一文打通 AI 知识脉络:大语言模型等关键内容详解
一、大语言模型(LLM)
1.什么是大语言模型?
大语言模型(Large Language Model,简称 LLM)是一种基于深度学习技术的人工智能系统,核心能力是理解、生成和处理人类语言。它通过海量文本数据的训练,学习人类语言的规律、逻辑和知识,从而能完成与语言相关的复杂任务。
2.大语言模型有啥特点?
规模庞大: 体现在两个方面:一是参数数量(模型内部用于存储语言规律的 “变量”)通常达到数十亿甚至数万亿,规模远超传统语言模型;二是训练数据海量,涵盖书籍、网页、论文、对话等多种文本类型,覆盖人类知识的多个领域。
基于 Transformer 架构: 这是一种能高效处理长文本序列的神经网络结构,通过 “注意力机制” 聚焦文本中关键信息(比如理解一句话时,重点关注上下文相关的词汇),让模型能捕捉语言中的长距离依赖关系(比如段落中前后文的逻辑关联)。
通过 “预测下一个词” 学习: 训练的核心目标是让模型根据已有文本(上下文),预测下一个最可能出现的词。通过反复优化这个能力,模型逐渐掌握语言的语法、语义、逻辑甚至常识。
3.大语言模型的训练步骤?
大模型训练主要分为三个阶段:预训练、SFT(监督微调)、RLHF(基于人类反馈的强化学习)。
无监督学习、监督学习、强化学习都可以参考本篇文章第二部分内容。
(1)预训练:
预训练是构建通用语言能力和知识基础的核心阶段,核心是让模型从海量文本中学习语言规律、常识和世界知识,却没有学会怎么样去领会人类的意图。假设我们向预训练的模型提问:“自由女神像在哪个国家?” 模型有可能不会回答 “美国”,而是根据它看到过的语料进行输出:“鸟巢在哪个城市?”。
简单来说,预训练是通过「无监督学习」,模式在大数据中自主学习。
(2)SFT(监督微调)
大模型预训练后的状态比作 “中学生”(掌握通用知识),SFT 阶段则像 “成长为大学生”—— 开始学习专业领域知识(如金融、法律)或人类对话逻辑。这时候我们再提问:“自由女神像在哪个国家?” 模型的回答大概率就是 “美国”。模型已经可以完成基本的人类对话了。
SFT 能让模型完成任务,但无法保证输出符合人类价值观—— 比如模型可能输出涉黄、涉政、暴力或歧视言论(因为预训练数据或 SFT 数据里可能隐含不良内容,或模型没学会 “偏好判断”),这就要用到RLHF(基于人类反馈的强化学习)。
(3)RLHF(基于人类反馈的强化学习)
RLHF 的过程类似于从大学生步入职场的阶段,在这个阶段我们会开始进行工作,但是我们的工作可能会受到领导和客户的表扬,也有可能会受到批评,我们会根据反馈调整自己的工作方法,争取在职场获得更多的正面反馈。对于大模型来说,在这个阶段它会针对同一问题进行多次回答,人类会对这些回答打分,大模型会在此阶段学习到如何输出分数最高的回答,使得回答更符合人类的偏好。
简单来说,RLHF 的本质就是让大模型 变成“懂人心的助手”—— 不仅把事做对,还能让人类觉得 “舒服、放心”。
二、机器学习
机器学习(Machine Learning, ML)是 人工智能的核心分支,核心是让计算机 从数据中自动学习规律(模式),并利用这些规律完成 预测、分类、决策 等任务(无需人为编写显式规则)。机器学习可以分为监督学习、无监督学习、强化学习。
1. 监督学习
核心逻辑:有人为标注的 “特征→类别” 映射(既有 “苹果 / 香蕉” 的特征描述,也有明确标签)。
举🌰说明:直接教孩子 “圆、红色是苹果,长条形、黄色是香蕉”,让孩子学 “特征→类别” 的对应关系。
关键:依赖 带标签的数据,目标是预测已知类别的归属(如新水果是苹果还是香蕉)。
2. 无监督学习
核心逻辑:只有 特征(形状、颜色),没有预设类别标签,让模型自主发现数据规律。
举🌰说明:给孩子一堆水果,不告诉名字,让他自己通过形状、颜色等属性分组(如把红色圆形归为一类)。
关键:无标签,核心是挖掘 数据内在结构(如聚类、降维),不预设 “苹果 / 香蕉” 等类别。
3. 强化学习
核心逻辑:不直接教规则,而是通过 “试错→奖励 / 惩罚” 的反馈机制 学习,平衡 “探索新方法” 和 “利用经验”。
举🌰说明:让孩子猜水果,猜对给糖(奖励)、猜错不奖励,孩子通过反复尝试,逐渐优化判断策略。
关键:依赖 动态反馈,目标是优化 长期策略(而非直接学特征,而是学 “怎么判断能获得更多奖励”)。
三者核心差异总结:
维度 | 监督学习 | 无监督学习 | 强化学习 |
|---|---|---|---|
数据标签 | 有(明确类别,如苹果) | 无(只有特征,无类别) | 无(靠反馈间接优化) |
学习目标 | 学 “特征→类别” 的映射 | 学数据的分布 / 关联 | 学 “行为→奖励” 的策略 |
类比特点 | 直接教 “答案” | 自主找 “规律” | 试错中找 “最优策略” |
三、AI Agent
1. Agent是什么
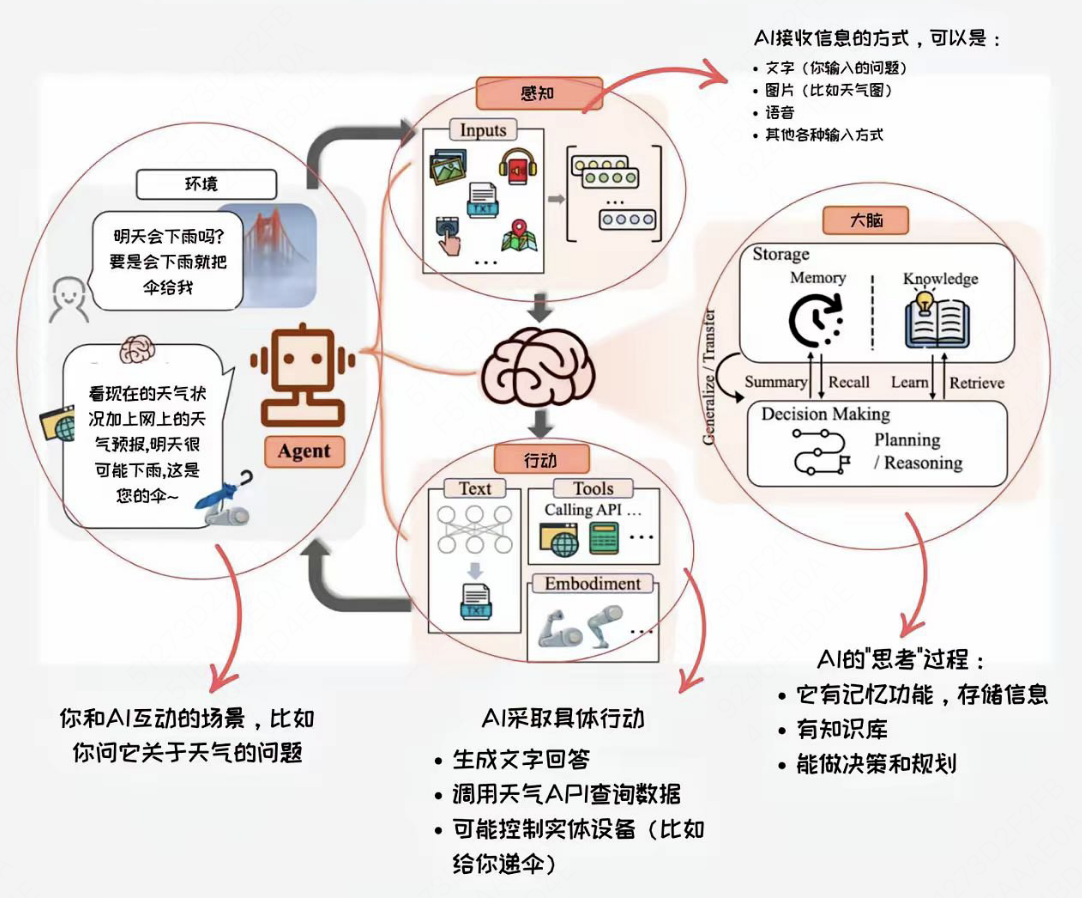
官方定义:AI Agent(人工智能代理)是能够感知环境、进行决策和执行动作的智能实体。
简单说就是:有脑子(LLM)+ 会规划(Planing)+ 会动手(工具调用)+ 懂复盘(记忆)的智能打工人,可以真正实现“理解复杂需求→拆解任务→调用资源→执行解决”的完整流程。
那么Agent 能做什么呢?如果把AI比作“打工人”,普通AI是只会回答问题的客服,而Agent则是能帮你订机票、写报告、管日程的全能管家。以需求 “查今天北京天气并翻译成英文” 为例,Agent 的处理步骤是 “理解需求→调用工具→加工结果→反馈用户” 的闭环:
理解意图:识别用户需要 “天气数据 + 英文翻译”,明确任务目标;
调用工具:自动调用天气接口(比如气象局 API),获取实时天气;
加工处理:调用翻译工具(比如翻译 API),把天气信息转成英文;
输出结果:整理成清晰内容,反馈给用户。
2. 为什么需要 Agent?
关键在于Agent 不是 “空谈”,而是可以串联多个工具、自动化执行任务,帮用户 “解决问题”,而非只回答问题。
用 “淘宝键盘退货” 案例,对比 “普通大模型” vs “Agent” 的核心差异:
普通大模型:只能 “说政策”(比如复述 “淘宝退货规则”),但无法实际操作(比如登录淘宝账号、找到对应订单、发起退货申请);
Agent:能理解复杂流程(退货需要哪些步骤),还能调用工具执行动作(查订单系统、触发退货申请接口),直接帮用户 “做事情”。
→ 总结:大模型是 “说得好但做不到”(靠知识回答),Agent 是 “说得好 + 做得到”(连接工具、执行操作),真正闭环解决问题。
3.Agent 怎么工作?
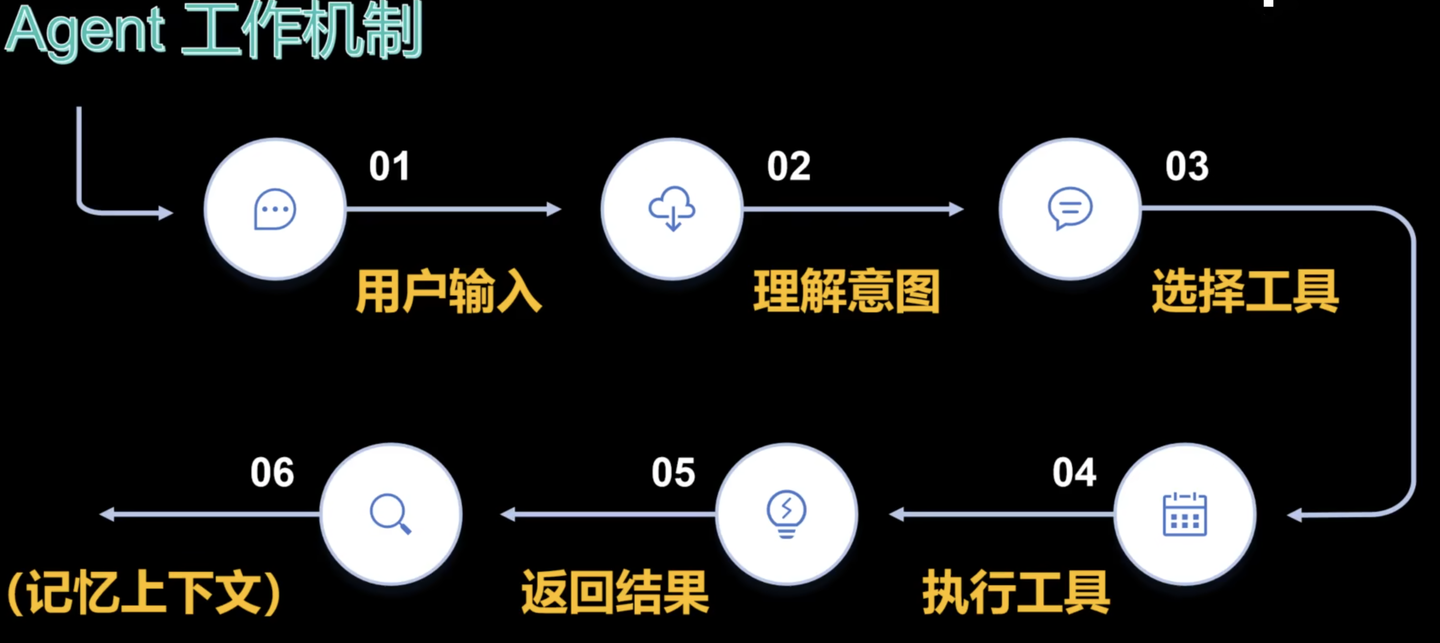
Agent 处理用户需求的完整流程:用户提问 → Agent理解意图 → 选工具 → 执行工具(查数据/调系统等) → 加工结果 → 输出答案。
核心逻辑(类似 “智能助手思维”):
感知:听懂用户需求(比如 “退货” 需要哪些信息);
规划:判断该用什么工具(查订单工具?退货申请接口?);
行动:调用工具执行操作(登录系统、提交申请);
反馈:把结果整理成用户能懂的答案(“已帮您发起退货,预计 3 天到账”)。
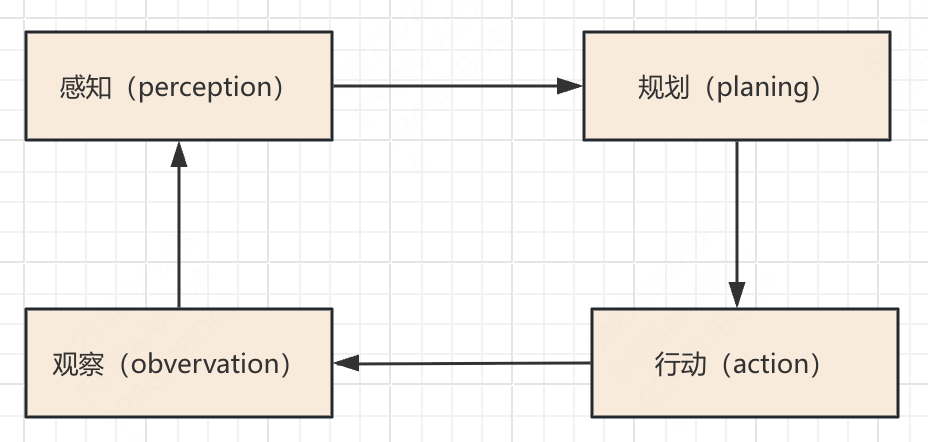
感知的意思就是从外部环境接受到输入,然后交给LLM大脑对任务进行拆解规划,然后根据每一步的规划进行执行该规划即行动,子任务完成后会得到结果即会有反馈,但是结果不一定是好是坏所以要观察该反馈。
Agent的核心工作架构图:
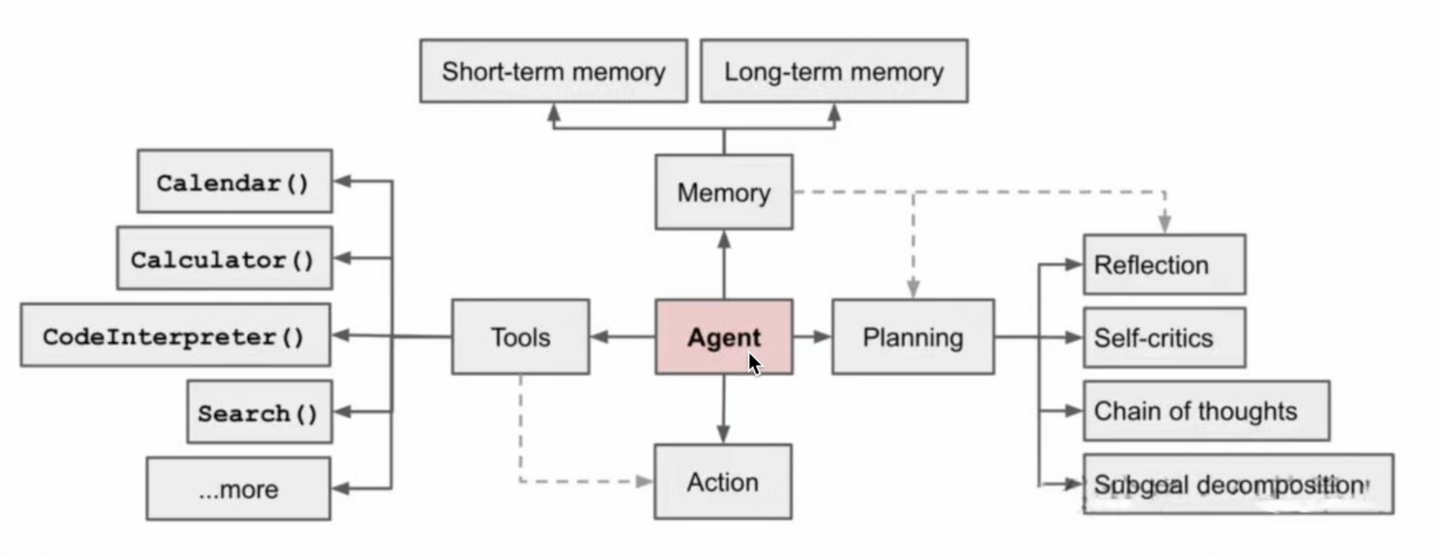
agent核心架构图
规划(Planning): 智能体会把大型任务分解为子任务,并规划执行任务的流程;智能体会对任务执行的过程进行思考和反思,从而决定是继续执行任务,或判断任务完结并终止运行。
记忆(Memory): 短期记忆,是指在执行任务的过程中的上下文,会在子任务的执行过程产生和暂存,在任务完结后被清空。长期记忆是长时间保留的信息,一般是指外部知识库,通常用向量数据库来存储和检索。
工具使用(Tools): 为智能体配备工具 API,比如:计算器、搜索工具、代码执行器、数据库查询工具等。有了这些工具 API,智能体就可以与物理世界交互,解决实际的问题。
执行(Action): 根据规划和记忆来实施具体行动,这可能会涉及到与外部世界的互动或通过工具来完成任务。
举例场景:假设我们有一个智能家居系统,它的任务是根据家庭成员的需求调节室内环境,比如温度和灯光。
感知 (Perception):
(1)家庭成员通过语音助手说:“我感觉有点冷,能不能把温度调高一些?”
(2)智能家居系统通过语音识别和情感分析技术 “感知” 到用户觉得房间温度太低,需要提高温度。
规划 (Planning):
(1)系统根据用户的需求,规划出下一步的行动,决定如何调节房间温度。
(2)系统可能会制定以下计划:
A. 检查当前的室内温度。
B. 根据用户的偏好和当前温度决定升高几度合适。
C. 调整温度设置,并告知用户。
行动 (Action):
(1)系统执行计划的行动,首先检查当前温度,例如发现室温是 20°C。
(2)根据用户的偏好,将温度调高到 23°C,并通过语音助手反馈给用户:“我已经将温度调高到 23°C,请您稍等,温度将逐渐上升。”
观察 (Observation):
(1)系统观察房间温度的变化,以及用户的反馈。如果用户在几分钟后再次说 “现在温度刚刚好”,系统会感知到环境调节成功。
(2)如果用户还觉得冷,系统可能会调整计划,进一步调高温度。
→ 本质:Agent 是一个会思考、会调用工具、会执行 的 AI 助手,不是单纯 "聊天机器人",而是能闭环解决实际问题的 "干活选手"。
4.从最简单通用LLM到专业领域Agent经历阶段
从最简单通用LLM到专业领域Agent经历阶段:直接使用LLM-> 纯知识问答型(知识库 + LLM)-> 知识问答 + 工具调用型(知识库 + LLM + 工具)
对比维度 | 直接使用 LLM | 纯知识问答型(知识库 + LLM) | 知识问答 + 工具调用型(知识库 + LLM + 工具) |
|---|---|---|---|
核心能力 | 通用自然语言处理 | 信息检索与生成(静态知识调用) | 信息检索 + 自动化执行(动态任务执行) |
知识来源 | 单一(LLM 训练数据) | 多源(私域知识 + 联网检索) | 多源(私域知识 + 联网检索 + 业务系统数据) |
技术依赖 | 仅 LLM 大模型 | RAG + LLM | RAG + LLM + MCP 协议 + 工具链(如 WeOps) |
场景适配 | 通用(缺乏运维专业性) | 运维场景适配(知识库增强) | 深度运维场景适配(工具集成 + 流程自动化) |
操作闭环 | 无(仅建议,无执行) | 无(仅知识输出,无工具调用) | 有(问答 - 执行 - 反馈闭环) |
数据时效性 | 滞后(依赖模型训练数据更新) | 实时(联网检索补充) | 实时(工具调用获取最新业务数据) |
典型输出 | 通用文本回答(如 “可能原因:网络问题” ) | 运维知识答案(如 “备份策略:每日全量 + 增量” ) | 操作结果反馈(如 “备份已执行,日志已生成” ) |
复杂度支持 | 低(单一任务,无流程) | 中(知识整合,无工具) | 高(复杂流程 + 工具联动) |
四、Prompt (提示词)
1. 提示词是什么
用一句来解释:提示词 (Prompt) 是引导 LLM 进行内容生成的命令。它可以是任何内容:一句话,一个问题,或者一个计算公式等灯。当 LLM 收到提示词后便开始根据提示词和之前训练的数据,生成相关的回应。
2. Prompt分为两种
SYSTEM PROMPT(系统提示):比如“你是一位极其专业的天气查询专家”。这种定义模型角色(如专业顾问、客服等 )、语调和限制,它影响整个对话过程,确保模型回复符合特定风格并且遵循特定规范。
USER PROMPT(用户提示):比如“我要查询最近三天上海天气”。这种由用户输入的内容,向模型提出具体情境或需求。
3. 提示词工程(Prompt Engineering)
提示词工程(Prompt Engineering),也被称为在上下文中提示,是有技巧的使用提示词,从而最大限度地提高 LLM 响应的有效性、准确性和实用性。“工程” 表明了这是一个持续的,不断迭代优化的过程。
通俗的理解:它是使用一种工程化的思维来指导编写提示词。
4. Prompt 构建的原则
原则一:清晰和明确的指令
模型的提示词需要清晰明确,避免模糊性和歧义。清晰性意味着提示词要直接表达出想要模型执行的任务,比如 “生成一篇关于气候变化影响的文章”,而不是仅仅说 “写一篇文章”。明确性则是指要具体说明任务的细节,比如文章的风格、长度、包含的关键点等。这样,模型就可以更精确地理解任务要求,并产生与之相匹配的输出。
反面例子:“写点关于环保的东西”(任务模糊,是文章、口号还是方案?)
正面例子:“写一篇 300 字的环保倡议书,面向社区居民,强调垃圾分类的具体做法”(任务、对象、内容、形式均明确)
原则二:具体详细,补充必要信息
模型的输出依赖输入的 “信息量”,需提供完成任务所需的关键背景、约束条件或细节(如格式、风格、受众、场景等)。
示例:“以《人工智能在教育中的应用》为主题,写一篇 800 字的学术短文,需引用 1 个具体案例(如智能辅导系统),语言严谨,分 3 个段落(现状、优势、挑战)”。
原则三:合理设定角色与场景
通过给模型 “贴标签”(指定角色)或 “搭场景”(限定语境),引导输出贴合特定身份或场景的内容,增强专业性和代入感。
角色:互联网公司产品经理
场景:给开发团队同步 “用户反馈中‘APP 加载慢’的优化需求”
任务:说明 3 个具体问题(如 “首页图片加载延迟 2 秒”“切换页面卡顿”),并给出优先级(“优先解决首页加载,需本周内出方案”)
效果:输出会包含 “用户痛点数据”“技术优化方向建议”“时间节点”,符合产品经理对接开发的专业沟通风格,而非泛泛而谈。
原则三:用 “示例” 引导输出格式 / 风格(少样本学习)
可以使用一些样例数据来指引模型输出,规范模型的输出格式。
例子如下,当然正常开发情况下我们会要求大模型用Json格式输出内容
添加图片注释,不超过 140 字(可选)
原则四:复杂任务拆解,分步引导
对于多步骤、高难度任务(如逻辑推理、方案设计),避免一次性抛出复杂需求,可拆分为 “子任务”,按顺序逐步引导模型完成。
举🌰说明:“请设计一个校园读书节活动方案: 第一步:确定活动主题(需包含‘青春’和‘阅读’关键词); 第二步:列出 3 个核心环节(每个环节说明目的和时长); 第三步:总结活动的预期效果。”
5. Prompt 的结构化设计
Prompt 的结构化设计框架,核心是通过 “分层定义要素” 让模型更精准理解任务
(1)Context 上下文(可选)
作用:提前交代背景信息,帮模型代入场景、明确模型身份和知识边界。
角色:指定模型扮演的身份(如 “初中数学老师”“民国小报记者”),约束语言风格和专业视角。
任务:一句话概括核心目标(如 “设计校园读书节方案”“分析用户投诉原因”),避免任务模糊。
知识:补充模型可能不知道的背景(如 “基于 2024 年某公司财报数据”“针对‘APP 加载慢’的用户反馈”),防止模型 “猜信息”。
(2)Instruction 命令(必选)
作用:明确 “怎么做”,是 Prompt 的核心指令区,决定模型的思考路径。
步骤:拆分任务为子步骤(如 “第一步确定主题,第二步设计环节”),降低模型处理复杂度(对应 “任务拆解原则”)。
思维链:要求模型展示思考过程(如 “先分析《静夜思》的修辞手法,再解释‘望’字的作用”),适合逻辑推理类任务(让模型 “透明化思考”)。
示例:提供参考案例(如 “模仿以下格式分类水果”),让模型快速对齐输出风格(对应 “少样本学习”)。
(3)input data 输入数据(必选)
作用:提供模型需要处理的具体内容。
句子:短文本(如 “分析‘举头望明月’的用字技巧”)。
文章:长文本(如 “基于以下 1000 字的产品说明书,提炼 3 个核心功能”)。
问题:具体疑问(如 “为什么彩虹是弧形的?用生活化例子解释”)。
(4)output indicator 输出格式(可选)
作用:约束输出的形式、长度、风格,可以供后续程序处理。
举一个例子:
Context(上下文): - 角色:初中语文老师(教《孔乙己》,班级是初二3班,学生活泼但对“隐喻”理解弱) - 任务:设计15分钟课堂活动,分析“孔乙己的长衫象征意义” - 知识:学生已学课文内容,需从“具象物品”过渡到“抽象象征” Instruction(命令): - 步骤:① 导入(拆解“长衫的材质/补丁”)→ ② 分组讨论(类比“现代社会的‘长衫’,如学历、标签”)→ ③ 创意造句(“如果孔乙己活在2025年,他的‘长衫’会是什么?”) - 思维链:从「具象→抽象→现实迁移」,降低理解难度(符合初中生认知) - 示例:活动开场话术 “同学们,孔乙己的长衫又脏又破,但他死也不肯脱——这件长衫上的补丁,像不像我们拼命想抓住的‘面子’?今天咱们就来拆拆这件‘长衫’里的秘密!” Input data(输入数据): 课文段落:“孔乙己是站着喝酒而穿长衫的唯一的人…穿的虽然是长衫,可是又脏又破,似乎十多年没有补,也没有洗。” Output indicator(输出格式): - 格式:分「导入语+活动流程+引导问题」3部分,每部分配1个互动技巧(如“让举手最快的同学当‘长衫解说员’”) - 语言:口语化+比喻(把“象征分析”比作“剥洋葱”,层层拆解)
五、RAG(检索增强生成)
1.RAG 是什么
RAG 的全称是 Retrieval Argumented Generation,中文是检索增强生成。意思是把检索(资料库)的结果发给大模型,以增强大模型的生成能力。
RAG技术定义:通过引入外部知识库,利用检索模型从大量文档中提取相关信息,Prompt组合问题和外部信息,生成更精准且实时的回答。
RAG 本质上就是把搜索到的资料作为提示词的一部分发给大语言模型,让大语言模型有根据地输出内容,从而降低大模型“臆想答案”的概率。 OpenAI 曾分享的案例中,通过对 RAG 技术的应用将回答准确率从 45% 提升到了 98%,可见 RAG 的重要性。
2.RAG 的应用
RAG 能够实时从企业或领域的私有知识库中检索相关信息,确保生成的回答不仅准确且符合企业内部的最新动态,解决了大模型在处理特定领域知识时的局限性。此能力应用在企业或专业领域知识管理与问答系统。
RAG 可以动态地将用户的询问与最新的产品信息、客服知识等外部数据相结合,生成的回答更加贴合客户的实际需求,且满足企业要求。此能力应用在客户支持与智能客服系统中。
3.RAG 标准技术流程
RAG 标准流程由索引(Indexing)、检索(Retriever)和生成(Generation)三个核心阶段组成。
索引阶段,通过处理多种来源多种格式的文档提取其中文本,将其切分为标准长度的文本块(chunk),并进行嵌入向量化(embedding),向量存储在向量数据库(vector database)中。
检索阶段,用户输入的查询(query)被转化为向量表示,通过相似度匹配从向量数据库中检索出最相关的文本块。
最后生成阶段,检索到的相关文本与原始查询共同构成提示词(Prompt),输入大语言模型(LLM),生成精确且具备上下文关联的回答。
六、Function calling (函数调用)
1.Function calling 是什么
Function calling 的中文意思是函数调用。通俗的理解:大语言模型的 Function calling 能力就是把自然语言指令转换为函数的调用指令,从而使自然语言指令可以被执行。
可以被运行的函数有很多种,比如 Java 函数、Python 函数,而在 AI 产品中最常见的函数调用方式就是调用微服务架构下的各种 API 。OpenAI的Function Calling规范:包含了工具类型Type和工具定义Function两个部分,工具类型是写死的 "function",工具定义包含名称、描述和参数三个部分。
例子如下,通过提示词的方式让大语言模型完成函数调用的任务。
## Instruction
你是一个人工智能编程助手,根据用户请求和函数定义,调用函数来完成任务,并以代码格式进行回应,无需回复其他话语。请特别注意函数的定义。## 函数定义tools = [{"type": "function","function": {"name": "get_current_weather","description": "Get the current weather in a given location","parameters": {"type": "object","properties": {"location": {"type": "string","description": "The city and state, e.g. San Francisco, CA",},},"required": ["location"],}}}]## 用户请求查一下今天上海的天气我们把上述的例子输入给到 Open AI 的 GPT Playground,GPT 就会输出以下 API Request,这就可以直接被机器运行。我们就实现了将自然语言指令转变为计算机可执行指令。
{"function": "get_current_weather","parameters": {"location": "上海"}
}