计算机网络:(十五)TCP拥塞控制与TCP拥塞控制算法
计算机网络:(十五)传输层(下)TCP拥塞控制与TCP拥塞控制算法
- 前言
- 一、什么是拥塞控制?
- 1. 先理解"网络拥塞"
- 2. 拥塞控制的核心目标
- 3. 拥塞控制的关键原则(为什么难?)
- 二、为什么会发生拥塞?
- 三、拥塞控制≠加资源
- 四、分清两个易混概念:拥塞控制vs流量控制
- 五、控制思路:开环vs闭环(TCP选哪种?)
- 六、TCP的核心工具:拥塞窗口(cwnd)
- 1. 什么是拥塞窗口?
- 2. 实际发送窗口怎么算?
- 七、怎么判断网络是否拥塞?TCP的两个"信号"
- 八、TCP如何调拥塞窗口?
- 九、TCP 拥塞控制算法
- 1. 慢开始
- 1.1 核心目的
- 1.2 关键工具
- 1.3 怎么“慢开始”?
- 1.4 为什么叫“慢”开始?
- 2. 拥塞避免
- 1. 核心目的
- 2. 增长规则
- 3. 与慢开始的区别
- 3. 快重传
- 3.1 怎么发现丢包?
- 3.2 核心操作:立即重传
- 3.3 为什么高效?
- 4. 快恢复
- 4.1 为什么不用“超时处理”?
- 4.2 核心操作
- 4.3 效果
前言
- 在前序博客中,我们讲解了TCP 的核心知识点,具体包括:TCP 报文段的首部格式、TCP 可靠传输的实现机制,以及 TCP 的流量控制方法。
- 接下来,我们继续详细TCP拥塞控制与TCP拥塞控制算法。
我的个人主页,欢迎来阅读我的其他文章
https://blog.csdn.net/2402_83322742?spm=1011.2415.3001.5343
我的计算机网络专栏,欢迎来阅读
https://blog.csdn.net/2402_83322742/category_12909527.html
一、什么是拥塞控制?
1. 先理解"网络拥塞"
想象公路堵车:车太多,超过道路承载能力,导致排队、慢走甚至瘫痪——这就是"拥塞"。
网络中同理:当发送的数据包数量超过路由器、链路等设备的承载上限,就会出现数据包排队延迟、丢失,甚至整个网络传输效率暴跌——这就是"网络拥塞"。
2. 拥塞控制的核心目标
简单说,拥塞控制就是让网络"不堵车":
- 在网络空闲时,充分利用资源(别浪费带宽);
- 在网络快拥塞时,及时减少数据发送(别让堵死);
- 在拥塞后,快速恢复传输效率(别一直卡着)。
3. 拥塞控制的关键原则(为什么难?)
- 网络有上限:就像公路有最大车流量,网络设备(路由器、链路)的处理能力、缓存大小是固定的,超过上限必拥塞。
- 动态性:拥塞是"时变的"(比如晚高峰大家刷视频时容易堵,凌晨则空闲),控制策略必须能适应变化。
- 信号与因果:数据包丢失是"拥塞的结果"(就像堵车时车抛锚),而非原因(原因是数据太多),控制时需正确解读信号。
- 风险点:策略设计不当会加剧拥塞(比如盲目让所有设备减速,反而导致数据堆积)。
二、为什么会发生拥塞?
拥塞不是偶然的,核心是"总需求 > 总资源",具体有4个诱因:
-
节点缓存不足
路由器的缓存像"临时停车场",如果缓存太小,来了太多数据包(车),装不下的就会被丢弃,引发拥塞。 -
链路容量不够
网线、光纤等"链路"像"道路车道数",单车道(低带宽)却要过大量数据(车),必然排队。 -
处理机速度太慢
路由器的处理机像"收费站工作人员",如果处理数据包的速度跟不上接收速度,数据就会堵在入口,越积越多。 -
拥塞自加剧(恶性循环)
拥塞→数据包丢失→触发重传→重传增加数据量→更拥塞(类似堵车时司机加塞,导致更堵)。
三、拥塞控制≠加资源
很多人觉得"网络堵了就加设备",但实际可能更糟:
- 只加大路由器缓存(扩停车场),但链路带宽没提(出口还是单车道):数据会堆在缓存里超时重传,反而增加数据量。
- 只提升处理机速度(收费站变快),但链路还是窄(前面路没变宽):拥堵点会转移,问题没解决。
结论:拥塞是"资源分配与需求匹配"的问题,需动态调控,而非单纯加硬件。
四、分清两个易混概念:拥塞控制vs流量控制
| 对比项 | 拥塞控制 | 流量控制 |
|---|---|---|
| 目标 | 防止"整个网络"过载(别让路由器、链路堵死) | 防止"接收方"来不及处理(别让对方缓存满了) |
| 范围 | 全局(涉及所有网络设备) | 点对点(只关心发送方和接收方) |
| 类比 | 交通管制:调控全城车流量,避免主干道瘫痪 | 快递送货:按收件人家里空间大小控制每次送货量 |
五、控制思路:开环vs闭环(TCP选哪种?)
治理拥塞有两种思路,TCP选了更灵活的那种:
| 开环控制(“一次设计定终身”) | 闭环控制(“实时监控调策略”) |
|---|---|
| 设计时就确保"绝对不拥塞"(比如把链路、缓存做得超大),运行中不调整。 | 实时监控网络状态(是否丢包、延迟高),动态调整数据发送量(堵了就少发,闲了就多发)。 |
| 缺点:死板,无法适应网络变化(比如几年后数据量增长,原设计不够用了)。 | 优点:灵活,能应对动态场景(TCP拥塞控制用的就是这种)。 |
六、TCP的核心工具:拥塞窗口(cwnd)
TCP通过"窗口大小"控制一次发送多少数据,核心是拥塞窗口(cwnd)——发送方自己算出来的"当前网络能扛住的最大数据包数量"。
1. 什么是拥塞窗口?
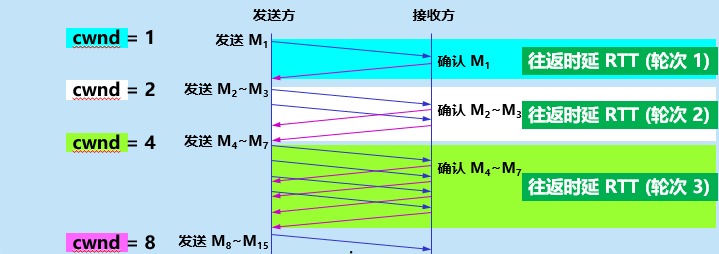
比如cwnd=8,代表"现在一次最多发8个包,网络能承受"。这个数值会随网络状态动态变化(拥塞时减小,空闲时增大)。
2. 实际发送窗口怎么算?
发送方不能只看网络,还要看接收方能不能接(比如对方缓存满了)。所以:
实际发送窗口 = min(接收方窗口(对方能接多少), 拥塞窗口(网络能扛多少))
例:接收方能接10个,但网络只能扛8个→发8个;接收方只能接5个,哪怕网络能扛8个→发5个。
七、怎么判断网络是否拥塞?TCP的两个"信号"
就像交警看"车排队长度"判断堵车,TCP靠两个信号判断网络状态:
-
超时重传计时器超时
发送一个包后,会启动计时器。如果超时没收到接收方的"确认消息",默认"包丢了"——大概率是网络已经拥塞(包太多被挤丢),需紧急减窗口。 -
收到3个重复确认
接收方收到包后会回复"确认"(比如"我收到第5个包了")。如果发送方连续收到3次同样的确认(比如3次"收到第5个"),说明"第6个包可能丢了"——这是"快拥塞"信号(网络有点挤,但没堵死),需提前减窗口。
八、TCP如何调拥塞窗口?
基于上面的信号,TCP用4个策略动态调整cwnd,实现拥塞控制:
-
慢开始:刚连接时,不知道网络能扛多少,从极小窗口(比如1个包)开始,每次收到确认就翻倍(1→2→4→8…),快速试探网络上限。
-
拥塞避免:当窗口大到一定程度(达到"慢开始门限"),不再翻倍,而是每次确认只加1(缓慢增长),避免突然拥塞。
-
快重传:收到3个重复确认时,不等超时就立即重传丢失的包,减少等待时间。
-
快恢复:重传后,不从头"慢开始",而是直接把窗口调到"门限"附近,快速恢复传输效率。
九、TCP 拥塞控制算法
1. 慢开始
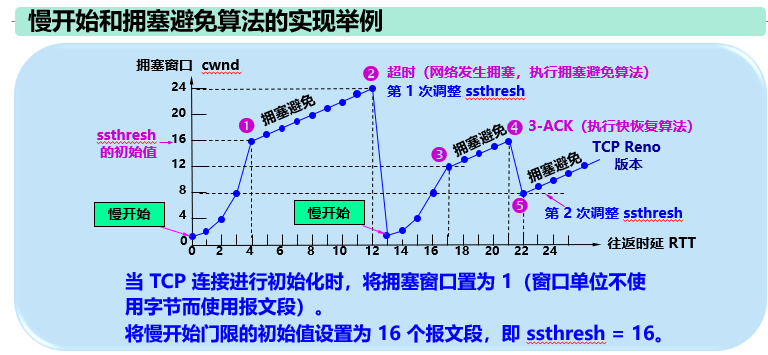
核心场景:当两台设备刚建立连接(比如你刚打开网页),TCP完全不知道当前网络能“扛住多少数据”
1.1 核心目的
从最小量开始,逐步增加发送的数据量,试探网络的“承载上限”,避免一上来发太多直接把路堵死。
1.2 关键工具
- 拥塞窗口(cwnd):TCP一次能发送的最大数据包数量(类似快递员一次能拉的快递数量)。
- 慢开始门限(ssthresh):一条“安全警戒线”(比如16个包),超过这个线就不能再“快速加量”了。
1.3 怎么“慢开始”?
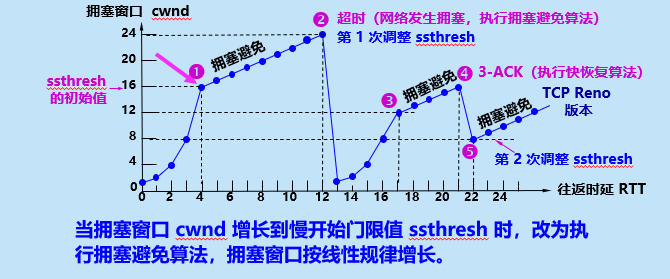
- 初始值:cwnd从很小开始(比如1个包,相当于快递员第一次只送1个快递)。
- 增长规则:每收到一次“对方已收到快递”的确认,就把cwnd翻倍(指数增长)。
- 例子:第一次送1个→收到确认→下次送2个→收到确认→下次送4个→8个→16个…
- 停止条件:当cwnd涨到接近ssthresh(比如达到16),就切换到“拥塞避免”模式。
1.4 为什么叫“慢”开始?
虽然cwnd是指数增长(看起来快),但起点极低(从1开始),本质是“小心翼翼试探”,所以叫“慢开始”。
2. 拥塞避免
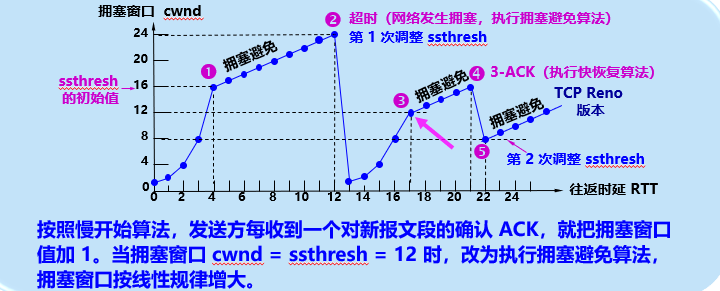
核心场景:经过慢开始后,cwnd已经接近网络的承载上限(达到ssthresh),这时候不能再“猛加量”了,得稳步增长,降低堵车风险。
1. 核心目的
让数据发送量“缓慢增长”,在不引发拥塞的前提下,尽量利用网络容量(类似快递员知道路快满了,每次只多送1个,不贪心)。
2. 增长规则
不再翻倍,而是“线性增长”:每完成一个往返时间(RTT,快递从发出到收到确认的时间),cwnd只加1。
- 例子:cwnd=16→17→18→…(每次多送1个,稳步增加)。
3. 与慢开始的区别
| 阶段 | 增长方式 | 适用场景 | 类比(快递) |
|---|---|---|---|
| 慢开始 | 指数增长 | 初始试探,远离上限时 | 刚开始不知道路宽,慢慢加量,从1→2→4… |
| 拥塞避免 | 线性增长 | 接近上限,风险较高时 | 知道路快满了,每次只多送1个,稳着来 |
3. 快重传
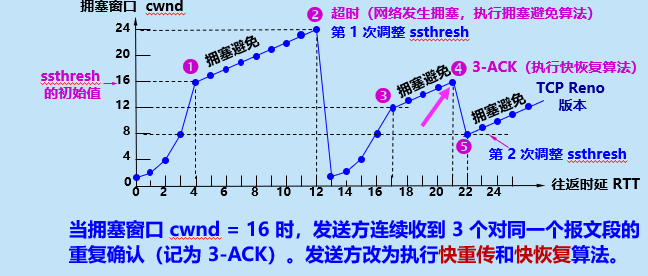
核心场景:网络没完全堵死,但个别数据包丢了(比如快递在路上掉了一个)。如果等超时再处理,效率太低,所以需要“快速发现并重传”。
3.1 怎么发现丢包?
靠“重复确认”:假设发送方发了1、2、3、4号包,接收方收到1,回复确认;收到2,回复确认;但没收到3,却收到了4。这时候接收方会连续回复“我要3号包”(重复确认3号)。
当发送方收到3个连续的重复确认,就知道“3号包丢了”(不用等超时)。
3.2 核心操作:立即重传
一旦确认丢包,不等重传计时器超时,马上重传丢失的包(比如立刻补发3号包)。
3.3 为什么高效?
超时通常要等几百毫秒甚至几秒,而快重传靠重复确认,几毫秒就能发现丢包,大大减少等待时间。
4. 快恢复
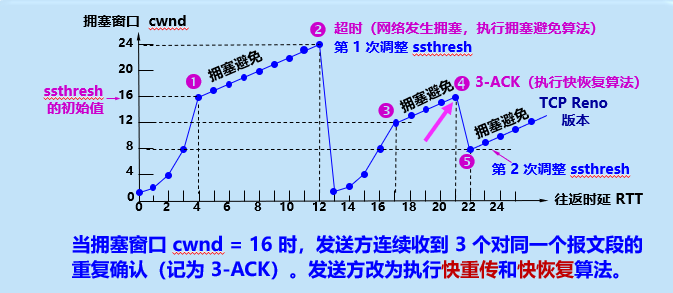
核心场景:快重传已经发现了个别丢包(不是网络全堵死,只是掉了一个包),这时候如果像“超时”那样把cwnd重置为1,太浪费效率,所以需要“快速恢复”。
4.1 为什么不用“超时处理”?
超时意味着“网络可能全堵死了”(比如路上全是车,根本动不了),这时候需要把cwnd重置为1,从头试探;但快重传发现的是“个别丢包”(路没堵死,只是掉了个包),不需要这么激进。
4.2 核心操作
- 第一步:把ssthresh降到当前cwnd的一半(比如当前cwnd=24,ssthresh就设为12,收紧安全线)。
- 第二步:把cwnd设为新的ssthresh(比如12,而不是重置为1),然后进入“拥塞避免”阶段,继续线性增长(12→13→14…)。
4.3 效果
避免了“从1开始慢开始”的低效,快速回到正常的发送节奏,兼顾了拥塞控制和效率。
以上就是本篇博客的全部内容,下一篇我们继续探讨计算机网络里面的知识。
我的个人主页,欢迎来阅读我的其他文章
https://blog.csdn.net/2402_83322742?spm=1011.2415.3001.5343
我的计算机网络专栏,欢迎来阅读
https://blog.csdn.net/2402_83322742/category_12909527.html
| 如果您觉得内容对您有帮助,欢迎点赞收藏,您的支持是我创作的最大动力! |
