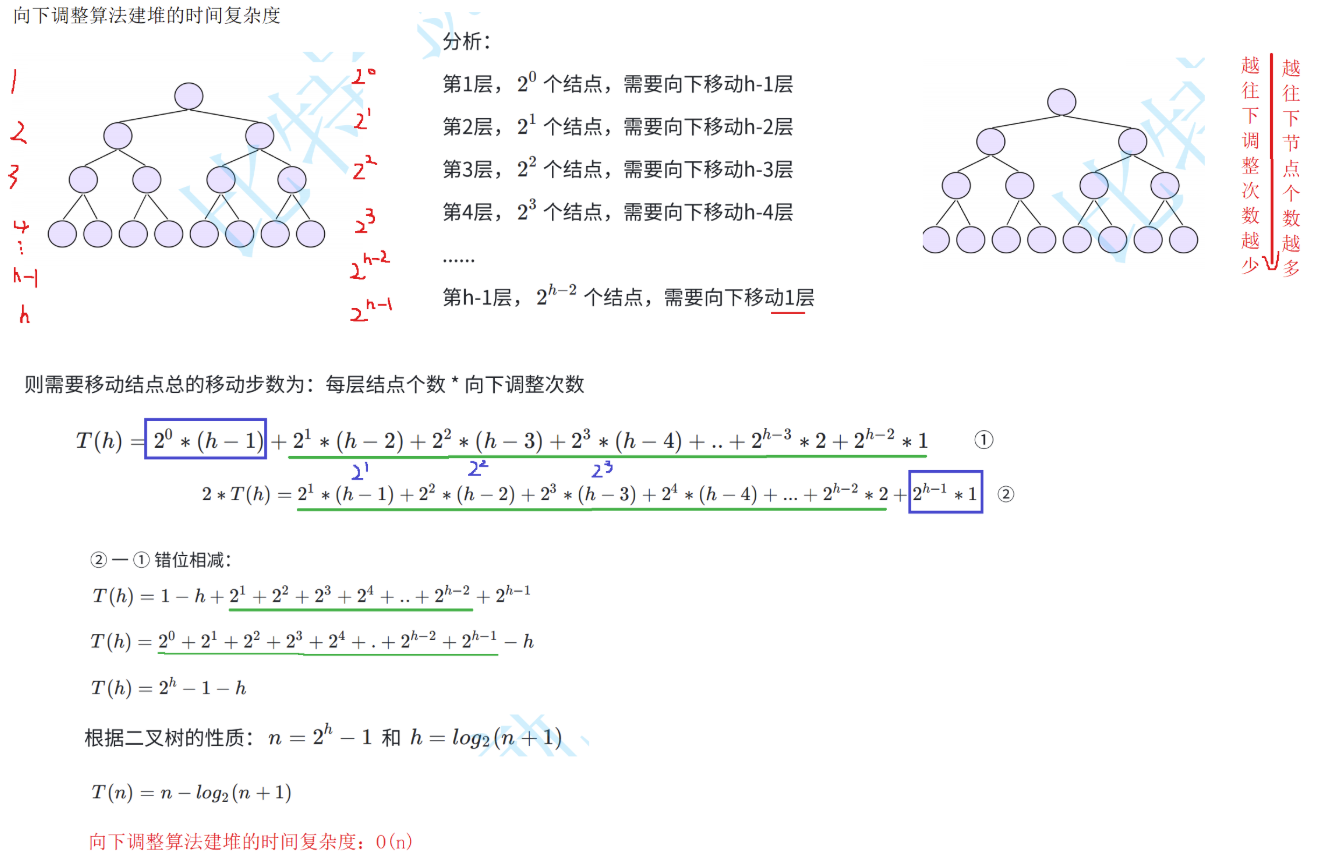
}3.2.3 堆排序时间复杂度计算
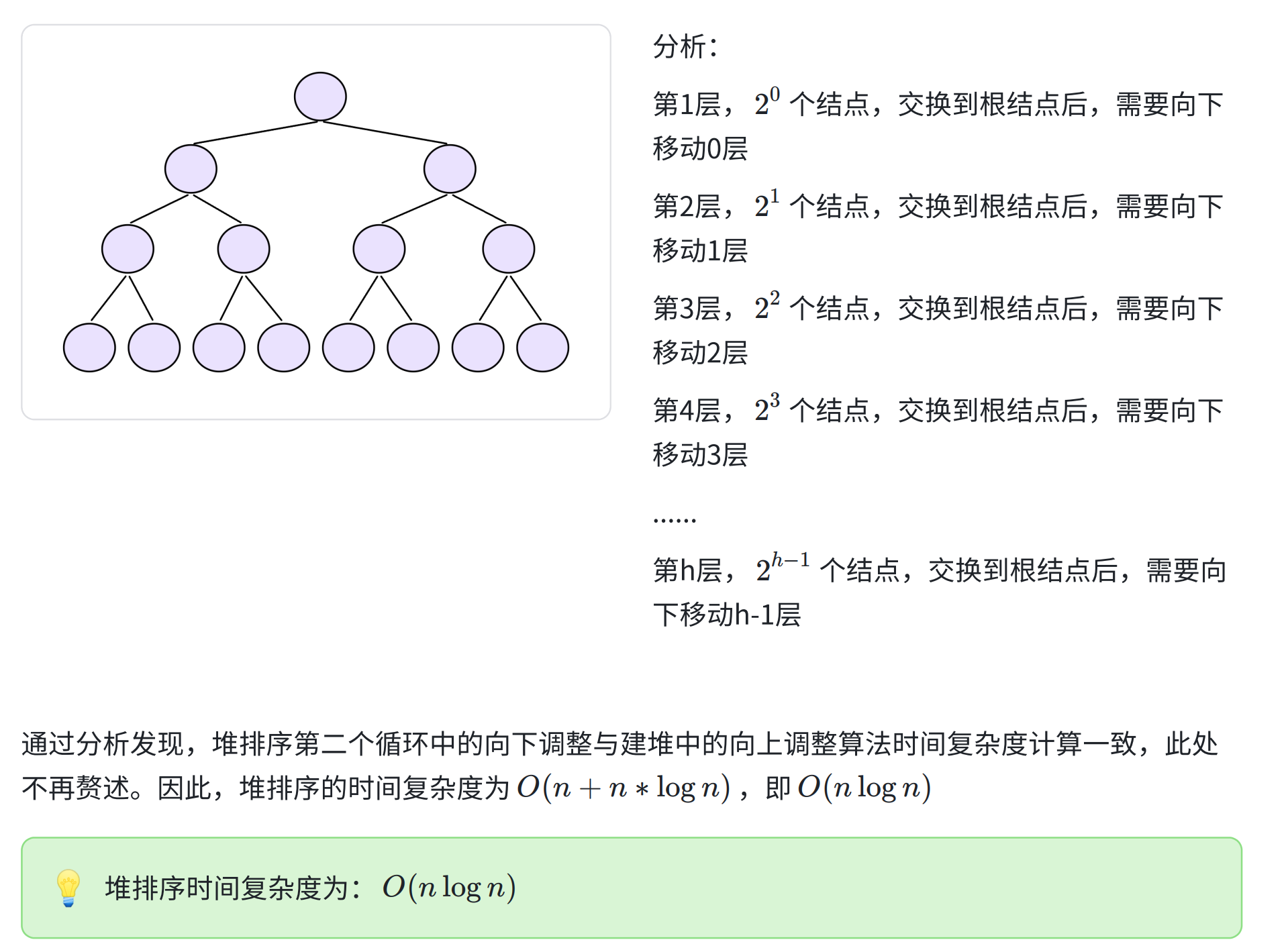
3.2.4 堆排序的特性
1、堆排序使用堆来选数,效率就高了很多;
2、时间复杂度:O(N*logN);
3、空间复杂度:O(1) ;
4、稳定性:不稳定